卷积神经网络(VGG-16)猫狗识别
文章目录
- 一、前言
- 二、前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 2. 导入数据
- 3. 查看数据
- 二、数据预处理
- 1. 加载数据
- 2. 再次检查数据
- 3. 配置数据集
- 4. 可视化数据
- 三、构建VG-16网络
- 四、编译
- 五、训练模型
- 六、模型评估
- 七、保存and加载模型
- 八、预测
一、前言
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
往期精彩内容:
- 卷积神经网络(CNN)实现mnist手写数字识别
- 卷积神经网络(CNN)多种图片分类的实现
- 卷积神经网络(CNN)衣服图像分类的实现
- 卷积神经网络(CNN)鲜花识别
- 卷积神经网络(CNN)天气识别
- 卷积神经网络(VGG-16)识别海贼王草帽一伙
- 卷积神经网络(ResNet-50)鸟类识别
- 卷积神经网络(AlexNet)鸟类识别
- 卷积神经网络(CNN)识别验证码
来自专栏:机器学习与深度学习算法推荐
二、前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")# 打印显卡信息,确认GPU可用
print(gpus)
2. 导入数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)#隐藏警告
import warnings
warnings.filterwarnings('ignore')import pathlib
image_count = len(list(data_dir.glob('*/*')))print("图片总数为:",image_count)
3. 查看数据
image_count = len(list(pictures_dir.glob('*.png')))
print("图片总数为:",image_count)
图片总数为: 3400
二、数据预处理
1. 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
batch_size = 8
img_height = 224
img_width = 224
TensorFlow版本是2.2.0的同学可能会遇到module 'tensorflow.keras.preprocessing' has no attribute 'image_dataset_from_directory'的报错,升级一下TensorFlow就OK了。
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 3400 files belonging to 2 classes.
Using 2720 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 3400 files belonging to 2 classes.
Using 680 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
['cat', 'dog']
2. 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(8, 224, 224, 3)
(8,)
Image_batch是形状的张量(8, 224, 224, 3)。这是一批形状224x224x3的8张图片(最后一维指的是彩色通道RGB)。Label_batch是形状(8,)的张量,这些标签对应8张图片
3. 配置数据集
AUTOTUNE = tf.data.AUTOTUNEdef preprocess_image(image,label):return (image/255.0,label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
4. 可视化数据
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(5, 8, i + 1) plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")

三、构建VG-16网络
VGG优缺点分析:
- VGG优点
VGG的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- VGG缺点
1)训练时间过长,调参难度大。2)需要的存储容量大,不利于部署。例如存储VGG-16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
结构说明:
- 13个卷积层(Convolutional Layer),分别用
blockX_convX表示 - 3个全连接层(Fully connected Layer),分别用
fcX与predictions表示 - 5个池化层(Pool layer),分别用
blockX_pool表示
VGG-16包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropoutdef VGG16(nb_classes, input_shape):input_tensor = Input(shape=input_shape)# 1st blockx = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)# 2nd blockx = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)# 3rd blockx = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)# 4th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)# 5th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)# full connectionx = Flatten()(x)x = Dense(4096, activation='relu', name='fc1')(x)x = Dense(4096, activation='relu', name='fc2')(x)output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)model = Model(input_tensor, output_tensor)return modelmodel=VGG16(1000, (img_width, img_height, 3))
model.summary()
四、编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 评价函数(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
model.compile(optimizer="adam",loss ='sparse_categorical_crossentropy',metrics =['accuracy'])
五、训练模型
from tqdm import tqdm
import tensorflow.keras.backend as Kepochs = 10
lr = 1e-4# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []for epoch in range(epochs):train_total = len(train_ds)val_total = len(val_ds)"""total:预期的迭代数目ncols:控制进度条宽度mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)"""with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:lr = lr*0.92K.set_value(model.optimizer.lr, lr)for image,label in train_ds: history = model.train_on_batch(image,label)train_loss = history[0]train_accuracy = history[1]pbar.set_postfix({"loss": "%.4f"%train_loss,"accuracy":"%.4f"%train_accuracy,"lr": K.get_value(model.optimizer.lr)})pbar.update(1)history_train_loss.append(train_loss)history_train_accuracy.append(train_accuracy)print('开始验证!')with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:for image,label in val_ds: history = model.test_on_batch(image,label)val_loss = history[0]val_accuracy = history[1]pbar.set_postfix({"loss": "%.4f"%val_loss,"accuracy":"%.4f"%val_accuracy})pbar.update(1)history_val_loss.append(val_loss)history_val_accuracy.append(val_accuracy)print('结束验证!')print("验证loss为:%.4f"%val_loss)print("验证准确率为:%.4f"%val_accuracy)
六、模型评估
epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, history_train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, history_train_loss, label='Training Loss')
plt.plot(epochs_range, history_val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
七、保存and加载模型
# 保存模型
model.save('model/21_model.h5')
# 加载模型
new_model = tf.keras.models.load_model('model/21_model.h5')
八、预测
# 采用加载的模型(new_model)来看预测结果plt.figure(figsize=(18, 3)) # 图形的宽为18高为5
plt.suptitle("预测结果展示")for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(1,8, i + 1) # 显示图片plt.imshow(images[i].numpy())# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0) # 使用模型预测图片中的人物predictions = new_model.predict(img_array)plt.title(class_names[np.argmax(predictions)])plt.axis("off")

相关文章:
卷积神经网络(VGG-16)猫狗识别
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、数据预处理1. 加载数据2. 再次检查数据3. 配置数据集4. 可视化数据 三、构建VG-16网络四、编译五、训练模型六、模型评估七、保存and加载模型八、预测…...
Mysql 行转列,把逗号分隔的字段拆分成多行
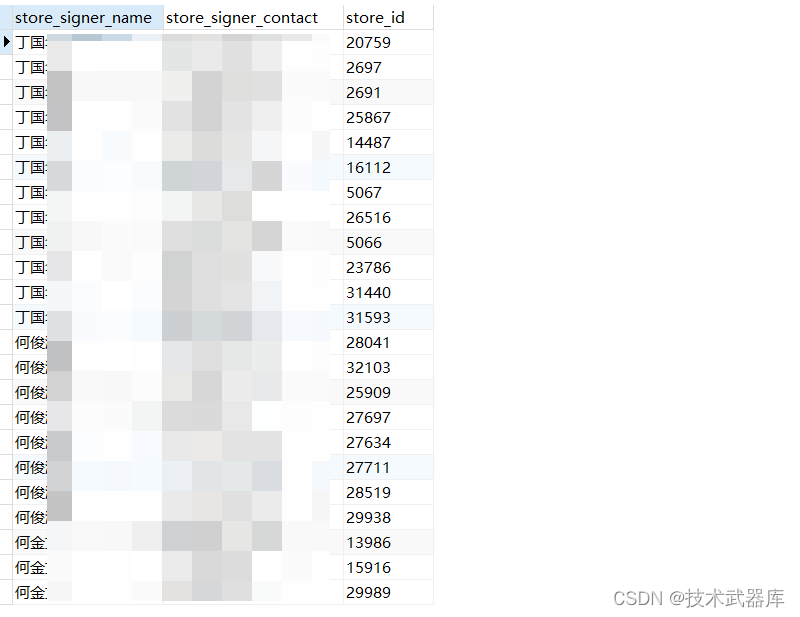
目录 效果如下源数据变更后的数据 方法第一种示例SQL和业务结合在一起使用 第二种示例SQL和业务结合在一起使用 结论 效果如下 源数据 变更后的数据 方法 第一种 先执行下面的SQL,看不看能不能执行,如果有结果,代表数据库版本是可以的&…...
基于单片机设计的智能水泵控制器
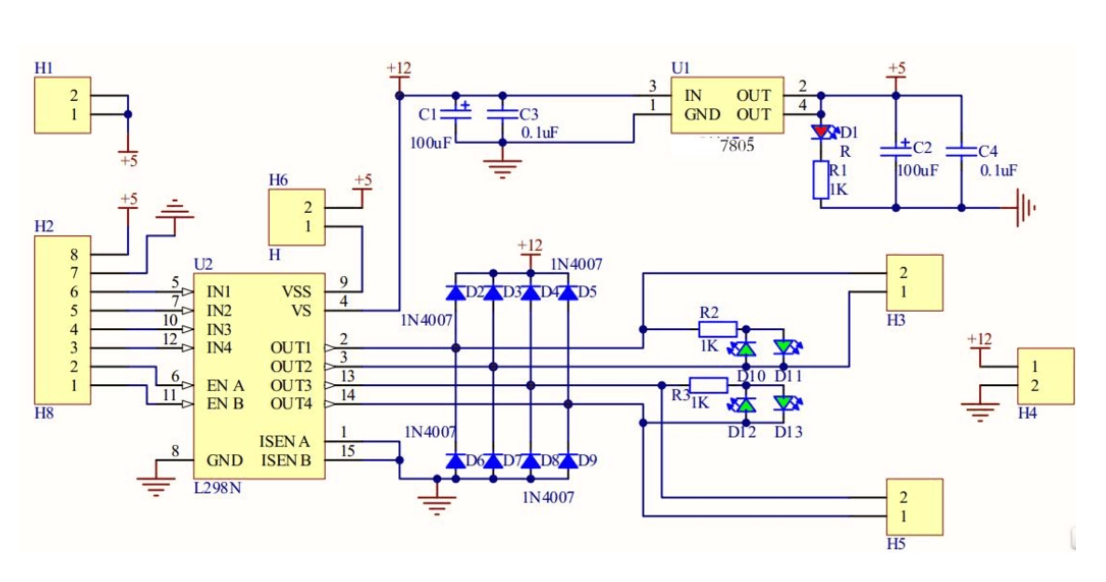
一、前言 在一些场景中,如水池、水箱等水体容器的管理中,保持水位的稳定是至关重要的。传统上,人们通常需要手动监测水位并进行水泵的启停控制,这种方式不仅效率低下,还可能导致水位过高或过低,从而对水体…...
反转链表的实现
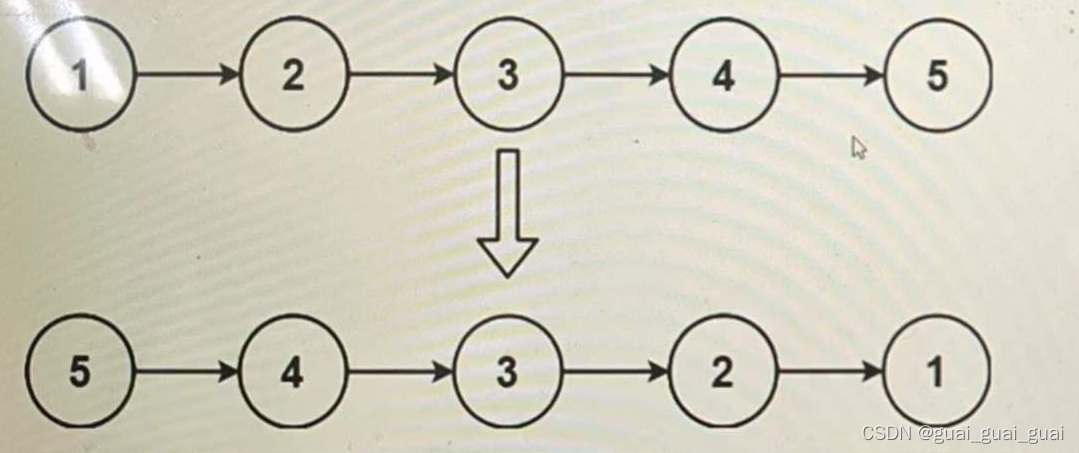
题目描述: 给出一个链表的头节点,将其反转,并返回新的头节点 思路1:反转地址 将每个节点里的地址由指向下一个节点变为指向前一个节点 定义三个结构体指针n1,n2,n3,n1表示改后指针的地址,n2表示要修改结构体里next的…...
python之pyqt专栏6-信号与槽2
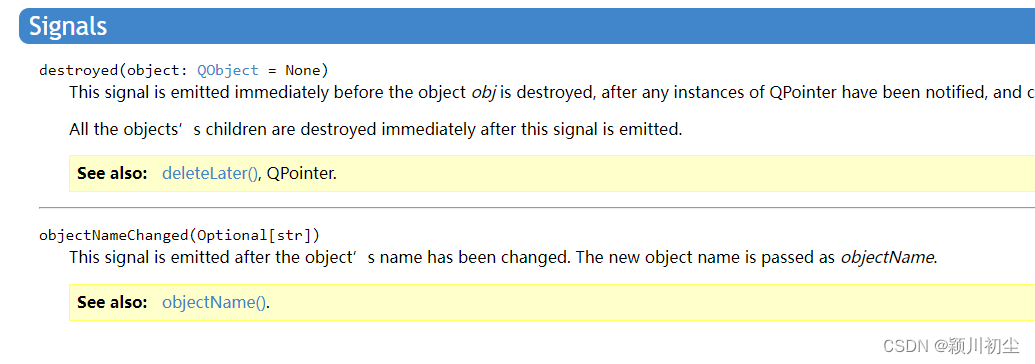
上一篇python之pyqt专栏5-信号与槽1-CSDN博客,我们通过信号与槽实现了点击Button,改变Label的文本内容。可以知道 信号是在类中定义的,是类的属性 槽函数是信号通过connect连接的任意成员函数,当信号发生时,执行与信号…...

C语言中一些特殊字符的输出
目录 %的介绍 斜杠与反斜杠 转义字符 %的介绍 int a1; 1、printf(’’%d’’,a);//输出1 2、printf(’’%%d’’,a);//输出%d 3、printf(’’%%%d ‘’,a)//输出%1 C语言中,%也是转义符,%%相当于% 斜杠与反斜杠 首先需要明白…...

Opencv制作电子签名(涉及知识点:像素过滤,图片通用resize函数,像素大于某个阈值则赋值为其它的像素值)
import cv2def resize_by_ratio(image, widthNone, heightNone, intercv2.INTER_AREA):img_new_size None(h, w) image.shape[:2] # 获得高度和宽度if width is None and height is None: # 如果输入的宽度和高度都为空return image # 直接返回原图if width is None:h_ratio …...

【漏洞复现】大华智慧园区综合管理平台deleteFtp接口远程命令执行
漏洞描述 大华智慧园区综合管理平台deleteFtp接口存在远程命令执行,攻击者可利用该漏洞执行任意命令,获取服务器控制权限。 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益…...
Unity Image - 镜像
1、为什么要使用镜像 在游戏开发过程中,我们经常会为了节省 美术图片资源大小,美术会将两边相同的图片进行切一半来处理。如下所示一个按钮 需要 400 * 236,然而美术只需要切一张 74*236的大小就可以了。这样一来图集就可以容纳更多的图片。…...

深入Spring Security魔幻山谷-获取认证机制核心原理讲解(新版)
文/朱季谦 这是一个古老的传说。 在神秘的Web系统世界里,有一座名为Spring Security的山谷,它高耸入云,蔓延千里,鸟飞不过,兽攀不了。这座山谷只有一条逼仄的道路可通。然而,若要通过这条道路前往另一头的…...

【知网稳定检索】第九届社会科学与经济发展国际学术会议 (ICSSED 2024)
第九届社会科学与经济发展国际学术会议 (ICSSED 2024) 2024 9th International Conference on Social Sciences and Economic Development 第九届社会科学与经济发展国际学术会议(ICSSED 2024)定于2024年3月22-24日在中国北京隆重举行。会议主要围绕社会科学与经济发展等研究…...

使用Spark写入数据到数据库表
项目场景: 使用Spark写入数据到数据库表 问题描述 Column "20231201" not found in schema Some(StructType(StructField(sdate,IntegerType,false),StructField(date_time,StringType,true),StructField(num,LongType,false),StructField(table_code,S…...

Codebeamer—软件全生命周期管理轻量级平台
产品概述 Codebeamer涵盖了软件研发的生命周期,在一个整合的平台内支持需求管理、测试管理、软件开发过程管理以及项目管理等,同时具有IToperations&DevOps相关的内容,并支持变体管理的功能。对于使用集成的应用程序生命周期管理…...

Yocto - bb脚本中使用的SRC_URI、SRCREV和S
我们遇到的各种自己不了解的技术或产品时,都需要阅读用户手册。用户手册里的内容很多时,除了由目录组织文档结构外,通常还有有一个词汇表,一般作为附录放在文档最后。 通过这个按照字母排序的词汇表,可以在对整个文档还…...
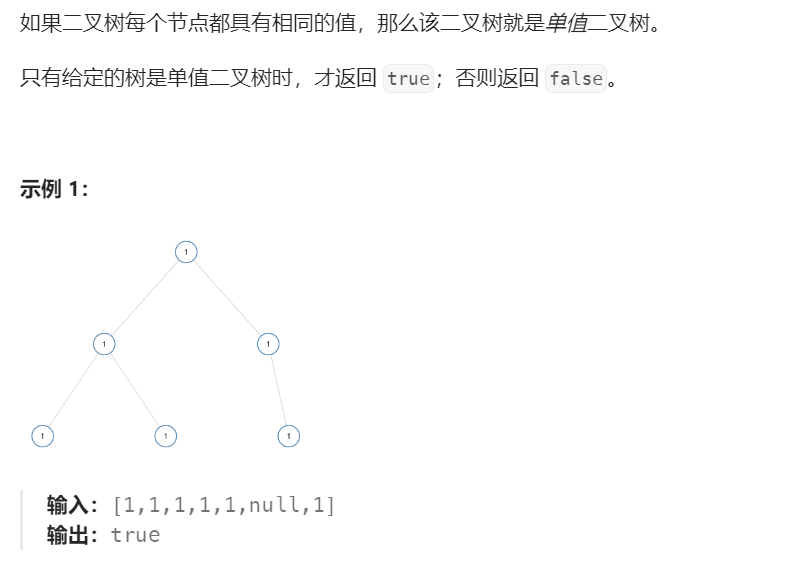
LeetCode | 965. 单值二叉树
LeetCode | 965. 单值二叉树 OJ链接 首先判断树为不为空,为空直接true然后判断左子树的val,和根的val相不相同再判断右子树的val,和根的val相不相同最后递归左子树和右子树 bool isUnivalTree(struct TreeNode* root) {if(root NULL)retur…...
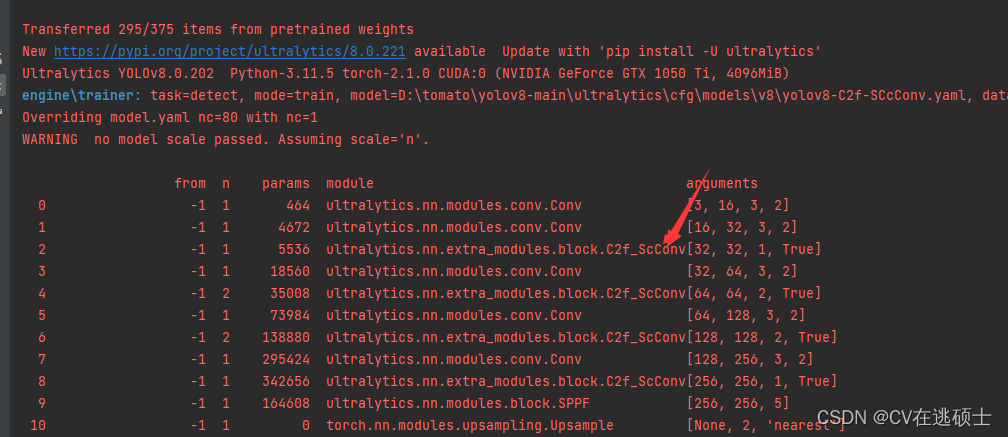
YOLOv8创新魔改教程(一)如何进行模块创新
YOLOv8创新魔改教程(一)如何进行模块创新 YOLOv8创新魔改教程 本人研一,最近好多朋友问我要如何修改模型创新模块,就想着不如直接开个专栏歇一歇文章,也算是对自己学习的总结,本专栏以YOLOv8为例…...

postgresql-shared_buffers参数详解
shared_buffers 是 PostgreSQL 中一个非常关键的参数,用于配置服务器使用的共享内存缓冲区的大小。这些缓冲区用于存储数据页,以便数据库可以更快地访问磁盘上的数据。 这个参数在 PostgreSQL 的性能方面有着重要的影响。增加 shared_buffers 可以提高数…...
windows10 Arcgis pro3.0-3.1
我先安装的arcgis pro3.0,然后下载的3.1。 3.0里面有pro、help、sdk、还有一些补丁包根据个人情况安装。 3.1里面也是这些。 下载 正版试用最新的 ArcGIS Pro 21 天教程,仅需五步!-地理信息云 (giscloud.com.cn) 1、安装windowsdesktop-…...

Apache Airflow (十四) :Airflow分布式集群搭建及测试
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...
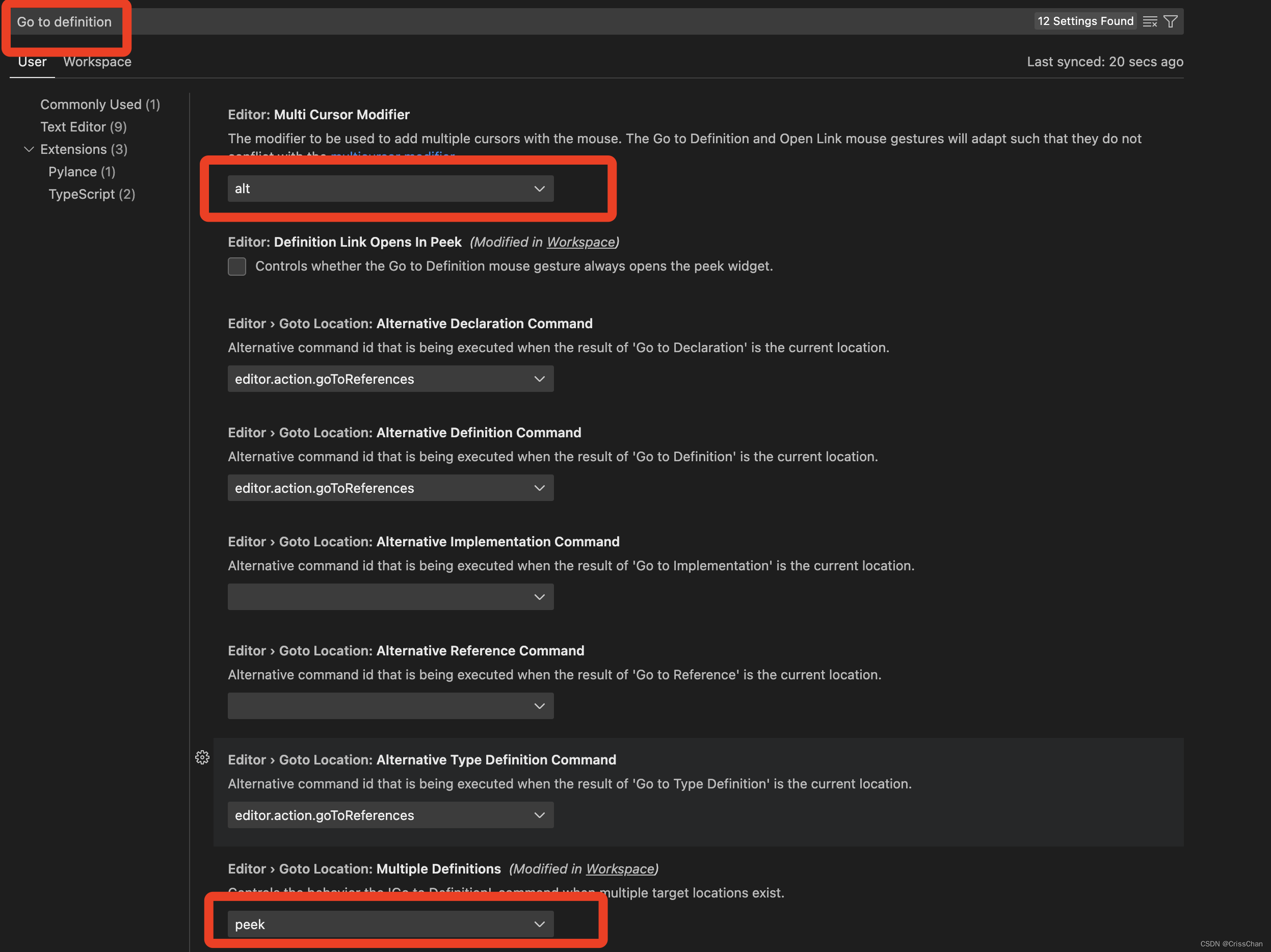
解决VSCode按住Ctrl(or Command) 点击鼠标左键不跳转的问题(不能Go to Definition)
问题出现 往往在升级了VSCode以后,就会出现按住Ctrl(or Command) 点击鼠标左键不跳转的问题,这个问题很常见。 解决办法 1 进入VScode的首选项,选择设置 2 输入Go to definition,找到如下两个设置&#…...

对比直接使用官方 API,Taotoken 在计费透明性上的优势体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API,Taotoken 在计费透明性上的优势体验 对于需要调用多种大语言模型的开发者而言,成本控…...

掌握Linux系统Realtek RTL8125 2.5GbE网卡驱动安装与性能优化的5个实战技巧
掌握Linux系统Realtek RTL8125 2.5GbE网卡驱动安装与性能优化的5个实战技巧 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms 在L…...
)
别再傻傻重启了!用JRebel插件实现Spring Boot项目秒级热更新(附2024最新激活与配置避坑指南)
解锁Spring Boot开发新姿势:JRebel热更新实战全攻略 每次修改完代码后,那个漫长的等待重启进度条的过程,是不是让你忍不住想砸键盘?作为经历过数百次Spring Boot项目重启的老司机,我完全理解这种抓狂感。直到遇见了JR…...

如何在5分钟内掌握ToolsFx密码学工具箱:新手完全指南
如何在5分钟内掌握ToolsFx密码学工具箱:新手完全指南 【免费下载链接】ToolsFx 跨平台密码学工具箱。包含编解码,编码转换,加解密, 哈希,MAC,签名,大数运算,压缩,二维码功…...

如何永久激活IDM?2024终极免费激活与试用重置完全指南
如何永久激活IDM?2024终极免费激活与试用重置完全指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script IDM Activation Script是一款专为Internet Dow…...

Cursor Free VIP技术架构深度解析:设备标识重置与多平台兼容实现
Cursor Free VIP技术架构深度解析:设备标识重置与多平台兼容实现 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reache…...

长期使用Taotoken Token Plan套餐对项目研发成本的控制效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐对项目研发成本的控制效果 在项目研发中,大模型API调用成本是预算管理的重要一环。对…...

杰理之RX修改为连接一个TX后需要再次按键或者其他操作才能连接第二个TX的功能需求【篇】
void user_wireless_dev_pair_code_pri() { y_printf(“user_wireless_dev_pair_code_pri”); u32 pair_code 0; wireless_dev_get_pair_code(“big_rx”, (u8 *)&pair_code, 1); wireless_dev_set_pair_code(“big_rx”, (u8 *)&pair_code); } //连接一个无线麦后&am…...

海外渠道通知短信接口
在跨境业务体系中,企业常面临区域代理商分散、信息同步滞后、补货提醒不及时的问题,传统邮件、即时通讯易出现漏读、延迟,而国际渠道通知短信接口凭借触达稳定、实时性强的优势,成为跨境企业对接代理商的高效通信方案。本文从接口…...
)
别再死记硬背公式了!用Excel+Python搞定数学建模三大评价模型(附代码)
用ExcelPython玩转数学建模三大评价模型:告别公式恐惧症 数学建模竞赛中,评价模型是绕不开的核心工具。但面对满屏的数学符号和抽象公式,很多同学的第一反应是头皮发麻——"这些矩阵运算到底怎么落地?""一致性检验…...