神经网络中BN层简介及位置分析
1. 简介
Batch Normalization是深度学习中常用的技巧,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (Ioffe and Szegedy, 2015) 第一次介绍了这个方法。
这个方法的命名,明明是Standardization, 非要叫Normalization, 把本来就混用、意义不明的两个词更加搅得一团糟。那standardization 和 Normalization有什么区别呢?
一般是下面这样(X是输入数据集):
- normalization(也叫 min-max scaling),一般译做 “归一化”:
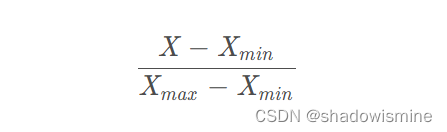
- standardization,一般译做 “标准化”:
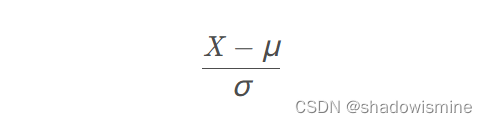
Batch-Norm 是一个网络层,对中间结果作上面说的 standardization 操作。实际上 standardization 也可以叫做 Z-score normalization。所以可以这样理解,standardization 是一种特殊的 normalization。normalization 作为一个 scaling 的大类,包括 min-max scaling,standardization 等。
2. BatchNorm
对输入进行标准化的时候,计算每个特征在样本集合中的均值、方差;然后将每个样本的每个特征减去该特征的均值,并除以它的方差。用数学公式表示,即:

而所谓的BatchNorm, 就是神经网络中间,在一小撮batch样本中进行标准化。具体如下(B: batch size)

注意,BatchNorm作为神经网络的一层,是有两个参数要训练的,分别称为拉伸和偏移参数。可能你会有疑问,既然已经对
作了标准化得到了
,为什么还要用
将它“还原”呢?
实际上,设置这两个参数是为了给神经网络足够的自由度。如果经过训练, 说明神经网络认为,不需要进行批标准化即可使loss function最小化,我们也充分“尊重”它的选择。
3. BN 的特点
- 使用 BatchNorm,我们可以尝试更大的学习率,从而加速收敛,但一般不会改变模型的精度;
- BatchNorm 的效果依赖于 Batch size;一般需要较大的 Batch size(>16)才能有好的效果
- 和 Dropout 一样,BatchNorm 在训练和推理时有不同的行为:训练时,它基于每个 batch 计算均值和方差,因此 batch size 必须足够大才能较好反映统计性质;推理时,BatchNorm 则直接用训练集整体的均值和方差进行标准化。
训练集整体的均值和方差如何得到?——在每个batch的均值和方差计算中,通过移动平均估算得到。

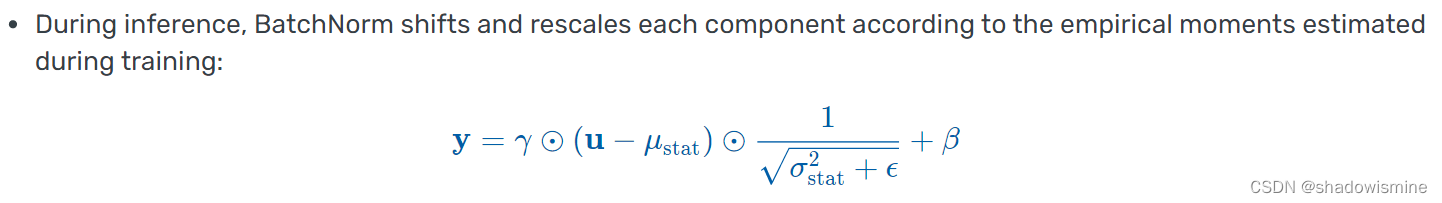
4. BN 的位置
BatchNorm 究竟应该放在哪,现在还存在争议。很多人说应该放在激活函数之前,但也有声音说应该放在激活函数之后。思考一下,两种说法都有道理。举个简单的例子。
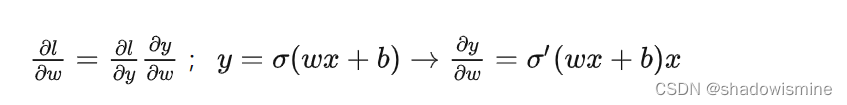
前一种说法是要对 作BatchNorm,这样可以保证
在0附近,
不至于太小;后一种说法 BatchNorm 的作用对象则直接是
,这样可以控制梯度
在合理的范围内,不会因为
的极端取值而波动过大。
但现在看来,前一种声音是占上风的:将 BatchNorm 作用在全连接层和卷积层的输出上,激活函数之前。在全连接网络中,顺序是:线性组合+BatchNorm+Activation
对于全连接层,BatchNorm 作用在特征维上。假设输入矩阵大小是 m×n —— m 等于 batch size,即这个小批量中的样本数, n 表示特征数。我们要在每个特征上计算 m 个样本的均值和方差,也就是对每一列做计算。
在卷积神经网络中,顺序是:卷积层+BatchNorm+Activation+池化+全连接。要注意一点是,如果卷积层有K个卷积核(即K个通道),要对每个通道的输出分别做批标准化,且每个通道都拥有独立的拉伸和偏移参数。
对于卷积层,BatchNorm 作用在通道维上。我们先考虑一个 1×1 的卷积层,通道数为 k 。它其实就等价于神经元个数为 k 的全连接层。图片中每个像素点都由一个 k 维的向量表示,可以看作是像素点的 k 个特征。同一批量各个图片的各个像素点,就是不同的样本,共有 m×p×q 个样本, m,p,q 分别为 batch size、高、宽。
类比全连接层 BatchNorm 作用在特征维上,要在每个通道(即每个特征)上计算 m×p×q 个样本的均值和方差。
设小批量中有m个样本。在单个通道上,假设卷积计算输出的高和宽分别为p和q。我们需要对该通道中m×p×q个元素同时标准化:对这些元素做标准化计算时,我们使用相同的均值和方差,即该通道中m×p×q个元素的均值和方差。——卷积神经网络之Batch Normalization(一)
5. BN的理解与延伸
BN 效果好是因为 BN 的存在会引入 mini-batch 内其他样本的信息,就会导致预测一个独立样本时,其他样本信息相当于正则项,使得 loss 曲面变得更加平滑,更容易找到最优解。相当于一次独立样本预测可以看多个样本,学到的特征泛化性更强,更加 general。
Conv+BN+Relu 是卷积网络的一个常见组合。在模型推理时,BN 层的参数已经固定下来,本质就是一个线性变换。我们可以把 Conv+BN+Relu 进行算子融合,以加速模型推理。
除了BN层,还有GN(Group Normalization)、LN(Layer Normalization、IN(Instance Normalization)这些个标准化方法,每个标注化方法都适用于不同的任务。
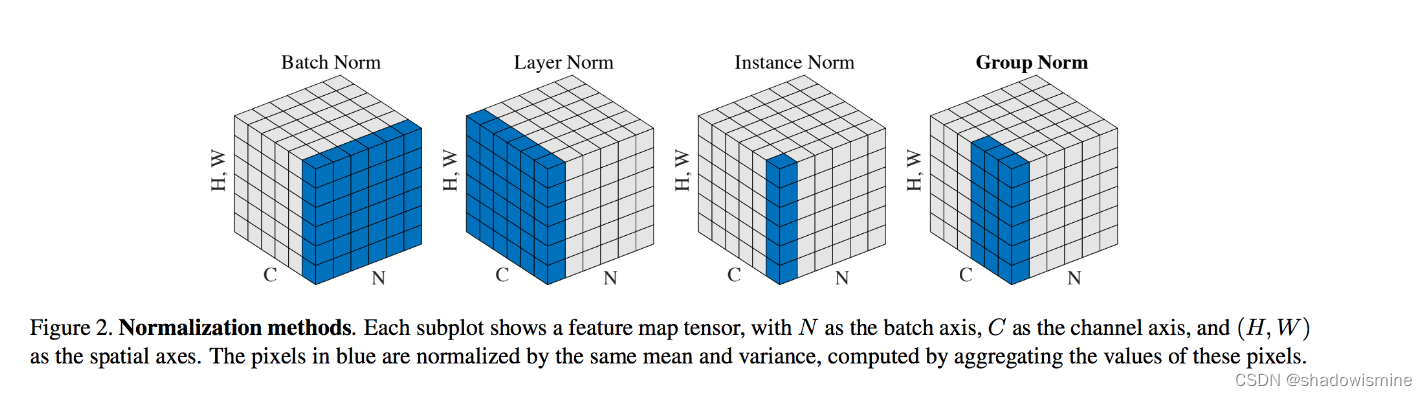
这个图很好地说明了BatchNorm、LayerNorm、InstanceNorm、GroupNorm的区别。N代表batch size;C代表卷积核个数(通道个数);H,W代表卷积结果的高和宽。
BatchNorm: 计算均值和方差时,考虑N * H * W 个元素;对每个通道分别做标准化
LayerNorm:计算均值和方差时,考虑C * H * W 个元素;对batch中的每个instance分别做标准化
InstanceNorm:计算均值和方差时,考虑H * W 个元素;对每个通道、batch中的每个instance分别做标准化
GroupNorm:介于LayerNorm和InstanceNorm二者之间,将C个通道分组,然后进行标准化。
直觉上来讲,GroupNorm把提取到类似特征的不同卷积核分到同一个group中。对这些卷积核进行标准化,确实make sense. 而且GroupNorm摆脱了对batch size的依赖。
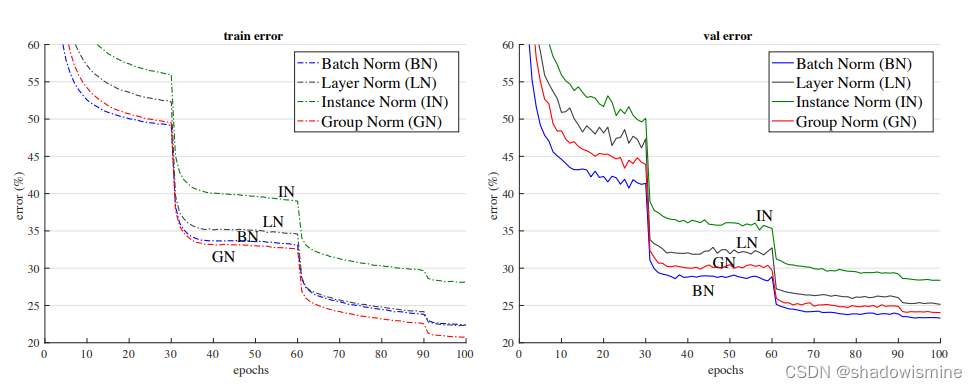
GN在训练集上表现最好,在测试集上稍逊于BN(引自 Group Normalization (Yuxin & Kaiming, 2018))
6. BN vs LN
Transformer模型中用到了LayerNorm,着重对比一下LayerNorm和BatchNorm。
对于一个输入序列 (x1,x2,...,xn) ,每一个 xi 都是 d 维的向量。譬如输入序列是一个句子,每个单词 xi 都用一个 d 维的向量表示。
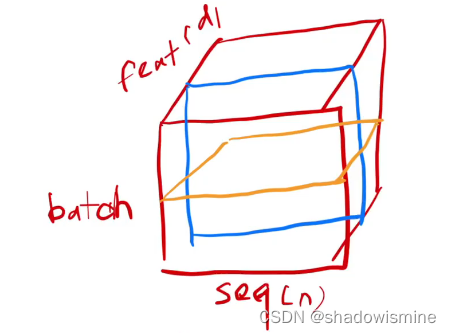
X轴是序列长度(n),Y轴是特征个数(d),Z轴是Batch size
此时BatchNorm是对图中蓝色框作标准化处理,就像我们上面说的——对每个特征分别做标准化;而LayerNorm针对每一个输入序列,对图中黄色框作标准化处理。总结来说,BatchNorm盯住每一个特征;而LayerNorm盯住的是每一个样本。
那么为什么Transformer模型要用LayerNorm而不是BatchNorm呢?
实际上,序列模型的背景下,BatchNorm有一个天然的硬伤,这使得它在所有序列模型中都不吃香:输入序列的长度(n)可能不一致。一般来说,我们会规定一个最长的序列长度,长度不够的序列用0填充。譬如下图这样,Batch中的序列长短不一。
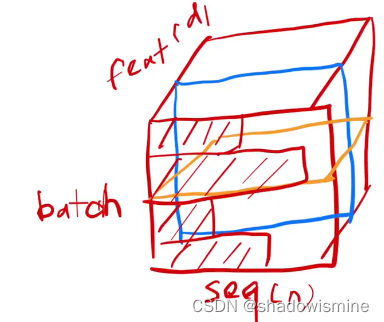
如果用BatchNorm,以一个feature为例,它的标准化有效范围是蓝色的图,其余用0填充;如果是LayerNorm,对于4个序列,它们的标准化有效范围是黄色的图。

直觉上来说,对于BatchNorm的计算方法,当Batch中序列长度差距过大时,均值和方差的波动也会很大。
但这个问题对于LayerNorm来说并不存在,因为它是在每一个序列内部计算均值和方差的。
这样,我们可以直观地理解,为什么BatchNorm对于序列模型并不好用;为什么Transformer要采用LayerNorm
7. BN代码实现
我们翻一翻常见的backbone的结构。可以看到在官方Pytorch的resnet.py的class BasicBlock中,forward时的基本结构是Conv+BN+Relu:
# 省略了一些地方
class BasicBlock(nn.Module):def __init__(self,...) -> None:...self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = norm_layer(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = norm_layer(planes)self.downsample = downsampleself.stride = stridedef forward(self, x: Tensor) -> Tensor:identity = x# 常见的Conv+BN+Reluout = self.conv1(x)out = self.bn1(out)out = self.relu(out)# 又是Conv+BN+reluout = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outresnet作为我们常见的万年青backbone不是没有理由的,效果好速度快方便部署。当然还有很多其他优秀的backbone,这些backbone的内部结构也多为Conv+BN+Relu或者Conv+BN的结构。
参考资料:BatchNorm and its variants - 知乎normalization 和 standardization 到底什么区别?_为什么batch normalization使用standardization而不是normaliz-CSDN博客不论是训练还是部署都会让你踩坑的Batch Normalization - 知乎
相关文章:
神经网络中BN层简介及位置分析
1. 简介 Batch Normalization是深度学习中常用的技巧,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (Ioffe and Szegedy, 2015) 第一次介绍了这个方法。 这个方法的命名,明明是Standardization, 非…...

BGP基础配置
EBGP是AS之间 IBGP是AS内 R1-R2是EBGP,R4-R5是EBGP R2-R3-R4是IBGP 第一步基础配置:IP地址 [r1-GigabitEthernet0/0/0]ip ad 12.0.0.1 24 [r1-LoopBack0]ip ad 1.1.1.1 32 [r2-GigabitEthernet0/0/0]ip ad 12.0.0.2 24 [r2-LoopBack0]ip ad 2.2.2.2 32 [r2-Loop…...

【开题报告】基于深度学习的驾驶员危险行为检测系统
研究的目的、意义及国内外发展概况 研究的目的、意义:我国每年的交通事故绝对数量是一个十分巨大的数字,造成了巨大的死亡人数和经济损失。而造成交通事故的一个很重要原因就是驾驶员的各种危险驾驶操作行为。如果道路驾驶员的驾驶行为能够得到有效识别…...

Linux云服务器打包部署前端Vue项目
1. 打包 在项目包的终端使用命令打包成dist文件。 npm run build2. Linux云服务器上创建文件夹 mkdir /home/www/dist注:dist文件夹不用创建,将打包好的dist.zip放进去,然后解压就行。 3. 安装nginx yum install -y nginx4. 修改配置文件…...

Egg.js中Cookie和Session
Cookie HTTP请求是无状态的,但是在开发时,有些情况是需要知道请求的人是谁的。为了解决这个问题,HTTP协议设计了一个特殊的请求头:Cookie。服务端可以通过响应头(set-cookie)将少量数据响应给客户端&#…...
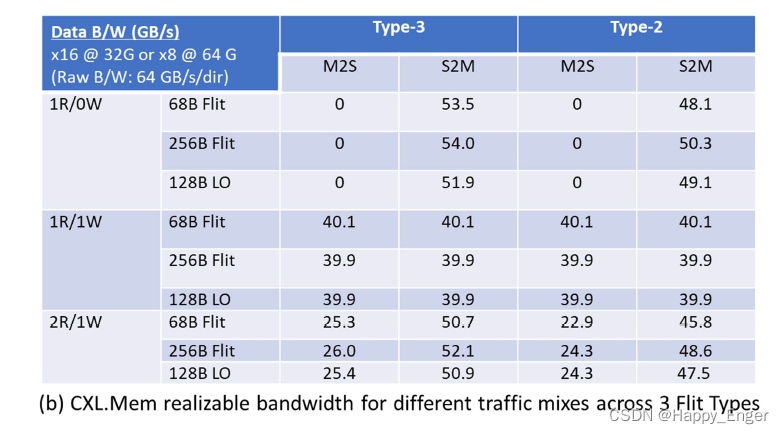
与 PCIe 相比,CXL为何低延迟高带宽?
文章目录 前言1. LatencyPCIE 生产者消费则模型结论Flit 包PCIE/CXL.ioCXL.cace & .mem总结 2. BandWidth常见开销CXL.IO Link efficiencyPCIe Link efficiencyCXL.IO bandwidthCXL.mem/.cache bandwidth 参考 前言 CXL 规范里没有具体描述与PCIe 相比低延时高带宽的原因&…...
Vue 入门指南:从零开始学习 Vue 的基础知识
🥝VUE官方文档 注意: 📒Vue 2 将于 2023 年 12 月 31 日停止维护。详见 Vue 2 延长 LTS。📒Vue 2 中文文档已迁移至 v2.cn.vuejs.org。📒想从 Vue 2 升级?请参考迁移指南。 文章目录 🍁前言&am…...
11.docker的网络-docker0的理解及bridge网桥模式的介绍与实例
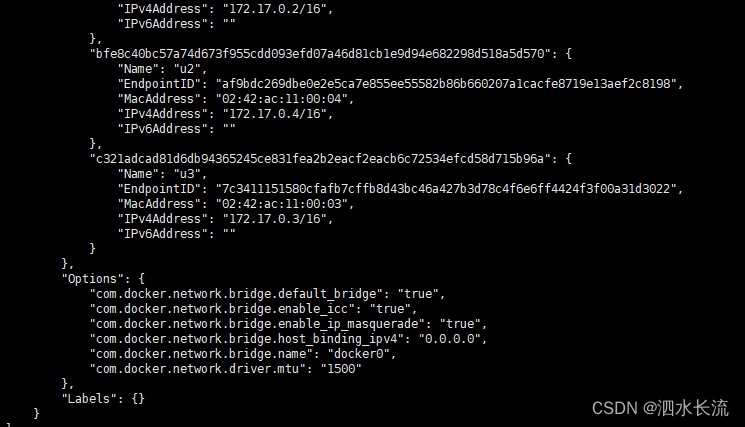
1.docker0的基本理解 安装完docker服务后,我们首先查看一下宿主机的网络配置 ifconfig我们可以看到,docker服务会默认在宿主机上创建一个虚拟网桥docker0,该网桥网络的名字称为docker0。它在内核层连通了其他物理或者虚拟网卡,这…...

新材料制造ERP用哪个好?企业应当如何挑选适用的
有些新材料存在特殊性,并且在制造过程中对车间、设备、工艺、人员等方面提出更高的要求。还有些新材料加工流程复杂,涉及多种材料的请购、出入库、使用和管理等环节,解决各个业务环节无缝衔接问题是很多制造企业面临的管理难题。 新材料制造…...

vr小鼠虚拟解剖实验教学平台减少了受感染风险
家畜解剖实验教学是培养畜牧兽医专业学生实际操作能力的专业教学活动中的核心手段。采取新型教学方式与手段,合理设置实验教学内容,有助于激发学生的操作积极性,促进实践教学的改革。 家畜解剖VR仿真教学是一种借助VR虚拟现实制作和web3d开发…...
【算法萌新闯力扣】:环形链表及环形链表II
力扣题目:环形链表及环形链表II 开篇 今天是备战蓝桥杯的第26天和算法村开营第4天。挑选了链表的黄金关卡与大家分享。 题目一:环形链表 题目链接: 141.环形链表 题目描述 方法一、哈希表 判断是否有环,可以利用哈希表,遍历…...
10.docker的网络network-概述
1.docker的网络模式 docker共有四种网路模式,分别是bridge、host、none和container. 1.1 bridge bridge,也称为虚拟网桥。在bridge模式下,为每个容器分配、配置IP等,并将容器连接到一个docker0。使用–network bridge命令指定,…...

CodeTON Round #7 (Div. 1 + Div. 2)
A.jagged Swaps 题意: 给出一个包含 n n n个数字的序列,每次可以选择一个同时大于左右两边相邻的数字,将这个数字与它右边的数字交换,问能否在经过若干次操作后使序列变为升序。 分析: 由于交换只能向后进行&#…...
面试题 10:斐波那契数列)
剑指 Offer(第2版)面试题 10:斐波那契数列
剑指 Offer(第2版)面试题 10:斐波那契数列 剑指 Offer(第2版)面试题 10:斐波那契数列解法1:递归解法2:动态规划解法3:动态规划 - 空间优化 剑指 Offer(第2版&…...

Debian 12 / Ubuntu 22.04 安装 Docker 以及 Docker Compose 教程
Debian 12 / Ubuntu 22.04 安装 Docker 以及 Docker Compose 教程 本文将指导如何在 Debian 12 和 Ubuntu 22.04 下安装 Docker 以及 Docker Compose。 PS:本文同时适用于 Debian 11 以及 Ubuntu 20.04 什么是 Docker? Docker 是一种容器化技术&#x…...

Spark_spark参数配置优先级
总结 : 优先级低-》优先级高 spark-submit 提交的优先级 < scala/java代码中的配置参数 < spark SQL hint spark submit 中提交参数 #!/usr/bin/env bashsource /home/work/batch_job/product/common/common.sh spark_version"/home/work/opt/spark&q…...

ElasticSearch之Search settings
相关参数 indices.query.bool.max_clause_count 本参数当前已失效。 search.max_buckets 本参数用于控制在单个响应中返回的聚合的桶的数量。 默认值为65536。 本参数允许在elasticsearch.yml中配置,配置样例如下: search.max_buckets: 30或者使用Ela…...
二十二、数组(4)
本章概要 随机生成泛型和基本数组 随机生成 我们可以按照 Count.java 的结构创建一个生成随机值的工具: Rand.java import java.util.*; import java.util.function.*;import static com.example.test.ConvertTo.primitive;public interface Rand {int MOD 10_0…...
及删除)
『 MySQL数据库 』CRUD之UD,表的数据更新(修改)及删除
文章目录 🥩 Update (更新/修改) 🦖🥚 修改单行数据的某个字段内的数据 🦕🥚 配合LIMIT分页与ORDER BY 对符合条件的多条数据进行修改 🦕🥚 对整表的某个数据字段进行修改 🦕 &#…...
贪心算法及相关例题
目录 什么是贪心算法? leetcode455题.分发饼干 leetcode376题.摆动序列 leetcode55题.跳跃游戏I leetcode45题.跳跃游戏II leetcode621题.任务调度器 leetcode435题.无重叠空间 leetcode135题.分发糖果 什么是贪心算法? 贪心算法更多的是一种思…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...

SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析
SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser&…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...
)
【独家首发】国内23家AI语音服务商最新报价数据库(含教育/医疗/金融行业专属折扣码及最小起订量红线)
更多请点击: https://kaifayun.com 第一章:AI语音合成价格与性价比分析 AI语音合成(TTS)服务的定价模式日益多样化,从按字符/音频时长计费到订阅制、API调用包、企业定制方案并存。理解不同服务商的成本结构与实际输出…...