Clickhouse UPDATE 和 DELETE操作
历史:
在OLAP数据库中,可变数据(Mutable data)通常是不被欢迎的,Clickhouse也是如此,早期版本不支持UPDATE和DELTE操作。在Clickhouse 1.1.54388版本之后才支持UPDATE和DELETE操作,适用于MergeTree引擎,并且这种操作方式是异步的(asynchronous),但是在一些交互场景下很难使用。在一些场景下用户需要修改了数据即刻可以看到。这种实时更新(real-tiime update)在2020年4月可以在clickhouse中实现了。
在clickhouse 开源的2016年ClickHouse当时不支持数据修改。为了模拟更新,只能使用特殊的插入结构,并且数据必须由分区删除。
在GDPR要求的压力下,ClickHouse团队在2018年发布了UPDATE和DELETE。这些异步的,非原子的更新被实现为ALTER TABLE UPDATE语句,并且有可能shuffle 很多数据。当不需要立即知道结果时,这对于批量操作和不频繁更新很有用。
常规意义(Normal SQL)上的SQL语句update支持依旧在clickhouse中缺失,尽管它们每年确实出现在路线图中。如果需要实时更新行为,我们必须使用其他方法。让我们考虑一个实际的用例,并比较ClickHouse中使用它的不同方法。
概述:
Clickhouse提供了delete和update操作,这类操作被称之为Mutation查询,是ALTER语句的变种。虽然Mutation能最终实现修改和删除,但是不能完全以通常意义上的update和delete操作来理解。
1.Mutation操作适用于批量数据的修改和删除
2.不支持事务 一旦语句被提交执行就会立刻对现有的数据产生影响,无法回滚。
3.Mutation操作执行是一个异步的过程,语句提交会立即返回,但是不代表具体逻辑已经执行完毕,具体的执行记录需要在system.mutations系统表查询。
1.数据UPDATE和DELETE操作示例:
1.创建表:
CREATE TABLE city
(`id` UInt8, `country` String, area String,`province` String, `city` String, `create_time` datetime DEFAULT now()
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id;2.插入数据:
insert into city(id,country,area,province,city) VALUES
(1,'China','North','Hubei','wuhan'),
(2,'China','South','Guangdong','guangzhou'),
(3,'China','South','Guangdong','shenzhen'),
(4,'China','North','Beijing','Beijing'),
(5,'China','South','Shanghai','Shanghai');数据查询:
┌─id─┬─country─┬─area──┬─province──┬─city──────┬─────────create_time─┐
│ 1 │ China │ North │ Hubei │ wuhan │ 2020-06-26 16:11:21 │
│ 2 │ China │ South │ Guangdong │ guangzhou │ 2020-06-26 16:11:21 │
│ 3 │ China │ South │ Guangdong │ shenzhen │ 2020-06-26 16:11:21 │
│ 4 │ China │ North │ Beijing │ Beijing │ 2020-06-26 16:11:21 │
│ 5 │ China │ South │ Shanghai │ Shanghai │ 2020-06-26 16:11:21 │
└────┴─────────┴───────┴───────────┴───────────┴─────────────────────┘5 rows in set. Elapsed: 0.003 sec. 3.update和delete操作:
-- UPDATE 操作:ALTER TABLE city UPDATE area='South' WHERE city='wuhan';Clickhouse> select database,table,mutation_id,command,create_time,block_numbers.number no,is_done from system.mutations where table='city';┌─database─┬─table─┬─mutation_id────┬─command────────────────────────────────────┬─────────create_time─┬─no──┬─is_done─┐
│ datasets │ city │ mutation_5.txt │ UPDATE area = 'South' WHERE city = 'wuhan' │ 2020-06-26 16:12:50 │ [5] │ 1 │
└──────────┴───────┴────────────────┴────────────────────────────────────────────┴─────────────────────┴─────┴─────────┘1 rows in set. Elapsed: 0.004 sec. --DELETE 操作:
ALTER TABLE city DELETE WHERE city='guangzhou';┌─database─┬─table─┬─mutation_id────┬─command────────────────────────────────────┬─────────create_time─┬─no──┬─is_done─┐
│ datasets │ city │ mutation_5.txt │ UPDATE area = 'South' WHERE city = 'wuhan' │ 2020-06-26 16:12:50 │ [5] │ 1 │
│ datasets │ city │ mutation_6.txt │ DELETE WHERE city = 'guangzhou' │ 2020-06-26 16:44:58 │ [6] │ 1 │
└──────────┴───────┴────────────────┴────────────────────────────────────────────┴─────────────────────┴─────┴─────────┘2 rows in set. Elapsed: 0.004 sec. 4.查看目录:
# ls -l /var/lib/clickhouse/data/datasets/city/
total 20
drwxr-x---. 2 clickhouse clickhouse 4096 Jun 26 16:12 202006_4_4_0_5
drwxr-x---. 2 clickhouse clickhouse 4096 Jun 26 16:44 202006_4_4_0_6
drwxr-x---. 2 clickhouse clickhouse 6 Jun 26 16:02 detached
-rw-r-----. 1 clickhouse clickhouse 1 Jun 26 16:02 format_version.txt
-rw-r-----. 1 clickhouse clickhouse 109 Jun 26 16:12 mutation_5.txt
-rw-r-----. 1 clickhouse clickhouse 96 Jun 26 16:44 mutation_6.txt# cat /var/lib/clickhouse/data/datasets/city/mutation_5.txt
format version: 1
create time: 2020-06-26 16:12:50
commands: UPDATE area = \'South\' WHERE city = \'wuhan\' # cat /var/lib/clickhouse/data/datasets/city/mutation_6.txt
format version: 1
create time: 2020-06-26 16:44:58
commands: DELETE WHERE city = \'guangzhou\' 可以发现在执行了update,delete操作之后数据目录会生成文件mutation_5.txt,mutation_6.txt。
此外还有在同名的
目录下在末尾增加了_5 ,_6的后缀。
可以看到mutation_5.txt和mutation_6.txt 是日志文件,完整的记录了update和delete操作语句和时间。
mutation_id:生成对应的日志文件用于记录相关的信息。
数据删除的过程是以数据表的每个分区目录为单位,将所有目录重写为新的目录,在目录的命名规则是在原有的名称上加上 block_numbers.number
数据的在重写的过程中会讲所需要删除的数据去掉。旧的数据并不会立即删除,而是被标记为非激活状态(active =0),
等到MergeTree引擎的下一次合并动作触发的时候,
这些非活动目录才会被真正的从物理上删除。UPDATE语句不能修改分区键和主键。
2.数据的实时更新操作(Real-time UPDATE):
应用场景:
假设一个收集各种信息的告警系统,用户或者机器学习算法不时的查询数据库库,以确认最新的告警信息。
若确认了
最新的消息需要修改数据库的告警记录,然后警报消息从用户视图中消除。这看起来像是Clickhouse的OLTP操作。由于我们无法使用更新,因此我们将不得不插入修改后的记录。 一旦数据库中有两条记录,我们需要一种有效的方法来
获取最新的一条。 为此,我们将尝试3种不同的方法:
ReplacingMergeTree
Aggregate functions
AggregatingMergeTree 1.创建表:
CREATE TABLE alerts(tenant_id UInt32,alert_id String,timestamp DateTime Codec(Delta, LZ4),alert_data String,acked UInt8 DEFAULT 0,ack_time DateTime DEFAULT toDateTime(0),ack_user LowCardinality(String) DEFAULT ''
)
ENGINE = ReplacingMergeTree(ack_time)
PARTITION BY tuple()
ORDER BY (tenant_id, timestamp, alert_id);为了简单便于演示,alert_id使用一个随机数,告警信息写入字段alert_data。实际上告警信息表可能有更多的字段信息。ReplacecingMergeTee是一种特殊的表引擎,它用主键(ORDER BY)替换数据-具有相同键值的行的较新版本将替换较旧的行。
在最新的(Newness)的数据信息由列ack_time确定,数据替换在后台合并操作期间执行。 它不会立即发生,也无法完全保证会发生,因此查询结果的一致性是一个问题。 不过,ClickHouse具有处理此类表的特殊语法:2.模拟数据:模拟1000个租户,产生1000万条记录。
INSERT INTO alerts(tenant_id, alert_id, timestamp, alert_data)
SELECTtoUInt32(rand(1)%1000+1) AS tenant_id,randomPrintableASCII(32) as alert_id,toDateTime('2020-01-01 00:00:00') + rand(2)%(3600*24*30) as timestamp,randomPrintableASCII(256) as alert_data
FROM numbers(10000000);3.我们让99%的数据标记为acked,由字段ack_user ack_time 确认。我们插入新的行,用以替代update操作。
INSERT INTO alerts (tenant_id, alert_id, timestamp, alert_data, acked, ack_user, ack_time)
SELECT tenant_id, alert_id, timestamp, alert_data, 1 as acked, concat('user', toString(rand()%1000)) as ack_user, now() as ack_time
FROM alerts WHERE cityHash64(alert_id) % 99 != 0;若立即查询有多少记录则反馈如下:
SELECT count() FROM alerts;
┌──count()─┐
│ 19898060 │
└──────────┘
1 rows in set. Elapsed: 0.008 sec此时可以确认 确认的数据和未确认的数据都包含在其中,数据的替换操作并未发生。为了查看真实的数据,我们使用关键字FINAL。Clickhouse> select count(1) from alerts FINAL;SELECT count(1)
FROM alerts
FINAL┌─count(1)─┐
│ 10000000 │
└──────────┘1 rows in set. Elapsed: 1.293 sec. Processed 10.00 million rows, 530.00 MB
(7.74 million rows/s., 409.97 MB/s.) 现在该计数是正确的,但查询时间增加了很多! 使用FINAL,ClickHouse必须扫描所有行并在查询时间内通过主键合并它们。
这会产生正确的答案,但会带来很多开销。 让我们看看是否可以通过仅过滤未确认的行来做得更好。Clickhouse> SELECT count() FROM alerts FINAL WHERE NOT acked;SELECT count()
FROM alerts
FINAL
WHERE NOT acked┌─count()─┐
│ 100696 │
└─────────┘1 rows in set. Elapsed: 0.740 sec. Processed 10.00 million rows, 540.00 MB
(13.51 million rows/s., 729.55 MB/s.) 查询时间和数据总量是一样的,尽管计数更小一些。过滤了反而没有加速查询,随着数据规模的增加,查询的成本会增加而不是缩小。ok 查询整个表 并没有很大的帮助,在我们的场景下还要继续使用ReplacingMergeTree 引起吗?
现在让我们随机查询租户ID(tenant_id)并且查询的所有的数据尚未确认。类似于有一个用户正在查看的仪表板。
由于“ alert_data”只是随机垃圾,因此我们将计算校验和,并使用它来确认结果在多种方法中是相同的:Clickhouse> SELECT count(),sum(cityHash64(*)) AS data FROM alerts FINAL WHERE (tenant_id = 451) AND (NOT acked);SELECT count(), sum(cityHash64(*)) AS data
FROM alerts
FINAL
WHERE (tenant_id = 451) AND (NOT acked)┌─count()─┬────────────────data─┐
│ 98 │ 8095029702435009750 │
└─────────┴─────────────────────┘1 rows in set. Elapsed: 0.025 sec. Processed 16.38 thousand rows, 5.29 MB (650.31 thousand rows/s., 210.01 MB/s.) 查询及其快,只有25ms就可以查询出非确认的数据。为啥如此快呢?
在这个过滤条件中不同的是tenant_id 是主键的一部分,所以clickhouse在FINAL之前就可以过滤数据,ReplacingMergeTree 变的更加有效。下面我们尝试过滤一个用户并且查询确认的数据。列的选择性(cardinality )是一样的,有1000个用户使用用户user451:
Clickhouse> SELECT count() FROM alerts FINAL WHERE (ack_user = 'user451') AND acked;SELECT count()
FROM alerts
FINAL
WHERE (ack_user = 'user451') AND acked┌─count()─┐
│ 9924 │
└─────────┘1 rows in set. Elapsed: 1.397 sec. Processed 10.00 million rows, 569.71 MB (7.16 million rows/s., 407.76 MB/s.)
可以看到查询非常慢并且没有使用索引,扫描了1000万条记录。
我们不能在 ack_user列添加索引,因为它会破坏ReplacingMergeTree的语义。 不过,我们可以使用PREWHERE技巧:Clickhouse> SELECT count() FROM alerts FINAL PREWHERE (ack_user = 'user451') AND acked;SELECT count()
FROM alerts
FINAL
PREWHERE (ack_user = 'user451') AND acked┌─count()─┐
│ 9924 │
└─────────┘1 rows in set. Elapsed: 0.277 sec. Processed 10.00 million rows, 567.78 MB (36.04 million rows/s., 2.05 GB/s.) PREWHERE是ClickHouse的特殊提示去应用于不同的过滤器。 通常,ClickHouse足够聪明,可以自动将条件移至PREWHERE,
因此用户无需理会。 此次没有发生,便于我们检查核对。clickhouse以大量的聚合函数功能而闻名,在最新的版本中已经支持超过100个聚合函数,这位经验丰富的用户提供了极大的灵活性。
本案例中我们无需使用任何高级函数,只需要使用argMax,max和any三个函数。
查询租户451 我们可以使用argMax聚合函数:
SELECT count(), sum(cityHash64(*)) data FROM (SELECT tenant_id, alert_id, timestamp, argMax(alert_data, ack_time) alert_data, argMax(acked, ack_time) acked,max(ack_time) ack_time_,argMax(ack_user, ack_time) ack_userFROM alerts GROUP BY tenant_id, alert_id, timestamp
)
WHERE tenant_id=451 AND NOT acked;结果和查询的行数相同,查询的时间极短。可以看到clickhouse的聚合效率不错,但是缺点是查询变的更加复杂。我们可以让他更加简单:注意我们确认告警信息的时候只需更新三个列:
acked: 0 => 1
ack_time: 0 => now()
ack_user: '' => ‘user1’在所有3种情况下,列值都会增加! 因此,我们可以使用 max代替笨重的argMax。
由于我们不更改alert_data,因此在此列上不需要任何实际的汇总。 ClickHouse为此
提供了
友好的any聚合功能。 它可以选择任何值而不会产生额外开销:SELECT count(), sum(cityHash64(*)) data FROM (SELECT tenant_id, alert_id, timestamp, any(alert_data) alert_data, max(acked) acked, max(ack_time) ack_time,max(ack_user) ack_userFROM alertsGROUP BY tenant_id, alert_id, timestamp
)
WHERE tenant_id=451 AND NOT acked;查询变的更加简单快速,原因是使用any函数,在alert_data列上无需计算max值AggregatingMergeTree
AggregatingMergeTree 是clickhouse中最强大的功能之一。当和物化视图结合时,可以实现实时数据聚合的功能。由于我们可以通过AggregatingMergeTree
让查询变的更加高效快速吗?实际上并没有太大的改进。我们一次只更新一行数据,所以一组只需要聚合两行。对于这种情况,AggregatingMergeTree引擎并不是最佳选择。但是我们可以使用小技巧。
我们知道告警信息始终智慧树先插入未确认的信息再被确认。用户确认告警信息之后只需要修改3列。若我们不重复其他列的
数据,是否可以节省磁盘空间并提升性能呢?我们使用max聚合函数来实现一个聚合功能的表。我们使用any函数替代max,但是需要一个列可以设置为Nullable,any函数可以选择non-null的值。DROP TABLE alerts_amt_max;
CREATE TABLE alerts_amt_max (tenant_id UInt32,alert_id String,timestamp DateTime Codec(Delta, LZ4),alert_data SimpleAggregateFunction(max, String),acked SimpleAggregateFunction(max, UInt8),ack_time SimpleAggregateFunction(max, DateTime),ack_user SimpleAggregateFunction(max, LowCardinality(String))
)
Engine = AggregatingMergeTree()
ORDER BY (tenant_id, timestamp, alert_id);由于原始数据是随机的,我们将从一个alerts表生成一个新的表。
我们使用两个insert语句,一个是确认的告警信息一个是非确认的告警信息。
INSERT INTO alerts_amt_max SELECT * FROM alerts WHERE NOT acked;
INSERT INTO alerts_amt_max
SELECT tenant_id, alert_id, timestamp,'' as alert_data, acked, ack_time, ack_user
FROM alerts WHERE acked;对于已确认的事件,我们插入一个空字符串而不是 alert_data 。
我们知道数据不会改变,并且只能存储一次! 聚合函数将填补空白。
在实际的应用程序中,我们可以跳过所有未更改的列,并让它们获取默认值。
-- 数据插入之后确认数据:
SELECT table, sum(rows) AS r,sum(data_compressed_bytes) AS c, sum(data_uncompressed_bytes) AS uc, uc /c AS ratio FROM system.parts WHERE active AND (database = 'datasets') GROUP BY table;由于是随机字符串我们几乎么有适用压缩,但是聚合小了两倍,因为我们不必存储两次alert_dataSELECT count(), sum(cityHash64(*)) data FROM (SELECT tenant_id, alert_id, timestamp, max(alert_data) alert_data, max(acked) acked, max(ack_time) ack_time,max(ack_user) ack_userFROM alerts_amt_maxGROUP BY tenant_id, alert_id, timestamp
)
WHERE tenant_id=451 AND NOT acked;
由于AggregatingMergeTree引擎,我们处理了更小的数据,也更加高效。Materializing The Update
Clickhouse 将尽其所能的在后台合并数据,删除重复的行并执行聚合。但是有时候,强制合并是有意义的比如释放磁盘空间。
我们可以使用 OPTIMIZE FINAL语句,OPTIMIZE操作是阻塞性且昂贵的,因此不能频繁的执行。我们来看下optimize对查询性能的影响。
OPTIMIZE TABLE alerts FINAL;
OPTIMIZE TABLE alerts_amt_max FINAL;应该optimize操作之后两个表具有相同的数据行数和其他相同的数据:
Clickhouse> SELECT table, sum(rows) AS r,sum(data_compressed_bytes) AS c, sum(data_uncompressed_bytes) AS uc, uc /c AS ratio FROM system.parts WHERE active AND (database = 'datasets') GROUP BY table;SELECT table, sum(rows) AS r, sum(data_compressed_bytes) AS c, sum(data_uncompressed_bytes) AS uc, uc / c AS ratio
FROM system.parts
WHERE active AND (database = 'datasets')
GROUP BY table┌─table──────────┬────────r─┬──────────c─┬─────────uc─┬──────────────ratio─┐
│ alerts │ 10000000 │ 2966402515 │ 3060027443 │ 1.0315617747512595 │
│ alerts_amt_max │ 10000000 │ 2966402515 │ 3060027443 │ 1.0315617747512595 │
└────────────────┴──────────┴────────────┴────────────┴────────────────────┘2 rows in set. Elapsed: 0.003 sec. 结论:
clickhouse提供了丰富的工具来处理实时更新,比如:ReplacingMergeTree, CollapsingMergeTree (not reviewed here), AggregatingMergeTree和聚合函数。这些方法有三个共同点:1.被修改的数据(Modified data)通过插入新版本的数据。clickhouse的INSERT操作极快。2.这些方式可以高效的模拟OLTP数据库中的update语义3.实际的修改并不是直接发生的,即异步特定方法的选取取决于使用场景。ReplacecingMergeTree简单明了,对用户来说最方便,但是仅可用于中小型表,或者始终由主键查询数据时使用。aggregate functions提供了更大的灵活性和性能,但是需要大量的重写。AggregatingMergeTree允许保存存储,仅保留修改的列。这些是clickhouse DB 设计人员的必备的工具,可以在需要的时候选用。参考:
https://www.altinity.com/blog/2020/4/14/handling-real-time-updates-in-clickhouse
https://www.altinity.com/blog/2018/10/16/updates-in-clickhouse
https://clickhouse.tech/blog/en/2016/how-to-update-data-in-clickhouse/
https://www.altinity.com/blog/2018/10/16/updates-in-clickhouse
https://www.altinity.com/blog/2018/1/23/updatingdeleting-rows-with-clickhouse-part-1
https://www.altinity.com/blog/2018/1/23/updatingdeleting-rows-from-clickhouse-part-2
转至:https://blog.csdn.net/vkingnew/article/details/106913907
相关文章:

Clickhouse UPDATE 和 DELETE操作
历史: 在OLAP数据库中,可变数据(Mutable data)通常是不被欢迎的,Clickhouse也是如此,早期版本不支持UPDATE和DELTE操作。在Clickhouse 1.1.54388版本之后才支持UPDATE和DELETE操作,适用于Merge…...

golang channel执行原理与代码分析
使用的go版本为 go1.21.2 首先我们写一个简单的chan调度代码 package mainimport "fmt"func main() {ch : make(chan struct{})go func() {ch <- struct{}{}ch <- struct{}{}}()fmt.Println("xiaochuan", <-ch)data, ok : <-chfmt.Println(&…...

OpenCvSharp从入门到实践-(04)色彩空间
目录 1、GRAY色彩空间 2、从BGR色彩空间转换到GRAY色彩空间 2.1色彩空间转换码 2.2实例 BGR色彩空间转换到GRAY色彩空间 3、HSV色彩空间 4、从BGR色彩空间转换到HSV色彩空间 4.1色彩空间转换码 4.2实例 BGR色彩空间转换到HSV色彩空间 1、GRAY色彩空间 GRAY色彩空间通常…...

100.有序数组的平方(力扣)
代码解决一 class Solution { public:// 函数接受一个整数数组,返回每个元素平方值排序后的结果vector<int> sortedSquares(vector<int>& nums) {int len nums.size(); // 获取数组的长度vector<int> v; // 创建一个新的数组,用…...
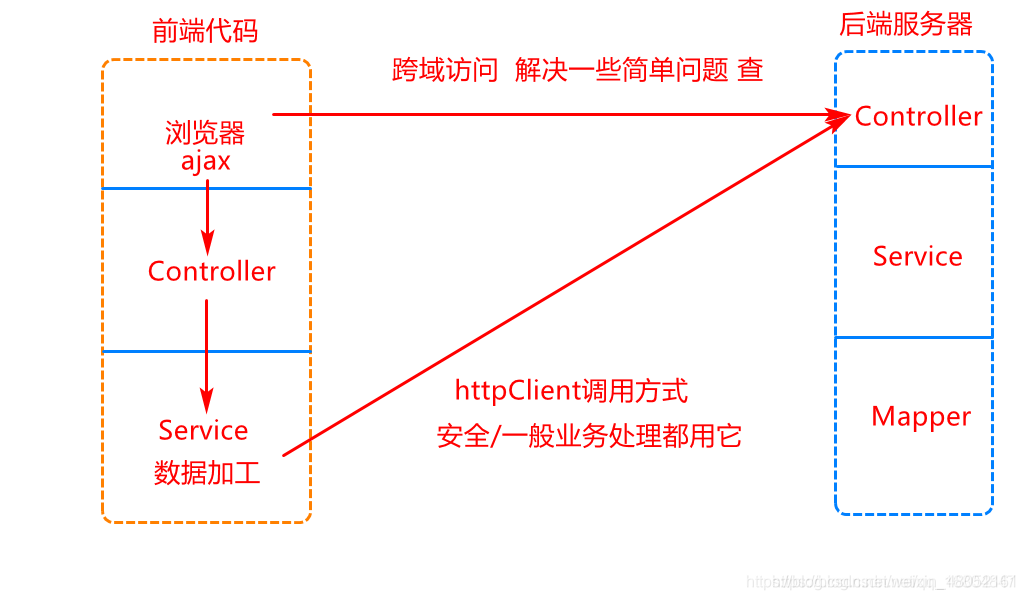
微服务--01--简介、服务拆分原则
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 微服务微服务架构,是服务化思想指导下的一套最佳实践架构方案。服务化,就是把单体架构中的功能模块拆分为多个独立项目。 单体架构微服务架构…...

IntelliJ IDEA安装使用教程
IntelliJ IDEA是一个流行的Java 集成开发环境(IDE),由JetBrains公司开发。它是一款全功能的IDE,支持多种编程语言,如Java、Kotlin、Groovy、Scala、Python、JavaScript、HTML、CSS等等。IntelliJ IDEA 提供了高效的代码…...
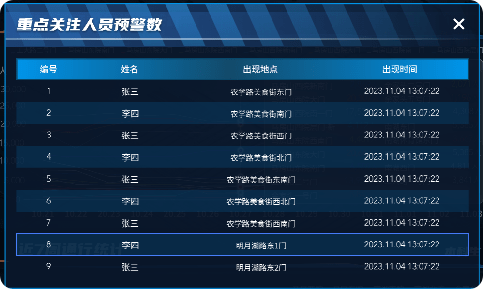
校园门禁可视化系统解决方案
随着科技的持续进步,数字化校园在教育领域中的地位日益上升,各种智能门禁、安防摄像头等已遍布校园各个地方,为师生提供安全便捷的通行体验。然而数据收集分散、缺乏管理、分析困难等问题也逐渐出现,在这个数字化环境中࿰…...

rest_framework_django学习笔记一(序列化器)
rest_framework_django学习笔记一(序列化器) 一、引入Django Rest Framework 1、安装 pip install djangorestframework2、引入 INSTALLED_APPS [...rest_framework, ]3、原始RESTful接口写法 models.py from django.db import models 测试数据 仅供参考 INSERT INTO de…...
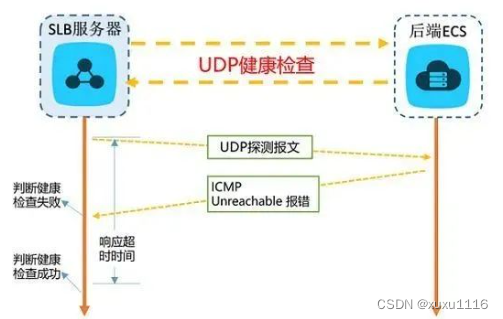
面试题:什么是负载均衡?常见的负载均衡策略有哪些?
文章目录 一、负载均衡二、负载均衡模型分类三、CDN负载均衡四、LVS负载均衡4.1 LVS 支持的三种模式4.1.1 DR 模式4.1.2 TUN 模式4.1.3 NAT 模式 4.2 LVS 基于 Netfilter 的框架实现 五、负载均衡策略是什么六、常用负载均衡策略图解6.1 轮询6.2 加权轮询6.3 最少连接数6.4 最快…...
读书笔记)
精通Git(第2版)读书笔记
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言第 1章 入门 11.1 关于版本控制 11.1.1 本地版本控制系统 1 第 2章 Git基础 132.1 获取Git仓库 132.1.1 在现有中初始化Git仓库 132.1.2 克隆现有仓库 14 2.2 在…...
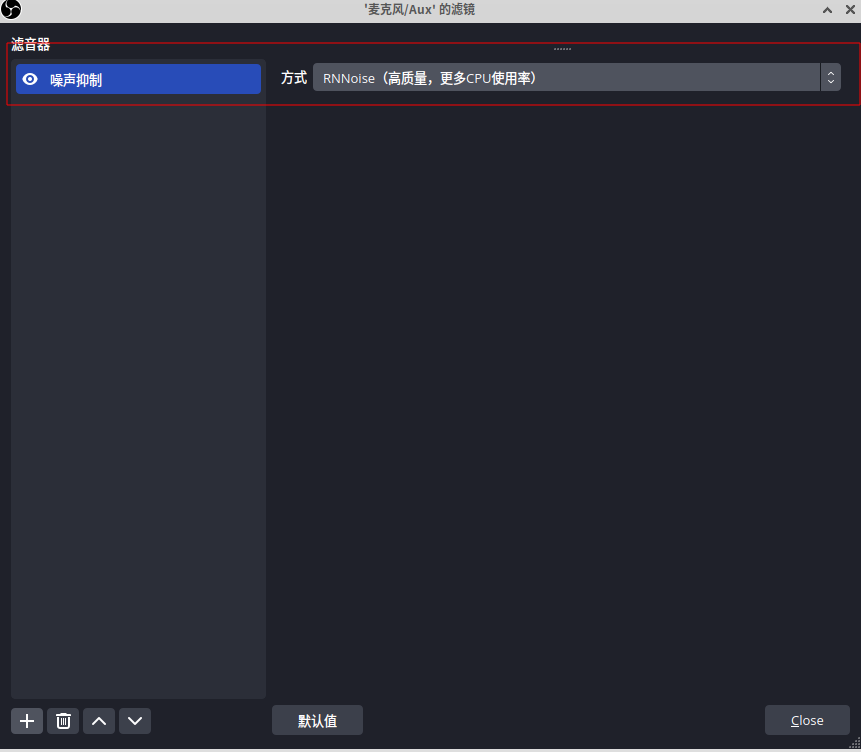
XUbuntu22.04之OBS30.0设置录制音频降噪(一百九十六)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
渗透测试学习day4
文章目录 靶机:SequelTask1Task2Task3Task4Task5Task6Task7Task8 靶机:CrocodileTask1Task2Task3Task4Task5Task6Task7Task8Task9Task10 靶机:ResponderTask1Task2Task3Task4Task5Task6Task7Task8Task9Task10Task11 靶机:ThreeTas…...
Deepin使用记录-deepin系统下安装RabbitMq
目录 0、引言 1、由于RabbitMq是erlang语言开发的,所有需要先安装erlang 2、更新源并安装RabbitMq 3、安装完成之后,服务是启动的,可以通过以下语句查看状态 4、这样安装完成之后,是看不到web页面的,需要再安装一…...

【腾讯云云上实验室】用向量数据库——实现高效文本检索功能
文章目录 前言Tencent Cloud VectorDB 简介Tencent Cloud VectorDB 使用实战申请腾讯云向量数据库腾讯云向量数据库使用步骤腾讯云向量数据库实现文本检索 结论和建议 前言 想必各位开发者一定使用过关系型数据库MySQL去存储我们的项目的数据,也有部分人使用过非关…...

Pytorch中的gather的理解和用法
Pytorch中的gather的理解和用法 这个Gather的用法花费了点时间,我相信很多人一开始不太懂。 跟着我简单理解。 首先样例是: tensor([[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])然后index: [[2, 1, 0]]然后执行的代码: tensor_0.gather(0…...

唯创知音WTN6系列语音芯片:高音频采样率与精细音量控制赋能广泛应用
在语音芯片领域,唯创知音的WTN6系列语音芯片以其出色的性能和广泛的应用领域,无疑是行业的一颗璀璨明星。近期,该系列芯片实现了音频采样率32kHz的突破,以及16级音量控制的精细调节,进一步提升了其在各类应用中的表现。…...

机器人分类
从发展阶段分类: 1第一代机器人2第二代机器人3第三代机器人:智能型机器人。生于90年代。具有传感器,以前的机器人都不具有传感器 从控制方式分类:(我觉得这个分类好乱) 操作型机器人:可自动控…...
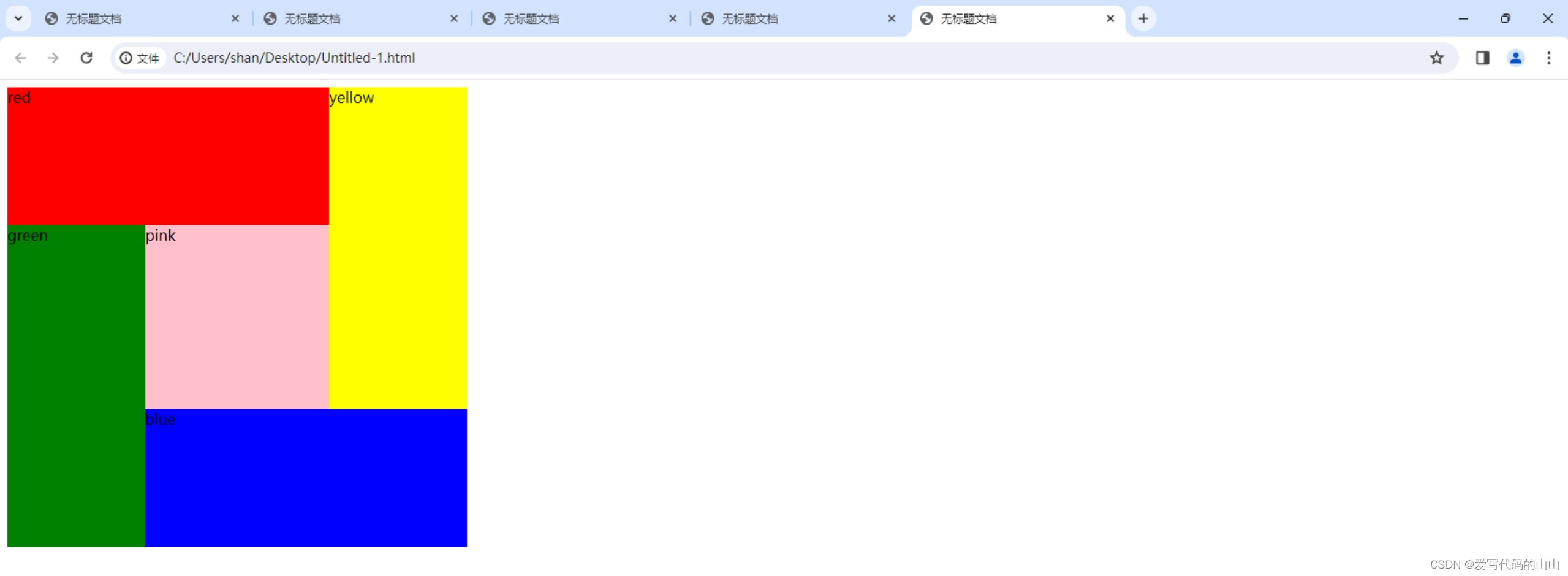
html/css中位置position的绝对位置absolute顺时针盒子案例图片排序
目标图片: Dreamweaver界面: 代码部分: <!doctype html> <html> <head> <meta charset"utf-8"> <title>无标题文档</title> <style type"text/css">.red{background-color:r…...

分享86个清新唯美PPT,总有一款适合您
分享86个清新唯美PPT,总有一款适合您 86个清新唯美PPT下载链接:https://pan.baidu.com/s/1QEaXeWAekCbAWDD0iTgvMw?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整…...

虚拟机系列:Oracle VM VirtualBox安装/更新/卸载出现 无法访问你试图使用的功能所在的网络位置
Oracle VM VirtualBox安装/更新/卸载出现 无法访问你试图使用的功能所在的网络位置 Oracle VM VirtualBox安装/更新/卸载出现 无法访问你试图使用的功能所在的网络位置Oracle VM VirtualBox安装/更新/卸载出现 无法访问你试图使用的功能所在的网络位置 在更新Oracle VM Virtua…...

技术人的黄金十年:软件测试从业者25到35岁每一年该怎么规划?
对于每一位进入软件行业的技术人而言,25岁到35岁这十年几乎决定了整个职业生涯的上限,而软件测试作为产品质量的最后一道防线,这个岗位的能力积累、职业路径选择,更需要在这黄金十年里做好清晰的规划。不同于开发岗的技术迭代焦虑…...

VHDL代码智能解析:基于大模型的硬件设计辅助实践
1. 项目背景与核心挑战在当今高性能处理器设计领域,VHDL作为硬件描述语言(HDL)的重要成员,因其严格的类型检查和结构化语法特性,被广泛应用于航空航天、汽车电子等关键行业。然而,随着芯片设计复杂度呈指数级增长,设计…...

单神经元动态记忆机制及其神经形态计算应用
1. 动态记忆的神经实现范式革新在神经科学与类脑计算领域,动态记忆(或称工作记忆)一直被视为认知功能的基础模块。传统理论认为,这种能够短暂保持神经活动状态的功能必须依赖于神经元群体构成的递归网络——通过兴奋性神经元间的相…...

【ChatGPT】锂电卷绕机深度拆解、信息图、爆炸图、C++代码框架
深度拆解信息图...

抖音视频批量下载终极指南:免费保存无水印内容的最佳方案
抖音视频批量下载终极指南:免费保存无水印内容的最佳方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

如何用免费纹理打包器优化游戏性能:5个实战技巧提升加载速度
如何用免费纹理打包器优化游戏性能:5个实战技巧提升加载速度 【免费下载链接】free-tex-packer Free texture packer 项目地址: https://gitcode.com/gh_mirrors/fr/free-tex-packer Free Texture Packer 是一款完全开源的精灵表生成工具,专门为游…...

Vue大屏自适应解决方案:如何应对多分辨率设备下的数据可视化挑战
Vue大屏自适应解决方案:如何应对多分辨率设备下的数据可视化挑战 【免费下载链接】v-scale-screen Vue large screen adaptive component vue大屏自适应组件 项目地址: https://gitcode.com/gh_mirrors/vs/v-scale-screen 在数字化转型浪潮中,企业…...

关于我尝试写博客这档事
一、起因 在学习过数据结构后,希望更改目前记笔记的形式,于是想到整理成文章,通过开源方式锻炼表达力与技术理解力,希望复习与拓展所学习过的知识,使用费曼学习法学习 二、自我介绍 1.基本信息 博主名为Doubletful(Dou…...
)
5G通信实战:手把手教你用Vivado LDPC IP核配置编码参数(附避坑指南)
5G通信实战:FPGA开发中的LDPC编解码参数配置全解析 在5G通信系统的开发过程中,LDPC(低密度奇偶校验)码作为物理层的关键技术之一,其实现质量直接影响着系统的传输性能和可靠性。对于使用Xilinx FPGA进行5G基带开发的工…...

LVGL样式进阶:别再只改颜色了!手把手教你定制lv_switch的动画和lv_btn的按压反馈
LVGL样式进阶:别再只改颜色了!手把手教你定制lv_switch的动画和lv_btn的按压反馈 在嵌入式UI开发中,LVGL作为轻量级图形库的代表,其样式系统的灵活性常常被低估。大多数开发者停留在修改背景色、字体颜色等基础操作,却…...