Spark-java版
SparkContext初始化
相关知识
- SparkConf 是
SparkContext的构造参数,储存着Spark相关的配置信息,且必须指定Master(比如Local)和AppName(应用名称),否则会抛出异常; - SparkContext 是程序执行的入口,一个
SparkContext代表一个Application。
初始化过程的主要核心:
- 依据
SparkConf创建一个Spark执行环境SparkEnv; - 创建并初始化
Spark UI,方便用户监控,默认端口为4040; - 设置
Hadoop相关配置及Executor环境变量; - 创建和启动
TaskScheduler,DAGScheduler。
初始化方式:
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master)JavaSparkContext sc=new JavaSparkContext(conf)
程序运行完后需使用sc.stop()关闭SparkContext。
import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.SparkConf; import java.util.Arrays; import java.util.List;public class Edu {public static void main(String[] args) {/********** Begin **********///第一步:设置SparkConfSparkConf conf = new SparkConf().setAppName("educoder").setMaster("local");//第二步:初始化SparkContextJavaSparkContext sc = new JavaSparkContext(conf);/********** End **********/List<String> data = Arrays.asList("hello");JavaRDD<String> r1 = sc.parallelize(data);System.out.print(r1.collect());/********** Begin **********///第三步:关闭SparkContextsc.stop();/********** End **********/} }
集合并行化创建RDD
任务描述
本关任务:计算并输出各个学生的总成绩。
相关知识
为了完成本关任务,你需要掌握:1.集合并行化创建RDD,2.reduceByKey。
集合创建RDD
Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。相当于是,集合中的部分数据会到一个节点上,而另一部分数据会到其他节点上。然后就可以用并行的方式来操作这个分布式数据集合,即RDD。
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);JavaRDD<Integer> rdd = sc.parallelize(list,3);//参数1:Seq集合,必须。参数2:分区数,默认为该Application分配到的资源的CPU核数Integer sum = rdd.reduce((a, b) -> a + b);System.out.print(sum);
输出:6
reduceByKey()
对元素为RDD[K,V]对的RDD中Key相同的元素的Value进行聚合。
List<Tuple2<String,Integer>> list = Arrays.asList(new Tuple2("hive",2),new Tuple2("spark",4),new Tuple2("hive",1));
JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);
List<Tuple2<String, Integer>> result = listRDD.reduceByKey((x, y) -> x + y).collect();输出: (spark,4) (hive,3)
collect() :以数组的形式返回RDD中的所有元素,收集分布在各个worker的数据到driver节点。
编程要求
根据提示,在右侧编辑器begin-end处补充代码,计算并输出各个学生的总成绩。
("bj",88):bj指学生姓名,88指学生成绩。
测试说明
平台会对你编写的代码进行测试:
预期输出: (bj,254) (sh,221) (gz,285)
package step1;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.*;
public class JStudent {public static void main(String[] args) {SparkConf conf = new SparkConf().setMaster("local").setAppName("JStudent");JavaSparkContext sc = new JavaSparkContext(conf);List<Tuple2<String,Integer>> list = Arrays.asList(new Tuple2("bj",88),new Tuple2("sh",67),new Tuple2("gz",92),new Tuple2("bj",94),new Tuple2("sh",85),new Tuple2("gz",95),new Tuple2("bj",72),new Tuple2("sh",69),new Tuple2("gz",98));//第一步:创建RDDJavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);//第二步:把相同key的进行聚合JavaPairRDD<String, Integer> result = listRDD.reduceByKey((x, y) -> x + y);//第三步:收集List<Tuple2<String, Integer>> collect = result.collect();//第四步:输出for (Tuple2 c:collect){System.out.println(c);}sc.stop();}
}读取外部数据集创建RDD
任务描述
本关任务:读取文本文件,按照文本中数据,输出老师及其出现次数。
相关知识
为了完成本关任务,你需要掌握:1.读取文件创建RDD,2.本关所需算子。
读取文件
textFile()
JavaRDD<String> rdd = sc.textFile("/home/student.txt")//文件路径算子
(1)mapToPair:此函数会对一个RDD中的每个元素调用f函数,其中原来RDD中的每一个元素都是T类型的,调用f函数后会进行一定的操作把每个元素都转换成一个<K2,V2>类型的对象
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
JavaRDD<Integer> rdd = sc.parallelize(list);
JavaPairRDD<Integer,String> result = rdd.mapToPair(x -> new Tuple2(x,1)输出:(1,1)(2,1)(3,1)
(2) reduceByKey() :对元素为RDD[K,V]对的RDD中Key相同的元素的Value进行聚合
List<Tuple2<String,Integer>> list = Arrays.asList(new Tuple2("hive",2),new Tuple2("spark",4),new Tuple2("hive",1));
JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);
List<Tuple2<String, Integer>> result = listRDD.reduceByKey((x, y) -> x + y).collect();输出: (spark,5) (hive,3)
编程要求
根据提示,在右侧编辑器begin-end处补充代码,输出老师姓名和出现次数。
- 输入文件样例:
bigdata,laozhang bigdata,laoduan javaee,xiaoxu
bigdata指科目,laozhang指老师名称。
预期输出: (laoliu,1) (laoli,3) (laoduan,5) (laozhang,2) (laozhao,15) (laoyang,9) (xiaoxu,4)
package step2;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;
import java.util.List;public class JTeachers {public static void main(String[] args) {SparkConf conf = new SparkConf().setMaster("local").setAppName("JTeachers");JavaSparkContext sc = new JavaSparkContext(conf);String dataFile = "file:///root/step2_files";//第一步:以外部文件方式创建RDDJavaRDD<String> teaRDD = sc.textFile(dataFile);//String name = line.split(",")[1];//第二步:将文件中每行的数据切分,得到自己想要的返回值Integer one = 1;JavaPairRDD<String, Integer> teacher = teaRDD.mapToPair(line ->{String names = line.split(",")[1];Tuple2<String, Integer> t2 = new Tuple2<>(names, one);return t2;});//第三步:将相同的key进行聚合JavaPairRDD<String, Integer> tea = teacher.reduceByKey((x, y) -> x + y);//第四步:将结果收集起来List<Tuple2<String, Integer>> result = tea.collect();//第五步:输出for (Tuple2 t:result){System.out.println(t);}sc.stop();}
}map算子完成转换操作
相关知识
为了完成本关任务,你需要掌握:如何使用map算子。
map
将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素。

图中每个方框表示一个RDD分区,左侧的分区经过自定义函数f:T->U映射为右侧的新RDD分区。但是,实际只有等到Action算子触发后,这个f函数才会和其他函数在一个Stage中对数据进行运算。
map 案例
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
System.out.println("init:" + list);
JavaRDD<Integer> rdd = sc.parallelize(list);
JavaRDD<Integer> map = rdd.map(x -> x * 2);
System.out.println("result :" + map.collect());输出:
init :[1, 2, 3, 4, 5, 6] result :[2, 4, 6, 8, 10, 12]
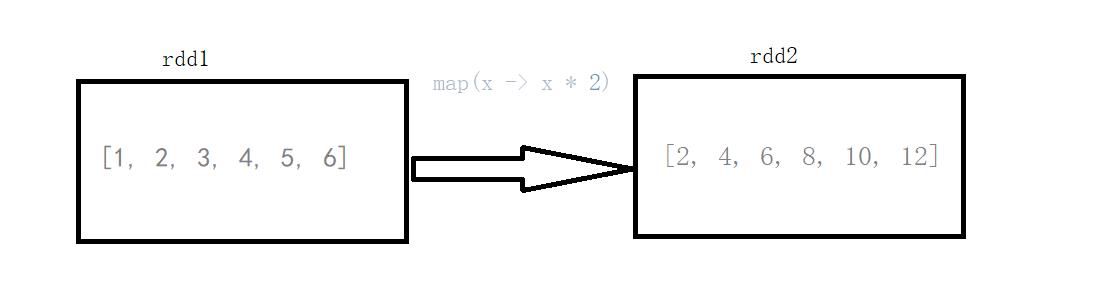
说明:rdd1的元素(1 , 2 , 3 , 4 , 5 , 6)经过map算子(x -> x*2)转换成了rdd2(2 , 4 , 6 , 8 , 10)
编程要求
根据提示,在右侧编辑器begin-end处补充代码,完成以下需求:
需求1:使用map算子,将rdd的数据(1, 2, 3, 4, 5)按照下面的规则进行转换操作,规则如下:
-
偶数转换成该数的平方;
-
奇数转换成该数的立方。
需求2:使用map算子,将rdd的数据("dog", "salmon", "salmon", "rat", "elephant")按照下面的规则进行转换操作,规则如下:
- 将字符串与该字符串的长度组合成一个元组,例如
dog --> (dog,3)salmon --> (salmon,6)package net.educoder; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2; import java.util.Arrays; import java.util.List; public class Step1 {private static SparkConf conf;private static JavaSparkContext sc;static {conf = new SparkConf().setAppName("Step1").setMaster("local");sc = new JavaSparkContext(conf);}/*** 返回JavaRDD** @return JavaRDD*/public static JavaRDD<Integer> MapRdd() {List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);JavaRDD<Integer> rdd = sc.parallelize(list);/**** 需求:使用map算子,将rdd的数据进行转换操作* 规则如下:* 偶数转换成该数的平方* 奇数转换成该数的立方**//********** begin ***********/JavaRDD<Integer> map = rdd.map(num -> {if (num % 2 == 0) {return num * num;} else {return num * num * num;}});return map;/********** end ***********/}/*** 返回JavaRDD** @return JavaRDD*/public static JavaRDD<Tuple2> MapRdd2() {List<String> list = Arrays.asList("dog", "salmon", "salmon", "rat", "elephant");JavaRDD<String> rdd = sc.parallelize(list);/**** 需求:使用map算子,将rdd的数据进行转换操作* 规则如下:* 将字符串与该字符串的长度组合成一个元组,例如:dog --> (dog,3),salmon --> (salmon,6)**//********** begin ***********/JavaRDD<Tuple2> map = rdd.map(str -> {int i = str.length();return new Tuple2(str, i);});return map;/********** end ***********/} }
相关文章:
Spark-java版
SparkContext初始化 相关知识 SparkConf 是SparkContext的构造参数,储存着Spark相关的配置信息,且必须指定Master(比如Local)和AppName(应用名称),否则会抛出异常;SparkContext 是程序执行的入口…...
RabbitMQ消息模型之Work Queues
Work Queues Work Queues,也被称为(Task Queues),任务模型,也是官网给出的第二个模型,使用的交换机类型是直连direct,也是默认的交换机类型。当消息处理比较耗时的时候,可能生产消息…...
vue3+ts 实现时间间隔选择器
需求背景解决效果视频效果balancedTimeElement.vue 需求背景 实现一个分片的时间间隔选择器,需要把显示时间段显示成图表,涉及一下集中数据转换 [“02:30-05:30”,“07:30-10:30”,“14:30-17:30”]‘[(2,5),(7,10),(14,17)]’[4, 5, 6, 7, 8, 9, 10, …...

PTA 魔法优惠券
7-83 魔法优惠券 分数 25 全屏浏览题目 作者 陈越 单位 浙江大学 在火星上有个魔法商店,提供魔法优惠券。每个优惠劵上印有一个整数面值K,表示若你在购买某商品时使用这张优惠劵,可以得到K倍该商品价值的回报!该商店还免费赠送…...
P8A110-A120经典赛题
Web应用程序SQL Inject安全攻防 任务环境说明: 服务器场景:WebServ2003(用户名:administrator;密码:空)服务器场景操作系统:Microsoft Windows2003 Server 服务器场景安装服务/工…...
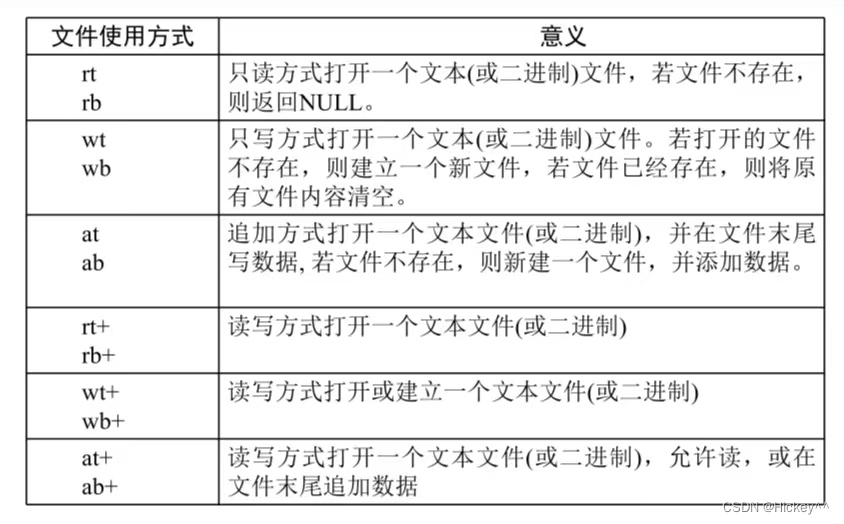
文件基础知识
计算机中的流:在C语言中将通过输入/输出设备(键盘、内存、显示器、网络等)之间的数据传输抽象表述为“流”。 1、文本流和二进制流 在文本流中输入输出的数据是一系列的字符,可以被修改在二进制流中输入输出数据是一系列字节&am…...

二叉树OJ题之二
今天我们一起来看一道判断一棵树是否为对称二叉树的题,力扣101题, https://leetcode.cn/problems/symmetric-tree/ 我们首先先来分析这道题,要判断这道题是否对称,我们首先需要判断的是这颗树根节点的左右子树是否对称࿰…...
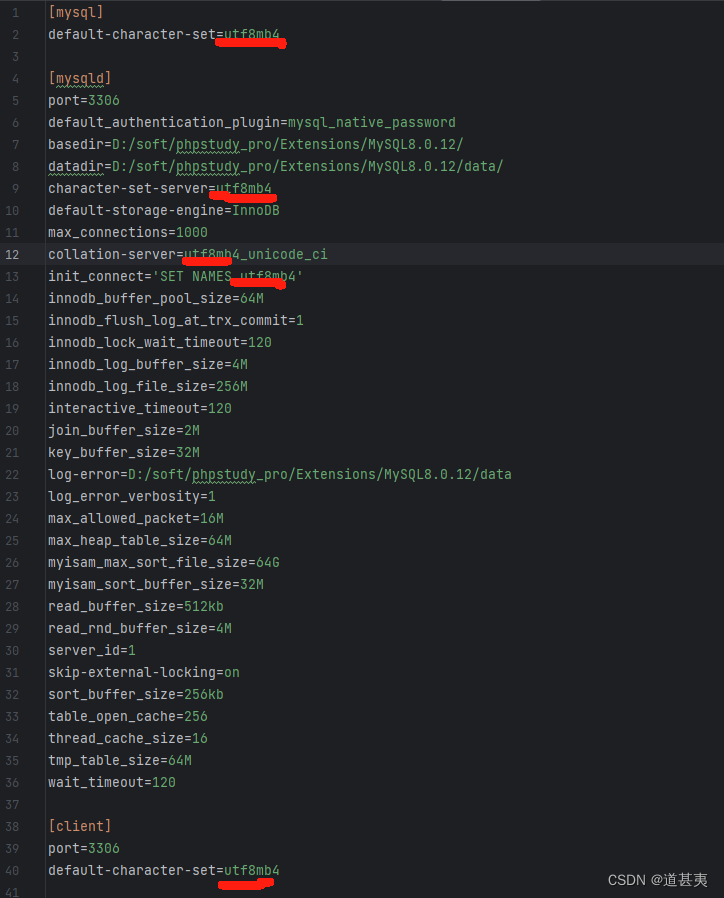
MySql表中添加emoji表情
共五处需要修改。 语句执行修改: ALTER TABLE xxxxx CONVERT TO CHARACTER SET utf8mb4;...

【新手解答1】深入探索 C 语言:变量名、形参 + 主调函数、被调函数 + 类和对象 + 源文件(.c 文件)、头文件(.h 文件)+ 库
C语言的相关问题解答 写在最前面目录 问题1变量名与变量的关系与区别变量和数据类型形参(形式参数)的概念 问题2解析:主调函数和被调函数延伸解析:主调函数对于多文件程序的理解总结 问题3类和对象变量和数据类型变量是否为抽象的…...
2023最新的软件测试热点面试题(答案+解析)
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...
NCo3.1(08) - Nco3 服务器端编程
本篇博文不再重复ABAP调用外部服务器的基础,只介绍 NCo3 开发的过程和要点。需要了解相关知识点的小伙伴们自行参考: SAP接口编程 之JCo3.0系列(06) - Jco服务器端编程 PyRFC 服务器端编程要点 创建项目 新建一个 Console 项目,选择 .Net …...

【代码随想录】算法训练计划36
贪心 1、435. 无重叠区间 题目: 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。 思路: 贪心,重叠个数,和射气球一样,重叠区间…...

Python (十五) 面向对象之多继承问题
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...
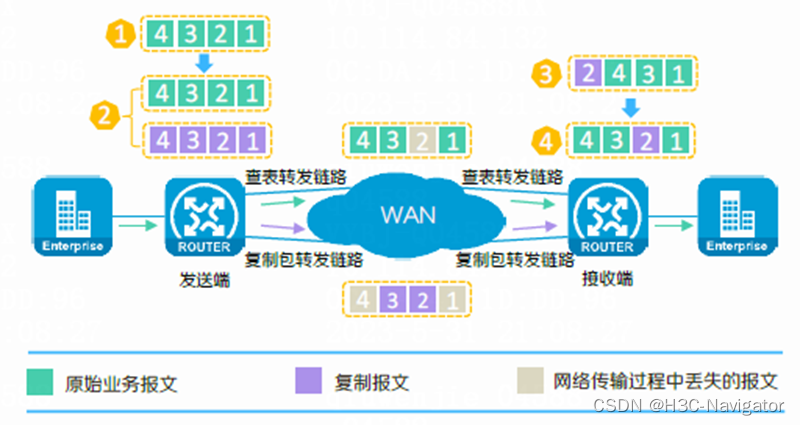
广域网加速技术
摘要: 随着企业数字化转型快速发展,越来越多企业将IT系统、应用和服务部署到云上,以实现更高效、灵活的管理和使用。这就对广域网提出了更高的要求,而广域网线路往往存在带宽费用昂贵、服务质量不可靠等问题。为了改善用户体验&am…...

构建智能医患沟通:陪诊小程序开发实战
在医疗科技的浪潮中,陪诊小程序的开发成为改善医患沟通的创新途径之一。本文将介绍如何使用Node.js和Express框架构建一个简单而强大的陪诊小程序,实现患者导诊和医生咨询功能。 1. 安装Node.js和Express 首先确保已安装Node.js,然后使用以…...

插入区间[中等]
优质博文:IT-BLOG-CN 一、题目 给你一个无重叠的 ,按照区间起始端点排序的区间列表。在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。 示例 1&#x…...
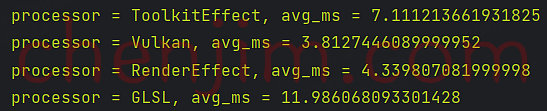
Android Bitmap 模糊效果实现 (二)
文章目录 Android Bitmap 模糊效果实现 (二)使用 Vukan 模糊使用 RenderEffect 模糊使用 GLSL 模糊RS、Vukan、RenderEffect、GLSL 效率对比 Android Bitmap 模糊效果实现 (二) 本文首发地址 https://blog.csdn.net/CSqingchen/article/details/134656140 最新更新地址 https:/…...

初识Java 18-4 泛型
目录 泛型存在的问题 在泛型中使用基本类型 实现参数化接口 类型转换和警告 无法实现的重载 基类会劫持接口 自限定类型 奇异递归类型 自限定 自限定提供的参数协变性 本笔记参考自: 《On Java 中文版》 泛型存在的问题 接下来讨论的,是在泛型…...

家政保洁预约小程序app开发特点有哪些?
家政预约服务小程序APP开发的特点介绍; 1. 低成本:用户通过手机APP下单,省去了中介费用,降低了雇主的雇佣成本。 2. 高收入:家政服务人员通过手机APP接单,省去了中介费用,从而提高了服务人员的…...

【JavaEE初阶】 HTTP响应报文
文章目录 🌲序言🎍200 OK🍀404 Not Found🎄403 Forbidden🌴405 Method Not Allowed🎋500 Internal Server Error🌳504 Gateway Timeout🌲302 Move temporarily🎍301 Move…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...

NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制
NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制 副标题: 从预分配+Attention Mask到三层软件栈,完整解析NPU推理架构 痛点:为什么NPU跑LLM这么难? LLM的生成机制和NPU的硬件特性存在根本冲突: LLM特性 NPU特性 冲突点 逐token生成 固定shape执行 KV Cache动态增长 动…...