Spark---资源、任务调度
一、Spark资源调度源码
1、Spark资源调度源码过程
Spark资源调度源码是在Driver启动之后注册Application完成后开始的。Spark资源调度主要就是Spark集群如何给当前提交的Spark application在Worker资源节点上划分资源。Spark资源调度源码在Master.scala类中的schedule()中进行的。
2、Spark资源调度源码结论
- Executor在集群中分散启动,有利于task计算的数据本地化。
- 默认情况下(提交任务的时候没有设置--executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
- 如果想在Worker上启动多个Executor,提交Application的时候要加--executor-cores这个选项。
- 默认情况下没有设置--total-executor-cores,一个Application会使用Spark集群中所有的cores。
- 启动Executor不仅和core有关还和内存有关。
3、资源调度源码结论验证
使用Spark-submit提交任务演示。也可以使用spark-shell来验证。
1、默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit
--master spark://node1:7077--class org.apache.spark.examples.SparkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar
100002、在workr上启动多个Executor,设置--executor-cores参数指定每个executor使用的core数量。
./spark-submit--master spark://node1:7077--executor-cores 1 --class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
100003、内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 3g
--class org.apache.spark.examples.SparkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000--total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 2g
--total-executor-cores 3
--class org.apache.spark.examples.SparkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000二、Spark任务调度源码
Spark任务调度源码是从Spark Application的一个Action算子开始的。action算子开始执行,会调用RDD的一系列触发job的逻辑。其中也有stage的划分过程:
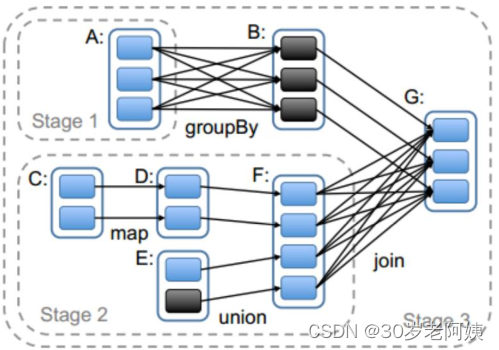
三、Spark二次排序和分组取topN
1、二次排序
大数据中很多排序场景是需要先根据一列进行排序,如果当前列数据相同,再对其他某列进行排序的场景,这就是二次排序场景。例如:要找出网站活跃的前10名用户,活跃用户的评测标准就是用户在当前季度中登录网站的天数最多,如果某些用户在当前季度登录网站的天数相同,那么再比较这些用户的当前登录网站的时长进行排序,找出活跃用户。这就是一个典型的二次排序场景。
解决二次排序问题可以采用封装对象的方式,对象中实现对应的比较方法。
1.SparkConf sparkConf = new SparkConf()
2..setMaster("local")
3..setAppName("SecondarySortTest");
4.final JavaSparkContext sc = new JavaSparkContext(sparkConf);
5.
6.JavaRDD<String> secondRDD = sc.textFile("secondSort.txt");
7.
8.JavaPairRDD<SecondSortKey, String> pairSecondRDD = secondRDD.mapToPair(new PairFunction<String, SecondSortKey, String>() {
9.
10. /**
11. *
12. */
13. private static final long serialVersionUID = 1L;
14.
15. @Override
16. public Tuple2<SecondSortKey, String> call(String line) throws Exception {
17. String[] splited = line.split(" ");
18. int first = Integer.valueOf(splited[0]);
19. int second = Integer.valueOf(splited[1]);
20. SecondSortKey secondSortKey = new SecondSortKey(first,second);
21. return new Tuple2<SecondSortKey, String>(secondSortKey,line);
22. }
23.});
24.
25.pairSecondRDD.sortByKey(false).foreach(new
26.VoidFunction<Tuple2<SecondSortKey,String>>() {
27.
28. /**
29. *
30. */
31. private static final long serialVersionUID = 1L;
32.
33. @Override
34. public void call(Tuple2<SecondSortKey, String> tuple) throws Exception {
35. System.out.println(tuple._2);
36. }
37.});
38.
39.
40.
41.public class SecondSortKey implements Serializable,Comparable<SecondSortKey>{
42. /**
43. *
44. */
45. private static final long serialVersionUID = 1L;
46. private int first;
47. private int second;
48. public int getFirst() {
49. return first;
50. }
51. public void setFirst(int first) {
52. this.first = first;
53. }
54. public int getSecond() {
55. return second;
56. }
57. public void setSecond(int second) {
58. this.second = second;
59. }
60. public SecondSortKey(int first, int second) {
61. super();
62. this.first = first;
63. this.second = second;
64. }
65. @Override
66. public int compareTo(SecondSortKey o1) {
67. if(getFirst() - o1.getFirst() ==0 ){
68. return getSecond() - o1.getSecond();
69. }else{
70. return getFirst() - o1.getFirst();
71. }
72. }
73.}2、分组取topN
大数据中按照某个Key进行分组,找出每个组内数据的topN时,这种情况就是分组取topN问题。
解决分组取TopN问题有两种方式,第一种就是直接分组,对分组内的数据进行排序处理。第二种方式就是直接使用定长数组的方式解决分组取topN问题。
1.SparkConf conf = new SparkConf()
2..setMaster("local")
3..setAppName("TopOps");
4.JavaSparkContext sc = new JavaSparkContext(conf);
5.JavaRDD<String> linesRDD = sc.textFile("scores.txt");
6.
7.JavaPairRDD<String, Integer> pairRDD = linesRDD.mapToPair(new PairFunction<String, String, Integer>() {
8.
9. /**
10. *
11. */
12. private static final long serialVersionUID = 1L;
13.
14. @Override
15. public Tuple2<String, Integer> call(String str) throws Exception {
16. String[] splited = str.split("\t");
17. String clazzName = splited[0];
18. Integer score = Integer.valueOf(splited[1]);
19. return new Tuple2<String, Integer> (clazzName,score);
20. }
21.});
22.
23.pairRDD.groupByKey().foreach(new
24.VoidFunction<Tuple2<String,Iterable<Integer>>>() {
25.
26. /**
27. *
28. */
29. private static final long serialVersionUID = 1L;
30.
31. @Override
32. public void call(Tuple2<String, Iterable<Integer>> tuple) throws Exception {
33. String clazzName = tuple._1;
34. Iterator<Integer> iterator = tuple._2.iterator();
35.
36. Integer[] top3 = new Integer[3];
37.
38. while (iterator.hasNext()) {
39. Integer score = iterator.next();
40.
41. for (int i = 0; i < top3.length; i++) {
42. if(top3[i] == null){
43. top3[i] = score;
44. break;
45. }else if(score > top3[i]){
46. for (int j = 2; j > i; j--) {
47. top3[j] = top3[j-1];
48. }
49. top3[i] = score;
50. break;
51. }
52. }
53. }
54. System.out.println("class Name:"+clazzName);
55. for(Integer sscore : top3){
56. System.out.println(sscore);
57. }
58.}
59.});相关文章:
Spark---资源、任务调度
一、Spark资源调度源码 1、Spark资源调度源码过程 Spark资源调度源码是在Driver启动之后注册Application完成后开始的。Spark资源调度主要就是Spark集群如何给当前提交的Spark application在Worker资源节点上划分资源。Spark资源调度源码在Master.scala类中的schedule()中进行…...

单片机开发常见问题集合
文章目录 发送串口数据偶尔丢失字节 发送串口数据偶尔丢失字节 场景: 在STM32单片机中进行串口数据发送,在Linux/Windows上进行串口数据接收,会偶发出现接收到的数据有某些字节丢失。 分析: 在STM32中可以使用printf用于发送串口…...

Matlab 点云曲率计算(之二)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 之前已经讨论过许多关于计算曲率的问题,这里使用一个通过拟合三次曲面方程的方式来计算曲率,计算过程如下图所示: 二、实现代码 %********...

C++11的原子变量
C11提供了一个原子类型std::atomic<T>,可以使用任意类型作为模板参数,C11内置了整型的原子变量,可以更方便的使用原子变量,使用原子变量就不需要使用互斥量来保护该变量了,用起来更简洁。例如,要做一…...
 考试试卷)
北京交通大学 计算机网络体系与协议(研) 考试试卷
计算机网络体系与协议2023年期末考试 时长:120分钟 学院: 学号: 姓名: 一、简答题(每题5分) 1.简述公开密钥密码体制的工作原理…...
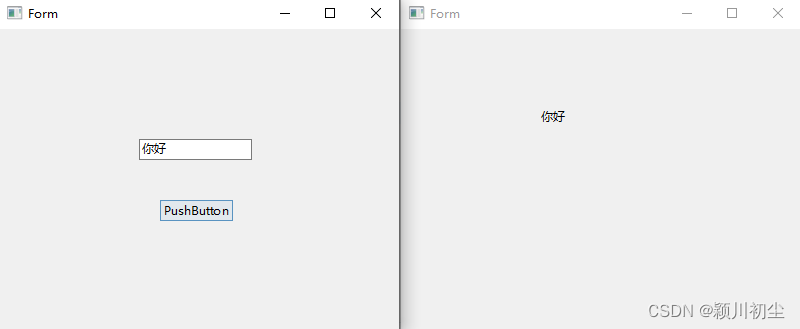
python之pyqt专栏7-信号与槽3
在上一篇文章中python之pyqt专栏6-信号与槽2-CSDN博客中,我们可以了解到对象可以使用内置信号,这些信号来自于类定义或者继承过来的。我们可以对这些信号可以通过connect连接槽函数。 需求 现在有一个需求,有两个UI界面“untitled.ui”和“u…...

高噪点灰度图目标粗定位CoraseLocation
高噪点的灰度图目标粗定位 /* ** name: CoraseLocation ** brief: 粗定位 ** param:[in] srcGray 灰度图() ** param:[in] box 目标尺寸(像素) ** param:[ou] roi 目标定位结果 ** return: true成功,false…...
)
Android:Google三方库之Firebase集成详细步骤(二)
Analytics分析 1、将 Firebase 添加到您的 Android 项目(如果尚未添加),并确保在 Firebase 项目中启用了 Google Analytics(分析): 如果您要创建新的 Firebase 项目,请在项目创建过程中启用 G…...

java使用freemarker模板生成html,再生成pdf
1.freemarker模板生成html 添加Maven依赖 在pom.xml文件中添加以下依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-freemarker</artifactId> </dependency>创建Freemarker…...

图解系列--Web服务器,Http首部
1.用单台虚拟主机实现多个域名 HTTP/1.1 规范允许一台 HTTP 服务器搭建多个 Web 站点。。比如,提供 Web 托管服务(Web Hosting Service)的供应商,可以用一台服务器为多位客户服务,也可以以每位客户持有的域名运行各自不…...
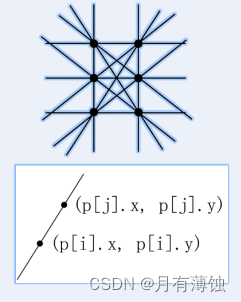
直线(蓝桥杯)
直线 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 在平面直角坐标系中,两点可以确定一条直线。如果有多点在一条直线上, 那么这些点中任意两点确定的直线是同一条。 给定平面上 2 3 个…...

Android:从源码看FragmentManager如何工作
一个Activity中,在某一个容器中,更换不同的Fragment,从而显示不同的界面,这个场景相信大家已经非常熟悉了,也知道Activity是通过FragmentManager来管理嵌入的Fragments的,所以今天就来看看FragmentManager是…...
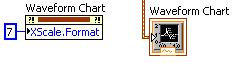
LabVIEW通过编程将图形类控件的X轴显示为时间戳
LabVIEW通过编程将图形类控件的X轴显示为时间戳 每个版本的LabVIEW中都有属性节点,可以以编程方式调整X轴和Y轴格式。对于不同版本的LabVIEW,这些属性节点无法在同一个位置找到。请参阅以下部分,了解特定版本LabVIEW的相关属性节点的位置。 …...
Spring Boot进行单元测试,一个思路解决重启低效难题!
所谓单元测试就是对功能最小粒度的测试,落实到JAVA中就是对单个方法的测试。 junit可以完成单个方法的测试,但是对于Spring体系下的web应用的单元测试是无能为力的。因为spring体系下的web应用都采用了MVC三层架构,依托于IOC,层级…...

c/c++ header_only 头文件实现的关键点
header_only 头文件实现的关键点 ------------------------------------------------------------------------- author: hjjdebug date: 2023年 11月 28日 星期二 16:58:38 CST descriptor: header_only 头文件实现的关键点1. 对外声明的函数必需加上inline, 消除连接的歧义…...
:通过docker安装redis)
Linux(CentOS7.5):通过docker安装redis
一、准备配置文件 在宿主机,准备映射配置文件的目录下,运行如下: wget http://download.redis.io/redis-stable/redis.conf二、安装 docker run \ --restartalways \ --log-opt max-size100m \ --log-opt max-file2 \ -p 6380:6379 \ -v /opt…...

唯创知音WT588F02B-8S语音芯片:灵活更换语音内容,降低开发成本与备货压力
在电子产品的开发阶段,语音芯片的选择与使用对于产品的功能、成本和上市时间都有着重要影响。唯创知音的WT588F02B-8S语音芯片以其独特的优势,成为工程师们的理想选择,尤其在样品阶段,它为工程师提供了自行更换语音内容的便利&…...
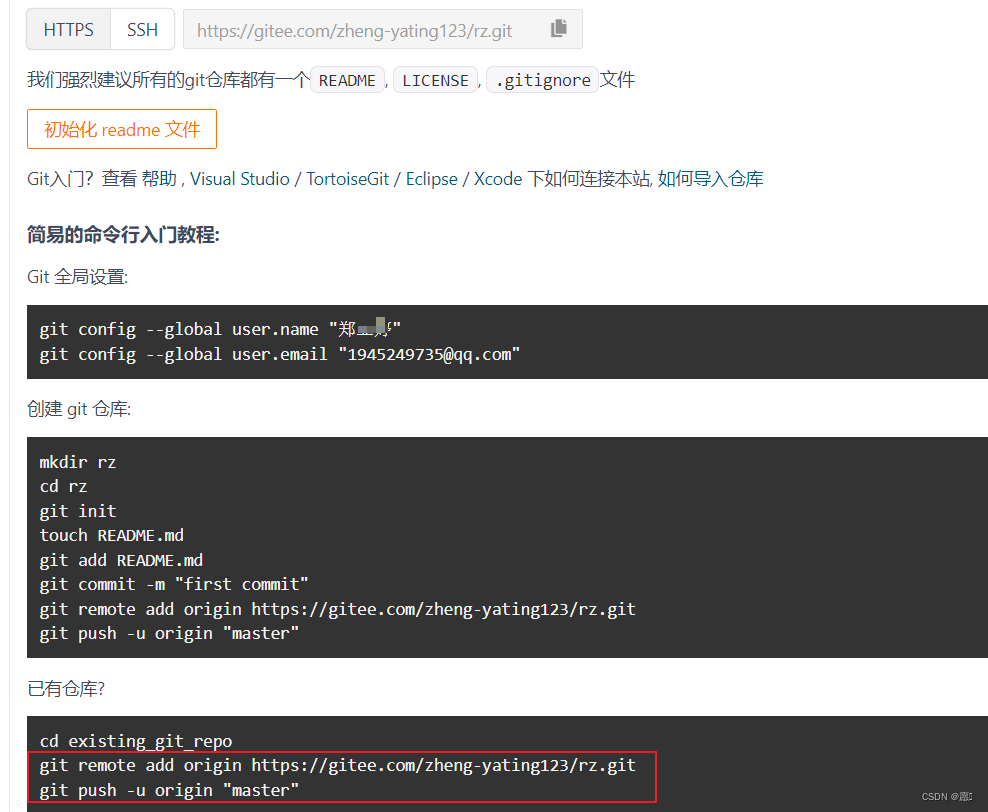
git的创建以及使用
1、上传本地仓库 首先确定项目根目录中没有.git文件,有的话就删了,没有就下一步。在终端中输入git init命令。注意必须是根目录! 将代码存到暂存区 将代码保存到本地仓库 2、创建git仓库 仓库名称和路径(name)随便写…...

面试笔记--Linux常用命令
文件和目录操作: ls: 列出目录内容 例子:ls -l - 列出详细信息,包括权限、所有者等 cd: 切换目录 例子:cd Documents - 进入 “Documents” 目录 pwd: 显示当前工作目录 例子:pwd - 显示当前工作目录的路径 cp: 复制文…...

【小黑嵌入式系统第十课】μC/OS-III概况——实时操作系统的特点、基本概念(内核任务中断)、与硬件的关系实现
文章目录 一、为什么要学习μC/OS-III二、嵌入式操作系统的发展历史三、实时操作系统的特点四、基本概念1. 前后台系统2. 操作系统3. 实时操作系统(RTOS)4. 内核5. 任务6. 任务优先级7. 任务切换8. 调度9. 非抢占式(合作式)内核10…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...