CNN对 MNIST 数据库中的图像进行分类
加载 MNIST 数据库
MNIST 是机器学习领域最著名的数据集之一。
- 它有 70,000 张手写数字图像 - 下载非常简单 - 图像尺寸为 28x28 - 灰度图
from keras.datasets import mnist# 使用 Keras 导入MNIST 数据库
(X_train, y_train), (X_test, y_test) = mnist.load_data()print("The MNIST database has a training set of %d examples." % len(X_train))
print("The MNIST database has a test set of %d examples." % len(X_test))将前六个训练图像可视化
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.cm as cm
import numpy as np# 绘制前六幅训练图像
fig = plt.figure(figsize=(20,20))
for i in range(6):ax = fig.add_subplot(1, 6, i+1, xticks=[], yticks=[])ax.imshow(X_train[i], cmap='gray')ax.set_title(str(y_train[i]))
查看图像的更多细节
def visualize_input(img, ax):ax.imshow(img, cmap='gray')width, height = img.shapethresh = img.max()/2.5for x in range(width):for y in range(height):ax.annotate(str(round(img[x][y],2)), xy=(y,x),horizontalalignment='center',verticalalignment='center',color='white' if img[x][y]<thresh else 'black')fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
visualize_input(X_train[0], ax) 预处理输入图像:通过将每幅图像中的每个像素除以 255 来调整图像比例
预处理输入图像:通过将每幅图像中的每个像素除以 255 来调整图像比例
# 调整比例,使数值在 0 - 1 范围内 [0,255] --> [0,1]
X_train = X_train.astype('float32')/255
X_test = X_test.astype('float32')/255 print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')对标签进行预处理:使用单热方案对分类整数标签进行编码
from keras.utils import to_categoricalnum_classes = 10
# 打印前十个(整数值)训练标签
print('Integer-valued labels:')
print(y_train[:10])# 对标签进行一次性编码
# 将类别向量转换为二进制类别矩阵
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)# 打印前十个(单次)训练标签
print('One-hot labels:')
print(y_train[:10])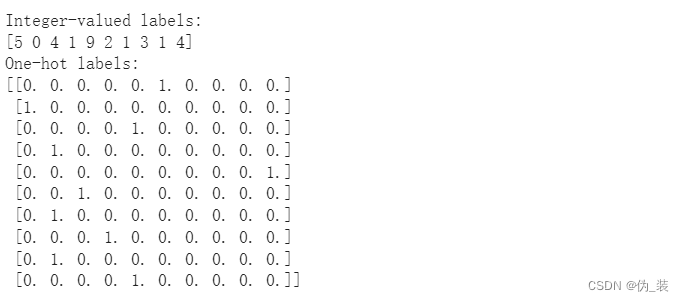 重塑数据以适应我们的 CNN(和 input_shape)
重塑数据以适应我们的 CNN(和 input_shape)
# 输入图像尺寸为 28x28 像素的图像。
img_rows, img_cols = 28, 28X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)print('input_shape: ', input_shape)
print('x_train shape:', X_train.shape)
定义模型架构
您必须传递以下参数:
- filters - 滤波器的数量。
- kernel_size - 指定(正方形)卷积窗口高度和宽度的数值。
还有一些额外的、可选的参数需要调整:
- strides - 卷积的步长。如果不指定任何参数,strides 将设为 1。
- padding - "有效 "或 "相同 "之一。如果不做任何指定,padding 将设置为 "有效"。
- activation - 通常为 "relu"。如果不指定任何内容,则不会应用激活。我们强烈建议你为网络中的每个卷积层添加 ReLU 激活函数。
需要注意的事项
- 始终为 CNN 中的 Conv2D 层添加 ReLU 激活函数。除网络中的最后一层外,密集层也应具有 ReLU 激活函数。
- 在构建分类网络时,网络的最终层应是具有 softmax 激活函数的密集层。最终层的节点数应等于数据集中的类总数。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout# 创建模型对象
model = Sequential()# CONV_1: 添加 CONV 层,采用 RELU 激活,深度 = 32 内核
model.add(Conv2D(32, kernel_size=(3, 3), padding='same',activation='relu',input_shape=(28,28,1)))
# POOL_1: 对图像进行下采样,选择最佳特征
model.add(MaxPooling2D(pool_size=(2, 2)))# CONV_2: 在这里,我们将深度增加到 64
model.add(Conv2D(64, (3, 3),padding='same', activation='relu'))
# POOL_2: more downsampling
model.add(MaxPooling2D(pool_size=(2, 2)))# 由于维度过多,我们只需要一个分类输出
model.add(Flatten())# FC_1: 完全连接,获取所有相关数据
model.add(Dense(64, activation='relu'))# FC_2: 输出软最大值,将矩阵压制成 10 个类别的输出概率
model.add(Dense(10, activation='softmax'))model.summary()
需要注意的事项:
- 网络以两个卷积层的序列开始,然后是最大池化层。
- 最后一层为数据集中的每个对象类别设置了一个条目,并具有软最大激活函数,因此可以返回概率。
- Conv2D 深度从输入层的 1 增加到 32 到 64。
- 我们还想减少高度和宽度--这就是 maxpooling 的作用所在。请注意,在池化层之后,图像尺寸从 28 减小到 14。
- 可以看到,每个输出形状都用 None 代替了批量大小。这是为了便于在运行时更改批次大小。
- 最后,我们会添加一个或多个全连接层来确定图像中包含的对象。例如,如果在上一个最大池化层中发现了车轮,那么这个 FC 层将转换该信息,以更高的概率预测图像中出现了一辆汽车。如果图像中有眼睛、腿和尾巴,那么这可能意味着图像中有一只狗。
编译模型
# rmsprop 和自适应学习率 (adaDelta) 是梯度下降的流行形式,仅次于 adam 和 adagrad
# 因为我们有多个类别 (10)# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])训练模型
from keras.callbacks import ModelCheckpoint # 训练模型
checkpointer = ModelCheckpoint(filepath='model.weights.best.hdf5', verbose=1, save_best_only=True)
hist = model.fit(X_train, y_train, batch_size=32, epochs=20,validation_data=(X_test, y_test), callbacks=[checkpointer], verbose=2, shuffle=True) 在验证集上加载分类准确率最高的模型
在验证集上加载分类准确率最高的模型
# 加载能获得最佳验证精度的权重
model.load_weights('model.weights.best.hdf5')计算测试集的分类准确率
# 评估测试的准确性
score = model.evaluate(X_test, y_test, verbose=0)
accuracy = 100*score[1]# 打印测试精度
print('Test accuracy: %.4f%%' % accuracy)![]()
评估模型
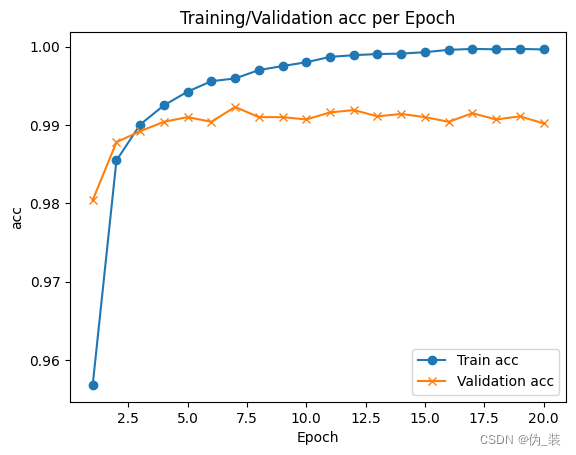
import matplotlib.pyplot as pltf, ax = plt.subplots()
ax.plot([None] + hist.history['accuracy'], 'o-')
ax.plot([None] + hist.history['val_accuracy'], 'x-')
# 绘制图例并自动使用最佳位置: loc = 0。
ax.legend(['Train acc', 'Validation acc'], loc = 0)
ax.set_title('Training/Validation acc per Epoch')
ax.set_xlabel('Epoch')
ax.set_ylabel('acc')
plt.show()
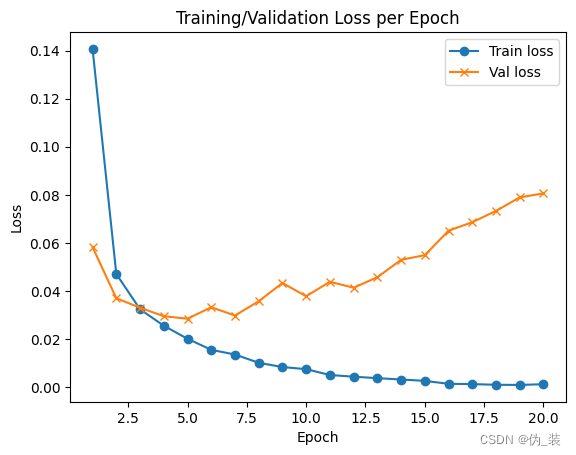
import matplotlib.pyplot as pltf, ax = plt.subplots()
ax.plot([None] + hist.history['loss'], 'o-')
ax.plot([None] + hist.history['val_loss'], 'x-')# Plot legend and use the best location automatically: loc = 0.
ax.legend(['Train loss', "Val loss"], loc = 0)
ax.set_title('Training/Validation Loss per Epoch')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
plt.show()
注意事项:
MLP 和 CNN 通常不会产生可比较的结果。MNIST 数据集非常特别,因为它非常干净,而且经过了完美的预处理。例如,所有图像大小相同,并以 28x28 像素网格为中心。如果数字稍有偏斜或不居中,这项任务就会难得多。对于真实世界中杂乱无章的图像数据,CNN 将真正超越 MLP。
为了直观地了解为什么会出现这种情况,要将图像输入 MLP,首先必须将图像转换为矢量。然后,MLP 会将图像视为没有特殊结构的简单数字向量。它不知道这些数字原本是按空间网格排列的。
相比之下,CNN 的设计目的完全相同,即处理多维数据中的模式。与 MLP 不同的是,CNN 知道,相距较近的图像像素比相距较远的像素关系密切。
相关文章:
CNN对 MNIST 数据库中的图像进行分类
加载 MNIST 数据库 MNIST 是机器学习领域最著名的数据集之一。 它有 70,000 张手写数字图像 - 下载非常简单 - 图像尺寸为 28x28 - 灰度图 from keras.datasets import mnist# 使用 Keras 导入MNIST 数据库 (X_train, y_train), (X_test, y_test) mnist.load_data()print(&…...

HarmonyOS开发工具简介
工具简介 更新时间: 2023-10-13 11:06 分享 添加收藏 说明 该文档匹配DevEco Studio 3.1.1 Release版本。 概述 HUAWEI DevEco Studio(获取工具请单击链接下载,以下简称DevEco Studio)是基于IntelliJ IDEA Community开源版本打造,…...

大量索引场景下 Easysearch 和 Elasticsearch 的吞吐量差异
最近有客户在使用 Elasticsearch 搜索服务时发现集群有掉节点,并且有 master 收集节点信息超时的日志,节点的负载也很高,不只是 data 节点,master 和协调节点的 cpu 使用率都很高,看现象集群似乎遇到了性能瓶颈。 查看…...
东明石化集团领导团队参访震坤行工业超市
东明石化集团领导团队参访震坤行工业超市 10月16日,山东东明石化集团(以下简称东明石化)总裁李治先生一行带队来访参观交流震坤行,与震坤行工业超市董事长兼CEO陈龙、销售负责团队开展座谈。期间,双方就企业数字化转型…...
)
Java常见的面试题(很基础那种)
这里介绍一下,一些比较基础的Java面试题,比较适合应届生、实习生这些朋友。因为对于刚出来工作的Java工程师,很多企业都偏向招一些基础比较好的苗子回来培养。所以啊,在校的朋友们,一定要在读书期间,多做项目,如果没有实际的项目,可以在github找一些案例来做参考,先模…...

MySQL处理并发访问和高负载的关键技术和策略
我深知在数据库管理中处理并发访问和高负载的重要性。在这篇文章中,我将探讨MySQL处理并发访问和高负载的关键技术和策略,以帮助读者更好地优化数据库性能。 图片来源:MySQL处理并发访问和高负载的关键技术和策略 MySQL数据库在处理并发访问…...
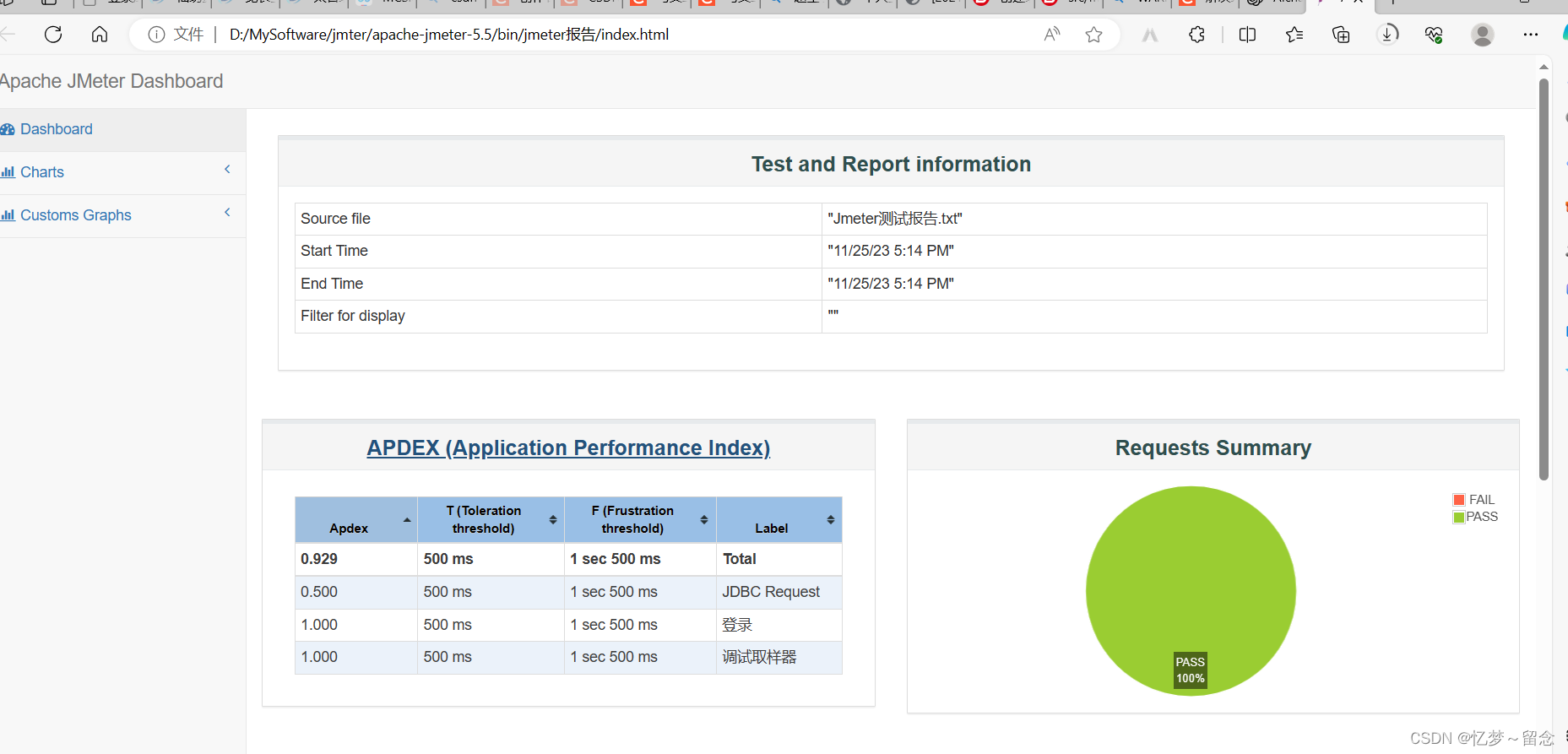
软件测试jmeter基本使用
1安装与配置 1.jdk下载 下载地址:https://www.oracle.com/java/technologies/downloads/#jdk18-windows(压缩包中会给) 2.jmeter下载 Apache JMeter - Download Apache JMeter(压缩包中有) 3.操作教学 打开软件后新…...

一文讲透Python函数中的局部变量和全局变量
变量的作用域就是变量能够发挥作用的区域,超出既定区域后就无法发挥作用。根据变量的作用域可以将变量分为局部变量和全局变量。 1.局部变量 局部变量是在函数内部定义并使用的变量,也就是说只有在函数内部,在函数运行时才会有效࿰…...

【LeetCode】每日一题 2023_11_23 HTML 实体解析器(调库/打工)
文章目录 刷题前唠嗑题目:HTML 实体解析器题目描述代码与解题思路 结语 刷题前唠嗑 题目:HTML 实体解析器 题目链接:1410. HTML 实体解析器 题目描述 代码与解题思路 func entityParser(s string) (ans string) {return strings.NewRepla…...
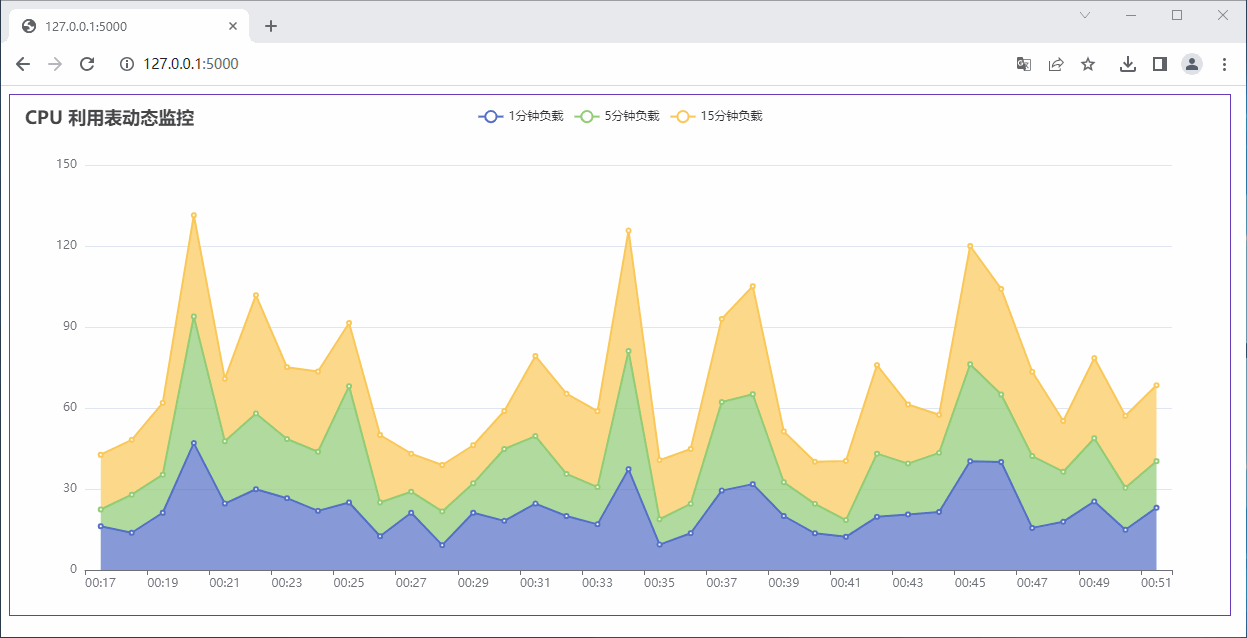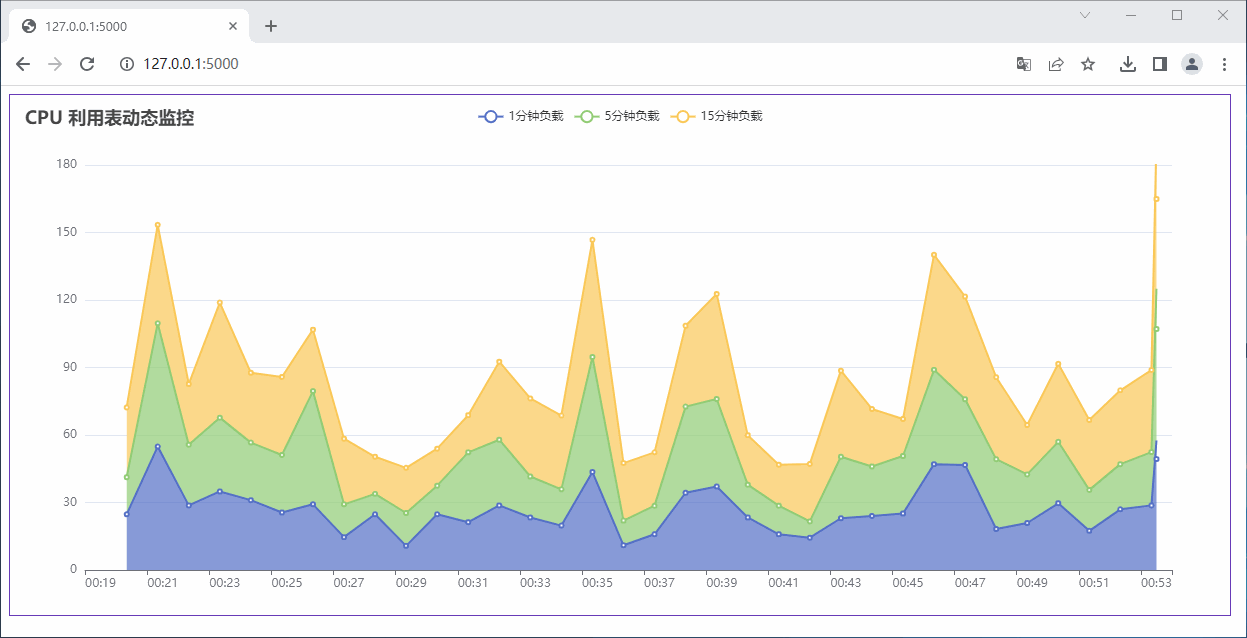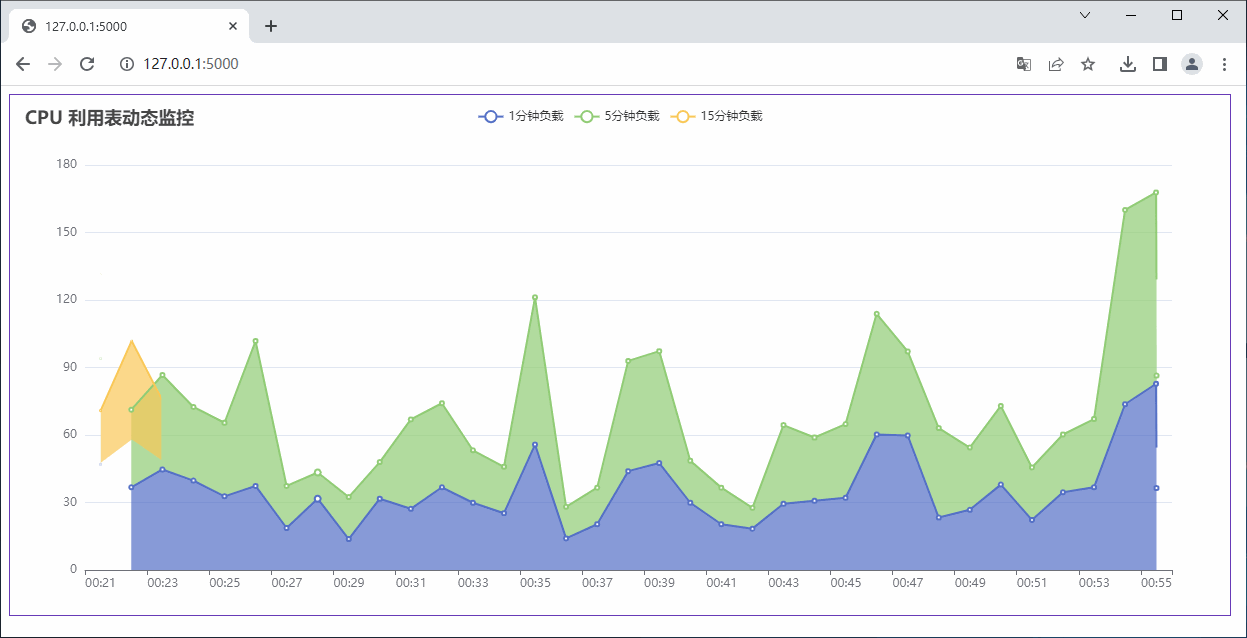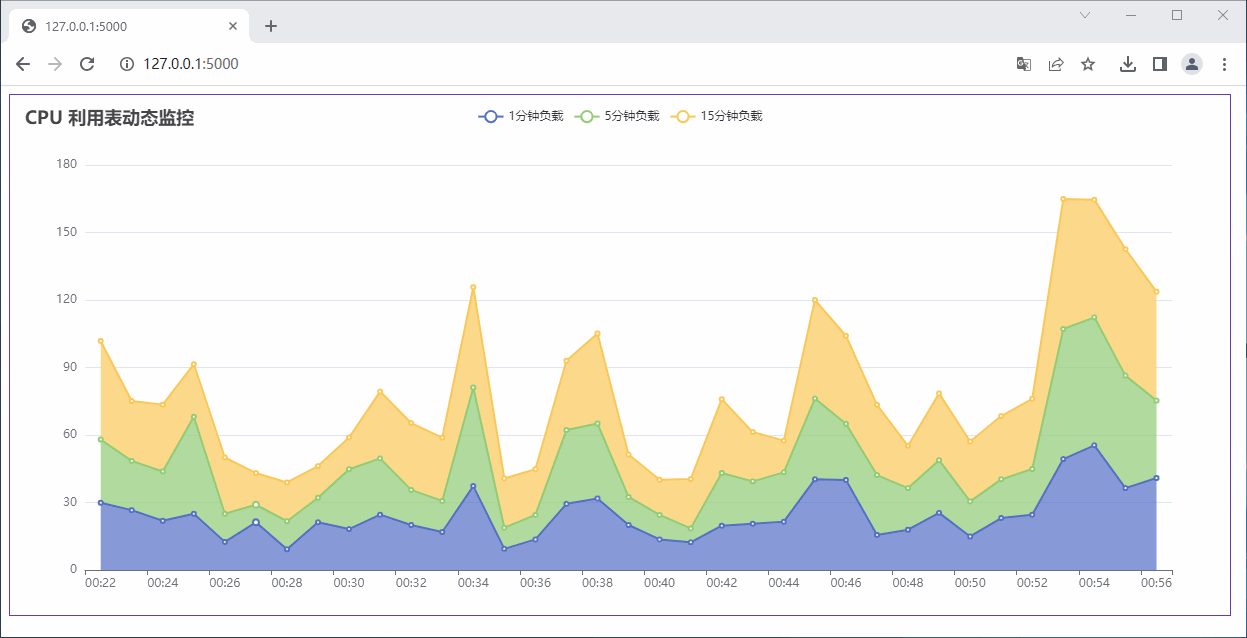
Flask SocketIO 实现动态绘图
Flask-SocketIO 是基于 Flask 的一个扩展,用于简化在 Flask 应用中集成 WebSocket 功能。WebSocket 是一种在客户端和服务器之间实现实时双向通信的协议,常用于实现实时性要求较高的应用,如聊天应用、实时通知等,使得开发者可以更…...

软著项目推荐 深度学习 植物识别算法系统
文章目录 0 前言2 相关技术2.1 VGG-Net模型2.2 VGG-Net在植物识别的优势(1) 卷积核,池化核大小固定(2) 特征提取更全面(3) 网络训练误差收敛速度较快 3 VGG-Net的搭建3.1 Tornado简介(1) 优势(2) 关键代码 4 Inception V3 神经网络4.1 网络结构 5 开始训练5.1 数据集…...

自动驾驶HWP 功能规范
目 录 概述 1 目的 1范围 1术语及缩写 1设计与实验标准 1 设计标准 2设计标准执行优先顺序 2功能规范 Specification 4 功能描述 Functional Description 4 工作条件与应用范围 Application Scope 4道路交通 4天气与光线 4传感器方案及需求 5 驾驶员状态监控系统 5前视摄像…...
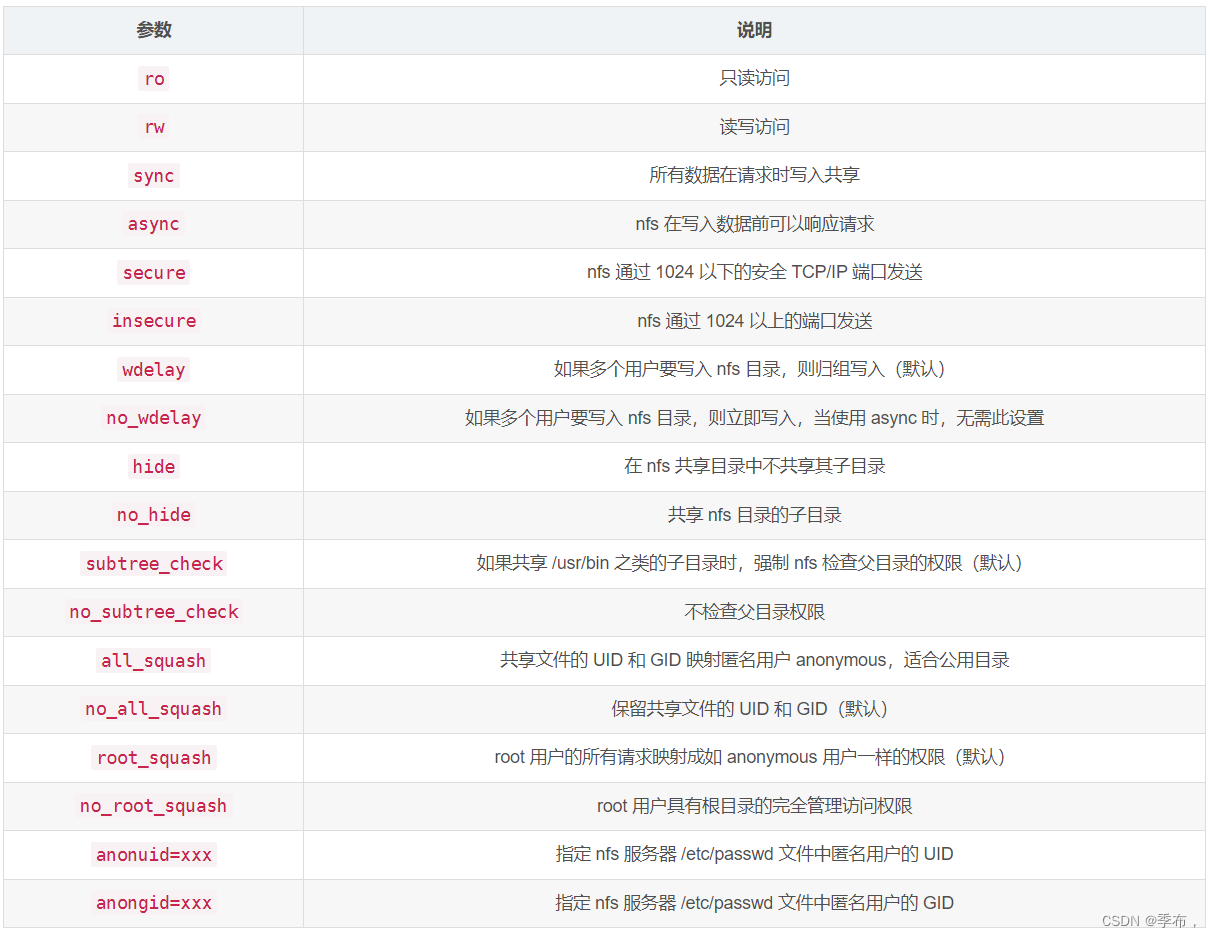
Ubuntu 环境下 NFS 服务安装及配置使用
需求:公司内部有多台物理服务器,需要A服务器上的文件让B服务器访问,也就是两台服务器共享文件,当然也可以对A服务器上的文件做权限管理,让B服务器只读或者可读可写 1、NFS 介绍 NFS 是 Network FileSystem 的缩写&…...
vue.js如何根据后台返回来的图片url进行图片下载
原创/朱季谦 最近在做一个前端vue.js对接的功能模块时,需要实现一个下载图片的功能,后台返回来的是一串图片url,试了很多种方法,发现点击下载时出来的效果,都是跳到一个新的图片网页,后来经过一番琢磨&…...

获取WordPress分类链接
CMS模板主题首页多以分类列表的形式展示内容,一般需要在适当位置添加某分类归档页面链接的按钮,下面的代码可以帮你实现。 代码一、通过分类别名获取Wordpress分类链接: <?php $catget_category_by_slug(‘wordpress’); $cat_linksget_…...
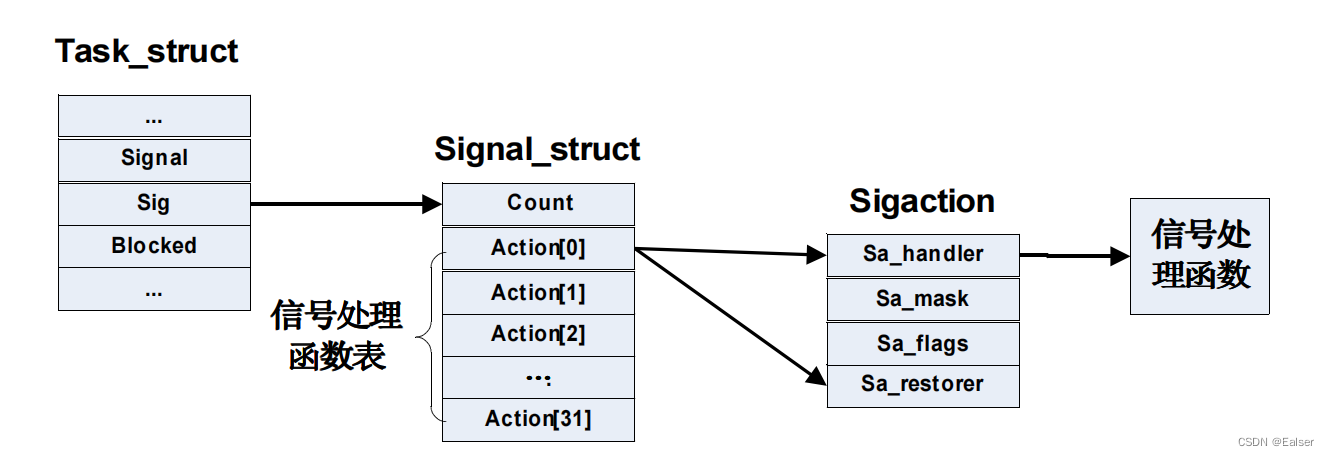
<Linux>(极简关键、省时省力)《Linux操作系统原理分析之Linux 进程管理 5》(9)
《Linux操作系统原理分析之Linux 进程管理 5》(9) 4 Linux 进程管理4.5 Linux 信号4.5.1 信号的作用和种类1.信号机制2.信号种类 4.5.2 信号的处理4.5.3 信号处理函数1.数据结构2. 处理函数 signal3.程序例 4 Linux 进…...

Anthropic推出Claude 2.1聊天机器人;使用AI工具写作:挑战与策略
🦉 AI新闻 🚀 Anthropic推出Claude 2.1聊天机器人,支持20万个Token输入和提高准确度 摘要:Anthropic推出了Claude 2.1聊天机器人及对应的AI模型,支持输入多达20万个Token,并在准确度上有所改善。Claude已…...

2023-11-30 LeetCode每日一题(确定两个字符串是否接近)
2023-11-30每日一题 一、题目编号 1657. 确定两个字符串是否接近二、题目链接 点击跳转到题目位置 三、题目描述 如果可以使用以下操作从一个字符串得到另一个字符串,则认为两个字符串 接近 : 操作 1:交换任意两个 现有 字符。 例如&…...
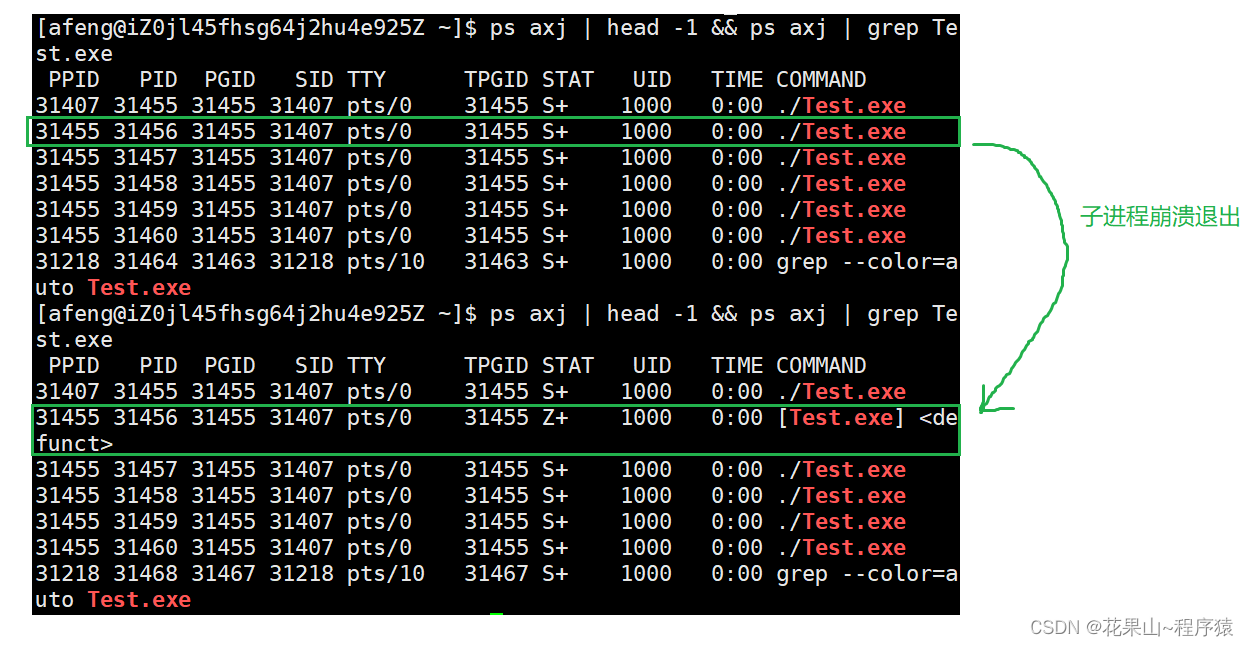
进程间通信基础知识【Linux】——上篇
目录 一,理解进程之间的通信 1. 进程间通信目的 2. 进程间通信的技术背景 3,常见的进程间通信 二,管道 1. 尝试建立一个管道 管道的特点: 管道提供的访问控制: 2. 扩展:进程池 阶段一:…...
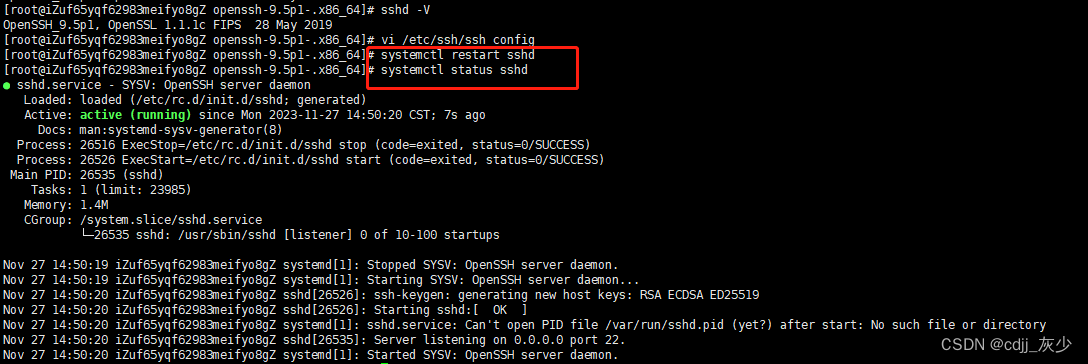
OpenSSH(CVE-2023-38408)OpenSsh9.5一键升级修复
yum install -y git cd /root git clone https://gitee.com/qqmiller/openssh-9.5p1-.x86_64.git cd openssh-9.5p1-.x86_64/ bash openssh_update.sh重启sshd: systemctl restart sshd 查看sshd状态: systemctl status sshd 重要的是按此操作升级完成…...

ChatGPT企业版知识库构建全流程:从非结构化PDF到可审计问答系统的48小时极速上线方案
更多请点击: https://kaifayun.com 第一章:ChatGPT企业版核心能力概览 ChatGPT企业版面向中大型组织设计,聚焦数据安全、系统集成与规模化部署三大支柱,在保留通用大模型强大语言理解与生成能力的同时,强化了企业级可…...

基于SpringBoot的技术博客与开源知识分享平台毕设
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot技术栈的技术博客与开源知识分享平台以解决传统知识传播模式中存在的信息孤岛现象与协作效率低下问题。随着信息技术的快速发…...

为Hermes Agent配置自定义供应商并接入Taotoken聚合服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置自定义供应商并接入Taotoken聚合服务 Hermes Agent 是一个流行的智能体开发框架,它支持通过配置不同…...

DeepSeek推理内存暴涨400%的元凶找到了:详解PagedAttention在DeepSeek-VL中的适配陷阱与绕过方案
更多请点击: https://codechina.net 第一章:DeepSeek推理内存暴涨400%的现象复现与根因定位 在部署 DeepSeek-R1-7B 模型进行批量文本生成时,我们观测到 GPU 显存占用从预期的约 8.2 GB 飙升至 41.3 GB,增幅达 400%,显…...

如何用NightX Client彻底改变你的Minecraft 1.8.9游戏体验?终极功能解析
如何用NightX Client彻底改变你的Minecraft 1.8.9游戏体验?终极功能解析 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client 想要在Minecraft 1.8.9中…...

PVZ Toolkit终极指南:如何用专业工具解锁植物大战僵尸无限可能
PVZ Toolkit终极指南:如何用专业工具解锁植物大战僵尸无限可能 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 你是否曾在植物大战僵尸的战场上为资源不足而苦恼?是否想体验…...

3步解锁:开源工具Applera1n完全指南——iOS 15-16激活锁绕过方案
3步解锁:开源工具Applera1n完全指南——iOS 15-16激活锁绕过方案 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n Applera1n是一款专为iOS 15-16系统设计的免费开源激活锁绕过工具ÿ…...

DeepXDE终极指南:如何用科学机器学习轻松求解物理方程
DeepXDE终极指南:如何用科学机器学习轻松求解物理方程 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde DeepXDE是一款革命性的开源科学机器学习库…...

量化精度不妥协,吞吐翻2.8倍——DeepSeek-R1推理优化黄金参数组合大曝光,仅限本周公开
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1推理优化的底层逻辑与精度守恒原理 DeepSeek-R1作为面向长上下文、高吞吐场景设计的开源大语言模型,其推理优化并非以牺牲数值精度为代价换取速度提升,而是建立在计算…...

【2024B站算法白皮书级洞察】:ChatGPT如何精准预测“推荐池准入阈值”?3个被官方文档隐去的关键信号
更多请点击: https://intelliparadigm.com 第一章:【2024B站算法白皮书级洞察】:ChatGPT如何精准预测“推荐池准入阈值”?3个被官方文档隐去的关键信号 Bilibili 2024年Q2推荐系统升级后,“推荐池准入阈值”ÿ…...