算法通关村第一关—青铜挑战—用Java基本实现各种链表操作
文章目录
- 第一关—链表【青铜挑战】
- 1.1 单链表的概念
- 1.2 链表的相关概念
- 1.3 创建链表 - Java实现
- 1.4 链表的增删改查
- 1.4.1 遍历单链表 - 求单链表长度
- 1.4.2 链表插入 - 三种位置插入
- (1)在链表的表头插入
- (2)在链表的中间插入
- (3)在链表的结尾插入
- (4)在链表的所有位置插入[总结]⭐
- 1.4.3 链表删除 - 三种位置删除
- (1)删除链表的表头结点
- (2)删除链表的最后一个结点
- (3)删除链表的中间结点
- (4)删除链表的任一位置[总结]⭐
第一关—链表【青铜挑战】
1.1 单链表的概念
- 单向链表就像一个铁链一样,元素之间互相连接,包含多个结点,每个结点**
只有一个**指向后继元素的next指针,并且最后一个元素的next指向null

小练:以下两张图,是否满足单链表的要求
解析:第一张图满足单链表的要求,第二张图不满足要求,因为c1它有两个后继结点a5和b4,单链表的核心是一个结点只能有一个后继,但是不代表一个结点只能有一个被指向(如c1可以被a2和b3指向)
注意:做题的时候注意比较的是值还是结点,有时可能两个结点的值是相等的,但并不是同一个结点,例如下图,有两个结点的值都是1,但并不是同一个结点



1.2 链表的相关概念
节点和头节点
在链表中,每个点都由
值和指向下一个节点的地址组成独立的单元,成为一个结点,有时也称为节点,含义都是一样的对于单链表而言,如果知道了第一个元素,就可以遍历访问整个链表,因此第一个节点最重要,一般称为头节点
虚拟结点
虚拟结点就是一个dummyNode,其next指针指向head头部,也就是
dummyNode.next = head因此,如果我们在算法里使用了虚拟结点,则要注意,如果要获得head结点,或者从方法里返回的时候,则应使用dummyNode.next
另外,dummyNode的val不会被使用,初始化为0或者-1等都是可以的,既然值不会被使用,那么我们就会有疑问?虚拟结点有啥用呢?简单来说,就是为了方便我们处理
头结点,否则我们需要在代码里单独处理头结点【首部结点】的问题

1.3 创建链表 - Java实现
我们首先要理解JVM是怎么构建出链表,JVM里面有栈区和堆区,堆区主要存引用,也就是一个指向实际对象的地址,而堆区存的才是创建的对象

/*** @Author Zan* @Date 2023/11/29 14:46* @Description : 传入一个数组,将其转换成单链表*/
public class BasicLink {public static void main(String[] args) {int[] a = {1, 2, 3, 4, 5, 6};Node head = initLinkedList(a);System.out.println(head);}private static Node initLinkedList(int[] array) {Node head = null, current = null;for (int i = 0; i < array.length; i++) {Node newNode = new Node(array[i]);if (i == 0) { // 头节点// 由于head = current,因此当current在变化的时候,head也在变化head = newNode;
// newNode = new Node(array[i]); // 如果在此将newNode重新定义,指向的是不同的堆数据,因此head就只是一个Node普通对象,单节点的链表current = newNode;} else { // 后面的节点current.next = newNode;current = newNode;}}return head;}static class Node {public int x;public Node next;public Node(int x) {this.x = x;next = null;}}
}

我们可以看到初始化链表的时候,head和current指向的是同一个对象,也就是指向堆中的同一个数据,因此当控制
current.next = newNode的时候,其实就是控制堆中的数据指向谁,next指向下一条数据,而head跟current一样指向的是同一个对象,因此就可以跟随其变化
最后得到head如下图所示 - 单链表的形式


1.4 链表的增删改查
- 对于单链表而言,不管进行什么操作,一定都是从头开始逐个向后开始访问,所以操作之后是否还能够找到表头非常重要
1.4.1 遍历单链表 - 求单链表长度
/*** 遍历链表,获取链表的长度* @param head 头节点* @return*/
public static int getListLength(Node head) { // 传入头节点int length = 0;Node node = head;while (node != null) { // 一个一个节点遍历length++;node = node.next;}return length;
}
1.4.2 链表插入 - 三种位置插入
- 单链表的插入,和数组的插入一样,过程不复杂。但是单链表的插入操作需要考虑三种情况:首部、中部和尾部
(1)在链表的表头插入
- 创建新结点newNode
- 新结点的next = head,即
newNode.next = head- 头head指向新的链表,即
head = newNode

/*** 在链表的表头插入* @param head 原链表* @param nodeInsert 要插入表头的结点元素* @return*/
public static Node insertNodeByHead(Node head, Node nodeInsert) {nodeInsert.next = head;head = nodeInsert;return head;
}

(2)在链表的中间插入
- 循环找到要插入位置position的前一个结点(位置从1开始)
- 将插入结点的next指向前一个结点的next,即
nodeInsert.next = newNode.next- 将前一个结点的next指向插入结点,即
newNode.next = nodeInsert
- 注意:我们不能先将前一个结点的next指向插入结点,这是因为每个结点都只有一个next,因此如果先将前一个结点的next指向插入结点,那么
15->7这一条线就断掉了,也就导致后面的7、40将会找不到,断开

/*** 在链表的中间位置插入* @param head 原链表的头结点* @param nodeInsert 要插入的结点* @param position 要插入的位置,从1开始* @return*/
public static Node insertNodeByPosition(Node head, Node nodeInsert, int position) {Node newNode = head; // 不对原链表进行操作,用新链表指向堆中的同一个元素,进行堆中的操作int i = 1;while (i < position - 1) { // 要在中间位置插入,因此要获取插入位置的前一个结点,这样子才能将next连接起来newNode = newNode.next;i++;}nodeInsert.next = newNode.next; // 将要插入的结点的next指向插入位置前一个结点的nextnewNode.next = nodeInsert; // 将插入位置前一个结点的next指向要插入的结点return head;
}

(3)在链表的结尾插入
- 获取原链表总共有多少个元素
- 循环遍历找到最后一个结点
- 将最后一个结点的next指向新结点

/*** 在链表的结尾插入* @param head 原链表的头结点* @param nodeInsert 要插入的结点* @return*/
public static Node insertByEnd(Node head, Node nodeInsert) {Node newNode = head;int nodeLength = getListLength(newNode); // 获取到原链表的元素个数int i = 1;while (i < nodeLength) { // 循环遍历找到最后一个结点newNode = newNode.next;i++;}newNode.next = nodeInsert; // 将最后一个结点的next指向新结点return head;
}

(4)在链表的所有位置插入[总结]⭐
/*** 链表的插入(所有情况,表头、中间、结尾)** @param head 原链表* @param nodeInsert 插入的结点* @param position 插入的位置,从1开始* @return*/
public static Node insertNode(Node head, Node nodeInsert, int position) {// head原链表中没有数据,插入的结点就是链表的头结点if (head == null) {return nodeInsert;}// 获取存放元素个数 - 进行校验(position在[1, size]之间)int size = getListLength(head);if (position > size + 1 || position < 1) {System.out.println("位置参数越界");return head;}// 表头插入if (position == 1) {nodeInsert.next = head;head = nodeInsert;return head;}// 中间插入和结尾插入Node newNode = head;int count = 1;while (count < position - 1) {count++;newNode = newNode.next;}nodeInsert.next = newNode.next;newNode.next = nodeInsert;return head;
}
1.4.3 链表删除 - 三种位置删除
- 删除同样分为删除头部元素、删除中间元素和删除尾部元素
(1)删除链表的表头结点
将head表头向前移动一次之后,原先的结点就变成了不可达,会被JVM回收掉

/*** 删除表头结点* @param head 原链表* @return*/
public static Node deleteByHead(Node head) {head = head.next;return head;
}

(2)删除链表的最后一个结点
- 获取该链表的总长度size
- 找到倒数第二个结点
- 将倒数第二个结点的next指向null,即
newNode.next = null

/*** 删除最后一个结点* @param head 原链表* @return*/
public static Node deleteByEnd(Node head) {Node newNode = head;int size = getListLength(head); // 获取该链表的总长度sizeint i = 1;while (i < size - 1) { // 找到倒数第二个结点i++;newNode = newNode.next;}newNode.next = null; // 将倒数第二个结点的next指向nullreturn head;
}

(3)删除链表的中间结点
- 找到要删除结点的前一个结点
- 将前一个结点的next指向下下个结点,即
newNode.next = newNode.next.next

/*** 删除中间结点* @param head 原链表* @return*/
public static Node deleteByPosition(Node head, int position) {Node newNode = head;int i = 1;while (i < position - 1) {i++;newNode = newNode.next;}newNode.next = newNode.next.next;return head;
}

(4)删除链表的任一位置[总结]⭐
/*** 删除结点(三种情况,表头、中间、最后一位结点)* @param head 原链表* @return*/
public static Node deleteNode(Node head, int position) {// 如果没有结点,说明无法删除,直接返回null即可if (head == null) {return null;}//校验int size = getListLength(head);if (position > size || position < 1) { // 这里不是size+1,而插入是size+1,因为插入可以插入到最后一位(未知的最后一位),而删除必须要是已知的,不能是未知的越界System.out.println("输入的参数有误");return head;}if (position == 1) { // 删除头节点return head.next;} else { // 删除中间结点或者最后一个结点Node newNode = head;int count = 1;while (count < position - 1) {count++;newNode = newNode.next;}newNode.next = newNode.next.next;return head;}
}
相关文章:
算法通关村第一关—青铜挑战—用Java基本实现各种链表操作
文章目录 第一关—链表【青铜挑战】1.1 单链表的概念1.2 链表的相关概念1.3 创建链表 - Java实现1.4 链表的增删改查1.4.1 遍历单链表 - 求单链表长度1.4.2 链表插入 - 三种位置插入(1)在链表的表头插入(2)在链表的中间插入&#…...

SparkRDD及算子-python版
RDD相关知识 RDD介绍 RDD 是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置…...
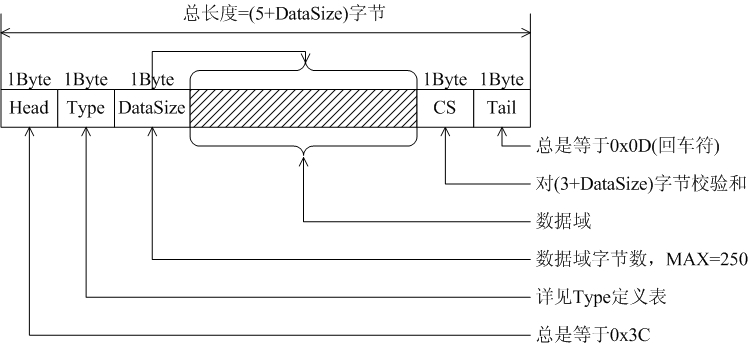
嵌入式设备与PC上位机通信协议设计的几点原则
嵌入式设备在运行中需要设置参数,这个工作经常由PC机来实现,需要为双方通信设计协议,有代表性协议是如下三种: 从上表可以看到,一般嵌入式设备内存和运算性能都有限,因此固定二进制是首选通信协议。 一&am…...
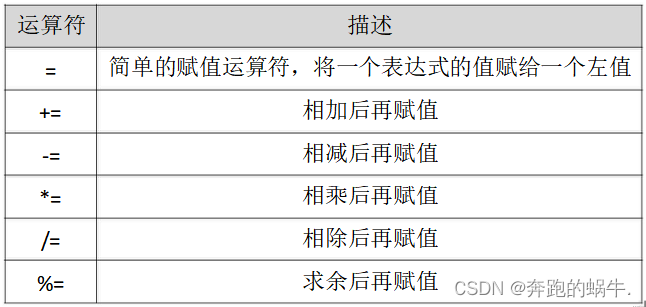
Go 内置运算符
一、算数运算符 1、算数运算符使用 package mainimport ("fmt" )func main(){fmt.PrintIn("103",103) //10313fmt.PrintIn("10-3",10-3) //10-37fmt.PrintIn("10*3",10*3) //10*330//除法注意:如果运算的数都是…...
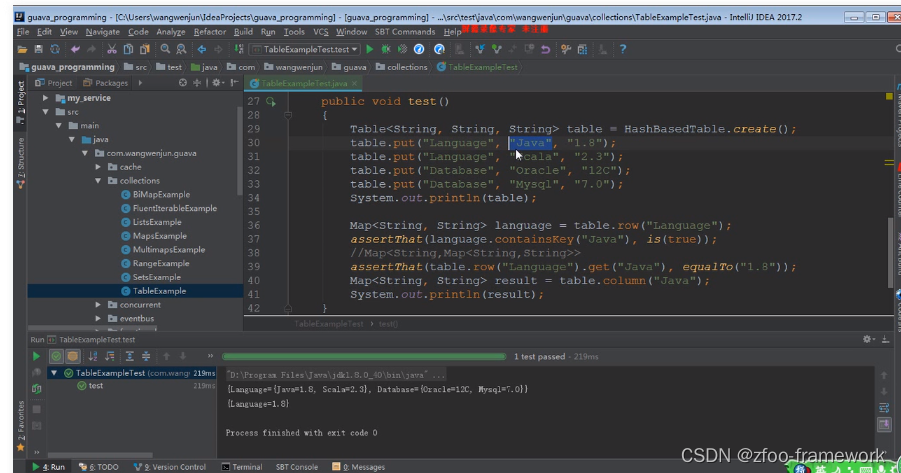
Table和HashBasedTable的使用案例
------------------- 1.普通使用 package org.example.testhashbasedtable;import com.google.common.collect.HashBasedTable; import com.google.common.collect.Table;import java.util.Map;public class TestHashBasedTable {public static void main(String[] args) {Ta…...

【执行批处理后 executeBatch() 没反应,一个参数相信就能搞定】
一、场景是在使用EasyExcel读取全表时,每次手动提交事务6w多条,总计190w数据量的情况下发生的。 博主比较fw,卡住了两天😶 此问题还有一个比较bug的地方,就是当你在 executeBatch() 上下打断点时还能够执行出来&…...
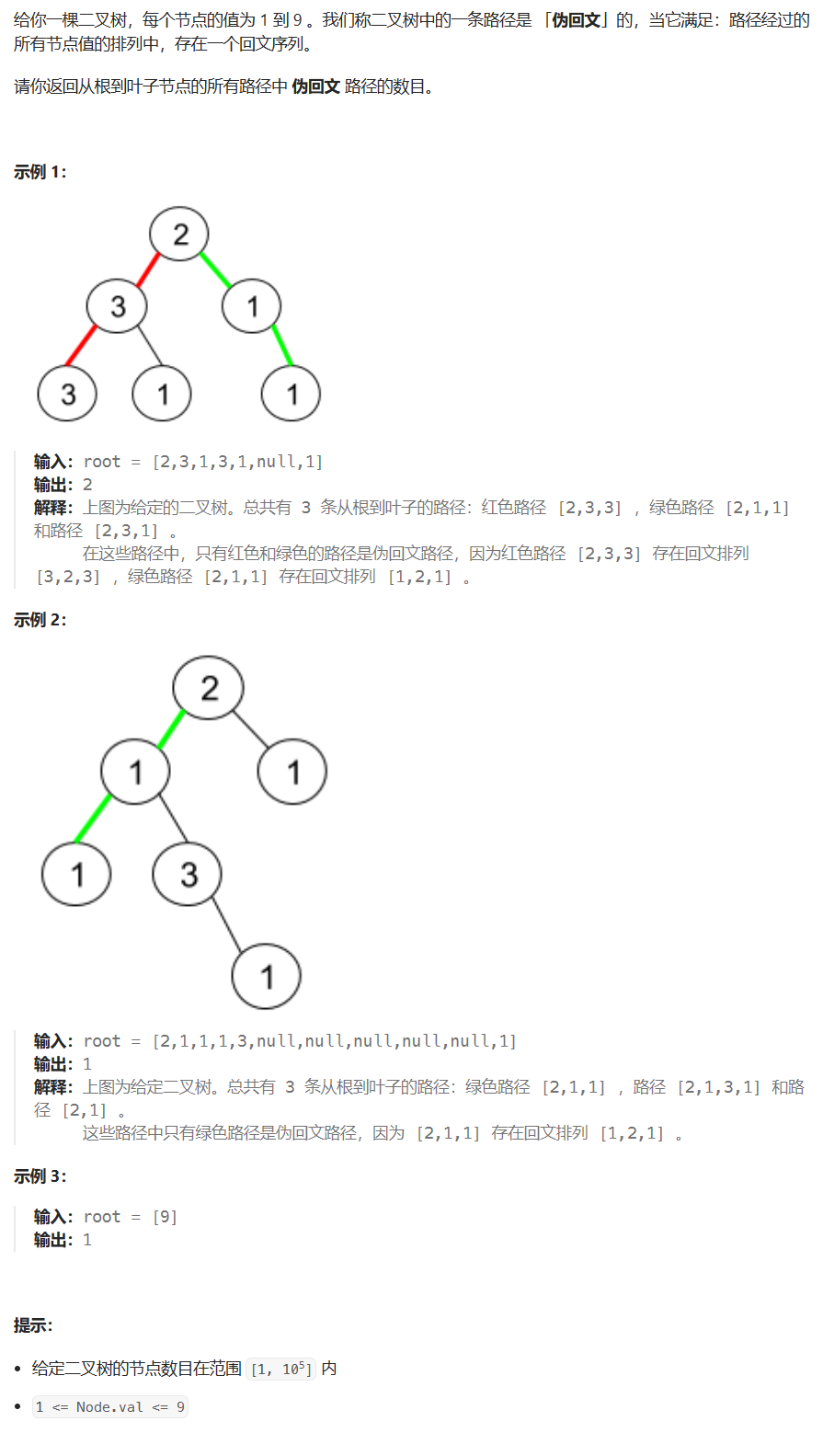
【LeetCode】每日一题 2023_11_25 二叉树中的伪回文路径(dfs,数组/位运算)
文章目录 刷题前唠嗑题目:二叉树中的伪回文路径题目描述代码与解题思路偷看大佬题解 结语 刷题前唠嗑 LeetCode?启动!!! 这个月第一次周末早起~ 题目:二叉树中的伪回文路径 题目链接:1457. 二…...

什么是海外私人IP代理?是纯净独享的代理吗?
相信许多互联网工作者都遇到过IP禁令,比如网络抓取项目,使用共享代理服务器向网站发出第一个请求,但却您收到了禁令,这大部分是由于你的共享IP经过多人使用被禁用所致。 那么到底什么是私人代理呢?它们是否适合您的情…...

Vue组件库推荐:Element UI深度解析
在Vue开发中,使用组件库可以极大地提高开发效率,减少重复工作量。Element UI作为一款优秀的Vue组件库,被广泛应用于各类项目中。本文将对Element UI进行深度解析,为开发者提供详细的使用说明和具体的代码示例。 1,Ele…...
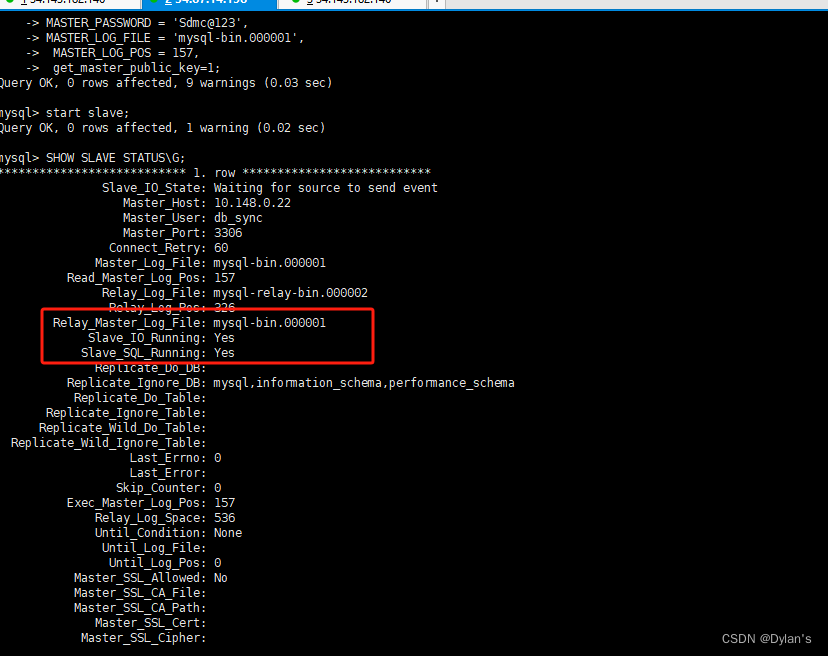
Mysql 8.0主从复制模式安装(兼容Mysql 5.7)
Mysql V8.0.35安装 官网地址:MySQL :: Download MySQL Community Server 下载【Mysql 8.0.35】压缩包 解压压缩包,仅保留6个安装文件即可 mysql-community-client-8.0.31-1.el7.x86_64.rpm mysql-community-client-plugins-8.0.31-1.el7.x86_64.rpm my…...
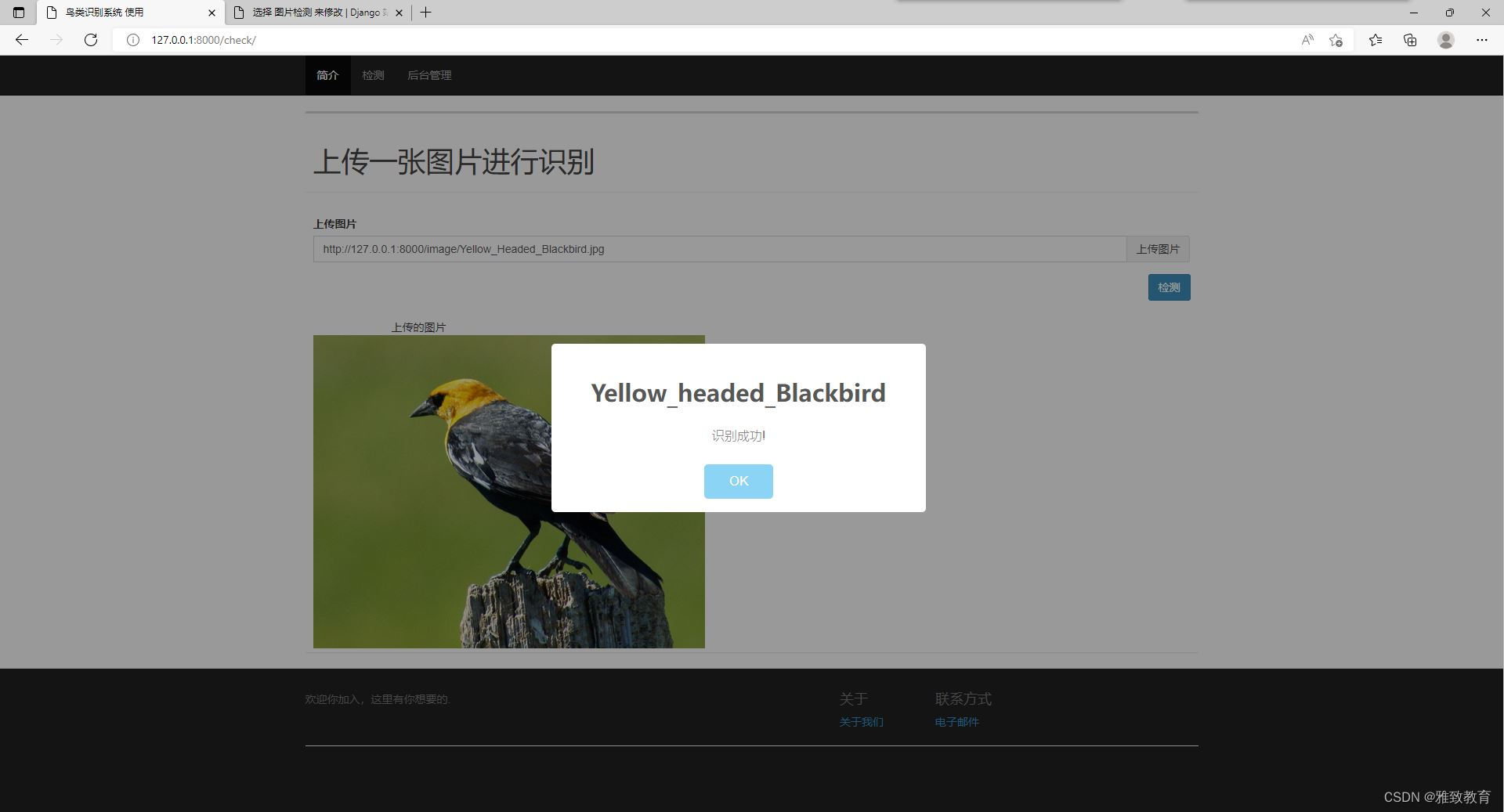
基于Django+Tensorflow卷积神经网络鸟类识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介系统概述系统功能核心技术系统架构系统优势 二、功能三、系统四. 总结 总结 一项目简介 介绍一个基于DjangoTensorflow卷积神经网络鸟类识别系统是一个非…...

史上最全前端知识点+高频面试题合集,十二大专题,命中率高达95%
前言: 下面分享一些关于阿里,美团,深信服等公司的面经,供大家参考一下。大家也可以去收集一些其他的面试题,可以通过面试题来看看自己有哪里不足。也可以了解自己想去的公司会问什么问题,进行有针对的复习。…...

我叫:基数排序【JAVA】
1.自我介绍 基数排序(radix sort)属于“分配式排序” (distribution sort),又称“桶子法” (bucket sort)或bin sort,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,是‘桶排序’的扩展 2.基本思想 将所有待比较数值统一为同样的数位长度,数位较短的数…...

ArkUI开发进阶—@Builder函数@BuilderParam装饰器的妙用与场景应用【鸿蒙专栏-05】
ArkUI开发进阶—@Builder函数@BuilderParam装饰器的妙用与场景应用 HarmonyOS,作为一款全场景分布式操作系统,为了推动更广泛的应用开发,采用了一种先进而灵活的编程语言——ArkTS。ArkTS是在TypeScript(TS)的基础上发展而来,为HarmonyOS提供了丰富的应用开发工具,使开…...

智慧城市内涝积水监测仪功能,提升城市预防功能
内涝积水监测仪不仅改变了人们应对城市内涝的老办法,还让智慧城市往前迈了一大步。这个监测仪是怎么做到的呢?就是靠它精准的数据监测和预警,让城市管理有了更科学高效的解决妙招。它就像有了个聪明又负责任的助手,让城市管理更加…...

ISCTF2023 部分wp
学一年了还在入门( web where_is_the_flag ISCTF{41631519-1c64-40f6-8dbb-27877a184e74} 圣杯战争 <?php // highlight_file(__FILE__); // error_reporting(0);class artifact{public $excalibuer;public $arrow;public function __toString(){echo "为Saber选择…...
)
springboot(ssm毕业生学历证明系统Java(codeLW)
springboot(ssm毕业生学历证明系统Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0) 数据…...

分布式锁3: zk实现分布式锁
一 zk 实现分布式锁 1.1 zk分布式操作命令 1.指令: ls / get /zookeeper create /aa "test" delete /aa set /aa "test1" 分布式锁实现原理与最佳实践 2..znode节点类型: 永…...

每日博客Day8
每日博客Day 8 每日算法 206.翻转链表 个人第一次思路: 其实我个人的第一个思路是比较暴力的,我第一遍暴力遍历链表,把链表的所有数值全部都保存到数组里面,然后翻转这个数组,再重复的覆盖当前的这个链表。但是这样…...
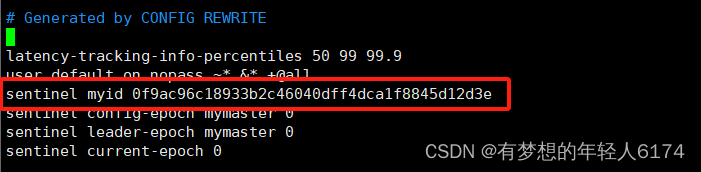
Redis-主从与哨兵架构
Jedis使用 Jedis连接代码示例: 1、引入依赖 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version> </dependency> 2、访问代码 public class JedisSingleTe…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...

告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境
告别依赖冲突:在Debian12上为特定项目搭建Python2.7.18独立运行环境 当现代Linux系统已全面拥抱Python3的时代,突然需要维护一个仅支持Python2.7的遗留项目,这种场景对开发者而言无异于一场噩梦。本文将带你用工程化的思维,在Deb…...