从0开始学python -44
Python3 正则表达式 -2
检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl,string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
#!/usr/bin/python3
import rephone = "2004-959-559 # 这是一个电话号码"# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
以上实例执行结果如下:
电话号码:2004-959-559
电话号码:2004959559
repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘以 2:
#!/usr/bin/pythonimport re# 将匹配的数字乘以 2
def double(matched):value = int(matched.group('value'))return str(value * 2)s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
执行输出结果为:
A46G8HFD1134
compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写* re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为’ . ‘并且包括换行符在内的任意字符(’ . '不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和’ # '后面的注释
实例
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print( m ) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0);start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
再看看一个例子:
>>>import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print( m ) # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串索引
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):File "<stdin>", line 1, in <module>
IndexError: no such group
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
re.findall(pattern,string, flags=0)
或
pattern.findall(string[, pos[, endpos]])
参数:
- pattern 匹配模式。
- string 待匹配的字符串。
- pos 可选参数,指定字符串的起始位置,默认为 0。
- endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
查找字符串中的所有数字:
import reresult1 = re.findall(r'\d+','runoob 123 google 456')pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)print(result1)
print(result2)
print(result3)
输出结果:
['123','456']
['123','456']
['88','12']
多个匹配模式,返回元组列表:
import reresult = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
[('width','20'),('height','10')]
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern,string, flags=0)
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
import reit = re.finditer(r"\d+","12a32bc43jf3")
for match in it: print (match.group() )
输出结果:
12
32
43
3
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern,string[, maxsplit=0, flags=0])
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| maxsplit | 分割次数,maxsplit=1 分割一次,默认为 0,不限制次数。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']>>> re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
['hello world']
相关文章:

从0开始学python -44
Python3 正则表达式 -2 检索和替换 Python 的re模块提供了re.sub用于替换字符串中的匹配项。 语法: re.sub(pattern, repl,string, count0, flags0)参数: pattern : 正则中的模式字符串。repl : 替换的字符串,也可为一个函数。string : …...

22- estimater使用 (TensorFlow系列) (深度学习)
知识要点 estimater 有点没理解透 数据集是泰坦尼克号人员幸存数据. 读取数据:train_df pd.read_csv(./data/titanic/train.csv) 显示数据特征:train_df.info() 显示开头部分数据:train_df.head() 提取目标特征:y_train tr…...

eKuiper 1.8.0 发布:零代码实现图像/视频流的实时 AI 推理
LF Edge eKuiper 是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 的主要目标是在边缘端提供一个流媒体软件框架(类似于 Apache Flink )。eKuiper 的规则引擎允许用户提供基于 SQL 或基…...

[Ansible系列]ansible JinJia2过滤器
目录 一. JinJia2简介 二. JinJia2模板使用 2.1 在play中使用jinjia2 2.2 template模块使用 2.3 jinjia2条件语句 2.4 jinjia2循环语句 2.5 jinjia2过滤器 2.5.1 default过滤器 2.5.2 字符串操作相关过滤器 2.5.3 数字操作相关过滤器 2.5.4 列表操作…...

Cookie、Session、Token区分
一开始接触这三个东西,肯定会被绕的不知道都是干什么的。1、为什么要有它们?首先,由于HTTP协议是无状态的,所谓的无状态,其实就是 客户端每次想要与服务端通信,都必须重新与服务端连接,这就意味…...

回暖!“数”说城市烟火气背后
“人间烟火气,最抚凡人心”。在全国各地政策支持以及企业的积极生产运营下,经济、社会、生活各领域正加速回暖,“烟火气”在城市中升腾,信心和希望正在每个人心中燃起。 发展新阶段,高效统筹经济发展和公共安全&#…...

JS逆向-百度翻译sign
前言 本文是该专栏的第36篇,后面会持续分享python爬虫干货知识,记得关注。 有粉丝留言,近期需要做个翻译功能,考虑到百度翻译语言语种比较全面,但是它的参数被逆向加密了,对于这种情况需要怎么处理呢?所以本文以它为例。 废话不多说,跟着笔者直接往下看正文详细内容。…...
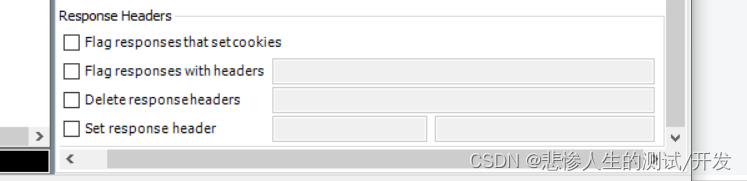
Fiddler抓包之Fiddler过滤器(Filters)调试
Filters:过滤器,帮助我们过滤请求。 如果需要过滤掉与测试项目无关的抓包请求,更加精准的展现抓到的请求,而不是杂乱的一堆,那功能强大的 Filters 过滤器能帮到你。 2、Filters界面说明 fiddler中的过滤 说明&#…...

【xib文件的加载过程 Objective-C语言】
一、xib文件的加载过程: 1.xib文件,是不是在这里啊: View这个文件夹里, 然后呢,我们加载xib是怎么加载的呢, 是不是在控制器里,通过我们这个类方法,加载xib: TestAppView *appView = [TestAppView appView]; + (instancetype)appView{NSBundle *rootBundle = [N…...

react setState学习记录
react setState学习记录1.总体看来2.setState的执行是异步的3.函数式setState1.总体看来 (1). setState(stateChange, [callback])------对象式的setState 1.stateChange为状态改变对象(该对象可以体现出状态的更改) 2.callback是可选的回调函数, 它在状态更新完毕、界面也更新…...

Docker容器cpu利用率问题
1.top原理 top 是读的/proc/stat文件 比如cat /proc/PID/stat 进程的总Cpu时间processCpuTime utime stime cutime cstime,该值包括其所有线程的cpu时间 某一进程Cpu使用率的计算 计算方法: 1 采样两个足够短的时间间隔的cpu快照与进程快照&…...

FreeRTOS入门(06):任务通知
文章目录目的基础说明使用演示作为二进制信号量作为计数信号量作为事件组作为队列或邮箱相关函数总结目的 任务通知(TaskNotify)是RTOS中相对常用的用于任务间交互的功能,这篇文章将对相关内容做个介绍。 本文代码测试环境见前面的文章&…...
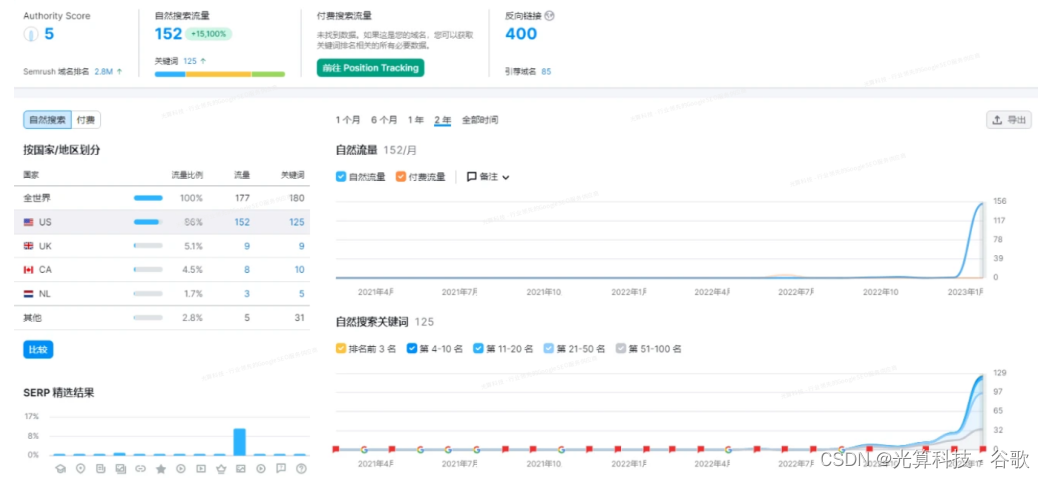
谷歌seo做的外链怎样更快被semrush识别
本文主要分享做谷歌seo外链如何能让semrush工具快速的记录并能查询到。 本文由光算创作,有可能会被剽窃和修改,我们佛系对待这种行为吧。 谷歌seo做的外链怎样更快被semrush识别? 答案是:多使用semrush搜索目标网站可加速爬虫抓…...

Java | IO 模式之 JavaBIO 应用
文章目录IO模型Java BIOJava NIOJava AIO(NIO.2)BIO、NIO、AIO的使用场景BIO1 BIO 基本介绍2 BIO 的工作机制3 BIO 传统通信实现3.1 业务需求3.2 实现思路3.3 代码实现4 BIO 模式下的多发和多收消息4.1 业务需求4.2 实现思路4.3 代码实现5 BIO 模式下接收…...

C语言学习及复习笔记-【18】C内存管理
18 C内存管理 C 语言为内存的分配和管理提供了几个函数。这些函数可以在 <stdlib.h> 头文件中找到。 序号函数和描述1void *calloc(int num, int size); 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了…...

linux--多线程(一)
文章目录Linux线程的概念线程的优点线程的缺点线程异常线程的控制创建线程线程ID以及进程地址空间终止线程线程等待线程分离线程互斥进程线程间的互斥相关概念互斥量mutex有线程安全问题的售票系统查看ticket--部分的汇编代码互斥量的接口互斥量实现原理探究可重入和线程安全常…...
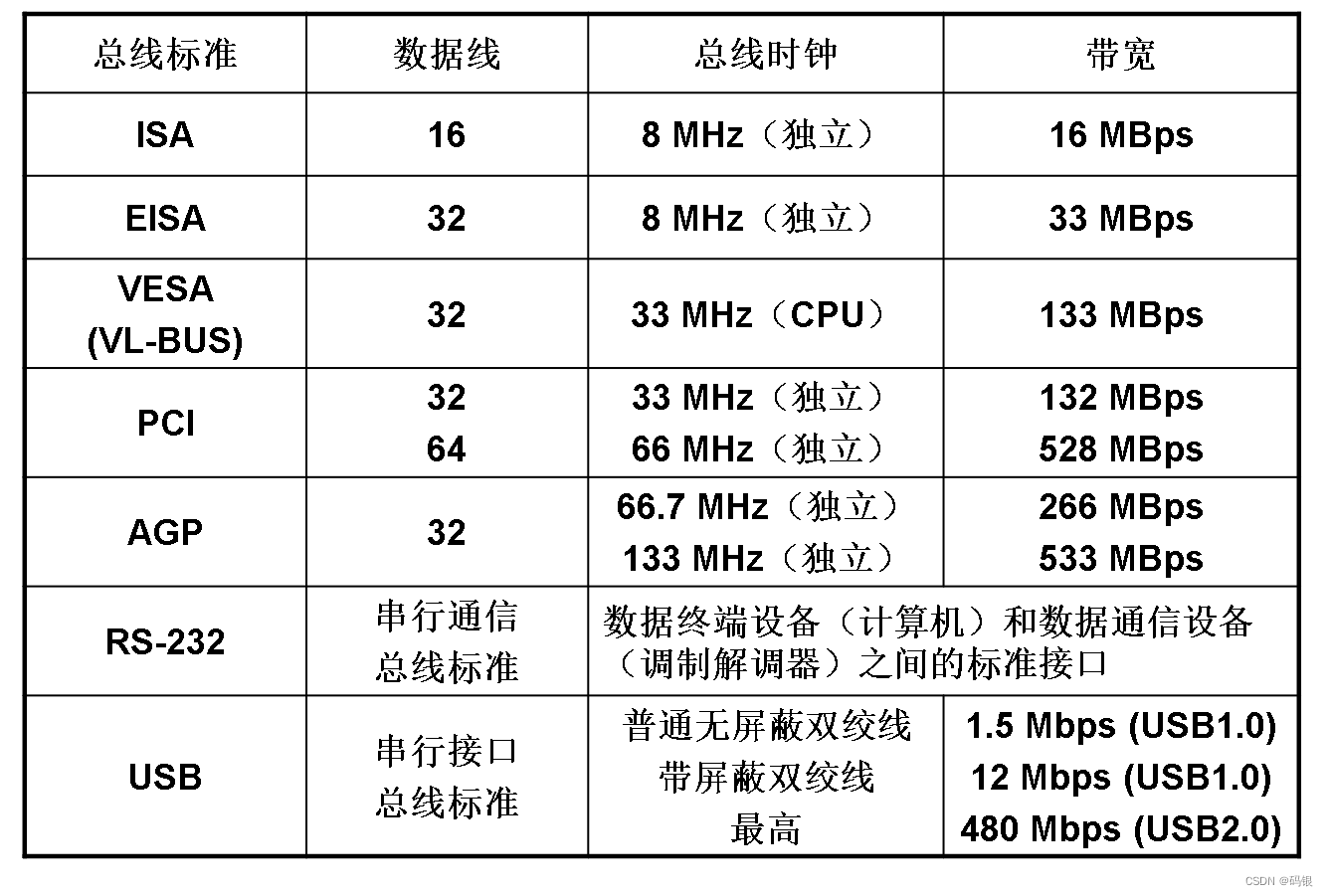
计算机组成原理(2.1)--系统总线
目录 一、总线基本知识 1.总线 2.总线的信息传送 3.分散连接图 4.注 二、总线结构的计算机举例 1.面向 CPU 的双总线结构框图 2.单总线结构框图 3.以存储器为中心的双总线结构框图 三、总线的分类 1.片内总线 2.系统总线 (板级总线或板间总线&#…...

C语言数组【详解】
数组1. 一维数组的创建和初始化1.1 数组的创建1.2 数组的初始化1.3 一维数组的使用1.4 一维数组在内存中的存储2. 二维数组的创建和初始化2.1 二维数组的创建2.2 二维数组的初始化2.3 二维数组的使用2.4 二维数组在内存中的存储3. 数组越界4. 数组作为函数参数4.1 冒泡排序函数…...

并行与体系结构会议
A类会议 USENIX ATC 2022: USENIX Annual Technical Conference(录用率21%) CCF a, CORE a, QUALIS a1 会议截稿日期:2022-01-06 会议通知日期:2022-04-29 会议日期:2022-07-11 会议地点:Carlsbad, Califo…...

【巨人的肩膀】JAVA面试总结(三)
1、💪 目录1、💪1、说说List, Set, Queue, Map 四者的区别1.1、List1.2、Set1.3、Map2、如何选用集合4、线程安全的集合有哪些?线程不安全的呢?3、为什么需要使用集合4、comparable和Comparator的区别5、无序性和不可重复性的含义…...

Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力
Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

【DSP学习】外部中断实验-基于普中DSP28335开发攻略
参考材料 普中DSP28335开发攻略 一、外部中断配置 1 失能 CPU 级中断,并初始化 PIE 控制器寄存器和 PIE 中断向量表在前面学习中断章节中,我们知道 F28335 的外设中断需通过 PIE 控制器来管理,因此需要初始化 PIE 相应的寄存器和中断向量表。…...

技术新人的“导师红利”:如何让前辈心甘情愿带你?
在软件测试这个领域,技术新人的成长路径往往决定了他未来能走多远。测试不像开发那样有清晰的代码逻辑可循,它更像一门“破案”的艺术,需要经验、直觉和对业务深刻的理解。而这些,恰恰是书本和教程给不了的。于是,一个…...

对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势 对于需要调用多种大模型能力的开发者而言,直接与各家…...

Ubuntu 24.04 + ROS2 Jazzy 开发环境避坑指南
️ 环境配置(仅需操作一次) 前提背景:Ubuntu 24.04 强制要求使用虚拟环境安装 pip 第三方库,而 ROS2 编译工具链(colcon, catkin_pkg)依赖系统全局 Python。为兼顾两者,需创建一个“能看见系统 …...

我受够了手动SEO,所以我让AI替我打工了
我受够了手动SEO,所以我让AI替我打工了 这事得从三个月前说起。我坐在电脑前,面前开了十四个标签页。一个Google Search Console在转圈圈,一个Ahrefs在加载报告,一个空白Google Doc等着我写东西,还有一个WordPress后台…...

告别重复图片困扰:AntiDupl.NET 智能图片去重工具完全指南
告别重复图片困扰:AntiDupl.NET 智能图片去重工具完全指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑中堆积如山的重复图片而感到困扰&…...

幸福依赖于抽象的 能力的庖丁解牛
它的本质是:**将幸福的源头从 具体实现类 (Concrete Implementations)(如特定的伴侣、具体的工作、固定的房产)转移到 抽象接口 (Abstract Interfaces)(如爱的能力、创造价值的技能、感知美好的心智)。具体实现是不可控…...
深度集成:让 AI 安全执行企业 API)
函数调用(Function Calling)深度集成:让 AI 安全执行企业 API
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 5/10 篇,当前这篇会重点解决:展示如何让 AI 安全可控地操作企业后端服务,实现真正的智能体能力。 上一篇回顾:第 4 篇《检索增强生成(RAG)实战:Spring AI 集成向量数据库实现知识问…...

Docker部署RabbitMQ后,你的admin账号真的能连上吗?一个权限配置的深度踩坑实录
Docker部署RabbitMQ后admin账号连接失败的深度排查指南 当你用Docker快速部署了RabbitMQ,创建了admin用户,甚至能通过Web界面登录,却在代码中遭遇ACCESS_REFUSED错误时,那种挫败感我深有体会。这不是简单的密码错误问题࿰…...