Kafka的存储机制和可靠性
文章目录
- 前言
- 一、Kafka 存储选择
- 二、Kafka 存储方案剖析
- 三、Kafka 存储架构设计
- 四、Kafka 日志系统架构设计
- 4.1、Kafka日志目录布局
- 4.2、Kafka磁盘数据存储
- 五、Kafka 可靠性
- 5.1、Producer的可靠性保证
- 5.1.1、kafka 配置为 CP(Consistency & Partition tolerance)系统
- 5.1.2、kafka 配置为 AP(Availability & Partition tolerance)系统
- 5.2、Broker 的可靠性保证
- 5.3、Consumer 的可靠性策略
前言
Kafka 是为了解决大数据的实时日志流而生的, 每天要处理的日志量级在千亿规模。对于日志流的特点主要包括 :
- 数据实时产生。
- 海量数据存储与处理。
所以它必然要面临分布式系统遇到的高并发、高可用、高性能等三高问题。
对于 Kafka 的存储需要保证以下几点:
- 存储的主要是消息流(可以是简单的文本格式也可以是其他格式)。
- 要支持海量数据的高效存储、高持久化(保证重启后数据不丢失)。
- 要支持海量数据的高效检索(消费的时候可以通过offset或者时间戳高效查询并处理)。
- 要保证数据的安全性和稳定性、故障转移容错性。
一、Kafka 存储选择
磁盘的顺序I/O性能要强于内存的随机I/O性能。如果需要较高的存储性能,必然是提高读速度和写速度:
- 提高读速度:利用索引,来提高查询速度,但是有了索引,大量写操作都会维护索引,那么会降低写入效率。常见的如关系型数据库:mysql等。
- 提高写速度:这种一般是采用日志存储, 通过顺序追加(批量)写的方式来提高写入速度,因为没有索引,无法快速查询,最严重的只能一行行遍历读取。常见的如大数据相关领域的基本都基于此方式来实现。
二、Kafka 存储方案剖析
对于 Kafka 来说, 它主要用来处理海量数据流,这个场景的特点主要包括:
- 写操作:写并发要求非常高,基本得达到百万级 TPS,顺序追加写日志即可,无需考虑更新操作。
- 读操作:相对写操作来说,比较简单,只要能按照一定规则高效查询即可(offset或者时间戳)。
对于写操作来说,直接采用顺序追加写日志的方式就可以满足 Kafka 对于百万TPS写入效率要求。重点在如何解决高效查询这些日志。Kafka采用了稀疏哈希索引(底层基于Hash Table 实现)的方式。

把消息的 Offset 设计成一个有序的字段,这样消息在日志文件中也就有序存放了,也不需要额外引入哈希表结构, 可以直接将消息划分成若干个块,对于每个块,我们只需要索引当前块的第一条消息的Offset (类似二分查找算法的原理),即先根据 Offset 大小找到对应的块, 然后再从块中顺序查找,这样就可以快速定位到要查找的消息。

一个Topic对应多个partition,一个partition对应多个segment,一个segment有.log/.index/.timeindex等文件。
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka采取了分片和索引机制。
它将每个 Partition 分为多个 Segment,每个 Segment 对应两个文件:“.index” 索引文件和 “.log” 数据文件。
这些文件位于同一文件下,该文件夹的命名规则为:topic 名-分区号。例如,test这个 topic 有三个分区,则其对应的文件夹为 test-0,test-1,test-2。
$ ls /tmp/kafka-logs/test-0
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint
index 和 log 文件以当前 Segment 的第一条消息的 Offset 命名。下图为 index 文件和 log 文件的结构示意图:
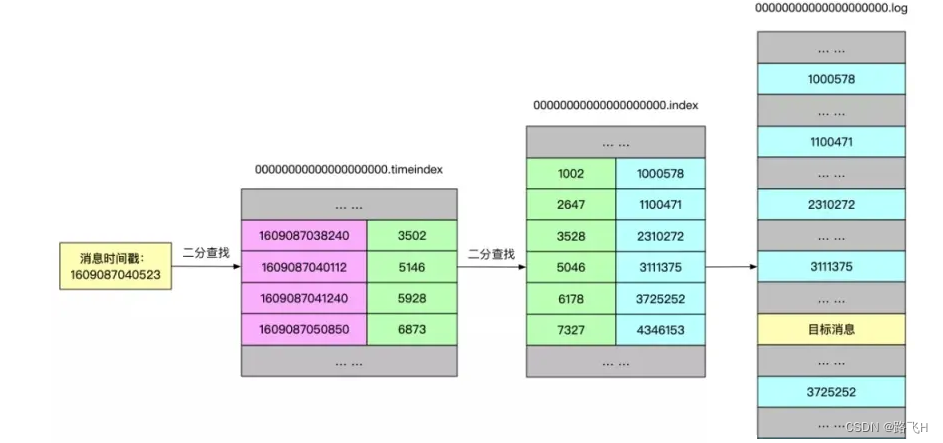
“.index” 文件存储大量的索引信息;“.log” 文件存储大量的数据。索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
查看索引:
sh ./kafka-dump-log.sh --files /tmp/kafka-logs/test-0/00000000000000000000.index
Dumping /tmp/kafka-logs/test-0/00000000000000000000.index
offset: 19999 position: 300695
Mismatches in :/tmp/kafka-logs/test-0/00000000000000000000.indexIndex offset: 19999, log offset: 10000
三、Kafka 存储架构设计
Kafka 最终的存储实现方案:基于顺序追加写日志 + 稀疏哈希索引。
Kafka 是基于「主题 + 分区 + 副本 + 分段 + 索引」的结构:
- kafka 中消息是以主题 Topic 为基本单位进行归类的,这里的 Topic 是逻辑上的概念,实际上在磁盘存储是根据分区 Partition 存储的, 即每个 Topic 被分成多个 Partition,分区 Partition 的数量可以在主题 Topic 创建的时候进行指定。
- Partition 分区主要是为了解决 Kafka 存储的水平扩展问题而设计的, 如果一个 Topic 的所有消息都只存储到一个 Kafka Broker上的话, 对于 Kafka 每秒写入几百万消息的高并发系统来说,这个Broker 肯定会出现瓶颈, 故障时候不好进行恢复,所以 Kafka 将 Topic 的消息划分成多个Partition, 然后均衡的分布到整个 Kafka Broker 集群中。
- Partition 分区内每条消息都会被分配一个唯一的消息 id,即偏移量 Offset,因此kafka 只能保证每个分区内部有序性,并不能保证全局有序性。
- 为了防止 Log 日志过大,Kafka 又引入了日志分段(LogSegment)的概念,将 Log 切分为多个 LogSegement,相当于一个巨型文件被平均分割为一些相对较小的文件,这样也便于消息的查找、维护和清理。这样在做历史数据清理的时候,直接删除旧的 LogSegement 文件就可以了。
- Log 日志在物理上只是以文件夹的形式存储,而每个 LogSegement 对应磁盘上的一个日志文件和两个索引文件,以及可能的其他文件(比如以".snapshot"为后缀的快照索引文件等)。
四、Kafka 日志系统架构设计
kafka 消息是按主题 Topic 为基础单位归类的,各个 Topic 在逻辑上是独立的,每个 Topic 又可以分为一个或者多个 Partition,每条消息在发送的时候会根据分区规则被追加到指定的分区中
4.1、Kafka日志目录布局
Log 对应了一个命名为-的文件夹。举个例子,假设现在有一个名为“topic-order”的 Topic,该 Topic 中 有4个 Partition,那么在实际物理存储上表现为“topic-order-0”、“topic-order-1”、“topic-order-2”、“topic-order-3” 这4个文件夹。
Log 中写入消息是顺序写入的。但是只有最后一个 LogSegement 才能执行写入操作,之前的所有LogSegement 都不能执行写入操作。为了更好理解这个概念,我们将最后一个 LogSegement 称 为"activeSegement",即表示当前活跃的日志分段。随着消息的不断写入,当 activeSegement 满足一定的条件时,就需要创建新的 activeSegement,之后再追加的消息会写入新的 activeSegement。

为了更高效的进行消息检索,每个 LogSegment 中的日志文件(以“.log”为文件后缀)都有对应的几个索引文件:偏移量索引文件(以“.index”为文件后缀)、时间戳索引文件(以“.timeindex”为文件后缀)、快照索引文件 (以“.snapshot”为文件后缀)。其中每个 LogSegment 都有一个 Offset 来作为基准偏移量(baseOffset),用来表示当前 LogSegment 中第一条消息的 Offset。偏移量是一个64位的Long 长整型数,日志文件和这几个索引文件都是根据基准偏移量(baseOffset)命名的,名称固定为20位数字,没有达到的位数前面用0填充。比如第一个 LogSegment 的基准偏移量为0,对应的日志文件为00000000000000000000.log。
注意每个 LogSegment 中不只包含“.log”、“.index”、“.timeindex”这几种文件,还可能包含“.snapshot”、“.txnindex”、“leader-epoch-checkpoint”等文件, 以及 “.deleted”、“.cleaned”、“.swap”等临时文件。
消费者消费的时候,会将提交的位移保存在 Kafka 内部的主题__consumer_offsets中。
4.2、Kafka磁盘数据存储
Kafka 是依赖文件系统来存储和缓存消息,以及典型的顺序追加写日志操作,另外它使用操作系统的 PageCache 来减少对磁盘 I/O 操作,即将磁盘的数据缓存到内存中,把对磁盘的访问转变为对内存的访问。
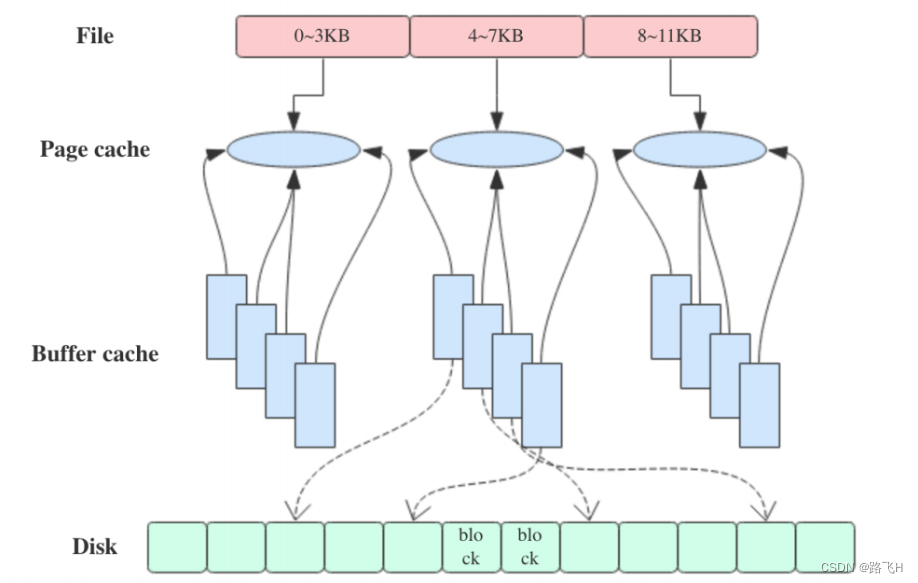
在 Kafka 中,大量使用了 PageCache, 这也是 Kafka 能实现高吞吐的重要因素之一, 当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据页是否在 PageCache 中,如果命中则直接返回数据,从而避免了对磁盘的 I/O 操作;如果没有命中,操作系统则会向磁盘发起读取请求并将读取的数据页存入 PageCache 中,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检查数据页是否在页缓存中,如果不存在,则 PageCache 中添加相应的数据页,最后将数据写入对应的数据页。被修改过后的数据页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
除了消息顺序追加写日志、PageCache以外, kafka 还使用了零拷贝(Zero-Copy)技术来进一步提升系统性能。

五、Kafka 可靠性
Kafka 从拓扑上分有如下角色:
- Consumer: 消费者。
- Producer: 生产者。
- Kafka broker: kafka 集群中的服务器,topic 里的消息数据存在上面。

Producer 采用发送 push 的方式将消息发到 broker 上,broker 存储后。由 consumer 采用 pull 模式订阅并消费消息。
5.1、Producer的可靠性保证
生产者的可靠性保证依靠回答: 发消息之后有没有 ack,发消息收到 ack 后,是不是消息就不会丢失了?而 Kafka 通过配置来指定 producer 生产者在发送消息时的 ack 策略:
# -1(全量同步确认,强可靠性保证)
Request.required.acks= -1
# 1(leader 确认收到, 默认)
Request.required.acks = 1
# 0(不确认,但是吞吐量大)
Request.required.acks = 0
5.1.1、kafka 配置为 CP(Consistency & Partition tolerance)系统
request.required.acks=-1
min.insync.replicas = ${N/2 + 1}
unclean.leader.election.enable = false
N是follower的数量。

正常情况下,所有 follower 复制完成后,leader 回 producer ack。
异常情况下,如果当数据发送到 leader 后部分副本(f1 和 f2 同步), leader 挂了?此时任何 follower 都有可能变成新的 leader, producer 端会得到返回异常,producer 端会重新发送数据,但这样数据可能会重复(但不会丢失)。
min.insync.replicas 参数用于保证当前集群中处于正常同步状态的副本 follower 数量,当实际值小于配置值时,集群停止服务。如果配置为 N/2+1, 即多一半的数量,则在满足此条件下,通过算法保证强一致性。当不满足配置数时,牺牲可用性即停服。
unclean.leader.election.enable 来控制在有些follower未同步的情况下,是否可以选举未同步的follower为 leader。旧版本中默认为true,在某个版本下已默认为 false,避免这种情况下消息截断的出现。
通过 ack 和 min.insync.replicas 和 unclean.leader.election.enable 的配合,保证在 kafka 配置为 CP系统时,要么不工作,要么得到 ack 后,消息不会丢失且消息状态一致。
5.1.2、kafka 配置为 AP(Availability & Partition tolerance)系统
request.required.acks=1
min.insync.replicas = 1
unclean.leader.election.enable = false
通过 producer 策略的配置和 kafka 集群通用参数的配置,可以针对自己的业务系统特点来进行合理的参数配置,在通讯性能和消息可靠性下寻得某种平衡。
5.2、Broker 的可靠性保证
消息落到 broker 后,集群通过何种机制来保证不同副本建的消息状态一致性。
LEO和HW简单介绍:
LEO:LogEndOffset的缩写,表示每个partition的log最后一条Message的位置。
HW: HighWaterMark的缩写,是指consumer能够看到的此partition的位置。 取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。
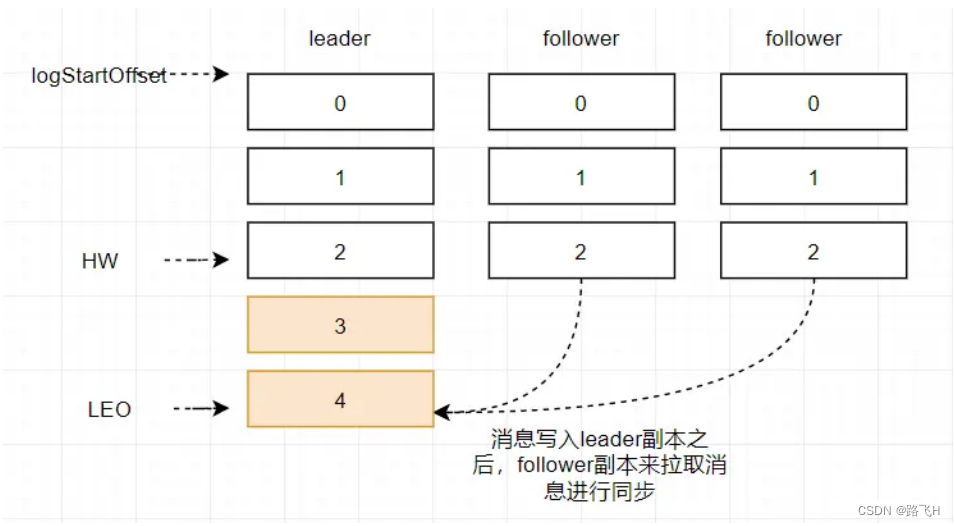
HW用于标识消费者可以读取的最大消息位置,LEO用于标识消息追加到文件的最后位置。
如果消息发送成功,不代表消费者可以消费这条消息。
5.3、Consumer 的可靠性策略
(1) AutoCommit。
enable.auto.commit = true
auto.commit.interval.ms 默认5000 (5 seconds)
配置如上的 consumer 收到消息就返回正确给 brocker, 但是如果业务逻辑没有走完中断了,实际上这个消息没有消费成功。这种场景适用于可靠性要求不高的业务。其中 auto.commit.interval.ms 代表了自动提交的间隔。
(2) 手动 Commit。
enable.auto.commit = false
配置为手动提交的场景下,业务开发者需要在消费消息到消息业务逻辑处理整个流程完成后进行手动提交。如果在流程未处理结束时发生重启,则之前消费到未提交的消息会重新消费到,即消息显然会投递多次。此处应用与业务逻辑明显实现了幂等的场景下使用。
相关文章:
Kafka的存储机制和可靠性
文章目录 前言一、Kafka 存储选择二、Kafka 存储方案剖析三、Kafka 存储架构设计四、Kafka 日志系统架构设计4.1、Kafka日志目录布局4.2、Kafka磁盘数据存储 五、Kafka 可靠性5.1、Producer的可靠性保证5.1.1、kafka 配置为 CP(Consistency & Partition tolerance)系统5.1.…...

数据库时间类型之间的转换魔法
解锁时间数据的魔法 时间,是数据库中一个充满魔法的复杂表现形式。在这篇博客中,我们将探讨在数据库中时间戳(timestamp)、日期(date)、日期时间(datetime)和字符串之间的转换技巧&…...

conda和pip常用命令整理
文章目录 一、conda常用指令1. 更新2 .环境管理3. 包管理 二、pip常用命令1. 常用命令2. 国内镜像 一、conda常用指令 1. 更新 conda --version 或 conda -V #查看conda版本 conda update conda # 基本升级 conda update anaconda # 大的升级 conda upd…...

英语翻译小软件 ← Python实现
【程序描述】 利用Python实现一个英语翻译小软件。 ★ 当输入一个英文单词后,输出对应的中文意思。 ★ 当输入 q 时,退出程序。 ★ 当输入一个不存在的词条时,捕获异常,提示“No finding!”。【程序代码】 dict{&quo…...
将项目放到gitee上
参考 将IDEA中的项目上传到Gitee仓库中_哔哩哔哩_bilibili 如果cmd运行ssh不行的话,要换成git bash 如果初始化后的命令用不了,直接用idea项放右键,用git工具操作...

【机器视觉技术】:开创人工智能新时代
🎥 屿小夏 : 个人主页 🔥个人专栏 : IT杂谈 🌄 莫道桑榆晚,为霞尚满天! 文章目录 📑 前言🌤️ 机器视觉技术的实现☁️ 图像采集☁️ 图像处理☁️ 数据建模☁️应用展示…...
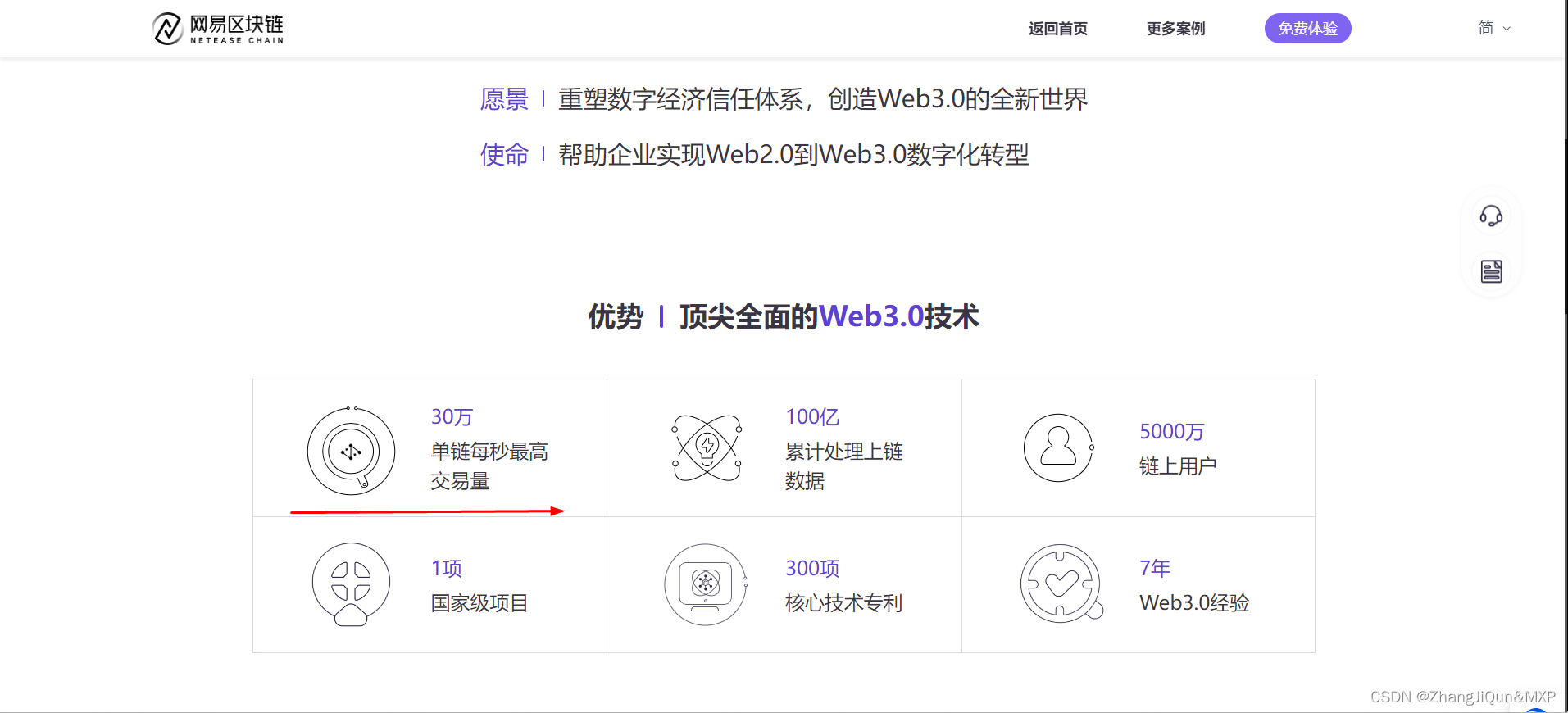
网易区块链,网易区块链赋能赣州脐橙数字藏品,数字指纹解决方案
目录 网易区块链 网易区块链赋能赣州脐橙数字藏品,助力革命老区三农之路 数字指纹解决方案 网易区块链 网易区块链成立于2017年,致力于Web3.0区块链技术的研发和应用。自主研发的区块链“天玄”引擎,在单链场景下支持每秒最高30万笔交易,单日可处理上链数据超10亿。 与…...

程序员如何兼职?
首先,写博客和制作短视频是一个好方法。想象一下,你是一个资深的程序员,而你的博客就像是一个个人课堂,帮助那些初入编程领域的人理解各种编程概念和技巧。你可以分享你的工作经验、解决问题的过程,甚至可以分享一些有…...

教育企业CRM选择技巧
教育行业的发展一波三折,要想在激烈的赛道脱颖而出,就需要有一套有效的CRM系统,来帮助教育机构提升招生效率、增加学员留存、提高教学质量。下面说说,教育企业选择CRM系统要具备的四大功能。 1、招生管理功能 教育机构的首要目标…...
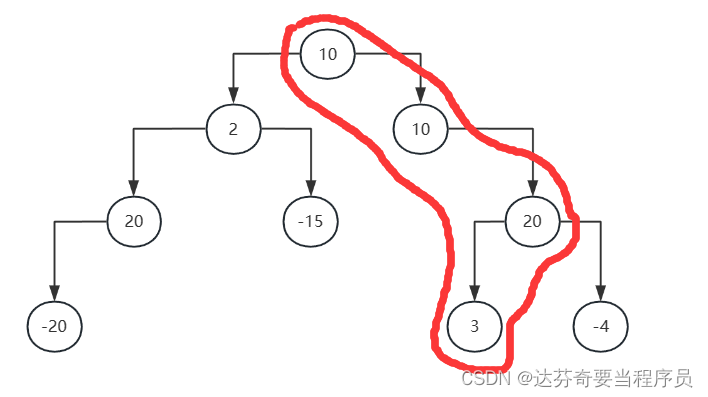
算法:Java计算二叉树从根节点到叶子结点的最大路径和
要求从根节点到叶子结点的最大路径和,可以通过递归遍历二叉树来实现。对于二叉树中的每个节点,我们都可以考虑包含该节点的最大路径和。在递归的过程中,我们需要不断更新全局最大路径和。 具体的思路 递归函数设计: 设计一个递归函…...

袖珍可穿戴手持气象仪是什么?
随着科技的不断发展,我们身边的世界正在变得越来越智能化。近日,一款名为WX-SQ12可穿戴手持气象仪的科技新品引起了人们的广泛关注。这款气象仪不仅具有创新性的可穿戴设计,还具备强大的气象数据监测功能,让用户可以随时掌握天气变…...
【Azure 架构师学习笔记】- Azure Databricks (1) - 环境搭建
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 前言 Databricks 已经成为了数据科学的必备工具,今时今日你已经很难抛开它来谈大数据,它常用于做复杂的ETL中的T, 数据分析,数据挖掘等,…...

无需繁琐编程 开启高效数据分析之旅!
不学编程做R统计分析:图形界面R Commander官方手册 R Commander是 R 的图形用户界面,不需要键入命令就可通过熟悉的菜单和对话框来访问 R 统计软件。 R 和 R Commander 均可免费安装于所有常见的操作系统——Windows、Mac OS X 和 Linux/UNIX。 本书作…...

JOSEF约瑟 剩余电流保护器 CLJ3-100A+LH30 导轨安装
CLJ3系列剩余电流动作继电器 系列型号: CLJ3-100A剩余电流动作继电器 CLJ3-250A剩余电流动作继电器 CLJ3-400A剩余电流动作继电器 CLJ3-630A剩余电流动作继电器 LH30剩余电流互感器 LH80剩余电流互感器 LH100剩余电流互感器 LH140剩余电流互感器 一、产品概…...

vue3自定义指令-文本超出宽度滚动
fontScroll.ts 指令文件 import { Directive } from vuefunction randomInt(min, max) {return Math.floor(Math.random() * (max - min 1)) min; } export default {// 可控制滚动速度,默认滚动速度20px/s,最低动画时长2smounted: (el, binding, vNode): void &…...
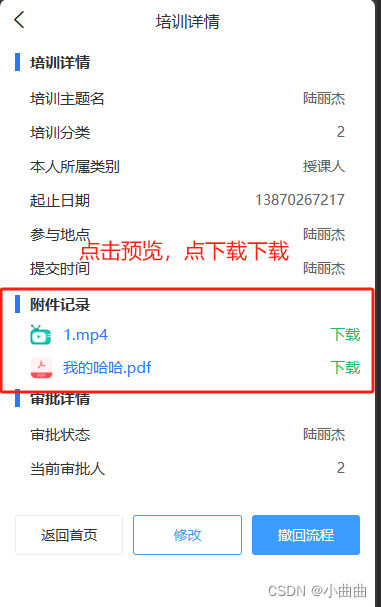
uniapp在H5端实现PDF和视频的上传、预览、下载
上传 上传页面 <u-form-item :label"(form.ququ3 1 ? 参培 : form.ququ3 2 ? 授课 : ) 证明材料" prop"ququ6" required><u-button click"upload" slot"right" type"primary" icon"arrow-upward" t…...

Kafka报错under-replicated partitions
1 under-replicated partitions异常原因 Kafka报错under replicated partitions意味着某些分区的副本数量未达到预期的复制因子。 主要有两种原因, Broker故障 如果某个Kafka Broker发生故障,导致其中一些分区的副本不再可用,那么这些分区就…...

【Python基础】字符集与字符编码
先行了解的知识: 1. 编码和解码 计算机内存储的信息都是二进制表示。 我们看到的英文,数字,汉字等在计算机内如何表示,那就需要编码 计算机内存储的信息需要解析出来,那就是解码 2.字符集与分类 什么是字符集…...

C# AES-128-CBC 加密
一、加密 /// <summary>/// 加密/// </summary>public static string AesEncrypt(string toEncrypt){byte[] toEncryptArray UTF8Encoding.UTF8.GetBytes(toEncrypt);byte[] keyArray UTF8Encoding.UTF8.GetBytes(Key);//注意编码格式(utf8编码 UTF8Encoding)byt…...
【惊喜福利】Docker容器化部署nextcloud网盘,享受高速稳定的文件共享体验!
Docker搭建nextcloud网盘 NextCloud是一款开源网络硬盘系统,它是一个私有、安全且功能完整的文件同步与共享解决方案,可以搭建一套属于自己或团队的云同步网盘。NextCloud的客户端覆盖了各种平台,包括Windows、Mac、Android、iOS、Linux等&am…...

Linux命令:strace
strace 命令 基本介绍 strace 是 Linux 系统中用于跟踪进程系统调用和信号的强大调试工具。它可以捕获并记录进程执行的所有系统调用、传递的参数、返回值以及接收到的信号,是程序员和系统管理员进行程序调试、性能分析和问题诊断的必备工具。 资料合集:…...

实战案例|向导布局一出手,企业流程表单直接专业满级
实战案例|向导布局一出手,企业流程表单直接专业满级 在企业系统里,有一类表单天生就必须按步骤走:用户注册、企业认证、项目申报、入职办理、采购申请、合同签署…这类表单一旦用 Tab 或折叠面板,就会显得不规范、不正…...

小红书内容采集终极指南:一键下载无水印图文视频的完整教程
小红书内容采集终极指南:一键下载无水印图文视频的完整教程 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...

单北斗GNSS变形监测系统在地质灾害监测中的应用与维护
北斗 GNSS 变形监测系统在地质灾害监测中发挥着重要作用。它通过高精度定位,实时捕捉地面形变,为防灾减灾提供精准数据支持。系统的定制化设计能适应不同环境,同时具备稳定性与可靠性。随着技术发展,监测和维护也变得更高效。这种…...

Taotoken的用量看板与成本管理功能实际使用感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的用量看板与成本管理功能实际使用感受 1. 功能定位与核心价值 在接入多个大模型进行开发时,一个普遍存在的困…...

python足球训练营系统的足球俱乐部管理系统 球员评估系统_m211bvkc
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能模块技术实现代码示例(球员评分计算)应用场景扩展方向获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货…...

2026时序数据库选型指南:为什么Apache IoTDB成为工业物联网首选
在数字化转型全面加速的今天,工业物联网、车联网、能源电力、智能制造等领域产生了海量的时序数据。这些数据具有高并发写入、海量存储、时间范围查询密集、实时分析要求高等特点,传统的关系型数据库和NoSQL数据库在处理这类数据时往往力不从心。 目录 …...

Windows 11系统优化终极方案:用Win11Debloat免费提升电脑性能
Windows 11系统优化终极方案:用Win11Debloat免费提升电脑性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter…...

HTR6916 共阴极16x9阵列LED驱动器 聚能芯半导体禾润电子一级代理
概述HTR6916 是一款功能卓越的 LED 驱动芯片。它可通过 2 线串行接口进行编程,能够完美支持 169 阵列的 LED 布局。芯片中的每一颗 LED 均能借助 8 位 PWM 数据实现独立调光,为用户提供了高度灵活的调光方案。此外,用户还能通过 ISET 端的外部…...

安卓悬浮看图神器 置顶悬浮,随时查看更便捷
手机修图。对着原图比对。疯狂切换后台。记个账号密码。来回切应用。手指头都快戳出老茧。看小说找配图。切屏像在玩杂技。急需一款神器。专治各种切屏多动症。浮动图片(安卓版)全局置顶图片永远钉在最上层。盖住其他所有APP。随心操控自由拖动位置。随意…...