SeaTunnel引擎下的SQL Server CDC解决方案:构建高效数据管道

在快速发展的数据驱动时代,实时数据处理已经成为企业决策和运营的关键因素。特别是在处理来自各种数据源的信息时,如何确保数据的及时、准确和高效同步变得尤为重要。本文着重介绍了如何利用 SqlServer CDC 源连接器在 SeaTunnel 框架下实现 SQL Server 到其他数据系统的实时数据同步,这对于希望提升数据处理能力和实时数据分析的企业来说,具有重要的实践意义。
SQL Server CDC
SqlServer CDC 源连接器
支持 SQL Server 版本
- 服务器:2019(或更高版本,仅供参考)
支持引擎
SeaTunnel Zeta
Flink
主要特性
- 批处理
- 流处理
- 精确一次
- 列投影
- 并行处理
- 支持用户自定义分片
描述
SqlServer CDC 连接器允许从 SqlServer 数据库读取快照数据和增量数据。本文档描述了如何设置 SqlServer CDC 连接器以在 SqlServer 数据库上运行 SQL 查询。
支持的数据源信息
| 数据源 | 支持的版本 | 驱动 | URL | Maven |
|---|---|---|---|---|
| SqlServer |
| com.microsoft.sqlserver.jdbc.SQLServerDriver | jdbc:sqlserver://localhost:1433;databaseName=column_type_test | 下载 |
安装 Jdbc 驱动
请下载并将 SqlServer 驱动放在 ${SEATUNNEL_HOME}/lib/ 目录下。例如:cp mssql-jdbc-xxx.jar ${SEATUNNEL_HOME}/lib/
数据类型映射
| SQL Server 数据类型 | SeaTunnel 数据类型 |
|---|---|
| CHAR VARCHAR NCHAR NVARCHAR STRUCT CLOB LONGVARCHAR LONGNVARCHAR | STRING |
| BLOB | BYTES |
| INTEGER | INT |
| SMALLINT TINYINT | SMALLINT |
| BIGINT | BIGINT |
| FLOAT REAL | FLOAT |
| DOUBLE | DOUBLE |
| NUMERIC DECIMAL(column.length(), column.scale().orElse(0)) | DECIMAL(column.length(), column.scale().orElse(0)) |
| TIMESTAMP | TIMESTAMP |
| DATE | DATE |
| TIME | TIME |
| BOOLEAN BIT | BOOLEAN |
源选项
| 名称 | 类型 | 必需 | 默认值 | 描述 |
|---|---|---|---|---|
| username | 字符串 | 是 | - | 连接数据库服务器时使用的用户名。 |
| password | 字符串 | 是 | - | 连接数据库服务器时使用的密码。 |
| database-names | 列表 | 是 | - | 需要监控的数据库名。 |
| table-names | 列表 | 是 | - | 表名为模式名和表名的组合(databaseName.schemaName.tableName)。 |
| base-url | 字符串 | 是 | - | 必须包含数据库的URL,如 "jdbc:sqlserver://localhost:1433;databaseName=test"。 |
| startup.mode | 枚举 | 否 | INITIAL | SqlServer CDC 消费者的可选启动模式,有效枚举为 "initial"、"earliest"、"latest" 和 "specific"。 |
| startup.timestamp | 长整型 | 否 | - | 从指定的纪元时间戳(以毫秒为单位)开始。 注意,当使用 "startup.mode" 选项为 'timestamp' 时,此选项是必需的。 |
| startup.specific-offset.file | 字符串 | 否 | - | 从指定的 binlog 文件名开始。 注意,当 "startup.mode" 选项使用 'specific' 时,此选项是必需的。 |
| startup.specific-offset.pos | 长整型 | 否 | - | 从指定的 binlog 文件位置开始。 注意,当 "startup.mode" 选项使用 'specific' 时,此选项是必需的。 |
| stop.mode | 枚举 | 否 | NEVER | SqlServer CDC 消费者的可选停止模式,有效枚举为 "never"。 |
| stop.timestamp | 长整型 | 否 | - | 从指定的纪元时间戳(以毫秒为单位)停止。 注意,当 "stop.mode" 选项使用 'timestamp' 时,此选项是必需的。 |
| stop.specific-offset.file | 字符串 | 否 | - | 从指定的 binlog 文件名停止。 注意,当 "stop.mode" 选项使用 'specific' 时,此选项是必需的。 |
| stop.specific-offset.pos | 长整型 | 否 | - | 从指定的 binlog 文件位置停止。 注意,当 "stop.mode" 选项使用 'specific' 时,此选项是必需的。 |
| incremental.parallelism | 整型 | 否 | 1 | 增量阶段中并行读取器的数量。 |
| snapshot.split.size | 整型 | 否 | 8096 | 表快照的分割大小(行数),快照期间的表会被分割成多个分片进行读取。 |
| snapshot.fetch.size | 整型 | 否 | 1024 | 读取表快照时每次轮询的最大提取量。 |
| server-time-zone | 字符串 | 否 | UTC | 数据库服务器中的会话时区。 |
| connect.timeout | 时长 | 否 | 30s | 连接器尝试连接到数据库服务器后等待超时的最大时间。 |
| connect.max-retries | 整型 | 否 | 3 | 连接器尝试建立数据库服务器连接的最大重试次数。 |
| connection.pool.size | 整型 | 否 | 20 | 连接池大小。 |
| chunk-key.even-distribution.factor.upper-bound | 双精度浮点型 | 否 | 100 | 分块键分布因子的上界。此因子用于判断表数据是否均匀分布。如果计算出的分布因子小于或等于此上界值(即 (MAX(id) - MIN(id) + 1) / 行数),则表分块将被优化为均匀分布。否则,如果分布因子更大,则表将被认为是不均匀分布的,并且如果估计的分片数超过 sample-sharding.threshold 指定的值,将使用基于抽样的分片策略。默认值为 100.0。 |
| chunk-key.even-distribution.factor.lower-bound | 双精度浮点型 | 否 | 0.05 | 分块键分布因子的下界。此因子用于判断表数据是否均匀分布。如果计算出的分布因子大于或等于此下界值(即 (MAX(id) - MIN(id) + 1) / 行数),则表分块将被优化为均匀分布。否则,如果分布因子更小,则表将被认为是不均匀分布的,并且如果估计的分片数超过 sample-sharding.threshold 指定的值,将使用基于抽样的分片策略。默认值为 0.05。 |
| sample-sharding.threshold | 整型 | 否 | 1000 | 触发抽样分片策略的估计分片数阈值。当分布因子超出 chunk-key.even-distribution.factor.upper-bound 和 chunk-key.even-distribution.factor.lower-bound 指定的范围,并且估计的分片数(计算为近似行数 / 分块大小)超过此阈值时,将使用抽样分片策略。这可以帮助更有效地处理大型数据集。默认值为1000分片。 |
| inverse-sampling.rate | 整型 | 否 | 1000 | 抽样分片策略中使用的抽样率的倒数。例如,如果这个值设置为1000,意味着抽样过程中应用了1/1000的抽样率。这个选项提供了在控制抽样粒度的灵活性,从而影响最终的分片数量。特别是在处理非常大的数据集时,更低的抽样率是首选。默认值为1000。 |
| exactly_once | 布尔型 | 否 | true | 启用精确一次语义。 |
| debezium.* | 配置 | 否 | - | 将Debezium的属性传递给用于从SqlServer服务器捕获数据变化的Debezium嵌入式引擎。 查看Debezium的SqlServer连接器属性获取更多信息 |
| format | 枚举 | 否 | DEFAULT | SqlServer CDC 的可选输出格式,有效枚举为 "DEFAULT"、"COMPATIBLE_DEBEZIUM_JSON"。 |
| common-options | 否 | - | 源插件的通用参数,请参考源通用选项获取详细信息。 |
任务示例
初始读取简单示例
这是一个流模式CDC初始化读取的示例,成功读取表数据后将进行增量读取。以下SQL DDL仅供参考。
env {# 在此处设置引擎配置execution.parallelism = 1job.mode = "STREAMING"execution.checkpoint.interval = 5000
}source {# 仅用于测试和演示功能的示例源插件SqlServer-CDC {result_table_name = "customers"username = "sa"password = "Y.sa123456"startup.mode="initial"database-names = ["column_type_test"]table-names = ["column_type_test.dbo.full_types"]base-url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"}
}transform {
}sink {console {source_table_name = "customers"}
增量读取简单示例
这是一个增量阅读示例,用于阅读变更数据并打印。
env {# 在此处设置引擎配置execution.parallelism = 1job.mode = "STREAMING"execution.checkpoint.interval = 5000
}source {# 仅用于测试和演示功能的示例源插件SqlServer-CDC {# 设置精确一次读取exactly_once=true result_table_name = "customers"username = "sa"password = "Y.sa123456"startup.mode="latest"database-names = ["column_type_test"]table-names = ["column_type_test.dbo.full_types"]base-url = "jdbc:sqlserver://localhost:1433;databaseName=column_type_test"}
}transform {
}sink {console {source_table_name = "customers"}
}随着数据处理需求的不断增长和实时数据同步的重要性日益凸显,SqlServer CDC 源连接器在 SeaTunnel 生态系统中扮演着至关重要的角色。
通过本文的深入解析,我们希望您能够更好地理解并利用这一强大工具,从而实现数据流的高效、稳定和精准同步。
无论您是数据工程师、系统架构师还是业务分析师,掌握如何在 SeaTunnel 中部署和优化 SQL Server CDC 连接器,都将为您的数据处理能力带来显著提升。
本文由 白鲸开源科技 提供发布支持!
相关文章:
SeaTunnel引擎下的SQL Server CDC解决方案:构建高效数据管道
在快速发展的数据驱动时代,实时数据处理已经成为企业决策和运营的关键因素。特别是在处理来自各种数据源的信息时,如何确保数据的及时、准确和高效同步变得尤为重要。本文着重介绍了如何利用 SqlServer CDC 源连接器在 SeaTunnel 框架下实现 SQL Server …...
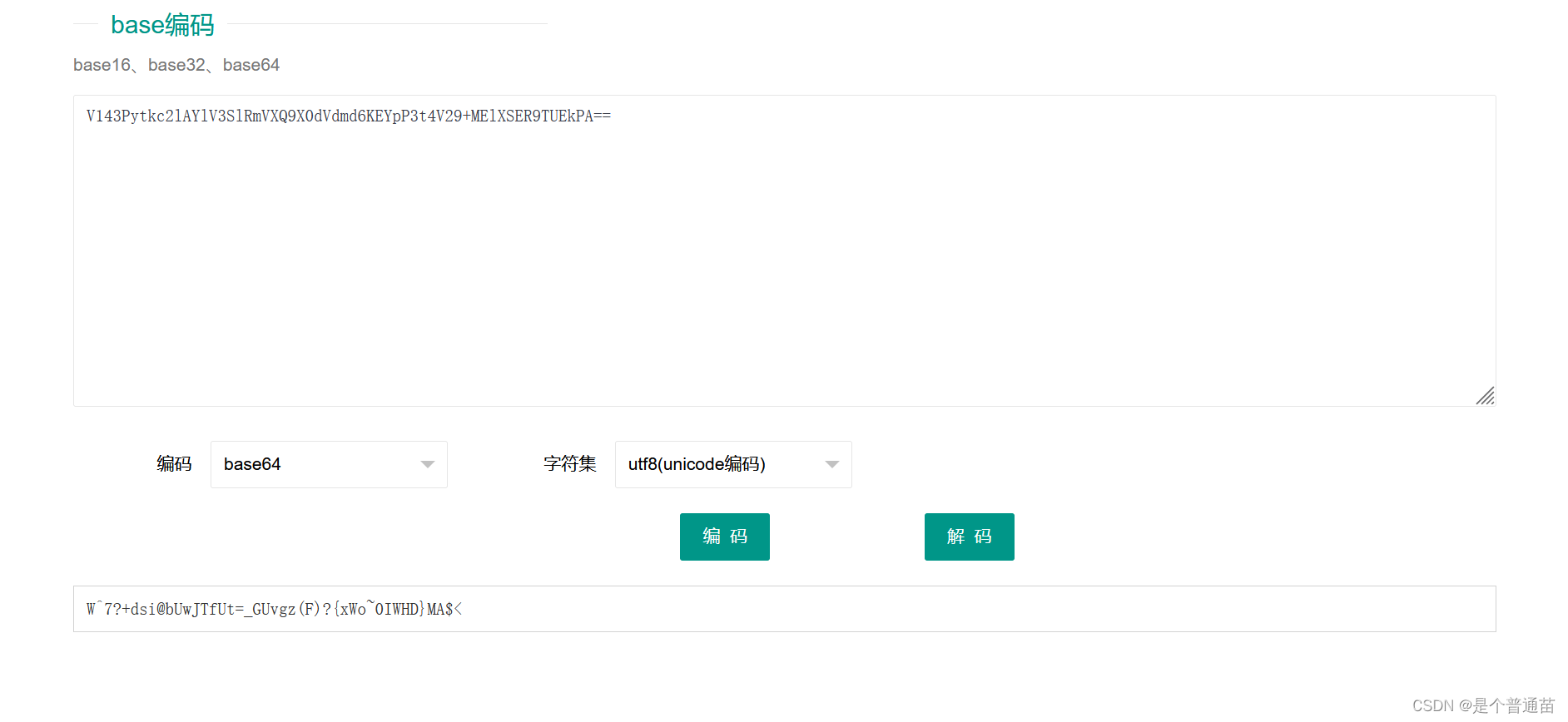
【攻防世界-misc】Encode
1.下载解压文件,打开这个内容有些疑似ROT13加密,利用在线工具解密:ROT13解码计算器 - 计算专家 得到了解密后的值 得到解码结果后,看到是由数字和字母组成,再根据题目描述为套娃,猜测为base编码(…...
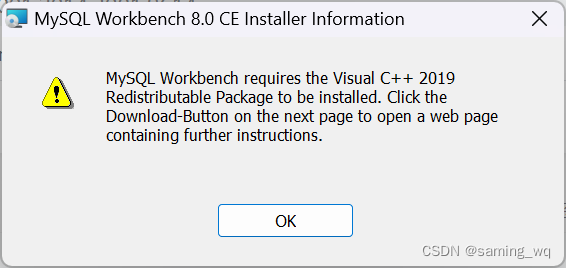
visual c++ 2019 redistributable package
直接安装下面包只有24M Microsoft Visual C Redistributable 2019 x86: https://aka.ms/vs/16/release/VC_redist.x86.exe x64: https://aka.ms/vs/16/release/VC_redist.x64.exe ———————————————— 版权声明:本文为CSDN博主「kpacnB_Z」的原创文章…...

WPF中DataGrid解析
效果如图: 代码如下: <DataGrid Grid.Row"1" x:Name"dataGrid" ItemsSource"{Binding DataList}" AutoGenerateColumns"False"SelectedItem"{Binding SelectedItem,UpdateSourceTriggerPropertyChange…...
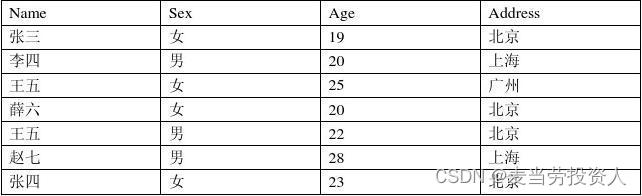
在数据库中进行表内容的修改(MYSQL)
根据表中内容,用命令语句创建数据库,表格,以及插入,修改,删除表格中的内容。 创建数据库:zrzy mysql> create database zrzy; 引用zrzy数据库: mysql> use zrzy; 创建student_info表&…...
Android中的多进程
在Android中也可以像pc一样开启多进程,这在android的编程中通常是比较少见的,以为在一个app基本上都是单进程工作就已经足够了,有一些特殊的场景,我们需要用多进程来做一些额外的工作,比如下载工作等。 在Android的An…...
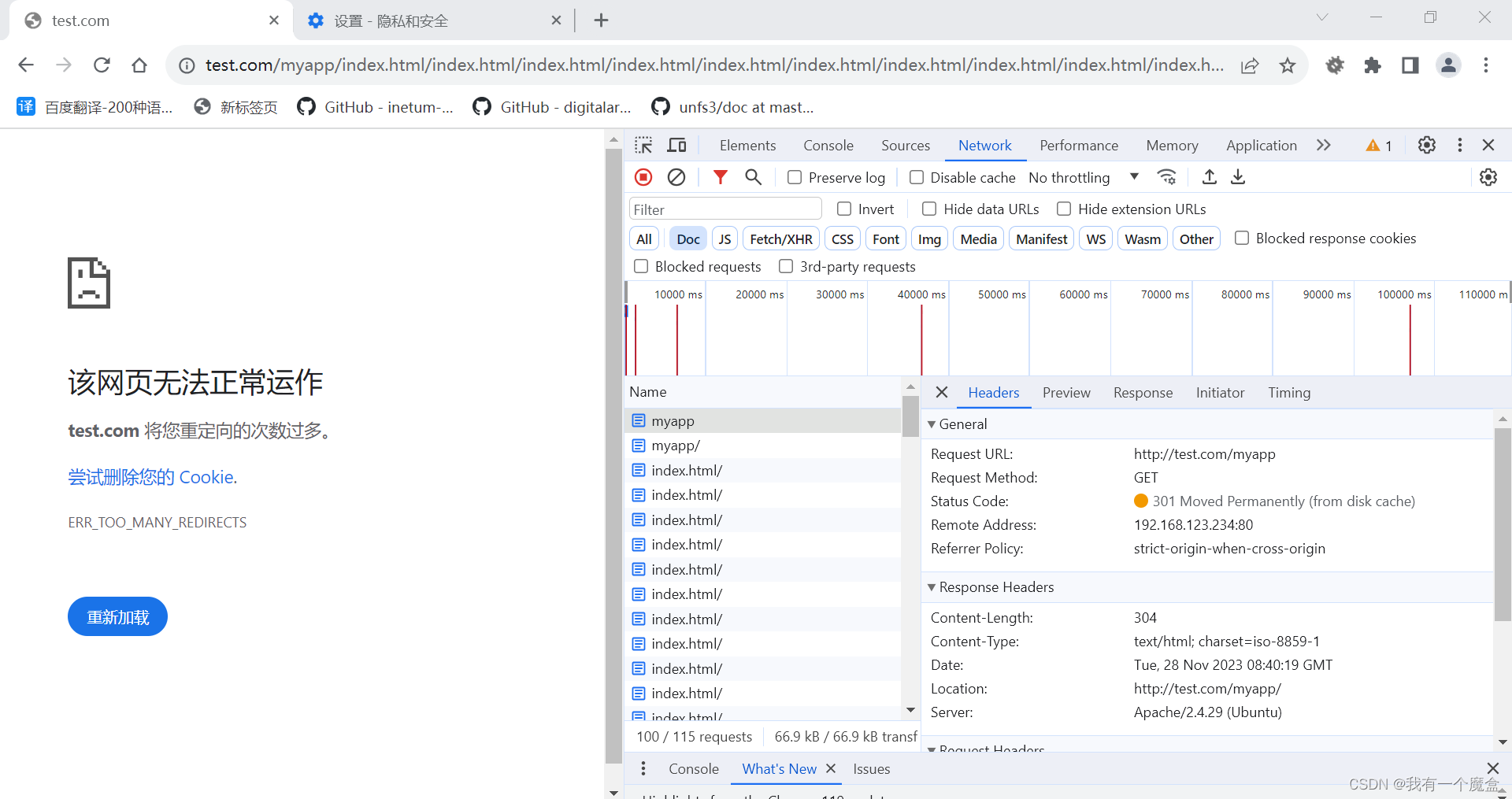
Apache2.4 AliasMatch导致301重定向问题?
环境:ubuntu18.04-desktop apache2版本: rootubuntu:/etc/apache2# apache2ctl -v Server version: Apache/2.4.29 (Ubuntu) Server built: 2023-03-08T17:34:33apache配置: DocumentRoot /var/www/html # Alias就没事 # Alias "/my…...

广州华锐视点:基于VR元宇宙技术开展法律法规常识在线教学,打破地域和时间限制
随着科技的飞速发展,人类社会正逐渐迈向一个全新的时代——元宇宙。元宇宙是一个虚拟的、数字化的世界,它将现实世界与数字世界紧密相连,为人们提供了一个全新的交流、学习和娱乐平台。在这个充满无限可能的元宇宙中,法律知识同样…...
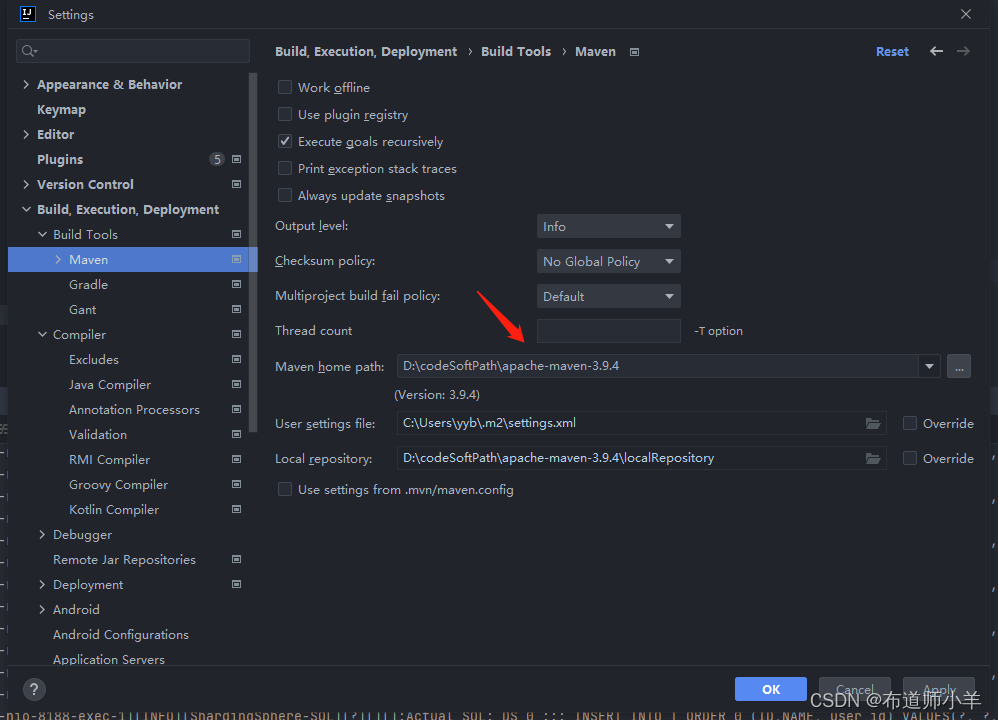
Maven——Maven使用基础
1、安装目录分析 1.1、环境变量MAVEN_HOME 环境变量指向Maven的安装目录,如下图所示: 下面看一下该目录的结构和内容: bin:该目录包含了mvn运行的脚本,这些脚本用来配置Java命令,准备好classpath和相关…...
U4_2:图论之MST/Prim/Kruskal
文章目录 一、最小生成树-MST生成MST策略一些定义 思路彩蛋 二、普里姆算法(Prim算法)思路算法流程数据存储分析 伪代码时间复杂度分析 三、克鲁斯卡尔算法(Kruskal算法)分析算法流程并查集-Find-set 伪代码时间复杂度分析 一、最…...

springboot 注解@JsonInclude
修饰 实体属性or实体类 //枚举值:ALWAYS,NON_NULL,NON_ABSENT,NON_EMPTY,NON_DEFAULT,CUSTOM,USE_DEFAULTS JsonInclude(Include.NON_EMPTY)//将该标记放在属性上,如果该属性为NULL则不参与序列化 //如果放在类上边,那对这个类的全部属性起作用 Inclu…...

Python 中文完整教程目录
Python 教程 Python 是一门易于学习、功能强大的编程语言。它提供了高效的高级数据结构,还能简单有效地面向对象编程。Python 优雅的语法和动态类型以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的理想语言。 Python 官网(…...

C/C++---------------LeetCode第35. 搜索插入位置
插入的位置 题目及要求二分查找在main内使用 题目及要求 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: …...

网络安全--基于Kali的网络扫描基础技术
文章目录 1. 标准ICMP扫描1.1使用Ping命令1.1.1格式1.1.2实战 1.2使用Nmap工具1.2.1格式1.2.2实战1.2.2.1主机在线1.2.2.2主机不在线 1.3使用Fping命令1.3.1格式1.3.2实战 2. 时间戳查询扫描2.1格式2.2实战 3. 地址掩码查询扫描3.1格式3.2实战 2. TCP扫描2.1TCP工作机制2.2TCP …...
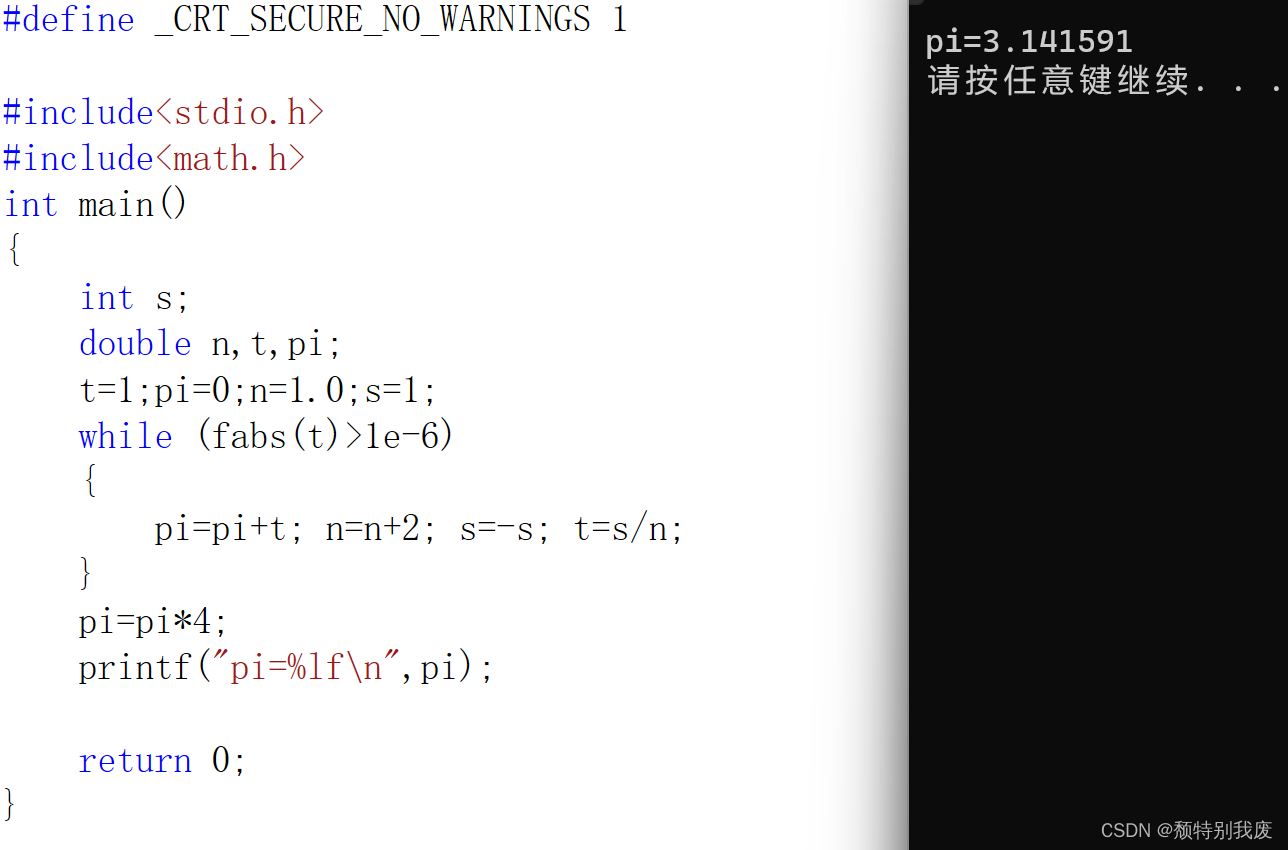
C语言——求π的近似值
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> #include<math.h> int main() {int s;double n,t,pi;t1;pi0;n1.0;s1;while (fabs(t)>1e-6){pipit; nn2; s-s; ts/n;}pipi*4;printf("pi%lf\n",pi);return 0; }这里是求小数点后6位——1e-6&#…...

如何使用ffmpeg转换图片格式
ffmpeg简介与图片格式介绍 windows安装ffmpeg,从如下网站下载release版本 https://www.gyan.dev/ffmpeg/builds/ ffmpeg 6.1版本仍然不支持heic的图片格式,未来可能会支持,具体见该issue: https://trac.ffmpeg.org/ticket/6521 …...

11 动态规划解最后一块石头的重量II
来源:LeetCode第1049题 难度:中等 描述:有一堆石头,用证书数组stones表示,其中stones[i]表示第i块石头的重量,每一回合,从中选出任意两块石头,然后将他们放在一起粉碎,…...
|LeetCode121. 买卖股票的最佳时机、LeetCode122. 买卖股票的最佳时机 II)
LeetCode算法题解(动态规划,股票买卖)|LeetCode121. 买卖股票的最佳时机、LeetCode122. 买卖股票的最佳时机 II
一、LeetCode121. 买卖股票的最佳时机 题目链接:121. 买卖股票的最佳时机 题目描述: 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一…...

python实验3 石头剪刀布游戏
实验3:石头剪刀布游戏 一、实验目的二、知识要点图三、实验1. 石头剪刀布2. 实现大侠个人信息 一、实验目的 了解3类基本组合数据类型。理解列表概念并掌握Python中列表的使用。理解字典概念并掌握Python中字典的使用。运用jieba库进行中文分词并进行文本词频统计。…...

米贸搜|如何设置 Facebook 转换 API + 事件重复数据删除
Facebook Pixel 可让您跟踪用户在您网站上的行为、收集再营销受众并创建相似对象。如果 Facebook 像素实现正确,它将向 FB 机器学习算法提供相关信息。 FB ML 将使用像素数据向最有可能转化的人展示您的广告。 几年来,我们可以通过 JavaScript 代码、应…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...

OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS
OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹…...

AI 如何改变软件工程:Martin Fowler 视角 + 实战洞见
AI 如何改变软件工程:Martin Fowler 视角 实战洞见 AI(尤其是 LLM)是软件工程自高级语言(从汇编到 C/Fortran)以来最大的转变。它引入了非确定性(Non-deterministic)编程,改变了从编…...