SparkRDD及算子-python版
RDD相关知识
RDD介绍
RDD 是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置感知性调度和可伸缩性。 在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用 RDD操作进行求值。
RDD结构图

RDD具有五大特性
-
一组分片(
Partition),即数据集的基本组成单位(RDD是由一系列的partition组成的)。将数据加载为RDD时,一般会遵循数据的本地性(一般一个HDFS里的block会加载为一个partition)。 -
RDD之间的依赖关系。依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失会进行重算。 -
由一个函数计算每一个分片。
Spark中的RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 -
(可选)如果
RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区。 -
(可选)
RDD提供一系列最佳的计算位置,即数据的本地性。
RDD之间的依赖关系
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
窄依赖:父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的,也可以理解为没有触发shuffle。
宽依赖:父RDD与子RDD partition之间的关系是一对多。 父RDD的一个分区的数据去到子RDD的不同分区里面。也可以理解为触发了shuffle。
特别说明:对于join操作有两种情况,如果join操作的使用每个partition仅仅和已知的Partition进行join,此时的join操作就是窄依赖;其他情况的join操作就是宽依赖。

RDD创建
-
从
Hadoop文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、Cassandra、HBase)输入(例如HDFS)创建。 -
通过集合进行创建。

算子
算子可以分为Transformation 转换算子和Action 行动算子。 RDD是懒执行的,如果没有行动操作出现,所有的转换操作都不会执行。
RDD直观图,如下:

RDD 的 五大特性
-
一组分片(
Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。 -
一个计算每个分区的函数。
Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 -
RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。 -
一个
Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 -
一个列表,存储存取每个
Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
相关API介绍
SparkContext创建;
sc = SparkContext("local", "Simple App")
说明:"local" 是指让Spark程序本地运行,"Simple App" 是指Spark程序的名称,这个名称可以任意(为了直观明了的查看,最好设置有意义的名称)。
- 集合并行化创建
RDD;
data = [1,2,3,4]rdd = sc.parallelize(data)
collect算子:在驱动程序中将数据集的所有元素作为数组返回(注意数据集不能过大);
rdd.collect()
- 停止
SparkContext。
sc.stop()
# -*- coding: UTF-8 -*-
from pyspark import SparkContextif __name__ == "__main__":#********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2.创建一个1到8的列表Listdata = [1, 2, 3, 4, 5, 6, 7, 8]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(data)# 4.使用 rdd.collect() 收集 rdd 的内容。 rdd.collect() 是 Spark Action 算子,在后续内容中将会详细说明,主要作用是:收集 rdd 的数据内容result = rdd.collect()# 5.打印 rdd 的内容print(result)# 6.停止 SparkContextsc.stop()#********** End **********#读取外部数据集创建RDD
编写读取本地文件创建Spark RDD的程序。
相关知识
为了完成本关任务,你需要掌握:1.如何读取本地文件系统中的文件来创建Spark RDD。
textFile 介绍
PySpark可以从Hadoop支持的任何存储源创建分布式数据集,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3 等。Spark支持文本文件,SequenceFiles和任何其他Hadoop InputFormat。
文本文件RDD可以使用创建SparkContex的textFile方法。此方法需要一个 URI的文件(本地路径的机器上,或一个hdfs://,s3a:// 等 URI),并读取其作为行的集合。这是一个示例调用:
distFile = sc.textFile("data.txt")# -*- coding: UTF-8 -*- from pyspark import SparkContextif __name__ == '__main__':#********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 文本文件 RDD 可以使用创建 SparkContext 的t extFile 方法。 #此方法需要一个 URI的 文件(本地路径的机器上,或一个hdfs://,s3a://等URI), #并读取其作为行的集合# 2.读取本地文件,URI为:/root/wordcount.txtrdd = sc.textFile("/root/wordcount.txt")# 3.使用 rdd.collect() 收集 rdd 的内容。 #rdd.collect() 是 Spark Action 算子,在后续内容中将会详细说明,主要作用是:收集 rdd 的数据内容result = rdd.collect()# 4.打印 rdd 的内容print(result)# 5.停止 SparkContextsc.stop()#********** End **********#
map 算子
本关任务:使用Spark的 map 算子按照相关需求完成转换操作。
相关知识
为了完成本关任务,你需要掌握:如何使用map算子。
map
将原来RDD的每个数据项通过map中的用户自定义函数 f 映射转变为一个新的元素。
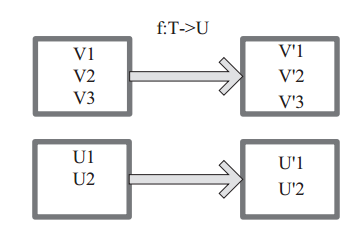
图中每个方框表示一个RDD 分区,左侧的分区经过自定义函数 f:T->U 映射为右侧的新 RDD 分区。但是,实际只有等到 Action 算子触发后,这个 f 函数才会和其他函数在一个 Stage 中对数据进行运算。
map 案例
-
sc = SparkContext("local", "Simple App") data = [1,2,3,4,5,6] rdd = sc.parallelize(data) print(rdd.collect()) rdd_map = rdd.map(lambda x: x * 2) print(rdd_map.collect())
输出:
[1, 2, 3, 4, 5, 6] [2, 4, 6, 8, 10, 12]
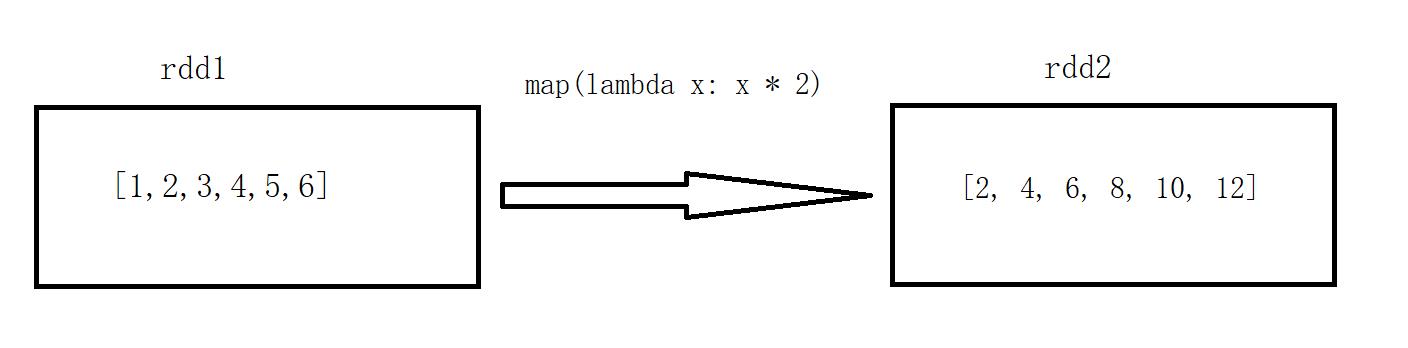
说明:rdd1 的元素( 1 , 2 , 3 , 4 , 5 , 6 )经过 map 算子( x -> x*2 )转换成了 rdd2 ( 2 , 4 , 6 , 8 , 10 )。
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,具体任务如下:
需求:使用 map 算子,将rdd的数据 (1, 2, 3, 4, 5) 按照下面的规则进行转换操作,规则如下:
- 偶数转换成该数的平方;
- 奇数转换成该数的立方。
# -*- coding: UTF-8 -*-
from pyspark import SparkContextif __name__ == "__main__":#********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2.创建一个1到5的列表Listdata = [1, 2, 3, 4, 5]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(data)# 4.使用rdd.collect() 收集 rdd 的元素。print(rdd.collect())"""使用 map 算子,将 rdd 的数据 (1, 2, 3, 4, 5) 按照下面的规则进行转换操作,规则如下:需求:偶数转换成该数的平方奇数转换成该数的立方"""# 5.使用 map 算子完成以上需求rdd_map = rdd.map(lambda x: x * x if x % 2 == 0 else x * x * x)# 6.使用rdd.collect() 收集完成 map 转换的元素print(rdd_map.collect())# 7.停止 SparkContextsc.stop()#********** End **********#mapPartitions算子
mapPartitions
mapPartitions函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭 代器对整个分区的元素进行操作。

图中每个方框表示一个RDD分区,左侧的分区经过自定义函数 f:T->U 映射为右侧的新RDD分区。
mapPartitions 与 map
map:遍历算子,可以遍历RDD中每一个元素,遍历的单位是每条记录。
mapPartitions:遍历算子,可以改变RDD格式,会提高RDD并行度,遍历单位是Partition,也就是在遍历之前它会将一个Partition的数据加载到内存中。
那么问题来了,用上面的两个算子遍历一个RDD谁的效率高? mapPartitions算子效率高。
mapPartitions 案例
-
def f(iterator): list = [] for x in iterator: list.append(x*2) return listif __name__ == "__main__": sc = SparkContext("local", "Simple App") data = [1,2,3,4,5,6] rdd = sc.parallelize(data) print(rdd.collect()) partitions = rdd.mapPartitions(f) print(partitions.collect())
输出:
[1, 2, 3, 4, 5, 6]
[2, 4, 6, 8, 10, 12]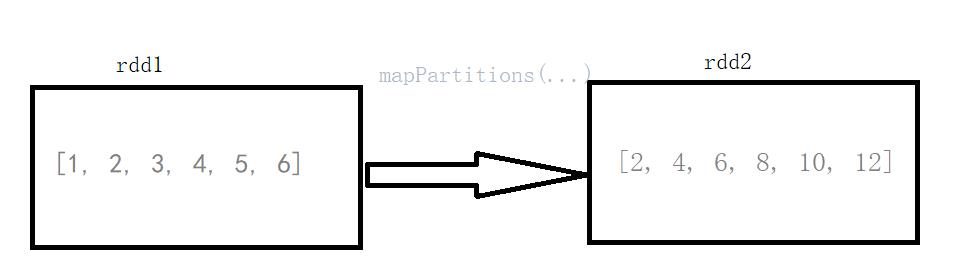
mapPartitions():传入的参数是rdd的 iterator(元素迭代器),返回也是一个iterator(迭代器)。
# -*- coding: UTF-8 -*-
from pyspark import SparkContext#********** Begin **********#
def f(iterator):list = []for x in iterator:list.append((x, len(x)))return list#********** End **********#
if __name__ == "__main__":#********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2. 一个内容为("dog", "salmon", "salmon", "rat", "elephant")的列表Listdata = ["dog", "salmon", "salmon", "rat", "elephant"]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(data)# 4.使用rdd.collect() 收集 rdd 的元素。print(rdd.collect())"""使用 mapPartitions 算子,将 rdd 的数据 ("dog", "salmon", "salmon", "rat", "elephant") 按照下面的规则进行转换操作,规则如下:需求:将字符串与该字符串的长度组合成一个元组,例如:dog --> (dog,3)salmon --> (salmon,6)"""# 5.使用 mapPartitions 算子完成以上需求partitions = rdd.mapPartitions(f)# 6.使用rdd.collect() 收集完成 mapPartitions 转换的元素print(partitions.collect())# 7.停止 SparkContextsc.stop()#********** End **********#filter算子。
filter
filter 函数功能是对元素进行过滤,对每个元素应用f函数,返 回值为 true的元素在RDD中保留,返回值为false的元素将被过滤掉。内部实现相当于生成。
FilteredRDD(this,sc.clean(f))
下面代码为函数的本质实现:
-
def filter(self, f): """ Return a new RDD containing only the elements that satisfy a predicate.>>> rdd = sc.parallelize([1, 2, 3, 4, 5]) >>> rdd.filter(lambda x: x % 2 == 0).collect() [2, 4] """ def func(iterator): return filter(fail_on_stopiteration(f), iterator) return self.mapPartitions(func, True)

上图中每个方框代表一个 RDD 分区, T 可以是任意的类型。通过用户自定义的过滤函数 f,对每个数据项操作,将满足条件、返回结果为 true 的数据项保留。例如,过滤掉 V2 和 V3 保留了 V1,为区分命名为 V’1。
filter 案例
-
sc = SparkContext("local", "Simple App") data = [1,2,3,4,5,6] rdd = sc.parallelize(data) print(rdd.collect()) rdd_filter = rdd.filter(lambda x: x>2) print(rdd_filter.collect())
输出:
[1, 2, 3, 4, 5, 6][3, 4, 5, 6]

说明:rdd1( [ 1 , 2 , 3 , 4 , 5 , 6 ] ) 经过 filter 算子转换成 rdd2( [ 3 ,4 , 5 , 6 ] )。
使用 filter 算子,将 rdd 中的数据 (1, 2, 3, 4, 5, 6, 7, 8) 按照以下规则进行过滤,规则如下:
- 过滤掉
rdd中的所有奇数。
# -*- coding: UTF-8 -*-
from pyspark import SparkContextif __name__ == "__main__":#********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2.创建一个1到8的列表Listdata = [1, 2, 3, 4, 5, 6, 7, 8]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(data)# 4.使用rdd.collect() 收集 rdd 的元素。print(rdd.collect())"""使用 filter 算子,将 rdd 的数据 (1, 2, 3, 4, 5, 6, 7, 8) 按照下面的规则进行转换操作,规则如下:需求:过滤掉rdd中的奇数"""# 5.使用 filter 算子完成以上需求rdd_filter = rdd.filter(lambda x: x % 2 == 0)# 6.使用rdd.collect() 收集完成 filter 转换的元素print(rdd_filter.collect())# 7.停止 SparkContextsc.stop()#********** End **********#flatMap算子
flatMap
将原来RDD中的每个元素通过函数f转换为新的元素,并将生成的RDD中每个集合的元素合并为一个集合,内部创建:
FlatMappedRDD(this,sc.clean(f))
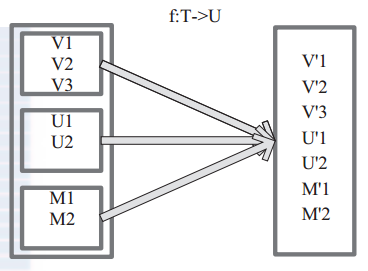
上图表示RDD的一个分区,进行flatMap函数操作,flatMap中传入的函数为f:T->U,T和U可以是任意的数据类型。将分区中的数据通过用户自定义函数f转换为新的数据。外部大方框可以认为是一个RDD分区,小方框代表一个集合。V1、V2、V3在一个集合作为RDD的一个数据项,可能存储为数组或其他容器,转换为V’1、V’2、V’3后,将原来的数组或容器结合拆散,拆散的数据形成RDD中的数据项。
flatMap 案例
sc = SparkContext("local", "Simple App")
data = [["m"], ["a", "n"]]
rdd = sc.parallelize(data)
print(rdd.collect())
flat_map = rdd.flatMap(lambda x: x)
print(flat_map.collect())输出:
[['m'], ['a', 'n']]['m', 'a', 'n']

flatMap:将两个集合转换成一个集合
需求:使用 flatMap 算子,将rdd的数据 ([1, 2, 3], [4, 5, 6], [7, 8, 9]) 按照下面的规则进行转换操作,规则如下:
- 合并
RDD的元素,例如:([1,2,3],[4,5,6]) --> (1,2,3,4,5,6)([2,3],[4,5],[6]) --> (1,2,3,4,5,6)from pyspark import SparkContextif __name__ == "__main__":#********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2.创建一个[[1, 2, 3], [4, 5, 6], [7, 8, 9]] 的列表Listlist = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(list)# 4.使用rdd.collect() 收集 rdd 的元素。print(rdd.collect()) """使用 flatMap 算子,将 rdd 的数据 ([1, 2, 3], [4, 5, 6], [7, 8, 9]) 按照下面的规则进行转换操作,规则如下:需求:合并RDD的元素,例如:([1,2,3],[4,5,6]) --> (1,2,3,4,5,6)([2,3],[4,5],[6]) --> (1,2,3,4,5,6)"""# 5.使用 filter 算子完成以上需求flat_map = rdd.flatMap(lambda x: x)# 6.使用rdd.collect() 收集完成 filter 转换的元素print(flat_map.collect())# 7.停止 SparkContextsc.stop()#********** End **********#distinct算子distinct
distinct将RDD中的元素进行去重操作。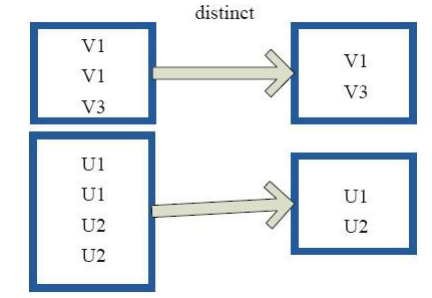
上图中的每个方框代表一个
RDD分区,通过distinct函数,将数据去重。 例如,重复数据V1、V1去重后只保留一份V1。distinct 案例
sc = SparkContext("local", "Simple App") data = ["python", "python", "python", "java", "java"] rdd = sc.parallelize(data) print(rdd.collect()) distinct = rdd.distinct()-
输出
['python', 'python', 'python', 'java', 'java'] ['python', 'java'] -

print(distinct.collect())sortByKey算子sortByKey
-
def sortByKey(self, ascending=True, numPartitions=None, keyfunc=lambda x: x): if numPartitions is None: numPartitions = self._defaultReducePartitions()memory = self._memory_limit() serializer = self._jrdd_deserializerdef sortPartition(iterator): sort = ExternalSorter(memory * 0.9, serializer).sorted return iter(sort(iterator, key=lambda kv: keyfunc(kv[0]), reverse=(not ascending)))if numPartitions == 1: if self.getNumPartitions() > 1: self = self.coalesce(1) return self.mapPartitions(sortPartition, True)# first compute the boundary of each part via sampling: we want to partition # the key-space into bins such that the bins have roughly the same # number of (key, value) pairs falling into them rddSize = self.count() if not rddSize: return self # empty RDD maxSampleSize = numPartitions * 20.0 # constant from Spark's RangePartitioner f\fraction = min(maxSampleSize / max(rddSize, 1), 1.0) samples = self.sample(False, f\fraction, 1).map(lambda kv: kv[0]).collect() samples = sorted(samples, key=keyfunc)# we have numPartitions many parts but one of the them has # an implicit boundary bounds = [samples[int(len(samples) * (i + 1) / numPartitions)] for i in range(0, numPartitions - 1)]def rangePartitioner(k): p = bisect.bisect_left(bounds, keyfunc(k)) if ascending: return p else: return numPartitions - 1 - preturn self.partitionBy(numPartitions, rangePartitioner).mapPartitions(sortPartition, True) -
说明:
ascending参数是指排序(升序还是降序),默认是升序。numPartitions参数是重新分区,默认与上一个RDD保持一致。keyfunc参数是排序规则。sortByKey 案例
sc = SparkContext("local", "Simple App")data = [("a",1),("a",2),("c",1),("b",1)]rdd = sc.parallelize(data)key = rdd.sortByKey()print(key.collect())-
输出:
-
[('a', 1), ('a', 2), ('b', 1), ('c', 1)] -

需求:使用 sortBy 算子,将 rdd 中的数据进行排序(升序)。
from pyspark import SparkContextif __name__ == "__main__":# ********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2.创建一个内容为[('B',1),('A',2),('C',3)]的列表ListList = [('B',1),('A',2),('C',3)]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(List)# 4.使用rdd.collect() 收集 rdd 的元素print(rdd.collect())"""使用 sortByKey 算子,将 rdd 的数据 ('B', 1), ('A', 2), ('C', 3) 按照下面的规则进行转换操作,规则如下:需求:元素排序,例如:[(3,3),(2,2),(1,1)] --> [(1,1),(2,2),(3,3)]"""# 5.使用 sortByKey 算子完成以上需求key = rdd.sortByKey()# 6.使用rdd.collect() 收集完成 sortByKey 转换的元素print(key.collect())# 7.停止 SparkContextsc.stop()# ********** End **********#mapValues 算子
mapValues
mapValues :针对(Key, Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理。

上图中的方框代表 RDD 分区。 a=>a+2 代表对 (V1,1) 这样的 Key Value 数据对,数据只对 Value 中的 1 进行加 2 操作,返回结果为 3。
mapValues 案例
-
sc = SparkContext("local", "Simple App") data = [("a",1),("a",2),("b",1)] rdd = sc.parallelize(data) values = rdd.mapValues(lambda x: x + 2) print(values.collect())
输出:
-
[('a', 3), ('a', 4), ('b', 3)]

需求:使用mapValues算子,将rdd的数据 ("1", 1), ("2", 2), ("3", 3), ("4", 4), ("5", 5) 按照下面的规则进行转换操作,规则如下:
- 偶数转换成该数的平方
- 奇数转换成该数的立方
from pyspark import SparkContextif __name__ == "__main__":# ********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App") # 2.创建一个内容为[("1", 1), ("2", 2), ("3", 3), ("4", 4), ("5", 5)]的列表ListList = [("1", 1), ("2", 2), ("3", 3), ("4", 4), ("5", 5)]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(List)# 4.使用rdd.collect() 收集 rdd 的元素print(rdd.collect())"""使用 mapValues 算子,将 rdd 的数据 ("1", 1), ("2", 2), ("3", 3), ("4", 4), ("5", 5) 按照下面的规则进行转换操作,规则如下:需求:元素(key,value)的value进行以下操作:偶数转换成该数的平方奇数转换成该数的立方"""# 5.使用 mapValues 算子完成以上需求values = rdd.mapValues(lambda x: x + 2)# 6.使用rdd.collect() 收集完成 mapValues 转换的元素print(values.collect())# 7.停止 SparkContextsc.stop()# ********** End **********#reduceByKey算子reduceByKey
reduceByKey算子,只是两个值合并成一个值,比如叠加。函数实现
def reduceByKey(self, func, numPartitions=None, partitionFunc=portable_hash): return self.combineByKey(lambda x: x, func, func, numPartitions, partitionFunc)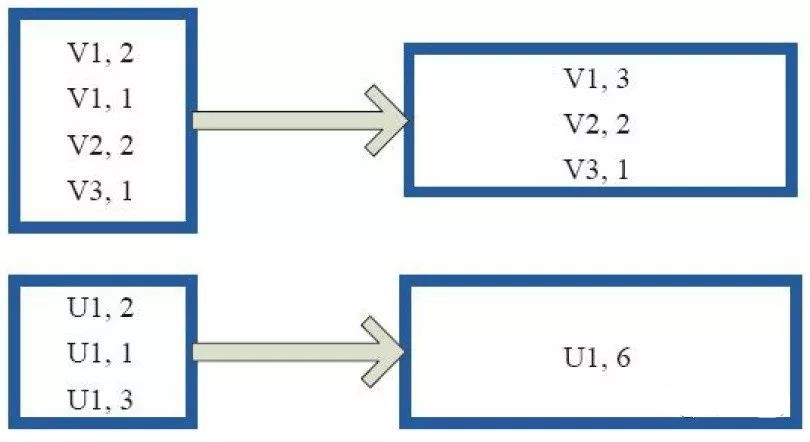
上图中的方框代表 RDD 分区。通过自定义函数 (A,B) => (A + B) ,将相同 key 的数据 (V1,2) 和 (V1,1) 的 value 做加法运算,结果为( V1,3)。
reduceByKey 案例
sc = SparkContext("local", "Simple App")
data = [("a",1),("a",2),("b",1)]
rdd = sc.parallelize(data)
print(rdd.reduceByKey(lambda x,y:x+y).collect())输出:
[('a', 3), ('b', 1)]
需求:使用 reduceByKey 算子,将 rdd(key-value类型) 中的数据进行值累加。
例如:
("soma",4), ("soma",1), ("soma",2) -> ("soma",7)
from pyspark import SparkContextif __name__ == "__main__":# ********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App") # 2.创建一个内容为[("python", 1), ("scala", 2), ("python", 3), ("python", 4), ("java", 5)]的列表ListList = [("python", 1), ("scala", 2), ("python", 3), ("python", 4), ("java", 5)]# 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(List) # 4.使用rdd.collect() 收集 rdd 的元素print(rdd.collect())"""使用 reduceByKey 算子,将 rdd 的数据[("python", 1), ("scala", 2), ("python", 3), ("python", 4), ("java", 5)] 按照下面的规则进行转换操作,规则如下:需求:元素(key-value)的value累加操作,例如:(1,1),(1,1),(1,2) --> (1,4)(1,1),(1,1),(2,2),(2,2) --> (1,2),(2,4)"""# 5.使用 reduceByKey 算子完成以上需求reduce = rdd.reduceByKey(lambda x,y:x+y)# 6.使用rdd.collect() 收集完成 reduceByKey 转换的元素print(reduce.collect())# 7.停止 SparkContextsc.stop()# ********** End **********#Action 的常用算子
count
count():返回 RDD 的元素个数。
示例:
-
sc = SparkContext("local", "Simple App") data = ["python", "python", "python", "java", "java"] rdd = sc.parallelize(data) print(rdd.count())
输出:
5
first
first():返回 RDD 的第一个元素(类似于take(1))。
示例:
-
sc = SparkContext("local", "Simple App") data = ["python", "python", "python", "java", "java"] rdd = sc.parallelize(data) print(rdd.first())
输出:
python
take
take(n):返回一个由数据集的前 n 个元素组成的数组。
示例:
-
sc = SparkContext("local", "Simple App") data = ["python", "python", "python", "java", "java"] rdd = sc.parallelize(data) print(rdd.take(2))
输出:
['python', 'python']
reduce
reduce():通过func函数聚集 RDD 中的所有元素,该函数应该是可交换的和关联的,以便可以并行正确计算。
示例:
-
sc = SparkContext("local", "Simple App") data = [1,1,1,1] rdd = sc.parallelize(data) print(rdd.reduce(lambda x,y:x+y))
输出:
4
collect
collect():在驱动程序中,以数组的形式返回数据集的所有元素。
示例:
-
sc = SparkContext("local", "Simple App") data = [1,1,1,1] rdd = sc.parallelize(data) print(rdd.collect())
输出:
[1,1,1,1]
具体任务如下:
需求1:使用 count 算子,统计下 rdd 中元素的个数;
需求2:使用 first 算子,获取 rdd 首个元素;
需求3:使用 take 算子,获取 rdd 前三个元素;
需求4:使用 reduce 算子,进行累加操作;
需求5:使用 collect 算子,收集所有元素。
from pyspark import SparkContext
if __name__ == "__main__":# ********** Begin **********## 1.初始化 SparkContext,该对象是 Spark 程序的入口sc = SparkContext("local", "Simple App")# 2.创建一个内容为[1, 3, 5, 7, 9, 8, 6, 4, 2]的列表ListList = [1, 3, 5, 7, 9, 8, 6, 4, 2] # 3.通过 SparkContext 并行化创建 rddrdd = sc.parallelize(List)# 4.收集rdd的所有元素并print输出print(rdd.collect())# 5.统计rdd的元素个数并print输出print(rdd.count())# 6.获取rdd的第一个元素并print输出print(rdd.first())# 7.获取rdd的前3个元素并print输出print(rdd.take(3))# 8.聚合rdd的所有元素并print输出print(rdd.reduce(lambda x,y:x+y))# 9.停止 SparkContextsc.stop()# ********** End **********#
相关文章:
SparkRDD及算子-python版
RDD相关知识 RDD介绍 RDD 是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置…...
嵌入式设备与PC上位机通信协议设计的几点原则
嵌入式设备在运行中需要设置参数,这个工作经常由PC机来实现,需要为双方通信设计协议,有代表性协议是如下三种: 从上表可以看到,一般嵌入式设备内存和运算性能都有限,因此固定二进制是首选通信协议。 一&am…...
Go 内置运算符
一、算数运算符 1、算数运算符使用 package mainimport ("fmt" )func main(){fmt.PrintIn("103",103) //10313fmt.PrintIn("10-3",10-3) //10-37fmt.PrintIn("10*3",10*3) //10*330//除法注意:如果运算的数都是…...
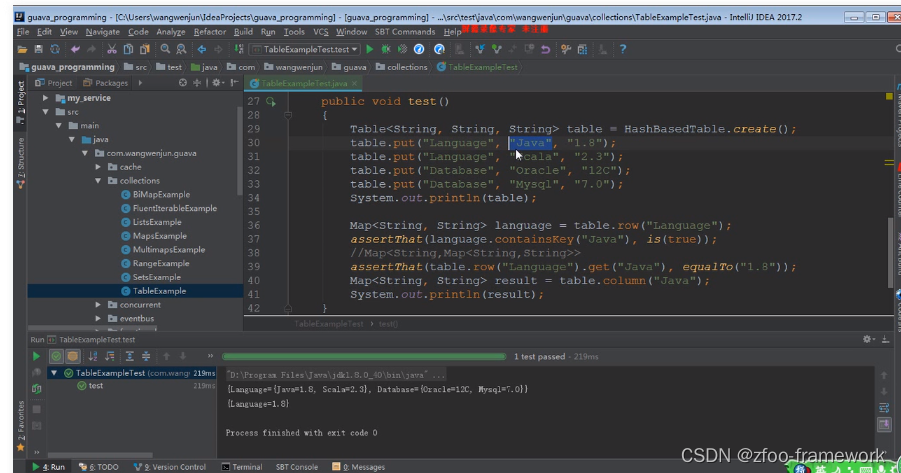
Table和HashBasedTable的使用案例
------------------- 1.普通使用 package org.example.testhashbasedtable;import com.google.common.collect.HashBasedTable; import com.google.common.collect.Table;import java.util.Map;public class TestHashBasedTable {public static void main(String[] args) {Ta…...

【执行批处理后 executeBatch() 没反应,一个参数相信就能搞定】
一、场景是在使用EasyExcel读取全表时,每次手动提交事务6w多条,总计190w数据量的情况下发生的。 博主比较fw,卡住了两天😶 此问题还有一个比较bug的地方,就是当你在 executeBatch() 上下打断点时还能够执行出来&…...
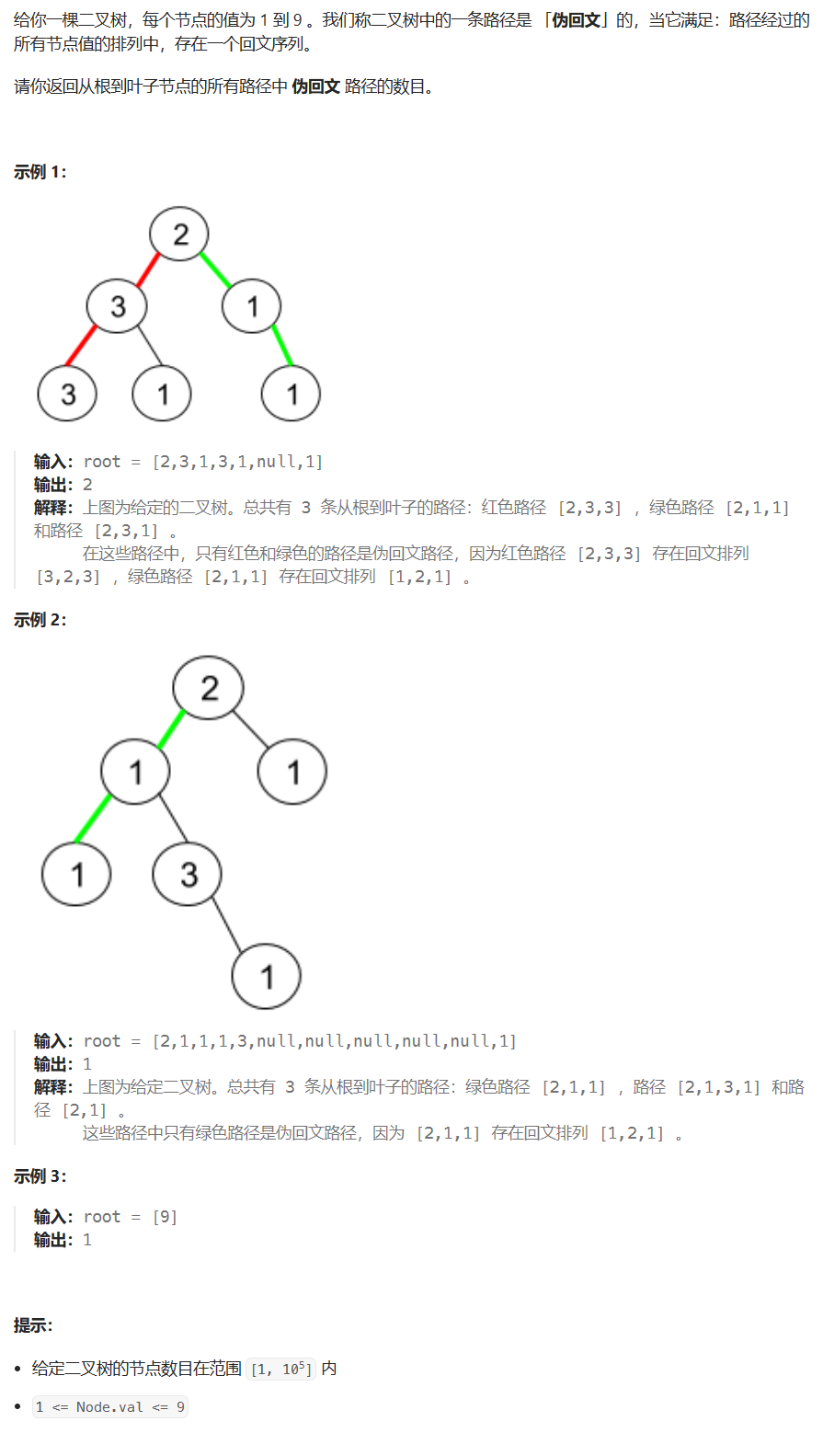
【LeetCode】每日一题 2023_11_25 二叉树中的伪回文路径(dfs,数组/位运算)
文章目录 刷题前唠嗑题目:二叉树中的伪回文路径题目描述代码与解题思路偷看大佬题解 结语 刷题前唠嗑 LeetCode?启动!!! 这个月第一次周末早起~ 题目:二叉树中的伪回文路径 题目链接:1457. 二…...

什么是海外私人IP代理?是纯净独享的代理吗?
相信许多互联网工作者都遇到过IP禁令,比如网络抓取项目,使用共享代理服务器向网站发出第一个请求,但却您收到了禁令,这大部分是由于你的共享IP经过多人使用被禁用所致。 那么到底什么是私人代理呢?它们是否适合您的情…...

Vue组件库推荐:Element UI深度解析
在Vue开发中,使用组件库可以极大地提高开发效率,减少重复工作量。Element UI作为一款优秀的Vue组件库,被广泛应用于各类项目中。本文将对Element UI进行深度解析,为开发者提供详细的使用说明和具体的代码示例。 1,Ele…...
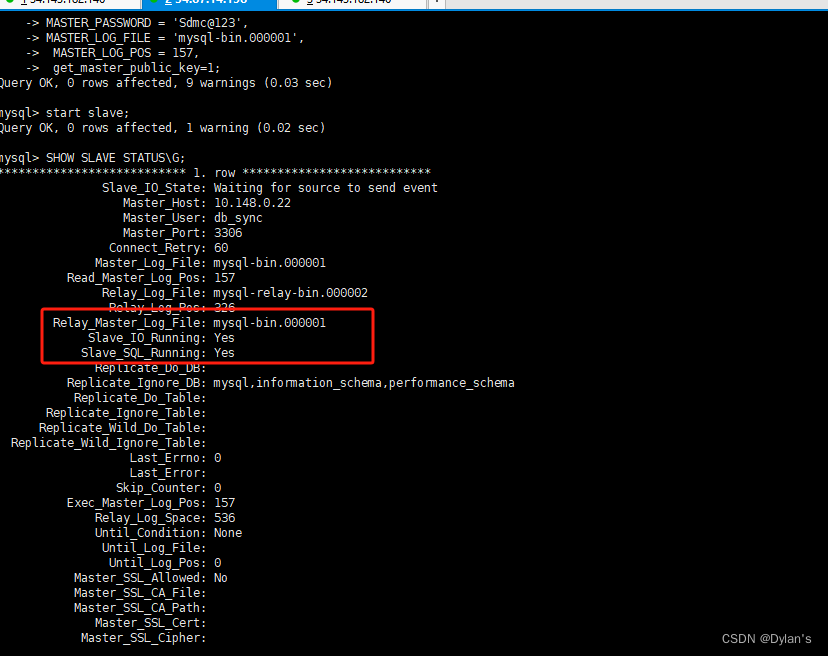
Mysql 8.0主从复制模式安装(兼容Mysql 5.7)
Mysql V8.0.35安装 官网地址:MySQL :: Download MySQL Community Server 下载【Mysql 8.0.35】压缩包 解压压缩包,仅保留6个安装文件即可 mysql-community-client-8.0.31-1.el7.x86_64.rpm mysql-community-client-plugins-8.0.31-1.el7.x86_64.rpm my…...
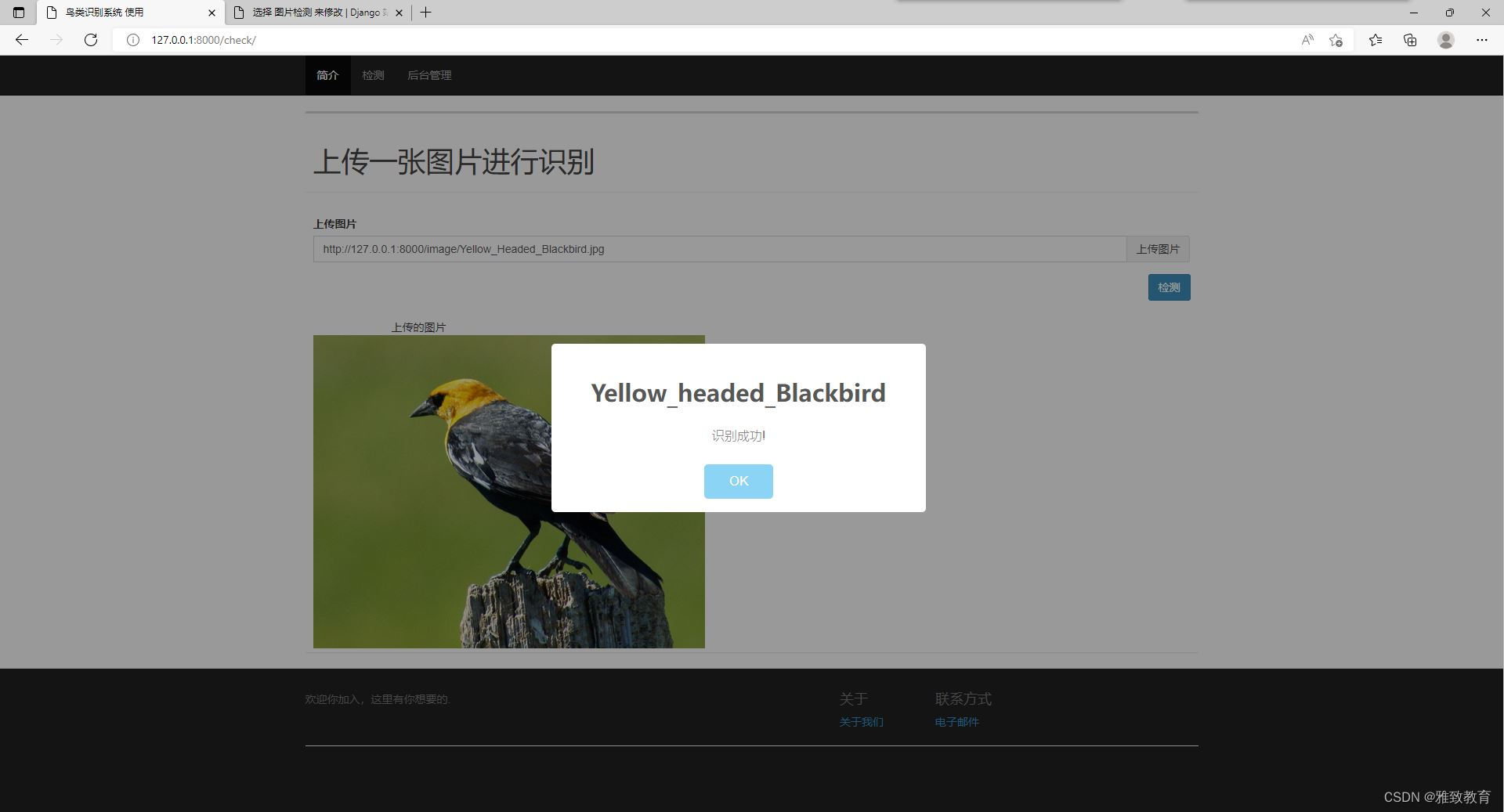
基于Django+Tensorflow卷积神经网络鸟类识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介系统概述系统功能核心技术系统架构系统优势 二、功能三、系统四. 总结 总结 一项目简介 介绍一个基于DjangoTensorflow卷积神经网络鸟类识别系统是一个非…...

史上最全前端知识点+高频面试题合集,十二大专题,命中率高达95%
前言: 下面分享一些关于阿里,美团,深信服等公司的面经,供大家参考一下。大家也可以去收集一些其他的面试题,可以通过面试题来看看自己有哪里不足。也可以了解自己想去的公司会问什么问题,进行有针对的复习。…...

我叫:基数排序【JAVA】
1.自我介绍 基数排序(radix sort)属于“分配式排序” (distribution sort),又称“桶子法” (bucket sort)或bin sort,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,是‘桶排序’的扩展 2.基本思想 将所有待比较数值统一为同样的数位长度,数位较短的数…...

ArkUI开发进阶—@Builder函数@BuilderParam装饰器的妙用与场景应用【鸿蒙专栏-05】
ArkUI开发进阶—@Builder函数@BuilderParam装饰器的妙用与场景应用 HarmonyOS,作为一款全场景分布式操作系统,为了推动更广泛的应用开发,采用了一种先进而灵活的编程语言——ArkTS。ArkTS是在TypeScript(TS)的基础上发展而来,为HarmonyOS提供了丰富的应用开发工具,使开…...

智慧城市内涝积水监测仪功能,提升城市预防功能
内涝积水监测仪不仅改变了人们应对城市内涝的老办法,还让智慧城市往前迈了一大步。这个监测仪是怎么做到的呢?就是靠它精准的数据监测和预警,让城市管理有了更科学高效的解决妙招。它就像有了个聪明又负责任的助手,让城市管理更加…...

ISCTF2023 部分wp
学一年了还在入门( web where_is_the_flag ISCTF{41631519-1c64-40f6-8dbb-27877a184e74} 圣杯战争 <?php // highlight_file(__FILE__); // error_reporting(0);class artifact{public $excalibuer;public $arrow;public function __toString(){echo "为Saber选择…...
)
springboot(ssm毕业生学历证明系统Java(codeLW)
springboot(ssm毕业生学历证明系统Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0) 数据…...

分布式锁3: zk实现分布式锁
一 zk 实现分布式锁 1.1 zk分布式操作命令 1.指令: ls / get /zookeeper create /aa "test" delete /aa set /aa "test1" 分布式锁实现原理与最佳实践 2..znode节点类型: 永…...

每日博客Day8
每日博客Day 8 每日算法 206.翻转链表 个人第一次思路: 其实我个人的第一个思路是比较暴力的,我第一遍暴力遍历链表,把链表的所有数值全部都保存到数组里面,然后翻转这个数组,再重复的覆盖当前的这个链表。但是这样…...
Redis-主从与哨兵架构
Jedis使用 Jedis连接代码示例: 1、引入依赖 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version> </dependency> 2、访问代码 public class JedisSingleTe…...

PTA 7-3 将数组中的数逆序存放
本题要求编写程序,将给定的n个整数存入数组中,将数组中的这n个数逆序存放,再按顺序输出数组中的元素。 输入格式: 输入在第一行中给出一个正整数n(1≤n≤10)。第二行输入n个整数,用空格分开。 输出格式:…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术
ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...

哪款台灯护眼效果最好孩子用?实测口碑爆款护眼灯品牌,买前必看
哪款台灯护眼效果最好孩子用?作为家长,最揪心的就是孩子的视力问题。有数据显示,现在孩子近视率越来越高,小学就有不少戴眼镜的,中学更是过半,看着实在让人担心。 孩子每天低头写作业、看书,灯光…...