用通俗的方法讲解:大模型微调训练详细说明(附理论+实践代码)
本文内容如下
-
介绍了大模型训练的微调方法,包括prompt tuning、prefix tuning、LoRA、p-tuning和AdaLoRA等。
-
介绍了使用deepspeed和LoRA进行大模型训练的相关代码。
-
给出了petals的介绍,它可以将模型划分为多个块,每个用户的机器负责其中一块,分摊了计算压力。
理解篇
prompt tuning
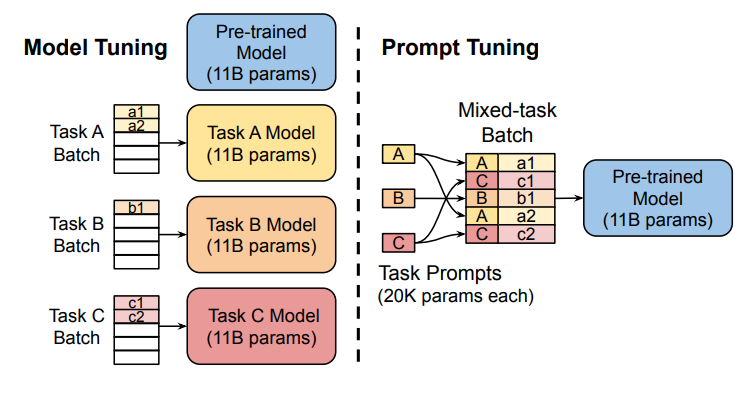
固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。左图为单任务全参数微调,右图为prompt tuning。
-
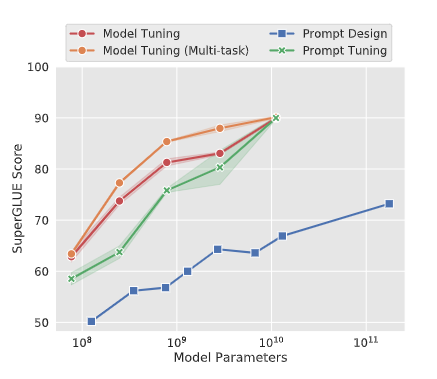
标准的T5模型(橙色线)多任务微调实现了强大的性能,但需要为每个任务存储单独的模型副本。
-
prompt tuning也会随着参数量增大而效果变好,同时使得单个冻结模型可重复使用于所有任务。
-
显著优于使用GPT-3进行fewshot prompt设计。
-
当参数达到100亿规模与全参数微调方式效果无异。
代码样例:
from peft import PromptTuningConfig, get_peft_model
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
prefix tuning
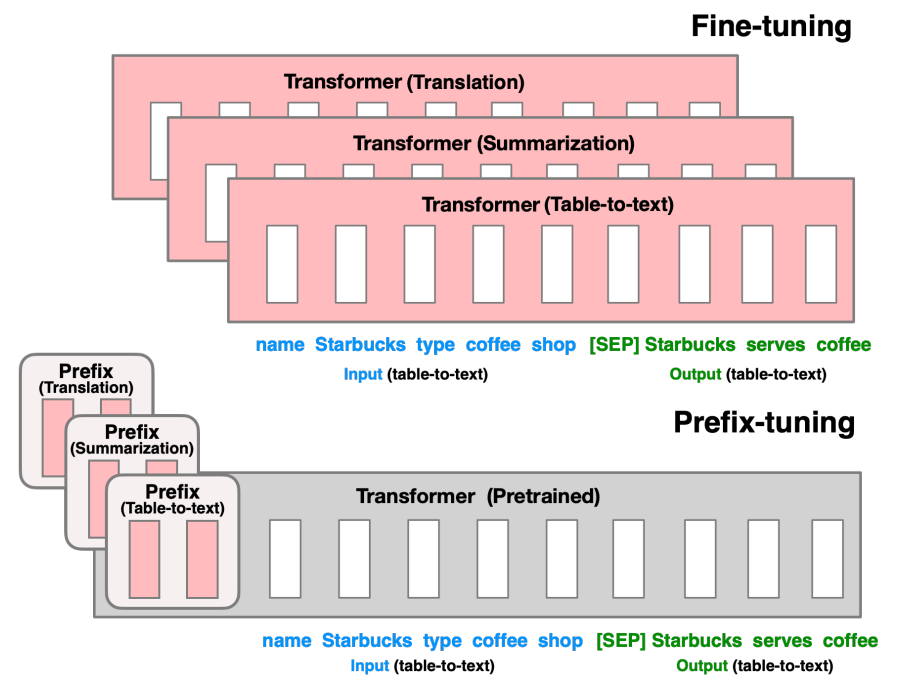
prefix tuning依然是固定预训练参数,但除为每一个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(torch.nn.Linear(token_dim, encoder_hidden_size),torch.nn.Tanh(),torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
在三个数据集中prefix和全参数微调的表现对比:

代码样例:
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
LoRA
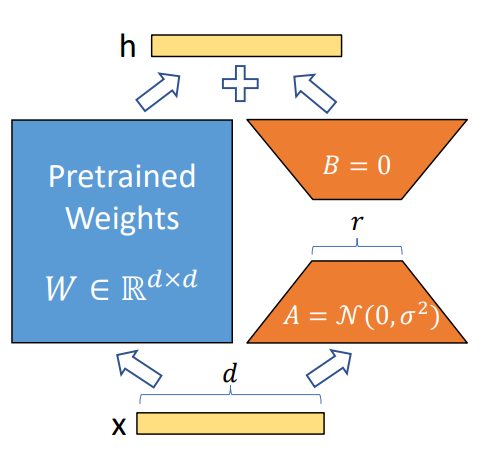
LoRA冻结了预训练模型的参数,并在每一层decoder中加入dropout+Linear+Conv1d额外的参数
那么,LoRA是否能达到全参数微调的性能呢?
根据实验可知,全参数微调要比LoRA方式好的多,但在低资源的情况下也不失为一种选择
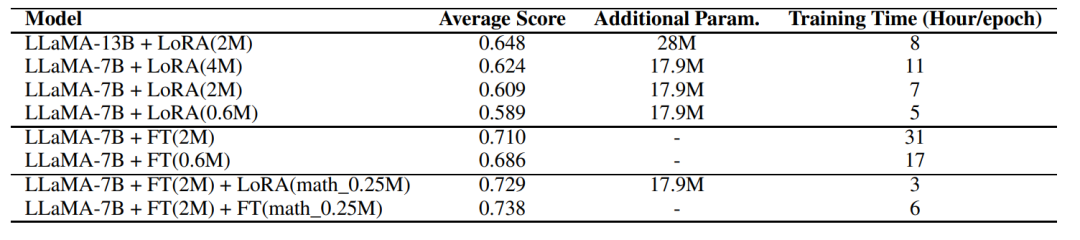
细致到每个任务中的差距如下图:
代码样例:
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
p-tuning
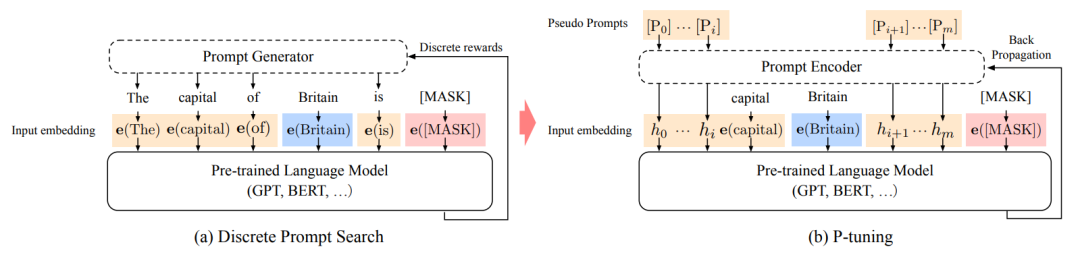
手动尝试最优的提示无异于大海捞针,于是便有了自动离散提示搜索的方法(作图),但提示是离散的,神经网络是连续的,所以寻找的最优提示可能是次优的。p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留prompt编码之后的向量即可,无需保留编码器。
self.lstm_head = torch.nn.LSTM(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=num_layers,dropout=lstm_dropout,bidirectional=True,batch_first=True,)self.mlp_head = torch.nn.Sequential(torch.nn.Linear(self.hidden_size * 2, self.hidden_size * 2),torch.nn.ReLU(),torch.nn.Linear(self.hidden_size * 2, self.output_size),
)
self.mlp_head(self.lstm_head(input_embeds)[0])
以上代码可清晰展示出prompt编码器的结构。
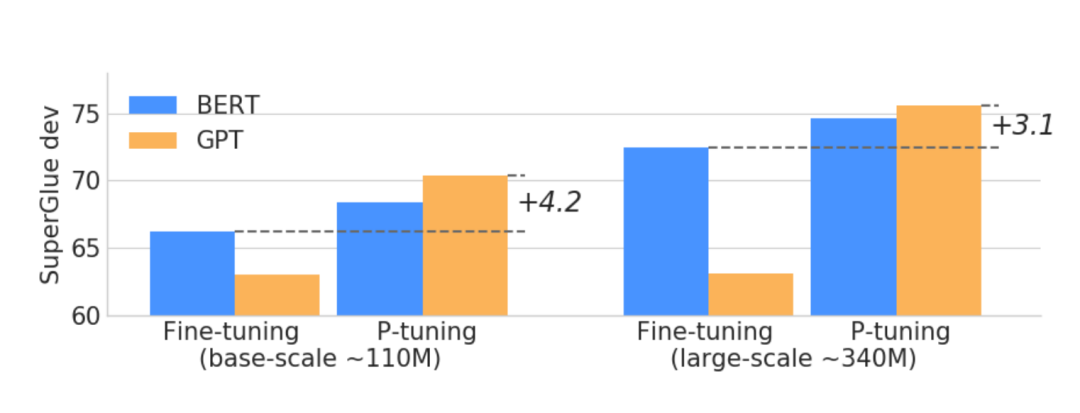
如上图所示,GPT在P-tuning的加持下可达到甚至超过BERT在NLU领域的性能。下图是细致的对比: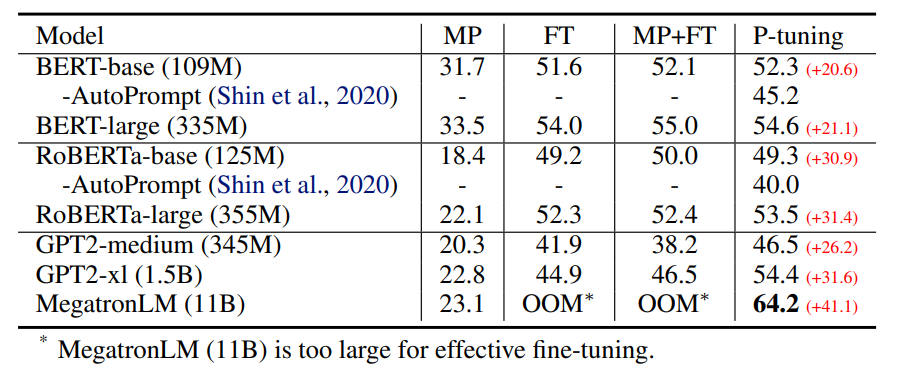
MP: Manual prompt
FT: Fine-tuning
MP+FT: Manual prompt augmented fine-tuning
PT: P-tuning
代码样例:
peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
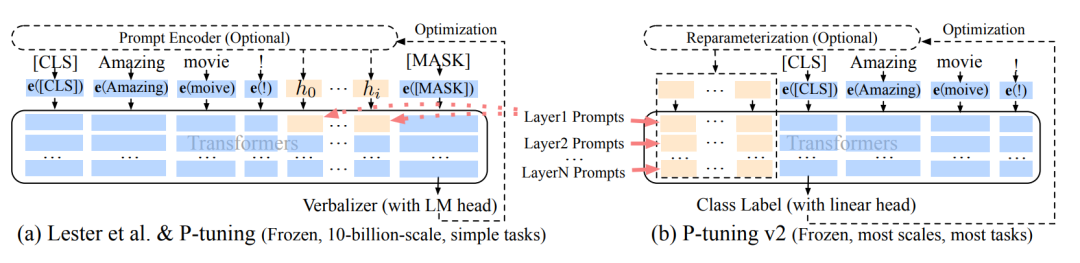
p-tuning v2
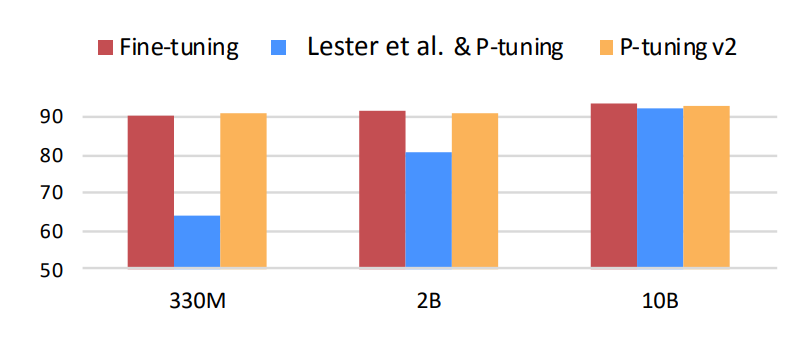
p-tuning的问题是在小参数量模型上表现差(如上图所示),于是有了V2版本,类似于LoRA每层都嵌入了新的参数(称之为Deep FT),下图中开源看到p-tuning v2 集合了多种微调方法。p-tuning v2 在多种任务上下进行微调,之后对于不同的任务如token classification与sentence classification添加了随机初始化的任务头(AutoModelForTokenClassification、AutoModelForSequenceClassification),而非使用自然语言的方式,可以说V2是集大成者。
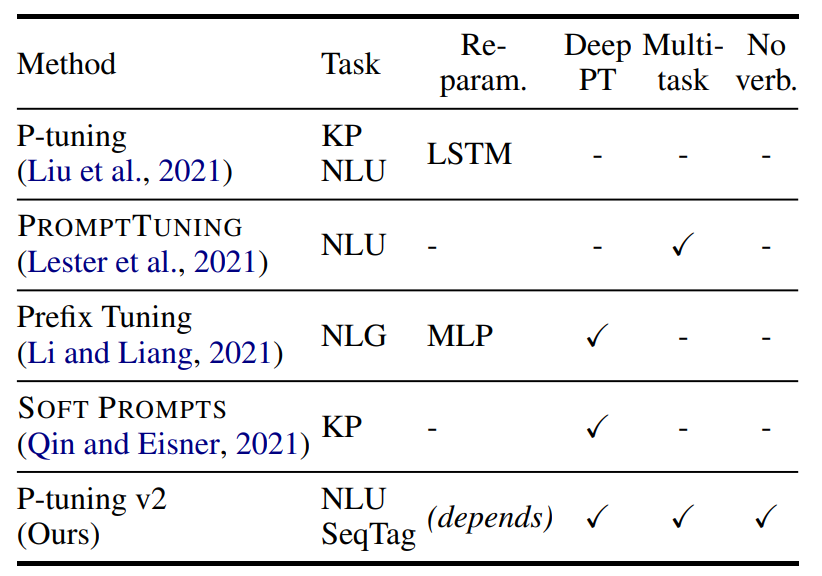
KP: Knowledge Probe,知识探针,用于检测LLM的世界知识掌握能力:https://github.com/facebookresearch/LAMA
SeqTag: Sequence Tagging,如抽取式问答、命名实体识别
Re-param.:Reparameterization,对提示词做单独的编码器
No verb.: No verbalizer,不直接使用LLM head而接一个随机初始化的linear head
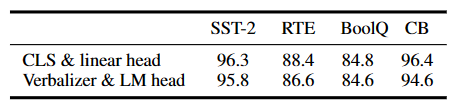
以下表格对比了[CLS] label linear head 和 verbalizer with LM head,[CLS] label linear head的方式药略好。
v1到v2的可视化:蓝色部分为参数冻结,橙色部分为可训练部分
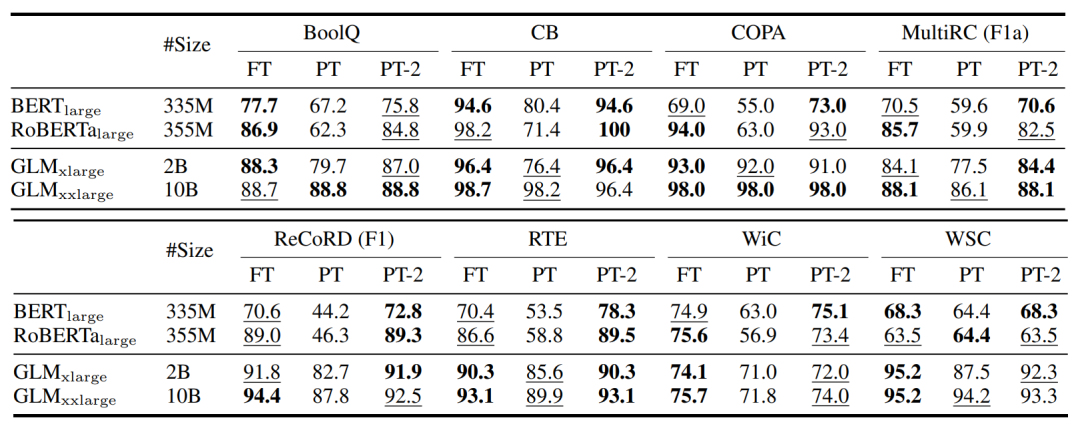
下图中对比了FT、PT、PT-2三种方法,粗体为性能最好的,下划线为性能次好的。
代码样例:
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
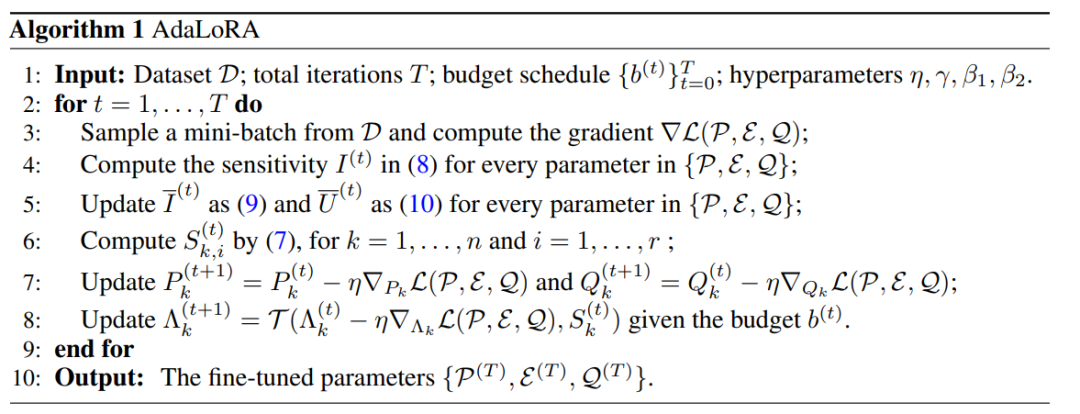
AdaLoRA
预训练语言模型中的不同权重参数对下游任务的贡献是不同的。因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。
具体来说,通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
详细的算法如下:
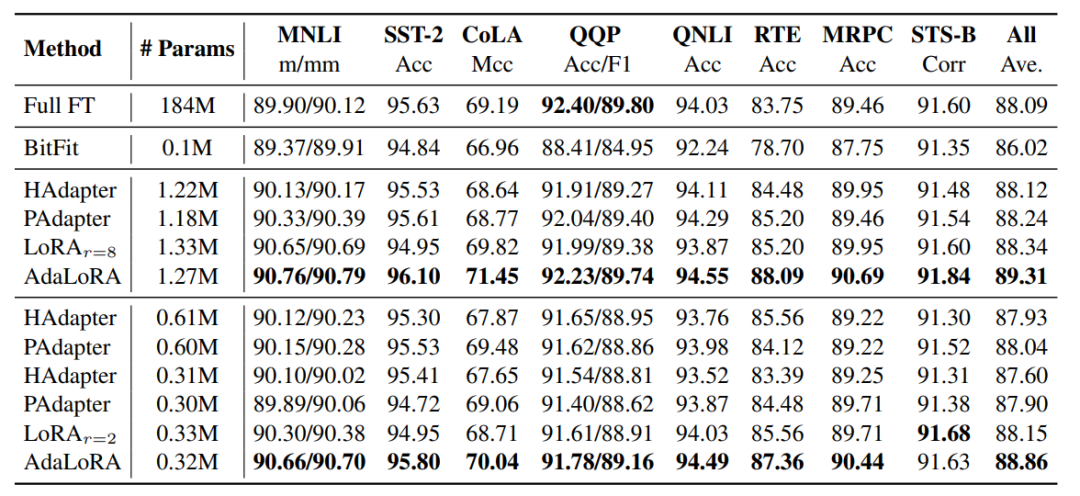
对比不同方法的性能:
代码样例:
peft_config = AdaLoraConfig(peft_type="ADALORA", task_type="SEQ_2_SEQ_LM", r=8, lora_alpha=32, target_modules=["q", "v"],lora_dropout=0.01)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
代码篇
注:以下代码在pytorch 1.12.1版本下运行,其他包都是最新版本
deepspeed
官方的demo所需要的配置如下:
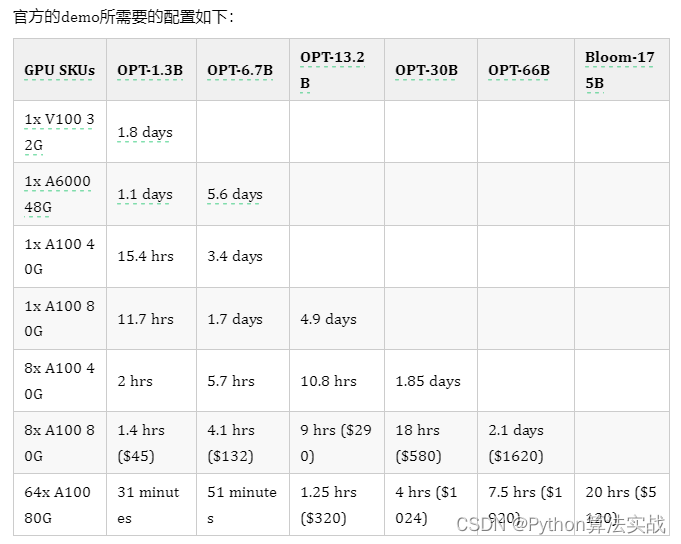
注意到官方给的样例单卡V100只能训练13亿规模的模型,如果换成67亿是否能跑起来呢?
按照官方文档搭建环境:
pip install deepspeed>=0.9.0git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
pip install -r requirements.txt
请注意如果你之前装了 deepspeed,请更新至0.9.0
试试全参数微调,这毫无疑问OOM
deepspeed --num_gpus 1 main.py \--data_path Dahoas/rm-static \--data_split 2,4,4 \--model_name_or_path facebook/opt-6.5b \--gradient_accumulation_steps 2 \--lora_dim 128 \--zero_stage 0 \--deepspeed \--output_dir $OUTPUT \&> $OUTPUT/training.log
答案是:我们需要卸载,这次便能愉快的run起来了
deepspeed main.py \--data_path Dahoas/rm-static \--data_split 2,4,4 \--model_name_or_path facebook/opt-6.7b \--per_device_train_batch_size 4 \--per_device_eval_batch_size 4 \--max_seq_len 512 \--learning_rate 9.65e-6 \--weight_decay 0.1 \--num_train_epochs 2 \--gradient_accumulation_steps 1 \--lr_scheduler_type cosine \--num_warmup_steps 0 \--seed 1234 \--lora_dim 128 \--gradient_checkpointing \--zero_stage 3 \--deepspeed \--output_dir $OUTPUT_PATH \&> $OUTPUT_PATH/training.log
可以加上LoRA
deepspeed --num_gpus 1 main.py \--data_path Dahoas/rm-static \--data_split 2,4,4 \--model_name_or_path facebook/opt-6.7b \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--max_seq_len 512 \--learning_rate 1e-3 \--weight_decay 0.1 \--num_train_epochs 2 \--gradient_accumulation_steps 16 \--lr_scheduler_type cosine \--num_warmup_steps 0 \--seed 1234 \--gradient_checkpointing \--zero_stage 0 \--lora_dim 128 \--lora_module_name decoder.layers. \--deepspeed \--output_dir $OUTPUT_PATH \&> $OUTPUT_PATH/training.logpeft
以下代码省略了数据处理
初始化
from datasets import load_dataset,load_from_disk
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,default_data_collator
from peft import prepare_model_for_int8_training, LoraConfig, get_peft_modelMICRO_BATCH_SIZE = 1
BATCH_SIZE = 1
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
EPOCHS = 3
LEARNING_RATE = 3e-6
CUTOFF_LEN = 256
LORA_R = 16
LORA_ALPHA = 32
LORA_DROPOUT = 0.05
模型加载,并使用int8进行训练
model_path = "facebook/opt-6.7b"
output_dir = "model"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, add_eos_token=True)
model = prepare_model_for_int8_training(model)
config = LoraConfig(r=LORA_R,lora_alpha=LORA_ALPHA,target_modules=None,lora_dropout=LORA_DROPOUT,bias="none",task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
tokenizer.pad_token_id = 0
data = load_from_disk("data")训练与保存
trainer = transformers.Trainer(model=model,train_dataset=data["train"],eval_dataset=data["validation"],args=transformers.TrainingArguments(per_device_train_batch_size=MICRO_BATCH_SIZE,per_device_eval_batch_size=MICRO_BATCH_SIZE,gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,warmup_steps=1000,num_train_epochs=EPOCHS,learning_rate=LEARNING_RATE,# bf16=True, fp16=True, logging_steps=1,output_dir=output_dir,save_total_limit=4,),data_collator=default_data_collator,
)
model.config.use_cache = False
trainer.train(resume_from_checkpoint=False)
model.save_pretrained(output_dir)
直接这么启动当然会OOM,依然需要卸载
编写accelerate配置文件accelerate.yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:gradient_accumulation_steps: 1gradient_clipping: 1.0offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: truezero3_save_16bit_model: truezero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'yes'
dynamo_backend: 'yes'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: fp16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
use_cpu: true
deepspeed配置文件:ds.json
{"fp16": {"enabled": true,"loss_scale": 0,"loss_scale_window": 500,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": 1e-8,"weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": 0,"warmup_max_lr": 2e-05,"warmup_num_steps": 0}},"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": false},"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 2e8,"contiguous_gradients": true},"gradient_accumulation_steps":2,"gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": 4,"train_micro_batch_size_per_gpu": 1,"wall_clock_breakdown": false
}启动
accelerate launch --dynamo_backend=nvfuser --config_file accelearte.yaml finetune.py
注:其他方法与Lora使用方法差距不大,不再赘述,在peft项目中均有代码样例。
顺便提一嘴:petals
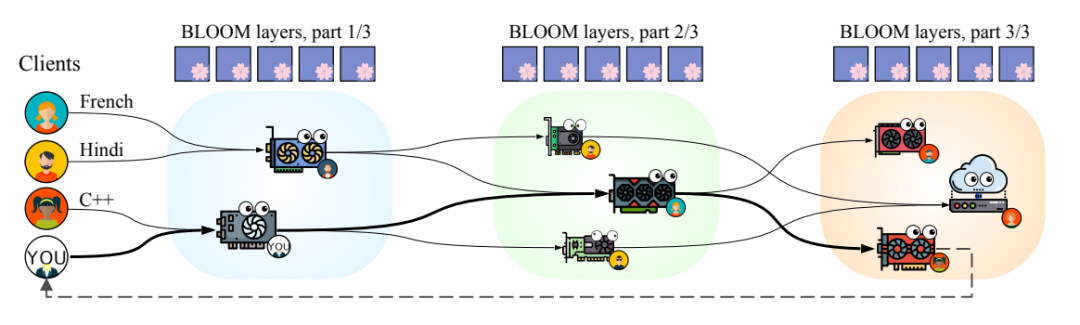
petals将模型划分为多个块,每个用户的机器负责其中一块,分摊了计算压力,类似于某磁力链接下载工具,利用hivemind库进行去中心化的训练与推理。当然你也可以创建自己局域网的群组,对自己独有的模型进行分块等自定义操作。
相关文章:
用通俗的方法讲解:大模型微调训练详细说明(附理论+实践代码)
本文内容如下 介绍了大模型训练的微调方法,包括prompt tuning、prefix tuning、LoRA、p-tuning和AdaLoRA等。 介绍了使用deepspeed和LoRA进行大模型训练的相关代码。 给出了petals的介绍,它可以将模型划分为多个块,每个用户的机器负责其中一…...

现代化工安全保障迎来巡查无人机新时代
当今现代化工企业呈现出规模不断扩大,设备逐渐趋向大型化的局面,由此导致化工安全生产面临日益严峻的挑战。然而,随着巡查无人机技术的成熟,这种新的高效手段正在提高化工安全检测的工作效率。 一、传统化工安全巡检存在弊端 化工…...

关于web前端通过js获取后端mysql数据库数据的一个方法
关于web前端通过js获取后端mysql数据库数据的一个方法 问题引入 关于html的教程很多,关于mysql的教程也很多,那么怎么让html展示mysql的数据呢? 一言以蔽之 前端通过js向后端发起一个http请求,后端响应这个请求并返回数据 实…...
如何下载IEEE出版社的Journal/Conference/Magazine的LaTeX/Word模板
当你准备撰写一篇学术论文或会议论文时,使用IEEE(电气和电子工程师协会)的LaTeX或Word模板是一种非常有效的方式,它可以帮助你确保你的文稿符合IEEE出版的要求。无论你是一名研究生生或一名资深学者,本教程将向你介绍如…...

京东数据运营-京东数据开放平台-鲸参谋10月粮油调味市场品牌店铺销售数据分析
鲸参谋监测的京东平台10月份料油调味市场销售数据已出炉! 根据鲸参谋数据显示,今年10月份,京东平台粮油调味市场的销量将近4600万,环比增长约10%,同比降低约20%;销售额将近19亿,环比增长约4%&am…...
ThermalLabel SDK for .NET 13.0.23.1113 Crack
ThermalLabel SDK for .NET 是一个 .NET 典型类库,它允许用户和开发人员创建非常创新的条码标签并将其发布在 zebra ZPL、EPL、EPSON ESC、POS 以及 Honeywell intermec 指纹中通过在 VB.NET 或 C# 上编写 .NET 纯代码来实现热敏打印机,以实现项目框架的…...

[Java学习日记]网络编程
目录 一.常见的软件架构、网络编程三要素、IP 二.利用UDP发送与接收数据 三.改聊天室 四.组播案例 五.TCP通信案例 一.常见的软件架构、网络编程三要素、IP 网络编程:在网络通信协议下,不同的计算机上运行的程序进行的数据传输 在Java中可以使用java…...

spring boot mybatis TypeHandler 看源码如何初始化及调用
目录 概述使用TypeHandler使用方式在 select | update | insert 中加入 配置文件中指定 源码分析配置文件指定Mapper 执行query如何转换 结束 概述 阅读此文 可以达到 spring boot mybatis TypeHandler 源码如何初始化及如何调用的。 spring boot 版本为 2.7.17,my…...
)
数据结构基础(带头节点的双向循环链表)
完整代码 DLinkList.hDLinkList.ctest.c DLinkList.h #pragma once #include <stdio.h> #include <stdlib.h> #include <assert.h>typedef int ElemType;// SList - 单链表 // DList - 双链表 // 带头节点的双向循环链表 - 最优链表结构,任意位置…...
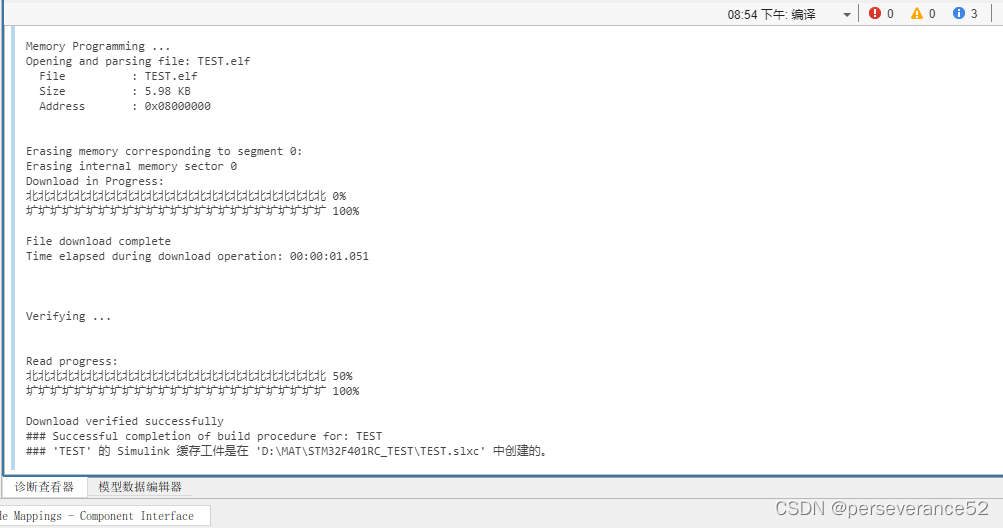
STM32CubeMx+MATLAB Simulink点灯程序
STM32CubeMxMATLAB点灯程序 ✨要想实现在MATLAB Simulink环境下使用STM32,前提是已经搭建好MATLAB环境并且安装了必要的Simulink插件,以及对应的STM32支持包。 🌿需要准备一块所安装支持包支持的STM32开发板. 🔖具体支持包详情页…...

【深度学习】gan网络原理生成对抗网络
【深度学习】gan网络原理生成对抗网络 GAN的基本思想源自博弈论你的二人零和博弈,由一个生成器和一个判别器构成,通过对抗学习的方式训练,目的是估测数据样本的潜在分布并生成新的数据样本。 1.下载数据并对数据进行规范 transform tran…...

springboot参数汇总
multipart multipart.enabled 开启上传支持(默认:true) multipart.file-size-threshold: 大于该值的文件会被写到磁盘上 multipart.location 上传文件存放位置 multipart.max-file-size最大文件大小 multipart.max-request-size 最大请求…...
【算法刷题】Day9
文章目录 611. 有效三角形的个数题干:题解:代码: LCR 179. 查找总价格为目标值的两个商品题干:题解:代码: 1137. 第 N 个泰波那契数题干:原理:1、状态表示(dp表里面的值所…...

LangChain的函数,工具和代理(三):LangChain中轻松实现OpenAI函数调用
在我之前写的两篇博客中:OpenAI的函数调用,LangChain的表达式语言(LCEL)中介绍了如何利用openai的api来实现函数调用功能,以及在langchain中如何实现openai的函数调用功能,在这两篇博客中,我们都需要手动去创建一个结构比较复杂的函数描述变量…...

WiFi概念介绍
WiFi概念介绍 1. 什么是WLAN2. 什么是Wi-Fi3. Wi-Fi联盟4. WLAN定义范围5. WiFi协议体系6. 协议架构7. WiFi技术的发展7.1 IEEE802.117.2 802.11标准和补充 8. 术语 1. 什么是WLAN Wireless Local Area Network,采用802.11无线技术进行互连的一组计算机和相关设备。…...
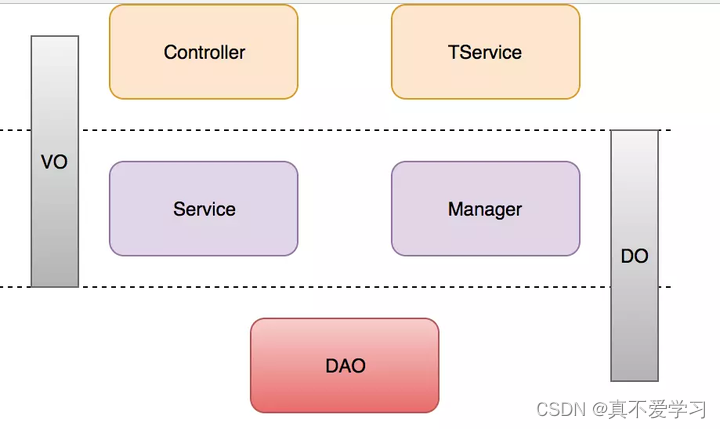
如何优雅的进行业务分层
1.什么是应用分层 说起应用分层,大部分人都会认为这个不是很简单嘛 就controller,service, mapper三层。 看起来简单,很多人其实并没有把他们职责划分开,在很多代码中,controller做的逻辑比service还多,service往往当…...

C++的std命名空间
总以为自己懂了,可是仔细想想,多问自己几个问题,发现好像又不是很清楚 命名空间(Namespace)是C中一种用于解决命名冲突问题的机制,它能够将全局作用域划分为若干个不同的区域,每个区域内可以有…...

unity学习笔记
一、射线检测 如何让鼠标点击某个位置,游戏角色就能移动到该位置? 实现的原理分析:我们能看见游戏的东西就是摄像机拍摄到的东西,所以摄像机的镜平面就是当前能看到的了。 那接下来我们可以让摄像机发射一条射线,鼠标…...

使用SpringBoot和ZXing实现二维码生成与解析
一、ZXing简介 ZXing是一个开源的,用Java实现的多种格式的1D/2D条码图像处理库。它包含了用于解析多种格式的1D/2D条形码的工具类,目标是能够对QR编码,Data Matrix, UPC的1D条形码进行解码。在二维码编制上,ZXing巧妙地利用构成计…...
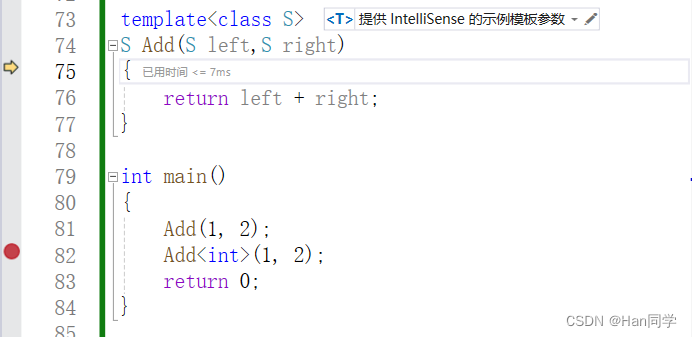
C++模板—函数模板、类模板
目录 一、函数模板 1、概念 2、格式 3、实例化 4、模板参数的匹配 二、类模板 1、定义格式 2、实例化 交换两个变量的值,针对不同类型,我们可以使用函数重载实现。 void Swap(double& left, double& right) {double tmp left;left ri…...

Linux 硬盘分区管理
Linux 硬盘分区管理 摘要:本文系统介绍了 Linux 硬盘分区管理的核心概念与实用工具。首先阐述了硬盘分区的必要性,包括数据隔离、分类整理、降低风险等。随后详细对比了 MBR(主引导记录)和 GPT(GUID 分区表)…...
)
毕业设计 深度学习车道线检测(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 YOLOV56 数据集处理7 模型训练8 最后 0 前言 🔥这两年开始毕业设计和毕业答辩的要求和难度不断…...
)
为什么你的ElevenLabs四川话输出总像“普通话+口音”?3步声学特征解耦法让韵律自然度提升2.8倍(附Python声谱可视化代码)
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs四川话输出总像“普通话口音”? ElevenLabs 当前并未提供原生四川话(西南官话成渝片)语音模型,其所谓“方言支持”实为在标准普通话…...

3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南
3步让PS手柄在Windows上完美运行:DS4Windows终极配置指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾为心爱的PlayStation手柄在Windows电脑上无法被游戏识别而烦…...

股票打分制方法论
人工列提纲做评审,AI丰富内容AI模型:Deepseek仅供参考,市场有风险,投资需谨慎打分制股票算法:构建系统化、多维度的股票评估体系在股票投资领域,面对纷繁复杂的市场信息和海量数据,如何科学、客…...

30天学会AI工程师|Day 13:Tool Calling 不是高级玩法,它是 Agent 开始有手脚的那一步
你先知道一件事 很多人第一次听到 Tool Calling,会觉得这是很后面的内容,好像得先学完模型、Prompt、框架,再轮到它。 为什么这一步重要 其实从工程视角看,它反而是一个很早就该理解的能力。 因为大模型只会“生成文本”这件事&am…...
一键脚本 + 完整配置)
OpenClaw 3 机集群(Windows + Linux 混合)一键脚本 + 完整配置
集群架构规划(1 主 2 从)统一安装脚本(Windows PowerShell / Linux bash)主节点配置(gateway 调度)从节点配置(worker 注册到主)集群通信、端口、令牌、存储一键启停、扩容、状态检…...

为什么我强烈推荐大学生打CTF!看完你就懂了!
前言 写这个文章是因为我很多粉丝都是学生,经常有人问: 感觉大一第一个学期忙忙碌碌的过去了,啥都会一点,但是自己很难系统的学习到整个知识体系,很迷茫,想知道要如何高效学习。 这篇文章我主要就围绕两点…...

打印机驱动程序无法使用?原因+修复方法全攻略
日常办公、学习打印时,最让人崩溃的莫过于打印机突然报错,弹出 “打印机驱动程序无法使用”“驱动异常”“驱动失效” 等提示,任凭怎么操作都无法打印。作为连接电脑与打印机的核心桥梁,驱动程序一旦故障,打印机就会彻…...

如何快速掌握uesave:Unreal引擎存档编辑的完整指南
如何快速掌握uesave:Unreal引擎存档编辑的完整指南 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave uesave是一款专门用于处理Unreal引擎游戏存档文件的开源…...