Pytorch进阶教学——训练一个图像分类模型(GPU)
目录
1、前言
2、数据集介绍
3、获取数据
4、创建网络
5、训练模型
6、测试模型
6.1、测试整个模型准确率
6.2、测试单张图片
1、前言
- 编写一个可以分类蚂蚁和蜜蜂图片的模型,使用数据集对卷积神经网络进行训练。训练后的模型可以对蚂蚁或蜜蜂的图片进行检测。
- 使用anaconda新建一个虚拟环境,安装好pytorch。后续缺什么包就安装什么包即可。
- 使用pycharm新建一个项目,配置好环境。
2、数据集介绍
- 使用的数据集为蚂蚁和蜜蜂的图片,分为训练集和测试集。
- 【注】数据集下载地址。

3、获取数据
- 代码中获取数据集使用的是txt文件,所以首先需要提取全部图片的地址和标签放入txt文件中。
- 下述代码为python提取全部图片地址和标签导出为txt文件的脚本。(自行修改)
-
import os # 导入os模块,用于操作文件路径等操作系统相关功能。def get_file_name(file_path, output_file, type): # 绝对路径path_list = os.listdir(file_path) # 列出指定路径下的所有文件和文件夹,并将结果存储在path_list中with open(output_file, 'a') as file:for filename in path_list:all_file_path = os.path.join(file_path, filename) # 拼接路径file.write(all_file_path + ' ' + type + '\n')if __name__ == '__main__':ants_file_path = r"D:\BaiduNetdiskWorkspace\PyTorch\image_recognition\hymenoptera_data\train\ants"bees_file_path = r"D:\BaiduNetdiskWorkspace\PyTorch\image_recognition\hymenoptera_data\train\bees"output_file = r"D:\BaiduNetdiskWorkspace\PyTorch\image_recognition\hymenoptera_data\train.txt"get_file_name(ants_file_path, output_file, 'ants')get_file_name(bees_file_path, output_file, 'bees') -
-
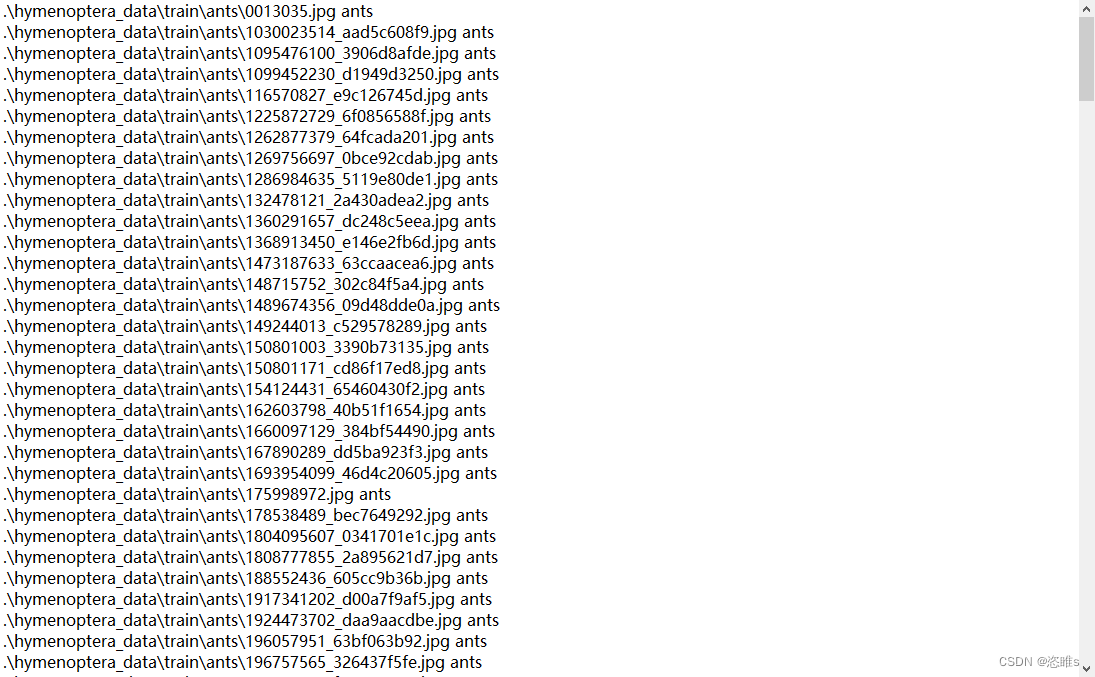
- 将全部地址修改为相对地址。
- 使用替换操作实现。例如:
- 使用替换操作实现。例如:
- 最后txt文件的内容如下:
- 新建一个dataset.py文件。
-
# 读取数据 import torch import torchvision.transforms as transforms from PIL import Image# 读取数据类 class MyDataset(torch.utils.data.Dataset): # 继承构建自定义数据集的基类def __init__(self, datatxt, datatransform):datas = open(datatxt, 'r').readlines() # 按行读取,每行包含图像路径和标签self.images = []self.labels = []self.transform = datatransformfor data in datas:item = data.strip().split(' ') # 去除首尾空格并按空格分割# 分别将图像路径和标签添加到self.images和self.labels列表中self.images.append(item[0]) # 路径self.labels.append(item[1]) # 标签returndef __len__(self):return len(self.images)# 获取数据集中的一个样本。接收一个索引item,根据索引获取对应的图像路径和标签def __getitem__(self, item):imagepath, label = self.images[item], self.labels[item]image = Image.open(imagepath) # 打开图片return self.transform(image), label # 返回转换后的图像和对应的标签# 用于测试 if __name__ == '__main__':# 利用txt文件读取图片信息,txt文件包括图片路径和标签traintxt = './hymenoptera_data/train.txt'valtxt = './hymenoptera_data/val.txt'# 图片转换形式traindata_transfomer = transforms.Compose([transforms.ToTensor(), # 转为Tensor格式transforms.Resize(60), # 调整图像大小,调整为高度或宽度为60像素,另一边按比例调整transforms.RandomCrop(48), # 裁剪图片,随机裁剪成高度和宽度均为48像素的部分transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行归一化处理。对每个通道执行了均值为0.5、标准差为0.5的归一化操作])valdata_transfomer = transforms.Compose([transforms.ToTensor(), # 转为Tensor格transforms.Resize(48), # 调整图像大小,调整为高度或宽度为48像素,另一边按比例调整transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 加载数据traindataset = MyDataset(traintxt, traindata_transfomer)valdataset = MyDataset(valtxt, valdata_transfomer)print("测试集:" + str(traindataset.__len__()))print("训练集:" + str(valdataset.__len__()))
-
- 单独运行结果:(只用于测试)


4、创建网络
- 新建一个net.py文件。
- 其中创建了一个简单的三层卷积神经网络。
-
# 三层卷积神经网络 import torch# 卷积神经网络类 class SimpleConv3(torch.nn.Module): # 继承创建神经网络的基类def __init__(self, classes):super(SimpleConv3, self).__init__()# 卷积层self.conv1 = torch.nn.Conv2d(3, 16, 3, 2, 1) # 输入通道3,输出通道16,3*3的卷积核,步长2,边缘填充1self.conv2 = torch.nn.Conv2d(16, 32, 3, 2, 1) # 输入通道16,输出通道32,3*3的卷积核,步长2,边缘填充1self.conv3 = torch.nn.Conv2d(32, 64, 3, 2, 1) # 输入通道32,输出通道64,3*3的卷积核,步长2,边缘填充1# 全连接层self.fc1 = torch.nn.Linear(2304, 100)self.fc2 = torch.nn.Linear(100, classes)def forward(self, x):# 第一次卷积x = torch.nn.functional.relu(self.conv1(x)) # relu为激活函数# 第二次卷积x = torch.nn.functional.relu(self.conv2(x))# 第三次卷积x = torch.nn.functional.relu(self.conv3(x))# 展开成一维向量x = x.view(x.size(0), -1)x = torch.nn.functional.relu(self.fc1(x))x = self.fc2(x)return x# 用于测试 if __name__ == '__main__':inputs = torch.rand((1, 3, 48, 48)) # 生成一个随机的3通道、48x48大小的张量作为输入net = SimpleConv3(2) # 二分类output = net(inputs)print(output)
- 单独运行结果:(只用于测试)

5、训练模型
- 新建一个train.py文件。
- 其中可自行设置的参数都有标出。
-
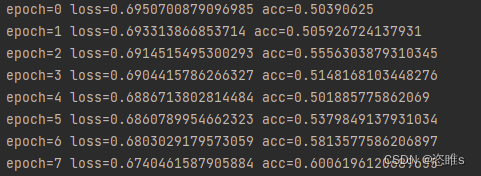
# 训练模型 import matplotlibmatplotlib.use('TkAgg') import matplotlib.pyplot as plt from dataset import MyDataset from net import SimpleConv3 import torch import torchvision.transforms as transforms from torch.optim import SGD # 优化相关 from torch.optim.lr_scheduler import StepLR # 优化相关 from sklearn import preprocessing # 处理label# 图片转换形式 traindata_transfomer = transforms.Compose([transforms.ToTensor(), # 转为Tensor格式transforms.Resize(60, antialias=True), # 调整图像大小,调整为高度或宽度为60像素,另一边按比例调整,antialias=True启用了抗锯齿功能transforms.RandomCrop(48), # 裁剪图片,随机裁剪成高度和宽度均为48像素的部分transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行归一化处理。对每个通道执行了均值为0.5、标准差为0.5的归一化操作 ])if __name__ == '__main__':traintxt = './hymenoptera_data/train.txt'valtxt = './hymenoptera_data/val.txt'# 加载数据traindataset = MyDataset(traintxt, traindata_transfomer)# 创建卷积神经网络net = SimpleConv3(2) # 二分类# 使用GPUdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")net.to(device)# 测试GPU是否能使用# print("The device is gpu later?:", next(net.parameters()).is_cuda)# print("The device is gpu,", next(net.parameters()).device)# 将数据提供给模型使用traindataloader = torch.utils.data.DataLoader(traindataset, batch_size=128, shuffle=True,num_workers=1) # batch_size可以自行调节# 优化器optim = SGD(net.parameters(), lr=0.1, momentum=0.9) # 使用随机梯度下降(SGD)作为优化器,学习率0.1,动量0.9,加速梯度下降过程,lr可自行调节criterion = torch.nn.CrossEntropyLoss() # 使用交叉熵损失作为损失函数lr_step = StepLR(optim, step_size=200, gamma=0.1) # 学习率调度器,动态调整学习率,每200个epoch调整一次,每次调整缩小为原来的0.1倍,step_size可自行调节epochs = 5 # 训练次数accs = []losss = []# 训练循环for epoch in range(0, epochs):batch = 0running_acc = 0.0 # 精度running_loss = 0.0 # 损失for data in traindataloader:batch += 1imputs, labels = data# 将标签从元组转换为tensor类型labels = preprocessing.LabelEncoder().fit_transform(labels)labels = torch.as_tensor(labels)# 利用GPU训练模型imputs = imputs.to(device)labels = labels.to(device)# 将数据输入至网络output = net(imputs)# 计算损失loss = criterion(output, labels)# 平均准确率acc = float(torch.sum(labels == torch.argmax(output, 1))) / len(imputs)# 累加损失和准确率,后面会除以batchrunning_acc += accrunning_loss += loss.data.item()optim.zero_grad() # 清空梯度loss.backward() # 反向传播optim.step() # 更新参数lr_step.step() # 更新优化器的学习率# 一次训练的精度和损失running_acc = running_acc / batchrunning_loss = running_loss / batchaccs.append(running_acc)losss.append(running_loss)print('epoch=' + str(epoch) + ' loss=' + str(running_loss) + ' acc=' + str(running_acc))# 保存模型torch.save(net, 'model.pth') # 保存模型的权重和结构x = torch.randn(1, 3, 48, 48).to(device) # # 生成一个随机的3通道、48x48大小的张量作为输入,新建的张量也要送到GPU中net = torch.load('model.pth') # 从保存的.pth文件中加载模型net.train(False) # 设置模型为推理模式,意味着不会进行梯度计算或反向传播torch.onnx.export(net, x, 'model.onnx') # 使用ONNX格式导出模型# 接受模型net、示例输入x和导出的文件名model.onnx作为参数# 可视化结果fig = plt.figure()plot1, = plt.plot(range(len(accs)), accs) # 创建一个图形对象plot1,绘制accs列表中的数据plot2, = plt.plot(range(len(losss)), losss) # 创建另一个图形对象plot2,绘制losss列表中的数据plt.ylabel('epoch') # 设置y轴的标签为epochplt.legend(handles=[plot1, plot2], labels=['acc', 'loss']) # 创建图例,指定图表中不同曲线的标签plt.show() # 展示所绘制的图表
- 【注】本项目使用的是GPU训练模型。如果GPU可以获得,但是无法使用,可能是pytorch的版本不对,需要重新安装。
- 运行结果:
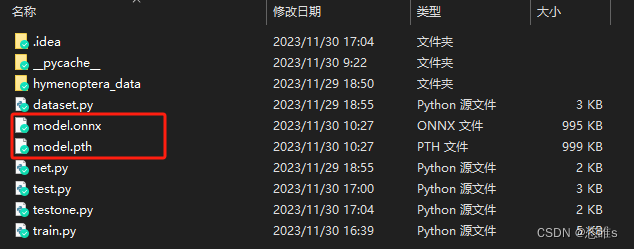
- 保存后的模型如下:


6、测试模型
6.1、测试整个模型准确率
- 利用测试集,测试整个模型的准确率。
- 新建一个test.py文件。
-
# 测试整个模型的准确率 import torch import torchvision.transforms as transforms from dataset import MyDataset # 您的数据集类 from sklearn import preprocessing # 处理label# 定义测试集的数据转换形式 valdata_transfomer = transforms.Compose([transforms.ToTensor(), # 转为Tensor格式transforms.Resize(60, antialias=True), # 调整图像大小,调整为高度或宽度为60像素,另一边按比例调整,antialias=True启用了抗锯齿功能transforms.CenterCrop(48), # 中心裁剪图片,裁剪成高度和宽度均为48像素的部分transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行归一化处理。对每个通道执行了均值为0.5、标准差为0.5的归一化操作 ])if __name__ == '__main__':valtxt = './hymenoptera_data/val.txt' # 测试集数据路径# 加载测试集数据valdataset = MyDataset(valtxt, valdata_transfomer)# 加载已训练好的模型,利用GPU进行测试device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")net = torch.load('model.pth').to(device)net.eval() # 将模型设置为评估模式,意味着不会进行梯度计算或反向传播# 使用 DataLoader 加载测试集数据valdataloader = torch.utils.data.DataLoader(valdataset, batch_size=1, shuffle=False)correct = 0 # 被正确预测的样本数total = 0 # 测试样本数# 测试模型with torch.no_grad():for data in valdataloader:images, labels = data# 将标签从元组转换为tensor类型labels = preprocessing.LabelEncoder().fit_transform(labels)labels = torch.as_tensor(labels)# 利用GPU训练模型images, labels = images.to(device), labels.to(device)outputs = net(images) # 输入图像并获取模型预测结果_, predicted = torch.max(outputs.data, 1) # 获取预测值中最大概率的索引total += labels.size(0) # 累计测试样本数量correct += (predicted == labels).sum().item() # 计算正确预测的样本数量# 计算并输出模型在测试集上的准确率accuracy = 100 * correct / totalprint('Test Accuracy: {:.2f}%'.format(accuracy))
-
- 运行结果:

- 因为训练模型时只迭代了200次,所以准确率并不高。可以尝试提高训练次数,提高准确率。
6.2、测试单张图片
- 使用训练后的模型,对单张图片进行预测。
- 新建一个testone.py文件。
-
import torch from PIL import Image import torchvision.transforms as transforms# 定义图片预处理转换 image_transforms = transforms.Compose([transforms.Resize(60, antialias=True), # 调整图像大小transforms.CenterCrop(48), # 中心裁剪transforms.ToTensor(), # 转为Tensor格式transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化处理 ])# 定义类别映射字典 class_mapping = {0: "ant",1: "bee" }# 加载已训练好的模型,利用GPU测试 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net = torch.load('model.pth').to(device) net.eval() # 将模型设置为评估模式,意味着不会进行梯度计算或反向传播# 加载要测试的图片 image_path = './hymenoptera_data/val/bees/26589803_5ba7000313.jpg' # 图片路径 input_image = Image.open(image_path) # 加载图片 input_tensor = image_transforms(input_image).unsqueeze(0) # 对图片进行预处理转换,并增加 batch 维度# 将输入数据移动到GPU上 input_tensor = input_tensor.to(device)# 使用模型进行预测 with torch.no_grad():output = net(input_tensor)_, predicted = torch.max(output, 1) # 在张量中沿指定维度找到最大值及其对应的索引# 输出预测结果 predicted_class = predicted.item() # 得到预测的标签 predicted_label = class_mapping[predicted_class] # 将标签转换为文字 print(f"The predicted class for the image is: {predicted_label}")
-
- 运行结果:

相关文章:

Pytorch进阶教学——训练一个图像分类模型(GPU)
目录 1、前言 2、数据集介绍 3、获取数据 4、创建网络 5、训练模型 6、测试模型 6.1、测试整个模型准确率 6.2、测试单张图片 1、前言 编写一个可以分类蚂蚁和蜜蜂图片的模型,使用数据集对卷积神经网络进行训练。训练后的模型可以对蚂蚁或蜜蜂的图片进行…...

Docker Swarm总结+CI/CD Devops、gitlab、sonarqube以及harbor的安装集成配置(3/5)
博主介绍:Java领域优质创作者,博客之星城市赛道TOP20、专注于前端流行技术框架、Java后端技术领域、项目实战运维以及GIS地理信息领域。 🍅文末获取源码下载地址🍅 👇🏻 精彩专栏推荐订阅👇🏻…...

Linux:windows 和 Linux 之间文本格式转换
背景 在 Windows 上编辑的文件,放到 Linux 平台,有时会出现奇怪的问题,其中有一个是 ^M 引起的,例如这种错误: /bin/bash^M: bad interpreter 这个问题相信大家也碰到过,原因是 Windows 和 Linux 关于换行的…...
VBA技术资料MF88:测试Excel文件名是否有效
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...

u8g2图形库——丝滑菜单制作
目录 一、实物效果展示 二、丝滑菜单实现原理 三、代码开源 1.ui_bmp.h 2.ui.h 3.ui.c 一、实物效果展示 u8g2图形库——丝滑菜单制作 二、丝滑菜单实现原理 int ui_run(short *a,short *a_tag,uint8_t step,uint8_t slow_cnt) //UI滑动效果 {uint8_t temp;…...

Go 异常处理流程
在 Go 语言中,panic、recover 和 defer 是用于处理异常情况的关键字。它们通常一起使用来实现对程序错误的处理和恢复。 1. defer 语句 defer 用于在函数返回之前执行一段代码。被 defer 修饰的语句或函数会在包含 defer 的函数执行完毕后执行。defer 常用于资源清…...
ubuntu20.04安装tensorRT流程梳理
目标:先跑demo,再学习源码 step1, 提前准备好CUDA环境 安装CUDA,cuDNN 注意,CUDA,cuDNN需要去官网下载.run和tar文件安装,否则在下面step4 make命令会报找不到cuda等的错误,具体安装教程网上…...

数字孪生技术:提升UI交互性与个性化设计
随着数字化时代的到来,数字孪生技术正在逐渐改变我们的生活和工作方式。数字孪生是一种复制现实世界系统或实体的技术,通过创建数字模型来模拟现实世界中的各种行为和事件。这种技术不仅为人们提供了一个全新的视角来看待和解决问题,同时也为…...

外包干了5个月,技术退步明显.......
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了四年的功能测…...
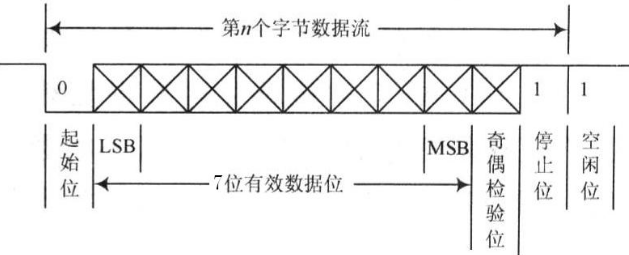
嵌入式常见的几种接口
嵌入式开发中,常见的外设通信接口/协议有SPI,I2C,UART三种,本文先分三个部分对SPI,I2C,UART进行介绍,最后对这三种协议进行比较。 1 SPI 1.1 SPI的简介 SPI(Serial Peripheral …...

基于SpringBoot+Redis的前后端分离外卖项目-苍穹外卖(七)
分页查询、删除和修改菜品 1. 菜品分页查询1.1 需求分析和设计1.1.1 产品原型1.1.2 接口设计 1.2 代码开发1.2.1 设计DTO类1.2.2 设计VO类1.2.3 Controller层1.2.4 Service层接口1.2.5 Service层实现类1.2.6 Mapper层 1.3 功能测试1.3.2 前后端联调测试 2. 删除菜品2.1 需求分析…...

Grafana采用Nginx反向代理,部分功能报错‘Origin not allowed’ behind proxy
只有部分功能会有这个提示,比如修改密码啥的,网上找了下,官方找到了答案:https://community.grafana.com/t/after-update-to-8-3-5-origin-not-allowed-behind-proxy/60598 有个回复是这样的: tl:dr: try adding prox…...

请大数据把奥威BI分析工具推给每一个财务!
这个财务指标怎么算?那些数据什么时候能拿到?看完报表,发现某部门上个月的支出涨幅过大,想了解原因怎么办?……财务人,你是不是每个月都把时间消耗在这些事情上了?那你可得快接住这个BI大数据分…...

知乎禁止转载的回答怎么复制做笔记?
问题 对于“禁止转载”的回答,右键复制是不行的,ctrl-c也不行,粘贴之后都是当前回答的标题。稍微看了代码,应该是对copy事件进行了处理。不过这样真的有用吗,真是防君子不防小人,只是给收集资料增加了许多…...

pta找鞍点—C语言
7-13 找鞍点 分数 300 全屏浏览题目 切换布局 作者 C课程组 单位 浙江大学 一个矩阵元素的“鞍点”是指该位置上的元素值在该行上最大、在该列上最小。 本题要求编写程序,求一个给定的n阶方阵的鞍点。 输入格式: 输入第一行给出一个正整数n(1…...

编程零基础算法 | 四、循环和选择结构——1572. 矩阵对角线元素的和
一、题目链接 1572. 矩阵对角线元素的和 二、题目简介 给你两个整数,n 和 start 。 数组 nums 定义为:nums[i] start 2*i(下标从 0 开始)且 n nums.length 。 请返回 nums 中所有元素按位异或(XOR)后…...
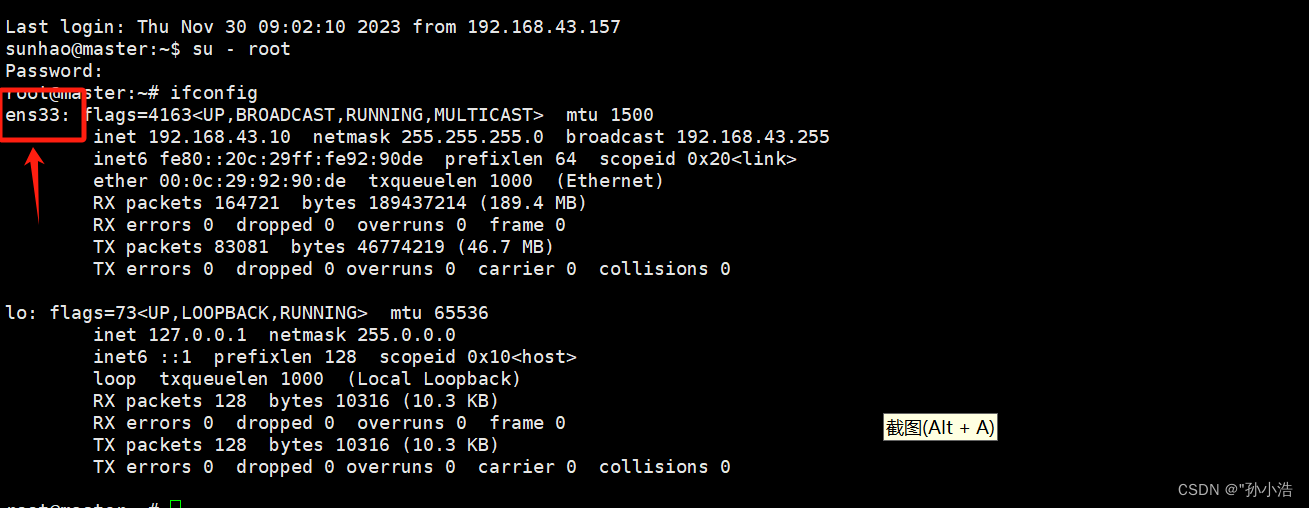
ubantu配置网卡ip
1.ifconfig查看网卡 2. vi /etc/network/interfaces auto ens33 # 网卡名 iface ens33 inet static # 注意网卡名 address 192.168.43.10 # 配置ip地址 netmask 255.255.255.0 # 掩码 gateway 192.168.43.1 # 网关 3.重启网卡 ifconfig ens33 down ifco…...
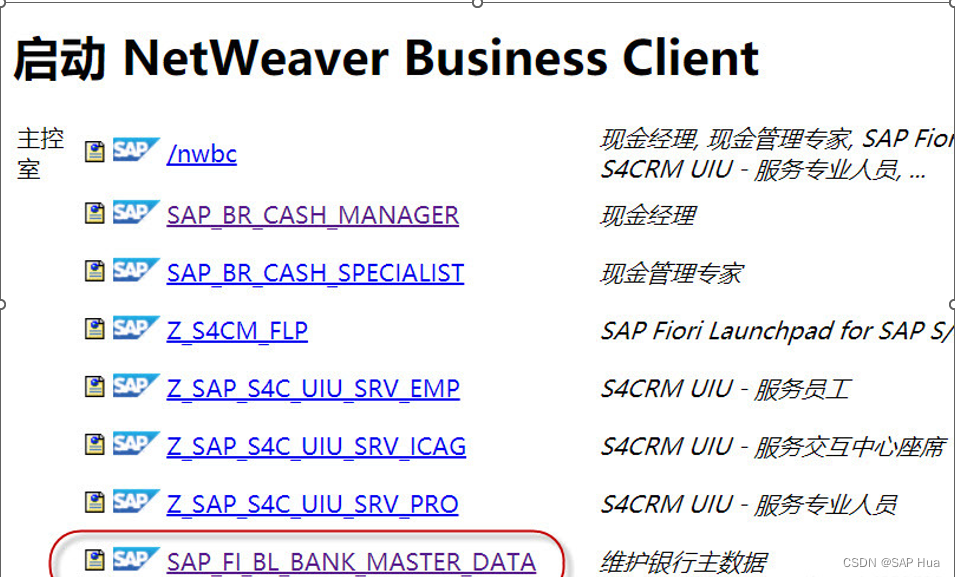
增加F110 付款方式的乱记录
随便记录一下,基本上有这些信息可以了 为了保持PRD与测试机一致的银行代码,需要先在DEV,QAS 改成4 外部给号 主要都是在FBZP 开户行维护-FI12_HBANK/FI12 S4hana 里面有的没有办法在FI12 维护只能去NWBC NWBC:维护银行账户并关联…...

软件系统安全漏洞检测应该怎么做?靠谱的软件安全检测公司推荐
软件系统安全漏洞检测是指通过对软件系统进行全面的、系统化的评估,发现和解决其中可能存在的安全漏洞和隐患。这些安全漏洞可能会被不法分子利用,引发数据泄露、系统瘫痪、信息被篡改等安全问题,给企业造成严重的经济和声誉损失。那么软件系…...
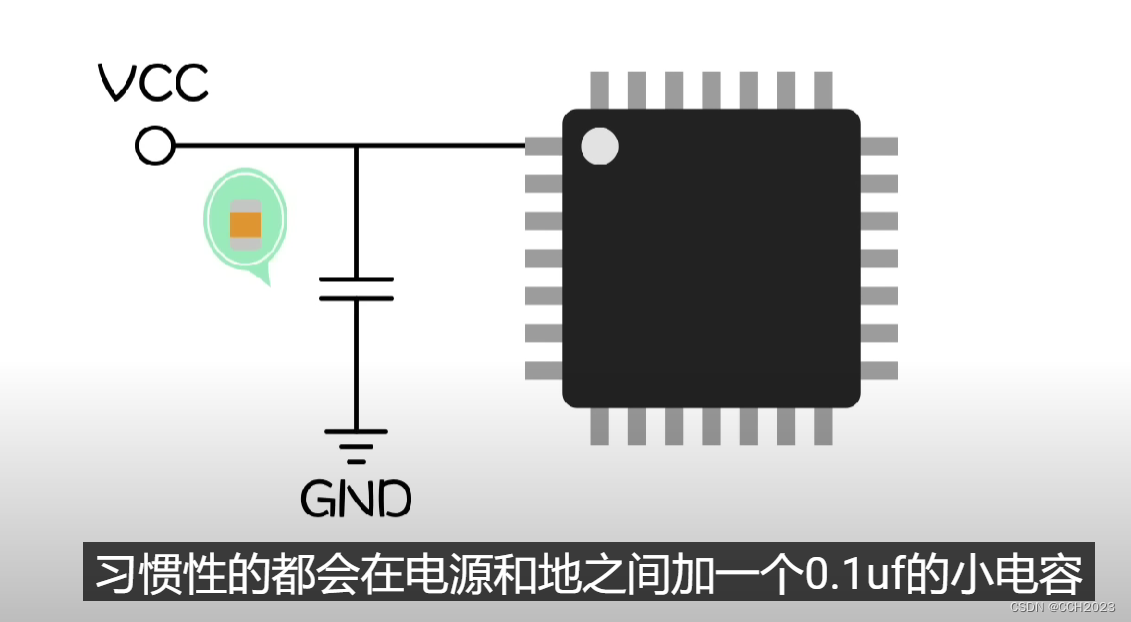
单片机学习12——电容
电容的作用: 1)降压作用: 容抗: Xc 1/2fc 串联分压原理。2100Ω的容量,50Hz的频率,可以得到1.5uF。断电之后,需要串联一个1MΩ的电阻放电。 那是不是可以使用2100欧姆的电阻来代替电容呢&am…...

为什么你的ChatGPT演讲稿总被说“像机器人”?深度拆解人类共情节奏建模与提示词嵌入技术
更多请点击: https://intelliparadigm.com 第一章:为什么你的ChatGPT演讲稿总被说“像机器人”? 当你精心调用 ChatGPT 生成一篇 800 字的 TED 风格演讲稿,满怀期待地朗读给同事听,却收到一句扎心反馈:“很…...

日志留存不合规?审计追溯难定位?DeepSeek 3.2+审计日志的4层加密+时间戳锚定机制,立即规避等保2.0扣分风险
更多请点击: https://intelliparadigm.com 第一章:DeepSeek审计日志功能全景概览 DeepSeek审计日志是企业级AI平台中保障合规性、可追溯性与安全治理的核心能力。它系统性地记录模型调用、权限变更、配置更新、数据访问等关键行为,支持毫秒级…...

Claude在国内用不了?我挨个试了一遍
你有没有这种感觉—— 每次看到Claude又出新版本,心里痒痒的。别人都在讨论Sonnet多好用、Opus推理多强,你打开官网,要么打不开,要么要翻墙,要么要国外手机号验证。 好不容易折腾注册上了,用了两周,某天突然收到封号邮件。 烦不烦? 说实话,作为一个重度AI用户,我…...

现在不掌握AI视频学习底层逻辑,3个月内将被淘汰:基于LinkedIn人才数据的技能贬值倒计时分析
更多请点击: https://intelliparadigm.com 第一章:AI视频生成工具学习曲线分析 AI视频生成工具的学习曲线呈现出显著的非线性特征——入门门槛看似平缓,但跨越“可用”到“可控”阶段往往遭遇陡峭的认知断崖。初学者常误以为上传文本提示即可…...

Props技术:基于隐私保护预言机的机器学习安全数据管道
1. Props技术:为机器学习解锁深网数据的安全钥匙如果你正在为机器学习项目寻找高质量的训练数据而发愁,或者为如何在应用中安全地处理用户敏感信息而头疼,那么你很可能已经触及了当前AI发展的一个核心痛点:数据瓶颈与信任危机。表…...

Solr CVE-2019-0193漏洞深度解析:DataImportHandler远程代码执行原理与实战修复
1. 这个漏洞不是“能远程执行代码”那么简单,而是Solr管理员自己亲手打开的后门 Apache Solr 是企业级搜索领域绕不开的基础设施,我经手过的金融、电商、政务类项目里,有七成以上都用它做全文检索底座。但2019年爆出的 CVE-2019-0193…...

CoreSight MTB-M33勘误文档解析与嵌入式开发实践
1. CoreSight MTB-M33 勘误文档解析作为一名长期从事嵌入式开发的工程师,我深知芯片勘误文档(Errata Notice)在实际项目中的重要性。今天要讨论的这份CoreSight MTB-M33勘误文档,是每个使用Cortex-M33处理器的开发者都必须仔细研读…...

英雄联盟智能助手:League Akari 的5大核心功能深度解析
英雄联盟智能助手:League Akari 的5大核心功能深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari 是一款基于英…...

EASY-HWID-SPOOFER:3步掌握硬件标识伪装技术,保护数字隐私安全
EASY-HWID-SPOOFER:3步掌握硬件标识伪装技术,保护数字隐私安全 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在当今数字时代,硬件标识&#x…...

ChatGPT翻译质量断崖式下滑的真相:当LLM遇上专业领域术语库缺失,这4种场景下错误率超61%——你的项目还在裸奔吗?
更多请点击: https://codechina.net 第一章:ChatGPT翻译质量怎么样 ChatGPT 在翻译任务中展现出较强的上下文理解能力与语言生成流畅性,但其质量受输入提示(prompt)设计、源语言复杂度、专业领域术语密度及目标语言语…...