kafka 集群 ZooKeeper 模式搭建
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序
Kafka 官网:Apache Kafka
关于ZooKeeper的弃用
根据 Kafka官网信息,随着Apache Kafka 3.5版本的发布,Zookeeper现已被标记为已弃用。未来计划在Apache Kafka(4.0版)的下一个主要版本中删除ZooKeeper,该版本最快将于2024年4月发布。在弃用阶段,ZooKeeper仍然支持用于Kafka集群元数据的管理,但不建议用于新的部署。新的部署方式使用 KRaft 模式,KRaft 模式部署可以看笔者的文章《kafka 集群 KRaft 模式搭建》,考虑到一些公司仍然在使用老版本的 Kafka,故笔者写这篇文章记录 Kafka 集群Zookeeper 模式搭建
官网信息截图

笔者使用3台服务器,它们的 ip 分别是 192.168.3.232、192.168.2.90、192.168.2.11
目录
1、官网下载 Kafka
2、配置 Kafka
3、启动 Kafka 集群
4、关闭 Kafka 集群
5、使用Kafka 可视化工具查看
6、测试Kafka集群
1、官网下载 Kafka
这里笔者下载最新版3.6.0
3.6.0 版本需要至少 java8 及以上版本,笔者使用的是 java8 版本
关于 linux 安装 java,没安装过的朋友可以参考《linux 系统安装 jdk》
下载完成
将 kafka分别上传到3台linux

在3台服务器上分别创建 kafka 安装目录
mkdir /usr/local/kafka在3台服务器上分别将 kafka 安装包解压到新创建的 kafka 目录
tar -xzf kafka_2.13-3.6.0.tgz -C /usr/local/kafka2、配置 Kafka
进入配置目录
cd /usr/local/kafka/kafka_2.13-3.6.0/config
编辑配置文件 server.properties
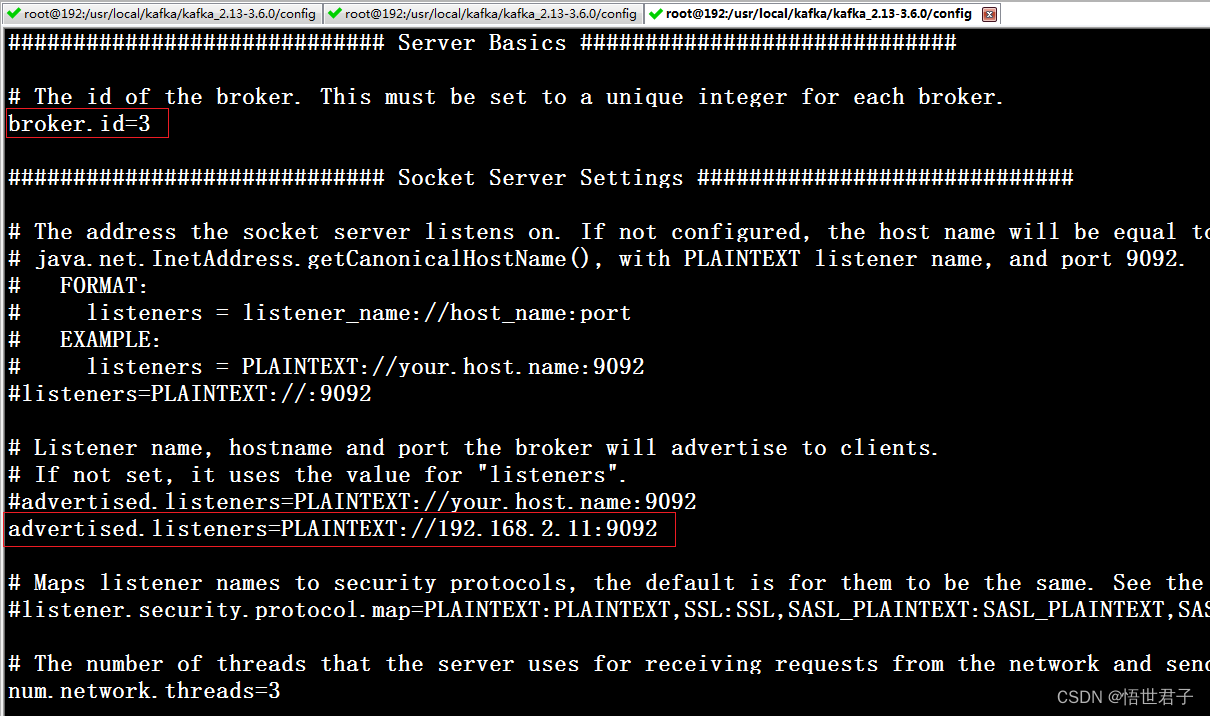
vi server.properties配置 broker.id,advertised.listeners,zookeeper.connect
broker.id 每个节点的id
advertised.listeners 本机的外网访问地址
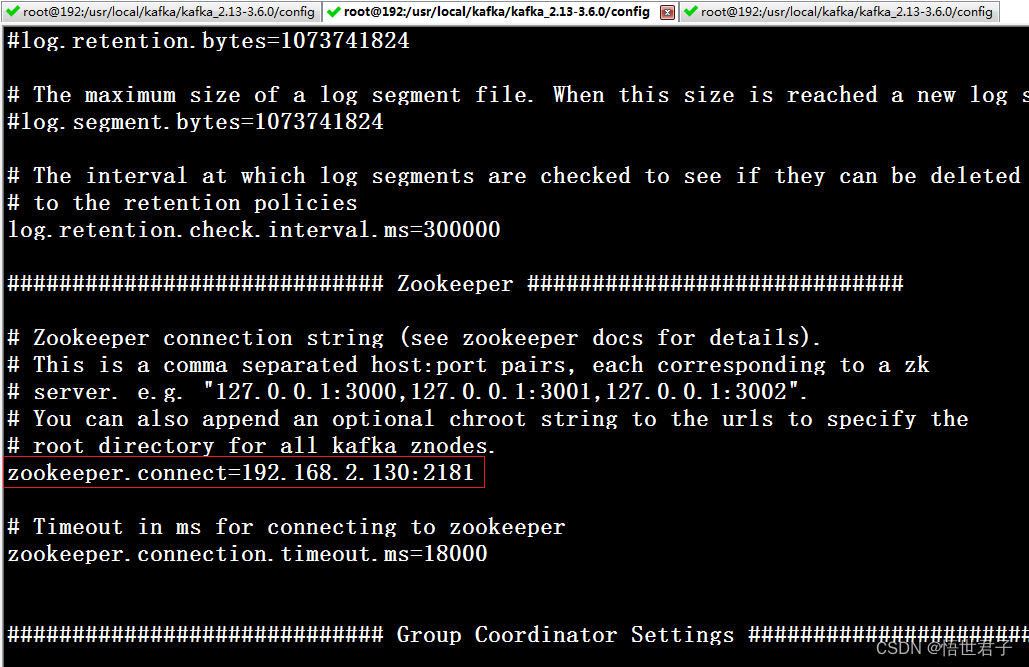
zookeeper.connect zookeeper 地址
192.168.3.232 节点配置
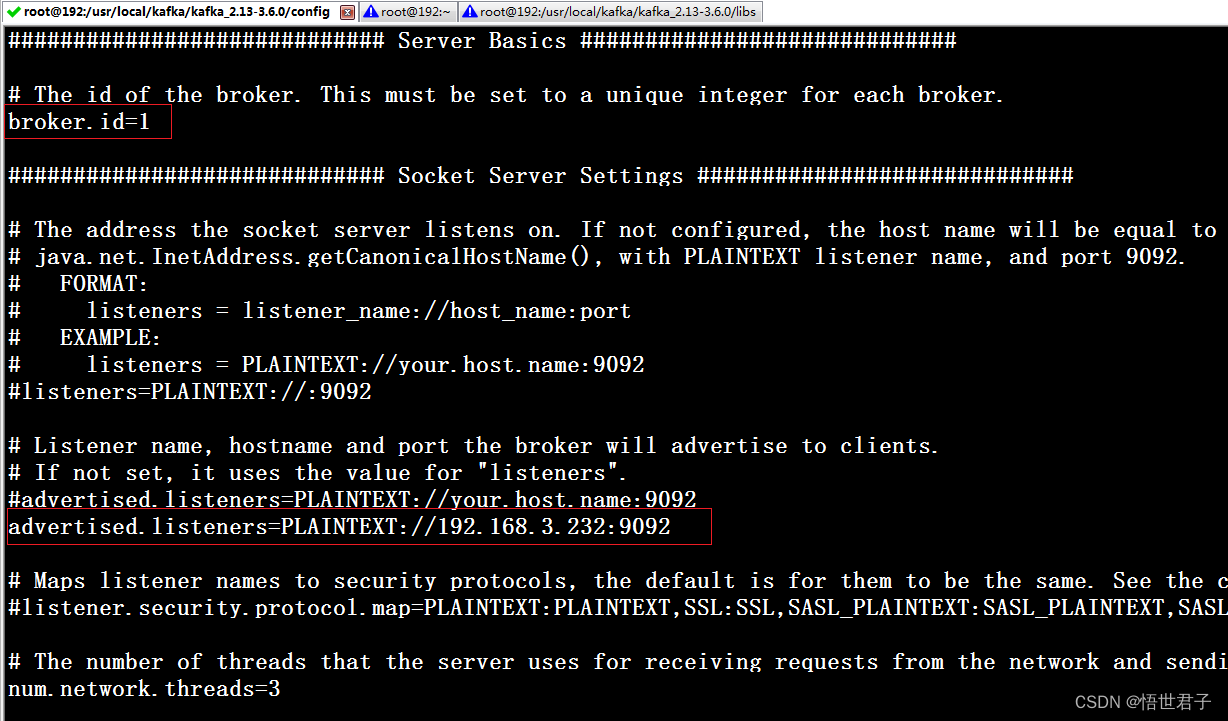
advertised.listeners 笔者配置为本机地址
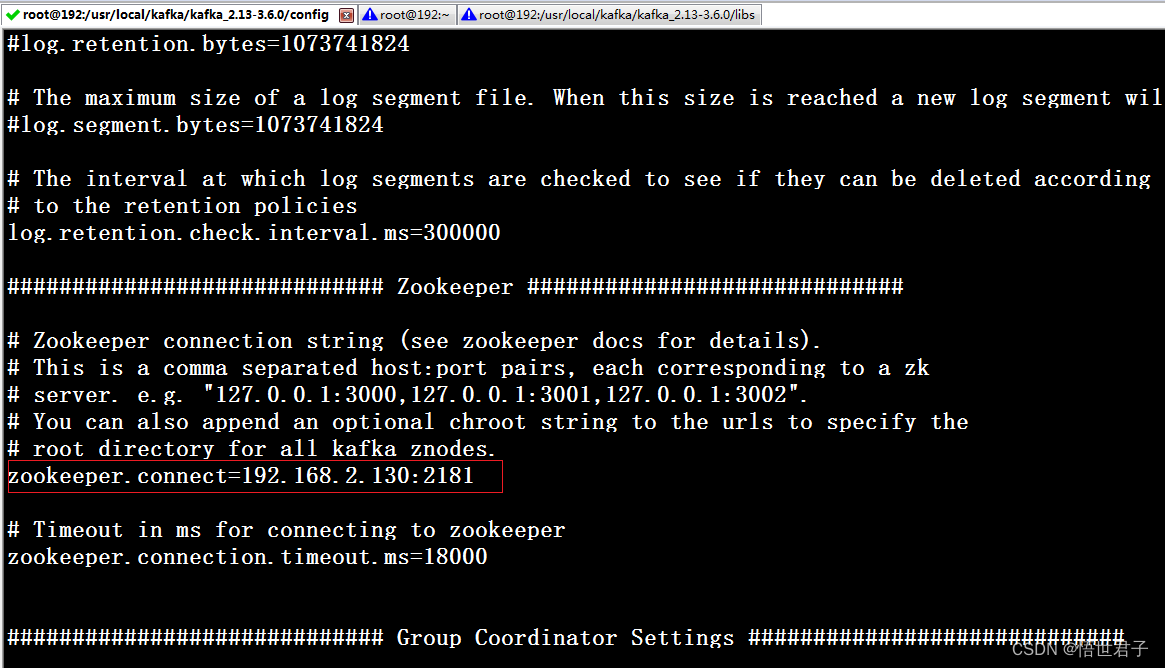
192.168.2.90 节点
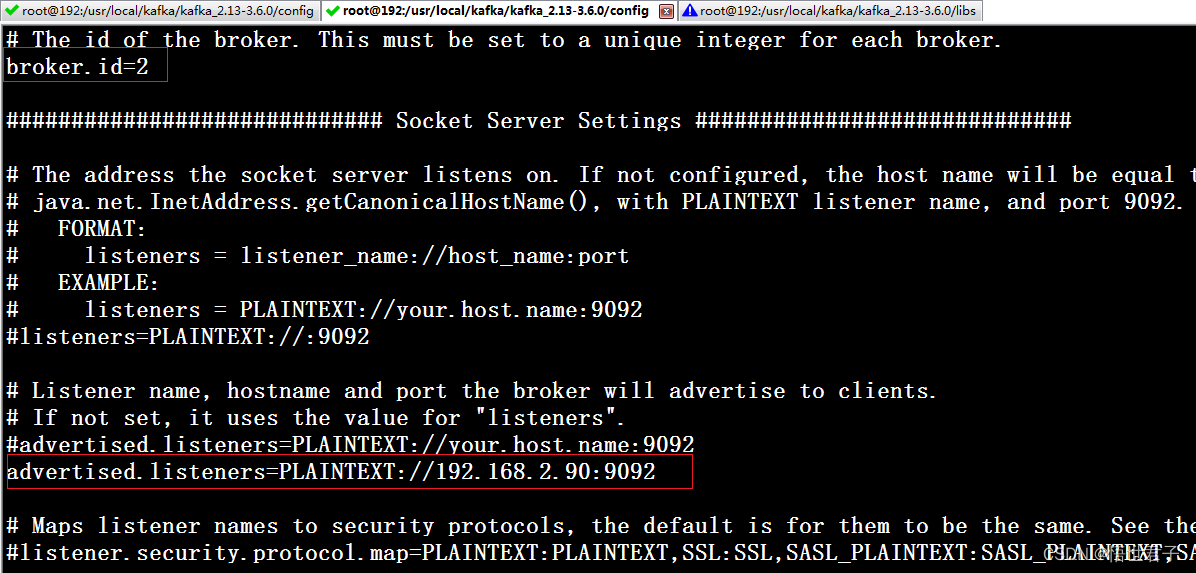
192.168.2.11 节点
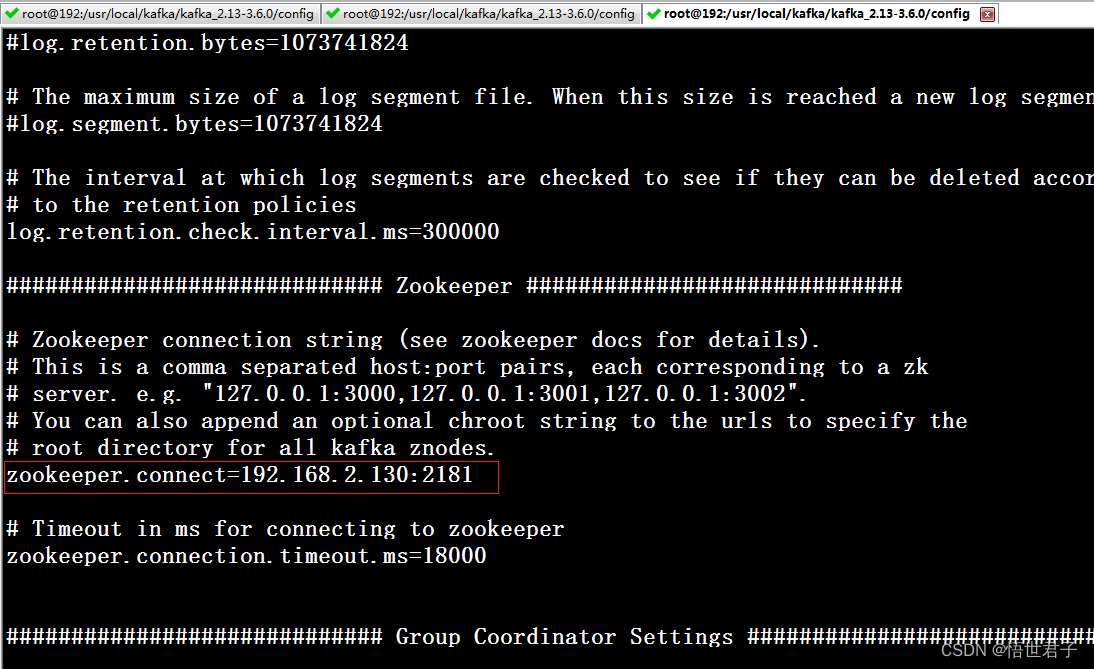
笔者zookeeper 地址是 192.168.2.130:2181
zookeeper 版本是3.8.3
关于zookeeper单机安装和集群安装可以参考:《Linux环境 安装 zookeeper》《windows环境 安装 zookeeper》《linux 使用 nginx 搭建 zookeeper 集群》
3、启动 Kafka 集群
首先启动 zookeeper
然后在3台机器上依次启动 Kafka
进入 kafka 目录
cd /usr/local/kafka/kafka_2.13-3.6.0下面2个命令皆可
bin/kafka-server-start.sh config/server.properties或
bin/kafka-server-start.sh -daemon config/server.properties
4、关闭 Kafka 集群
关闭命令
bin/kafka-server-stop.sh在 3 个节点上分别执行关闭命令
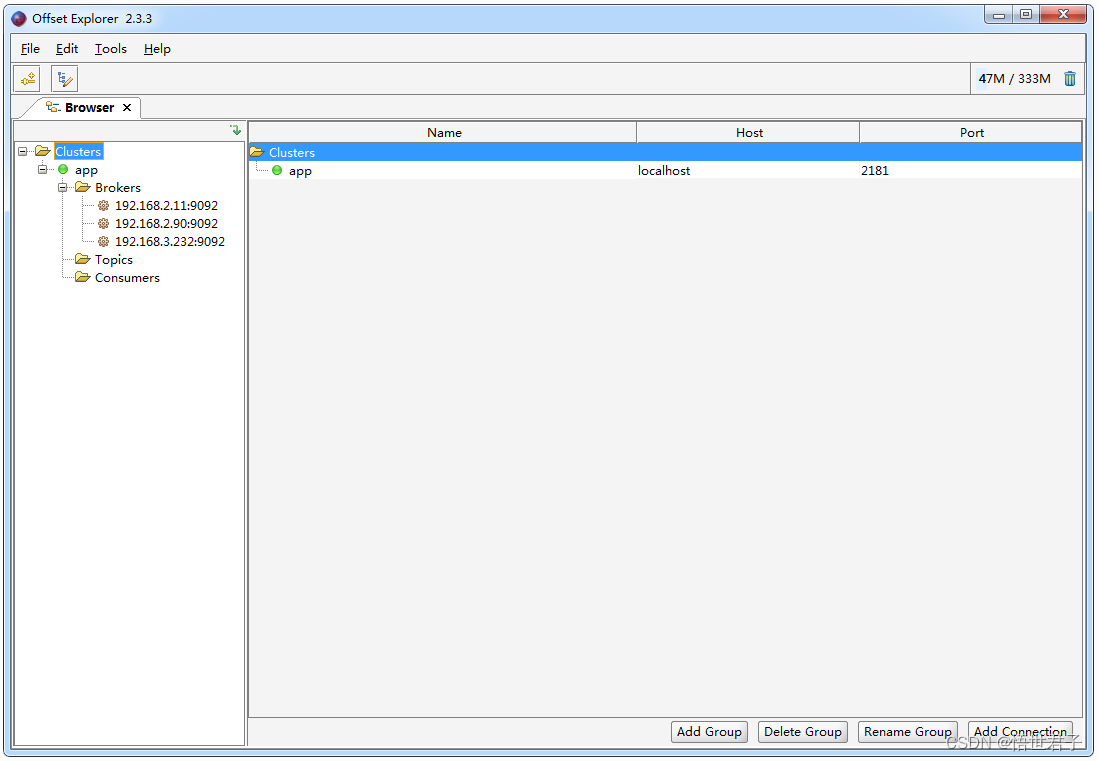
5、使用Kafka 可视化工具查看
下载地址:https://www.kafkatool.com/download.html
运行效果
6、测试Kafka集群
新建 maven 项目,添加 Kafka 依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.6.0</version>
</dependency>笔者新建 maven项目 kafka-learn
kafka-learn 项目 pom 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.wsjzzcbq</groupId><artifactId>kafka-learn</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.6.0</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><configuration><source>11</source><target>11</target></configuration></plugin></plugins></build>
</project>新建生产者 ProducerDemo
package com.wsjzzcbq;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;/*** Demo** @author wsjz* @date 2023/11/24*/
public class ProducerDemo {public static void main(String[] args) throws ExecutionException, InterruptedException {Properties properties = new Properties();//配置集群节点信息properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.232:9092,192.168.2.90:9092,192.168.2.11:9092");//配置序列化properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());Producer<String, String> producer = new KafkaProducer<>(properties);//topic 名称是demo_topicProducerRecord<String, String> producerRecord = new ProducerRecord<>("demo_topic", "明月别枝惊鹊");RecordMetadata recordMetadata = producer.send(producerRecord).get();System.out.println(recordMetadata.topic());System.out.println(recordMetadata.partition());System.out.println(recordMetadata.offset());}
}新建消费者 ConsumerDemo
package com.wsjzzcbq;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;/*** ConsumerDemo** @author wsjz* @date 2023/11/24*/
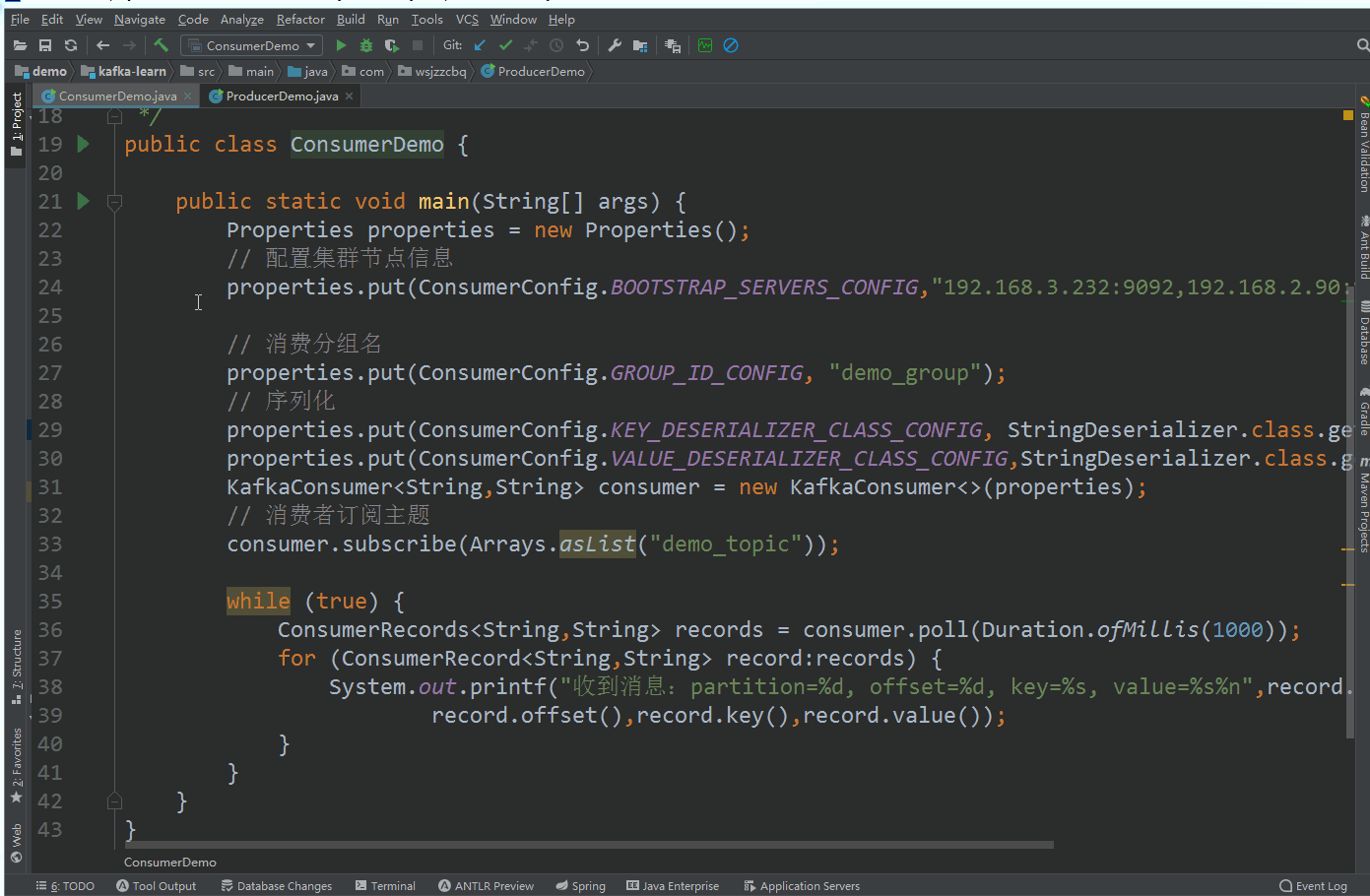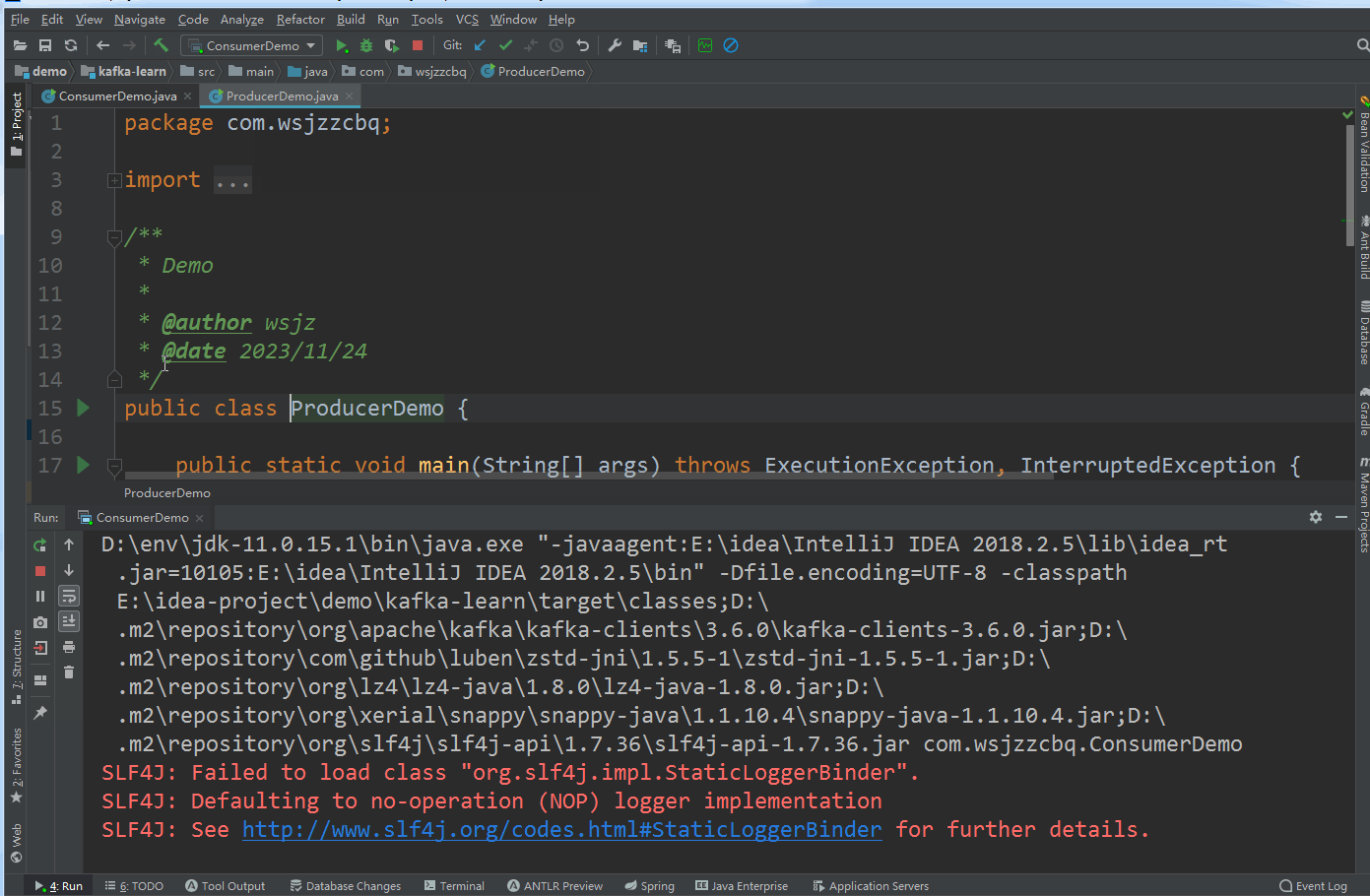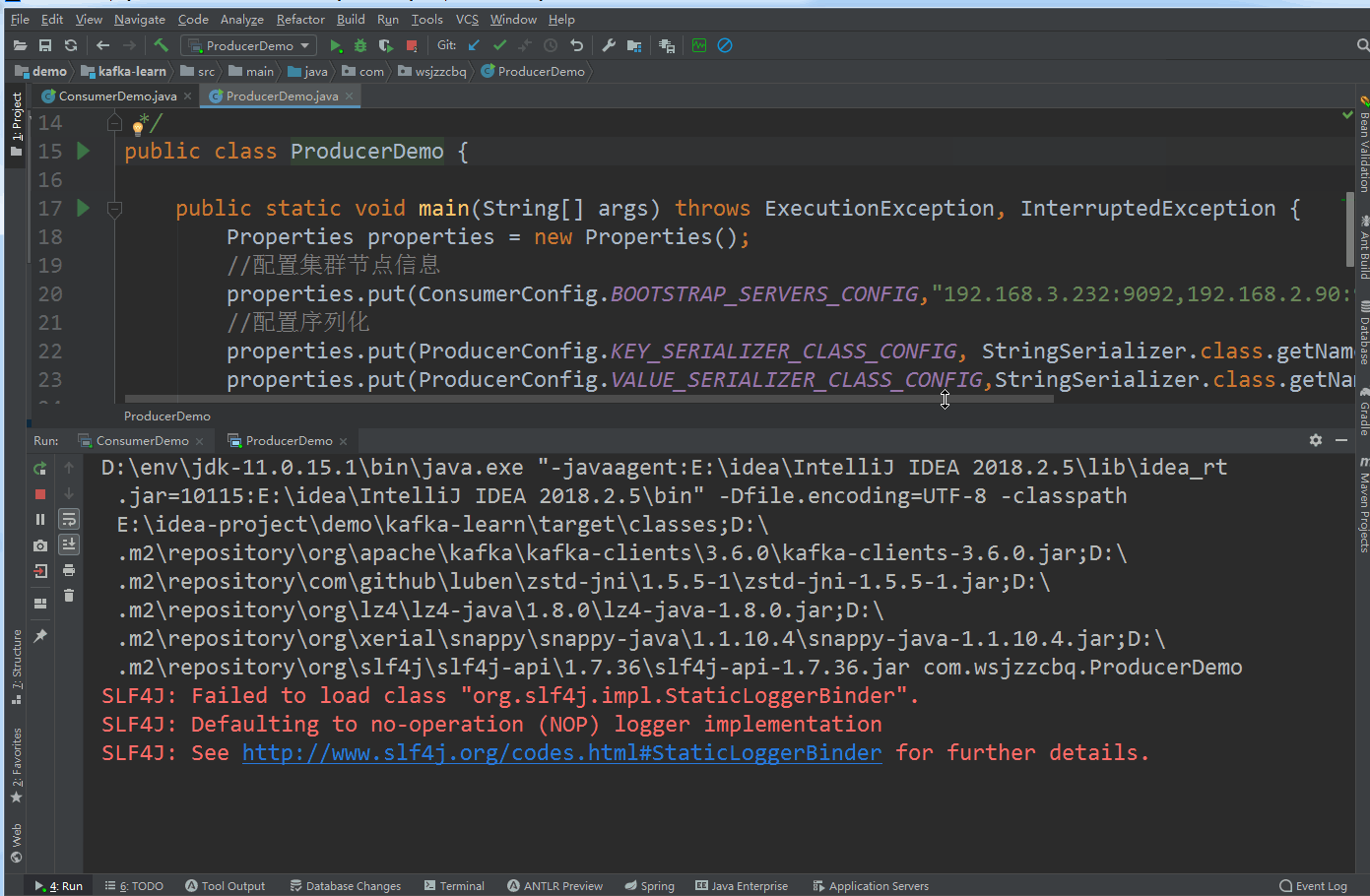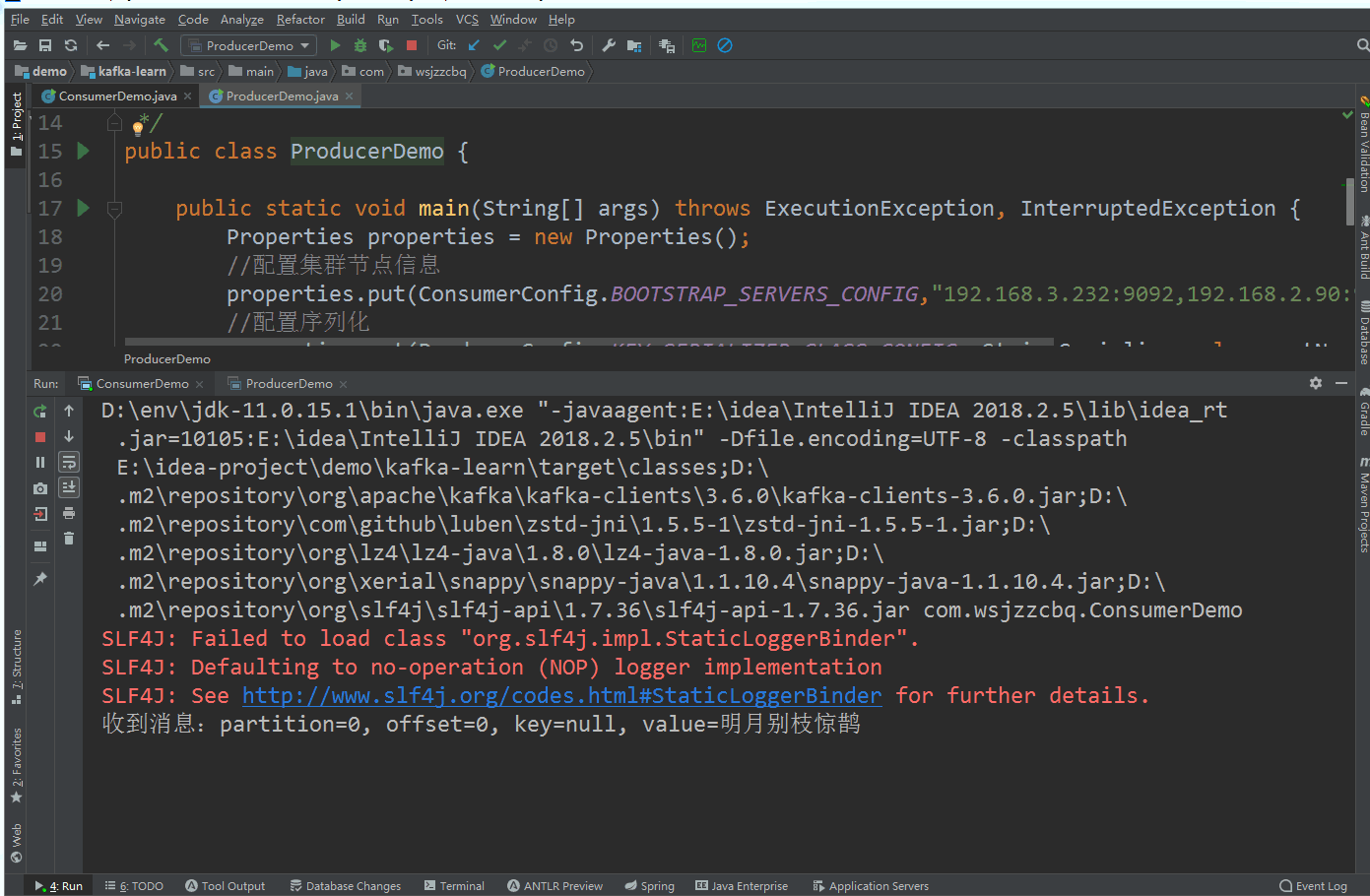
public class ConsumerDemo {public static void main(String[] args) {Properties properties = new Properties();// 配置集群节点信息properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.232:9092,192.168.2.90:9092,192.168.2.11:9092");// 消费分组名properties.put(ConsumerConfig.GROUP_ID_CONFIG, "demo_group");// 序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);// 消费者订阅主题consumer.subscribe(Arrays.asList("demo_topic"));while (true) {ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String,String> record:records) {System.out.printf("收到消息:partition=%d, offset=%d, key=%s, value=%s%n",record.partition(),record.offset(),record.key(),record.value());}}}
}运行测试
效果图
至此完
相关文章:
kafka 集群 ZooKeeper 模式搭建
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序 Kafka 官网:Apache Kafka 关于ZooKeeper的弃用 根据 Kafka官网信息,随着Apache Kafka 3.5版本的发布,Zookeeper现…...
【LeetCode】 160. 相交链表
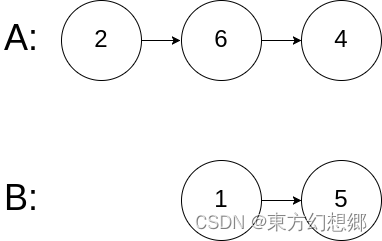
相交链表 题目题解 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意&am…...

TZOJ 1429 小明A+B
答案: #include <stdio.h> int main() {int T0, A0, B0, sum0;scanf("%d", &T); //输入测试数据的组数while (T--) //循环T次{scanf("%d %d", &A, &B); //输入AB的值sum A B;if (sum > 100) //如果是三位数{…...

制作openeuler的livecd
下载该项目,执行下面的操作gitee openeuler livecd项目 基于openeuler环境 #安装工具,第一次可能报错,可以再执行一次 make installx86 livecd-creator -d -v --config./config/euler_x86_64.ks --fslabeleuler-LiveCD --cachecache --log…...

B.牛牛排队伍——模拟双链表
当前位置: 首页 > news >正文 B.牛牛排队伍——模拟双链表 news 2023/12/1 15:14:37 分析 题目其实很简单,就是双链表的增删查,但是刚开始,直接vis标记删除元素,查找一个位置的前一个用的while不断向前找,但是TLE;毕竟O(n*k)的复杂度,一开始没有考虑时间复杂度…...
损失函数与优化器)
【PyTorch】(四)损失函数与优化器
文章目录 1. 损失函数2. 优化器 1. 损失函数 2. 优化器...
执行insert之后没有插入数据)
【Python】使用execute(sql)执行insert之后没有插入数据
在sql为insert语句,用Python的sqlalchemy模块中的execute()执行之后没有插入数据的情况,主要是因为sqlalchemy版本的更新,不能直接只用execute()了,MySQL数据库连接的配置和sql都需要多处理一步: 之前的版本ÿ…...
虚拟机备份数据自动化验证原理
备份数据成功备份下来了,但是备份数据是否可用可靠?对于这个问题,最好最可靠的方法是将备份数据实际恢复出来验证。 但是这样的方法,不仅费时费力,而且需要随着备份数据的定期产生,还应当定期做备份数据验…...
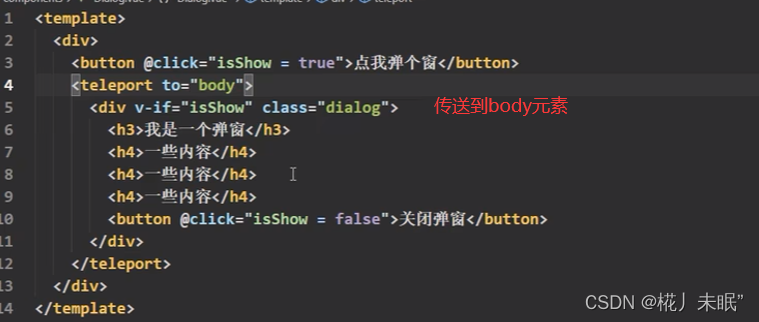
前端入门(五)Vue3组合式API特性
文章目录 Vue3简介创建Vue3工程使用vite创建vue-cli方式 常用 Composition API启动项 - setup()setup的执行时机与参数 响应式原理vue2中的响应式vue3中的响应式ref函数reactive函数reactive与ref对比 计算属性 - computed监视属性 - watchwatchEffect Vue3生命周期自定义hook函…...

Doris 数据导入二:Stream Load 方式
Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。 1 适用场景 Stream load 主要适用于导入本地文件,或通过程序导入数据流中…...
【算法刷题】Day10
文章目录 15. 三数之和题干:算法原理:1、排序 暴力枚举 利用set 去重2、排序 双指针 代码: 18. 18. 四数之和题干:算法原理:1、排序 暴力枚举 利用set 去重2、排序 双指针 代码: 15. 三数之和 原题链…...
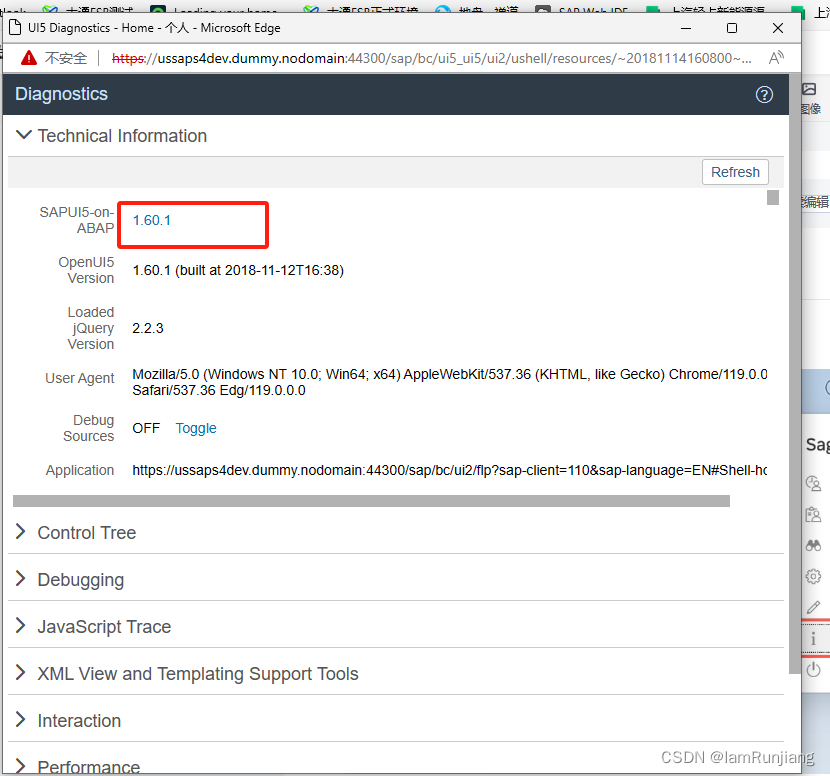
SAP 如何检查已安装的SAP UI5 版本
第一个方法是直接从FLP中查看 但是部分高版本的FLP中没有这个about, 那么在当前界面可以使用:CTRL ALT SHIFT S 查看当前版本 根据此版本,去进行你的UI5的开发吧...
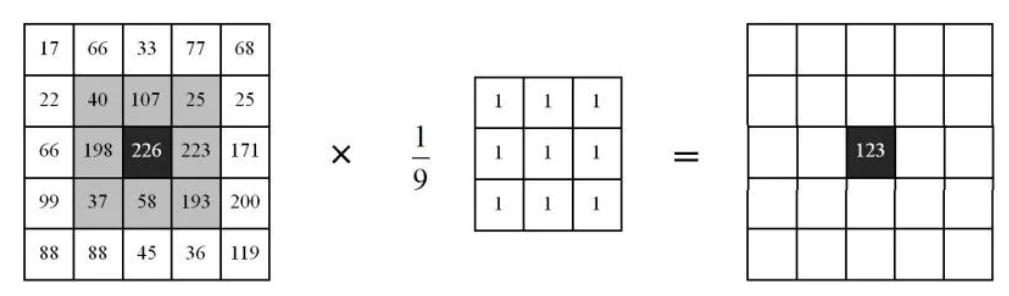
15、 深度学习之正向传播和反向传播
上一节介绍了训练和推理的概念,这一节接着训练和推理的概念讲一下,神经网络的正向传播和反向传播。 其实单看正向传播和反向传播这两个概念,很好理解。 正向传播(Forward Propagation)是指从输入层到输出层的数据流动过程,而反向传播(Backpropagation)是指数据从输出…...

微信小程序中复制文本
在微信小程序中,可以使用wx.setClipboardData()方法来实现复制文本内容的功能。以下是一个示例代码: // 点击按钮触发复制事件 copyText: function() {var that this;wx.setClipboardData({data: 要复制的文本内容,success: function(res) {wx.showToa…...
vue3学习--初始
...
cmake和vscode 下的cmake的使用详解(二)
第四讲: GDB 调试器 前言: GDB(GNU Debugger) 是一个用来 调试 C/C 程序 的功能强大的 调试器 ,是 Linux 系统开发 C/C 最常用的调试器 程序员可以 使用 GDB 来跟踪程序中的错误 ,从而减少程序员的工作量。 Linux 开发 C/C …...

集成开发环境 PyCharm 的安装【侯小啾python领航班系列(二)】
集成开发环境PyCharm的安装【侯小啾python领航计划系列(二)】 大家好,我是博主侯小啾, 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹…...
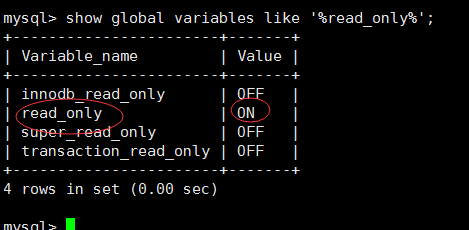
mysql从库设置为只读
直奔主题,mysql设置为只读后,无法增删改。 设置命令: mysql> set global read_only1; #1是只读,0是读写 mysql> show global variables like %read_only%; 以下是相关说明: 1、对于数据库读写状态…...
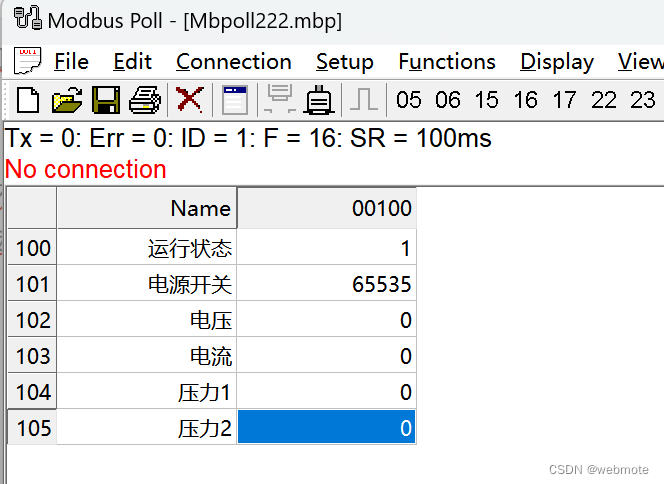
.NET6实现破解Modbus poll点表配置文件
📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!📢本文作者:由webmote 原创📢作者格言:新的征程,我们面对的不仅仅是技术还有人心,人心不可测,海水不可量,唯有技术,才是深沉黑夜中的一座闪烁的灯塔 !序言 Modbus 协议是工控领域常见…...

【零基础入门Docker】Dockerfile中的USER指令以及dockerfile命令详解
✍面向读者:所有人 ✍所属专栏:Docker零基础入门专栏 目录 第 1 步:创建 Dockerfile 第 2 步:构建 Docker 镜像 第 3 步:运行 Docker 容器 第 4 步:验证输出 dockerfile命令详解 最佳实践 默认情况下…...

免费开源AMD Ryzen调试工具SMUDebugTool:释放处理器性能的终极指南
免费开源AMD Ryzen调试工具SMUDebugTool:释放处理器性能的终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

JetBrains IDE试用期重置终极指南:轻松解决IDE过期问题
JetBrains IDE试用期重置终极指南:轻松解决IDE过期问题 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经遇到过这样的困扰:正在专注编码时,突然弹出的"试用期已结…...

Themes 与 Styles
Themes 与 Styles 主题目录:Source/Themes项目说明H.Theme主题核心。H.Themes.Colors.Accent强调色。H.Themes.Colors.Blue蓝色。H.Themes.Colors.Copper铜色/复古。H.Themes.Colors.Gray灰色。H.Themes.Colors.Industrial工业风。H.Themes.Colors.Mineral矿物色。H…...

Robo 3T:原生跨平台MongoDB管理工具的架构解析与技术实践
Robo 3T:原生跨平台MongoDB管理工具的架构解析与技术实践 【免费下载链接】robomongo Native cross-platform MongoDB management tool 项目地址: https://gitcode.com/gh_mirrors/ro/robomongo Robo 3T作为一款原生跨平台的MongoDB管理工具,为开…...

别再只删node_modules了!npm run serve报错‘There is likely additional logging output above’的完整排查与修复手册
从日志溯源到根治:npm run serve报错的系统性排查指南 当你满怀期待地敲下npm run serve,却迎面撞上那句"There is likely additional logging output above"时,是否感到一阵无力?删除node_modules重装就像重启电脑——…...
)
智能车竞赛实战:用逐飞库搞定TC264摄像头与按键中断(附完整代码)
智能车竞赛实战:用逐飞库高效配置TC264中断系统 全国大学生智能汽车竞赛中,实时性往往是决定胜负的关键因素。当摄像头采集图像、传感器读取数据、按键响应控制等任务需要即时处理时,中断机制便成为嵌入式系统的核心武器。TC264作为竞赛常用主…...

wpr_simulation机器人仿真平台:架构设计与高级应用实战
wpr_simulation机器人仿真平台:架构设计与高级应用实战 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation wpr_simulation是一个基于ROS(机器人操作系统)的完整机器人仿真平台࿰…...

经营分析——解读集团经营分析报告框架【附全文阅读】
集团经营分析报告框架推介总结 适应人群:集团高管、经营管理部、财务负责人、各业务单元负责人、经营分析专员、数据分析师及战略规划人员。 重要性总结:本 PPT 是集团级经营分析的标准化、体系化顶层框架,构建 “战略 — 环境 — 业绩 — 问…...

8255与74LS273实现流水灯控制原理
箱图片和题目要求,这是一个经典的微机原理/接口技术实验。你需要构建一个包含输入(开关)、处理(8255读取)、输出(74LS273锁存驱动LED)的系统。由于我无法直接为你绘制CAD图纸,我为你…...

BilibiliDown终极指南:5分钟掌握B站视频下载与音频提取
BilibiliDown终极指南:5分钟掌握B站视频下载与音频提取 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/…...