文档理解的新时代:LayOutLM模型的全方位解读
一、引言
在现代文档处理和信息提取领域,机器学习模型的作用日益凸显。特别是在自然语言处理(NLP)技术快速发展的背景下,如何让机器更加精准地理解和处理复杂文档成为了一个挑战。文档不仅包含文本信息,还包括布局、图像等非文本元素,这些元素在传递信息时起着至关重要的作用。传统的NLP模型通常忽略了这些视觉元素,但LayOutLM模型的出现改变了这一局面。
LayOutLM模型是一种创新的深度学习模型,它结合了传统的文本处理能力和对文档布局的理解,从而在处理包含丰富布局信息的文档时表现出色。这种模型的设计思想源于对现实世界文档处理需求的深刻理解。例如,在处理一份报告时,我们不仅关注报告中的文字内容,还会关注图表、标题、段落布局等视觉信息。这些信息帮助我们更好地理解文档的结构和内容重点。
为了说明LayOutLM模型的重要性和实用性,我们可以考虑一份含有多种元素(如文本、表格、图片)的商业合同。在这样的文档中,合同的条款可能以不同的字体或布局突出显示,而关键的图表和数据则以特定的方式呈现。传统的文本分析模型可能无法有效地识别和处理这些复杂的布局和视觉信息,导致信息提取不完整或不准确。而LayOutLM模型则能够识别这些元素,准确提取关键信息,从而大大提高文档处理的效率和准确性。
在接下来的章节中,我们将详细探讨LayOutLM模型的架构、技术实现细节以及在实际场景中的应用。通过深入了解LayOutLM模型,读者将能够更好地理解其在现代文档理解领域的独特价值和广泛应用前景。
二、LayOutLM模型详解
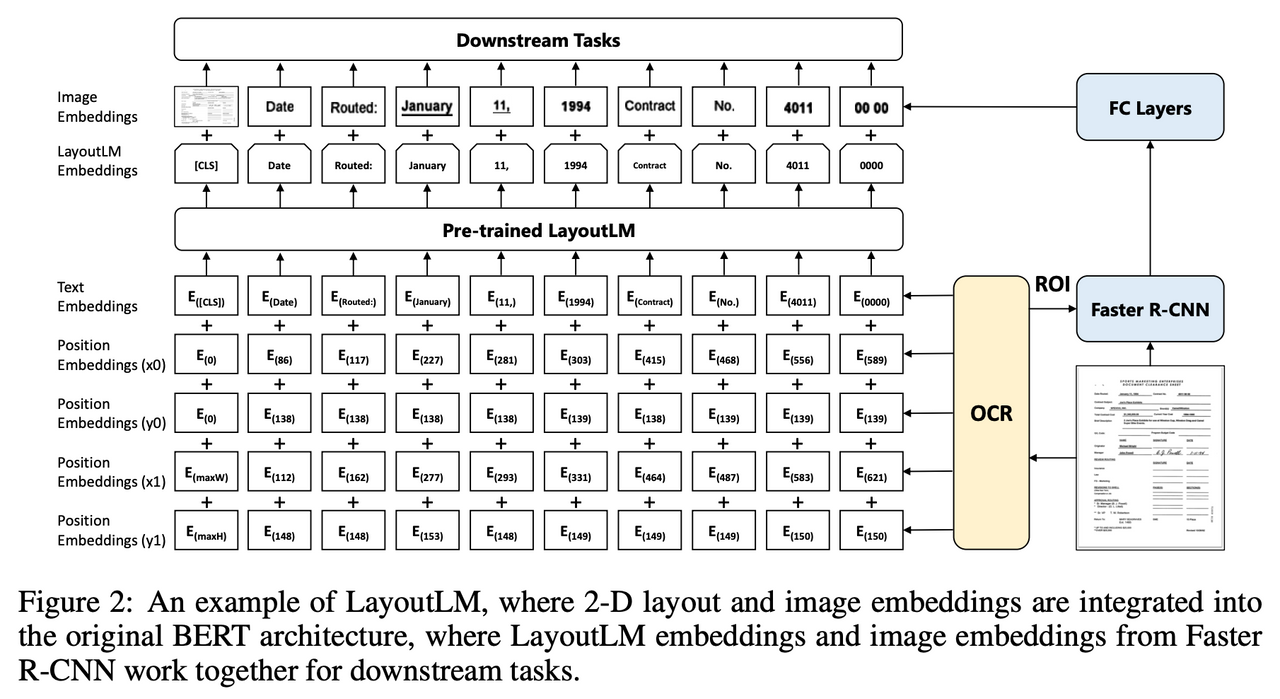
LayOutLM模型代表了自然语言处理(NLP)与计算机视觉(CV)交叉领域的一大步。它不仅理解文本内容,还融入了文档的布局信息,为文档理解带来了革新性的进步。接下来,我们将深入探讨LayOutLM模型的关键组成部分、工作原理和实际应用。
模型架构概览
LayOutLM采用了与BERT类似的架构,但它在输入表示中加入了视觉特征。这些视觉特征来自文档中的每个词的布局信息,如位置坐标和页面信息。LayOutLM利用这些信息来理解文本在视觉页面上的分布,这在处理表格、表单和其他布局密集型文档时特别有用。
输入表示方法
在LayOutLM中,每个词的输入表示由以下几部分组成:
- 文本嵌入: 类似于传统的NLP模型,使用词嵌入来表示文本信息。
- 位置嵌入: 表示词在文本序列中的位置。
- 布局嵌入: 新增加的特征,包括词在页面上的相对位置(例如左上角坐标和右下角坐标)。
例如,考虑一个简单的发票文档,包含“发票号码”和具体的数字。LayOutLM不仅理解这些词的语义,还能通过布局嵌入识别数字是紧跟在“发票号码”标签后面的,从而有效地提取信息。
预训练任务和过程
LayOutLM的预训练包括多种任务,旨在同时提高模型的语言理解和布局理解能力。这些任务包括:
- 掩码语言模型(MLM): 类似于BERT,部分词被掩盖,模型需要预测它们。
- 布局预测: 模型不仅预测掩盖的词,还预测它们的布局信息。
微调和应用
在预训练完成后,LayOutLM可以针对特定任务进行微调。例如,在表单理解任务中,可以用具有标注的表单数据对模型进行微调,使其更好地理解和提取表单中的信息。
# 示例代码: LayOutLM模型微调
from transformers import LayoutLMForTokenClassification# 加载预训练的LayOutLM模型
model = LayoutLMForTokenClassification.from_pretrained('microsoft/layoutlm-base-uncased')# 微调模型(伪代码)
train_dataloader = ... # 定义训练数据
optimizer = ... # 定义优化器for epoch in range(num_epochs):for batch in train_dataloader:inputs = batch['input_ids']labels = batch['labels']outputs = model(inputs, labels=labels)loss = outputs.lossloss.backward()optimizer.step()
在这一部分,我们通过深入分析LayOutLM模型的架构和工作机制,展示了其在理解包含丰富布局信息的文档方面的强大能力。通过举例和代码展示,我们希望读者能够更全面地理解LayOutLM模型的工作原理和应用场景。在接下来的章节中,我们将进一步探讨LayOutLM在实际应用中的表现和实战指南。
三、LayOutLM在实际中的应用
LayOutLM模型不仅在理论上具有创新性,更在实际应用中显示出其强大的能力。本节将探讨LayOutLM在多个实际场景中的应用,通过具体的例证来阐明其在解决实际问题中的有效性和灵活性。
文档分类与排序
在企业和机构的日常工作中,大量的文档需要被分类和归档。传统方法依赖于文本内容的关键词搜索,但LayOutLM可以进一步利用文档的布局信息。例如,不同类型的报告、发票或合同通常具有独特的布局特征。LayOutLM能够识别这些特征,从而更准确地将文档分类。

信息提取
信息提取是LayOutLM的另一个重要应用场景。在处理发票、收据等文档时,关键信息(如总金额、日期、项目列表)通常分布在不同的位置,且每个文档的布局可能略有不同。LayOutLM利用其对布局的理解,能够准确地从这些文档中提取所需信息。例如,从一堆杂乱的发票中提取出所有的发票号码和金额,即便它们的布局不尽相同。

表单处理
在表单处理中,LayOutLM的应用尤为突出。不同于传统的基于规则的处理方法,LayOutLM可以理解表单中的问题和答案的布局关系。这使得在自动化处理问卷调查或申请表时,模型可以更加高效和准确地提取出关键信息。

自动化文档审核
在法律和金融领域,文档审核是一项关键任务。LayOutLM可以辅助审核人员快速地找出文档中的关键条款或可能存在的问题。例如,在一份合同中,模型可以快速定位到关键的责任条款或特殊的免责声明,辅助法律专业人士进行深入分析。

通过上述应用案例,可以看出LayOutLM模型在实际中的广泛应用和显著效果。这些例证不仅展示了LayOutLM在处理具有复杂布局的文档方面的能力,也说明了其在提高工作效率和准确性方面的巨大潜力。接下来的章节将进一步提供实战指南,帮助读者了解如何在自己的项目中实施和优化LayOutLM模型。
四、实战指南
在本节中,我们将提供一个基于Python和PyTorch的实战指南,展示如何使用LayOutLM模型进行文档理解任务。我们将通过一个实际场景——从一组商业发票中提取关键信息——来演示LayOutLM的实现和应用。
场景描述
假设我们有一批不同格式的商业发票,需要从中提取关键信息,如发票号、日期、总金额等。这些发票在布局上有所差异,但都包含了上述关键信息。
输入和输出
- 输入: 一批包含文本和布局信息的发票图像。
- 输出: 提取的关键信息,如发票号、日期和总金额。
处理过程
-
环境准备: 安装必要的库。
pip install transformers torch torchvision -
模型加载: 加载预训练的LayOutLM模型。
from transformers import LayoutLMForTokenClassification, LayoutLMTokenizermodel_name = 'microsoft/layoutlm-base-uncased' model = LayoutLMForTokenClassification.from_pretrained(model_name) tokenizer = LayoutLMTokenizer.from_pretrained(model_name) -
数据准备: 对发票图像进行预处理,提取文本和布局信息。
# 这里是一个示例函数,用于将发票图像转换为模型输入 def preprocess_invoice(image_path):# 实现图像的加载和预处理,提取文本和布局信息# 返回模型所需的输入格式,如tokenized text, attention masks, 和token type idspass# 示例:处理单个发票图像 input_data = preprocess_invoice("path_to_invoice_image.jpg") -
信息提取: 使用LayOutLM模型提取关键信息。
import torch# 调整输入数据以适应模型 input_ids = torch.tensor([input_data["input_ids"]]) token_type_ids = torch.tensor([input_data["token_type_ids"]]) attention_mask = torch.tensor([input_data["attention_mask"]])with torch.no_grad():outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)predictions = outputs.logits.argmax(dim=2) -
结果解析: 解析模型输出,提取和整理关键信息。
# 示例函数,用于解析模型的输出并提取信息 def extract_info(predictions, tokens):# 实现提取关键信息的逻辑# 返回结构化的信息,如发票号、日期和金额passtokens = input_data["tokens"] extracted_info = extract_info(predictions, tokens) -
后处理: 根据需要对提取的信息进行格式化和存储。
在以上步骤中,我们描述了使用LayOutLM模型从商业发票中提取关键信息的完整过程。请注意,数据预处理和结果解析步骤将依赖于具体的应用场景和数据格式。通过这个实战指南,读者应该能够理解如何在实际项目中部署和使用LayOutLM模型,从而解决复杂的文档理解任务。
五、结论
随着人工智能领域的迅速发展,模型如LayOutLM的出现不仅是技术进步的象征,更代表了我们对于信息处理方式的深刻理解和创新。LayOutLM模型在NLP和CV的交汇点上打开了新的可能性,为处理和理解复杂文档提供了新的视角和工具。这一点在处理具有丰富布局信息的文档时尤为明显,它不仅提升了信息提取的准确性,还极大地增强了处理效率。
域的独特洞见
-
跨领域融合的趋势: LayOutLM的成功展示了跨领域(如NLP和CV)融合的巨大潜力。这种跨学科的方法为解决复杂问题提供了新的思路,预示着未来人工智能发展的一个重要趋势。
-
对复杂数据的深层次理解: 传统的NLP模型在处理仅包含文本的数据时表现出色,但在面对包含多种数据类型(如文本、图像、布局)的复杂文档时则显得力不从心。LayOutLM的出现弥补了这一空缺,它的能力在于不仅理解文本内容,还能解读文档的视觉布局,展示了对更复杂数据的深层次理解。
-
实用性与应用广泛性: LayOutLM不仅在理论上具有创新性,而且在实际应用中表现出色。从商业发票的信息提取到法律文档的自动审核,这些应用案例证明了其在多个行业的广泛适用性和实用价值。
-
持续的创新与优化: 正如LayOutLM在现有技术上的进步,未来的研究可能会继续在模型的精度、速度和灵活性上进行优化。这可能包括更高效的训练方法、对更多种类的文档格式的支持,以及更加智能的上下文理解能力。
综上所述,LayOutLM模型不仅在技术上取得了显著的进展,更重要的是它为我们提供了一种全新的视角来看待和处理文档信息。随着人工智能技术的不断发展,我们可以预见到更多类似LayOutLM这样的模型将出现,并在各个领域发挥重要作用。在此过程中,对技术的深入理解和创新思维将是推动这一领域发展的关键。
相关文章:
文档理解的新时代:LayOutLM模型的全方位解读
一、引言 在现代文档处理和信息提取领域,机器学习模型的作用日益凸显。特别是在自然语言处理(NLP)技术快速发展的背景下,如何让机器更加精准地理解和处理复杂文档成为了一个挑战。文档不仅包含文本信息,还包括布局、图…...

【二叉树】Leetcode 637. 二叉树的层平均值
637.二叉树的层平均值 解题思路 根据层序遍历的模板进行修改;主要的不同是,不需要输出每一层所有节点值,只需要输出平均值,只需要定义一个double双精度浮点数储存每一层数的总和,输出时将总和除以层节点总数即为层平均…...

设计模式-15-Jdk源码中的设计模式
之前我们学习了一些设计模式,今天我们剖析Java JDK 源码中用到的几种常见的设计模式。 1-jdk之工厂模式 在前面讲到工厂模式的时候,大部分工厂类都是以Factory作为后缀来命名,并且工厂类主要负责创建对象这样一件事情。但在实际的项目开发中…...
Vue框架学习笔记——事件scroll和wheel的区别
文章目录 前文提要滚动条滚动事件 scroll鼠标滚动事件 wheel二者不同点 前文提要 本人仅做个人学习记录,如有错误,请多包涵 滚动条滚动事件 scroll scroll事件绑定html页面中的指定滚动条,无论你拖拽滚动条,选中滚动条之后按键盘…...
【LeetCode】每日一题 2023_11_29 无限集中的最小数字(哈希/堆)
文章目录 刷题前唠嗑题目:无限集中的最小数字题目描述代码与解题思路偷看大佬题解 结语 刷题前唠嗑 LeetCode?启动!!! 今天的题目也比较的简单,因为数据量不大,所以什么做法都能过的去 题目&a…...

C/C++ 常用的四种查找算法
在计算机科学中,搜索算法是一种用于在数据集合中查找特定元素的算法。C语言作为一种强大的编程语言,提供了多种搜索算法的实现方式。本文将介绍C语言中的四种常见搜索算法其中包括(线性查找,二分法查找,树结构查找&…...
Linux | Ubuntu设置 netstat(网络状态)
netstat命令用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。netstat是在内核中访问网络及相关信息的程序,它能提供TCP连接,TCP和UDP监听,进程内存管理的相关报告。 1.netstat的安装 搜…...
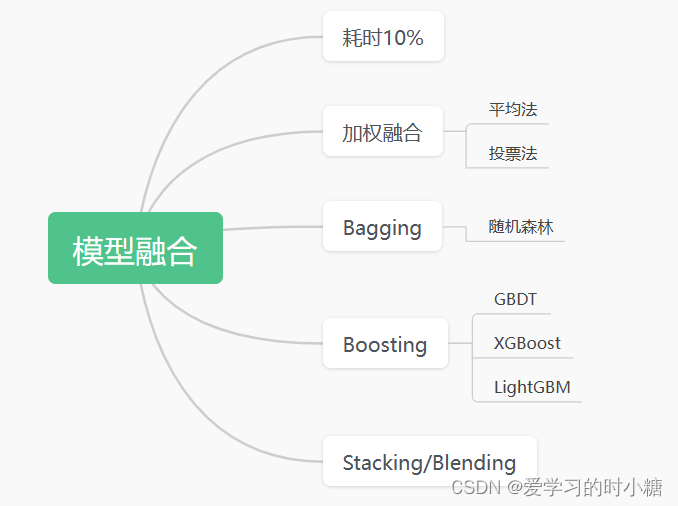
成为AI产品经理——模型构建流程(下)
目录 1.模型训练 2.模型验证 3.模型融合 4.模型部署 上节课我们讲了模型设计、特征工程,这节课我们来讲模型构建剩下的三个部分:模型训练、模型验证和模型融合。 1.模型训练 模型训练就是要不断地训练、验证、调优直至让模型达到最优。 那么怎么达…...

TCP Socket API 讲解,以及回显服务器客户端的实现
文章目录 TCPServerSocket APISocket API TCP 客户端服务器的实现 TCP ServerSocket API ServerSocket 是创建TCP服务端 Socket 的 API。 serverSocket构造方法: 方法签名方法说明ServerSocket(int port)创建一个服务端流套接字Socket,并绑定到指定端…...
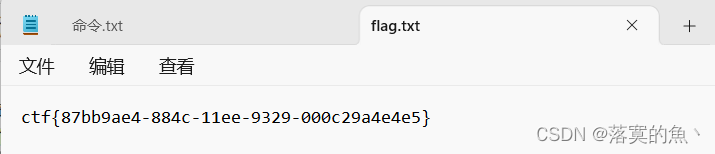
2023年掌控安全学院CTF暖冬杯——数据流分析
前言:打工仔一枚,第一波上新的3题misc 做完了 再打ISCTF随便记录一下 PS:环境关了,题目描述忘记了,反正就是找flag。 筛选HTTP数据流 导出数据流慢慢看 ctrl F 搜flag 看到一条 有flag.txt 的数据 导出另存.zip 这里…...
UE4 基础篇十四:自定义插件
文末有视频地址和git地址 一、概念 虚幻里插件都是用C++写的,C++包括.h文件和.cpp文件,.h头文件通常包含函数类型和函数声明,cpp文件包含这些类型和函数的实现, 你为项目编写的所有代码文件都必须位于模块中,模块就是硬盘里的一个文件夹,包含名为“Build.cs”的C#文件…...
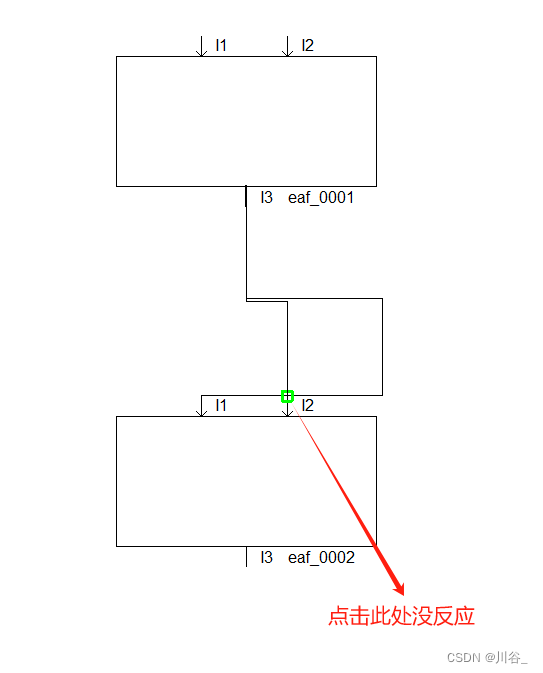
QT QGraphicsItem 图元覆盖导致鼠标点击事件不能传递到被覆盖图元
一、概述 在日常开发中,遇到这样一个问题,线图元和引脚图元重叠,导致点击引脚图元,没有进入引脚图元的鼠标点击事件中。 二、产生原因 如果您的 QGraphicsItem 上有一个图元覆盖了它,可能会导致鼠标事件无法正常触发…...

proto语法学习笔记
proto语法学习笔记 Protocol Buffers(Proto是由谷歌开发的一种数据序列化格式。 Proto 不是一种编程语言,而是一种接口描述语言(IDL),用于定义数据结构和消息格式。 它的设计目标是提供一种简单、高效、可扩展的方法来…...
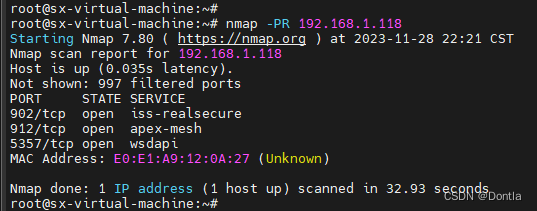
python-nmap库使用教程(Nmap网络扫描器的Python接口)(功能:主机发现、端口扫描、操作系统识别等)
文章目录 Python-nmap库使用教程前置条件引入python-nmap创建Nmap扫描实例执行简单的主机发现(nmap -sn)示例,我有一台主机配置为不响应 ICMP 请求,但使用nmap -sn,仍然能够探测到设备: 端口扫描扫描特定端…...
什么是智慧工地?
一、什么是智慧工地? 工地本身不拥有智慧,工地的运作是依赖于人的智慧。工地信息化技术,能够减少对人的依赖,使工地拥有智慧。 智慧工地,就是立足于“智慧城市”和“互联网”,采用云计算、大数据和物联网等…...
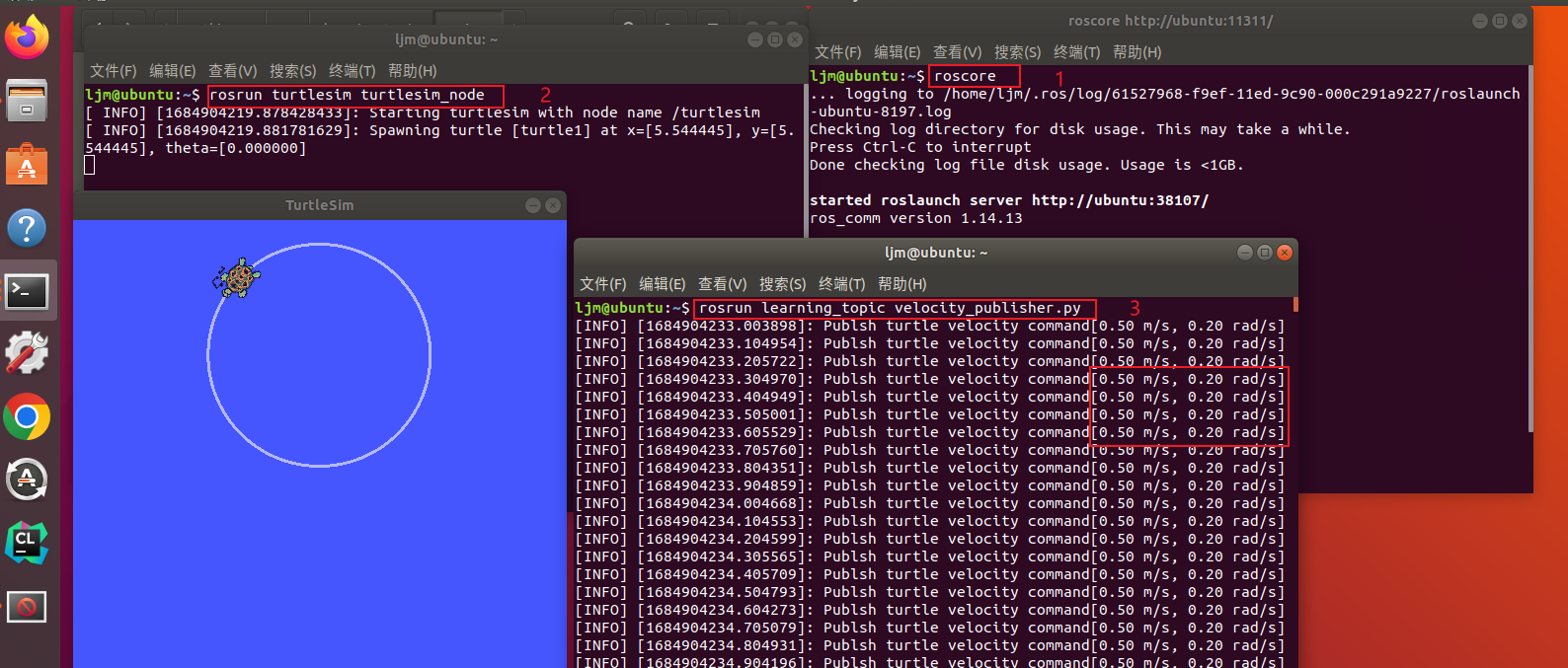
【古月居《ros入门21讲》学习笔记】08_发布者Publisher的编程实现
目录 说明: 1. 话题模型 图示 说明 2. 实现过程(C) 创建功能包 创建发布者代码(C) 配置发布者代码编译规则 编译并运行 编译 运行 3. 实现过程(Python) 创建发布者代码(…...

沿着马可·波罗的足迹,看数字云南
刚入行的时候,有位前辈跟我说过一句话:去现场“要像外国人一样去看”,重新审视那些自己可能早已“熟视无睹”的事物。 前不久,我跟随“看见数字云南——云南数字经济媒体探营活动”,奔赴昆明、大理、西双版纳等地&…...

记录问题-使用@Validated报错Validation failed for argument [0]
类字段 NotNull(message "双坐标不能为空", groups {Insert.class, Update.class})private Integer yAxisType;接口 /*** 添加** return*/RequestMapping(value "/add", method RequestMethod.POST)public Result add(Validated(Insert.class) Request…...

three.js--立方体
作者:baekpcyyy🐟 使用three.js渲染出可以调节大小的立方体 1.搭建开发环境 1.首先新建文件夹用vsc打开项目终端 2.执行npm init -y 创建配置文件夹 3.执行npm i three0.152 安装three.js依赖 4.执行npm I vite -D 安装 Vite 作为开发依赖 5.根…...

App的测试,和传统软件测试有哪些区别?应该增加哪些方面的测试用例?
从上图可知,测试人员所测项目占比中,App测试占比是最高的。 这就意味着学习期间,我们要花最多的精力去学App的各类测试。也意味着我们找工作前,就得知道,App的测试点是什么,App功能我们得会测试࿰…...

高能物理实时触发系统:HGQ与LGN算法在FPGA上的极致优化实践
1. 项目概述:当粒子对撞遇见实时AI在大型强子对撞机(LHC)每秒数千万次的质子对撞中,CMS探测器会捕获海量的高维数据。第一级触发系统(L1T)的任务,是在3.8微秒的极短时间内,将事件率从…...

2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南
2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主…...

探索DeepPurpose预训练模型:10分钟实现SARS-CoV-3CL蛋白酶抑制剂虚拟筛选
探索DeepPurpose预训练模型:10分钟实现SARS-CoV-3CL蛋白酶抑制剂虚拟筛选 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...
)
WSL2终端颜值与效率双飞:保姆级oh-my-zsh配置指南(含autojump、语法高亮插件)
WSL2终端颜值与效率双飞:保姆级oh-my-zsh配置指南(含autojump、语法高亮插件)在开发者的日常工作中,终端是使用频率最高的工具之一。一个高效、美观的终端环境不仅能提升工作效率,还能让枯燥的命令行操作变得愉悦。对于…...

用Python和Pandas搞定泰坦尼克号数据集:从数据清洗到特征工程的完整实战
用Python和Pandas征服泰坦尼克号数据集:从数据清洗到特征工程的实战指南当第一次打开泰坦尼克号数据集时,那些密密麻麻的乘客信息就像一艘沉船上的碎片——杂乱无章却又充满故事。作为数据科学领域最经典的入门数据集,它包含了891名乘客的12个…...

Wireshark抓不到国密TLCP流量?揭秘协议解析断层与电信数智版实战方案
1. 为什么普通Wireshark根本抓不到国密流量——从协议栈底层看TLCP的“隐身”逻辑你有没有试过,在一台刚装好国密SM2/SM3/SM4算法支持的Linux服务器上,用标准Wireshark 3.7.1抓包,结果在过滤器里输入tls或ssl,却一条加密握手记录都…...

深度学习篇---cuSPARSELt
cuSPARSELt 是 NVIDIA CUDA 生态中一个专门为结构化稀疏矩阵设计的 GPU 加速数学库。它和我们常说的 cuSPARSE 是同门师兄弟,但各有绝活。如果说 cuSPARSE 是什么都能处理的“通用军刀”,那 cuSPARSELt 就是为深度学习这类特定任务量身定制的“手术刀”。…...

BooruDatasetTagManager:如何用AI智能标注工具将图像数据集处理效率提升10倍
BooruDatasetTagManager:如何用AI智能标注工具将图像数据集处理效率提升10倍 【免费下载链接】BooruDatasetTagManager 项目地址: https://gitcode.com/gh_mirrors/bo/BooruDatasetTagManager 你是否曾经为AI模型训练准备数据集时,面对数千张需要…...

在node js后端服务中集成taotoken实现多模型智能客服响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Node.js 后端服务中集成 Taotoken 实现多模型智能客服响应 构建一个在线客服系统时,一个核心挑战是如何平衡响应质量…...

在自动化客服系统中集成多模型 API 以提升响应稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服系统中集成多模型 API 以提升响应稳定性 对于构建自动化客服系统的团队而言,服务的连续性与稳定性是核心诉…...