【Linux进阶之路】进程间通信
文章目录
- 一、原理
- 二、方式
- 1.管道
- 1.1匿名管道
- 1.1.1通信原理
- 1.1.2接口使用
- 1.2命名管道
- 2.共享内存
- 2.1原理
- 2.2接口使用
- 3.消息队列
- 原理
- 4.信号量
- 引入
- 原理
- 总结
一、原理
- 进程间的通信是什么?
- 解释: 简单理解就是,不同进程之间进行数据的输入输出。
- 为什么要进行进程间通信呢?
解释:
- 不同进程实现数据的交互,资源的共享,进程控制的手段。
- 数据交互,类似与读写过程,你给我发消息,我收到了,并对消息进行读取和处理;
- 资源共享,是多个进程可以对同一块空间进行读取和写入;
- 进程控制,比如一个进程给另一个进程发送kill -9 号新号结束一个进程。
- 如何实现进程间通信呢?
解释:
- 首先进程间是独立的,这就意味着一个进程不可能直接从另一个进程中拿数据,即使是父子进程,因为有写时拷贝的原因,在数据写入之前,即使数据共享,也无法完成通信(因为一旦写入就会发生写时拷贝)。
- 因此进程间通信是有成本的,而实现进程间通信,必然免不了要靠操作系统牵线搭桥 ,即让操作系统开辟空间,让不同的进程访问同一份资源,对第三方空间进行修改,自然可以完成通信。
- 进程代表着用户,而操作系统不会让程序员写的代码直接访问内核,而是给用户提供系统调用接口,这样既保证了内核的安全,也能让内核能帮程序员干正事。
- 因此进程间实现通信本质上是进程通过系统调用接口进而使操作系统让不同的进程看到了同一份资源。
- 拓展
- 进程通信是要有一定的标准,当所有人都遵循一套标准时,可以扩大标准的影响范围,同时还能降低通信的成本。
- 进程通信采取的标准为IPC(System V 与POSIX),而没有这套通信标准时,通常采用管道的方式进行通信。
二、方式
1.管道
- 首先我们先从其名理解一下管道的意思:

这样数据从一端进去,然后从一端出去,这样的具有单向通信的特点的,我们就称之为管道。
- 其次管道是文件我们从文件的角度来理解管道。
如何存储数据呢?我们通常都会想到文件,那文件是可以多进程共享吗?答案是可以的,既然这样文件也可以实现通信,那根据之前我们所学的文件,如果文件通信具体的过程是如何的?我们画图演示。
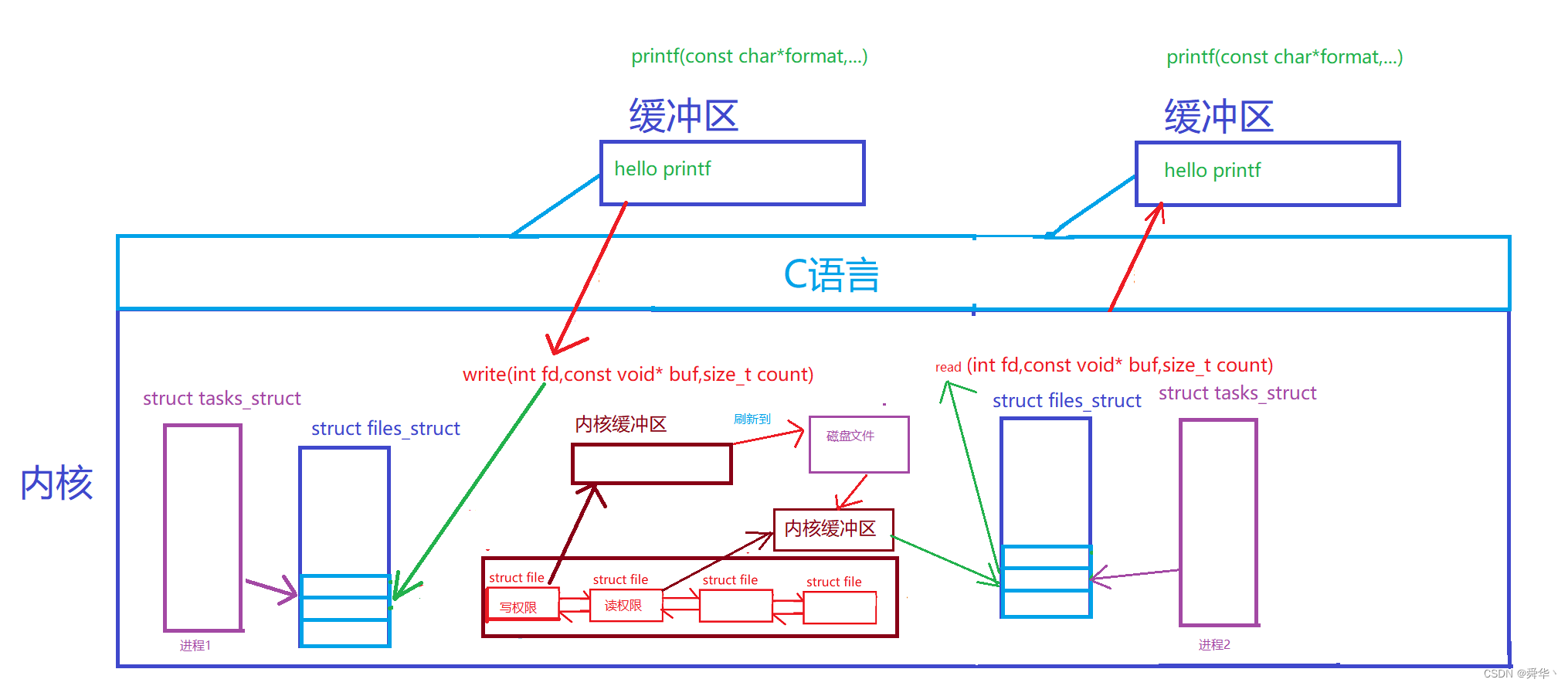
光看图比较直观,但还尚需一些文字进行点缀,下面我们进行补充:
- 不同进程在进行打开文件时,其实有两个缓存区,其一在于C语言层次方便进行格式化的缓存区,其二是操作系统自动维护的用于存数据的缓存区。
- 在进行写入时,我们首先要将内容拷贝到C语言的缓存区当中,在刷新时拷贝到内核的缓存区中,由缓存区再刷新到磁盘当中,这其中进行了3次拷贝。而且还要刷新到磁盘当中,时间的效率是比较低的。
- 在读取时,需要先让磁盘刷新完成再进行读取,与写入同理也要进行3次拷贝,而且由于磁盘是外设,效率也是比较低的。
- 拓展: 由于文件打开时权限的不同,因此会拥有不同的struct file,但其中的其它信息基本都是一致的比如文件的innode编号。
- 我们看到这其中的具体过程之后,发现进程通信是有一定成本的,这个成本在于硬件的刷新速度,以及拷贝的效率等方面,那我们如何提升呢?这就该思考是否存在这样的文件,无需刷新到磁盘,只需在用时在内存开辟空间呢?
- 答案是肯定的,那就是内存文件,且内存文件除了不写入磁盘外,跟普通的文件一样。但是就是因为这一点,内存文件当做通信的共享资源的效率是比普通文件高很多的。
- 那管道很显然就是内存文件。再结合之前的定义,管道的结构,单向通信,我们便可大概知道管道的基本原理。
下面我们进一步来看两种管道——匿名管道与命名管道。
1.1匿名管道
1.1.1通信原理
- 首先看名字便知是没有名字的管道。
- 通过之前的知识我们并不会感到奇怪,因为文件的属性并不包含文件名,只有inode编号所为唯一标识符。
- 其文件名是放在目录下的,没有文件名就代表着我们用路径 + 文件名的方式是找不到这个文件的。
- 其次没有名字的管道我们如何创建与读写。
- 肯定存在系统调用接口,让我们创建没有名字的管道。
- 但是对于进程来讲,文件描述符便是文件/管道的名字,即使没有名字我们也可以用文件描述符对文件/管道进行读写。
- 最后没有名字的管道如何实现共享。
- 首先没有名字,我们看是否可以将inode传给另一个进程,发现是不可行的,因为我们实现的问题本身就是进行通信。
- 那我们可以从进程的files_struct进行入手,因为进程在创建时,子进程会继承到files_struct,也就是父进程的文件,子进程是也可以进行进行操作。
- 因此进程的创建与files_struct的拷贝变相的实现了,匿名管道的资源的共享。
因此:进程通过匿名管道进行通信,我们可以断定进程之间必然拥有血缘关系。
1.1.2接口使用
- 初识接口
头文件:
#include<unistd.h>
函数声明:
int pipe(int pipefd[2]);
函数参数:
* 一个至少有两个元素的数组,实际上传参传的是数组名。
* 这里的pipefd[0]是读端,pipefd[0]是写端。
返回值:
* 成功返回0。
* 失败返回-1,并设置合适的错误码。
下面我们细讲一下为什么要设计int pipefd[2]这样的接口:
- 从管道的定义来看,管道具有单向通信的特点。
- 这就意味着只能一端读一端写,因此需要读写两个文件描述符。
- 其次父进程打开读和写,子进程继承之后,假设父进程关闭读端,子进程关闭写端,这样父端写子端读,进而达成了单向通信。
图解:

- 为什么要单向通信呢?
解释:
- 读端和写端可以看做出数据的口,和入数据的口,从而更加方便的处理数据。
- 如果都进行写入和读取,数据会杂乱无章,不方便进行处理。
- 使用与论证
1 .论证,这里我们实验验证几个问题。
说明:为了验证下面的结论我们只给出读写方法,因为这里的整体框架大致相同,只有读写方法不同。
#include<iostream>
#include<string>
#include<cstdio>
#include<cstdlib>
#include<unistd.h>
using namespace std;
#define SIZE (4096)
int main()
{int pipe_fd[2];int ret_pipe = pipe(pipe_fd);if(ret_pipe != 0){perror("pipe");exit(1);}int pid = fork();if(pid == 0){//子进程//关闭写端,保留读端close(pipe_fd[1]);Read(pipe_fd[0]);exit(0);}else if(pid < 0){perror("fork");exit(1);}//父进程//关闭读端,保留写端close(pipe_fd[0]);Write(pipe_fd[1],pid);return 0;
}
- 既然只能进行单向通信,那么我们可能会关心如下问题:
- 读端与写端都打开,如何正常运行。
验证代码:
- 读写方法
void Read(int rfd)
{while(true){char buf[SIZE];int sz = read(rfd,buf,sizeof(buf));if(sz == 0) break;if(sz == -1){perror("read");exit(-1);}//cout << sz << endl;buf[sz] = '\0';//添上字符串结尾标识符。cout << "my pid is " << getpid() << " What I read from father is " << buf << endl;}
}
void Write(int wfd,int pid)
{while(true){string buf;cout << "fahter say to "<< pid << " :";getline(cin,buf);int ret = write(wfd,buf.c_str(),buf.size());if(ret == -1){perror("write");exit(1);}sleep(1);}
}
- 代码解读:首先,我们写的代码意思是,父进程进行写,子进程进行读,两个进程进行通信。
- 实验过程:
- 观察现象:
- 首先,我们向子进程发送了ni hao 信息,写完之后,子进程进行了读取。
- 其次,我们再向子进程发送信息,写完之后,子进程进行读取,此时上一次的信息已经没了。
- 实验结论:
- 是在父进程写完之后,子进程再进行读取的,因此在父进程未完成写入之前,子进程的读端是陷入阻塞状态的,这样可以保证读取数据的完整性。
- 再进行写入与读取时,上一次的数据已经被刷新了,因此再子进程进行读取时,会刷新管道,并且会调整文件指针(写与读)到开头。
- 拓展:
原子性—— 文件执行流,比如这里子进程与父进程进行的读写操作,是在父进程完成写入之后,子进程再进行读取的,不是在父进程正在写的过程中进行的读取,前面的写完再读,这样进程之间再操作同一文件的互不干扰的性质,我们称之为原子性。

- 读端与都打开,写端写满之后,会发生什么。
- 读写方法
void Read(int rfd)
{while(true);
}
void Write(int wfd,int pid)
{int cnt = 0;while(true){cout << cnt++ << endl;int ret = write(wfd,"C",1);}
}
- 代码说明:此处我们一直进行写,并记录写入的字节数,直到写不进看看写端会发生什么,并且看看此时的已经写入的字节数。
- 实验过程:
- 观察现象
- 我们可以看出此时写端陷入了阻塞状态,并且此时写入的字节数为65536,即64KB。
- 实验结论:
- 管道在Linux下大概为64KB,不同平台的数据可能不一样,要根据实际情况进行讨论。
- 管道在写满时,写端会陷入阻塞。

- 读端关闭,写端会发生什么。
- 读写方法
void Read(int rfd)
{int cnt = 3;while(true){char buf[SIZE];int sz = read(rfd,buf,sizeof(buf));buf[sz] = '\0';//添上字符串结尾标识符。cout << "my pid is " << getpid() << " What I read from father is " << buf << endl;if(cnt-- == 0)//读写4次之后读端进行关闭{ close(rfd);break;}}
}
void Write(int wfd,int pid)
{while(true){string buf;cout << "fahter say to "<< pid << " :";getline(cin,buf);int ret = write(wfd,buf.c_str(),buf.size());sleep(1);}
}
- 代码解读:首先我们先正常的读写三次,然后关闭读端,看看写端会发生什么。
- 实验过程:
- 现象分析
- 首先这里读写四次是正常的,当我们关闭读端时,写端还没有异常现象,此时我们再进行写入,发现代码异常退出了。
- 其次这里我们打印出退出信息发现,这里的信息异常为代码异常退出的结果。
- 最后我们分析141,发现其是管道破裂信号。
- 实验结论:
- 关闭读端时,此时写端写是没有意义的。
- 其次关闭读端,写端不知道的情况下写,会收到管道破裂信号。


- 写端关闭,读端会发生什么。
- 读写方法
void Read(int rfd)
{while(true){char buf[SIZE];int sz = read(rfd,buf,sizeof(buf));if(sz == 0){cout << "I read nothing" << endl;break;}buf[sz] = '\0';//添上字符串结尾标识符。cout << "my pid is " << getpid() << " What I read from father is " << buf << endl;}
}
void Write(int wfd,int pid)
{ int cnt = 3;while(true){string buf;cout << "fahter say to "<< pid << " :";getline(cin,buf);int ret = write(wfd,buf.c_str(),buf.size());if(--cnt == 0)//读写3次之后读端进行关闭{ close(wfd);cout << "wfd is closed"<< endl;break;}sleep(1);}
}
- 代码解读:首先正常的读取3次之后,写端进行关闭,此时我们看看读端会发生什么。
- 实验现象:
- 观察现象:
- 正常读写三次之后,我们将写端关闭,此时读端立马从阻塞状态转换为非阻塞状态。打印出 I read nothing.
- 此后,读端break,最终退出。
- 实验结论:
- 写端关闭,意味着无法对管道进行写入,而读端从阻塞状态转换为非阻塞状态,若没有break会一直读取。
- 写端关闭,读端是会收到状态转化的影响,但并不会使进程陷入异常状态。

- 总结一下:
- 管道读写端打开,正常写入时,读端陷入阻塞,且读完之后会刷新缓存区和文件指针。
- 管道读写端打开,一直写,不进行读取。管道写满之后,写端会陷入阻塞状态。
- 管道读端关闭,写端打开。无法正常进行读写,强行写会收到管道破裂信号。
- 管道写端关闭,读端打开。读端从阻塞状态变为非阻塞状态,一直进行读(读到文件末尾)。
- 使用,此处我们模拟实现一个进程池。
- 定义:在没有使用进程时,我们预先创建一批进程,在用时使用,不用再还回去。
- 原理:这就好比买一桶可乐放在身边想喝就喝,和想喝可乐了,再去商店里只买一瓶的道理一样。买一桶,可以喝好多次,方便。而现喝现买,而且还只能喝一瓶,不方便。
- 实现方法:
- 先由父进程创建若干个进程,在下面的实验中我创建十个子进程。
- 让父进程与子进程之间产生建立管道产生通信。
- 子进程进入读信息的死循环中,父进程进入到写信息的死循环中。
- 对进程进行初始化
struct conduit//管道段
{conduit(){}conduit(string pipename,int pipepid,int pipefd):_pipename(pipename),_pipepid(pipepid),_pipefd(pipefd){}//1.管道名string _pipename;//2.管道的pidint _pipepid;//3.写端的文件描述符(写端)int _pipefd;
};
const int PIPENUM = 10;
//所创建的管道(进程池)
vector<conduit> pipe_array;
void Init()
{for(int i = 0; i < PIPENUM; i++){//先创建管道int pipefd[2];int pipe_ret = pipe(pipefd);if(pipe_ret == -1){perror("pipe");exit(errno);}//创建子进程int pid = fork();if(pid == 0){//此处我们在后面还会补上一段代码。//...//子进程关闭写端close(pipefd[1]);//管道进行重定向,重定向到键盘,减少传参。dup2(pipefd[0],0);//子进程从管道读信息Read();//之后会给出接口。//退出子进程exit(1);}if(pid == -1){//进程创建失败,没有创建子进程perror("fork");exit(errno);}//父进程关闭读端close(pipefd[0]);//将创建的子进程放进vector中string pipe_name = "process_" + to_string(i); pipe_array.push_back({pipe_name,pid,pipefd[1]});}
}
图解:

- 可见我们在不断创建过程中,子进程读端的文件描述符始终都没发生改变,具体的原因,图解已经很清楚了。
- 此处还有一个小bug,不过不影响我们的后续操作,最后我们在清理进程时再进行详细说明。
- 上述代码我们使用C++创建了一个管道类,并且使用vector容器进行管理,本质上,体现了先描述,再组织的思想。
- 对进程实现控制,也就是对子进程发送消息,通过发送的消息控制进程。
首先我们先设计一下,看看通过父进程让子进程完成什么任务,此处简单设计了一个LoL的资源更新的接口。
#include<functional>
#include<map>
#include<iostream>
using namespace std;
void Menu()
{//打印功能cout << "+-----------------------------------+" << endl;cout << "|-----1.刷新野区--------2.刷新兵线---|" << endl;cout << "|-----3.初始化防御塔-----4.退出------|" << endl;cout << "+-----------------------------------+" << endl;
}
void Exit()
{exit(0);
}
void ClearWlidArea()
{cout << "野区已被刷新" << endl;
}
void ClearSolidLine()
{cout << "兵线已被刷新" << endl;
}
void InitDefenseTower()
{cout << "防御塔初始化" << endl;
}
//对功能进行包装。
map<int,function<void()>> Hash = {{1,ClearWlidArea},{2,ClearSolidLine},{3,InitDefenseTower}
};
//... 更多功能敬请期待!
- 说明: 此处使用了C++的包装器,对函数返回值与参数相同的函数进行了封装,且使用了map对函数进行编号,方便进行调用。
然后给出父进程写的接口与子进程读的接口。
void Write(vector<conduit>& pipe_array)
{while(true){Menu();cout << "请选择:";int cmd;cin >> cmd;if(cmd == 4) return;int pipe = rand() % pipe_array.size(); int w_ret = write(pipe_array[pipe]._pipefd,&cmd,sizeof(cmd));if(w_ret == -1){perror("write");exit(errno);}cout << "I am father, I write " << cmd << " to "\<< pipe_array[pipe]._pipename << " It Pid is" \<< pipe_array[pipe]._pipepid << endl;sleep(1);}
}void Read()
{while(true){int cmd;int r_ret = read(0,&cmd,sizeof(cmd));if(r_ret == sizeof(cmd)){cout << "I am child, my pid is:" << getpid() << \", which cmd I read is " << cmd << endl;if(cmd >= 1 && cmd < 4)Hash[cmd]();//执行任务}else if(r_ret == 0)break;sleep(1);}
}
- 父进程输入任务编号,向子进程发送任务,让子进程进行执行。
- 子进程收到任务编号,调用任务编号对应的函数。
- 我们这里是随机派发给一个进程,当然也可以进行轮转派发给指定进程。
- 回收释放子进程的资源。
void DeletePipeArray(const vector<conduit>& pipe_array)
{for(int i = 0; i < pipe_array.size(); i++){//将子进程的写端进行关闭close(pipe_array[i]._pipefd);}for(int i = 0; i < pipe_array.size(); i++){//等待子进程,阻塞等待waitpid(pipe_array[i]._pipepid,NULL,0);}
}
这里我们再处理上面留下的一个小bug:
- 这里我们画图可以看出,创建两个进程之后,一个子进程的读端虽然只有一个,但是在创建两个子进程之后,第二个创建的子进程会从父进程那里继承第一个子进程的写端,从而可以向第一个子进程里面进行写入。
- 这样创建进程是不好的,因为管道是单向通信的,多个写端可能会导致数据错乱。

- 再来看上述删除的代码,由于这里我们是一下子将所有进程的写端关闭,因此不会发生错误。
- 继续分析为什么不会发生错误,因此一旦父进程的写端关闭,第二个子进程就会读到0个字节,然后退出,第二子进程的写端就会关闭,因此第一个子进程的所有写端就关闭了,因此第一个子进程读到0个字节,然后就会退出。是一连串的反应。
- 那我们如何修改代码,一次循环就可以删除呢?
答案很简单——倒着关即可。
void DeletePipeArray(const vector<conduit>& pipe_array)
{for(int i = pipe_array.size() - 1; i >= 0; i--){close(pipe_array[i]._pipefd);waitpid(pipe_array[i]._pipepid,NULL,0);}
}
其次如果我们只要一个读写端,还需要对子进程的所有的管道写端进行关闭。
因此需要在Init的接口的子进程创建后添加:
for(int i = 0; i < pipe_array.size(); i++)
{close(pipe_array[i]._pipefd);
}
加上这个补丁之后,我们再来看管道的清理,不管正着删还是倒着删,其实都只需一次循环。
- 拓展——日志
趁热打铁,我们回过头看一看日志的图解,顺便实现一个简单的日志类。

#include<map>
#include<iostream>
#include<cstdio>
#include<stdarg.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<time.h>
using namespace std;
#define SIZE (4096)#define EMRGE 1
#define ALERK 2
#define CRIT 3
#define ERRO 4
#define WARNNING 5
#define NOTICE 6
#define INFORE 7
#define DEBUG 8
#define NONE 9#define DEFAULTFILE 1
#define CLASSFILE 2
#define SCREAN 0
//说明:一般我们在传参时一般都是以宏的方式进行传参的,如果需要打印出字符串可以用KV类型进行映射转换。
map<int,string> Mode = {{1,"EMERG"},{2,"ALERK"},{3,"CRIT"},{4,"ERRO"},{5,"WARNING"},{6,"NOTICE"},{7,"INFOR"},{8,"DEBUG"},{9,"NONE"}
};//分类文件处理的后缀。
map<int,string> file = {{1,"emerg"},{2,"alerk"},{3,"crit"},{4,"erro"},{5,"warning"},{6,"notice"},{7,"infor"},{8,"debug"},{9,"none"}
};
class log
{
public:void operator()(int level,int where,const char* format,...){//将输入的字符串信息进行输出。va_list arg;va_start(arg,format);char buf[SIZE];vsnprintf(buf,SIZE,format,arg);va_end(arg);//获取时间time_t date = time(NULL);struct tm* t = localtime((const time_t *)&date);char cur_time[SIZE] = {0};snprintf(cur_time,SIZE,"[%d-%d-%d %d:%d:%d]",t->tm_year + 1900,t->tm_mon + 1,、t->tm_mday,t->tm_hour,t->tm_min,t->tm_sec);//输入再进行合并string Log = "[" + Mode[level] + "]" + cur_time + string(buf) + "\n";//处理输出方向PrintClassFile(level,where,Log);}void PrintDefaultFILE(string& file_name,const string& mes){int fd = open(file_name.c_str(),O_CREAT | O_WRONLY | O_APPEND,0666);write(fd,mes.c_str(),mes.size());close(fd);}//将文件进行分类进行输出。void PrintClassFile(int level,int where,const string& mes){if(where == SCREAN)cout << mes;else{string file_name = "./log.txt";if(where == CLASSFILE)file_name += ("." + file[level]);PrintDefaultFILE(file_name,mes);}}
};
1.2命名管道
- 顾名思义,就是有名字的管道。既然有名字,那就可以实现不同进程的之间的通信了。
- 上面提及过找到文件有两种方法,一种是inode;一种是路径+文件名(同一路径下不可能存在相同的文件名)。用户常用的就是第二种。
如何实现呢?涉及一条命令。一条系统调用接口。
- 命令:
mkfifo 【管道名】
- 系统调用接口
头文件:
#include<sys/type.h>
#include<sys/stat.h>
函数声明:
int mkfifo(const char* pathname,mode_t mode);
函数参数:
1. pathname:要创建的所在路径 + 管道名。
2. mode:权限。
函数返回值:
1.创建管道成功,返回0.
2.创建管道失败,返回-1并设置合适的错误码。
- 使用——简易实现一个本地聊天程序。
- 聊天的基本原理:
- 我们在QQ里面的聊天窗口的有两种基本信息。
- 第一种是输入窗口。
- 第二种是输出窗口。
- 这是每个用户都拥有的基本窗口,通过输入窗口进行传递信息,通过输出窗口进行发送信息。不同用户之间通过网络进行数据传输,使数据显示在输出窗口中。
- 这里由于网络还没学,无法进行在网络端的数据传输,因此这里我们的实现的基本原理是这样的:
- 大体逻辑: 输入端进行向共享信息区输入数据,通过共享区进行数据的交互。

首先我们建立两个管道,即两个输入端分别连到一个管道的写端,共享信息区与两个管道的读端。
实现代码:
为了便于理解,先将头文件进行给出:
- pipe.h
#pragma once
#include<iostream>
#include<cstdlib>
#include<string>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
using namespace std;
const string server_name = "shun_hua";
const string client_name = "舜华";
const string server_pipe = "server_pipe";
const string client_pipe = "client_pipe";#define SIZE (4096)
//实现管道管理//此处我们实现一个简单的窗口聊天菜单
void menu(const string& username)
{//获取时间time_t date = time(NULL);struct tm* t = localtime((const time_t *)&date);char cur_time[SIZE] = {0};snprintf(cur_time,SIZE,"[%d:%d:%d]",t->tm_hour,t->tm_min\,t->tm_sec);cout << cur_time << username << ":";
}- 服务端写端(serverw.cc)
#include"pipe.h"
int main()
{ //创建管道文件mkfifo(server_pipe.c_str(),0666);mkfifo(client_pipe.c_str(),0666);//打开写端。int fd = open(server_pipe.c_str(),O_WRONLY);if(fd == -1){perror("open server_pipe");exit(1);}//打开成功while(true){menu(server_name);//输入你想说的话:string str;getline(cin,str);write(fd,str.c_str(),str.size());}return 0;
}
- 客户端写端(clientw.cc)
#include"pipe.h"
int main()
{ //创建管道文件//打开服务端管道的写端。int fd = open(client_pipe.c_str(),O_WRONLY);if(fd == -1){perror("open client_pipe");exit(1);}//打开成功while(true){menu(client_name);//输入你想说的话:string str;getline(cin,str);write(fd,str.c_str(),str.size());} return 0;
}
- 服务端的读端(serverr.cc)
#include"pipe.h"
int main()
{ //一个打开读端,一个打开写端。int fd = open(server_pipe.c_str(),O_RDONLY);if(fd == -1){perror("open server_pipe");exit(1);}//打开成功while(true){char buf[SIZE];int sz = read(fd,buf,SIZE);buf[sz] = '\0';if(sz == 0) break;//从client读到的话menu(client_name);cout << buf << endl;}return 0;
}
- 客户端读端(clientr.cc)
#include"pipe.h"
int main()
{ //一个打开读端,一个打开写端。int fd = open(client_pipe.c_str(),O_RDONLY);if(fd == -1){perror("open server_pipe");exit(1);}while(true){char buf[SIZE];int sz = read(fd,buf,SIZE);if(sz == 0) break;buf[sz] = '\0';//从client读到的话menu(client_name);cout << buf << endl;}return 0;
}
- 此时代码写好之后我们将之编译成可执行程序。

-
然后我们开三个窗口,根据上面的图,进行运行程序。
-
简单的聊天效果。

我们实现的还是较为粗糙的代码,有兴趣的小伙伴可以进行丰富与补充。
- 除此之外,在读端未打开,写端会陷入阻塞状态,这是正常现象。与此同理写端未打开,读端打开,读端也会陷入阻塞状态。
- 拓展
- 推论:由于管道在内存中并不会刷新到磁盘,因此我们可以推断管道文件的大小为0。
- 验证:
- piper.cc
#include<iostream>
#include<fcntl.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<unistd.h>
using namespace std;
char buf[4096];
int main()
{int rfd = open("pipe",O_RDONLY);cout << "open success" << endl;sleep(10);read(rfd,buf,sizeof(buf));cout << buf;return 0;
}
- pipew.cc
#include<iostream>
#include<fcntl.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<unistd.h>
using namespace std;
int main()
{mkfifo("pipe",0666);int wfd = open("pipe",O_WRONLY);cout << "open true" << endl;int cnt = 10;while(cnt--){string str = "hello world\n";write(wfd,str.c_str(),str.size());cout << "writing " << cnt << endl; sleep(1);}return 0;
}
- 实验现象:

2.共享内存
2.1原理
- 简要说明: 此共享内存是System V 标准中的。
- 大前提:进程间要进行通信,必须要看到同一份资源。
共享内存如何让进程看到同一份资源呢?我们画图进行解释:

我们对这张图进行深入分析:
- 共享内存是内存,若要开辟,应交由操作系统进行开辟,进程若要开辟,必然要使用操作系统提供的系统调用接口。
- 共享内存是映射在进程地址空间内的,且位于进程地址空间的共享区。
- 既然在进程地址空间内,我们可以通过进程地址空间直接的对共享内存进行访问。
- 不同的进程通过与共享内存建立链接,可看到同一份资源,从而实现通信。
- 该共享内存是操作系统管理的,且不只有一个共享内存,因此共享内存也需要先描述,再组织起来。且由于是操作系统进行管理的第三方资源,因此不会发生类似写时拷贝的现象。
- 补充:我们之前的动态链接,其实也是看到了同一份资源,但这份资源无法进行修改,因此无法进行通信。
2.2接口使用
- 共享内存的创建
* 接口1
头文件:
#include<sys/ipc.h>
#include<sys/shem.h>
函数声明:
int shmget((key_t key, size_t size, int shmflg);
函数参数:
1. 共享内存的内核标识符。
2. 共享内存的开辟的字节数。
3. 共享内存的创建方式。其中包括:1. IPC_CREAT:没有创建,有则返回。2. IPC_EXIT: 有则出错返回。若要使用也得跟上方式1
返回值:
4. 如果成功,返回共享内存的用户标识符。
5. 如果失败,返回-1,并设置合适的错误码。*接口2
头文件:
#include<sys/ipc.h>
#include<sys/shm.h>
函数声明:
key_t ftok(const char *pathname, int proj_id);
函数参数:
1. 生成路径,是生成key_t类型内核共享内存表示符(这只是我这样叫的)的key.
2. 生成码,生成key_t类型的内核共享内存标识符的key,不能是0.说明:这两个参数都是为了生成key_t类型的内核的标识符。返回值:
1. 成功,返回key_t类型的内核共享内存标识符。
2. 失败,返回-1
- 其实光看这两个接口是有点懵逼的,我们把这两个接口联系起来。
- 首先操作系统,得知道key才能生成与key对应的共享内存。
- 系统无法自动生成,因为多个进程还要靠key找到同一份共享内存。如若生成,进程之间无法知道同一个key。
- key生成需要依赖于生成路径与生成码,即pathname与proj_id
- pathname 与proj_id相同生成的key也就相同,因此多个进程 可通过相同的pathname与proj_id得到同一份key,因此可找到 同一份共享内存。从而看到同一份资源,进而实现通信。
- 补充:至于shemget的返回值是为了让用户方便接下来的操作,且对内核的数据做了封装更加的安全。

接下来我们简单的使用一下接口。
- shm.h
#include<iostream>
#include<string>#include<sys/ipc.h>
#include<sys/shm.h>using std::string;const string pathname = "/home/shun_hua";
const int proj_id = 0xFFFF;
- shm.cc
#include"shm.h"using namespace std;
int main()
{key_t key = ftok(pathname.c_str(),proj_id);if(key == -1) return;int ud = shmget(key,4096,IPC_CREAT);if(ud == -1) return;cout << "创建成功!" << endl;return 0;
}
- 编译运行一下:

- 此时由于共享内存是由操作系统进行管理的,因此在没有调用对应的系统调用接口时,进程退出时不会进行释放共享内存。
如何验证呢?涉及一条命令:
ipcs -m

既然这样,那如何删除呢?又涉及一条命令。
ipcrm -m 【shmid】

- 我们发现这里的权限也就是perms我们并没有进行设置,因此我们还得设置一下,如何设置呢?其实获取共享内存时,我们在第三个参数 | 上权限即可。
int ud = shmget(key,4096,IPC_CREAT | 0666);

- 共享内存的链接与取消
*产生链接
头文件:
#include<sys/shm.h>
函数声明:
void *shmat(int shmid, const void *shmaddr, int shmflg);
函数参数:
1. 用户共享内存标识符。
2. 指定的进程的共享区地址,若被占用失败,返回-1,为空,系统自动分配地址。
3. 进程映射共享内存的方式。这里只介绍SHM_RDONLY,以只读方式映射共享内存区域。一般设为0。返回值:
1. 成功,返回共享内存的进程空间的地址。
2. 失败,返回-1,并设置合适的错误码。*取消链接
头文件:
#include<sys/shm.h>
函数声明:
int shmdt(const void *shmaddr);
函数参数:
*共享内存的地址
返回值
1.成功返回0
2.失败返回-1,并设置合适的错误码。
简单使用:
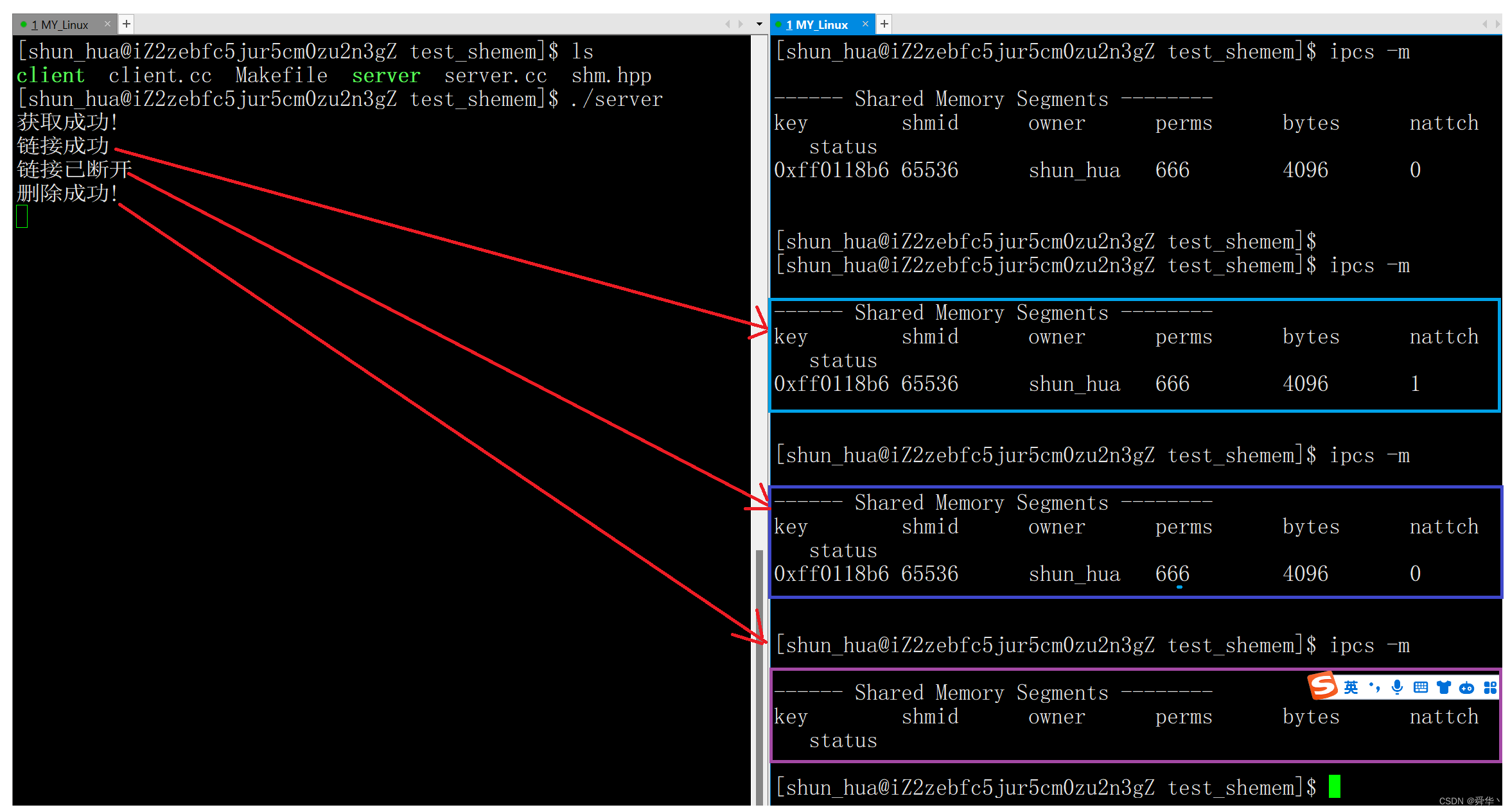
#include"shm.hpp"
int main()
{key_t key = ftok(pathname.c_str(),proj_id);if(key == -1) return -1;int shmid = shmget(key,4096,IPC_CREAT | 0666);if(shmid == -1) return -1;cout << "获取成功!" << endl;//产生链接char* shmptr = (char*)shmat(shmid ,nullptr,0);if(shmptr != -1) cout << "链接成功"<< endl; sleep(5);//断开链接int ret = shmdt(shmptr);if(ret == 0) cout << "链接已断开" << endl;sleep(5);return 0;
}

- 删除共享内存
头文件:
#include<sys/ipc.h>
#include<sys/shm.h>
函数声明:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
函数参数:
1.用户共享内存标识符。
2.选项,常见的有:1.IPC_STAT,获取共享内存的状态信息,放在buf指向的变量中。2.IPC_SET,设置共享内存的状态,需要将buf变量传进去,方便修改3.IPC_RMID,删除共享内存。4.SHM_LOCK,锁定共享内存。5.SHM_UNLOCK,解锁共享内存。
3.输入或者输出型参数,用于存放共享内存的信息。返回值:
1.成功,返回0.
2.失败返回-1.并设置合适的错误码。
- 简单使用:
#include"shm.hpp"
int main()
{key_t key = ftok(pathname.c_str(),proj_id);if(key == -1) return -1;int shmid = shmget(key,4096,IPC_CREAT | 0666);if(shmid == -1) return -1;cout << "获取成功!" << endl;//产生链接char* shmptr = (char*)shmat(shmid,NULL,0);if(shmptr != (void*)(-1)) cout << "链接成功"<< endl; sleep(5);//断开链接int ret = shmdt(shmptr);if(ret == 0) cout << "链接已断开" << endl;sleep(5);//上面这一坨代码,我们已经循序渐进讲过了。//下面是核心代码.//将共享内存进行删除。ret = shmctl(shmid,IPC_RMID,NULL);if(ret == -1) cout << "删除失败" << endl;cout << "删除成功!"<< endl;sleep(5);return 0;
}
- 实验结果:
- 补充:由于多个进程的共享内存的虚拟地址映射到到同一物理内存,这样数据读取时,与写入时直接输入输出,由于管道是将准备好的数据,拷贝到管道,需要各自准备好一块空间,因此共享内存的通信方式,比管道的方式少拷贝两次,因此比较高效。
3.消息队列
原理
顾名思义,消息队列就是能看到消息的队列,不同进程之间必须看到这个队列,那是如何做到的呢?同理我们先画一张图,进行辅助理解:

- 其次我们再来根据这张图进行深入。
- 内核区,也就是由操作系统进行管理的区域,且操作系统是进程的管理者,进程又代表着用户,因此我们这里的进程分成了两部分,一部分是暴露给用户进行操作的,一部分是给操作系统进行管理的。
- 进程1与进程2通过与操作系统产生链接,并分发数据,因此在内核区,必然要由操作系统进行操作,那也就意味着操作系统要提供系统调用接口给进程。
- 进程2与进程1都给消息队列分发数据,那如何区分数据是谁的呢?必然存在数据的标识符,使进程1获取进程2的数据,进程2获取进程1的数据。
再来谈接口(具体细节我们等到后面再讲):
头文件:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
函数声明:
key_t ftok(const char *pathname, int proj_id);
*此函数共享内存的创建处已经提及到过。int msgget(key_t key, int msgflg);
*此函数用于消息队列的创建。 int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
*此函数用于消息的发送。ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,\
int msgflg);
*此函数用于消息的获取。int msgctl(int msqid, int cmd, struct msqid_ds *buf);
*此函数用于消息队列信息的获取与删除。
通过此类接口,我们不难发现此类接口与共享内存的接口高度类似,这是为什么呢?
- 其实很简单,消息队列用的也是是System V标准的。
既然这样,那操作系统是如何统一的进行管理的呢?我们通过两个结构体进行分析:
共享内存:struct shmid_ds
消息队列:struct msqid_ds
通过查看这两个结构体的声明看是否有相同之处,下面以图解的方式进行呈现:

- 可以观察到两个结构体声明中都有 struct ipc_perm这一个结构体,操作系统便可以通过指针数组对这个结构体进行管理。
- 其次对地址进行管理,变相的就对struct ipc_perm所在的结构体进行了管理,因为这个struct ipc_perm位于这两个结构体的开头,因此可以通过强转的方式,对指向所在结构体的信息获取和管理。这种思想对应是C++的多态。
- 指针数组通过下标的形式进行管理,且下标的趋势大体随着开辟的数量的增多而增大,跟文件描述符类似。
4.信号量
引入
在共享内存的讲解中,我们可以直接在进程中直接访问共享内存,但是若有多个进程同时进行访问那就可能会出现这样的问题:
- 数据错乱无章,数据可能会紊乱。
假如有两个进程,一个进程一边从进程读数据,一个进程一边从进程写数据,两者同时发生,那就可能会导致一个进程没写完的数据被另一个进程读走了,从而导致读到的数据并不完整,这样的问题我们叫做数据不一致问题。
- 说明:管道是具有原子性的,因此不会出现这样的问题。
此时我们需要对资源进行加锁,也就是一个进程访问时,另一个进程不能进行访问。这种现象我们称之为互斥。
而有的资源,只能一次被一个进程进行占用,比如说显示器,键盘等,像这种资源我们称之为临界资源。
若我们将临界资源的访问,限制在一段代码里面,也就是通过代码限制临界资源的访问,这样的代码我们称之为临界区。
原理
- 首先给出一个概念:
信号量的本质就是一个计数器
- 前面我们已经讲过,像有些资源只能一次被一个进程访问占用。
- 如果我们在资源空闲时设置标记为1,在资源被进程占用时,设置标记为0。
- 这样如果标记为0,则表示资源已经被占用,别的进程无法进行使用;标记为1,则资源没有被占用,其它进程可以被占用。
- 如此一来,只有当进程在共享资源中,把事情干完,才会退出。其它进程才能接着使用共享资源的现象,我们称之为原子性。
这里标记我们就可以看做计数器,像这种只有0,1两种状态的我们称之为二元信号量。
- 在现实生活中,像一些去ATM机里面取钱,为了防止其它人,干扰这个过程,一般进去之后我们会自动上锁,还有一些比如上厕所,为了不让在蹲坑的时候,被其它人看见,通常都会把门锁上……诸如此类的现象都体现出了信号量的概念。
还有一些可以多执行流进行访问的资源,那信号量可能就不只是0,1两种状态,可能是[0,n]种状态。
- 比如我们去看一场电影,放映厅里面的座位是固定的,要想看电影,就得买电影票预定座位,即获取座位的在一定时间内的使用权,且座位的数量是固定的,这就意为电影票的数量最多与座位的数量一致。不可能出现票的数量大于座位的数量的情况。
回归到信号量:
- 首先,假设有这样的共享资源,这个资源分为40份,供进程进行使用。
- 信号量初始值为40。
- 当共享资源被访问时,信号量就减减,最多被减到0。
- 当减到0时,其它资源不能被继续访问。
- 同时,联想到电影票,当我们买票成功后,就代表我们可以直接使用座位了么。答案很显然不是,因为我们买到票只是预定了座位的使用权,同理我们进程访问使信号量减减,也并不代表我们就会立马访问资源。因此进程获取的只是对资源的预定。
- 再想到电影院包场,其实就是将电影院看成一个整天进行使用。不就是信号量为1的共享资源吗?
- 拓展
- 既然要申请共享资源,必须要通过信号量,那也就意为着信号量也是共享资源,那信号量安不安全?
- 我们把信号量看成一个整形变量的减减操作。
- 转换成汇编语言也就是三条左右,把整形变量放到寄存器中,将寄存器的值减1,再将寄存器的值写会到变量当中。
- 那也就意味着,在进程执行过程中,很可能执行到某一句汇编就切换进程了,就要保存进程的上下文进行下次接着运行。
- 在进程在等待队列等待的过程中,很可能被其它进程接着访问,从而修改进程的上下文,导致信号量的减减操作不安全,因此信号量也需要被保护。
总结
- 我们围绕着进程通信的本质,展开了管道,共享内存,消息队列的话题,及其相关细节的讨论。
- 其次我们通过对信号量的理解,深刻的认识到了,进程通信不仅需要传递数据,还需要保持传递的同步与协调。
如果本篇对您有所帮助,不妨点个赞鼓励一下吧!
相关文章:
【Linux进阶之路】进程间通信
文章目录 一、原理二、方式1.管道1.1匿名管道1.1.1通信原理1.1.2接口使用 1.2命名管道 2.共享内存2.1原理2.2接口使用 3.消息队列原理 4.信号量引入原理 总结 一、原理 进程间的通信是什么?解释: 简单理解就是,不同进程之间进行数据的输入输出…...
深度学习框架配置
目录 1. 配置cuda环境 1.1. 安装cuda和cudnn 1.1.1. 显卡驱动配置 1.1.2. 下载安装cuda 1.1.3. 下载cudnn,将解压后文件复制到cuda目录下 1.2. 验证是否安装成功 2. 配置conda环境 2.1. 安装anaconda 2.2. conda换源 2.3. 创建conda环境 2.4. pip换源 3.…...

全局配置
1.全局配置文件及其配置项 1.1.小程序窗口 1.2 窗口节点 1.2.1 导航栏标题 标题: 标题颜色: 背景色:只支持16进制值 下拉刷新: 刷新背景色: 刷新样式: 触底距离:...

leetcode算法之字符串
目录 1.最长公共前缀2.最长回文子串3.二进制求和4.字符串相乘 1.最长公共前缀 最长公共前缀 class Solution { public:string longestCommonPrefix(vector<string>& strs) {//法一:两两比较string ret strs[0];for(int i1;i<strs.size();i){ret f…...

mongodb查询数据库集合的基础命令
基础命令 启动mongo服务 mongod -f /usr/local/mongodb/mongod.conf //注意配置文件路径停止mongo服务 关闭mongodb有三种方式: 一种是进入mongo后通过mongo的函数关闭; use admin db.shutdownServer()一种是通过mongod关闭; mongod --s…...
基于FactoryBean、实例工厂、静态工厂创建Spring中的复杂对象
😉😉 学习交流群: ✅✅1:这是孙哥suns给大家的福利! ✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料 🥭🥭3:QQ群:583783…...
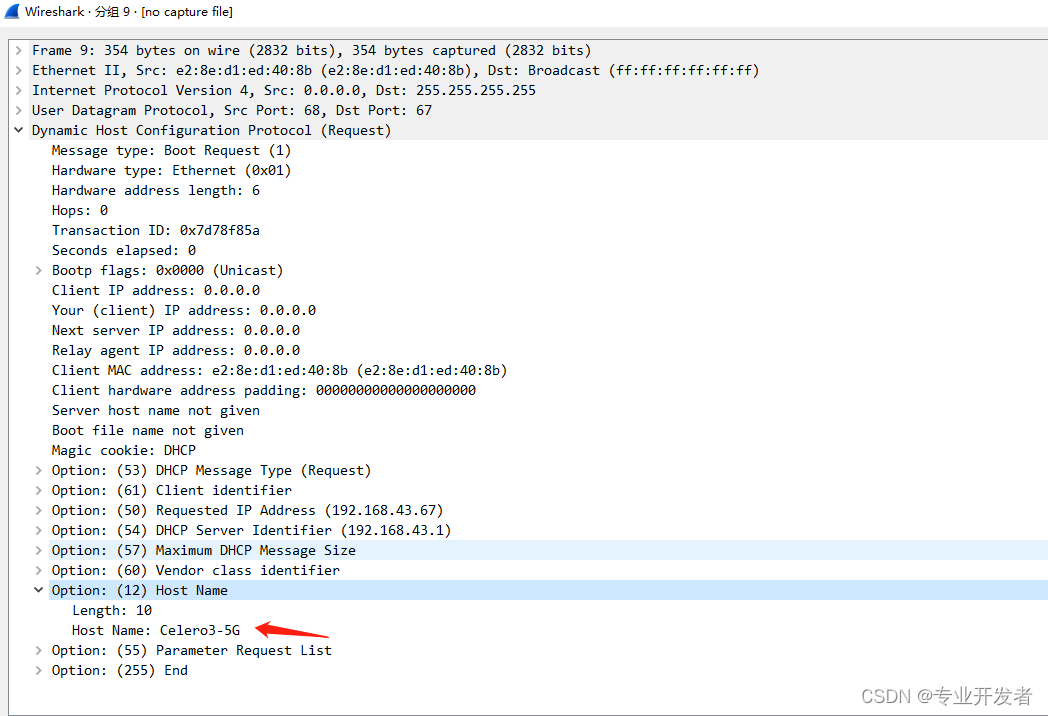
Android 如何让路由器或者其他AP设备获取到主机名
问题原因: 连接到AP设备后,发现主机名在路由器或者其他AP设备都无法正常显示 抓取tcpdump log发现DHCP request option中没有携带host name(Option 12)字段 如下图所示 修改方法: 将config_dhcp_client_hostname配置true后,可以看到host name了 具体代码逻辑如下 pack…...
java三大集合类--List
List Set Map 一、List 几个小问题: 1、接口可以被继承吗?(可以) 2、接口可以被多个类实现吗?(可以) 3、以下两种写法有什么区别? //List list1new List();是错误的因为List()…...

机器人向前冲
欢迎来到程序小院 机器人向前冲 玩法:一直走动的机器人,点击鼠标左键进行跳跃,跳过不同的匝道,掉下去即为游戏接续, 碰到匝道铁钉游戏结束,一直往前冲吧^^。开始游戏https://www.ormcc.com/play/gameStart…...

jq——实现弹幕滚动(往左滚动+往右滚动)——基础积累
最近同事在写弹幕功能,下面记录以下代码: 1.html代码 <div id"scrollContainer"></div>2.引入jq <script src"./script/jquery-1.8.3.js" type"text/javascript"></script>3.jq代码——往左滚…...
深度学习第2天:RNN循环神经网络
☁️主页 Nowl 🔥专栏《机器学习实战》 《机器学习》 📑君子坐而论道,少年起而行之 文章目录 介绍 记忆功能对比展现 任务描述 导入库 处理数据 前馈神经网络 循环神经网络 编译与训练模型 模型预测 可能的问题 梯度消失 梯…...

深度学习之基于百度飞桨PaddleOCR图像字符检测识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介主要特点使用步骤 二、功能三、系统四. 总结 一项目简介 # Introduction to PaddleOCR Image Character Detection and Recognition System Based on Baidu…...

九、LuaTable(表)
文章目录 一、定义二、Table(表)的构造三、Table 操作(一)Table连接(二)插入和移除(三)Table 排序(四)Table 最大值 一、定义 table 是 Lua 的一种数据结构用来帮助我们创建不同的数…...
每日一题(LeetCode)----链表--链表最大孪生和
每日一题(LeetCode)----链表–链表最大孪生和 1.题目(2130. 链表最大孪生和) 在一个大小为 n 且 n 为 偶数 的链表中,对于 0 < i < (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n…...
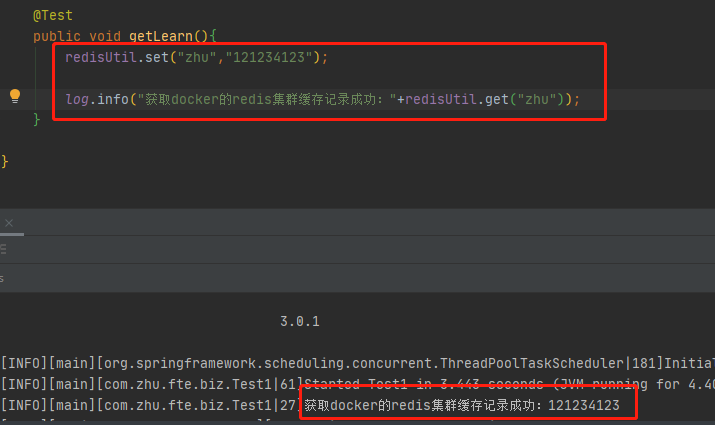
腾讯云轻量服务器通过Docker搭建外网可访问连接的redis5.x集群
原创/朱季谦 最近买了一台4核16的腾讯云轻量应用服务器,花了我快四百的大洋,打算搭建一堆docker组件集群,最先开始是通过docker搭建redis集群,计划使用三个端口,分别是7001,7002,7003。 腾讯云服务器有防火墙限制,故…...
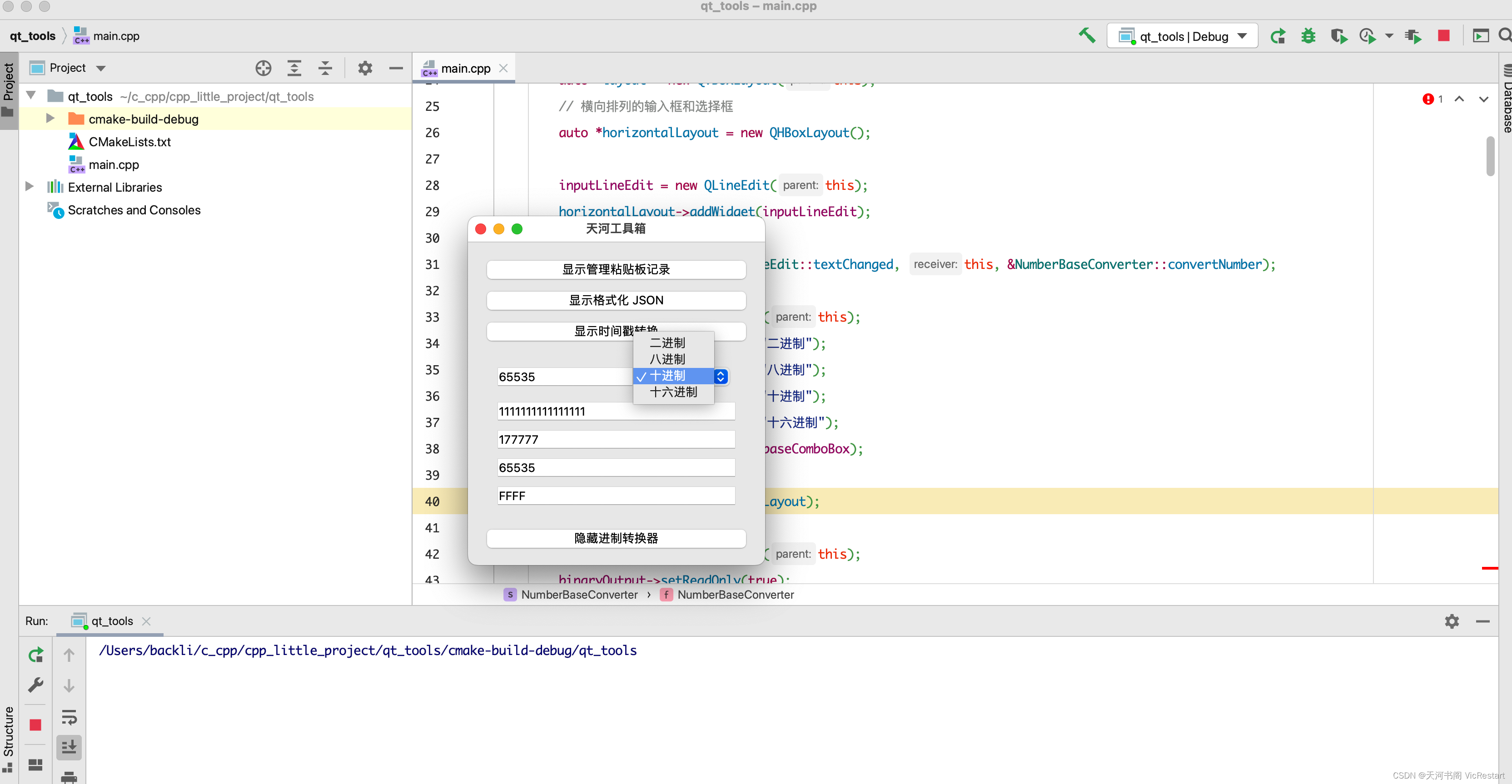
C++学习之路(十一)C++ 用Qt5实现一个工具箱(增加一个进制转换器功能)- 示例代码拆分讲解
上篇文章,我们用 Qt5 实现了在小工具箱中添加了《时间戳转换功能》功能。为了继续丰富我们的工具箱,今天我们就再增加一个平时经常用到的功能吧,就是「 进制转换 」功能。下面我们就来看看如何来规划开发一个这样的小功能并且添加到我们的工具…...
栈实现队列)
C语言每日一题(40)栈实现队列
力扣232 用栈实现队列 题目描述 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾int pop() 从队列的开头移除并…...

Vue.js 的生命周期
Vue.js 的生命周期钩子函数是一组在 Vue 实例生命周期中执行的函数,它们允许你在特定阶段执行自定义逻辑。以下是 Vue.js 的生命周期钩子函数以及它们在生命周期中的执行时机: 1、beforeCreate: 在实例初始化之后,数据观测 (data observer)…...

SeaTunnel引擎下的SQL Server CDC解决方案:构建高效数据管道
在快速发展的数据驱动时代,实时数据处理已经成为企业决策和运营的关键因素。特别是在处理来自各种数据源的信息时,如何确保数据的及时、准确和高效同步变得尤为重要。本文着重介绍了如何利用 SqlServer CDC 源连接器在 SeaTunnel 框架下实现 SQL Server …...
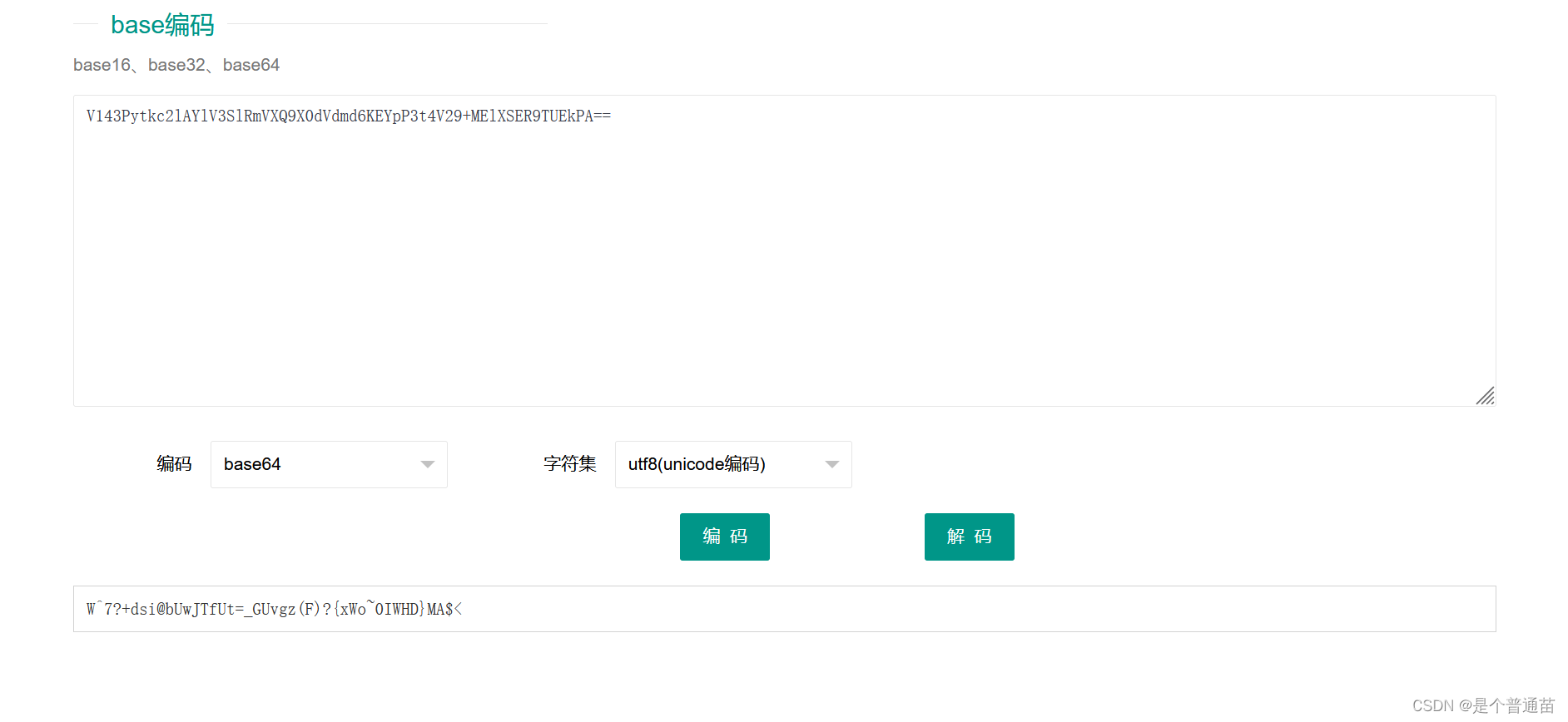
【攻防世界-misc】Encode
1.下载解压文件,打开这个内容有些疑似ROT13加密,利用在线工具解密:ROT13解码计算器 - 计算专家 得到了解密后的值 得到解码结果后,看到是由数字和字母组成,再根据题目描述为套娃,猜测为base编码(…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...