与 PCIe 相比,CXL为何低延迟高带宽?
文章目录
- 前言
- 1. Latency
- PCIE 生产者消费则模型
- 结论
- Flit 包
- PCIE/CXL.io
- CXL.cace & .mem
- 总结
- 2. BandWidth
- 常见开销
- CXL.IO Link efficiency
- PCIe Link efficiency
- CXL.IO bandwidth
- CXL.mem/.cache bandwidth
- 参考
前言
CXL 规范里没有具体描述与PCIe 相比低延时高带宽的原因,一开始我也很不理解,不过慢慢就有点轮廓了,做一个总结,尽量讲通俗一点,欢迎指正。
1. Latency
PCIE 生产者消费则模型
在开始之前,首先提一嘴 PCIE 的生产者消费者模型,因为在使用 PCIE 设备的时候,主机与设备通信,比如网卡收发数据、显卡接受数据等,进行具体的业务数据传输时,为了维护数据的准确性,必须是使用生产者消费者模型的。
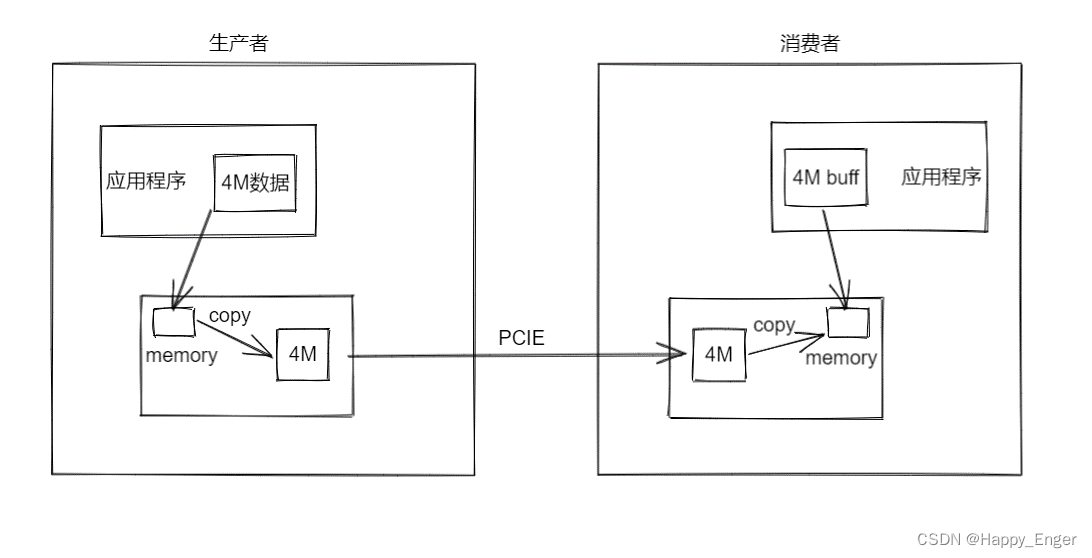
如上图,右侧为主机,左侧为设备,如果主机想要获取设备某段内存的地址,除非特殊设计,将设备内存映射到BAR 空间,主机侧可直接地址访问,否则,必须是设备将要读取的内存区域的数据 copy 到 DMA 传输内存缓冲区中,然后启动 DMA 传输,通过PCIE 控制器传输数据到主机侧相应的 DMA 缓冲区,并通过中断或者 flag 通知主机,传输完成;主机收到完成信号后,会开始操作,将DMA 缓冲区的数据拷贝到应用程序缓冲区,进行下一步数据处理。
哪怕是主机读设备一个字节,也是上面这个流程,延迟的分布不仅在 PCIE 协议层,而且主要分布在最少两次的内存拷贝中。
所以,我要将延迟分两部分介绍,一部分是控制器到控制器的延迟,一部分是站在应用程序的角度,读写对端内存的延迟.
结论
后面内容太杂,所以先说结论,以免越看越乱。CXL 低延迟的实现根据上面两部分分类,一类是控制器到控制器的延迟,主要是因为采用 FLIT 模式的包,增加了少数据量的带宽,简化了硬件设计,取消了PCIE的ordering rule, access right check、DLLP等,换句话说,CXL 控制器与PCIe 控制器设计上就降低了很多 latency。第二类,站在应用层角度上看,延迟主要是因为 CXL 协议可以维护缓存一致性,所以减少了内存 copy 的操作,从而降低了整体延迟。
Flit 包
在讲 Flit 包之前,我们可以先看一下 PCIe 传输层协议包的格式,如下图
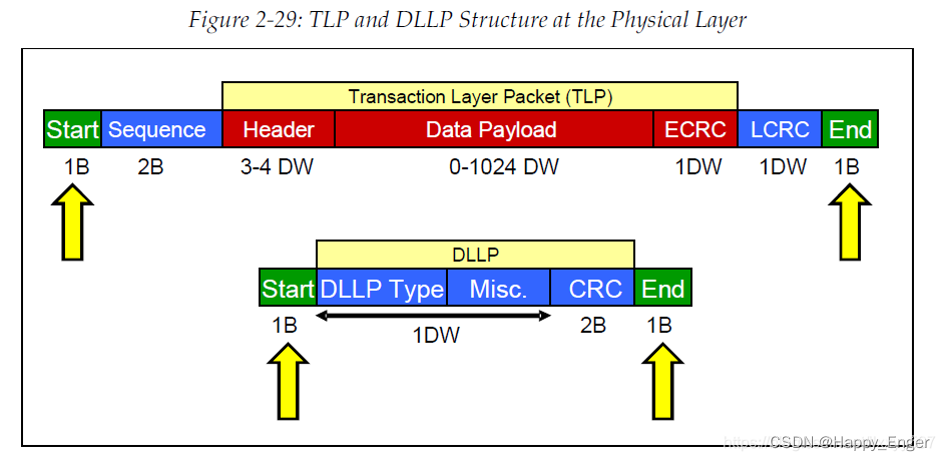
其中,红色部分为 TLP 包格式,分为 3 -4 DW 的头,0 - 1024 DW 变长的数据负载以及最后 1DW 的CRC. 其他字节为数据链路层以及物理层额外添加的开销。
不同于 TLP, CXL 采用 Flit 模式发送数据,CXL.cache / mem flie 大小固定 528bit, 有2字节的CRC以及 4 slots 的16字节块。
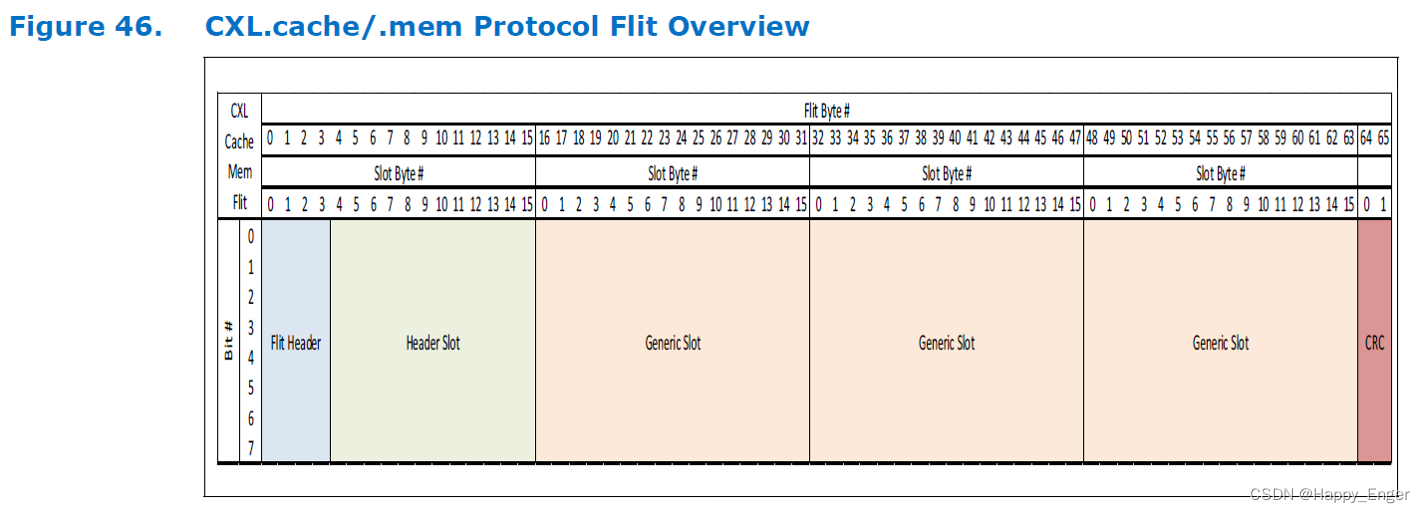
其中:
A “Header” Slot is defined as one that carries a “Header” of link-layer specific information
A “Generic” Slot can carry one or more request/response messages or a single 16B data chunk.
The flit can be composed of a Header Slot and 3 Generic Slots or four 16B Data Chunks.
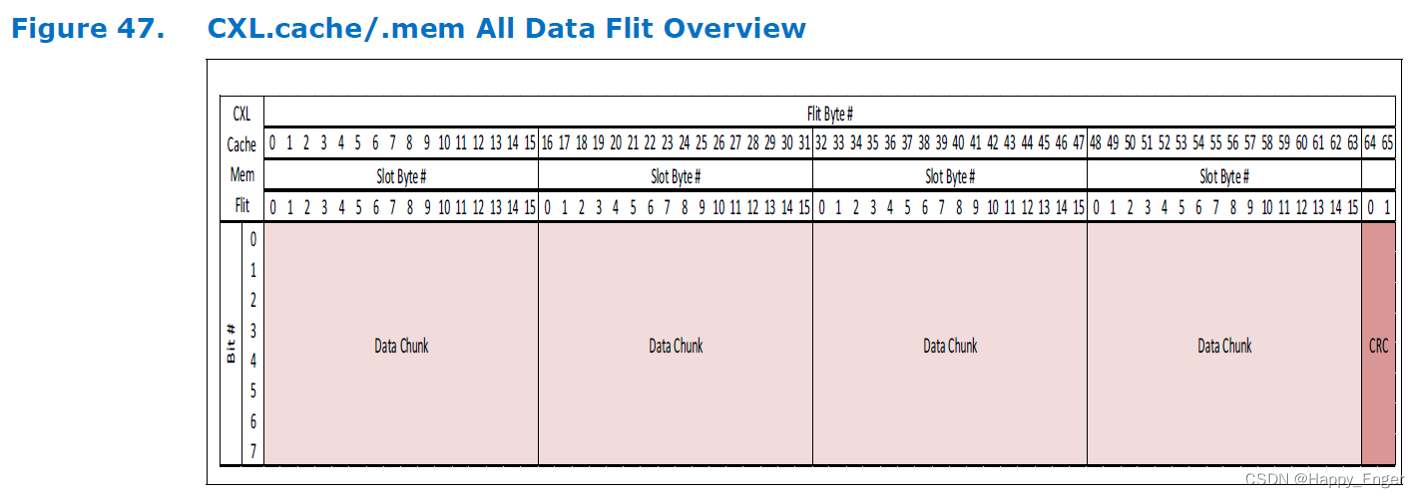
总结一下,就是 CXL Flit 就是固定的 4块 16 字节的区域外加一个2字节CRC. 这 4 块区域每块都可以放请求响应包,也可以放数据块,头只能放在 slot0 中。
举个例子如下,设备到主机的 flit 包, 最上面 slot0 有头,也有响应包,其他的有请求包也有响应包,最后一个slot 放的16字节数据,然后最后2字节CRC.
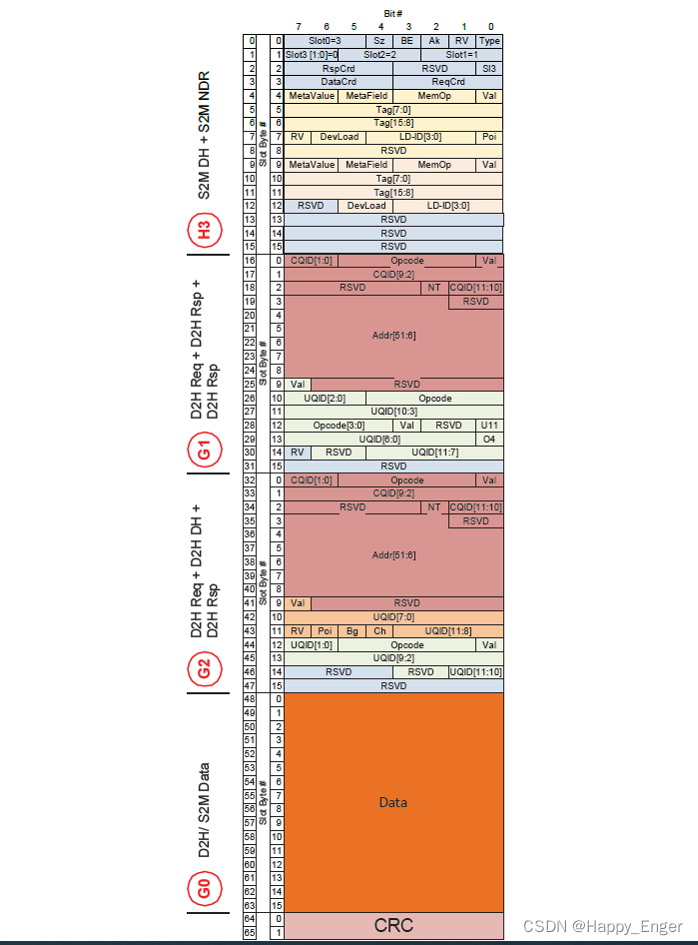
使用 Flit 优点如下:
- 其携带的额外信息很多,优势就在于当你出现高速数据传输的时,携带数据的能力越强,速率越高,数据量越大,这种flit模式下的低延迟高速率的优势就会越明显;
- PCIe 6.0 引入了 FLIT 模式,其中数据包以固定大小的流量控制单元组织,而不是过去几代 PCIe 中的可变大小。引入 FLIT 模式的最初原因是纠错需要使用固定大小的数据包;
- FLIT 模式还简化了控制器级别的数据管理,从而提高了带宽效率、降低了延迟并缩小了控制器占用空间。对于固定大小的数据包,不再需要在物理层对数据包进行成帧,这为每个数据包节省了 4 字节;
- FLIT 编码还消除了以前 PCIe 规范中的 128B/130B 编码和 DLLP(数据链路层数据包)开销,从而显著提高了效率,尤其是对于较小的数据包。
PCIE/CXL.io
首先借鉴一下其他公司的 PPT , PCIe 设备访问主机内存的数据流如下:
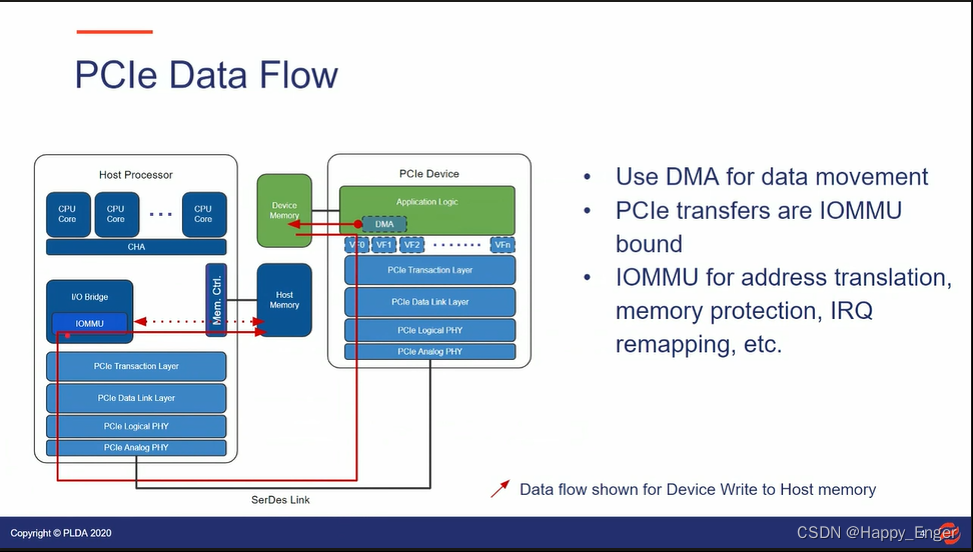
PCIe 设备访问主机内存有两种情况,一种是直接内存访问,流向如上图;还有一种是站在应用程序的角度,需要内存拷贝至少两次,如前面的生产者消费者模型。他们都用不到缓存,但会都用到 IOMMU.
PCIe Latency Breakdown 如下:
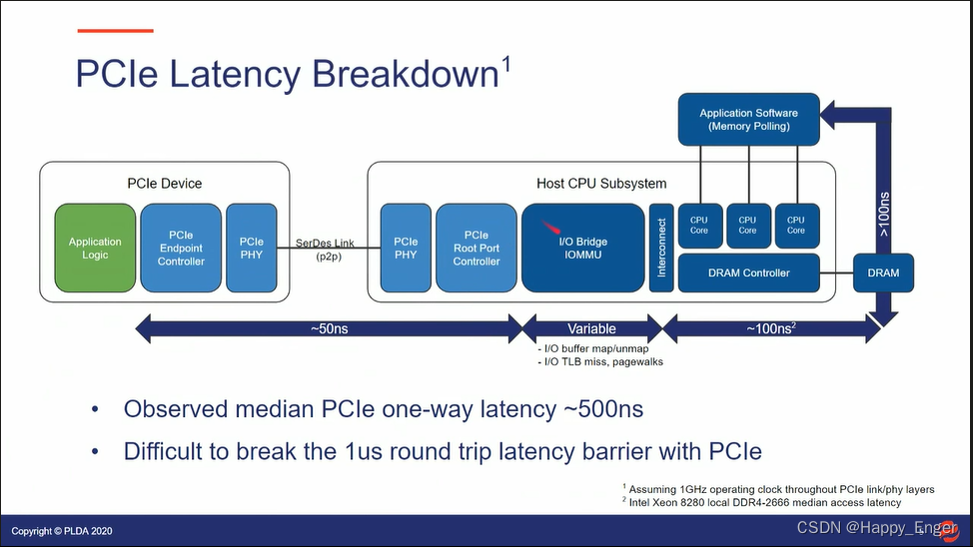
PCIe 控制器到控制器为 50ns, IOMMU 根据不同的环境时间是变化的,内存控制器读写内存需要 100ns. 整体一路大概 500ns, 来回很难打破 1us. 这是站在应用层角度,有了第二次拷贝,这个 latency 算进去。实际延时应该会更长。
如下为 CXLIO 设备到主机内存的数据流向:
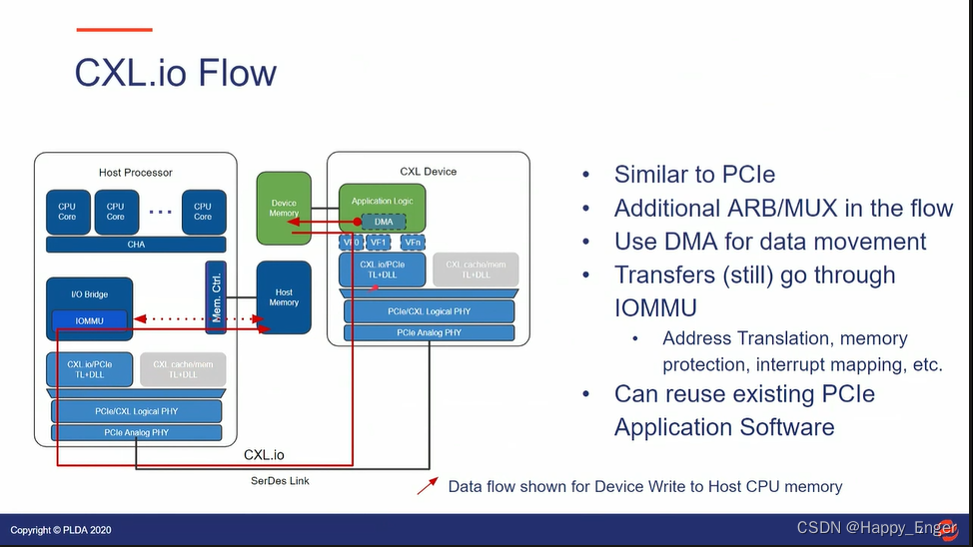
与 PCIe 基本相似,不同的是,CXL 控制器与 PCIe控制器还是有点差异的,多了一个 ARB/MUX 动态多路复用器件。软件层面,可以与 PCIe 复用。
CXL.io 的性能如下:

IO 的吞吐量比 PCIe 还要差 6%, 因为CXL.io 协议就是封装了PCIe 的TLP, 在前面加了2字节 Protocol ID 以及后面增加了 2字节的 reserved bytes。增加了的 ARB/MUX 器件也会消耗 2 - 4 ns。
如下图, CXL Flit 包的在 X8 的分布,每条 Lane 发送一个字节, 第一部分的橙色部分为封装的 PCIe 的包,黄色部分为添加的 2 字节 Protocol ID, 最后有 2字节的 reserved bytes:
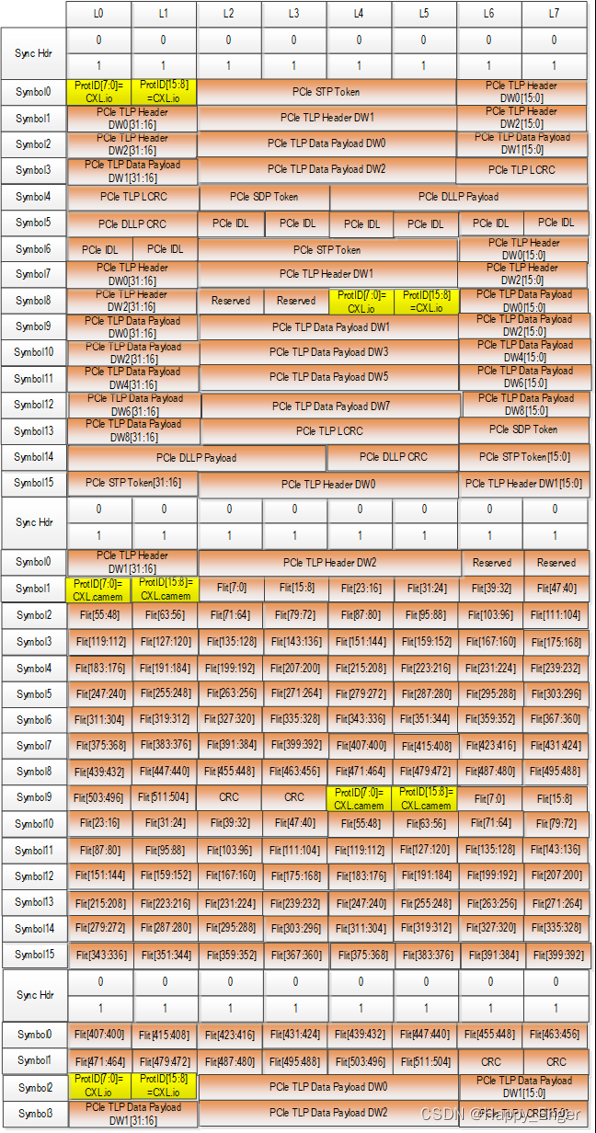
CXL.cace & .mem
下图为 CXL.cache 设备访问主机内存的数据流向:
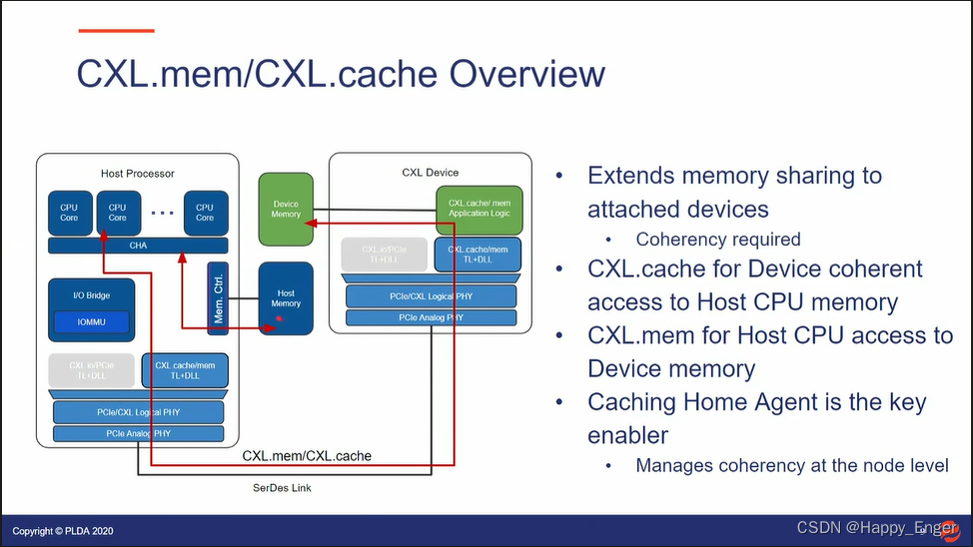
.cache 协议可以让设备像访问本地内存一样访问主机内存,设备CPU与主机 CPU 可以共同访问同一个地址的数据,缓存一致性由主机侧的 Cache Home Agent 来维护。根据 MESI 协议,看情况是否去访问实际内存。
.mem 则相反方向,让主机使用缓存访问设备内存,就像访问本地 DDR 内存一样。
下图为 .cache 与 .mem 的好处:

- 主机和设备相互访问对方内存,可以直接使用内存语义, load/store,不用再使用生产者消费者模型,使用中断或者 flag 通知对方,也不用多次拷贝了;
- 设备侧可以同样使用主机页表,那样,主机进程和设备就可以访问同一块虚拟地址空间了;
下图为 CXL microarchitecture with CXL.$Mem measured latency.
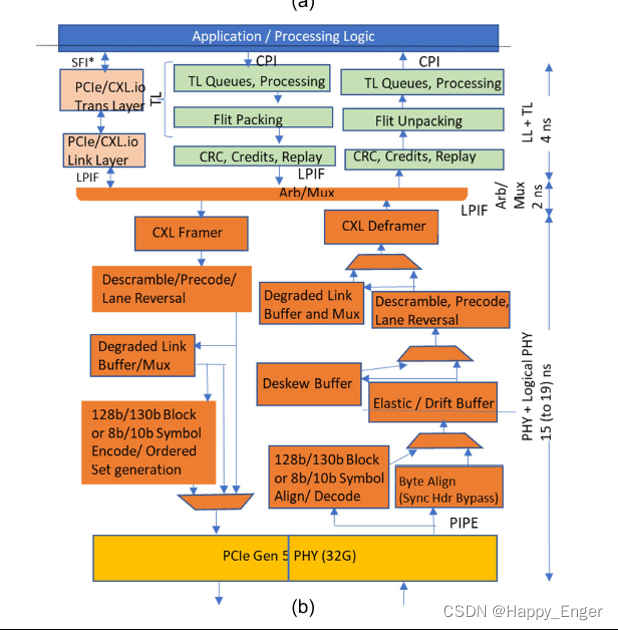
intel 控制器比标准PCIe PHY 做了如下延迟优化:
- bypassing the 128-/130-byte encoding
- bypassing the logic and serializing flops needed to support
- bypassing the deskew buffer if the lane to lane skew is less than half the internal PHY logical clock period
- adopting a predictive policy of processing entries from the elastic buffer (versus waiting for the clock domain synchronization handshake for every entry)
最终, PHY 到 PHY 之间有一个 15 - 19 ns 的延迟,其中4ns 的差异是由参考时钟决定的,depending on whether a common reference clock or independent reference clocks are deployed. 与前面 PCIe 的50 ns 对比,是有时间节省的,不过实际情况,根据不同的IP, 可能会有更大的差距。
这里需要注意的一点是,最底层的模拟 PHY,PCIe 与 CXL 使用的是同一个,这个意味着对于RC与EP的模拟phy 到模拟 phy,相同的数据量,时间是一样的。
More Latency Savings with CXL.mem /.cache

及其他:
- The link layer and transaction layer paths have a low latency since they are natively flit based.
This eliminates the higher latency in the PCIe/ CXL.io path due to the support for variable packet size, ordering rules, access rights checks, etc. saving latency due to simplified controller design. - Break out of the PCIe ordering model
Latency saving through out-of-order transfers, write completions - ARB/MUX:
CXL.Cache/Mem protocol muxing at the PHY level (versus higher level of the stack) helps deliver a low latency path for CXL.$Mem traffic. - Coherence Bias
Latency savings with optimized snoop traffic in Device Bias mode
其他的介绍开销的地方,前两个由于使用 FLIT 模式传输,PCIe 协议包耗时的逻辑取消了;第 3 点是硬件期间 ARB/MUX 为协议选择低延迟路径,还是硬件控制器IP 加速了;最后一条是 CXL 协议的功能,设备偏置,有利于加速设备访问主机内存。
下图为 CXL.cache/mem 延迟分布
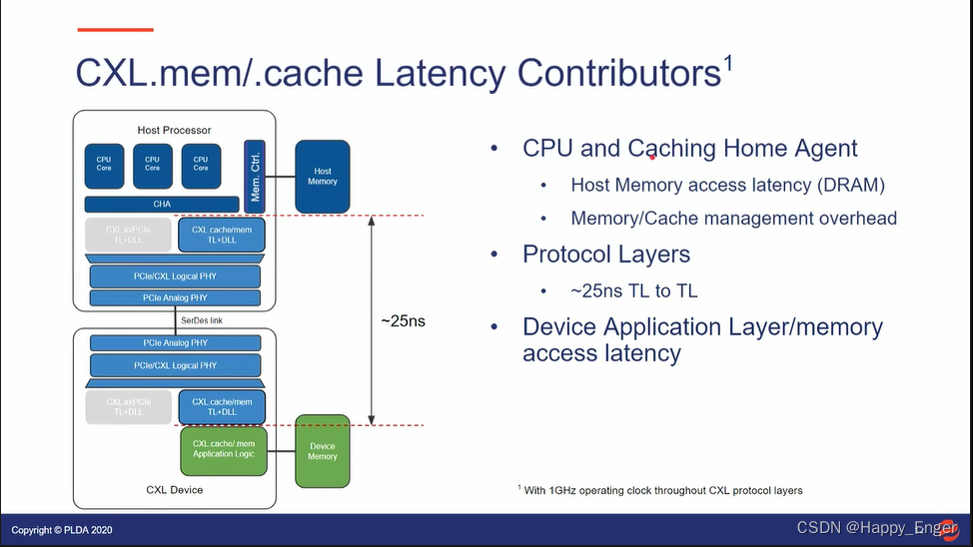
CPU 访问内存以及 Cache 一致性操作;CXL 协议层消耗 25 ns; 设备侧应用层延迟以及内存访问延迟;
下图是一个 Type2 设备读主机内存的时间估计:

请求响应包一个来回共 25 + 25 = 50ns, 主机访问内存消耗 100ns 左右,整体 150ns 左右,外加设备侧应用消耗;
下图为写:
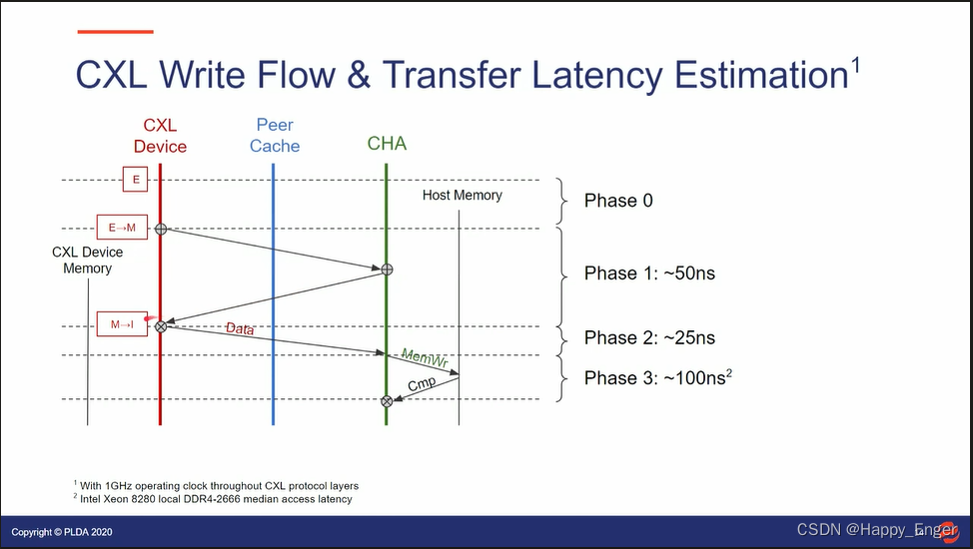
请求与响应一个来回,写操作再携带数据发送一遍,25 + 25 + 25 = 75 ns, 主机侧写内存消耗 100ns 左右,总计 175ns左右。
其他影响延迟的因素:

多处理器环境,以及 snoop 的响应的缓存一致性管理增加延迟,IOMMU 中的虚拟地址到物理地址的转换等也会有影响,不过这是 PCIe 与 CXL 共同面临的问题。
如下是 RAMBUS 公司设计的 CXL Controller IP

控制器与上层接口也使用了 Intel 低延迟的 CPI 接口,控制器也使用了其他技术减少延迟。
总结
由上总结,CXL 比 PCIe 延迟低的原因如下:
- 与PCIe相比,CXL Flit 模式简化控制器设计,控制器其他硬件设计降低延迟, 最少 50 ns-> 25ns;
- Flit 模式增加了少数据量的带宽;
- CXL 协议包降低了数据处理逻辑,取消了排序规则以及DLLP等,节省开销;
- CXL 协议功能取消了内存拷贝,节省开销等;
2. BandWidth
这里的带宽是指每秒传输的有效数据,有效数据即读写的数据。前提,X16 Gen5 在速率 32 GT/s 下原始带宽每个方向 64 GB/s = 32 GT / s * 16 / 8bit。
常见开销
在 68-byte flit 模式下,三种常见开销:
-
128/130 = 0.9846 represents the sync HDR overhead (which can be reclaimed when sync HDR bypass is supported)
这里不是 128/130 编码, 是 Flit 每条Lane上的 2bit的 Sync Header,01代表128bit前插入 Order set block, 10 表示该 block 为 data block
支持 Sync HDR bypass 的时候此开销可以取消 -
374/375 = 0.9973 represents the bandwidth loss due to SKP ordered sets for common clock (higher for other mode)
SKP : 最多 375 字符插入 SKP 方式,达到补偿时钟偏差的目的, PCIe 与 CXL 都有的开销 -
64/68 = 0.9412 representing the flit overhead (2 bytes each for protocol ID and flit CRC).
CXL Flit 模式特有的,前面 2字节 Protocol ID, 后面 2 字节 CRC
FLit 包格式如下图,CRC 画错了,PROTID 与 CRC 之间应该是 4 个 slot 共 64字节:
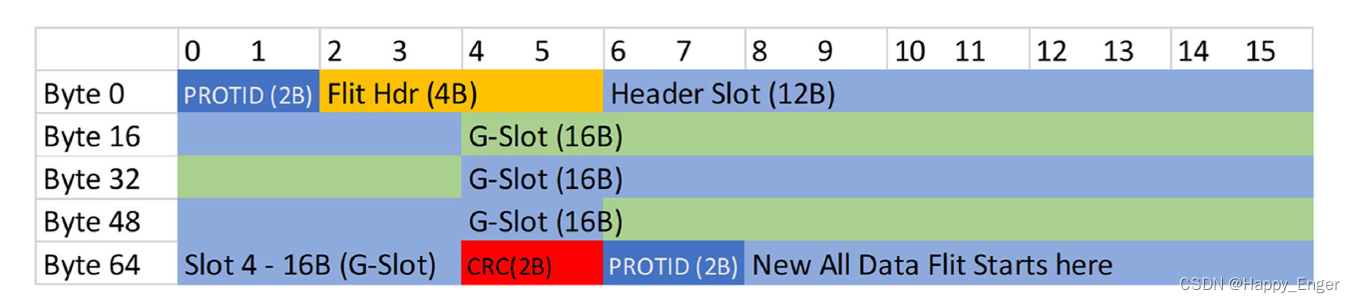
下图也是 68B Flit 包:

由上知链路效率:
使用 HDR Flit 包: 0.9846 * 0.9973 * 0.9412 = 0.9242
关闭 HDR Flit 包: 0.9973 * 0.9412 = 0.9387
CXL.IO Link efficiency
68-byte flit 模式下, 假设DLLP 包损耗 2%, .IO 链路层效率为:
使用 Sync HDR : 0.9242 * (1 - 0.02) = 0.9055
关闭 Sync HDR : 0.9387 * (1 - 0.02) = 0.9199
PCIe Link efficiency
PCIe 不适用 flit 模式,所以第三个开销没有,另外两个开销: 0.9846 * 0.9973 = 0.9819,此外还有 2%的 DLLP 开销,所以总开销为:
0.982 * (1 - 0.02) = 0.9624.
与 CXL.io 相比,PCIe 链路层效率还上升了 6%,主要在 Protocol ID 与 CRC 上。
CXL.IO bandwidth
计算带宽一般是 100% 读,100%写,50%读50%写三种情况,这里就不一一分析了。只分析个简单的 100% 读。
设 D 为数据负载,单位 DW 双字, 1 DW = 4 字节。
IO 里面封装的 TLP 包, TLP 包头是 3-DW for completions and 4-DW for requests (read/write).
An additional overhead of 2-DWs for framing and CRC is incurred per TLP with 68-byte flit (FT_CRC = 2),这里可能是计算的 CXL3.0 256B Flit 的开销。
带宽计算方式如下:
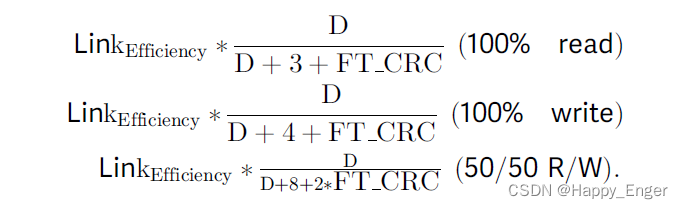
所以 1R0W 的结果为: 0.9199 /6 * 64GB /s = 9.812GB /s, 其他同理。
CXL.IO Bandwidth 结果如下:
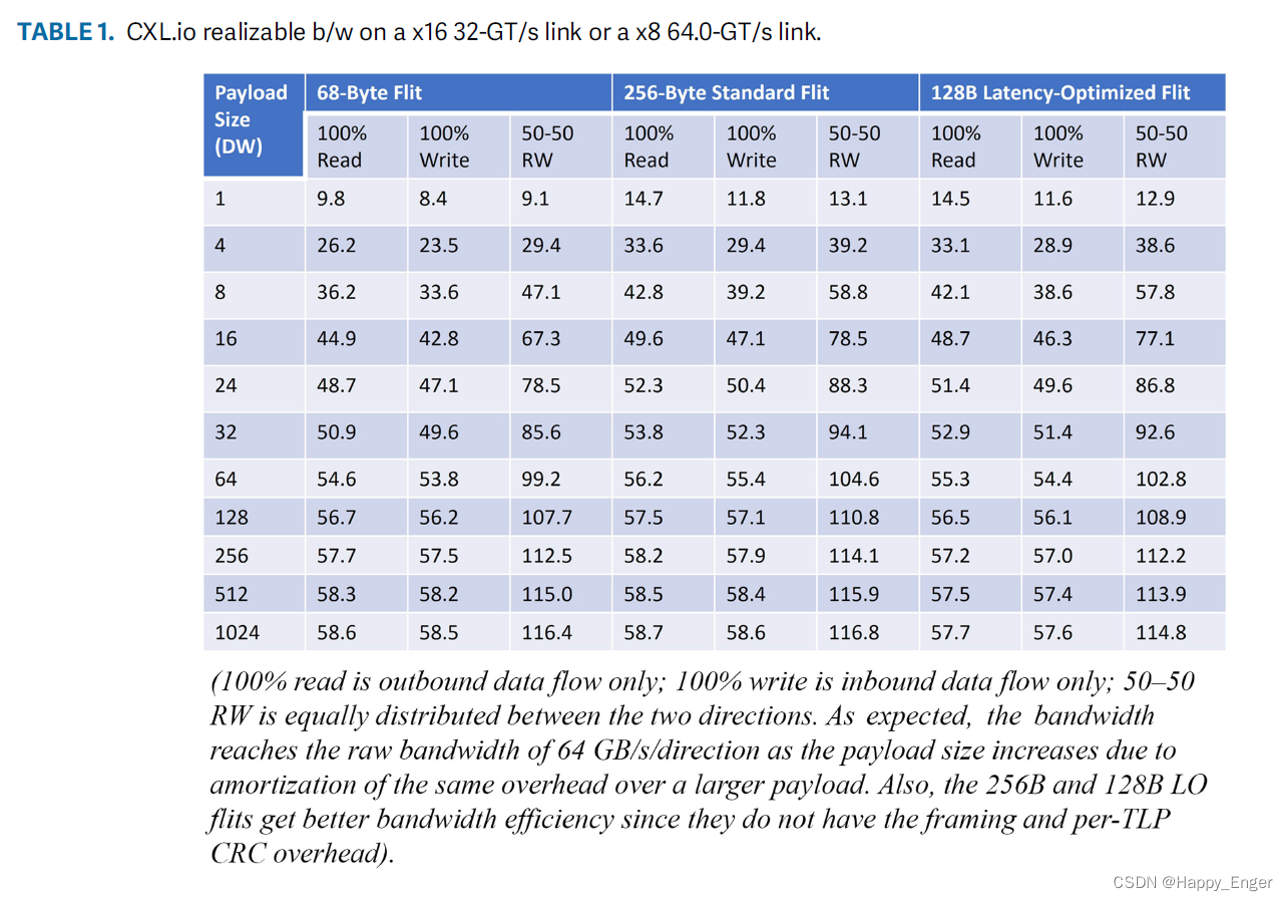
PCIe 与 CXL.IO 差不多,从结果看,少量数据效率低,大量数据效率高,所以,对于大数据量来说, CXL 与 PCIe 相比提高不大,不过对于小数据量的读写访问,比如 8个字节来说,优势则巨大。
CXL.mem/.cache bandwidth
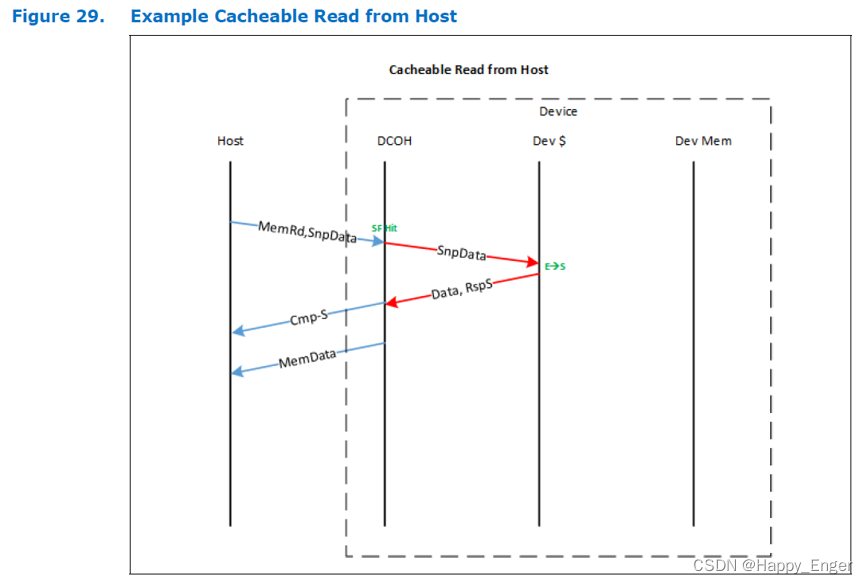
主机读 Type 2 设备内存流程如下图:
主机读 Type 3 设备内存流程如下图:
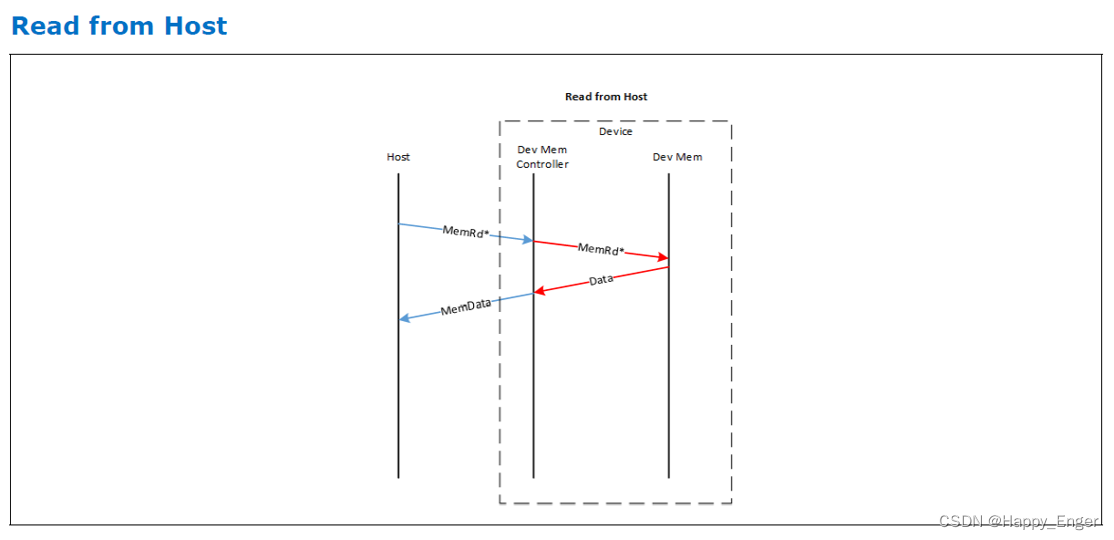
主机读设备,都是发送一个读请求,只不过对于 Type2 设备,会附加缓存状态信息Snoop SnpData, Type2 设备会返回 S2M DRS + NDR, Type3 设备会只返回 S2M DRS,这是 Type2 与 Type3 的重要区别,此条信息值一万。
S2M DRS 是响应数据包,NDR 是无数据响应,用来指示主机缓存状态的,此外都要外加一个缓存行大小的数据 64 字节。
同样,以 1R0W 为例计算带宽,x reads, y writes, 以 slot 为单位,有效数据占 4 slot.
在看下图 S2M DRS + S2M NDR Flit 包
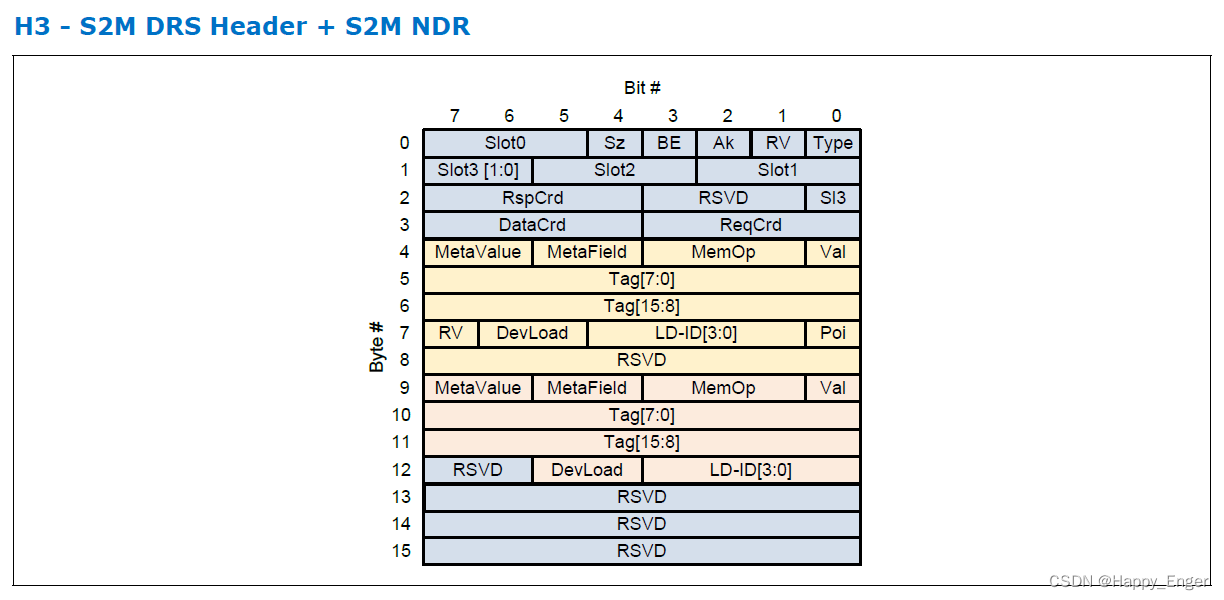
0 - 3 字节为头,4 - 8 字节为 S2M DRS, 9 - 12 字节为 S2M NDR.
所以对于 Type3 来说,S2M DRS 占半个 Slot.
由上可计算得到 S2M 使用的最大 slots 为 (x + y) / 2 + 4x, 有效数据占 4x
则最终 bandwidth 为 LinkEfficiency * 4x / ((x + y) / 2 + 4x) = 0.9387 * 4 / (1/2 + 4) = 0.8344, 0.8344 * 64GB/s = 53.4 GB / s
其他 cache 与 mem bandwidth 计算公式如下图:

结果如下:
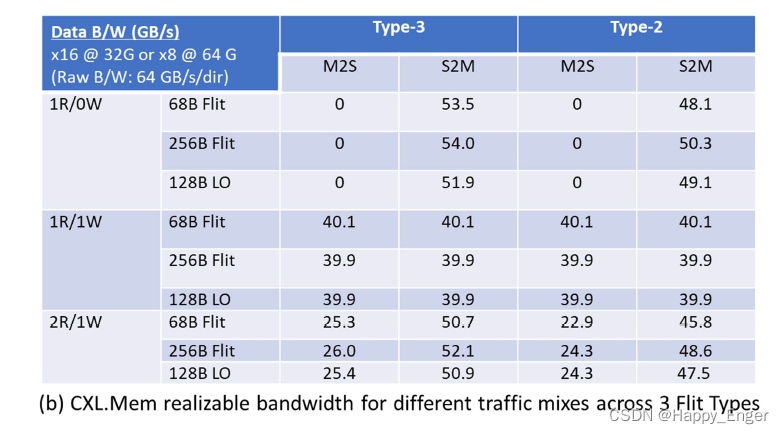
因为PCIe 的有效数据负载是可变的,所以 1DW - 1024 DW 效率随着负载的增多在不断增大,CXL 读写操作的字节长度是 64 字节,读128字节的数据就是发送两个 S2M DRS 包,所以一个方向的带宽是不变的。
打完收工!
参考
- 《Compute Express Link (CXL) Specification Revision 3.0》
- 《An Introduction to the Compute Express LinkTM (CXLTM) Interconnect》
- 《Compute Express Link (CXL): Enabling Heterogeneous Data-Centric Computing With Heterogeneous Memory Hierarchy》
- RAMBUS Company PPT
相关文章:
与 PCIe 相比,CXL为何低延迟高带宽?
文章目录 前言1. LatencyPCIE 生产者消费则模型结论Flit 包PCIE/CXL.ioCXL.cace & .mem总结 2. BandWidth常见开销CXL.IO Link efficiencyPCIe Link efficiencyCXL.IO bandwidthCXL.mem/.cache bandwidth 参考 前言 CXL 规范里没有具体描述与PCIe 相比低延时高带宽的原因&…...
Vue 入门指南:从零开始学习 Vue 的基础知识
🥝VUE官方文档 注意: 📒Vue 2 将于 2023 年 12 月 31 日停止维护。详见 Vue 2 延长 LTS。📒Vue 2 中文文档已迁移至 v2.cn.vuejs.org。📒想从 Vue 2 升级?请参考迁移指南。 文章目录 🍁前言&am…...
11.docker的网络-docker0的理解及bridge网桥模式的介绍与实例
1.docker0的基本理解 安装完docker服务后,我们首先查看一下宿主机的网络配置 ifconfig我们可以看到,docker服务会默认在宿主机上创建一个虚拟网桥docker0,该网桥网络的名字称为docker0。它在内核层连通了其他物理或者虚拟网卡,这…...

新材料制造ERP用哪个好?企业应当如何挑选适用的
有些新材料存在特殊性,并且在制造过程中对车间、设备、工艺、人员等方面提出更高的要求。还有些新材料加工流程复杂,涉及多种材料的请购、出入库、使用和管理等环节,解决各个业务环节无缝衔接问题是很多制造企业面临的管理难题。 新材料制造…...

vr小鼠虚拟解剖实验教学平台减少了受感染风险
家畜解剖实验教学是培养畜牧兽医专业学生实际操作能力的专业教学活动中的核心手段。采取新型教学方式与手段,合理设置实验教学内容,有助于激发学生的操作积极性,促进实践教学的改革。 家畜解剖VR仿真教学是一种借助VR虚拟现实制作和web3d开发…...
【算法萌新闯力扣】:环形链表及环形链表II
力扣题目:环形链表及环形链表II 开篇 今天是备战蓝桥杯的第26天和算法村开营第4天。挑选了链表的黄金关卡与大家分享。 题目一:环形链表 题目链接: 141.环形链表 题目描述 方法一、哈希表 判断是否有环,可以利用哈希表,遍历…...
10.docker的网络network-概述
1.docker的网络模式 docker共有四种网路模式,分别是bridge、host、none和container. 1.1 bridge bridge,也称为虚拟网桥。在bridge模式下,为每个容器分配、配置IP等,并将容器连接到一个docker0。使用–network bridge命令指定,…...

CodeTON Round #7 (Div. 1 + Div. 2)
A.jagged Swaps 题意: 给出一个包含 n n n个数字的序列,每次可以选择一个同时大于左右两边相邻的数字,将这个数字与它右边的数字交换,问能否在经过若干次操作后使序列变为升序。 分析: 由于交换只能向后进行&#…...
面试题 10:斐波那契数列)
剑指 Offer(第2版)面试题 10:斐波那契数列
剑指 Offer(第2版)面试题 10:斐波那契数列 剑指 Offer(第2版)面试题 10:斐波那契数列解法1:递归解法2:动态规划解法3:动态规划 - 空间优化 剑指 Offer(第2版&…...

Debian 12 / Ubuntu 22.04 安装 Docker 以及 Docker Compose 教程
Debian 12 / Ubuntu 22.04 安装 Docker 以及 Docker Compose 教程 本文将指导如何在 Debian 12 和 Ubuntu 22.04 下安装 Docker 以及 Docker Compose。 PS:本文同时适用于 Debian 11 以及 Ubuntu 20.04 什么是 Docker? Docker 是一种容器化技术&#x…...

Spark_spark参数配置优先级
总结 : 优先级低-》优先级高 spark-submit 提交的优先级 < scala/java代码中的配置参数 < spark SQL hint spark submit 中提交参数 #!/usr/bin/env bashsource /home/work/batch_job/product/common/common.sh spark_version"/home/work/opt/spark&q…...

ElasticSearch之Search settings
相关参数 indices.query.bool.max_clause_count 本参数当前已失效。 search.max_buckets 本参数用于控制在单个响应中返回的聚合的桶的数量。 默认值为65536。 本参数允许在elasticsearch.yml中配置,配置样例如下: search.max_buckets: 30或者使用Ela…...
二十二、数组(4)
本章概要 随机生成泛型和基本数组 随机生成 我们可以按照 Count.java 的结构创建一个生成随机值的工具: Rand.java import java.util.*; import java.util.function.*;import static com.example.test.ConvertTo.primitive;public interface Rand {int MOD 10_0…...
及删除)
『 MySQL数据库 』CRUD之UD,表的数据更新(修改)及删除
文章目录 🥩 Update (更新/修改) 🦖🥚 修改单行数据的某个字段内的数据 🦕🥚 配合LIMIT分页与ORDER BY 对符合条件的多条数据进行修改 🦕🥚 对整表的某个数据字段进行修改 🦕 &#…...
贪心算法及相关例题
目录 什么是贪心算法? leetcode455题.分发饼干 leetcode376题.摆动序列 leetcode55题.跳跃游戏I leetcode45题.跳跃游戏II leetcode621题.任务调度器 leetcode435题.无重叠空间 leetcode135题.分发糖果 什么是贪心算法? 贪心算法更多的是一种思…...

给企业做公众号运营你都有哪些宝贵经验?
运营企业公众号需要长期的坚持和不断的创新,如何运营好一个企业公众号,使其成为企业与受众互动、传递价值、提升品牌形象的平台,是许多企业所面临的挑战。但只要不断学习,总结经验,就一定能够找到适合自己企业的公众号…...

2023亚太地区数学建模B题思路分析+模型+代码+论文
目录 2023亚太地区数学建模A题思路:开赛后第一时间更新,获取见文末名片 2023亚太地区数学建模B题思路:开赛后第一时间更新,获取见文末名片 2023亚太地区数学建模C题思路:开赛后第一时间更新,获取见文末名…...

Electron+Ts+Vue+Vite桌面应用系列:sqlite增删改查操作篇
文章目录 1️⃣ sqlite应用1.1 sqlite数据结构1.2 初始化数据库1.3 初始化实体类1.4 操作数据类1.5 页面调用 优质资源分享 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418 ElectronTsVueVite桌面应用系列 :这个系列包括了从桌…...
)
c语言编程题经典100例——(36~40例)
1,实现快速排序算法。 下面是用C语言实现快速排序算法的示例代码: #include <stdio.h> void swap(int* a, int* b) { int t *a; *a *b; *b t; } int partition(int arr[], int low, int high) { int pivot arr[high]; int i (low …...

SQL Server实现参数化增删改查Class类
目录 SqlServerDatabase.Class Main调用 SqlServerDatabase.Class using System; using System.Data; using System.Data.SqlClient; class SqlServerDatabase { private readonly string connectionString; public SqlServerDatabase(string connectionString) { …...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

理想二极管控制器:用MOSFET实现毫伏级压降的电源管理方案
1. 理想二极管控制器:告别传统二极管的压降损耗 在电源设计、电池保护、太阳能板并联这些领域里,二极管是个再常见不过的元件。我们用它来防反接、做整流、实现“或”逻辑供电,几乎不假思索。但如果你设计过一个需要处理大电流、低电压的系统…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...