第十三章 python之爬虫
Python基础、函数、模块、面向对象、网络和并发编程、数据库和缓存、 前端、django、Flask、tornado、api、git、爬虫、算法和数据结构、Linux、设计题、客观题、其他
第十三章 爬虫
1. 写出在网络爬取过程中, 遇到防爬问题的解决办法。
在网络爬取过程中,可能会遇到防爬措施,网站为了防止被爬虫访问而采取一些手段。以下是一些常见的防爬措施以及相应的解决办法:### 1. **User-Agent检测:**
**问题:** 网站通过检查User-Agent头来判断请求是否来自浏览器。
**解决办法:** 修改请求的User-Agent头,使其模拟正常浏览器的请求。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)### 2. **IP封锁:**
**问题:** 网站限制了某个IP地址的访问频率。
**解决办法:** 使用代理IP轮换,通过更换IP地址来规避封锁。
proxies = {'http': 'http://your_proxy_ip:your_proxy_port', 'https': 'https://your_proxy_ip:your_proxy_port'}
response = requests.get(url, proxies=proxies)### 3. **验证码:**
**问题:** 网站通过弹出验证码来验证访问者的身份。
**解决办法:** 使用自动化工具识别和处理验证码,或者手动处理验证码。### 4. **动态加载和异步加载:**
**问题:** 网站使用JavaScript进行动态加载或异步加载数据,爬虫无法直接获取到全部数据。
**解决办法:** 使用带有JavaScript渲染功能的爬虫工具,如Selenium或Pyppeteer,来模拟浏览器行为。### 5. **Cookie检测:**
**问题:** 网站使用Cookie来跟踪用户,拒绝没有Cookie的请求。
**解决办法:** 在请求中加入合适的Cookie信息,可以通过登录获取Cookie,或手动设置Cookie。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Cookie': 'your_cookie_here'}
response = requests.get(url, headers=headers)### 6. **限制请求频率:**
**问题:** 网站设置了请求频率限制,过于频繁的请求会被拒绝。
**解决办法:** 降低爬取速度,增加请求的时间间隔,模拟人类的访问行为。### 7. **模拟登录:**
**问题:** 需要登录后才能访问网站内容。
**解决办法:** 使用爬虫模拟登录,获取登录后的Cookie,然后在后续请求中使用这些Cookie。以上是一些常见的防爬措施及其解决办法,需要根据具体情况选择合适的方法。
需要注意的是,爬虫行为应该遵循网站的规定,不应用于非法目的。
2. 如何提高爬虫的效率?
提高爬虫效率是爬虫开发中的一个关键目标,可以通过以下方法来提高爬虫的效率:### 1. **并发请求:**使用异步框架或多线程/多进程进行并发请求,以便同时发送多个请求,提高数据获取速度。常见的异步框架有`asyncio`、`aiohttp`、`twisted`等。### 2. **连接池:**使用连接池来复用HTTP连接,减少连接的建立和关闭开销。这可以通过`requests`库的`Session`对象来实现。### 3. **合理设置请求头和延时:**设置合理的User-Agent、Referer和其他请求头,模拟浏览器行为。另外,合理设置请求之间的延时,避免对服务器造成过大压力。### 4. **使用代理IP:**使用代理IP来避免IP封锁,提高访问频率。可以使用公开代理IP,或者购买专业代理服务。### 5. **使用缓存:**对已经获取的数据进行缓存,避免重复请求。可以使用内存缓存、文件缓存或者数据库缓存,根据实际情况选择合适的缓存方式。### 6. **使用分布式爬虫:**如果爬取的目标数据量庞大,可以考虑使用分布式爬虫架构,将任务分配到多台机器上并行执行。### 7. **优化解析过程:**优化HTML解析过程,选择高效的解析库(例如BeautifulSoup、lxml);避免使用过于复杂的XPath或正则表达式,尽量减少解析的深度。### 8. **降低访问频率:**在遇到反爬虫限制时,可以通过减少请求频率、模拟人类行为、使用不同的IP等方式降低被封禁的概率。### 9. **合理设计爬取策略:**根据网站的特点和反爬虫机制,制定合理的爬取策略。可以通过设置合理的请求头、使用动态代理、避免过于频繁的爬取等方式规避反爬虫措施。### 10. **定期更新爬虫规则:**定期检查目标网站的变化,更新爬虫规则。网站结构和反爬虫策略可能会发生变化,及时更新爬虫以适应新的情况。### 11. **使用高性能数据库:**如果爬虫需要将数据存储到数据库,选择高性能的数据库,以提高数据存取效率。### 12. **异常处理和重试机制:**设置良好的异常处理机制,对于请求失败的情况进行合理的重试。避免由于一次请求失败导致整个爬虫中断。通过综合运用这些方法,可以提高爬虫的效率,使其更加稳定和高效地获取目标数据。
根据具体的爬取场景和网站特点,选择合适的优化方法是关键。
3. 你的爬虫 爬取的数据量有多少?
在这里插入代码片
4. 列举您使用过的python网络爬虫所用到的模块。
我是一个通用性的语言模型,没有实际的使用历史或记忆。但我可以为你列举一些常用的Python网络爬虫模块,这些模块在实际的网络爬虫开发中经常被使用:
1. **requests:** 用于发送HTTP请求,获取网页内容。import requests2. **BeautifulSoup:** 用于解析HTML或XML文档,提供方便的数据提取方法。from bs4 import BeautifulSoup3. **Scrapy:** 一个开源的、基于Python的爬虫框架,提供了完整的爬取流程。import scrapy4. **Selenium:** 用于模拟浏览器行为,支持JavaScript渲染。from selenium import webdriver5. **lxml:** 用于处理XML和HTML,比较快速高效。from lxml import etree6. **PyQuery:** 类似于jQuery的库,用于解析HTML文档。from pyquery import PyQuery as pq7. **urllib:** Python标准库中的模块,提供了一些处理URL的基本功能。from urllib import request, parse8. **ProxyPool:** 一个用于获取代理IP的工具,用于防止IP被封锁。- 可以通过第三方库,如`requests`,调用代理池中的代理IP。以上模块是常用的一些网络爬虫工具和库,它们可以根据具体的需求灵活组合使用。
在进行网络爬取时,需要根据目标网站的结构和反爬虫机制选择合适的工具和策略。
5. 简述 requests模块的作用及基本使用?
`requests` 是一个常用的Python第三方库,用于发送HTTP请求。
它简化了HTTP请求过程,提供了简洁而人性化的API,使得与Web服务进行交互变得更加容易。
`requests` 模块支持HTTP和HTTPS,可以方便地进行GET、POST等各种类型的请求。#### 主要功能:
1. **发送HTTP请求:** 使用requests.get(url)发送GET请求,使用requests.post(url, data=params)发送POST请求等。2. **请求头和参数设置:** 可以通过 `headers` 参数设置请求头,通过 `params` 参数设置请求参数。3. **响应处理:** 获取服务器响应内容,包括文本、二进制数据、JSON等。可以使用 `response.text` 获取文本内容,`response.content` 获取二进制内容。4. **状态码和异常处理:** 可以检查服务器返回的状态码,根据状态码进行异常处理。#### 基本使用示例:
1. **发送GET请求:**
import requestsurl = 'https://www.example.com'
response = requests.get(url)# 获取响应内容
content = response.text
print(content)
2. **发送POST请求:**
import requestsurl = 'https://www.example.com/login'
data = {'username': 'your_username', 'password': 'your_password'}
response = requests.post(url, data=data)# 获取响应内容
content = response.text
print(content)3. **设置请求头和参数:**
import requestsurl = 'https://www.example.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
params = {'key1': 'value1', 'key2': 'value2'}response = requests.get(url, headers=headers, params=params)# 获取响应内容
content = response.text
print(content)4. **异常处理:**
import requestsurl = 'https://www.example.com'try:response = requests.get(url)response.raise_for_status() # 检查是否请求成功(状态码2xx)content = response.textprint(content)
except requests.exceptions.RequestException as e:print(f"Error: {e}")6. 简述 beautifulsoup模块的作用及基本使用?
`BeautifulSoup` 是一个Python库,用于从HTML或XML文档中提取数据。
它提供了一种Pythonic的方式来遍历、搜索和修改文档树,使得数据提取变得更加方便。
`BeautifulSoup` 可以解析标准的HTML或XML文档,处理不规范的标记,
并提供了简便的API用于导航文档树和搜索特定元素。#### 主要功能:
1. **解析HTML/XML文档:** 将HTML或XML文档解析为一个文档树,方便后续的搜索和遍历。2. **搜索文档:** 提供强大的搜索功能,可以通过标签名、类名、属性等条件来定位和提取数据。3. **遍历文档树:** 可以沿着文档树的层次结构进行遍历,获取文档中的各个元素。4. **提取数据:** 通过各种方法,如获取标签内容、属性值等,方便地提取所需的数据。#### 基本使用示例:
1. **安装 BeautifulSoup:**
pip install beautifulsoup42. **解析HTML文档:**
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>Sample HTML Document</title>
</head>
<body><h1>Heading 1</h1><p class="paragraph">This is a sample paragraph.</p><ul><li>Item 1</li><li>Item 2</li></ul>
</body>
</html>
"""# 使用BeautifulSoup解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')3. **搜索文档:**
# 通过标签名搜索
heading = soup.h1
print(heading.text)# 通过类名搜索
paragraph = soup.find('p', class_='paragraph')
print(paragraph.text)# 通过属性值搜索
list_item = soup.find('li', text='Item 1')
print(list_item.text)4. **遍历文档树:**
# 遍历所有的段落标签
for paragraph in soup.find_all('p'):print(paragraph.text)# 遍历所有的列表项标签
for li in soup.find_all('li'):print(li.text)5. **提取数据:**
# 获取标题标签的文本内容
title = soup.title
print(title.text)# 获取第一个列表项的文本内容
first_item = soup.ul.li
print(first_item.text)以上是 `BeautifulSoup` 的一些基本用法,用于解析和提取HTML文档中的数据。
`BeautifulSoup` 还有更多高级的功能,可以根据具体需求查看官方文档:[Beautiful Soup Documentation](https://www.crummy.com/software/BeautifulSoup/bs4/doc/)。
7. 简述 seleninu模块的作用及基本使用?
**Selenium** 是一个用于自动化浏览器操作的工具,常用于Web应用的测试,但也可以用于爬虫等任务。Selenium支持多种浏览器,包括Chrome、Firefox、Edge等,它能够模拟用户在浏览器中的操作,如点击、输入文本、提交表单等。#### 主要功能:
1. **模拟浏览器操作:**Selenium可以自动打开浏览器,模拟用户在浏览器中的操作,如点击、输入文本、提交表单等。2. **动态页面渲染:** 对于使用JavaScript动态加载内容的页面,Selenium可以等待页面完全加载后再进行操作。3. **跨浏览器兼容性:** Selenium支持多种浏览器,使得脚本可以在不同的浏览器中执行。#### 基本使用示例:
1. **安装 Selenium:**
pip install selenium2. **下载浏览器驱动:**Selenium需要与浏览器对应版本的驱动程序,例如Chrome需要下载ChromeDriver。将驱动程序放在系统的PATH中或指定路径。ChromeDriver下载地址:[ChromeDriver](https://sites.google.com/chromium.org/driver/)3. **基本使用示例:**
from selenium import webdriver
# 创建浏览器对象
driver = webdriver.Chrome(executable_path='path/to/chromedriver')# 打开网页
driver.get('https://www.example.com')# 操作页面元素
search_box = driver.find_element('name', 'q')
search_box.send_keys('Python')# 提交表单
search_box.submit()# 等待页面加载
driver.implicitly_wait(10) # 最多等待10秒# 获取页面内容
content = driver.page_source
print(content)# 关闭浏览器
driver.quit()上述示例演示了使用Selenium打开Chrome浏览器,访问网页,输入关键词,提交搜索表单,
等待页面加载,获取页面内容,最后关闭浏览器。Selenium还有其他丰富的功能,包括处理弹窗、切换窗口、模拟鼠标操作等。
根据需要可以查阅官方文档获取更多信息:[Selenium with Python](https://selenium-python.readthedocs.io/)。
8. 简述scrapy框架中各组件的工作流程?
Scrapy是一个开源的Python爬虫框架,它的工作流程可以简要描述为以下几个组件:
1. **Spider:**- Spider是定义爬取规则和开始爬取的组件。每个Spider负责爬取一个特定的网站(或一部分网站)。- Spider定义了如何发起请求、如何处理响应、如何提取数据等规则。2. **Scheduler:**- Scheduler负责管理Spider发起的请求,将请求队列中的请求分发给Downloader。- 当Spider发起一个请求时,该请求会经过Scheduler,Scheduler会将请求加入请求队列,等待下载。3. **Downloader:**- Downloader是负责下载网页内容的组件。它接收来自Scheduler的请求,下载网页内容,并将下载的响应返回给Spider。- Downloader还负责处理请求的中间件、处理重定向、处理Cookies等。4. **Item Pipeline:**- Item Pipeline负责处理Spider返回的爬取到的数据。可以定义多个Item Pipeline,每个Pipeline都是一个单独的组件,处理特定的任务。- 例如,可以将数据存储到数据库、写入文件、发送邮件等。5. **Item:**- Item是爬取到的数据的容器,它定义了数据结构。Spider通过解析网页,从中提取数据,并将数据存储在Item中。- Item在Spider和Item Pipeline之间传递。6. **Middleware:**- Middleware是一个可扩展组件,可以在整个Scrapy流程中介入。它可以修改请求、修改响应、处理异常、设置代理等。- Scrapy提供了多个内置的Middleware,同时也支持用户自定义的Middleware。Scrapy的工作流程如下:
1. Spider发起初始请求。
2. 请求经过Scheduler,加入请求队列。
3. 请求被Downloader下载,返回响应。
4. 响应经过Downloader Middleware,处理请求、处理响应。
5. 响应传递给Spider,由Spider进行解析,提取数据。
6. 提取的数据被存储在Item中,传递给Item Pipeline进行后续处理。
7. Item Pipeline对数据进行处理,可以进行持久化存储等操作。整个过程循环执行,直到请求队列为空或达到停止条件。
Scrapy的组件结构使得用户能够灵活定义爬取规则、数据处理逻辑,并方便地进行扩展。
9. 在scrapy框架中如何设置代理(两种方法)?
在Scrapy框架中,设置代理可以通过使用Downloader Middleware来实现。下面介绍两种设置代理的方法:### 方法一:使用HttpProxyMiddleware
Scrapy提供了一个内置的HttpProxyMiddleware,可以方便地设置代理。在settings.py文件中进行配置。
1. 在settings.py中添加以下配置:DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 1,}2. 添加代理地址:HTTP_PROXY = 'http://your_proxy_address:your_proxy_port'HTTPS_PROXY = 'https://your_proxy_address:your_proxy_port'### 方法二:自定义Downloader Middleware
你也可以自定义一个Downloader Middleware来设置代理。
这种方法更加灵活,可以在请求级别设置不同的代理。
1. 创建一个名为middlewares.py的文件,并定义一个自定义的Downloader Middleware:from scrapy import signalsclass ProxyMiddleware:def process_request(self, request, spider):# 设置代理地址request.meta['proxy'] = 'http://your_proxy_address:your_proxy_port'2. 在settings.py中启用自定义Middleware:DOWNLOADER_MIDDLEWARES = {'your_project_name.middlewares.ProxyMiddleware': 1,}注意替换'your_project_name'为你的Scrapy项目名称。这两种方法都可以有效地为Scrapy设置代理,具体选择哪种取决于你的需求和项目结构。
如果只是简单地为整个Scrapy项目设置一个全局代理,使用HttpProxyMiddleware可能更加方便。
如果需要更灵活地在Spider中设置不同的代理,或者需要使用HTTPS代理,自定义Middleware可能更合适。
10. scrapy框架中如何实现大文件的下载?
在Scrapy框架中,可以使用`FilesPipeline`来处理大文件的下载。
`FilesPipeline`是Scrapy内置的一个管道,专门用于处理文件下载。下面是实现大文件下载的步骤:
1. **在settings.py中启用FilesPipeline:**在项目的settings.py文件中,确保启用了`FilesPipeline`:ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1,}2. **配置文件下载路径:**配置文件下载的存储路径,可以设置为相对路径或绝对路径。添加以下配置到settings.py:FILES_STORE = '/path/to/your/files'将`'/path/to/your/files'`替换为实际的存储路径。3. **定义Item中的文件字段:**在你的Item中定义一个字段用于存储文件的URL。假设你的Item类为`MyItem`,并且你要下载的文件URL存储在`file_urls`字段中,可以如下定义:class MyItem(scrapy.Item):file_urls = scrapy.Field()4. **调用FilesPipeline下载文件:**在Spider中,当你生成包含文件URL的Item时,Scrapy会自动调用`FilesPipeline`进行文件下载。确保你的Spider生成的Item包含正确的文件URL,例如:def parse(self, response):item = MyItem()item['file_urls'] = ['http://example.com/largefile.zip']yield item这样,Scrapy会自动将文件下载到指定的存储路径,并在Item中生成相应的字段(默认为`file`字段),包含文件的本地路径。5. **处理下载结果:**在Item中,可以通过`file`字段获取文件的本地路径:class MyItem(scrapy.Item):file_urls = scrapy.Field()files = scrapy.Field()在Pipeline中,你可以通过`file_path`字段获取文件的本地路径:class MyPipeline:def process_item(self, item, spider):file_info = item['files'][0]file_path = file_info['path']# 处理文件路径return item通过以上步骤,你可以使用Scrapy的`FilesPipeline`来方便地处理大文件的下载。
确保文件存储路径设置正确,Scrapy会自动下载文件并将文件路径存储在相应的Item字段中。
11. scrapy中如何实现限速?
在Scrapy中,你可以通过设置下载延迟(download delay)或使用AutoThrottle来实现限速。
这有助于控制爬虫的访问速度,防止对目标网站造成过大的压力,同时遵守爬取道德和法规。### 方法一:设置下载延迟
在`settings.py`中,通过设置`DOWNLOAD_DELAY`参数来控制下载延迟。
这个值表示两次下载请求之间的最小等待时间,单位为秒。
DOWNLOAD_DELAY = 2 # 设置下载延迟为2秒### 方法二:使用AutoThrottle
AutoThrottle是Scrapy的一个扩展,可以自动调整下载延迟以控制爬虫的访问速度。启用AutoThrottle需要设置以下参数:
AUTOTHROTTLE_ENABLED = True # 启用AutoThrottle
AUTOTHROTTLE_START_DELAY = 5.0 # 初始下载延迟(单位:秒)
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # 目标并发数
AUTOTHROTTLE_DEBUG = False # 开启调试模式- `AUTOTHROTTLE_START_DELAY`: 设置初始下载延迟。
- `AUTOTHROTTLE_TARGET_CONCURRENCY`: 设置目标并发数,即同时进行下载的请求数。
- `AUTOTHROTTLE_DEBUG`: 如果设置为True,将会输出更多关于AutoThrottle行为的调试信息。启用AutoThrottle后,Scrapy将根据目标并发数和下载延迟的调整,自动控制爬虫的访问速度。选择使用哪种方式,取决于你的具体需求。如果你希望手动设置一个常量的下载延迟,可以使用方法一。
如果你希望系统自动调整下载延迟,可以使用AutoThrottle。
12. scrapy中如何实现暂定爬虫?
在Scrapy中,你可以通过在Spider中使用信号(signal)来实现暂停爬虫。
具体来说,你可以使用`engine_paused`信号,这个信号会在引擎暂停时触发。以下是一个示例,演示如何在Spider中使用信号来实现爬虫的暂停和恢复:
import scrapy
from scrapy import signals
from twisted.internet import reactorclass MySpider(scrapy.Spider):name = 'my_spider'start_urls = ['http://example.com']def parse(self, response):# 爬虫处理逻辑self.log('Processing: %s' % response.url)def spider_idle(self):# 当爬虫空闲时,发送信号暂停爬虫self.log('Spider is idle. Pausing...')self.crawler.engine.pause()# 设置定时器,模拟一段时间后恢复爬虫reactor.callLater(60, self.resume_spider)def resume_spider(self):# 恢复爬虫self.log('Resuming spider...')self.crawler.engine.unpause()在这个示例中,Spider定义了`spider_idle`方法,该方法会在爬虫空闲时触发。
在`spider_idle`方法中,爬虫暂停使用`self.crawler.engine.pause()`,
并设置了一个60秒的定时器,模拟一段时间后恢复爬虫。你可以根据实际需求修改暂停和恢复的逻辑,例如,可以根据某些条件来触发暂停和恢复。
13. scrapy中如何进行自定制命令?
在Scrapy中,你可以通过编写自定义命令来扩展Scrapy的功能。自定义命令可以用于执行各种任务,
例如运行特定的爬虫、管理数据库、生成报告等。以下是一个简单的示例,展示如何创建和使用自定义命令:
1. **创建自定义命令文件:**在你的Scrapy项目中,创建一个名为`mycommand.py`的文件,用于定义自定义命令。from scrapy.commands import ScrapyCommandclass MyCommand(ScrapyCommand):requires_project = Truedefault_settings = {'LOG_ENABLED': False}def syntax(self):return "<argument>"def short_desc(self):return "Custom command to demonstrate Scrapy customization"def run(self, args, opts):argument = args[0] if args else Noneself.crawler_process.crawl('myspider', custom_argument=argument)self.crawler_process.start()在这个示例中,自定义命令`MyCommand`继承自`ScrapyCommand`,实现了`syntax`、`short_desc`和`run`等方法。`run`方法定义了自定义命令的具体执行逻辑。2. **注册自定义命令:**在你的Scrapy项目中的`settings.py`文件中,添加以下配置,将自定义命令注册到Scrapy中:COMMANDS_MODULE = 'myproject.commands'注意,`myproject`应该替换为你的Scrapy项目的实际名称。3. **运行自定义命令:**运行自定义命令的方法是使用`scrapy`命令行工具,并指定自定义命令的名称:scrapy mycommand arg_value其中,`mycommand`是自定义命令的名称,`arg_value`是自定义命令的参数。通过这个简单的示例,你可以看到如何创建和使用自定义命令。
根据实际需求,你可以扩展自定义命令的功能,执行不同的任务。
14. scrapy中如何实现的记录爬虫的深度?
在Scrapy中,记录爬虫的深度通常通过`meta`属性来实现。
`meta`属性是一个字典,用于在请求之间传递额外的信息,可以用来记录当前爬取的深度。以下是一个简单的示例,展示如何使用`meta`属性记录爬虫的深度:
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):# 获取当前深度depth = response.meta.get('depth', 0)# 爬虫处理逻辑self.log(f'Processing {response.url} at depth {depth}')# 如果深度未达到限制,继续爬取下一层链接if depth < 3:for next_url in response.css('a::attr(href)').extract():yield response.follow(next_url, callback=self.parse, meta={'depth': depth + 1})在这个示例中,`meta`属性用于传递当前深度信息。在`parse`方法中,
首先使用`response.meta.get('depth', 0)`获取当前深度,如果没有设置深度,默认为0。
然后在处理逻辑中,可以根据实际需求对深度进行操作。在继续爬取下一层链接时,使用`response.follow`方法传递`meta`属性,将深度加1。
这样就可以在后续请求中记录和使用深度信息。需要注意的是,Scrapy的深度是相对于起始URL而言的,而不是全局深度。
如果你需要记录全局深度,可能需要更复杂的逻辑和数据结构来进行管理。
15. scrapy中的pipelines工作原理?
在Scrapy中,Pipeline是一组按顺序处理爬取数据的组件。每个Pipeline都是一个Python类,
负责处理爬虫产生的Item。通过在settings.py中配置,你可以启用或禁用不同的Pipeline,
并控制它们的执行顺序。Pipeline的工作原理如下:
1. **Item生成:** 在Spider中,当Item被生成时,它会被传递到Pipeline。2. **Pipeline处理:** \Item会被依次传递给启用的每个Pipeline,并经过这些Pipeline的处理逻辑。每个Pipeline都需要实现process_item方法,对Item进行处理。process_item方法的返回值可以是Item本身,也可以是一个新的Item或者DropItem异常(用于丢弃Item)。class MyPipeline:def process_item(self, item, spider):# 处理Item的逻辑return item3. **处理顺序:** 在settings.py中,通过`ITEM_PIPELINES`设置启用的Pipeline及其执行顺序。例如:ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,'myproject.pipelines.AnotherPipeline': 400,}数字表示执行的顺序,数字越小越早执行。可以根据实际需求调整Pipeline的执行顺序。4. **处理结果:** 最终,经过所有启用的Pipeline处理后的Item将会被返回给引擎,然后根据Spider的配置(如写入文件、存储数据库等)进行最终的数据处理。5. **异常处理:** 如果任何一个Pipeline的`process_item`方法抛出异常,该Item将不再传递给后续的Pipeline,而是进入异常处理逻辑。通过合理配置和编写Pipeline,可以方便地对爬取的数据进行处理、存储和清洗。
Pipeline的灵活性使得你可以根据实际需求定制各种处理逻辑。
16. scrapy的pipelines如何丢弃一个item对象?
在Scrapy中,如果你希望在Pipeline中丢弃(不处理)某个Item对象,可以抛出`DropItem`异常。
`DropItem`异常通知Scrapy不再传递当前Item给后续的Pipeline,直接跳过该Item的处理。以下是一个简单的示例,演示如何在Pipeline中丢弃Item:
from scrapy.exceptions import DropItemclass MyPipeline:def process_item(self, item, spider):# 根据某个条件判断是否丢弃Itemif item.get('some_field') is None:raise DropItem(f"Item with missing field: {item}")# 处理Item的逻辑# ...return item在这个示例中,如果Item中的`some_field`字段为`None`,就会抛出`DropItem`异常,
并携带一条错误信息。Scrapy会捕获这个异常,不再传递当前Item给后续的Pipeline。请注意,在Pipeline中丢弃Item时,建议提供明确的错误信息,以便于调试和跟踪问题。
17. 简述scrapy中爬虫中间件和下载中间件的作用?
Scrapy中间件是一组处理Scrapy请求和响应的组件,可以通过它们来扩展和自定义Scrapy的功能。Scrapy中主要有两类中间件:爬虫中间件(Spider Middleware)和下载中间件(Downloader Middleware)。### 爬虫中间件(Spider Middleware):
爬虫中间件主要作用于Spider和其输出的Item、Request对象。爬虫中间件可以在Spider处理请求和
生成Item的过程中干预,允许你修改、过滤或添加请求,以及对Spider输出的Item进行处理。一些常见的爬虫中间件任务包括:
- **处理请求前的预处理:** 在请求发送给下载器之前,进行请求的预处理,例如修改请求头、加入代理等。- **处理Spider生成的Item:** 对Spider输出的Item进行处理,例如去重、过滤、修改等。- **处理Spider生成的请求:** 在请求发送给下载器之前,对Spider输出的请求进行处理,例如修改URL、添加请求头等。### 下载中间件(Downloader Middleware):
下载中间件主要作用于Scrapy的下载器,可以在请求经过下载中间件的过程中进行处理。
下载中间件允许你修改请求和响应,以及在请求之前和之后执行各种操作。一些常见的下载中间件任务包括:
- **处理请求前的预处理:** 在请求发送给服务器之前,进行请求的预处理,例如修改请求头、加入代理等。- **处理响应后的后处理:** 在接收到服务器的响应之后,对响应进行处理,例如修改响应内容、处理重定向等。- **处理请求和响应的异常:** 在请求或响应过程中出现异常时,进行异常处理,例如重试请求、记录日志等。爬虫中间件和下载中间件的工作流程如下:
1. 爬虫中间件按照配置的优先级依次处理Spider生成的Item和Request对象。
2. 下载中间件按照配置的优先级依次处理请求和响应,然后将请求发送给下载器并获取响应。
3. 爬虫中间件再次按照配置的优先级依次处理Spider生成的Item和Request对象。通过使用中间件,你可以轻松地定制和扩展Scrapy的功能,以满足特定的需求。
18. scrapy-redis组件的作用?
`scrapy-redis`是一个用于在Scrapy中集成分布式爬虫的组件。
它基于Scrapy框架,通过Redis实现分布式爬虫的任务调度、URL去重和数据共享。以下是`scrapy-redis`组件的主要作用:
1. **分布式任务调度:** `scrapy-redis`允许多个爬虫节点(即多台机器)同时执行任务。通过Redis作为中心调度器,不同爬虫节点可以协同工作,避免任务冲突,提高爬虫的效率。2. **URL去重:** 在分布式环境中,很容易出现重复的URL。`scrapy-redis`通过Redis的Set数据结构来实现全局的URL去重,确保每个URL只被爬取一次。3. **数据共享:** 爬虫节点之间可以通过Redis实现数据的共享,例如共享爬取状态、共享爬取结果等。这使得分布式爬虫更容易管理和监控。4. **支持分布式爬取和分布式存储:** `scrapy-redis`可以与不同的分布式存储系统(例如MongoDB、MySQL)集成,实现分布式的数据存储。使用`scrapy-redis`时,需要在Scrapy项目的配置中引入相关设置,以便启用分布式爬虫的功能。
例如,配置文件中需要设置Redis连接信息、使用的调度器、使用的去重类等。以下是一个简单的示例配置:
# settings.py# 使用scrapy_redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 在Redis中保持爬虫队列,从高优先级开始爬取
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'# 使用布隆过滤器进行URL去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'# 设置Redis连接信息
REDIS_URL = 'redis://localhost:6379/0'# 允许暂停和恢复爬虫
SCHEDULER_PERSIST = True通过这些配置,你可以启用`scrapy-redis`组件,使Scrapy项目支持分布式爬虫。
这对于大规模爬取和分布式部署的情况非常有用。
19. scrapy-redis组件中如何实现的任务的去重?
`scrapy-redis`组件通过使用Redis来实现任务的去重。在Scrapy中,任务的去重主要指URL的去重,
确保每个URL只被爬取一次。`scrapy-redis`通过使用Redis的Set数据结构来管理已经爬取过的URL,
避免重复爬取。以下是`scrapy-redis`中任务去重的工作原理:
1. **Redis Set存储URL:** `scrapy-redis`使用Redis的Set来存储已经爬取过的URL。每个Spider维护一个对应的Set,用于记录已经爬取的URL。2. **去重判断:** 在爬虫中,每次生成一个新的Request对象时,`scrapy-redis`会使用哈希函数计算URL的哈希值,并检查该哈希值是否在对应的Redis Set中。如果哈希值存在,说明URL已经爬取过,将该Request对象过滤掉,不再发送。3. **配置去重类:** 在Scrapy项目的配置中,需要设置`DUPEFILTER_CLASS`参数为`'scrapy_redis.dupefilter.RFPDupeFilter'`,以启用`scrapy-redis`的去重功能。这样,`scrapy-redis`将会使用哈希函数计算URL的哈希值,并检查是否在对应的Redis Set中。以下是一个简单的配置示例:
# settings.py# 使用布隆过滤器进行URL去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'# 设置Redis连接信息
REDIS_URL = 'redis://localhost:6379/0'通过上述配置,`scrapy-redis`将会使用布隆过滤器进行URL去重,确保在分布式爬虫中,
每个URL只被爬取一次。在不同的Spider中,对应的URL去重信息会存储在不同的Redis Set中。
20. scrapy-redis的调度器如何实现任务的深度优先和广度优先?
`scrapy-redis`中的调度器(Scheduler)默认使用广度优先算法进行任务调度,
但你可以通过设置一些参数来实现深度优先或其他调度算法。### 广度优先调度:
广度优先调度是`scrapy-redis`的默认调度方式,任务按照深度从浅到深依次执行。
这是因为默认的队列类是`scrapy_redis.queue.SpiderQueue`,它实现了广度优先的任务调度。
# settings.py# 在Redis中保持爬虫队列,从高优先级开始爬取
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'### 深度优先调度:
要实现深度优先调度,可以使用`scrapy_redis.queue.SpiderStack`队列类,
该队列类实现了深度优先的任务调度。
# settings.py# 在Redis中保持爬虫栈,从低优先级开始爬取
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'### 其他调度方式:
除了广度优先和深度优先之外,`scrapy-redis`还提供了其他一些队列类,
如`scrapy_redis.queue.FifoQueue`(先进先出)
和`scrapy_redis.queue.LifoQueue`(后进先出)。你可以根据具体需求选择合适的队列类。# settings.py# 在Redis中保持先进先出队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'通过设置`SCHEDULER_QUEUE_CLASS`参数,你可以灵活地调整任务调度的方式。
选择合适的调度方式有助于优化爬虫的性能和效率。
相关文章:

第十三章 python之爬虫
Python基础、函数、模块、面向对象、网络和并发编程、数据库和缓存、 前端、django、Flask、tornado、api、git、爬虫、算法和数据结构、Linux、设计题、客观题、其他 第十三章 爬虫 1. 写出在网络爬取过程中, 遇到防爬问题的解决办法。 在网络爬取过程中,可能会遇…...

scrum 敏捷开发
scrum 敏捷开发 Scrum 是一种敏捷软件开发方法,旨在通过迭代、增量和协作的方式提高团队的效率和产品质量。下面是关于 Scrum 的一些重要概念和实践: 1. Scrum 团队角色 Scrum 团队通常由以下角色组成: 产品负责人(Product Ow…...

亚信科技AntDB数据库完成中国信通院数据库迁移工具专项测试
近日,在中国信通院“可信数据库”数据库迁移工具专项测试中,湖南亚信安慧科技有限公司(简称:亚信安慧科技)数据库数据同步平台V2.1产品依据《数据库迁移工具能力要求》、结合亚信科技AntDB分布式关系型数据库产品&…...

深度学习(一):Pytorch之YOLOv8目标检测
1.YOLOv8 2.模型详解 2.1模型结构设计 和YOLOv5对比: 主要的模块: ConvSPPFBottleneckConcatUpsampleC2f Backbone ----->Neck------>head Backdone 1.第一个卷积层的 kernel 从 6x6 变成了 3x3 2. 所有的 C3 模块换成 C2f,可以发现…...
EasyExcel如何读取全部Sheet页数据方法
一、需求描述 Excel表格里面大约有20个sheet页,每个sheet页65535条数据,需要读取全部数据,并导入至数据库。 找了好多种方式,EasyExcel比较符合,下面看代码。 二、实现方式 采用EasyExcel框架的doReadAll()方法 1、…...
GDPU 数据结构 天码行空12
文章目录 数据结构实验十二 图的遍历及应用一、【实验目的】二、【实验内容】三、实验源代码🍻 CPP🍻 C 数据结构实验十二 图的遍历及应用 一、【实验目的】 1、 理解图的存储结构与基本操作; 2、熟悉图的深度度优先遍历和广度优先遍历算法…...

什么是 Proxy?
目录 Proxy 的作用 1. 流量过滤 2. 记录日志 3. 加快访问速度 4. 隐藏 IP 地址 Proxy 的分类 1. 按协议分类 - HTTP 代理:只支持 HTTP 协议的代理服务器,它可以缓存 HTTP 请求和响应并过滤 HTTP 流量。 - FTP 代理:只支持 FTP 协议的…...

Vue系列:Vue Element UI中,使用按钮实现视频的播放、停止、停止后继续播放、播放完成后重新播放功能
最近在工作中有个政务大屏用到了视频播放; 技术栈是Vue2、Element UI; 要实现的功能是:使用按钮实现视频的播放、停止、停止后继续播放、播放完成后重新播放功能 具体可以按照以下步骤进行操作: 引入插件: 在Vue组件…...

.Net 8 Blazor下 Auto交互渲染模式试用
一、环境 C:\Users\zhuji>dotnet --version 8.0.100C:\Users\zhuji>dotnet --list-sdks 5.0.403 [C:\Program Files\dotnet\sdk] 6.0.404 [C:\Program Files\dotnet\sdk] 8.0.100 [C:\Program Files\dotnet\sdk] Microsoft Visual Studio Enterprise 2022 (64 位) - Cu…...
AndroidStudio - 新版本 Logcat 使用详解
最近这俩天正好有时间给自己做一下减法,忘记是去年还是今年,在升级 AndroidStudio 后使用 Logcat查看日志的方式也发生了一些变化,虽然一直在使用,但每当看到之前还未关闭 Logcat 命令行工具额昂也,就感觉可能还存在知…...

Webpack ECMAScript 模块
文章目录 前言标题一导出导入将模块标记为 ESM 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:webpack 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&a…...

knife4j集合化postman
knife4j集合化postman 01 knife4j的介绍 基于 JavaMVC的集成框架swagger的进一步强化,在原有通过注释就能生成文档的前身swagger-bootstrap-ui之上,增加了postman的测试功能,优化了文档的UI界面,在测试api接口的方面有了极大的进…...

MongoDB的原子性和多文档事务处理
原子性和事务处理是数据库操作的核心,保证了数据的准确性。依据数据库原子性,数据库和使用数据库的人员定义事务处理的方式。本文依据Mongodb的官方文档,整理Mongodb数据库的原子性和事务处理方法。 Mongodb的原子操作 Mongodb中,…...
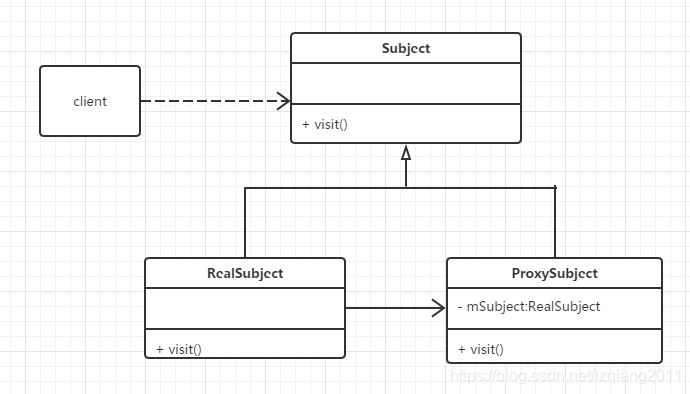
代理模式 1、静态代理 2、动态代理 jdk自带动态代理 3、Cglib代理
文章目录 代理模式1、静态代理2、动态代理jdk自带动态代理 3、Cglib代理 来和大家聊聊代理模式 代理模式 代理模式:即通过代理对象访问目标对象,实现目标对象的方法。这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操…...

ELK+filebeat+kafka
无需创建logstash的端口,直接创建topic 远程收集mysql和httpd的日志 (一)安装nginx和mysql服务 1、打开mysql的日志功能 2、创建日志(创库、创表、添加数据) (1)mysql服务器上安装http system…...
)
LLVM学习笔记(63)
4.4.3.3.2.3. 向量操作数类型的处理 下面开始处理向量类型。在默认情形下这些操作都会拆分为更小的操作或者调用库。 X86TargetLowering::X86TargetLowering(续) 667 // Some FP actions are always expanded for vector types. 668 for…...

【python+requests】接口自动化测试
这两天一直在找直接用python做接口自动化的方法,在网上也搜了一些博客参考,今天自己动手试了一下。 一、整体结构 上图是项目的目录结构,下面主要介绍下每个目录的作用。 Common:公共方法:主要放置公共的操作的类,比如数据库sql…...
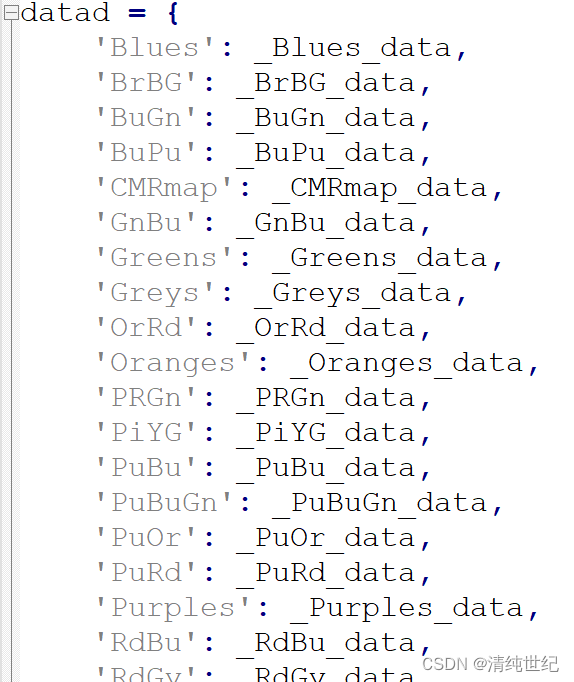
plt创建指定色系
1、创建不连续色系 import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap# 定义颜色的RGB值 colors [(0.2, 0.4, 0.6), # 蓝色(0.8, 0.1, 0.3), # 红色(0.5, 0.7, 0.2),(0.3,0.5,0.8)] # 绿色# 创建色系 cmap ListedColormap(colors)# 绘制…...
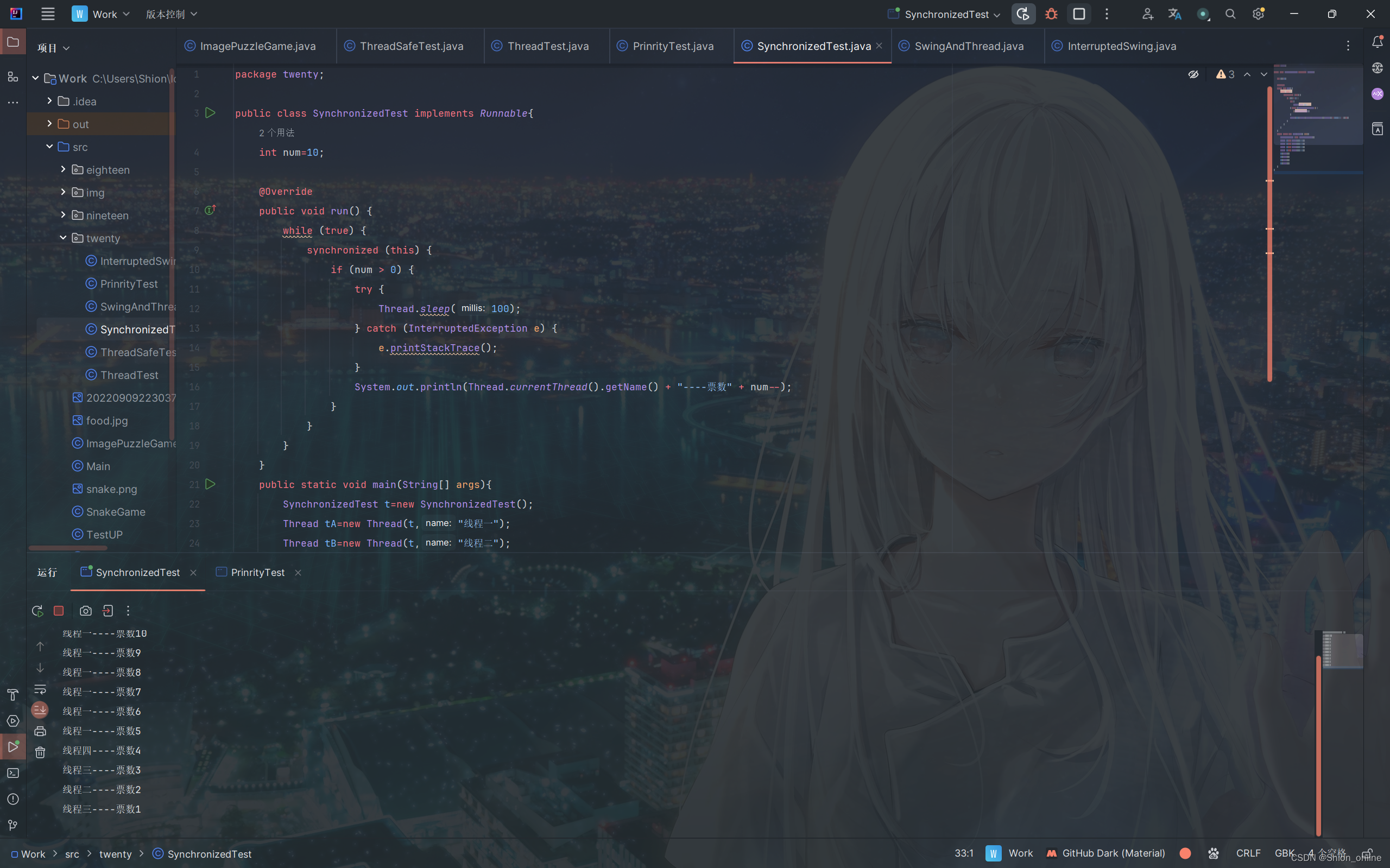
Java多线程-第20章
Java多线程-第20章 1.创建线程 Java是一种支持多线程编程的编程语言。多线程是指在同一程序中同时执行多个独立任务的能力。在Java中,线程是一种轻量级的子进程,它是程序中的最小执行单元。Java的多线程编程可以通过两种方式实现:继承Threa…...

寿险公司通过开源治理保障数字创新,安全打通高质量服务新通道
某寿险公司致力于为消费者提供人性化的产品和服务,在中国保险市场中始终保持前列。该寿险公司以挖掘和满足客户需求为出发点,从产品开发、渠道销售、运营流程和售后服务等各环节,借助数字化工具,不断地努力探索并提升服务品质。 精…...
SPF-10G-T :10G 电口模块,重塑短距网络升级性价比)
安科士(AndXe)SPF-10G-T :10G 电口模块,重塑短距网络升级性价比
数字化转型浪潮下,企业园区、数据中心对10Gbps 高速互联的需求呈爆发式增长。但传统 10G 升级方案深陷困境:光纤布线成本高昂、施工周期长且需专业运维技能,而多数企业机架内、相邻机架间及办公楼层内的链路距离普遍低于 30 米,光…...

工业内窥镜哪家好用?
经常有不同行业的朋友问我,工业内窥镜品牌这么多,到底该怎么选?其实对于大多数企业来说,选择一款适用性广、能满足多种检测场景的设备,才是最划算的。我用了这么多年韦林工业内窥镜,最大的感受就是它几乎能…...

AI 大模型未来技术演进方向与应用发展趋势预判
引言:AI 技术快速迭代,未来已来AI 大模型技术正以超乎想象的速度迭代演进,从参数规模扩张到能力提升、从技术架构创新到应用场景拓展、从成本高企到普惠落地,每一次技术突破都在重塑产业格局、改变商业逻辑、影响生活方式。2026 年…...

【芯片测试】:SmarTest 开发环境入门
SmarTest 开发环境入门:Eclipse IDE 集成与工作区管理系列: Advantest V93000 SmarTest 8 核心概念解析|第 1 篇(共 8 篇) 适合读者: 初次接触 SmarTest 的测试工程师、ATE 软件开发者前言 很多工程师第一次…...

UE5蓝图与C++权力边界:编辑器独占与全栈覆盖解析
1. 这不是“选哪个更好”,而是“谁在什么时候说了算”在UE5项目组里,我见过太多次这样的场景:美术同学改完一个材质参数,发现蓝图里调用的函数突然不生效了;程序刚写完一套C Actor逻辑,策划在编辑器里拖拽组…...

【Feed 高并发架构实战】:雪花 ID + 三级缓存 + 计数旁路设计详解
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 目录…...

AI时代什么建站软件功能强大?从GEO流量重构看CMS的智慧进化
2026年,互联网的底层逻辑正在发生一场“静默革命”。如果你的思维还停留在“建一个网站只是为了有个官网给客户看”,那么你可能正在被时代抛弃。当下的AI已经不仅仅是一个聊天工具,它正在重构整个信息的传播秩序。传统的SEO(搜索引…...

为什么我看不到我的图库中的照片?修复并恢复图片
照片在我们生活中占据着特殊的地位,它们帮助我们重温珍贵的回忆,并与远近的亲人保持联系。照片就像一扇通往我们最珍贵时刻的私人窗口,因此,当它们突然从相册应用中消失时,会格外令人沮丧。如果你曾经疑惑过“为什么我…...

成都制造企业电费越来越高,AI能耗异常预警该先接哪些数据?
一、电费上涨,先别只看总表对成都不少制造企业来说,电费已经不只是后勤费用,而是影响订单毛利、交付节奏和产线管理的一项经营变量。问题在于,许多企业发现电费升高时,第一反应仍然停留在“今年产量多了”“设备老了”…...
)
Perplexity案例法检索深度解析(工业级RAG系统落地避坑手册)
更多请点击: https://intelliparadigm.com 第一章:Perplexity案例法检索深度解析(工业级RAG系统落地避坑手册) Perplexity作为衡量语言模型预测不确定性的核心指标,在RAG系统中并非仅用于后处理重排序,而是…...