理解BatchNormalization层的作用
深度学习
文章目录
- 深度学习
- 前言
- 一、“Internal Covariate Shift”问题
- 二、BatchNorm的本质思想
- 三、训练阶段如何做BatchNorm
- 四、BatchNorm的推理(Inference)过程
- 五、BatchNorm的好处
- 六、机器学习中mini-batch和batch有什么区别
前言
Batch Normalization作为最近一年来DL的重要成果,已经广泛被证明其有效性和重要性。虽然有些细节处理还解释不清其理论原因,但是实践证明好用才是真的好,别忘了DL从Hinton对深层网络做Pre-Train开始就是一个经验领先于理论分析的偏经验的一门学问。本文是对论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》的导读。
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
接下来一步一步的理解什么是BN。
为什么深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢?这是个在DL领域很接近本质的好问题。很多论文都是解决这个问题的,比如ReLU激活函数,再比如Residual Network,BN本质上也是解释并从某个不同的角度来解决这个问题的。
一、“Internal Covariate Shift”问题
从论文名字可以看出,BN是用来解决“Internal Covariate Shift”问题的,那么首先得理解什么是“Internal Covariate Shift”?
论文首先说明Mini-Batch SGD相对于One Example SGD的两个优势:梯度更新方向更准确;并行计算速度快;(为什么要说这些?因为BatchNorm是基于Mini-Batch SGD的,所以先夸下Mini-Batch SGD,当然也是大实话);然后吐槽下SGD训练的缺点:超参数调起来很麻烦。(作者隐含意思是用BN就能解决很多SGD的缺点)
接着引入covariate shift的概念:如果ML系统实例集合<X,Y>中的输入值X的分布老是变,这不符合IID假设,网络模型很难稳定的学规律,这不得引入迁移学习才能搞定吗,我们的ML系统还得去学习怎么迎合这种分布变化啊。对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
然后提出了BatchNorm的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了。
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
二、BatchNorm的本质思想
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。
上面说得还是显得抽象,下面更形象地表达下这种调整到底代表什么含义。

图1 几个正态分布
假设某个隐层神经元原先的激活输入x取值符合正态分布,正态分布均值是-2,方差是0.5,对应上图中最左端的浅蓝色曲线,通过BN后转换为均值为0,方差是1的正态分布(对应上图中的深蓝色图形),意味着什么,意味着输入x的取值正态分布整体右移2(均值的变化),图形曲线更平缓了(方差增大的变化)。这个图的意思是,BN其实就是把每个隐层神经元的激活输入分布从偏离均值为0方差为1的正态分布通过平移均值压缩或者扩大曲线尖锐程度,调整为均值为0方差为1的正态分布。
那么把激活输入x调整到这个正态分布有什么用?首先我们看下均值为0,方差为1的标准正态分布代表什么含义:
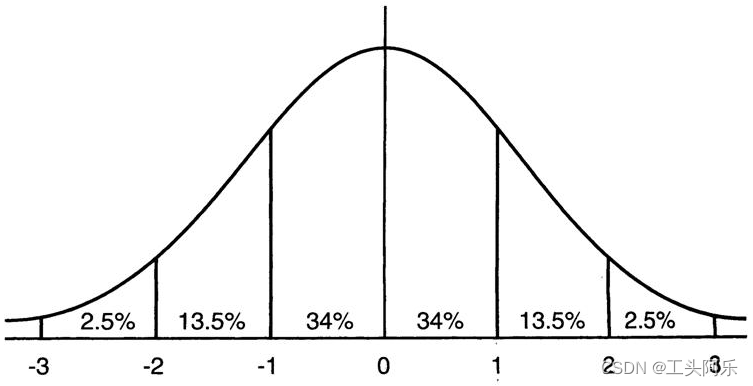
图2 均值为0方差为1的标准正态分布图
这意味着在一个标准差范围内,也就是说64%的概率x其值落在[-1,1]的范围内,在两个标准差范围内,也就是说95%的概率x其值落在了[-2,2]的范围内。那么这又意味着什么?我们知道,激活值x=WU+B,U是真正的输入,x是某个神经元的激活值,假设非线性函数是sigmoid,那么看下sigmoid(x)其图形:
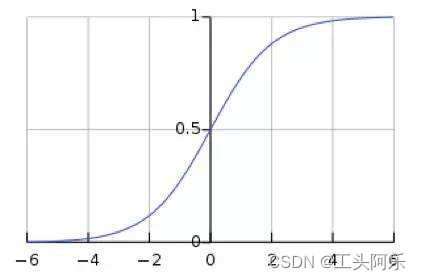
图3. Sigmoid(x)
及sigmoid(x)的导数为:G’=f(x)*(1-f(x)),因为f(x)=sigmoid(x)在0到1之间,所以G’在0到0.25之间,其对应的图如下:
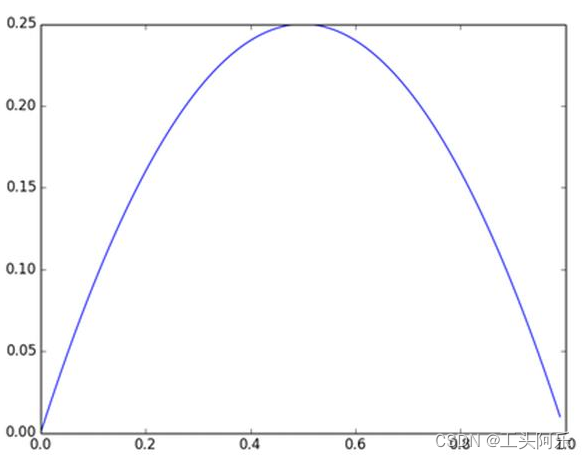
图4 Sigmoid(x)导数图
假设没有经过BN调整前x的原先正态分布均值是-6,方差是1,那么意味着95%的值落在了[-8,-4]之间,那么对应的Sigmoid(x)函数的值明显接近于0,这是典型的梯度饱和区,在这个区域里梯度变化很慢,为什么是梯度饱和区?请看下sigmoid(x)如果取值接近0或者接近于1的时候对应导数函数取值,接近于0,意味着梯度变化很小甚至消失。而假设经过BN后,均值是0,方差是1,那么意味着95%的x值落在了[-2,2]区间内,很明显这一段是sigmoid(x)函数接近于线性变换的区域,意味着x的小变化会导致非线性函数值较大的变化,也即是梯度变化较大,对应导数函数图中明显大于0的区域,就是梯度非饱和区。
从上面几个图应该看出来BN在干什么了吧?其实就是把隐层神经元激活输入x=WU+B从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的正态分布,即原始正态分布中心左移或者右移到以0为均值,拉伸或者缩减形态形成以1为方差的图形。什么意思?就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。
文章中举了个例子,在sigmoid激活函数的中间部分,函数近似于一个线性函数(如下图所示),使用BN后会使归一化后的数据仅使用这一段线性的部分。
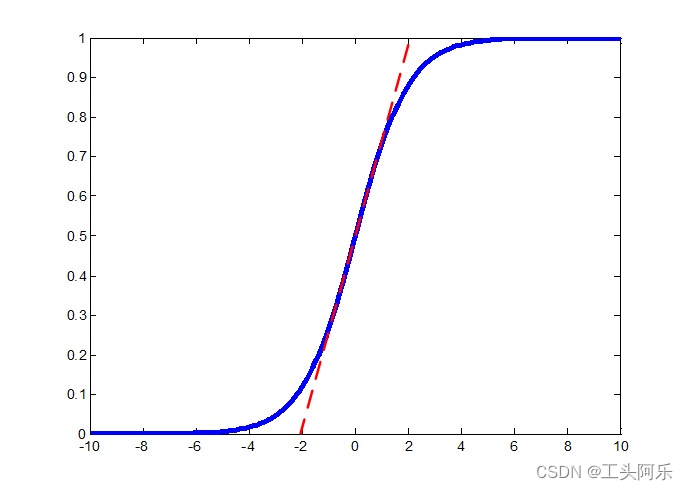
可以看到,在[0.2, 0.8]范围内,sigmoid函数基本呈线性递增,甚至在[0.1, 0.9]范围内,sigmoid函数都是类似于线性函数的,如果只用这一段,那网络不就成了线性网络了么,这显然不是大家愿意见到的。
这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。当然,这是我的理解,论文作者并未明确这样说。但是很明显这里的scale和shift操作是会有争议的,因为按照论文作者论文里写的理想状态,就会又通过scale和shift操作把变换后的x调整回未变换的状态,那不是饶了一圈又绕回去原始的“Internal Covariate Shift”问题里去了吗,感觉论文作者并未能够清楚地解释scale和shift操作的理论原因。
三、训练阶段如何做BatchNorm
上面是对BN的抽象分析和解释,具体在Mini-Batch SGD下做BN怎么做?其实论文里面这块写得很清楚也容易理解。为了保证这篇文章完整性,这里简单说明下。
假设对于一个深层神经网络来说,其中两层结构如下:
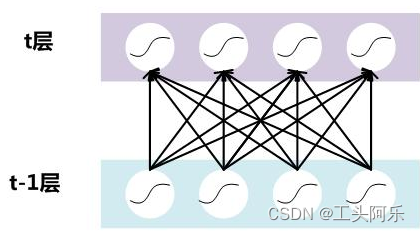
图5 DNN其中两层
要对每个隐层神经元的激活值做BN,可以想象成每个隐层又加上了一层BN操作层,它位于X=WU+B激活值获得之后,非线性函数变换之前,其图示如下:
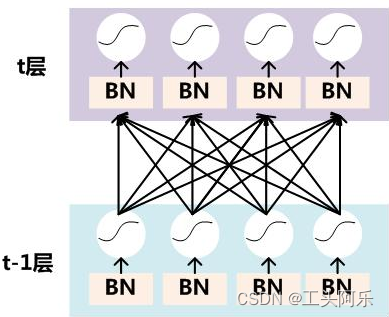
图6. BN操作
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
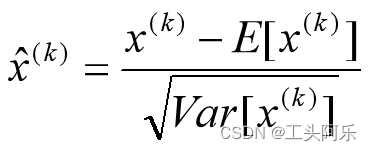
要注意,这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的线性激活x=WU+B,这里的U才是t-1层神经元的输出。变换的意思是:某个神经元对应的原始的激活x通过减去mini-Batch内m个实例获得的m个激活x求得的均值E(x)并除以求得的方差Var(x)来进行转换。
上文说过经过这个变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
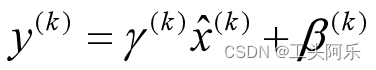
BN其具体操作流程,如论文中描述的一样:

过程非常清楚,就是上述公式的流程化描述,这里不解释了,直接应该能看懂。
四、BatchNorm的推理(Inference)过程
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,很明显输入就只有一个实例,看不到Mini-Batch其它实例,那么这时候怎么对输入做BN呢?因为很明显一个实例是没法算实例集合求出的均值和方差的。这可如何是好?
既然没有从Mini-Batch数据里可以得到的统计量,那就想其它办法来获得这个统计量,就是均值和方差。可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,因为本来就打算用全局的统计量,只是因为计算量等太大所以才会用Mini-Batch这种简化方式的,那么在推理的时候直接用全局统计量即可。
决定了获得统计量的数据范围,那么接下来的问题是如何获得均值和方差的问题。很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:
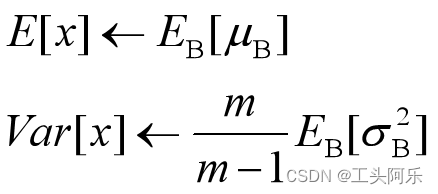
(在测试时,所使用的均值和方差是整个训练集的均值和方差。整个训练集的均值和方差的值通常是在训练的同时用移动平均法来计算的。)
关于滑动平均值怎么求,请看链接:深度学习中的Batch Normalization_whitesilence的博客-CSDN博客
有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算NB进行变换了,在推理过程中进行BN采取如下方式:

这个公式其实和训练时
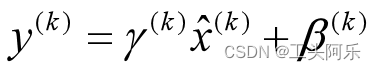
是等价的,通过简单的合并计算推导就可以得出这个结论。那么为啥要写成这个变换形式呢?我猜作者这么写的意思是:在实际运行的时候,按照这种变体形式可以减少计算量,为啥呢?因为对于每个隐层节点来说:
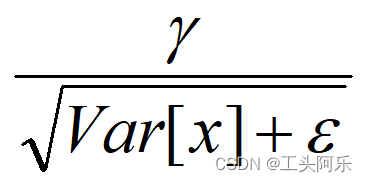
都是固定值,这样这两个值可以事先算好存起来,在推理的时候直接用就行了,这样比原始的公式每一步骤都现算少了除法的运算过程,乍一看也没少多少计算量,但是如果隐层节点个数多的话节省的计算量就比较多了。
这里其实是和训练保持一致,因为都要先减去训练集的均值再除以方差。这里你把训练时候的x^(k)带进去算下就能理解测试时候的了。
五、BatchNorm的好处
BatchNorm为什么NB呢,关键还是效果好。①不仅仅极大提升了训练速度,收敛过程大大加快;②还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;③另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
六、机器学习中mini-batch和batch有什么区别
在机器学习和深度学习中,“mini-batch” 和 “batch” 是两个常用的术语,它们之间存在一些区别。
Mini-batch(小批量):Mini-batch 是指从训练数据集中选择的较小的数据子集。在训练模型时,通常将整个训练数据集划分为多个 mini-batch。每个 mini-batch 包含一定数量的训练样本,通常是2的幂次方,例如 32、64 或 128。模型使用每个 mini-batch 的样本来进行前向传播、计算损失和反向传播,然后根据这些样本的梯度更新模型的参数。使用 mini-batch 的主要目的是减少计算开销和内存占用,并提高训练的效率。
Batch(批量):Batch 是指将整个训练数据集作为一个大批量进行训练。在每次迭代时,模型使用整个训练数据集的样本进行前向传播、计算损失和反向传播,然后根据这些样本的梯度更新模型的参数。相比于 mini-batch,使用 batch 的训练过程可能会占用更多的内存和计算资源,因为需要同时处理整个数据集。
因此,mini-batch 和 batch 的区别在于处理的数据规模不同。mini-batch 是一个相对较小的数据子集,用于训练过程中的迭代更新,而 batch 是整个训练数据集的一次性处理。选择使用 mini-batch 还是 batch 取决于数据集的大小、计算资源的限制以及训练的效率要求。通常情况下,mini-batch 是更常用和常见的训练方式。
相关文章:
理解BatchNormalization层的作用
深度学习 文章目录 深度学习前言一、“Internal Covariate Shift”问题二、BatchNorm的本质思想三、训练阶段如何做BatchNorm四、BatchNorm的推理(Inference)过程五、BatchNorm的好处六、机器学习中mini-batch和batch有什么区别 前言 Batch Normalization作为最近一年来DL的重…...
uniapp实现文件预览过程
H5实现预览 <template><iframe :src"_url" style"width:100vw; height: 100vh;" frameborder"0"></iframe> </template> <script lang"ts"> export default {data() {return {_url: ,}},onLoad(option…...

深度学习-学习笔记记录
1、点云语义分割方法分类 分为5类:点、二维投影、体素、融合、集成 2、融合与集成的区别 融合: 概念:主要是将不同来源、类型的模型,例如深度学习、传统机器学习等,的结果或特征进行结合,以得到一个更好的模…...

程序员养生之道:延寿不忘初心——延寿必备
文章目录 每日一句正能量前言如何养生饮食篇运动篇休息篇后记 每日一句正能量 现代社会已不是大鱼吃小鱼的年代,而是快鱼吃慢鱼的年代。 前言 在IT行业中,程序员是一个重要的职业群体。由于长时间的繁重编程工作,程序员们常常忽略了身体健康…...
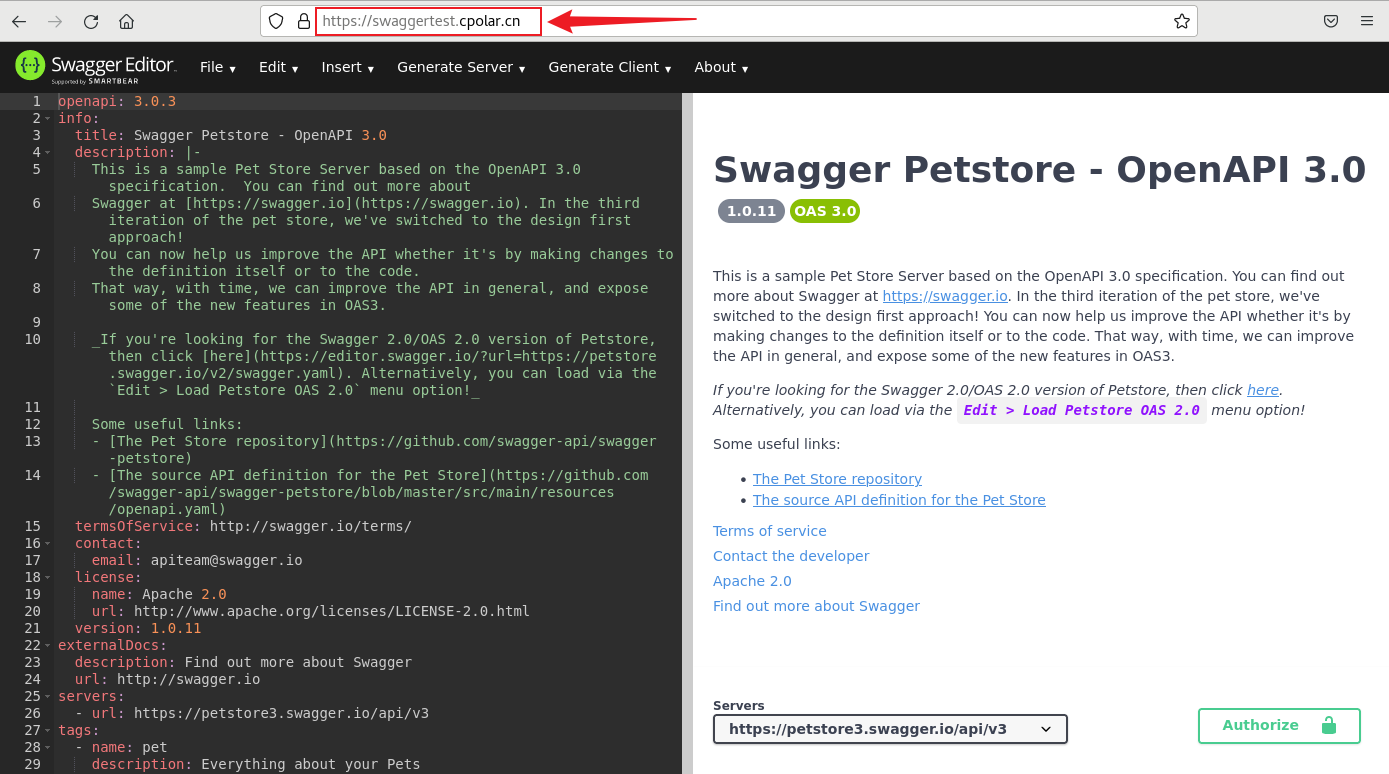
使用Docker安装部署Swagger Editor并远程访问编辑API文档
文章目录 Swagger Editor本地接口文档公网远程访问1. 部署Swagger Editor2. Linux安装Cpolar3. 配置Swagger Editor公网地址4. 远程访问Swagger Editor5. 固定Swagger Editor公网地址 Swagger Editor本地接口文档公网远程访问 Swagger Editor是一个用于编写OpenAPI规范的开源编…...
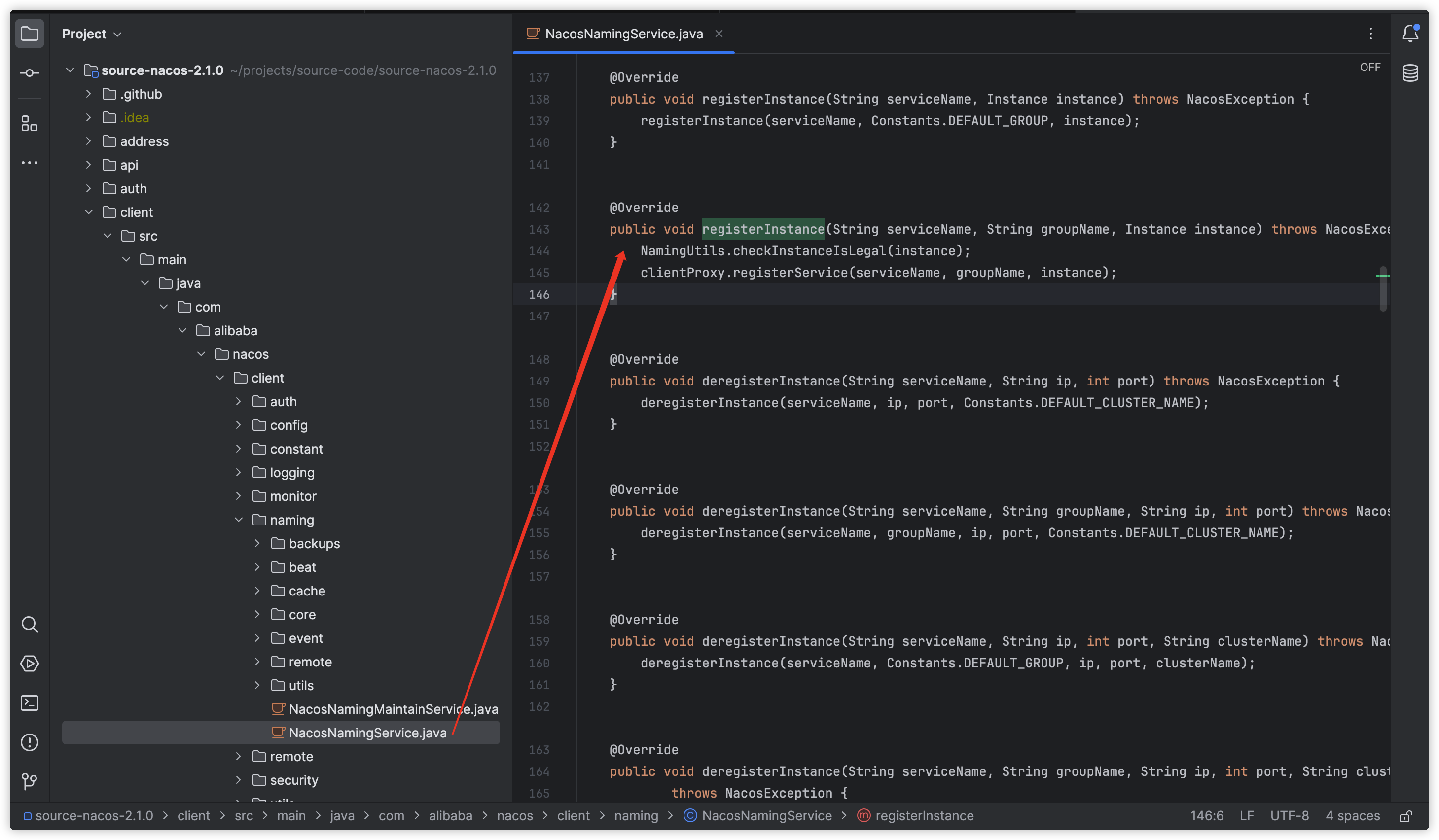
Nacos 2.X核心架构源码剖析
概述 注册中心并发处理,1.4.x 写时复制,2.1.0 读写分离;nacos 一般使用 AP 架构,即临时实例,1.4.x 为 http 请求,2.1.0 优化为 gRPC 协议;源码中使用了大量的事件通知机制和异步定时线程池&…...
C语言--每日选择题--Day31
第一题 1. 下面程序 i 的值为() int main() {int i 10;int j 0;if (j 0)i; elsei--; return 0; } A:11 B:9 答案及解析 B if语句中的条件判断为赋值语句的时候,因为赋值语句的返回值是右操作数; …...

chrome vue devTools安装
安装好后如下图所示: 一:下载vue devTools 下载链接https://download.csdn.net/download/weixin_44659458/13192207?spm1001.2101.3001.6661.1&utm_mediumdistribute.pc_relevant_t0.none-task-download-2%7Edefault%7ECTRLIST%7EPaid-1-13192207…...

Spring Security 6.x 系列(7)—— 源码分析之Builder设计模式
一、Builder设计模式 WebSecurity、HttpSecurity、AuthenticationManagerBuilder 都是框架中的构建者,把他们放到一起看看他们的共同特点: 查看AuthenticationManagerBuilder的继承结构图: 查看HttpSecurity的继承结构图: 查看W…...

PyQt6 中自定义浮点型滑块类
介绍: 在PyQt6中,滑块(Slider)是常用的用户界面元素之一,用于选择数值范围。然而,有时候我们可能需要使用浮点数值,而标准的滑块仅支持整数。为了解决这个问题,我们可以创建一个自定…...

笔记,B+树
B树面对的场景,是一个有10亿行的表,希望某一列是有序的。这么大的数据量,内存里放不下,需要放在硬盘里。结果,原本运行于内存的二叉树,就升级为B树了。 在二叉树中,每个节点存储着一个数字&…...
代码随想录刷题题Day2
刷题的第二天,希望自己能够不断坚持下去,迎来蜕变。😀😀😀 刷题语言:C / Python Day2 任务 977.有序数组的平方 209.长度最小的子数组 59.螺旋矩阵 II 1 有序数组的平方(重点:双指针…...

【JAVA面向对象编程】--- 探索子类如何继承父类
🌈个人主页: Aileen_0v0🔥学习专栏: Java学习系列专栏 💫个人格言:"没有罗马,那就自己创造罗马~" 目录 继承 继承的普通成员方法调用 及 普通成员变量修改 构造方法的调用 子类构造方法 继承 package Inherit;class Animal …...

从浏览器控制台发送get,post请求
---------------------get请求--------------------------- fetch(url, { method: get, }) .then(response > response.json()) .then(data > { // 获取到响应的数据后的处理逻辑 console.log(data); }) .catch(error > { // 请求发生错误的处理逻…...
海外问卷调查怎么批量做?可以用指纹浏览器吗?
海外问卷调查通常是指产品与品牌上线时,基于消费者、市场调查而组织的问卷调查,包括个人、企业或其他组织,以获取关于市场、消费者行为、产品需求、社会趋势等方面的见解。 通常,研究人员或组织会设计一份问卷,通过在线…...

HarmonyOS 位置服务开发指南
位置服务开发概述 移动终端设备已经深入人们日常生活的方方面面,如查看所在城市的天气、新闻轶事、出行打车、旅行导航、运动记录。这些习以为常的活动,都离不开定位用户终端设备的位置。 当用户处于这些丰富的使用场景中时,系统的位置能力…...

ThinkPHP6学生选课管理系统
有需要请加文章底部Q哦 可远程调试 ThinkPHP6学生选课管理系统 一 介绍 此学生选课管理系统基于ThinkPHP6框架开发,数据库mysql8,前端bootstrap。系统角色分为学生,教师和管理员。学生登录后可进行选课,教师登录后可查看选课情况…...

uniapp如何与原生应用进行混合开发?
目录 前言 1.集成Uniapp 2.与原生应用进行通信 3.实现原生功能 4.使用原生UI组件 结论: 前言 随着移动应用市场的不断发展,使用原生开发的应用已经不能满足用户的需求,而混合开发成为了越来越流行的选择。其中,Uniapp作为一种跨平台的开…...

Csharp(C#)无标题栏窗体拖动代码
C#(C Sharp)是一种现代、通用的编程语言,由微软公司在2000年推出。C#是一种对象导向的编程语言,它兼具C语言的高效性和Visual Basic语言的易学性。C#主要应用于Windows桌面应用程序、Windows服务、Web应用程序、游戏开发等领域。C…...
- 深度学习)
李宏毅2020机器学习课程笔记(二)- 深度学习
相关专题: 李宏毅2020机器学习资料汇总 本系列笔记: 李宏毅2020机器学习课程笔记(一)- 分类与回归李宏毅2020机器学习课程笔记(二)- 深度学习李宏毅2020机器学习课程笔记(三)- CNN、半监督、RNN文章目录 3. Deep LearningBrief Introduction of Deep Learning(P12)Ba…...

《QGIS空间数据处理与高级制图》022:融合后拓扑错误预检查
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

15万个科技岗位消失的真相
周四早上7点43分,我的手机震动了一下,是一位同行的消息——另一位我认识了五年的数据团队负责人。他管理的团队规模是我的两倍,所在的公司你一定听说过。 消息只有四个字:“你的人安全吗?” 我立刻明白他的意思。Met…...

CANN/asc-devkit:UB到GM数据拷贝函数
asc_copy_ub2gm 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

为什么选择Minimal:GitHub Pages最简洁主题的深度解析与快速入门指南
为什么选择Minimal:GitHub Pages最简洁主题的深度解析与快速入门指南 【免费下载链接】minimal Minimal is a Jekyll theme for GitHub Pages 项目地址: https://gitcode.com/gh_mirrors/mini/minimal Minimal主题是GitHub Pages平台上最受欢迎、最简洁的Jek…...

网关连接ModbusRTU串行设备故障排查
客户在使用我们串行网关时常常遇到串行侧网络通讯问题,但是又无从下手,不知道如何排查。根据客户常见问题,进行了以下总结。即便是不连接我们网关,对于ModbusRTU串行设备在通讯故障时,都可以按照以下步骤来排查和解决。…...

Perseus:5分钟解锁碧蓝航线全皮肤的神奇补丁
Perseus:5分钟解锁碧蓝航线全皮肤的神奇补丁 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 还在为碧蓝航线中那些精美皮肤需要付费而烦恼吗?想免费体验所有舰娘的不同外观吗&…...

USB扩展坞
usb中引脚含意DP表示USB的差分信号线正极DM表示USB的差分信号线负极差分对布线:大于设置的距离,使用等长调节每一个晶振都要放置...

怎么跨领域写文献综述?
刚踏入陌生交叉领域的科研人,最怕的就是面对动辄数十万篇的文献——翻了几十篇却找不到奠基性成果,读了一堆边缘文献导致研究方向跑偏,几周时间耗进去却连领域脉络都没理清,这种低效焦虑几乎每个科研人都经历过。传统方法里&#…...

5分钟掌握抖音资源批量下载:开源douyin-downloader终极指南
5分钟掌握抖音资源批量下载:开源douyin-downloader终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

软件许可优化选到头大?八家公司直接给你答案
上周一个做采购的朋友打电话来,声音都哑了。说他们公司被Adobe审计盯上了,对方要他们在两周内提交过去三年的部署报告。他们IT就两个人,连公司有多少台电脑装了Photoshop都说不清。我问她你现在打算怎么办,她说正在看各种软件许可…...