机器学习的复习笔记1
机器学习是一种人工智能的分支,它通过让计算机从数据中学习规律和模式,从而实现对未知数据的预测和决策。根据不同的学习方法和任务,机器学习可以分为以下几种类型:
-
监督学习:在监督学习中,计算机会被提供一组包含输入和期望输出的训练数据,从而学习到一个映射关系。在训练完成后,计算机可以使用这个映射关系对未知数据进行预测。常见的监督学习算法有线性回归、逻辑回归、支持向量机等。
-
无监督学习:与监督学习不同,无监督学习的目标是发现数据中的隐藏结构和模式,而无需提供明确的输入和输出关系。常见的无监督学习算法有聚类(K-means、DBSCAN等)、降维(PCA、t-SNE等)和异常检测等。
-
半监督学习:半监督学习是一种结合了监督学习和无监督学习的方法,它同时利用带有标签和无标签的数据进行学习。半监督学习的目标是利用有限的标签数据提高模型性能,并在一定程度上利用无标签数据进行自我调整。
-
强化学习:强化学习是一种让计算机通过与环境互动学习最优行为策略的方法。在强化学习中,计算机扮演着一个智能体的角色,通过不断尝试和调整行为,以最大化预期的长期回报。常见的强化学习算法有Q学习、深度Q网络(DQN)和策略梯度方法(PG)等。
-
深度学习:深度学习是一种基于神经网络的机器学习方法,它通过多层神经元来模拟人脑的复杂结构,以实现对高级别抽象和复杂数据的处理。深度学习在很多领域取得了显著的成果,如计算机视觉、自然语言处理、语音识别等。
一、监督学习与无监督学习的异同
相同点:
- 都属于机器学习范畴,通过训练数据来提高模型性能。
- 都需要大量数据作为训练样本,以获取更好的泛化能力。
- 训练过程中都需要对数据进行预处理,如特征提取、特征缩放等。
不同点:
- 数据集性质:监督学习数据集包含输入特征和对应的目标变量(标签),而无监督学习数据集仅包含输入特征,没有目标变量。
- 学习目标:监督学习旨在寻找输入特征和目标变量之间的映射关系,从而实现对未知数据的预测;无监督学习则旨在挖掘数据内部的结构和分布规律,不关注具体的目标变量。
- 模型评价:监督学习可以使用准确率、精确率、召回率等指标来评估模型性能;无监督学习通常使用聚类效果、降维效果等指标来评估模型性能。
- 应用场景:监督学习适用于分类、回归等具有明确目标变量的任务;无监督学习适用于聚类、降维、异常检测等无明确目标变量的任务。
翻译成人话就是:
1.监督学习的数据集中不仅要给出前提条件(特征),还要给正确答案;而无监督学习只给出条件。
2.在监督学习中既然给出了条件,又给出了答案,那么训练后的模型当然是跟你的答案差距做为评判标准;但无监督学习的数据中本就是杂乱的,机器只是通过设定的模型进行归类,归类的结构的合理与否则成了评判无监督学习的优劣标准。
3.监督学习可以利用回归来预测数据走势,也可以进行分类;而无监督学习只能用来聚类。
【分类:分类任务主要用于将数据集中的数据点划分到预先定义的类别中。分类方法通常用于识别模式并将有相似特征的数据点归为一类。分类任务的关键在于找到不同类别之间的特征差异,例如垃圾邮件分类、情感分析、疾病预测等。
聚类:聚类任务则用于发现数据集中的潜在结构,将相似的数据点划分到同一组中,而无需预先定义类别。聚类方法可以帮助我们了解数据点之间的相互关系,例如客户分群、文档主题分类、蛋白质结构分析等。】
二、深度学习与机器学习的异同
深度学习和机器学习都是人工智能领域的技术,它们在某些方面有一定的相似性,但也有显著的不同之处。以下是深度学习和一般机器学习的异同:
相同点:
-
目标:深度学习和机器学习都是为了实现人工智能,提高计算机系统对数据的处理和分析能力。
-
数据处理:两者都需要大量数据进行训练,以便对未知数据进行预测和分类。
-
迭代优化:深度学习和机器学习算法都采用迭代优化的方法,通过不断调整模型参数来逼近最优解。
不同点:
-
工作原理:深度学习是一种基于神经网络的机器学习方法,它通过多层神经网络结构对数据进行特征提取和表示;而机器学习则是利用数学算法和统计方法对数据进行建模,从而实现对数据的分析。
-
模型结构:深度学习模型通常具有多层结构,包括输入层、隐藏层和输出层,层与层之间有全连接或卷积连接;机器学习模型的结构则因算法而异,如线性回归、决策树等。
-
数据表示:深度学习能够处理连续和离散的数据,并通过神经网络自动学习数据的特征表示;而机器学习通常需要人工设计特征提取方法来表示数据。
-
训练方法:深度学习采用反向传播算法来调整权重和偏置,同时可以使用动量、权重衰减等技巧加速收敛;机器学习算法包括梯度下降、随机梯度下降、牛顿法等优化方法。
-
数据量要求:深度学习需要大量的数据进行训练,以充分学习数据的特征;而机器学习算法在数据量较少的情况下也能取得较好的效果。
-
应用领域:深度学习在图像识别、语音识别、自然语言处理等领域具有广泛应用;机器学习则广泛应用于数据挖掘、推荐系统、金融领域等。
-
解释性:深度学习往往缺乏可解释性,难以解释模型的决策依据;而机器学习算法在一定程度上具有可解释性,可以分析模型的决策过程。
总之,深度学习和机器学习在某些方面有一定的相似性,但在工作原理、模型结构、训练方法和应用领域等方面存在显著差异。在实际应用中,可以根据具体问题和数据特点选择合适的方法进行处理。
三、半监督学习
半监督学习是一种机器学习方法,它结合了监督学习和无监督学习的特点,利用标记数据和未标记数据进行训练。以下是半监督学习的主要特点:
-
数据分布:半监督学习数据集由标记数据和未标记数据组成。通常情况下,标记数据较少,未标记数据占主导地位。
-
学习方式:半监督学习结合了监督学习和无监督学习的方法。它利用标记数据进行分类或回归任务,同时利用未标记数据进行无监督特征学习或数据聚类。
-
一致性正则化:半监督学习通过一致性正则化方法鼓励模型在无标签数据上的预测结果保持一致,使模型学习到更具有泛化能力的决策边界。
-
代理标签法:半监督学习可以利用无监督学习方法生成伪标签,将未标记数据转化为半监督数据。通过这种方式,模型可以利用更多的未标记数据进行训练。
-
自我训练:半监督学习可以通过不断迭代的方式,利用已有的模型对未标记数据进行预测,生成新的标记数据,从而扩充训练集。
-
降低标注成本:半监督学习可以利用大量未标记数据进行训练,降低对标注数据的依赖,从而降低标注成本。
-
鲁棒性:半监督学习在面对噪声数据和数据不平衡的情况下具有较强的鲁棒性。
-
适用场景:半监督学习适用于许多实际场景,如图像识别、自然语言处理、生物信息学等领域,其中部分数据具有难以获取或标注的特点。
以下是一些半监督学习的具体应用:
-
图像识别:在图像识别任务中,半监督学习可以利用少量的标注数据和大量的未标注数据来提高模型的性能。例如,可以使用标注数据训练一个初步的分类器,然后用该分类器对未标注数据进行分类,并根据分类结果对模型进行进一步的训练和调整。
-
自然语言处理:在自然语言处理领域,半监督学习可以应用于词义消歧、文本分类和机器翻译等任务。例如,在机器翻译任务中,可以使用少量标注的双语语料库和大量的未标注单语语料库来训练模型。
-
语音识别:半监督学习在语音识别领域也有广泛应用。例如,可以使用标注数据训练一个初步的声学模型,然后利用未标注数据进行模型调整,以提高识别性能。
-
推荐系统:在推荐系统中,半监督学习可以用于解决冷启动问题(即新用户或新物品的推荐问题)。通过使用少量标注数据和大量未标注数据,半监督学习可以帮助模型学习用户和物品之间的隐含关系,从而提高推荐效果。
-
生物信息学:在生物信息学领域,半监督学习可以应用于基因表达数据分析、蛋白质结构预测等任务。例如,可以使用少量标注的生物数据和大量的未标注数据来训练模型,以预测生物分子的功能或结构。
-
计算机视觉:在计算机视觉领域,半监督学习可以用于目标检测、目标跟踪等任务。例如,可以使用标注数据训练一个初步的目标检测模型,然后利用未标注数据进行模型调整,以提高检测性能。
总之,半监督学习在许多领域都具有广泛的应用前景,通过利用有限的标注数据和大量的未标注数据,可以有效提高模型的性能和泛化能力。
【半监督学习即给出基础判断能力(初始能力),划定初始方向,避免无序发展】
四、强化学习
强化学习(Reinforcement Learning,简称 RL)是机器学习的一种方法,它通过让智能体(Agent)在环境(Environment)中采取行动,根据环境给出的奖励或惩罚信号进行学习,使得智能体在同样的环境中采取的行动能够获得最大累计奖励。
强化学习的核心概念如下:
-
智能体(Agent):执行动作并学习优化策略的实体。
-
环境(Environment):智能体所处的情境,为智能体提供状态(State)和反馈(Reward)。
-
状态(State):描述智能体在环境中的具体状况。
-
动作(Action):智能体在环境中可以采取的行为。
-
奖励(Reward):智能体在采取某个动作后,环境给出的正面或负面反馈。
-
策略(Policy):智能体根据当前状态选择动作的规则。
-
价值函数(Value Function):用于评估智能体在某个状态下的长期收益。
强化学习的目标是使智能体在与环境互动的过程中,学会制定最优策略,从而在同样的环境中获得最大累计奖励。强化学习与监督学习和无监督学习的区别在于,它不需要大量标记数据,而是通过与环境的交互和学习奖励信号来提高性能。
强化学习可以应用于各种领域,如游戏、机器人控制、推荐系统、自动驾驶等。在这些应用中,智能体需要在与环境互动的过程中学习最优策略,以完成特定任务或最大化奖励。
【强化学习最大的特点是能够与外界环境交互,类似于训练犬类一样,叼对了东西有奖励,叼错了给惩罚,需要外部环境给予判断来干预】
相关文章:

机器学习的复习笔记1
机器学习是一种人工智能的分支,它通过让计算机从数据中学习规律和模式,从而实现对未知数据的预测和决策。根据不同的学习方法和任务,机器学习可以分为以下几种类型: 监督学习:在监督学习中,计算机会被提供一…...
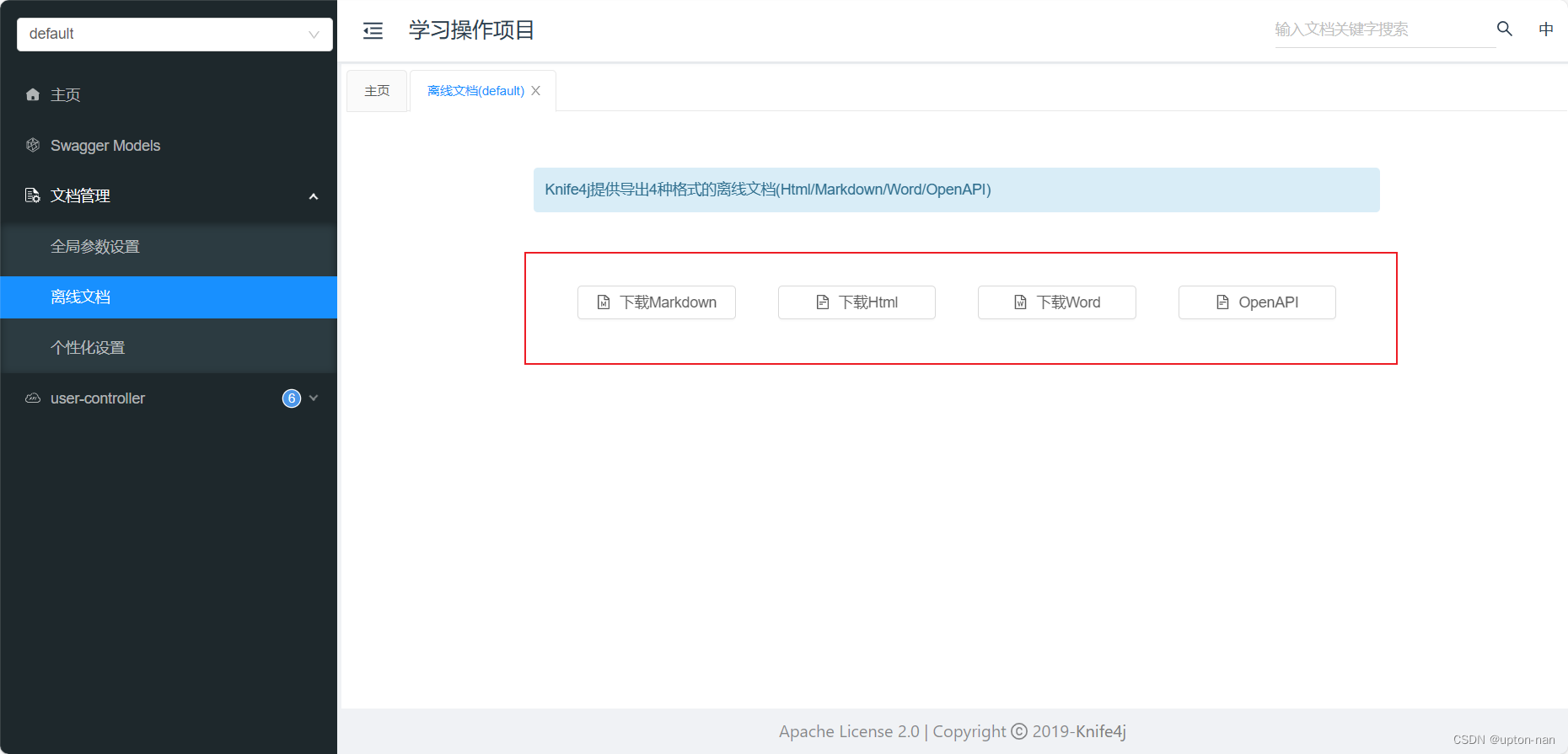
【Spring Boot】如何集成Swagger
Swagger简单介绍 Swagger是一个规范和完整的框架,用于生成、描述、调用和可视化RESTful风格的Web服务。功能主要包含以下几点: 可以使前后端分离开发更加方便,有利于团队协作接口文档可以在线自动生成,有利于降低后端开发人员编写…...
优化-查询数据接口太慢
有一个查询接口,主业务表有几万多条数据,没超过十万,由于没有使用分页,所以每次查询都要返回大几万的数据,然后问题是前端页面查询数据显示数据要转很久。 压缩响应体大小 我发现查询的时间是1秒多,但是浏…...

c++ 谓词
1. 一元谓词 #include <iostream> #include<vector> #include<algorithm>using namespace std;class CreaterFive{ public:bool operator()(int val){return val>5;} };int main() {vector<int> vec;for(int i0; i<10; i){vec.push_back(i);}ve…...

一篇总结 Linux 系统启动的几个汇编指令
学习 Linux 系统启动流程,必须熟悉几个汇编指令,总结给大家。 这里不是最全的,只列出一些最常用的汇编指令。 一.数据处理指令 1.数据传送指令 【MOV指令】 把一个寄存器的值(立即数)赋给另一个寄存器,或者将一个…...
python技术栈之单元测试中mock的使用
什么是mock? mock测试就是在测试过程中,对于某些不容易构造或者不容易获取的对象,用一个虚拟的对象来创建以便测试的测试方法。 mock的作用 特别是开发过程中上下游未完成的工序导致当前无法测试,需要虚拟某些特定对象以便测试…...
LeetCode(37)矩阵置零【矩阵】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 73. 矩阵置零 1.题目 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]…...

[Python入门系列之十一]在windows上安装OpenCV
1-安装OpenCV 如果是python3.7–python3.9(已测试),直接安装即可 注:conda需要先激活虚拟环境后再安装 pip install opencv-python如果安装速度慢,使用下面的指令: pip install opencv-python -i https://pypi.tuna.tsinghua.e…...
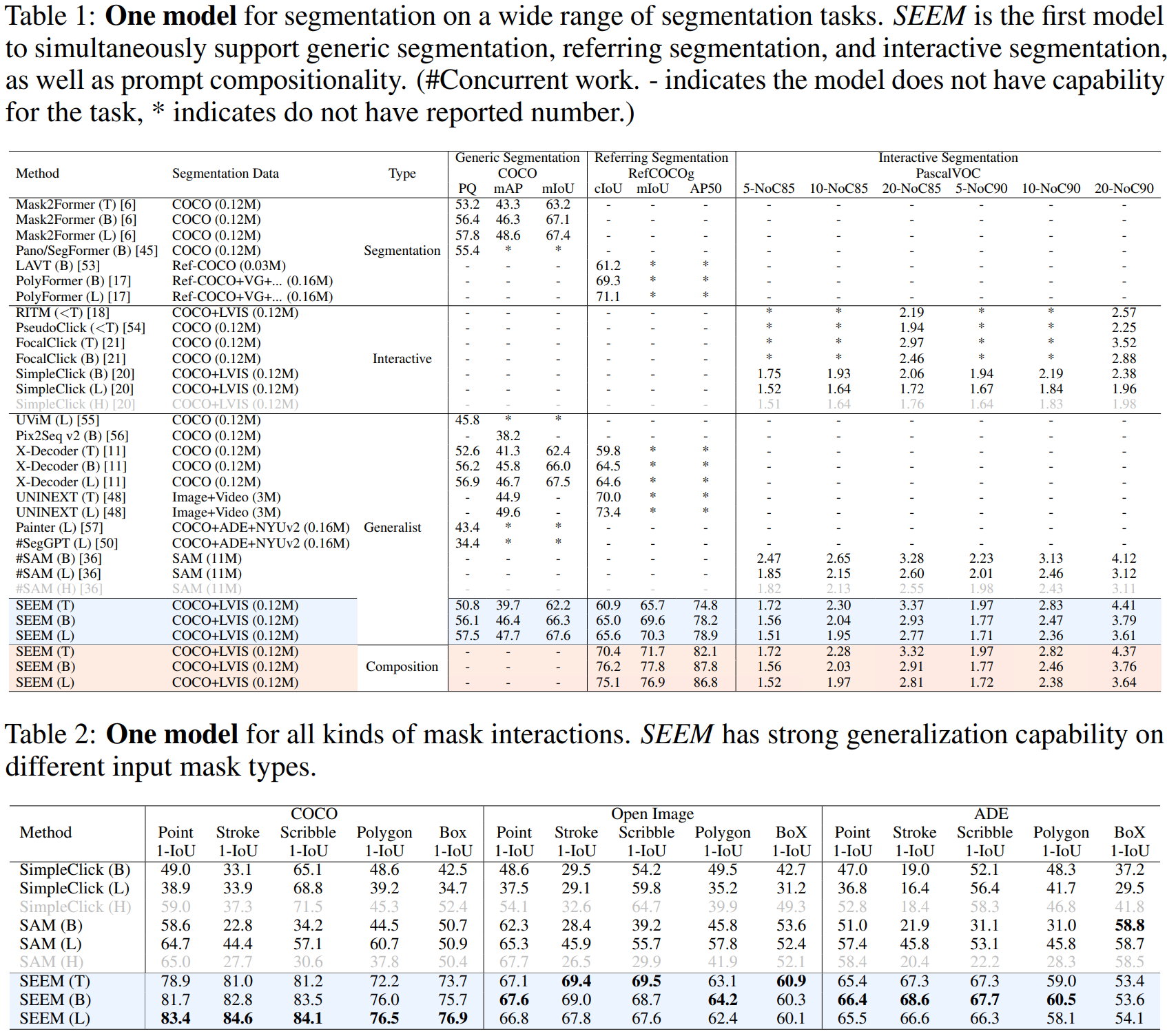
论文阅读——SEEM
arxiv: 分割模型向比较灵活的分割的趋势的转变:封闭到开放,通用到特定、one-shot到交互式。From closed-set to open-vocabulary segmentation,From generic to referring segmentation,From one-shot to interactive segmentati…...
Python入门06布尔值
目录 1 什么是布尔值2 怎么生成布尔值3 在控制程序中使用布尔值4 数据过滤、排序和其他高级操作总结 1 什么是布尔值 首先我们要学习一下布尔值的定义,布尔值是一种数据类型,它只有两个可能的值:True(真)或 False&…...

js查询详情接口控制执行时间的命令
在JavaScript中,可以使用console.time()和console.timeEnd()来控制执行时间的命令。 console.time()用于开始计时,可以指定一个标识符作为参数,用于标识计时器。 console.time(query); // 执行查询操作 console.timeEnd(query); 执行上述代…...
Linux系统iptables
目录 一. 防火墙简介 1. 防火墙定义 2. 防火墙分类 ①. 网络层防火墙 ②. 应用层防火墙 二. iptables 1. iptables定义 2. iptables组成 ①. 规则表 ②. 规则链 3. iptables格式 ①. 管理选项 ②. 匹配条件 ③. 控制类型 四. 案例说明 1. 查看规则表 2. 增加新…...

每日一题 1410. HTML 实体解析器(中等,模拟)
模拟,没什么好说的 class Solution:def entityParser(self, text: str) -> str:entityMap {": ",': "",>: >,<: <,⁄: /,&: &,}i 0n len(text)res []while i < n:isEntity Falseif …...
Docker Swarm总结+service创建和部署、overlay网络以及Raft算法(2/5)
博主介绍:Java领域优质创作者,博客之星城市赛道TOP20、专注于前端流行技术框架、Java后端技术领域、项目实战运维以及GIS地理信息领域。 🍅文末获取源码下载地址🍅 👇🏻 精彩专栏推荐订阅👇🏻…...

对抗产品团队中的认知偏误:给产品经理的专家建议
今天的产品经理面临着独特的挑战。他们不仅需要设计和构建创新功能,还必须了解这些功能将如何为客户带来价值并推进关键业务目标。如果不加以控制,认知偏差可能会导致您构建的内容与客户想要的内容或业务需求之间不一致。本文将详细阐述产品经理可以避免…...

element-ui表格无法横向拖动问题
是不是用到了fixed // 因为我只有在小屏显示不下的时候才会出现这个问题所以我在这里做了适配(建议把样式放在全局) media screen and (max-width: 1800px) {// 由于使用了fixed导致横向条无法拖动出现bug.Table-page .el-table__fixed {height: auto !important;bottom: 2px …...

每天学习一点点之 MySQL TINYINT
我已经不是第一次遇到关于 TINYINT 的问题了。在 MySQL 中,当我们将某个字段设置为 TINYINT,随着业务的扩展,我们可能会发现 TINYINT 的范围无法满足需求。这时需要修改字段属性。但如果表的数据量很大,或者由于分表导致涉及的表数…...

【数据集】未来不同情景下预测数据:如人口、土地利用等
未来不同情景下预测数据:如人口、土地利用等 1 人口数据1.1 Global One-Eighth Degree Population Base Year and Projection Grids Based on the SSPs, v1.01 (2000 – 2100)数据介绍数据下载1.2 Global dataset of gridded population and GDP scenarios数据介绍数据下载2…...

TDA4VM EVM开发板调试笔记
文章目录 1. 前言2. 官网资料导读3. 安装 Linux SDK4. 制作SD 启动卡5. 验证启动1. 前言 TDA4作为一般经典的车规级SOC芯片,基于它的低阶智驾方案目前成为各家智驾方案公司的量产首选,这也使得基于TDA4的开发需求陡增,开发和使用TDA4既要熟悉Linux驱应用开发,还要熟悉传统…...

项目里边更换了同名的图片地址 / 图片没有及时更新 / 什么原因
一、问题分析 1.1、分析一 浏览器缓存 项目里边更换了同名的图片地址,图片没有及时更新 可能是浏览器缓存的原因,浏览器会将之前访问过的文件缓存下来,下次访问同名的文件时会先从缓存中读取。 如果相同的图片地址没有发生变化,…...

管理企业多项目API Key与访问权限的最佳实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 管理企业多项目API Key与访问权限的最佳实践 在企业或团队中引入大模型能力时,一个常见的挑战是如何安全、高效地管理多…...

昇腾CANN cann-recipes-infer Continuous Batching:从静态 Padding 到动态调度,吞吐翻 10 倍
LLM 推理服务线上最大的浪费:静态 batching。一个 batch 里 8 个请求,序列长度从 12 到 2048——短的 12 个 token 2ms 就算完了,然后等长的那条跑完。190ms 算力闲置,GPU/NPU 空转。Continuous Batching 的解法:不等—…...

ChatGPT翻译质量断崖式下滑的真相:当LLM遇上专业领域术语库缺失,这4种场景下错误率超61%——你的项目还在裸奔吗?
更多请点击: https://codechina.net 第一章:ChatGPT翻译质量怎么样 ChatGPT 在翻译任务中展现出较强的上下文理解能力与语言生成流畅性,但其质量受输入提示(prompt)设计、源语言复杂度、专业领域术语密度及目标语言语…...

CentOS 7 Minimal安装后,别急着装图形界面!先试试这个命令搞定粘贴和联网
CentOS 7 Minimal安装后的高效运维起点:命令行解决粘贴与联网难题当你第一次启动刚安装好的CentOS 7 Minimal系统,面对漆黑终端闪烁的光标,是否感到一丝不安?许多新手在遇到无法从宿主机粘贴命令或无法联网时,第一反应…...

解密AliceSoft游戏资源处理:从提取到编辑的完整解决方案
解密AliceSoft游戏资源处理:从提取到编辑的完整解决方案 【免费下载链接】alice-tools Tools for extracting/editing files from AliceSoft games. 项目地址: https://gitcode.com/gh_mirrors/al/alice-tools 你是否曾经想要深入了解AliceSoft游戏的内部结构…...

终极GTA5线上小助手:免费开源的游戏体验增强工具完整指南
终极GTA5线上小助手:免费开源的游戏体验增强工具完整指南 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 你是否厌倦了在GTA5线上模式中重复枯燥的刷钱任务?是否对复杂的游戏机制…...

颠覆性GIF处理终极方案:Gifsicle深度解密
颠覆性GIF处理终极方案:Gifsicle深度解密 【免费下载链接】giflossy Merged into Gifsicle! 项目地址: https://gitcode.com/gh_mirrors/gi/giflossy 你是否曾为网站上的GIF动画加载缓慢而烦恼?是否在处理大量GIF素材时感到力不从心?今…...

KLayout 0.29.12版图编辑工具:DRC验证引擎性能提升20%与多工艺节点设计支持
KLayout 0.29.12版图编辑工具:DRC验证引擎性能提升20%与多工艺节点设计支持 【免费下载链接】klayout KLayout Main Sources 项目地址: https://gitcode.com/gh_mirrors/kl/klayout KLayout是一款开源的集成电路版图编辑与验证工具,专注于GDSII/O…...

ChatGPT企业版安全合规全解析:如何在72小时内完成GDPR/等保2.0双认证接入?
更多请点击: https://intelliparadigm.com 第一章:ChatGPT企业版核心架构与合规定位 ChatGPT企业版并非简单叠加访问权限的SaaS服务,而是基于隔离部署、数据主权保障与策略可编程性构建的合规优先架构。其底层采用多租户物理隔离的专用基础设…...

如何实现离线语音识别:Vosk API终极实战指南
如何实现离线语音识别:Vosk API终极实战指南 【免费下载链接】vosk-api Offline speech recognition API for Android, iOS, Raspberry Pi and servers with Python, Java, C# and Node 项目地址: https://gitcode.com/GitHub_Trending/vo/vosk-api 想要为你…...