BiLSTM-CRF的中文命名实体识别
项目地址:NLP-Application-and-Practice/11_BiLSTM-ner-bilstm-crf/11.3-BiLSTM-CRF的中文命名实体识别/ner_bilstm_crf at master · zz-zik/NLP-Application-and-Practice (github.com)
读取renmindata.pkl文件
read_file_pkl.py
# encoding:utf-8import pickle# 读取数据
def load_data():pickle_path = './data_target_pkl/renmindata.pkl'with open(pickle_path, 'rb') as inp:word2id = pickle.load(inp)id2word = pickle.load(inp)tag2id = pickle.load(inp)id2tag = pickle.load(inp)x_train = pickle.load(inp)y_train = pickle.load(inp)x_test = pickle.load(inp)y_test = pickle.load(inp)x_valid = pickle.load(inp)y_valid = pickle.load(inp)print("train len:", len(x_train))print("test len:", len(x_test))print("valid len:", len(x_valid))return word2id, tag2id, x_train, x_test, x_valid, y_train, y_test, y_valid, id2tagdef main():word = load_data()print(len(word))if __name__ == '__main__':main()
这段代码定义了一个函数load_data(),用于读取存储在文件'../data_target_pkl/renminddata.pkl'中的数据。函数首先使用pickle模块打开文件,然后逐个加载文件中的数据并赋值给相应的变量。最后,打印出训练集、测试集和验证集的长度,并返回这些变量。在main()函数中,调用load_data()函数并打印其返回值。这段代码的目的是读取并加载pickle文件中的数据,并在main()函数中测试load_data()函数的正确性。
构建BiLSTM-CRF
bilstm_crf_model.py
# encoding:utf-8import torch
import torch.nn as nn
from TorchCRF import CRF
from torch.utils.data import Dataset# 命名体识别数据
class NERDataset(Dataset):def __init__(self, X, Y, *args, **kwargs):self.data = [{'x': X[i], 'y': Y[i]} for i in range(X.shape[0])]def __getitem__(self, index):return self.data[index]def __len__(self):return len(self.data)# LSTM_CRF模型
class NERLSTM_CRF(nn.Module):def __init__(self, config):super(NERLSTM_CRF, self).__init__()self.embedding_dim = config.embedding_dimself.hidden_dim = config.hidden_dimself.vocab_size = config.vocab_sizeself.num_tags = config.num_tagsself.embeds = nn.Embedding(self.vocab_size, self.embedding_dim)self.dropout = nn.Dropout(config.dropout)self.lstm = nn.LSTM(self.embedding_dim,self.hidden_dim // 2,num_layers=1,bidirectional=True,batch_first=True, # 该属性设置后,需要特别注意数据的形状)self.linear = nn.Linear(self.hidden_dim, self.num_tags)# CRF 层self.crf = CRF(self.num_tags)def forward(self, x, mask):embeddings = self.embeds(x)feats, hidden = self.lstm(embeddings)emissions = self.linear(self.dropout(feats))outputs = self.crf.viterbi_decode(emissions, mask)return outputsdef log_likelihood(self, x, labels, mask):embeddings = self.embeds(x)feats, hidden = self.lstm(embeddings)emissions = self.linear(self.dropout(feats))loss = -self.crf.forward(emissions, labels, mask)return torch.sum(loss)# ner chinese这段代码定义了一个用于命名体识别的LSTM_CRF模型。NERDataset类是一个自定义的用于存储命名体识别数据的类,继承自torch.utils.data.Dataset。NERLSTM_CRF类是一个自定义的继承自torch.nn.Module的类,用于实现LSTM_CRF模型的前向传播和训练过程。该模型包含嵌入层、LSTM层、线性层和CRF层。通过调用log_likelihood方法可以计算给定输入序列的对数似然。
模型信息
utils.py
# encoding:utf-8
import torch
from utils import load_data
from utils import parse_tags
from utils import utils_to_train
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_reportword2id = load_data()[0]
max_epoch, device, train_data_loader, valid_data_loader, test_data_loader, optimizer, model = utils_to_train()# 中文命名体识别
class ChineseNER(object):def train(self):for epoch in range(max_epoch):# 训练模式model.train()for index, batch in enumerate(train_data_loader):# 梯度归零optimizer.zero_grad()# 训练数据-->gpux = batch['x'].to(device)mask = (x > 0).to(device)y = batch['y'].to(device)# 前向计算计算损失loss = model.log_likelihood(x, y, mask)# 反向传播loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(parameters=model.parameters(),max_norm=10)# 更新参数optimizer.step()if index % 200 == 0:print('epoch:%5d,------------loss:%f' %(epoch, loss.item()))# 验证损失和精度aver_loss = 0preds, labels = [], []for index, batch in enumerate(valid_data_loader):# 验证模式model.eval()# 验证数据-->gpuval_x, val_y = batch['x'].to(device), batch['y'].to(device)val_mask = (val_x > 0).to(device)predict = model(val_x, val_mask)# 前向计算损失loss = model.log_likelihood(val_x, val_y, val_mask)aver_loss += loss.item()# 统计非0的,也就是真实标签的长度leng = []res = val_y.cpu()for i in val_y.cpu():tmp = []for j in i:if j.item() > 0:tmp.append(j.item())leng.append(tmp)for index, i in enumerate(predict):preds += i[:len(leng[index])]for index, i in enumerate(val_y.tolist()):labels += i[:len(leng[index])]# 损失值与评测指标aver_loss /= (len(valid_data_loader) * 64)precision = precision_score(labels, preds, average='macro')recall = recall_score(labels, preds, average='macro')f1 = f1_score(labels, preds, average='macro')report = classification_report(labels, preds)print(report)torch.save(model.state_dict(), 'params1.data_target_pkl')# 预测,输入为单句,输出为对应的单词和标签def predict(self, input_str=""):model.load_state_dict(torch.load("../models/ner/params1.data_target_pkl"))model.eval()if not input_str:input_str = input("请输入文本: ")input_vec = []for char in input_str:if char not in word2id:input_vec.append(word2id['[unknown]'])else:input_vec.append(word2id[char])# convert to tensorsentences = torch.tensor(input_vec).view(1, -1).to(device)mask = sentences > 0paths = model(sentences, mask)res = parse_tags(input_str, paths[0])return res# 在测试集上评判性能def test(self, test_dataloader):model.load_state_dict(torch.load("../models/ner/params1.data_target_pkl"))aver_loss = 0preds, labels = [], []for index, batch in enumerate(test_dataloader):# 验证模式model.eval()# 验证数据-->gpuval_x, val_y = batch['x'].to(device), batch['y'].to(device)val_mask = (val_x > 0).to(device)predict = model(val_x, val_mask)# 前向计算损失loss = model.log_likelihood(val_x, val_y, val_mask)aver_loss += loss.item()# 统计非0的,也就是真实标签的长度leng = []for i in val_y.cpu():tmp = []for j in i:if j.item() > 0:tmp.append(j.item())leng.append(tmp)for index, i in enumerate(predict):preds += i[:len(leng[index])]for index, i in enumerate(val_y.tolist()):labels += i[:len(leng[index])]# 损失值与评测指标aver_loss /= len(test_dataloader)precision = precision_score(labels, preds, average='macro')recall = recall_score(labels, preds, average='macro')f1 = f1_score(labels, preds, average='macro')report = classification_report(labels, preds)print(report)if __name__ == '__main__':cn = ChineseNER()cn.train()
这段代码定义了一个用于命名实体识别的模型和训练函数。其中,parse_tags函数用于将模型的预测结果解码成可读的实体类别;Config类定义了一些超参数;utils_to_train函数返回训练过程中需要用到的各种对象和参数。
BiLSTM-CRF的训练
train.py
# encoding:utf-8
import torch
from utils import load_data
from utils import parse_tags
from utils import utils_to_train
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import classification_reportword2id = load_data()[0]
max_epoch, device, train_data_loader, valid_data_loader, test_data_loader, optimizer, model = utils_to_train()# 中文命名体识别
class ChineseNER(object):def train(self):for epoch in range(max_epoch):# 训练模式model.train()for index, batch in enumerate(train_data_loader):# 梯度归零optimizer.zero_grad()# 训练数据-->gpux = batch['x'].to(device)mask = (x > 0).to(device)y = batch['y'].to(device)# 前向计算计算损失loss = model.log_likelihood(x, y, mask)# 反向传播loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(parameters=model.parameters(),max_norm=10)# 更新参数optimizer.step()if index % 200 == 0:print('epoch:%5d,------------loss:%f' %(epoch, loss.item()))# 验证损失和精度aver_loss = 0preds, labels = [], []for index, batch in enumerate(valid_data_loader):# 验证模式model.eval()# 验证数据-->gpuval_x, val_y = batch['x'].to(device), batch['y'].to(device)val_mask = (val_x > 0).to(device)predict = model(val_x, val_mask)# 前向计算损失loss = model.log_likelihood(val_x, val_y, val_mask)aver_loss += loss.item()# 统计非0的,也就是真实标签的长度leng = []res = val_y.cpu()for i in val_y.cpu():tmp = []for j in i:if j.item() > 0:tmp.append(j.item())leng.append(tmp)for index, i in enumerate(predict):preds += i[:len(leng[index])]for index, i in enumerate(val_y.tolist()):labels += i[:len(leng[index])]# 损失值与评测指标aver_loss /= (len(valid_data_loader) * 64)precision = precision_score(labels, preds, average='macro')recall = recall_score(labels, preds, average='macro')f1 = f1_score(labels, preds, average='macro')report = classification_report(labels, preds)print(report)torch.save(model.state_dict(), 'params1.data_target_pkl')# 预测,输入为单句,输出为对应的单词和标签def predict(self, input_str=""):model.load_state_dict(torch.load("../models/ner/params1.data_target_pkl"))model.eval()if not input_str:input_str = input("请输入文本: ")input_vec = []for char in input_str:if char not in word2id:input_vec.append(word2id['[unknown]'])else:input_vec.append(word2id[char])# convert to tensorsentences = torch.tensor(input_vec).view(1, -1).to(device)mask = sentences > 0paths = model(sentences, mask)res = parse_tags(input_str, paths[0])return res# 在测试集上评判性能def test(self, test_dataloader):model.load_state_dict(torch.load("../models/ner/params1.data_target_pkl"))aver_loss = 0preds, labels = [], []for index, batch in enumerate(test_dataloader):# 验证模式model.eval()# 验证数据-->gpuval_x, val_y = batch['x'].to(device), batch['y'].to(device)val_mask = (val_x > 0).to(device)predict = model(val_x, val_mask)# 前向计算损失loss = model.log_likelihood(val_x, val_y, val_mask)aver_loss += loss.item()# 统计非0的,也就是真实标签的长度leng = []for i in val_y.cpu():tmp = []for j in i:if j.item() > 0:tmp.append(j.item())leng.append(tmp)for index, i in enumerate(predict):preds += i[:len(leng[index])]for index, i in enumerate(val_y.tolist()):labels += i[:len(leng[index])]# 损失值与评测指标aver_loss /= len(test_dataloader)precision = precision_score(labels, preds, average='macro')recall = recall_score(labels, preds, average='macro')f1 = f1_score(labels, preds, average='macro')report = classification_report(labels, preds)print(report)if __name__ == '__main__':cn = ChineseNER()cn.train()
这段代码实现了一个中文命名体识别的训练和预测功能。通过加载数据和训练参数,使用循环神经网络模型进行训练和验证,计算损失和评估指标,然后在测试集上进行性能评估。最后,提供一个函数用于对输入文本进行预测,并返回预测结果。
相关文章:

BiLSTM-CRF的中文命名实体识别
项目地址:NLP-Application-and-Practice/11_BiLSTM-ner-bilstm-crf/11.3-BiLSTM-CRF的中文命名实体识别/ner_bilstm_crf at master zz-zik/NLP-Application-and-Practice (github.com) 读取renmindata.pkl文件 read_file_pkl.py # encoding:utf-8import pickle# …...

paddle detection 训练参数
#####################################基础配置##################################### # 检测算法使用YOLOv3,backbone使用MobileNet_v1,数据集使用roadsign_voc的配置文件模板,本配置文件默认使用单卡,单卡的batch_size=1 # 检测模型的名称 architecture: YOLOv3 # 根据…...
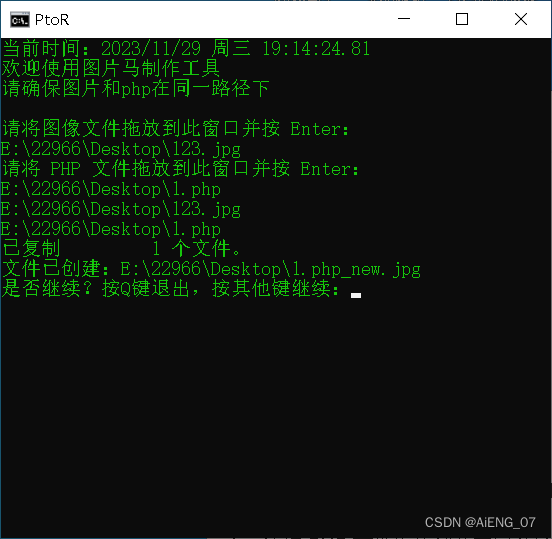
用bat制作图片马——一句话木马
效果图 代码 ECHO OFF TITLE PtoR MODE con COLS55 LINES25 color 0A:main cls echo.当前时间:%date% %time% echo.欢迎使用图片马制作工具 echo.请确保图片和php在同一路径下 echo.echo 请将图像文件拖放到此窗口并按 Enter: set /p "imagefile&q…...
 返回 false)
json_encode() 返回 false
当 json_encode() 返回 false 时,表示 JSON 编码过程失败。这通常是因为要编码的数据包含了无效的 UTF-8 字符,而默认情况下 json_encode() 会对无效的 UTF-8 字符进行严格的处理 通过添加 JSON_INVALID_UTF8_IGNORE 选项,你告诉 json_encod…...

Android-Jetpack--Hilt详解
善学者尽其理,善行者究其难 一,定义 Hilt是针对dagger2的二次封装依赖注入框架,至于什么是依赖注入,在Android开源框架--Dagger2详解-CSDN博客 中已经讲解,建议大家先去了解Dagger2之后,再来看Hilt。这样就…...

Docker 下载加速
文章目录 方式1:使用 网易数帆容器镜像仓库进行下载。方式2:配置阿里云加速。方式3:方式4:结尾注意 Docker下载加速的原理是,在拉取镜像时使用一个国内的镜像站点,该站点已经缓存了各个版本的官方 Docker 镜…...
)
1091 Acute Stroke (三维搜索)
题目可能看起来很难的样子,但是看懂了其实挺简单的。(众所周知,pat考察英文水平) 题目意思大概是:给你一个L*M*N的01长方体,求全为1的连通块的总体积大小。(连通块体积大于T才计算在内…...
)
java elasticsearch 桶聚合(bucket)
Elasticsearch指标聚合,就是类似SQL的统计函数,指标聚合可以单独使用,也可以跟桶聚合一起使用,下面介绍Java Elasticsearch指标聚合的写法。 实例: // 首先创建RestClient,后续章节通过RestClient对象进行…...
Python 常用内置数据类型 II —— 序列数据类型(str、tuple、list、bytes和bytearray))
【人生苦短,我学 Python】(4)Python 常用内置数据类型 II —— 序列数据类型(str、tuple、list、bytes和bytearray)
目录 简述 / 前言1. str 数据类型(字符串)1.1 str对象1.2 str对象属性和方法1.3 字符串编码1.4 转义字符1.5 字符串的格式化 2. tuple 数据类型(元组)2.1 创建元组对象 3. list 数据类型(列表)3.1 创建列表…...

Android 9.0 系统默认显示电量百分比
Android 9.0 系统默认显示电量百分比 近来收到项目需求需要设备默认显示电量百分比,具体修改参照如下: /frameworks/base/packages/SystemUI/src/com/android/systemui/BatteryMeterView.java private void updateShowPercent() {final boolean showin…...

原神:夏洛蒂是否值得培养?全队瞬抬治疗量不输五星,但缺点也很明显
作为四星冰系治疗角色,夏洛蒂的实战表现可以说相当让人惊喜。不仅有相当有意思的普攻动作以及技能特效,而且她还有治疗和挂冰等功能性。下面就来详细聊聊夏洛蒂是否值得培养。 【治疗量让人惊喜,但也有缺点】 说实话,在使用夏洛蒂…...

Sublime text 添加到鼠标右键菜单,脚本实现
Sublime text 添加到鼠标右键菜单 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\*\shell\SublimeText] "Open with Sublime Text" "Icon""D:\\Program Files\\Sublime Text\\sublime_text.exe,0" [HKEY_CLASSES_ROOT\*\shell\Subl…...

【算法】离散化 与 哈希 之间的区别
离散化(Discretization)和哈希(Hashing)是两种不同的数据处理技术,用于处理不同类型的问题。 1. 离散化(Discretization): 离散化是将一组连续的数据映射到有限个离散值的过程。主要…...

Android : GPS定位 获取当前位置—简单应用
示例图: MainActivity.java package com.example.mygpsapp;import androidx.annotation.NonNull; import androidx.appcompat.app.AppCompatActivity; import androidx.core.app.ActivityCompat; import androidx.core.content.ContextCompat;import android.Manif…...
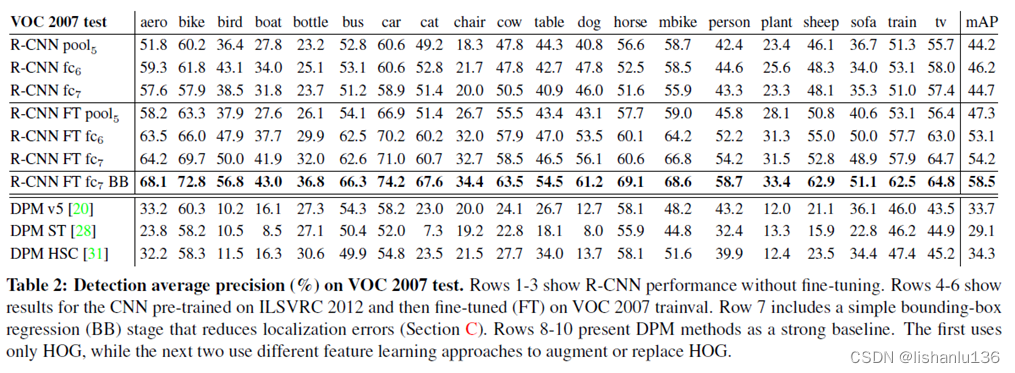
目标检测——R-CNN算法解读
论文:Rich feature hierarchies for accurate object detection and semantic segmentation 作者:Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik 链接:https://arxiv.org/abs/1311.2524 代码:http://www.cs.berke…...
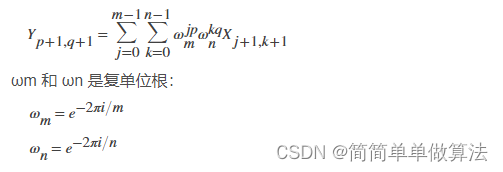
基于傅里叶变换的运动模糊图像恢复算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1、傅里叶变换与图像恢复 4.2、基于傅里叶变换的运动模糊图像恢复算法原理 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 %获取角度 img…...
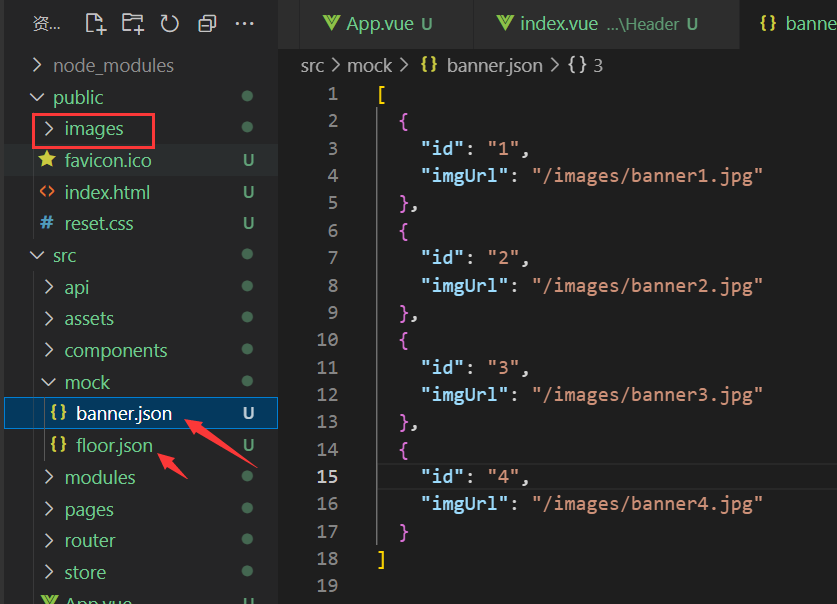
使用mock.js模拟数据
一、安装mock.js npm i mockjs 二、配置JSON文件 我们创建一个mock文件夹,用于存放mock相关的模拟数据和代码实现。 我们将数据全部放在xxx.json文件夹下,里面配置我们需要的JSON格式的数据。 注意:json文件中不要留有空格,否则…...

Android Handler同步屏障:深入解析
Android Handler同步屏障:深入解析 在Android开发中,Handler和MessageQueue是处理线程间通信的重要组件。除了常见的消息发送和处理功能,Handler还提供了一个高级特性:同步屏障。本文将深入探讨这一特性,包括它的工作…...
HT for Web (Hightopo) 使用心得(5)- 动画的实现
其实,在 HT for Web 中,有多种手段可以用来实现动画。我们这里仍然用直升机为例,只是更换了场景。增加了巡游过程。 使用 HT 开发的一个简单网页直升机巡逻动画(Hightopo 使用心得(5)) 这里主…...
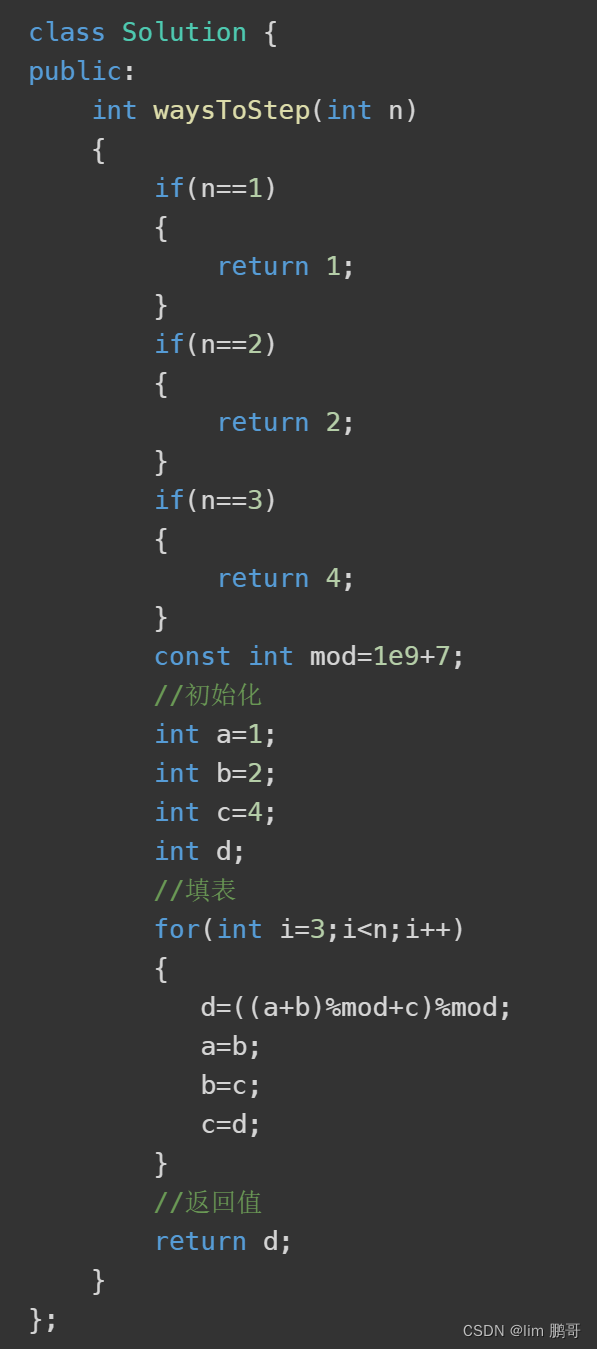
Leetcode(面试题 08.01.)三步问题
文章目录 前言一、题目分析二、算法原理1.状态表示2.状态转移方程3.初始化4.填表顺序5.返回值是什么 三、代码实现总结 前言 在本文章中,我们将要详细介绍一下Leetcode(面试题 08.01.)三步问题相关的内容 一、题目分析 1.小孩可以上一阶,两阶ÿ…...

滨会生物冲刺港股:年亏1.2亿 乐普生物与扬子江药业是股东
雷递网 雷建平 4月5日武汉滨会生物科技股份有限公司(简称:“滨会生物”)日前更新招股书,准备在港交所上市。滨会生物总计募资超10亿元,其中,2021年2月完成募资6亿元,2022年7月完成募资2.4亿元&a…...

力扣热门100题之最大子数组和
最优解法:Kadane 算法(一遍遍历)核心思想遍历数组时,维护当前最大和如果前面的和是负数,只会拖累当前数,直接抛弃前面否则,把当前数加进去全程记录最大值完整代码实现:class Solutio…...

VS2019+CMake实战:Super4PCS点云配准从源码编译到运行全流程指南
VS2019CMake实战:Super4PCS点云配准从源码编译到运行全流程指南 在三维视觉和机器人领域,点云配准一直是核心难题之一。Super4PCS算法作为4PCS的改进版本,以其在低重叠率点云上的优异表现,成为工业检测和SLAM系统中的热门选择。本…...

百度飞桨PaddleOCR图片印章检测技术简介
百度飞桨PaddleOCR图片印章检测技术简介 全文链接 百度飞桨PaddleOCR图片印章检测技术简介 github仓库:使用PaddleOCR识别图片红色印章文字 red-seal-ocr 3.X和2.X区别较大,建议使用3.X版本。 PaddleX简介 PaddleX github地址PaddleX模型产线使用概览…...

08_微服务划分与团队人数之监控治理与跨团队协作
微服务划分与团队人数之监控治理与跨团队协作 体系内容 可观测性三支柱:指标、日志、链路追踪 治理要素:SLO、Dashboard、告警分级、容量视图、契约审计 Spring Cloud Alibaba 关联:Nacos、Sentinel、Gateway、RocketMQ、Dubbo 与观测平台协同 跨团队机制:接口契约、消息契…...

**发散创新:基于Python的本体推理与知识表示实战解析**在人工智能和语义网技术飞速发展的今天,**知识表
发散创新:基于Python的本体推理与知识表示实战解析 在人工智能和语义网技术飞速发展的今天,知识表示(Knowledge Representation) 已成为构建智能系统的底层核心能力之一。它不仅决定了系统对现实世界的理解深度,还直接…...

jEasyUI 显示海量数据
jEasyUI 显示海量数据 引言 随着互联网技术的飞速发展,大数据时代已经到来。在众多前端框架中,jEasyUI以其简洁、易用、功能强大等特点,受到了广大开发者的喜爱。本文将深入探讨jEasyUI在显示海量数据方面的应用,帮助开发者更好地应对大数据挑战。 jEasyUI简介 jEasyUI…...

2026届最火的六大降AI率平台实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要让AIGC(人工智能生成内容)检测率降低,关键之处便在于把…...

Kazumi插件扩展完全指南:从安装到高级配置
Kazumi插件扩展完全指南:从安装到高级配置 【免费下载链接】Kazumi 基于自定义规则的番剧采集APP,支持流媒体在线观看,支持弹幕,支持实时超分辨率。 项目地址: https://gitcode.com/gh_mirrors/ka/Kazumi Kazumi作为一款基…...

2026届学术党必备的六大AI辅助论文方案解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 跟随着人工智能技术以较快速度发展,AI工具于毕业论文写作阶段的应用越发广泛起来…...