【机器学习】交叉验证 Cross-validation
交叉验证(CrossValidation)方法思想简介
以下简称交叉验证(Cross Validation)为CV.CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标.常见CV的方法如下:
1).Hold-Out Method
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性.
2).K-fold Cross Validation(记为K-CV)
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标.K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2.K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性.
3).Leave-One-Out Cross Validation(记为LOO-CV)
如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标.相比于前面的K-CV,LOO-CV有两个明显的优点:
①
a.每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
②
b.实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间.
对交叉验证这个问题,一直以来,不明白是怎么回事。近期看材料,涉及到了这个问题,写的通俗易懂,有种恍然大悟的感觉。下面,我写下对这个问题的理解。
现在假设这里有一堆数据,作为统计er的任务就是从这些数据中提取有用的信息。如何提取信息呢,我们的法宝就是–模型。模型在统计当中是极其重要的,学统计就是跟各种各样的模型混个脸熟。在模型的基础上,我们利用数据对模型的参数进行估计,从而通过参数化后的模型来描述数据的内在关系,了解数据内在的关系(pattern)非常必要,有助于对未来进行预测。
那么对于手里的数据,我们该套用什么样的模型呢?事实上,对于一个数据分析问题而言,可用的模型不只一个,不存在所谓最优的模型。你不能说,某个模型是最好的,其他模型都是不可取的,某个模型在某个问题下,可能解释能力优于其他模型,但这并不意味着在该类问题下,该模型就是万能的,可能换一种评价标准,这种模型就不是最好的。我们的任务是从几个备选模型中,按照某种评价标准,选择出较为合理的一个模型。
一个直接的想法是比较各个模型的对数据的拟合效果。例如,对于一个x,y
数据而言,线性回归的残差平方和可能比非线性回归的残差平方和要小,这时我们说,线性回归拟合效果更好,线性回归模型是理想的选择。但是这种比较方式存在一种缺陷—过拟合问题。有些模型,对原始数据拟合相当好,但是它的预测效果却出奇的差。更重要的是,数据分析的最终目的并不是拟合数据,而是对未来进行预测。一个合理的模型一方面可以拟合原始数据,另一方面又应该可以以高准确率进行预测。所以进行模型选择时,要综合考虑这两方面因素。情况常常是,拟合效果和预测误差二者鱼和熊掌不能兼得,我们需要在二者之间寻找一种平衡。
交叉验证就是基于这样的考虑。我们以K折交叉验证(k-folded cross validation)来说明它的具体步骤。
{A1,A2,A3,A4,A5,A6,A7,A8,A9}{A1,A2,A3,A4,A5,A6,A7,A8,A9}
为了简化,取k=10。在原始数据A的基础上,我们随机抽取一组观测,构成一个数据子集(容量固定),记为A1
重复以上过程10次,我们就会获得一个数据子集集合 {A1,A2,A3,A4,A5,A6,A7,A8,A9,A10}
。
接下来,我们首先对模型M1
进行交叉验证,如下,
在{A2,A3,A4,A5,A6,A7,A8,A9,A10}基础上构建模型M1,并对数据集A1进行验证,将预测值与真值进行比较,在某一评价标准下,计算一个得分a1,1
.
在{A1,A3,A4,A5,A6,A7,A8,A9,A10}
基础上构建模型M1,并对数据集A2进行验证,将预测值与真值进行比较,在同一评价标准下,计算一个得分a1,2
.
……
在{A1,A2,A3,A4,A5,A6,A7,A8,A9}
基础上构建模型,并对数据集A10进行验证,将预测值与真值进行比较,在同一评价标准下,计算一个得分a1,10
.
a1=a1,1+a1,2+…+a1,10/10
作为模型M1的综合得分。
{A2,A3,A4,A5,A6,A7,A8,A9,A1
对每个模型都这样过一遍,最后得到了每个模型的一个得分,按照得分,我们就可以选择最合理的模型。
将数据打成好多份,交叉验证模型,很有点bootstrap的意思,bootstrap的思想渗透到了统计学的各个领域了已经。
除了K折交叉验证,另外两种交叉验证为Hold Out 验证和留一验证:
Hold验证:常识来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。
留一验证: 正如名称所建议, 留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料, 而剩余的则留下来当做训练资料。 这个步骤一直持续到每个样本都被当做一次验证资料。 事实上,这等同于 K-fold 交叉验证是一样的,其中K为原本样本个数。
一、训练集 vs. 测试集
在模式识别(pattern recognition)与机器学习(machine learning)的相关研究中,经常会将数据集(dataset)分为训练集(training set)跟测试集(testing set)这两个子集,前者用以建立模型(model),后者则用来评估该模型对未知样本进行预测时的精确度,正规的说法是泛化能力(generalization ability)。怎么将完整的数据集分为训练集跟测试集,必须遵守如下要点:
1、只有训练集才可以用在模型的训练过程中,测试集则必须在模型完成之后才被用来评估模型优劣的依据。
2、训练集中样本数量必须够多,一般至少大于总样本数的50%。
3、两组子集必须从完整集合中均匀取样。
其中最后一点特别重要,均匀取样的目的是希望减少训练集/测试集与完整集合之间的偏差(bias),但却也不易做到。一般的作法是随机取样,当样本数量足 够时,便可达到均匀取样的效果,然而随机也正是此作法的盲点,也是经常是可以在数据上做手脚的地方。举例来说,当辨识率不理想时,便重新取样一组训练集/ 测试集,直到测试集的识别率满意为止,但严格来说这样便算是作弊了。
二、交叉验证(Cross Validation)
交叉验证(Cross Validation)是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集 (training set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。常见的交叉验证方法如下:
1、Hold-Out Method
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。 此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关 系,所以这种方法得到的结果其实并不具有说服性。
2、Double Cross Validation(2-fold Cross Validation,记为2-CV)
做法是将数据集分成两个相等大小的子集,进行两回合的分类器训练。在第一回合中,一个子集作为training set,另一个便作为testing set;在第二回合中,则将training set与testing set对换后,再次训练分类器,而其中我们比较关心的是两次testing sets的辨识率。不过在实务上2-CV并不常用,主要原因是training set样本数太少,通常不足以代表母体样本的分布,导致testing阶段辨识率容易出现明显落差。此外,2-CV中分子集的变异度大,往往无法达到“实 验过程必须可以被复制”的要求。
3、K-fold Cross Validation(K-折交叉验证,记为K-CV)
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证 集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取 2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
4、Leave-One-Out Cross Validation(记为LOO-CV)
如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模 型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。相比于前面的K-CV,LOO-CV有两个明显的优点:
(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。
三、使用Cross-Validation时常犯的错误
由于实验室许多研究都有用到 evolutionary algorithms(EA)与 classifiers,所使用的 fitness function 中通常都有用到 classifier 的辨识率,然而把cross-validation 用错的案例还不少。前面说过,只有 training data 才可以用于 model 的建构,所以只有 training data 的辨识率才可以用在 fitness function 中。而 EA 是训练过程用来调整 model 最佳参数的方法,所以只有在 EA结束演化后,model 参数已经固定了,这时候才可以使用 test data。那 EA 跟 cross-validation 要如何搭配呢?Cross-validation 的本质是用来估测(estimate)某个 classification method 对一组 dataset 的 generalization error,不是用来设计 classifier 的方法,所以 cross-validation 不能用在 EA的 fitness function 中,因为与 fitness function 有关的样本都属于 training set,那试问哪些样本才是 test set 呢?如果某个 fitness function 中用了cross-validation 的 training 或 test 辨识率,那么这样的实验方法已经不能称为 cross-validation 了。
EA 与 k-CV 正确的搭配方法,是将 dataset 分成 k 等份的 subsets 后,每次取 1份 subset 作为 test set,其余 k-1 份作为 training set,并且将该组 training set 套用到 EA 的 fitness function 计算中(至于该 training set 如何进一步利用则没有限制)。因此,正确的 k-CV 会进行共 k 次的 EA 演化,建立 k 个classifiers。而 k-CV 的 test 辨识率,则是 k 组 test sets 对应到 EA 训练所得的 k 个 classifiers 辨识率之平均值。
相关文章:

【机器学习】交叉验证 Cross-validation
交叉验证(CrossValidation)方法思想简介 以下简称交叉验证(Cross Validation)为CV.CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进…...
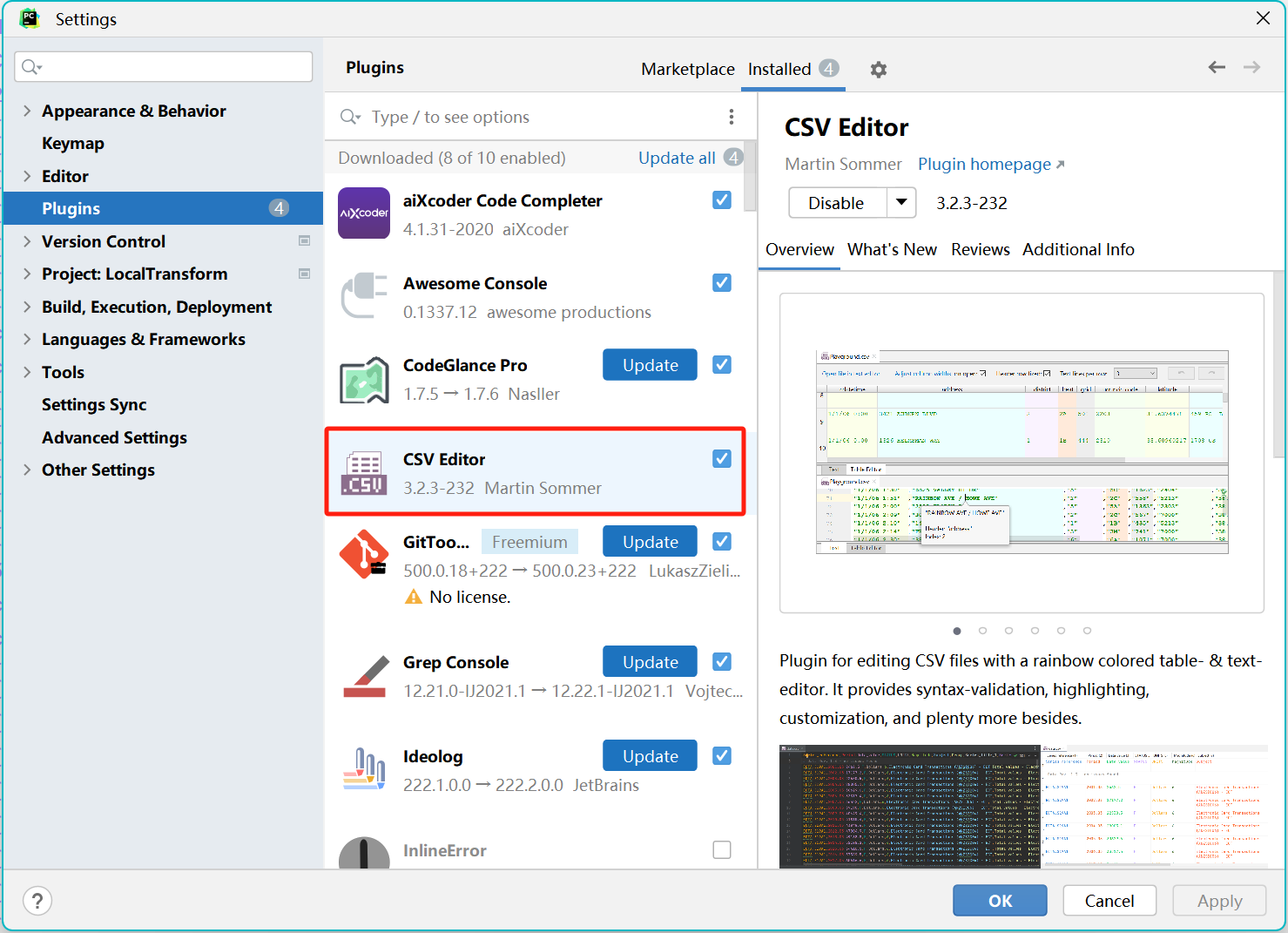
Pycharm修改文件默认打开方式 + CSV Editor插件使用
1、File —> Settings —> Editor —> File Types 然后将*csv添加到最上面 在plugins中下载插件,CSV Editor 备注:不在上一步的“File Types”中将*.csv设置为CSV格式,插件是不起作用的 就可以使用了...
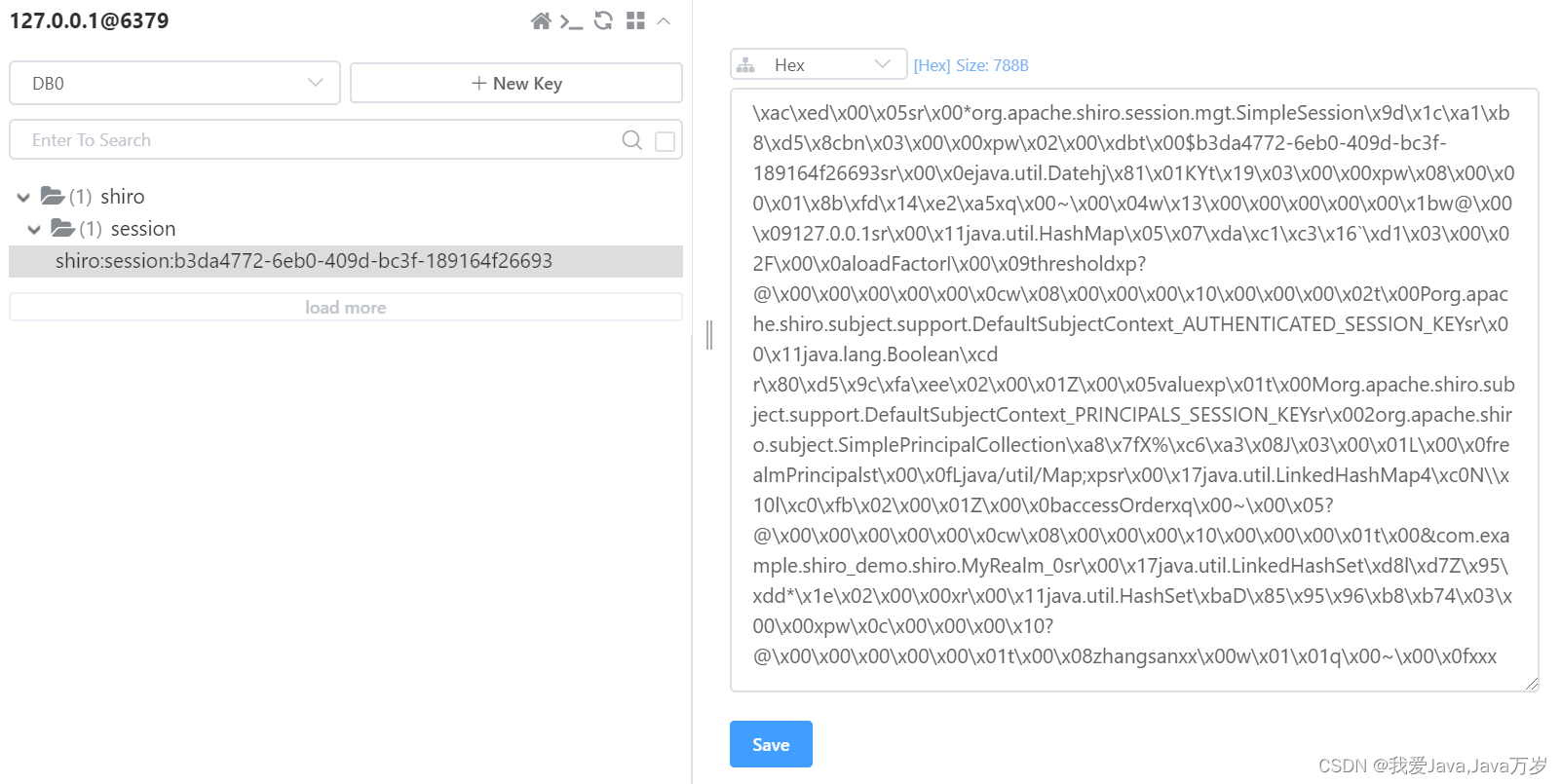
shiro整合redis
shiro整合redis 前言:shiro默认的session是存储在jvm内存中的,这样会导致java服务内存占用更大以及一旦服务器宕机或者版本迭代需要重启服务时,缓存中的数据不能恢复,导致用户需要重新登录认证,体验很差。因此利用第三…...
——@BuilderParam装饰器)
HarmonyOS(七)——@BuilderParam装饰器
前言: 前面我们认识了Builder装饰器:自定义构建函数,今天我们继续认识下一个装饰器——BuilderParam装饰器。 当开发者创建了自定义组件,并想对该组件添加特定功能时,例如在自定义组件中添加一个点击跳转操作。若直接…...
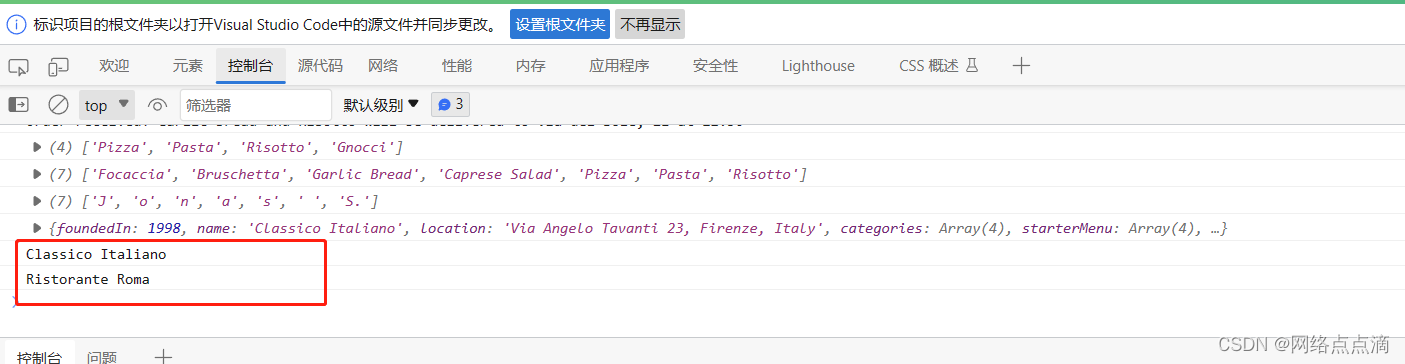
展开运算符(...)
假如我们有一个数组: const arr [7,8,9];● 我们如果想要数组中的元素,我们必须一个一个手动的去获取,如下: const arr [7,8,9]; const badNewArr [5, 6, arr[0], arr[1],arr[2]]; console.log(badNewArr);● 但是通过展开运…...
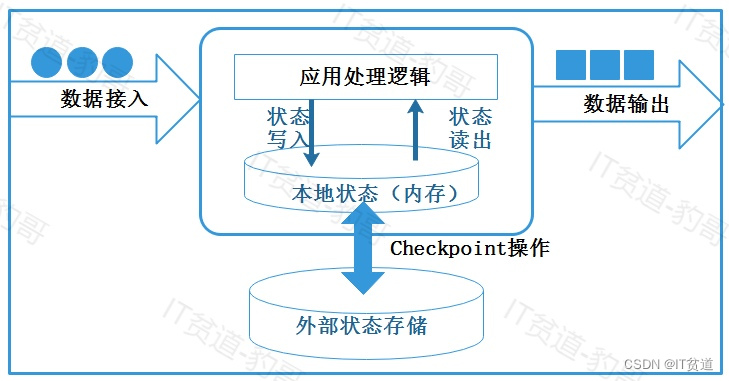
Apache Flink(二):数据架构演变
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...
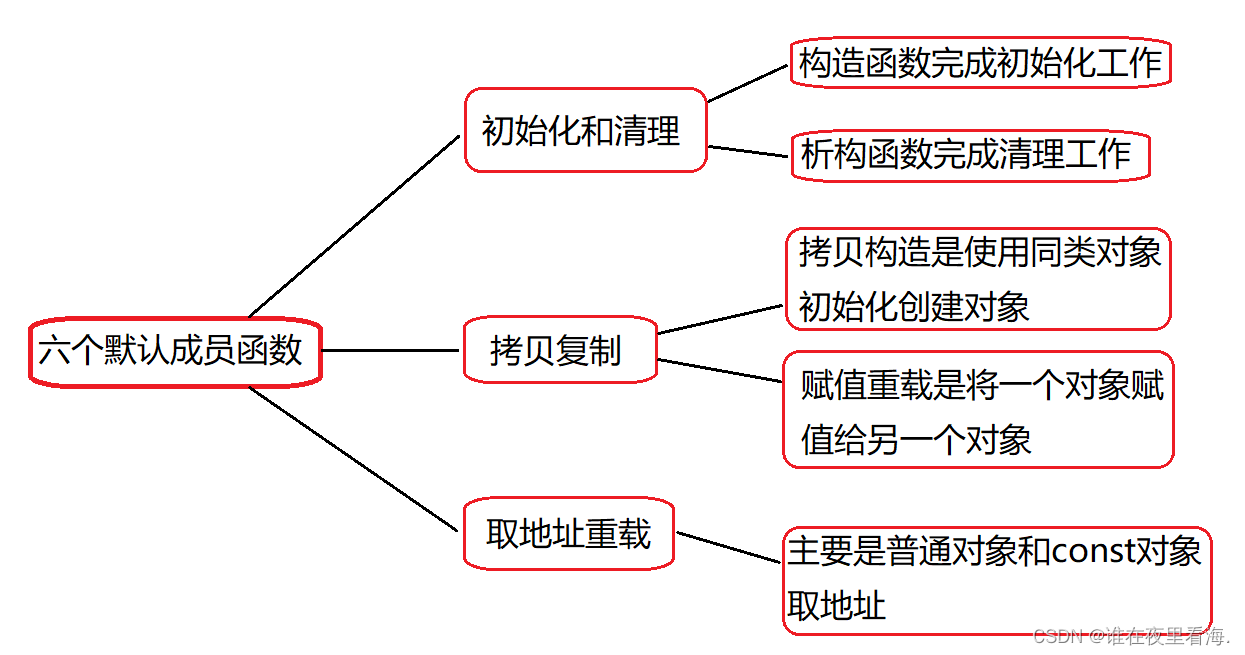
【C++】类与对象(中)
一、类的默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数:用户没有显式实现,编译器会自…...

webshell之无扩展免杀
1.php加密 这里是利用phpjiami网站进行加密,进而达到加密效果 加密前: 查杀效果 可以看到这里D某和某狗都查杀 里用php加密后效果 查杀效果 可以看到这里只有D某会显示加密脚本,而某狗直接绕过 2.dezend加密 可以看到dezend加密的特征还是…...

用 VirtualBox 安装 OpenWrt 等 Linux 系统,无法启动的解决办法
用 VirtualBox 安装 OpenWrt 等 Linux 系统,无法启动的解决办法 最近新买了台联想小新 Pro 14 2023 锐龙版,因为有 32GB 的运行内存,所以想安装虚拟机以充分发挥。一开始使用 Hyper-V 来安装可以正常使用,但是后面想使用 Virtual…...

Windows下搭建Tomcat HTTP服务,发布公网远程访问
文章目录 前言1.本地Tomcat网页搭建1.1 Tomcat安装1.2 配置环境变量1.3 环境配置1.4 Tomcat运行测试1.5 Cpolar安装和注册 2.本地网页发布2.1.Cpolar云端设置2.2 Cpolar本地设置 3.公网访问测试4.结语 前言 Tomcat作为一个轻量级的服务器,不仅名字很有趣࿰…...

k8s-daemonset、job、cronjob控制器 6
Daemonset控制器(一个节点部署一个) 、 创建Daemonset控制器 控制节点上不能进行部署,有污点 解决方式: 扩容节点,token值过期的解决方法: 回收pod job控制器 需要使用perl镜像,仓库没有&…...

技术面时,一定要掌握这3个关键点
前言 现在有这么多优秀的测试工程师,大家都知道技术面试是不可避免的一个环节,一般技术面试官都会通过自己的方式去考察你的技术功底与基础理论知识。 如果你参加过一些大厂面试,肯定会遇到一些这样的问题: 1、看你项目都用到了…...
[Linux]进程创建➕进程终止
文章目录 1.再谈fork()函数1.1fork()创建子进程 OS都做了哪些工作?1.2对上述问题的理解1.3写时拷贝进行父子进程分离的优势1.4了解eip寄存器和pc1.5了解进程的上下文数据1.6对计算机组成的理解1.7fork常规用法1.8fork调用失败的原因 2.进程终止2.1进程终止时操作系统要做的工作…...
)
【隐私计算】算术秘密分享的加法和乘法运算(Beaver Triple预处理)
在安全多方计算中(MPC)中,算术秘密分享是最基础的机制。一直有在接触,但是一直没有整理清楚最基础的加法和乘法计算流程。 算术秘密分享 概念: 一个位宽为 l l l-bit的数 x x x,被拆分为两个在 Z 2 l \ma…...
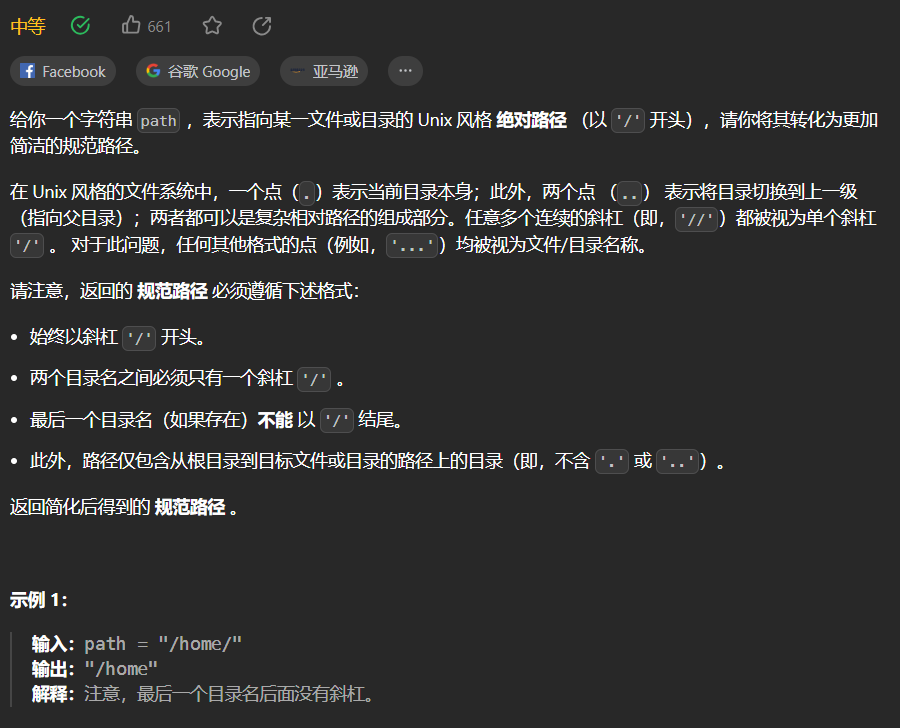
【LeetCode刷题-字符串】--71.简化路径
71.简化路径 思路: 对于给定的字符串,先根据/分割成一个由若干字符串组成的列表,记为names,根据题意names中包含的字符串只能是以下几种: 空字符串一个点两个点只包含英文字母、数字或_的目录名 对于空字符串和一个…...

数据结构与算法(Java)-树形DP题单
树形DP(灵神笔记) 543 二叉树的直径 543. 二叉树的直径 - 力扣(LeetCode) 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根…...
C#,《小白学程序》第一课:初识程序,变量,数据与显示
曰:扫地僧练就绝世武功的目的是为了扫地更干净。 1 引言 编程只是一项技术,如包包子,不是什么高深的科学。 学习程序最不好的方法是先学习枯燥的语法。 学习程序主要是用代码解决问题。因此,我们抛开所有的语法与诸多废物&…...

oracle的sysaux使用量排查sql
水1篇工具sql SELECT OCCUPANT_NAME,OCCUPANT_DESC,SCHEMA_NAME,MOVE_PROCEDURE,MOVE_PROCEDURE_DESC,SPACE_USAGE_KBYTES SPACE_USAGE_KB,ROUND(SPACE_USAGE_KBYTES / 1024 / 1024,2) SPACE_USAGE_GFROM V$SYSAUX_OCCUPANTS DORDER BY D.SPACE_USAGE_KBYTES DESC; 分享些经…...
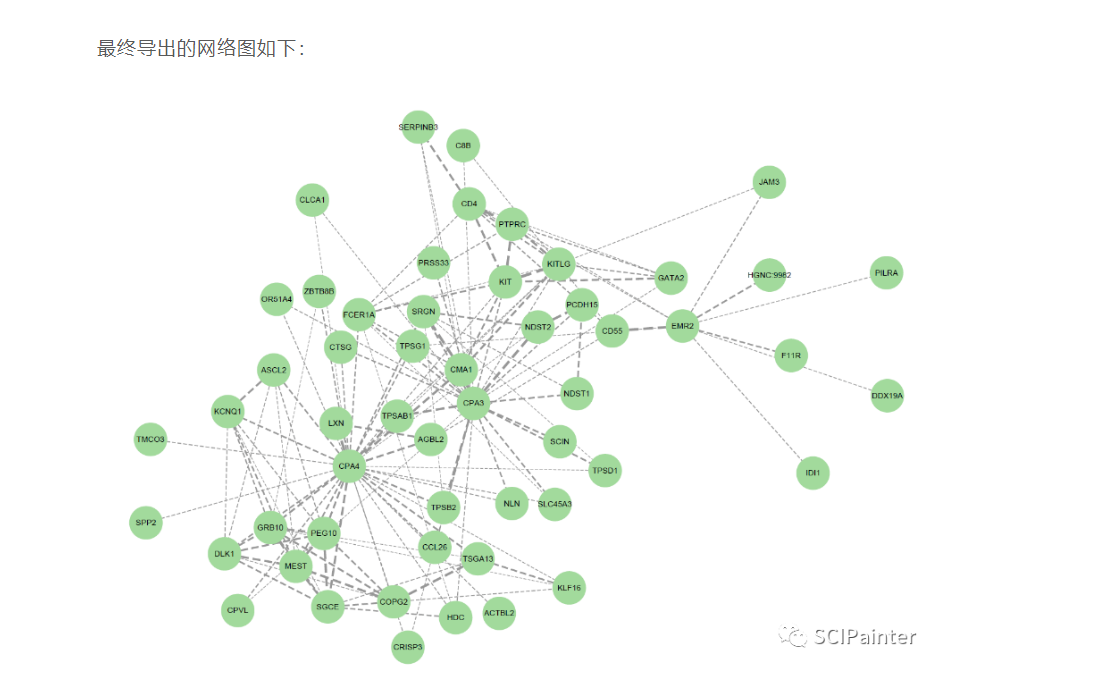
Cytoscape软件下载、安装、插件学习[基础教程]
写在前面 今天分享的内容是自己遇到问题后,咨询社群里面的同学,帮忙解决的总结。 关于Cytoscape,对于做组学或生物信息学的同学基本是陌生的,可能有的同学用这个软件作图是非常溜的,做出来的网络图也是十分的好看&am…...
[Linux] linux防火墙
一、防火墙是什么 防火墙(FireWall):隔离功能,工作在网络或主机的边缘,数据包的匹配规则与由一组功能定义的操作组件处理的规则相匹配,根据特定规则检查网络或主机的入口和出口 当要这样做时,基…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...