大语言模型概述(一):基于亚马逊云科技的研究分析与实践
大型语言模型指的是具有数十亿参数(B+)的预训练语言模型(例如:GPT-3, Bloom, LLaMA)。这种模型可以用于各种自然语言处理任务,如文本生成、机器翻译和自然语言理解等。
大语言模型的这些参数是在大量文本数据上训练的。现有的大语言模型主要采用 Transformer 模型架构,并且在很大程度上扩展了模型大小、预训练数据和总计算量。他们可以更好地理解自然语言,并根据给定的上下文(例如 prompt)生成高质量的文本。其中某些能力(例如上下文学习)是不可预测的,只有当模型大小超过某个水平时才能观察到。
以下是 2019 年以来出现的各种大语言模型(百亿参数以上)时间轴,其中标黄的大语言模型已开源。
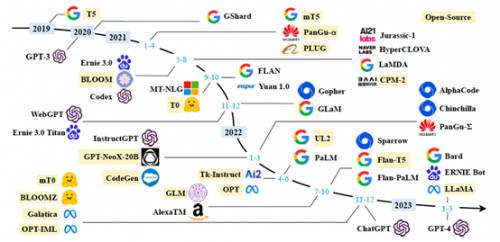
在本期文章中,我们将一起探讨大语言模型的发展历史、语料来源、数据预处理流程策略、训练使用的网络架构、最新研究方向分析(LLaMA、PaLM-E 等),以及在亚马逊云科技上进行大语言模型训练的一些最佳落地实践等。
大语言模型的发展历史
我们首先来了解下大语言模型的发展历史和最新研究方向分析。
大语言模型 1.0。过去五年里,自从我们看到最初的Transformer模型 BERT、BLOOM、GPT、GPT-2、GPT-3 等的出现,这一代的大语言模型在 PaLM、Chinchilla 和 LLaMA 中达到了顶峰。第一代 Transformers 的共同点是:它们都是在大型未加标签的文本语料库上进行预训练的。
大语言模型 2.0。过去一年里,我们看到许多经过预训练的大语言模型,正在根据标记的目标数据进行微调。第二代 Transformers 的共同点是:对目标数据的微调,使用带有人工反馈的强化学习(RLHF)或者更经典的监督式学习。第二代大语言模型的热门例子包括:InstructGPT、ChatGPT、Alpaca 和 Bard 等。
大语言模型 3.0。过去的几个月里,这个领域的热门主题是参数高效微调和对特定领域数据进行预训练,这是目前提高大语言模型计算效率和数据效率的最新方法。另外,下一代大语言模型可能以多模态和多任务学习为中心,这将为大语言模型带来更多崭新并突破想象力的众多新功能。
近年来的大语言模型概览
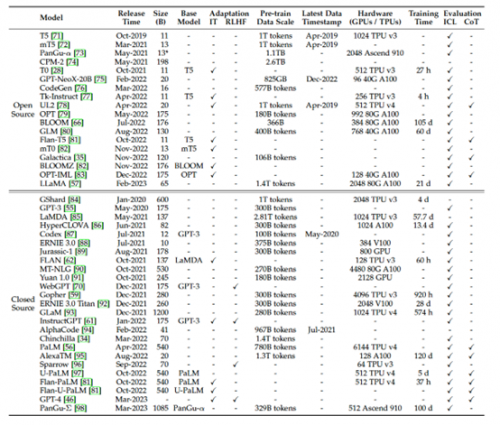
上图展示了近年来大语言模型(大于 10B 的参数)的统计数据,包括容量评估、预训练数据规模(token 数量或存储大小)和硬件资源成本。
图中,“Adaptation” 表示大语言模型是否经过了后续微调:IT 表示指令调整,RLHF 表示通过人工反馈进行强化学习。“Evaluation” 表示大语言模型在原始论文中是否经过了相应能力的评估:ICL 表示上下文学习(in-context learning),CoT 表示思维链(chain-of-thought)。
大语言模型的语料来源
与早期的预训练语言模型(PLMs)相比,包含更多参数的大语言模型需要更大的训练数据量,涵盖了更广泛的内容。为了满足这种需求,已经发布了越来越多的用于研究的训练数据集。根据他们的内容类型,大致可分类为六组:图书、CommonCrawl、Reddit 链接、维基百科、代码和其它。如下表所示:
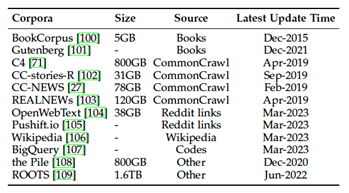

上图展示了现有大语言模型预训练数据中,各种不同的数据来源占比比率的信息。
大语言模型的数据预处理策略
在收集了大量数据后,对其进行预处理对于构建预训练语料库至关重要,尤其是要删除嘈杂、冗余、不相关和潜在的有毒数据,这可能会在很大程度上影响大语言模型的容量和性能。该论文中,研究者们用一个章节专门阐述了其研究团队的数据预处理策略,以及如何通过各种方法来提高所收集数据质量。

上图为该论文阐述大语言模型的预训练数据处理的典型策略概览图。
大语言模型的网络结构
大语言模型在训练阶段的网络结构设计参数,也是影响大语言模型性能的重要指标之一。下表列举了一些大语言模型的主要网络结构参数,包括:token 大小、归一化方式、位置嵌入方式、激活函数、是否使用 Bias、层数、注意力头的数量、隐藏状态大小、最大上下文长度等参数。如下表所示:
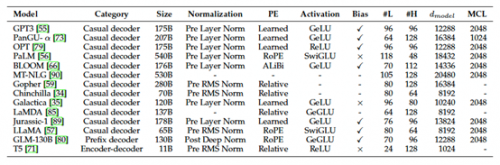
上表概述了包含详细配置信息的多个大语言模型的型号卡(Model cards):
PE 表示位置嵌入
#L 表示层数
#H 表示注意力头的数量
dmodel 表示隐藏状态的大小
MCL 表示最大上下文长度
大语言模型的涌现能力
LLM 的涌现能力被正式定义为「在小模型中不存在但在大语言模型中出现的能力」,这是 LLM 与以前的 PLM 区分开来的最显著特征之一。当出现这种新的能力时,它还引入了一个显著的特征:当规模达到一定水平时,性能显著高于随机的状态。以此类推,这种新模式与物理学中的相变现象密切相关。原则上,这种能力也可以与一些复杂的任务有关,而人们更关心可以应用于解决多个任务的通用能力。
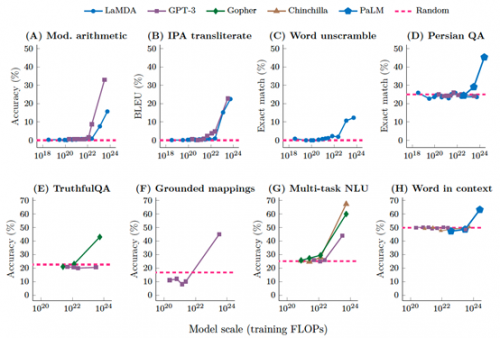
在少量提示(few-shot prompting)方法下测试了以下八个不同场景的大语言模型性能:
算术运算(Mod. arithmetic)
语音翻译(IPA transliterate)
单词解读(Word unscramble)
Persian QA
TruthfulQA 基准
概念映射(Grounded mappings)
多任务语言理解(Multi-task NLU)
上下文理解基准
每个点都是一个单独的大语言模型。当大语言模型实现随机时,就会出现通过少量提示(few-shot prompting)方法执行任务的能力性能,在模型大小达到一定规模之后,性能会显著提高到远高于随机水平。
目前大语言模型主要有三种代表性的涌现能力,分别是:
上下文学习
指令遵循
循序渐进的推理
上下文学习。GPT-3 正式引入了上下文学习能力:假设大语言模型已经提供了自然语言指令和多个任务描述,它可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新。
指令遵循。通过对自然语言描述(即指令)格式化的多任务数据集的混合进行微调,LLM 在微小的任务上表现良好,这些任务也以指令的形式所描述。这种能力下,指令调优使 LLM 能够在不使用显式样本的情况下通过理解任务指令来执行新任务,这可以大大提高泛化能力。
循序渐进的推理。对于小语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学学科单词问题。同时,通过思维链推理策略,LLM 可以通过利用涉及中间推理步骤的 prompt 机制来解决此类任务得出最终答案。据推测,这种能力可能是通过代码训练获得的。
相关文章:
大语言模型概述(一):基于亚马逊云科技的研究分析与实践
大型语言模型指的是具有数十亿参数(B)的预训练语言模型(例如:GPT-3, Bloom, LLaMA)。这种模型可以用于各种自然语言处理任务,如文本生成、机器翻译和自然语言理解等。 大语言模型的这些参数是在大量文本数据上训练的。…...
--repl - “读取-求值-输出” 循环)
LuatOS-SOC接口文档(air780E)--repl - “读取-求值-输出” 循环
示例 --[[ 本功能支持的模块及对应的端口 模块/芯片 端口 波特率及其他参数 Air101/Air103 UART0 921600 8 None 1 Air105 UART0 1500000 8 None 1 ESP32C3 UART0 921600 8 None 1 -- 注意, 简约版(无CH343)不支持 ESP32C2 …...

SpringBoot项目打成jar包后,上传的静态资源(图片等)如何存储和访问
1.问题描述: 使用springboot开发一个项目,开发文件上传的时候,通常会将上传的文件存储到资源目录下的static里面,然后在本地测试上传文件功能没有问题,但是将项目打成jar包放到服务器上运行的时候就会报错,…...

Selenium Grid
Selenium Grid 什么是Selenium Grid Selenium是Selenium套件的一部分,它专门用于并行运行多个测试用例在不同的浏览器、操作系统和机器上 Selenium Grid的两个版本 Grid1与Grid2两个版本的原理和基本工作方式完全相同,Grid2同时支持Selenium1和Selenium2&#x…...
ubuntu系统下搭建本地物联网mqtt服务器的步骤
那么假如我们需要做一些终端设备,例如温湿度传感器、光照等物联网采集设备要接入呢?怎么样才能将数据报送到服务器呢? 以下内容基于我们ubuntu系统下的emqx成功启动的基础上。我们可以用浏览器键入控制板的地址,如果启动成功&…...
)
计算机二级考试题库(答案)
题目一:计算机网络基础 1.计算机网络的定义是什么? 计算机网络是指由通讯设备和不同类型计算机组成的计算机系统,利用传输介质,如电缆、光缆、无线等与通讯协议,实现计算机之间的信息传递和共享资源。 2. 内网和外网有什么区别?…...
—— Fabric创建View的过程)
React Native 源码分析(五)—— Fabric创建View的过程
这篇文章详细分析一下,在React Native 新架构下,Fabric是如何创建View的,从React层发送把View信息到原生端开始分析。说明一点,React 层fiber的创建更新过程,不属于Fabric。其中Yoga的绘制过程不会太详细,只会给出大概流程,像布局缓存这些。文章的重点是帮你理解Fabric的…...

为什么同样的C代码在arm64-v8a可以跑,在armeabi-v7a会奔溃?
文章目录 背景过程第一个坑第二个坑 arm64-v8a 和 armeabi-v7a的区别实例64位,Android设备CPU:arm64-v8a32位,Android设备CPU:armeabi-v7a 基本数据类型在32位和64位的区别指针长度在32位和64位的区别 其他可能性chatgpt回答参考 背景 使用NDK开发项目的…...

C++初学者线路图 23年12月
高精度计算 1. 高精度加减法 高精度加减法课程(12月1日~12月4日)高精度加减法配套程序(12月5日~12月6日) 2. 高精度乘法 高精度乘法课程(12月7日~12月10日)高精度乘法…...

Day37| Leetcode 738. 单调递增的数字
今天就一个题目,做完吃完饭抓紧做六级试题。 Leetcode 738. 单调递增的数字 题目链接 738 单调递增的数字 本题目思路还是比较巧妙的,对于98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首…...
【工具分享】| 阅读论文神器 使用技巧 AI润色 AI翻译
文章目录 1 使用技巧1.1 功能一 即时翻译1.2 功能二 文献跳转1.3 功能三 多设备阅读1.4 功能四 小组讨论笔记共享1.5 功能五 个人文献管理 2 其他功能 超级喜欢Readpaper这一款论文阅读软件,吹爆他哈哈 为什么? 当然是他可以解决我们传统阅读论文的种种…...

String.prototype.match进行==判断
今天发现一个String.prototype.match的奇葩用法 export const isWeChat (() > {let ua window.navigator.userAgent.toLowerCase();return ua.match(/MicroMessenger/i) "micromessenger"; })();这是我在网站上找到的一个判断是否是微信浏览器的方法ÿ…...

less 笔记
<link rel"stylesheet/less" type"text/css" href"styles.less" /> <script src"https://cdn.jsdelivr.net/npm/less4" ></script>变量(Variables) 原生已支持 --前缀定义属性 var() 函数获取…...
Java中的异常你了解多少?
目录 一.认识异常二.异常分类三.异常的分类1.编译时异常2.运行时异常 四.异常的处理1.LYBL:事前防御型2.EAFP:事后认错型 五.异常的抛出Throw注意事项 六.异常的捕获1.异常的捕获2.异常声明throws3.try-catch捕获并处理 七.自定义异常 一.认识异常 在Jav…...
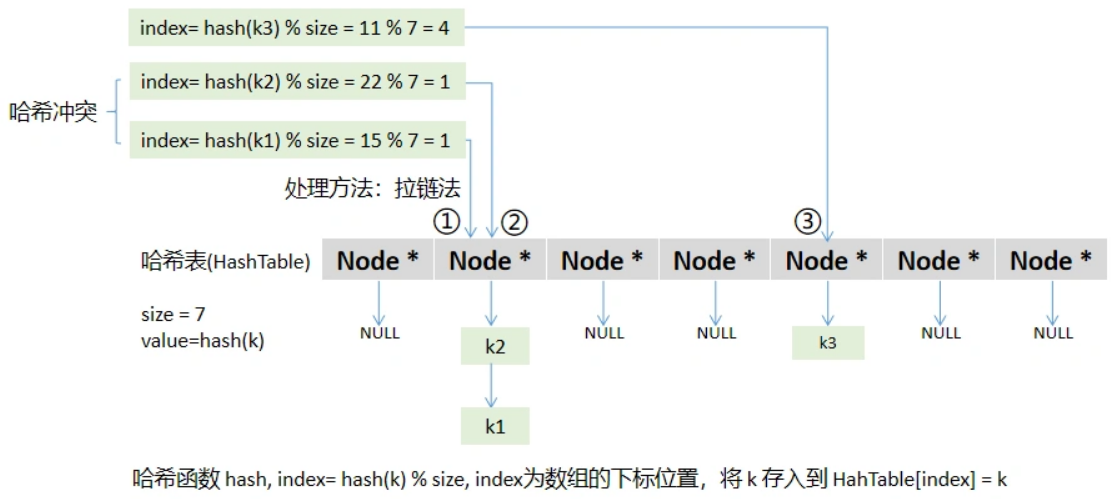
查找算法及哈希表
1 二分查找 1.1 重要概念 拟解决的问题:判断某个区间是否包含某个元素,无法确定区间中包含重复元素的具体位置;使用条件:查找的区间必须符合单调性;本质:采用分治思想,将某个单调区间一分为二…...

ELK分布式日志管理平台部署
目录 一、ELK概述 1、ELK概念: 2、其他数据收集工具: 3、ELK工作流程图: 4、ELK 的工作原理: 5、日志系统的特征: 二、实验部署: 1、ELK Elasticsearch 集群部署 2、安装 Elasticsearch-head 插件 …...
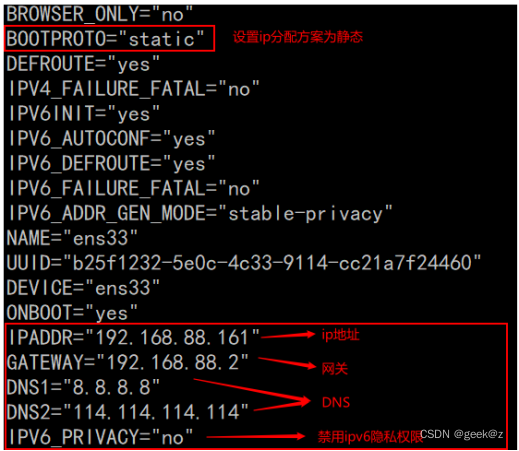
四、虚拟机网络配置
目录 1、VMware网卡配置模式 1.1 桥接模式 1.2 NAT模式 1.3 仅主机模式 2、编辑虚拟机的网络编辑器 3、编辑Window的虚拟网卡 4、修改IP地址为静态 4.1 查看网卡名字 4.2 编辑修改网卡IP地址的配置文件 4.3 重启网络: 4.…...
四、Lua循环
文章目录 一、while(循环条件)二、for(一)数值for(二)泛型for(三)repeat util 既然同为编程语言,那么控制逻辑里的循环就不能缺少,它可以帮助我们实现有规律的重复操作,而…...
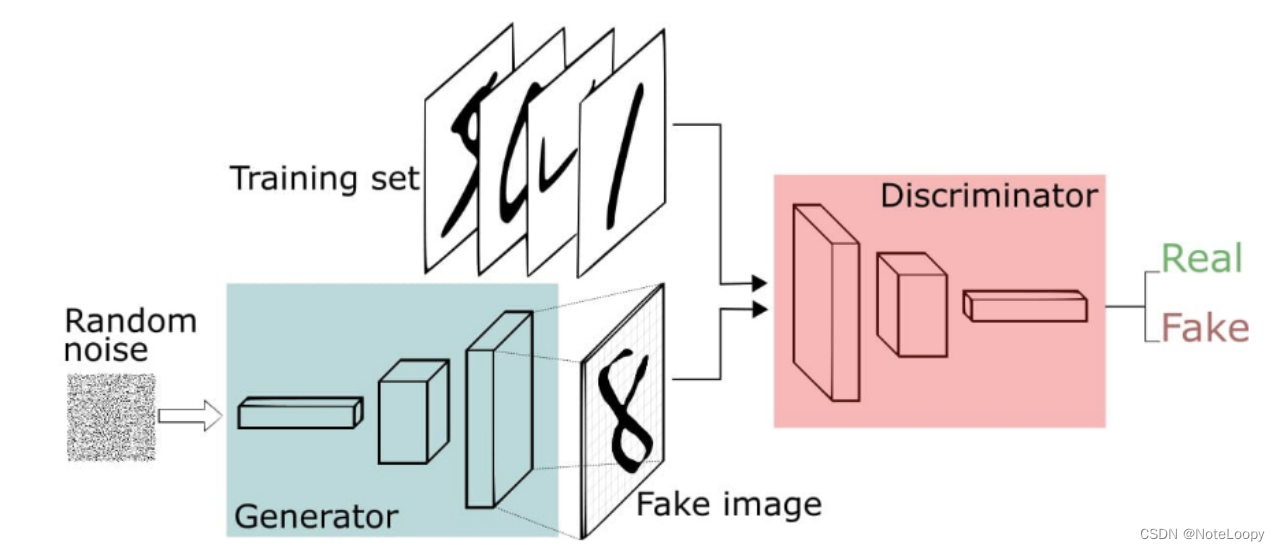
生成对抗网络(GAN)手写数字生成
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步) 二、什么是生成对抗网络1. 简单介绍2. 应用领域 三、网络结构四、构建生成器五、构建鉴别器六、训练模型1. 保存样例图片2. 训练模型 七、生成动图 一、前言 我的环境࿱…...

LeetCode Hot100 31.下一个排列
题目: 整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。 例如,arr [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。 整数数组的 下一个排列 是指其整数的下一个字典序更大的排列…...

5个关键功能:如何将普通鼠标打造成macOS生产力神器?
5个关键功能:如何将普通鼠标打造成macOS生产力神器? 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾为macOS上的…...

在 Node.js 后端服务中接入 Taotoken 多模型 API 的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Node.js 后端服务中接入 Taotoken 多模型 API 的实践 为后端服务添加 AI 能力,例如智能客服或内容生成,…...

油雾净化设备哪家技术更专业
在机械加工、五金锻造、热处理等工业生产场景中,机床切削、乳化液喷淋、高温加工会持续产生大量工业油雾。悬浮在车间内的油雾不仅会腐蚀生产设备、污染生产环境,还会刺激人体呼吸道,危害操作人员身体健康,同时超标排放还会违反环…...

保姆级教程:用UltraISO给U盘刻录Ubuntu 22.04启动盘,一次成功不踩坑
零基础实战:用UltraISO打造Ubuntu 22.04启动盘的终极指南 第一次接触Linux系统安装的新手,往往会在制作启动盘这一步遇到各种意想不到的问题。U盘明明已经刻录完成,却在启动时出现黑屏、报错甚至根本无法识别——这些困扰过无数初学者的坑&am…...

揭秘硬件安全:ChipWhisperer如何成为嵌入式设备的安全守护神?
揭秘硬件安全:ChipWhisperer如何成为嵌入式设备的安全守护神? 【免费下载链接】chipwhisperer ChipWhisperer - the complete open-source toolchain for side-channel power analysis and glitching attacks 项目地址: https://gitcode.com/gh_mirror…...

CANN/pypto CODEGEN组件错误码
CODEGEN 组件错误码 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 范围:F6XXXX本文档说明 CODEGEN 组件的错误码定义、场景说明与排…...

C++链接与符号管理
C链接与符号管理链接是将编译后的目标文件组合成可执行程序的过程。理解链接机制和符号管理对于解决链接错误和优化程序结构至关重要。外部链接允许符号在多个翻译单元间共享。#include extern int global_variable; extern void external_function();void external_linkage_ex…...

AI如何从“0”到“1”设计一把完美的“蛋白钥匙”?
你是否想过,在微观的生命世界里,无数的生命活动都像是一把把精密的钥匙打开一把把特定的锁?蛋白质之间的相互作用正是这套机制的核心。找到那把独一无二的“钥匙”,一直是生命科学研究者们追求的目标。 过去的挑战:大…...

2026免费在线去水印软件对比推荐|五款工具测评,快速去掉各平台水印
在日常内容创作和素材整理中,很多人都会遇到水印的问题。无论是从抖音、快手、小红书还是B站保存视频,亦或是收集网络图片素材,几乎所有平台的内容都会附带水印。这些水印虽然有利于版权保护,但对于正常的个人使用、内容再创作或学…...

3步实现百度网盘高速下载:Python解析工具实战指南
3步实现百度网盘高速下载:Python解析工具实战指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse baidu-wangpan-parse是一款高效的Python工具,专门用于…...