Apache Airflow (十四) :Airflow分布式集群搭建及测试

🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客
🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。
🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. 节点规划
2. airflow集群搭建步骤
3. 初始化Airflow
4. 创建管理员用户信息
5. 配置Scheduler HA
6. 启动Airflow集群
7. 访问Airflow 集群WebUI
8. 测试Airflow HA
1. 节点规划
| 节点IP | 节点名称 | 节点角色 | 运行服务 |
| 192.168.179.4 | node1 | Master1 | webserver,scheduler |
| 192.168.179.5 | node2 | Master2 | websever,scheduler |
| 192.168.179.6 | node3 | Worker1 | worker |
| 192.168.179.7 | node4 | Worker2 | worker |
2. airflow集群搭建步骤
1) 在所有节点安装python3.7
参照单节点安装Airflow中安装anconda及python3.7。
2) 在所有节点上安装airflow
- 每台节点安装airflow需要的系统依赖
yum -y install mysql-devel gcc gcc-devel python-devel gcc-c++ cyrus-sasl cyrus-sasl-devel cyrus-sasl-lib - 每台节点配置airflow环境变量
vim /etc/profileexport AIRFLOW_HOME=/root/airflow#使配置的环境变量生效source /etc/profile- 每台节点切换airflow环境,安装airflow,指定版本为2.1.3
(python37) conda activate python37(python37) pip install apache-airflow==2.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple默认Airflow安装在$ANCONDA_HOME/envs/python37/lib/python3.7/site-packages/airflow目录下。配置了AIRFLOW_HOME,Airflow安装后文件存储目录在AIRFLOW_HOME目录下。可以每台节点查看安装Airflow版本信息:
(python37) airflow version2.1.3- 在Mysql中创建对应的库并设置参数
aiflow使用的Metadata database我们这里使用mysql,在node2节点的mysql中创建airflow使用的库及表信息。
CREATE DATABASE airflow CHARACTER SET utf8;create user 'airflow'@'%' identified by '123456';grant all privileges on airflow.* to 'airflow'@'%';flush privileges;在mysql安装节点node2上修改”/etc/my.cnf”,在[mysqld]下添加如下内容:
[mysqld]explicit_defaults_for_timestamp=1以上修改完成“my.cnf”值后,重启Mysql即可,重启之后,可以查询对应的参数是否生效:
#重启mysql[root@node2 ~]# service mysqld restart#重新登录mysql查询mysql> show variables like 'explicit_defaults_for_timestamp';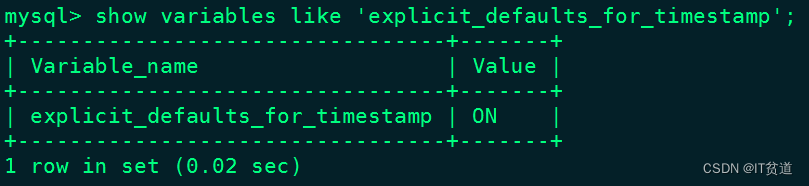
- 每台节点配置Airflow airflow.cfg文件
修改AIRFLOW_HOME/airflow.cfg文件,确保所有机器使用同一份配置文件,在node1节点上配置airflow.cfg,配置如下:
[core]dags_folder = /root/airflow/dags#修改时区default_timezone = Asia/Shanghai#配置Executor类型,集群建议配置CeleryExecutorexecutor = CeleryExecutor# 配置数据库sql_alchemy_conn=mysql+mysqldb://airflow:123456@node2:3306/airflow?use_unicode=true&charset=utf8[webserver]#设置时区default_ui_timezone = Asia/Shanghai[celery]#配置Celery broker使用的消息队列broker_url = redis://node4:6379/0#配置Celery broker任务完成后状态更新使用库result_backend = db+mysql://root:123456@node2:3306/airflow将node1节点配置好的airflow.cfg发送到node2、node3、node4节点上
3. 初始化Airflow
1) 每台节点安装需要的python依赖包
初始化Airflow数据库时需要使用到连接mysql的包,执行如下命令来安装mysql对应的python包。
(python37) # pip install mysqlclient -i Simple Index2) 在node1上初始化Airflow 数据库
(python37) [root@node1 airflow]# airflow db init初始化之后在MySQL airflow库下会生成对应的表。
4. 创建管理员用户信息
在node1节点上执行如下命令,创建操作Airflow的用户信息:
airflow users create \--username airflow \--firstname airflow \--lastname airflow \--role Admin \--email xx@qq.com执行完成之后,设置密码为“123456”并确认,完成Airflow管理员信息创建。
5. 配置Scheduler HA
1) 下载failover组件
登录https://github.com/teamclairvoyant/airflow-scheduler-failover-controller下载 airflow-scheduler-failover-controller 第三方组件,将下载好的zip包上传到node1 “/software”目录下。
在node1节点安装unzip,并解压failover组件:
(python37) [root@node1 software]# yum -y install unzip(python37) [root@node1 software]# unzip ./airflow-scheduler-failover-controller-master.zip2) 使用pip进行安装failover需要的依赖包
需要在node1节点上安装failover需要的依赖包。
(python37) [root@node1 software]# cd /software/airflow-scheduler-failover-controller-master(python37) [root@node1 airflow-scheduler-failover-controller-master]# pip install -e .3) node1节点初始化failover
(python37) [root@node1 ~]# scheduler_failover_controller initAdding Scheduler Failover configs to Airflow config file...Finished adding Scheduler Failover configs to Airflow config file.Finished Initializing Configurations to allow Scheduler Failover Controller to run. Please update the airflow.cfg with your desired configurations.注意:初始化airflow时,会向airflow.cfg配置中追加配置,因此需要先安装 airflow 并初始化。
4) 修改airflow.cfg
首先修改node1节点的AIRFLOW_HOME/airflow.cfg
[scheduler_failover]# 配置airflow Master节点,这里配置为node1,node2,两节点需要免密scheduler_nodes_in_cluster = node1,node2#在1088行,特别注意,需要去掉一个分号,不然后期自动重启Scheduler不能正常启动airflow_scheduler_start_command = export AIRFLOW_HOME=/root/airflow;nohup airflow scheduler >> ~/airflow/logs/scheduler.logs &配置完成后,可以通过以下命令进行验证Airflow Master节点:
(python37) [root@node1 airflow]# scheduler_failover_controller test_connectionTesting Connection for host 'node1'(True, ['Connection Succeeded', ''])Testing Connection for host 'node2'(True, ['Connection Succeeded\n'])将node1节点配置好的airflow.cfg同步发送到node2、node3、node4节点上:
(python37) [root@node1 ~]# cd /root/airflow/(python37) [root@node1 airflow]# scp airflow.cfg node2:`pwd`(python37) [root@node1 airflow]# scp airflow.cfg node3:`pwd`(python37) [root@node1 airflow]# scp airflow.cfg node4:`pwd`6. 启动Airflow集群
1) 在所有节点安装启动Airflow依赖的python包
(python37) [root@node1 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.3(python37) [root@node2 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.3(python37) [root@node3 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.3(python37) [root@node4 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.32) 在Master1节点(node1)启动相应进程
#默认后台启动可以使用-D ,这里使用-D有时不能正常启动Airflow对应进程airflow webserverairflow scheduler3) 在Master2节点(node2)启动相应进程
airflow webserver4) 在Worker1(node3)、Worker2(node4)节点启动Worker
在node3、node4节点启动Worker:
(python37) [root@node3 ~]# airflow celery worker(python37) [root@node4 ~]# airflow celery worker5) 在node1启动Scheduler HA
(python37) [root@node1 airflow]# nohup scheduler_failover_controller start > /root/airflow/logs/scheduler_failover/scheduler_failover_run.log &
至此,Airflow高可用集群搭建完成。
7. 访问Airflow 集群WebUI
浏览器输入node1:8080,查看Airflow WebUI:
8. 测试Airflow HA
1) 准备shell脚本
在Airflow集群所有节点{AIRFLOW_HOME}目录下创建dags目录,准备如下两个shell脚本,将以下两个脚本放在$AIRFLOW_HOME/dags目录下,BashOperator默认执行脚本时,默认从/tmp/airflow**临时目录查找对应脚本,由于临时目录名称不定,这里建议执行脚本时,在“bash_command”中写上绝对路径。如果要写相对路径,可以将脚本放在/tmp目录下,在“bash_command”中执行命令写上“sh ../xxx.sh”也可以。
first_shell.sh
#!/bin/bashdt=$1echo "==== execute first shell ===="echo "---- first : time is ${dt}"second_shell.sh
#!/bin/bashdt=$1echo "==== execute second shell ===="echo "---- second : time is ${dt}"2) 编写airflow python 配置
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperatordefault_args = {'owner':'zhangsan','start_date':datetime(2021, 9, 23),'retries': 1, # 失败重试次数'retry_delay': timedelta(minutes=5) # 失败重试间隔
}dag = DAG(dag_id = 'execute_shell_sh',default_args=default_args,schedule_interval=timedelta(minutes=1)
)first=BashOperator(task_id='first',#脚本路径建议写绝对路径bash_command='sh /root/airflow/dags/first_shell.sh %s'%datetime.now().strftime("%Y-%m-%d"),dag = dag
)second=BashOperator(task_id='second',#脚本路径建议写绝对路径bash_command='sh /root/airflow/dags/second_shell.sh %s'%datetime.now().strftime("%Y-%m-%d"),dag=dag
)first >> second将以上内容写入execute_shell.py文件,上传到所有Airflow节点{AIRFLOW_HOME}/dags目录下。
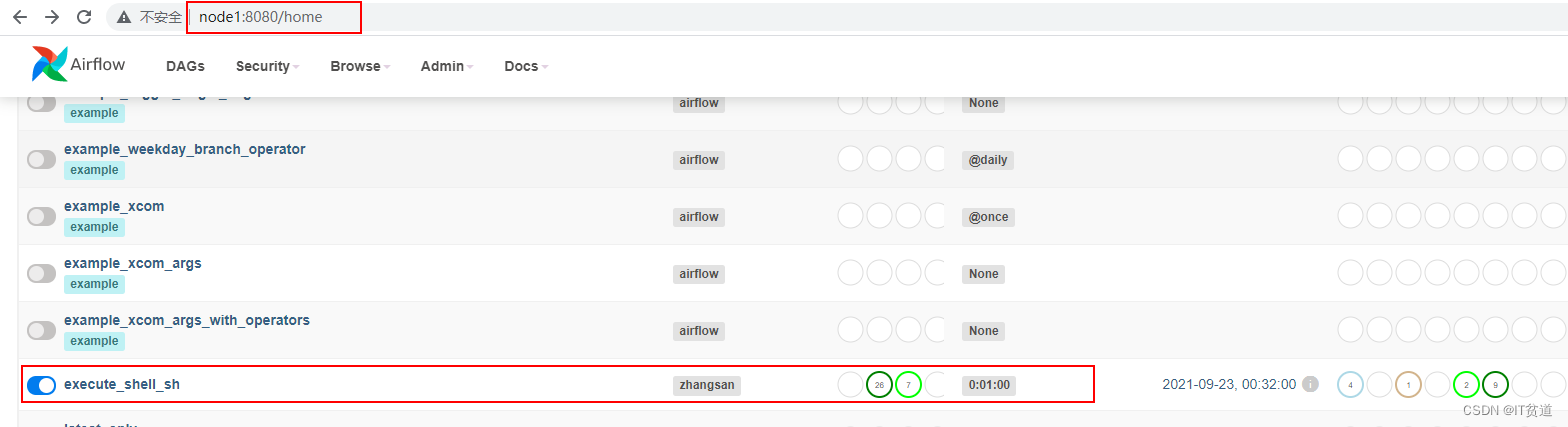
3) 重启Airflow,进入Airflow WebUI查看对应的调度
重启Airflow之前首先在node1节点关闭webserver ,Scheduler进程,在node2节点关闭webserver ,Scheduler进程,在node3,node4节点上关闭worker进程。
如果各个进程是后台启动,查看后台进程方式:
(python37) [root@node1 dags]# ps aux |grep webserver(python37) [root@node1 dags]# ps aux |grep scheduler(python37) [root@node2 dags]# ps aux |grep webserver(python37) [root@node2 dags]# ps aux |grep scheduler(python37) [root@node3 ~]# ps aux|grep "celery worker"(python37) [root@node4 ~]# ps aux|grep "celery worker"找到对应的启动命令对应的进程号,进行kill。重启后进入Airflow WebUI查看任务:
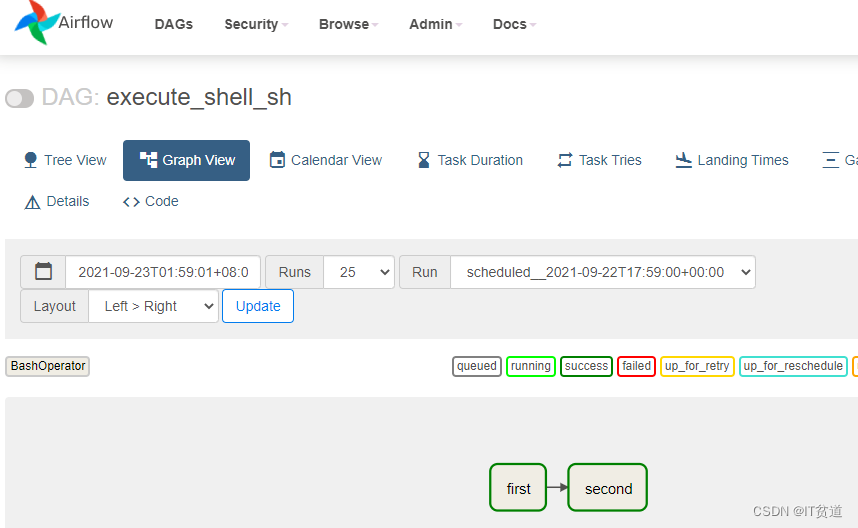
点击“success”任务后,可以看到脚本执行成功日志:
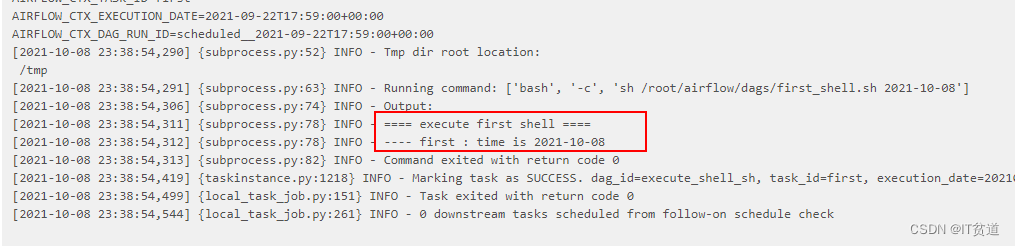
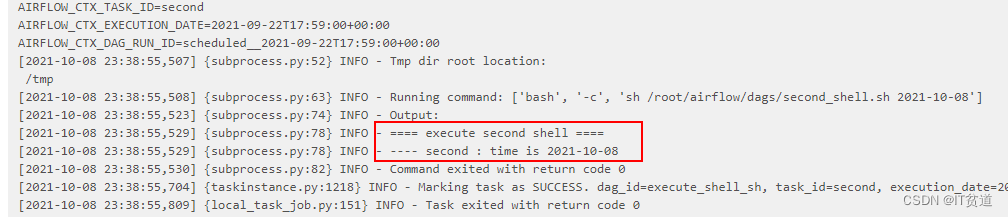
4) 测试Airflow HA
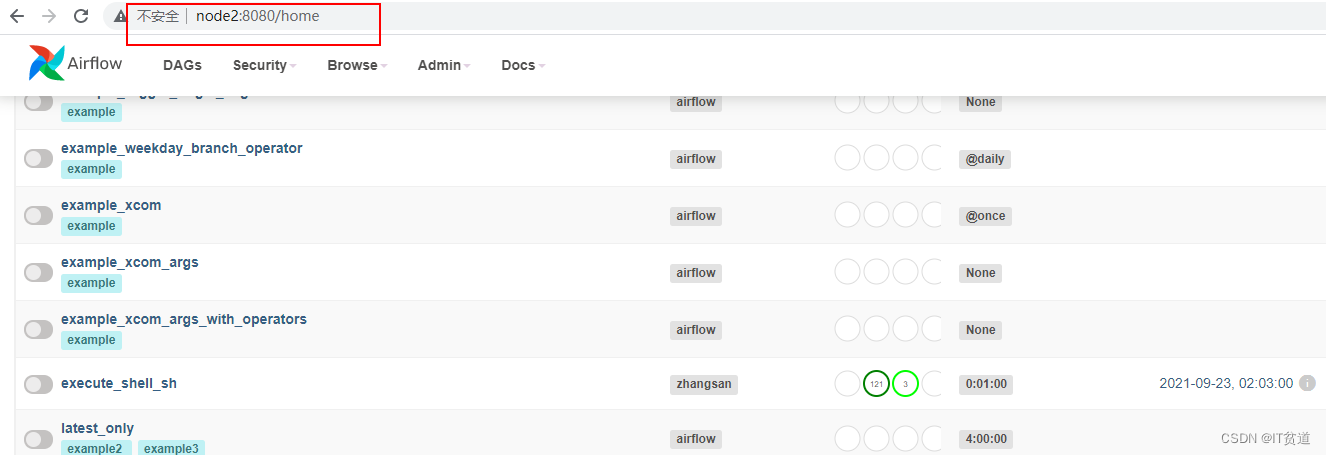
当我们把node1节点的websever关闭后,可以直接通过node2节点访问airflow webui:
在node1节点上,查找“scheduler”进程并kill,测试scheduler HA 是否生效:
(python37) [root@node1 ~]# ps aux|grep schedulerroot 23744 0.9 3.3 326940 63028 pts/2 S 00:08 0:02 airflow scheduler -- DagFileProcessorManager#kill 掉scheduler进程(python37) [root@node1 ~]# kill -9 23744访问webserver webui
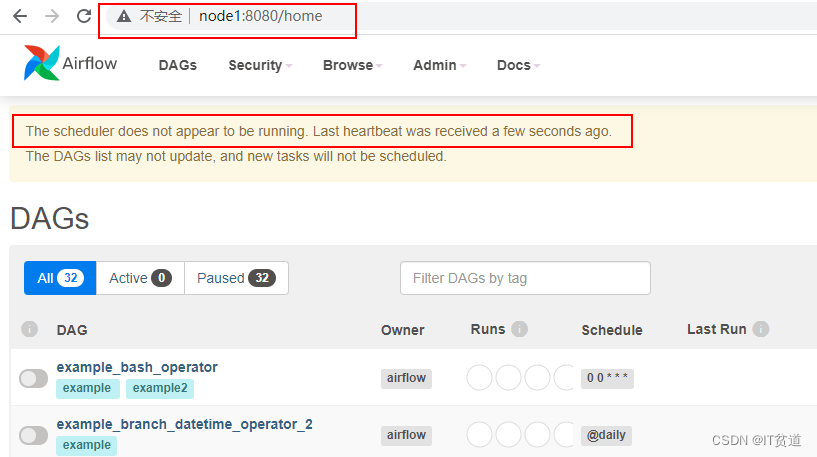
在node1节点查看scheduler_failover_controller进程日志中有启动schudler动作,注意:这里是先从node1启动,启动不起来再从其他Master 节点启动Schduler。

相关文章:
Apache Airflow (十四) :Airflow分布式集群搭建及测试
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...
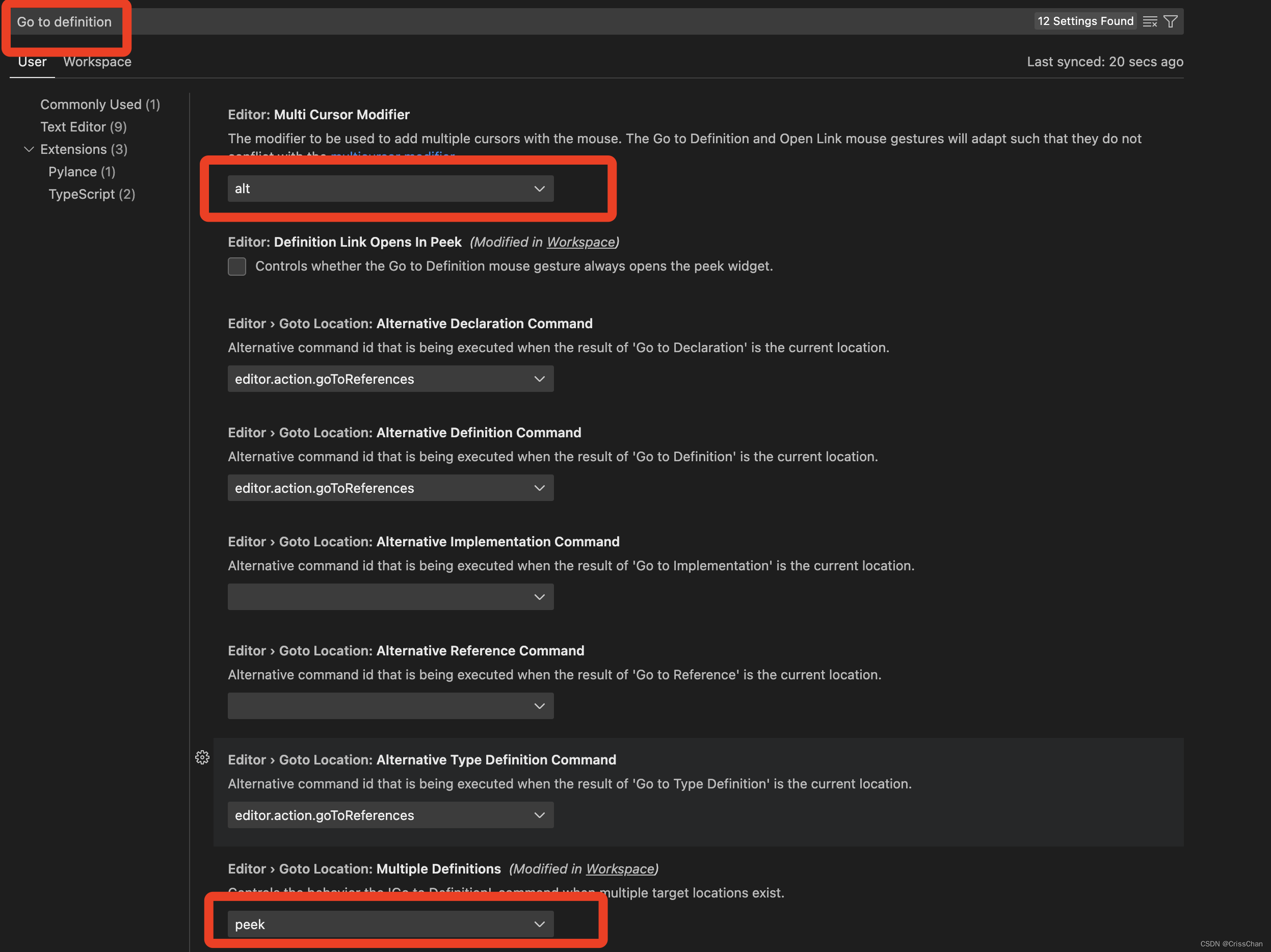
解决VSCode按住Ctrl(or Command) 点击鼠标左键不跳转的问题(不能Go to Definition)
问题出现 往往在升级了VSCode以后,就会出现按住Ctrl(or Command) 点击鼠标左键不跳转的问题,这个问题很常见。 解决办法 1 进入VScode的首选项,选择设置 2 输入Go to definition,找到如下两个设置&#…...

使用DrlParser 检测drl文件是否有错误
为避免运行时候错误,drools 7 可以使用DrlParser预先检测 drl文件是否正常。 parser 过程通常不会返回异常ruleDescr parser.parse(resource); 为空代表有异常 具体测试代码如下: public class DrlParserTest {public static void main(String[] arg…...

ArcGIS中基于人口数据计算人口密度的方法
文章目录 一、密度分析原理二、点密度分析三、线密度分析四、核密度分析一、密度分析原理 密度分析是指根据输入的要素数据集计算整个区域的数据聚集状况,从而产生一个联系的密度表面。通过密度计算,将每个采样点的值散步到整个研究区域,并获得输出栅格中每个像元的密度值。…...

在CentOS 8.2中安装Percona Xtrabackup 8.0.x备份MySql
添加Percona软件库: yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm 安装Percona Xtrabackup 8.0.x: yum install percona-xtrabackup-80 确认安装完成后,您可以使用以下命令验证Percona Xtrabackup的安装…...

javascript中的正则表达式的相关知识积累
01-javascript中的正则表达式用符号/作为正则表达式的开始符和结束符 javascript中的正则表达式用符号/作为正则表达式的开始符和结束符。 即javascript的正则表达式如下所示: /正则表达式/02-^:匹配字符串的开始 ^: 该符号表示匹配字符串的开始。这个…...
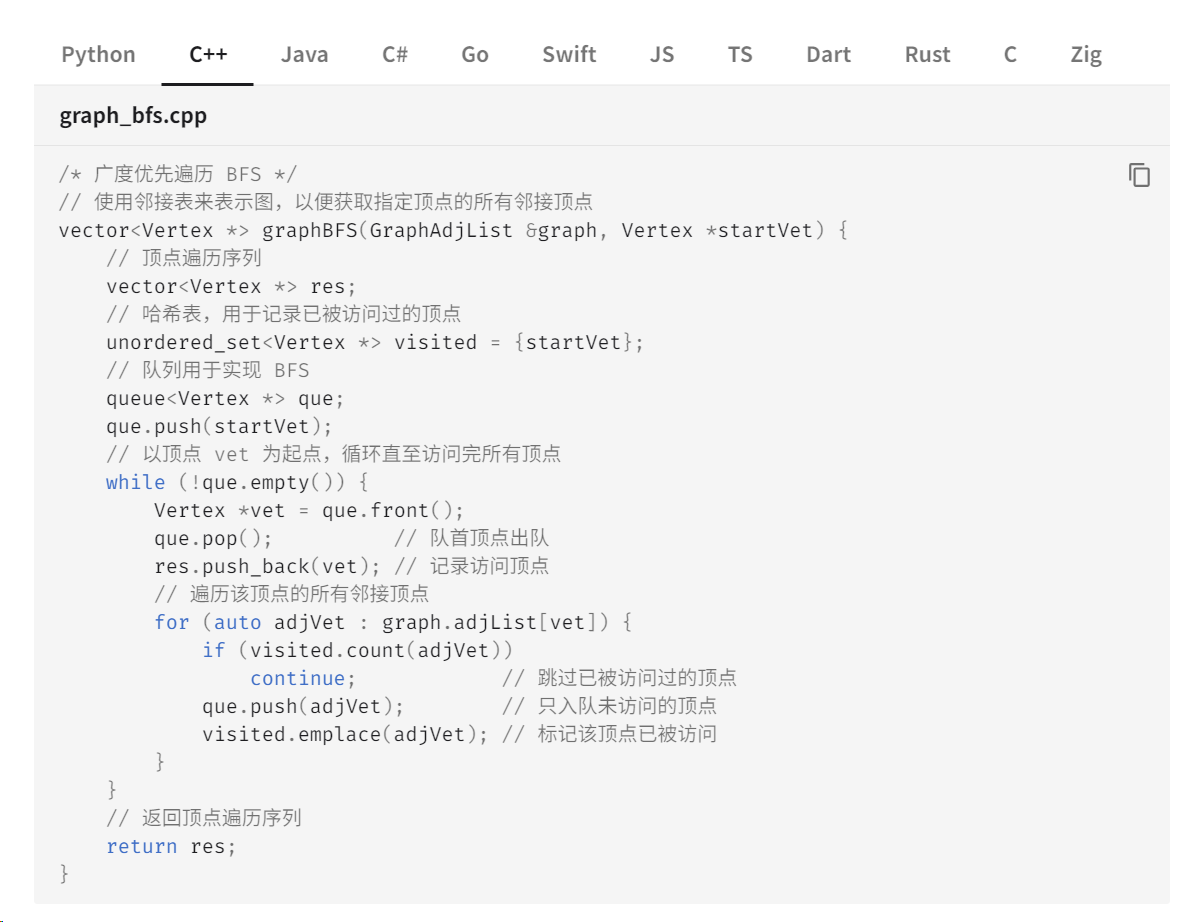
51k+ Star!动画图解、一键运行的数据结构与算法教程!
大家好,我是 Java陈序员。 我们都知道,《数据结构与算法》 —— 是程序员的必修课。 无论是使用什么编程语音,亦或者是前后端开发,都需要修好《数据结构与算法》这门课! 在各个互联网大产的面试中,对数据…...
)
4.7 矩阵的转置运算(C语言实现)
【题目描述】用键盘从终端输入一个3行4列的矩阵,编写一个函数对该矩阵进行转置操作。 【题目分析】矩阵的转置运算是线性代数中的一个基本运算。显然,一个m行n列的矩阵经过转置运算后就变成了一个n行m列的矩阵。这个问题的解决关键是要解决两个问题&…...

快速掌握Pyqt5的9种显示控件
Pyqt5相关文章: 快速掌握Pyqt5的三种主窗口 快速掌握Pyqt5的2种弹簧 快速掌握Pyqt5的5种布局 快速弄懂Pyqt5的5种项目视图(Item View) 快速弄懂Pyqt5的4种项目部件(Item Widget) 快速掌握Pyqt5的6种按钮 快速掌握Pyqt5的10种容器&…...

【WP】Geek Challenge 2023 web 部分wp
EzHttp http协议基础题 unsign 简单反序列化题 n00b_Upload 很简单的文件上传,上传1.php,抓包,发现php内容被过滤了,改为<? eval($_POST[‘a’]);?>,上传成功,命令执行读取就好了 easy_php …...

Elasticsearch:为现代搜索工作流程和生成式人工智能应用程序铺平道路
作者:Matt Riley Elastic 的创新投资支持开放的生态系统和更简单的开发者体验。 在本博客中,我们希望分享 Elastic 为简化你构建 AI 应用程序的体验而进行的投资。 我们知道,开发人员必须在当今快速发展的人工智能环境中保持灵活性。 然而&a…...

【WinForm.NET开发】Windows窗体开发概述
本文内容 介绍为什么要从 .NET Framework 迁移生成丰富的交互式用户界面显示和操纵数据将应用部署到客户端计算机 Windows 窗体是一个可创建适用于 Windows 的丰富桌面客户端应用的 UI 框架。 Windows 窗体开发平台支持广泛的应用开发功能,包括控件、图形、数据绑…...

WPF 简单绘制矩形
Canvas 画矩形: view和viewModel 绑定一起才显示移动轨迹(可以定义一个string 看是否绑定属性的路径是正确的) 前台(绑定事件和显示移动的线): <Canvas Name"canvas" Background"#01FF…...

crui_lvgl 一个LVGL的DSL辅助工具的设想
设想 Target以LVGL为目标,语法以CSS为Reference。 CSS 规范 略 CSS规范最强大的属于CSS自身的属性很多,可以通过class和伪属性选择器对UI进行直接控制。 QML规范 ApplicationWindow {visible: truewidth: Constants.widthheight: Constants.height…...

公共部门生成式人工智能的未来
作者:Dave Erickson 最近,我与 IDC Government Insights 研究副总裁阿德莱德奥布莱恩 (Adelaide O’Brien) 坐下来讨论了全球公共部门生成式人工智能的当前和未来状况。 完整的对话可以按需查看,但我也想强调讨论中的一些要点。 我们的目标是…...

【报名】2023产业区块链生态日暨 FISCO BCOS 开源六周年生态大会
作为2023深圳国际金融科技节系列活动之一,由深圳市地方金融监督管理局指导,微众银行、金链盟主办的“2023产业区块链生态日暨FISCO BCOS开源六周年生态大会”将于12月15日下午14:00在深圳举办。 今年的盛会将进一步升级,以“FISCO BCOS和TA的…...
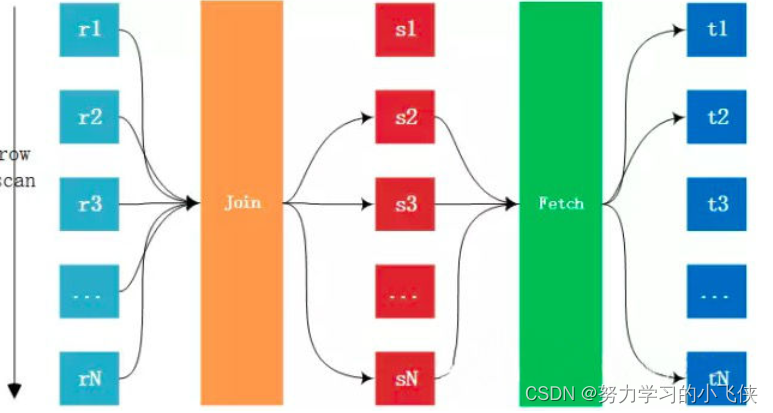
MySQL之性能分析和系统调优
MySQL之性能分析和系统调优 性能分析 查看执行计划 EXPLAIN EXPLAIN作为MySQL的性能分析神器,可以用来分析SQL执行计划,需要理解分析结果可以帮助我们优化SQL explain select … from … [where ...]TABLE 表名 查询的每一行记录都对于着一张表 id 该…...
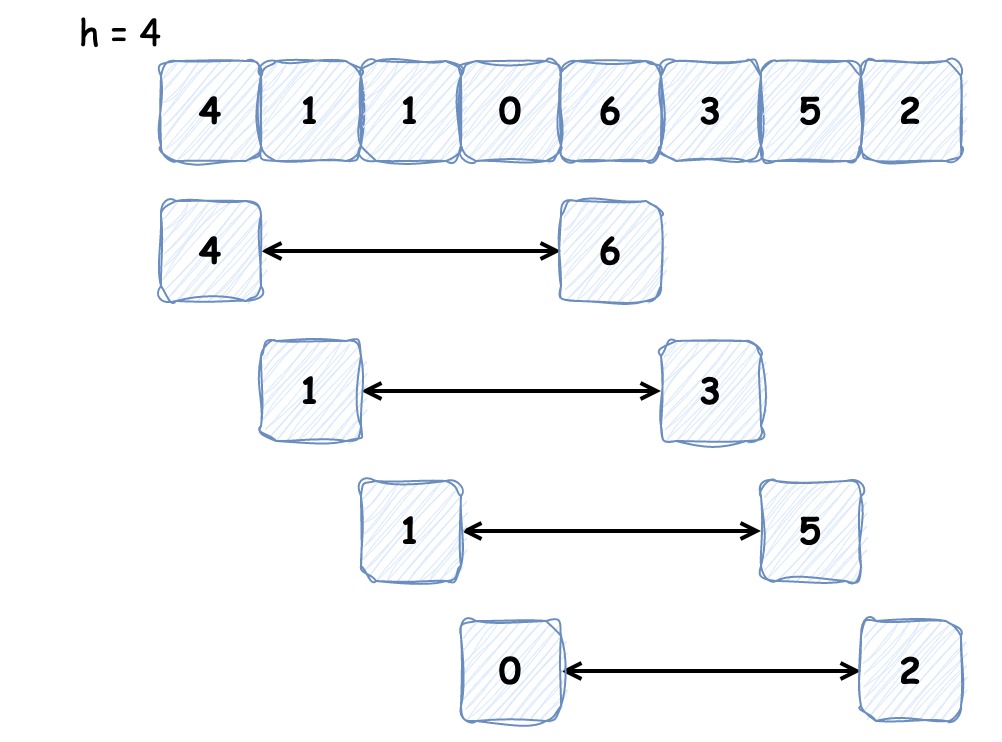
时间复杂度为 O(n^2) 的排序算法 | 京东物流技术团队
对于小规模数据,我们可以选用时间复杂度为 O(n2) 的排序算法。因为时间复杂度并不代表实际代码的执行时间,它省去了低阶、系数和常数,仅代表的增长趋势,所以在小规模数据情况下, O(n2) 的排序算法可能会比 O(nlogn) 的…...
关于前端学习的思考-内边距、边框和外边距
从最简单的盒子开始思考 先把实际应用摆出来: margin:居中,控制边距。 padding:控制边距。 border:制作三角形。 盒子分为内容盒子,内边距盒子,边框和外边距。 如果想让块级元素居中&#…...

【linux】/etc/security/limits.conf配置文件详解、为什么限制、常见限制查看操作
文章目录 一. limits.conf常见配置项详解二. 文件描述符(file descriptor)简述三. 为什么限制四. 相关操作1. 展示当前资源限制2. 查看系统当前打开的文件描述符数量3. 查看某个进程打开的文件描述符数量4. 各进程占用的文件描述符 /etc/security/limits…...

别再折腾环境了!手把手教你用Texlive 2022 + Texstudio 4.4.1 一键搞定西电XDUTS论文模板
西电LaTeX论文写作终极指南:Texlive 2022与Texstudio 4.4.1高效配置方案 每到毕业季,总有一群学生在深夜的实验室里对着报错的LaTeX界面抓狂。去年此时,我也曾是其中一员——连续三天尝试配置西电XDUTS论文模板未果,直到在一位学…...

AI 不锈钢保温杯智能功率 MOSFET 完整选型方案
2026年随着 AI 技术在智能保温杯领域的深度渗透(如精准温控、语音交互、健康监测、无线充电管理),对功率 MOSFET 提出更高要求:高集成度、低功耗、小封装、高可靠性。微碧半导体(VBsemi)基于 SGT 及 Trench…...

StarUML Java插件终极指南:高效实现UML与Java代码双向转换
StarUML Java插件终极指南:高效实现UML与Java代码双向转换 【免费下载链接】staruml-java Java extension for StarUML 项目地址: https://gitcode.com/gh_mirrors/st/staruml-java StarUML Java插件为Java开发者提供了强大的UML建模与代码生成能力ÿ…...

如何永久激活IDM?2024终极免费激活与试用重置完全指南
如何永久激活IDM?2024终极免费激活与试用重置完全指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script IDM Activation Script是一款专为Internet Dow…...

体验Taotoken官方折扣与Token Plan带来的实际费用节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken官方折扣与Token Plan带来的实际费用节省 对于开发者个人或小团队而言,在项目开发或日常工作中使用大模型…...

百度文库文档免费下载终极指南:三步获取PDF完整教程
百度文库文档免费下载终极指南:三步获取PDF完整教程 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到心仪的文档,却因为需要下载券或付费而无法保存…...

GitHub Desktop汉化神器:3分钟让英文界面变中文
GitHub Desktop汉化神器:3分钟让英文界面变中文 【免费下载链接】GitHubDesktop2Chinese GithubDesktop语言本地化(汉化)工具 【GitHub桌面客户端中文汉化】 项目地址: https://gitcode.com/gh_mirrors/gi/GitHubDesktop2Chinese 还在为GitHub Desktop的英文…...

抖音批量下载神器:douyin-downloader开源工具完整使用指南
抖音批量下载神器:douyin-downloader开源工具完整使用指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...
)
避坑指南:STM32连接畅科125KHz RFID读卡器的那些事儿(附完整工程)
STM32与125KHz RFID读卡器实战:从硬件对接到数据解析全流程 在物联网和自动化识别领域,低频RFID技术因其稳定的性能和较低的成本,依然占据着重要地位。本文将深入探讨如何基于STM32F103系列微控制器实现与125KHz RFID读卡器的完整对接方案&a…...

Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节
Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节 当工业自动化遇上Python,pylogix库成为了连接AB PLC与Python世界的桥梁。但在处理数组、字符串和用户自定义数据类型(UDT)时,即便是经验丰富的开发…...