Elasticsearch:为现代搜索工作流程和生成式人工智能应用程序铺平道路
作者:Matt Riley
Elastic 的创新投资支持开放的生态系统和更简单的开发者体验。

在本博客中,我们希望分享 Elastic® 为简化你构建 AI 应用程序的体验而进行的投资。 我们知道,开发人员必须在当今快速发展的人工智能环境中保持灵活性。 然而,常见的挑战使得构建生成式人工智能应用变得不必要的僵化和复杂。 仅举几例:
- 向量 — 从可以使用多少向量到可以使用哪些向量以及如何对大段文本进行分块
- 评估、交换和管理大型语言模型 (LLM)
- 设置有效的语义搜索(特别是如果你的开发团队资源有限或有技能上的差距)
- 利用现有投资和当前架构,同时平衡技术债务
- 从概念验证扩展到生产
- 确保最终用户应用程序快速、经济高效,并在响应查询时反映安全、最新的专有数据
- 实施分散且复杂
灵活的工具可帮助你快速适应、响应变化并加速你的项目。 这就是为什么 Elastic 建立在 Apache Lucene 的基础上,提供最好的开放代码向量数据库和搜索引擎。 Elastic 还积极与整个生态系统合作,以扩大对转换器(transformer)和基础模型的支持。
此外,我们还利用 Elastic 专有的 Learned Sparse EncodeR 模型 ELSER(现已已正式发布)让开箱即用的高度相关语义搜索变得更加容易。 我们正在减少与检索增强生成 (RAG) 相关的成本和处理时间,该检索过程为自定义用例的从专有数据源到 LLM 的自然语言查询提供相关响应。 而且,我们正在简化 Elasticsearch® 的开发人员体验,以便实现简单明了。
开发人员正在积极塑造生成式人工智能应用程序的未来。 Elastic 的突破性投资(以及即将到来的更多投资)反映了为什么我们的人工智能搜索分析平台是新一代搜索工作负载的最佳选择。
一切都在 Apache Lucene 上
这一切都始于 Apache Lucene,这是一个开源搜索引擎软件库,经受住了时间的考验,并为 Elasticsearch 提供了基础。 虽然 Elasticsearch 凭借其在向量搜索、可扩展性和性能方面的创新,已成为下载次数最多的向量数据库,但我们平台的优势源于 Elastic 和 Lucene 社区首先投资于 Apache Lucene 的这些进步。 事实上,Elastic 有着增强 Lucene 功能的历史,例如数字和地理空间搜索功能、Weak AND 支持以及改进的列式存储。 推动 Lucene 社区的发展意味着每个人都走得更远、更快。 作为这些投资的推动者意味着 Elastic 用户首先会获得根据其搜索需求量身定制的价值。
在 Elastic,我们知道 Lucene 具有超越全文搜索的潜力:开发人员需要全面的功能来构建搜索应用程序和生成式 AI 体验,包括聚合、过滤、分面等。最终,我们有望使 Lucene 成为最领先的 - 全球领先的向量数据库,并与全球数百万 Elasticsearch 用户分享其功能。 这就是为什么 Elastic 的开发人员定期向 Lucene 提交代码并利用其基础代码进行新项目的原因,例如:
- 将最大内积引入 Lucene
- 使用 SIMD 指令加速向量搜索
- 提供完整的文档向量搜索,允许文档在一个字段内具有多个向量,并按最相似的向量进行排名 - 处理从长文本段落派生的正确评分向量的复杂性,以解决一个常见的挑战 - 当使用文本嵌入时,维护大型文本的整体上下文
- Lucene 中的融合乘加 (FMA)
由于 Elasticsearch 构建在 Lucene 之上,因此当你升级到我们的最新版本时,你将自动受益于所有最新改进。 我们已经开始通过向 Lucene 添加标量量化支持(一项关键的成本节约功能)来贡献客户所需的下一个基础投资。
在语义搜索和 RAG 方面首屈一指
开发人员的任务是构建相关、高性能且经济高效的搜索和生成人工智能应用程序。 很简单,你需要能够从所有专有数据源检索数据来构建 RAG,从而提供最佳、最相关的结果。 为此,我们为企业数据库和流行的生产力工具以及 OneDrive、Google Drive、GitHub、ServiceNow、Sharepoint、Teams、Slack 等内容源添加了更多本机连接器和连接器客户端。
更值得注意的是,在 Elastic 8.11 版本中,我们宣布全面推出 Elastic Learned Sparse EncodeR (ELSER)。 这是我们专有的人工智能模型,用于提供世界一流的语义搜索。 ELSER 是一种预先训练的文本检索模型,可提供跨领域高度相关的结果,并允许你通过执行几个简单的步骤来实现语义搜索。 自 5 月份推出技术预览版以来,ELSER 已得到广泛采用,使我们能够根据客户反馈进行改进。 我们的正式版 ELSER 模型提高了相关性并减少了摄取和检索时间。 你现在可以升级以利用这些增强功能。
生成式人工智能领域面临的另一个障碍是:更高的计算成本和更慢的响应时间。 生成式 LLM 调用会产生每个 token 的成本,并且需要额外的处理,这需要时间。 然而,凭借嵌入和快速 k 最近邻算法 (kNN) 的强大功能,Elastic 可以用作生成式 AI 应用程序的缓存层,轻松识别类似的查询和响应,并提供更快、更具成本效益的答案。 就成本效率而言,在 AWS 上,我们现在还提供向量搜索优化的 Elastic Cloud 硬件配置文件,具有最佳的默认 RAM 比率,能够以经济高效的方式存储更多向量。
Elastic 在使语义搜索和 RAG 易于一起使用方面做得越好,开发人员就能越快地为最终用户打造出色的生成式 AI 体验。 这就是为什么我们专注于让开发人员能够轻松实用地使用该技术。
整个生态系统的选择和灵活性
通过开放平台帮助你快速响应人工智能时代的变化,你可以在其中使用各种工具和一致的标准,这是加速生成式人工智能项目的关键。 这就是为什么开发人员可以在 Elasticsearch 中灵活使用和托管各种 Transformer 模型,包括私有和公共 Hugging Face 模型。 你还可以将由 AWS SageMaker、Google Vertex AI、Cohere、OpenAI 等第三方服务生成的向量存储在 Elasticsearch 中。
我们还扩大了对生态系统工具的支持,以便你可以轻松地将 Elasticsearch 与 LangChain 和 LlamaIndex 一起用作向量数据库。 事实上,我们最近与 LangChain 团队就 LangChain Templates 进行了合作,以帮助开发人员构建可立即投入生产的生成式 AI 应用程序。 感谢我们的社区,Elastic 已经成为 LangChain 上最受欢迎的矢量商店之一。 现在,借助新的 RAG 模板,你可以使用 LangSmith 和 Elasticsearch 创建生产级功能。
简单的开发者体验
我们致力于打造简化的开发者体验。 我们正在发布简化的命令,这些命令抽象了推理和模型管理工作流的复杂性,你可以在一个简单的 API 后面使用这些工作流。 我们正在改进密集向量的默认设置,并提供自动映射。 通过一次调用,你可以总结结果或将文本嵌入任何模型的向量,从而减少构建和学习所需的时间。
很快,我们将推出 Elastic 的新无服务器(severless)架构,这是一个新的部署选项,适合那些想要专注于创造创新体验而不是管理底层基础设施的开发人员。 我们专注于为你提供所需的所有工具,因此我们在 Python、PHP、JavaScript、Ruby、Java、.Net 和 Go 的无服务器架构中添加新的语言客户端。
我们还清楚地意识到,开始使用快速变化的新技术可能具有挑战性,这就是为什么我们为每个 Elastic 部署选项提供简单的入门指导和代码,包括实际示例来帮助你快速启动新项目。
现在是成为一名 Elasticsearch 开发人员的最佳时机。 我们最近的研究和开发工作正在使 Lucene 成为世界上最好的向量数据库。 我们确保语义搜索和 RAG 在易用性、相关性、速度、规模和成本效率方面无与伦比。 我们将生态系统的开放性、灵活性和简单性作为开发者体验的核心。
准备好开始在 Elasticsearch 上构建下一代搜索了吗? 尝试 Elasticsearch Relevance Engine™,这是我们用于构建 AI 搜索应用程序的开发人员工具套件。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用或引用了第三方生成人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 和相关标记是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:Paving the way for modern search workflows and generative AI apps | Elastic Blog
相关文章:
Elasticsearch:为现代搜索工作流程和生成式人工智能应用程序铺平道路
作者:Matt Riley Elastic 的创新投资支持开放的生态系统和更简单的开发者体验。 在本博客中,我们希望分享 Elastic 为简化你构建 AI 应用程序的体验而进行的投资。 我们知道,开发人员必须在当今快速发展的人工智能环境中保持灵活性。 然而&a…...

【WinForm.NET开发】Windows窗体开发概述
本文内容 介绍为什么要从 .NET Framework 迁移生成丰富的交互式用户界面显示和操纵数据将应用部署到客户端计算机 Windows 窗体是一个可创建适用于 Windows 的丰富桌面客户端应用的 UI 框架。 Windows 窗体开发平台支持广泛的应用开发功能,包括控件、图形、数据绑…...

WPF 简单绘制矩形
Canvas 画矩形: view和viewModel 绑定一起才显示移动轨迹(可以定义一个string 看是否绑定属性的路径是正确的) 前台(绑定事件和显示移动的线): <Canvas Name"canvas" Background"#01FF…...

crui_lvgl 一个LVGL的DSL辅助工具的设想
设想 Target以LVGL为目标,语法以CSS为Reference。 CSS 规范 略 CSS规范最强大的属于CSS自身的属性很多,可以通过class和伪属性选择器对UI进行直接控制。 QML规范 ApplicationWindow {visible: truewidth: Constants.widthheight: Constants.height…...

公共部门生成式人工智能的未来
作者:Dave Erickson 最近,我与 IDC Government Insights 研究副总裁阿德莱德奥布莱恩 (Adelaide O’Brien) 坐下来讨论了全球公共部门生成式人工智能的当前和未来状况。 完整的对话可以按需查看,但我也想强调讨论中的一些要点。 我们的目标是…...

【报名】2023产业区块链生态日暨 FISCO BCOS 开源六周年生态大会
作为2023深圳国际金融科技节系列活动之一,由深圳市地方金融监督管理局指导,微众银行、金链盟主办的“2023产业区块链生态日暨FISCO BCOS开源六周年生态大会”将于12月15日下午14:00在深圳举办。 今年的盛会将进一步升级,以“FISCO BCOS和TA的…...
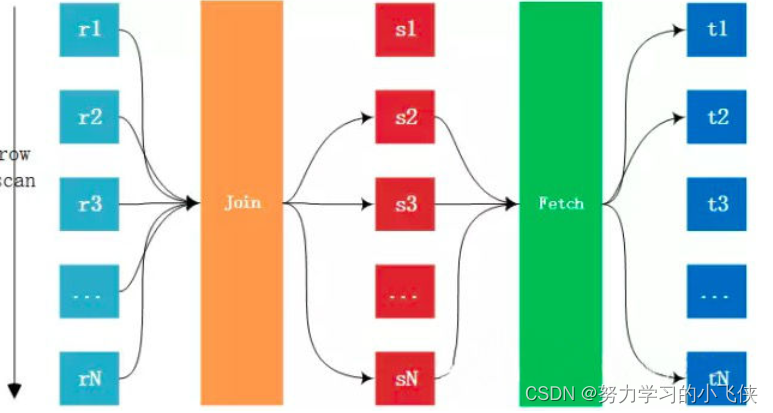
MySQL之性能分析和系统调优
MySQL之性能分析和系统调优 性能分析 查看执行计划 EXPLAIN EXPLAIN作为MySQL的性能分析神器,可以用来分析SQL执行计划,需要理解分析结果可以帮助我们优化SQL explain select … from … [where ...]TABLE 表名 查询的每一行记录都对于着一张表 id 该…...
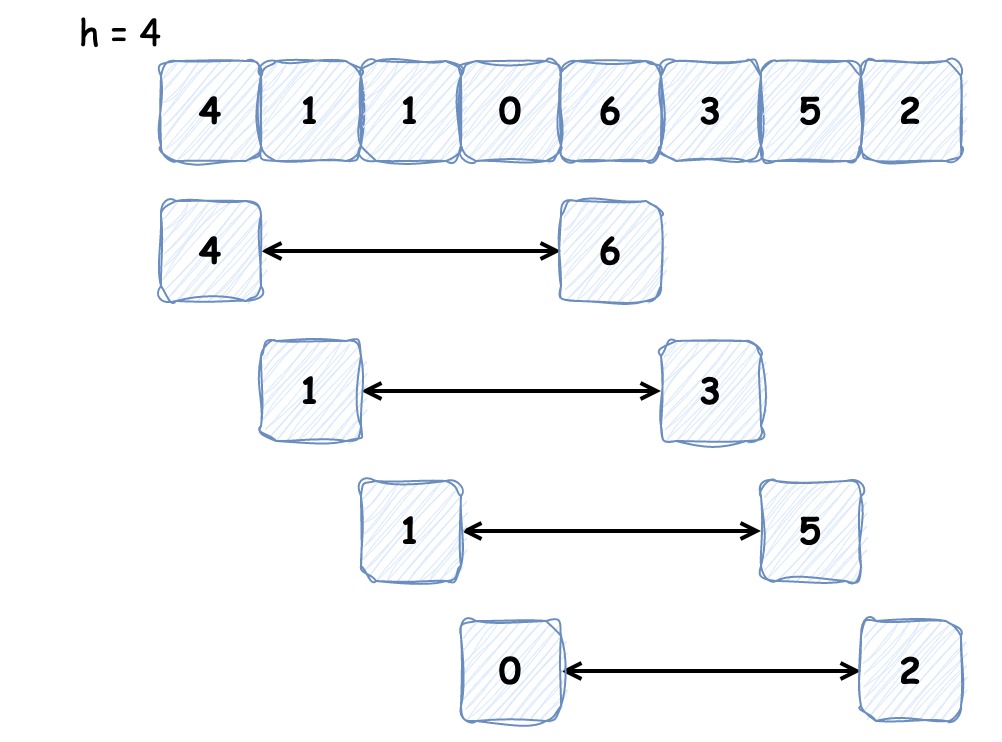
时间复杂度为 O(n^2) 的排序算法 | 京东物流技术团队
对于小规模数据,我们可以选用时间复杂度为 O(n2) 的排序算法。因为时间复杂度并不代表实际代码的执行时间,它省去了低阶、系数和常数,仅代表的增长趋势,所以在小规模数据情况下, O(n2) 的排序算法可能会比 O(nlogn) 的…...
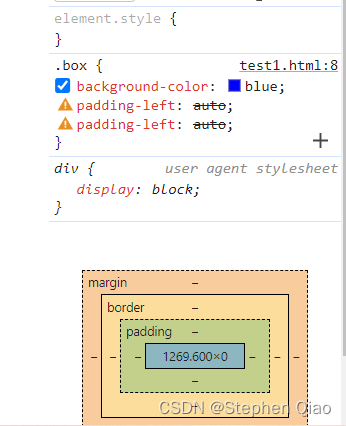
关于前端学习的思考-内边距、边框和外边距
从最简单的盒子开始思考 先把实际应用摆出来: margin:居中,控制边距。 padding:控制边距。 border:制作三角形。 盒子分为内容盒子,内边距盒子,边框和外边距。 如果想让块级元素居中&#…...

【linux】/etc/security/limits.conf配置文件详解、为什么限制、常见限制查看操作
文章目录 一. limits.conf常见配置项详解二. 文件描述符(file descriptor)简述三. 为什么限制四. 相关操作1. 展示当前资源限制2. 查看系统当前打开的文件描述符数量3. 查看某个进程打开的文件描述符数量4. 各进程占用的文件描述符 /etc/security/limits…...
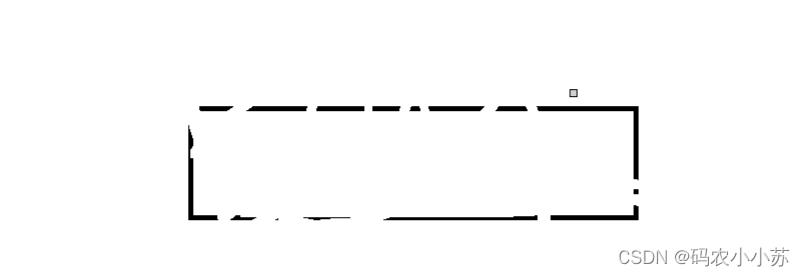
Windows系统下更新后自带的画图软件出现马赛克bug
一.bug的样子🍗 在使用橡皮后,原来写的内容会变成马赛克。而我们希望它是纯白色的。 二.解决方法🍗 第一步 第二步 第三步 三. 解决后的效果🍗 用橡皮擦随便擦都不会出现马赛克了。 更新过后,想用win自带的画图软件会出…...

[HTML]Web前端开发技术6(HTML5、CSS3、JavaScript )DIV与SPAN,盒模型,Overflow——喵喵画网页
希望你开心,希望你健康,希望你幸福,希望你点赞! 最后的最后,关注喵,关注喵,关注喵,佬佬会看到更多有趣的博客哦!!! 喵喵喵,你对我真的…...

SQL练习
建数据库: mysql> create database worker; Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE worker (-> 部门号 int(11) NOT NULL,-> 职工号 int(11) NOT NULL,-> 工作时间 date NOT NULL,-> 工资 float(8,2) NOT NULL,-> 政治面貌…...
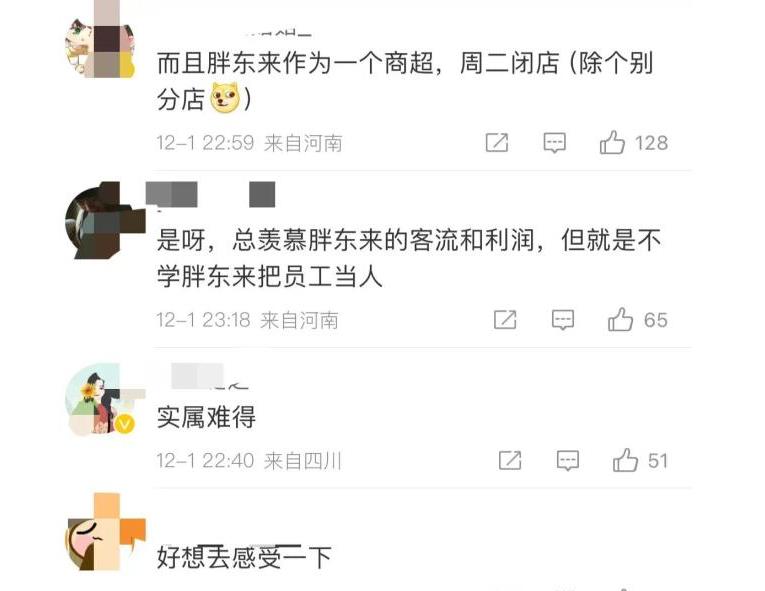
创始人于东来:胖东来员工不想上班,请假不允许不批假!
12月2日早晨,一则关于“胖东来员工不想上班请假不允许不批假”的新闻登上了热搜,引起了广泛关注。熟悉胖东来的网友们可能知道,这并不是这家企业第一次成为热搜的焦点。据白鹿视频12月1日报道,11月25日,河南许昌的胖东…...
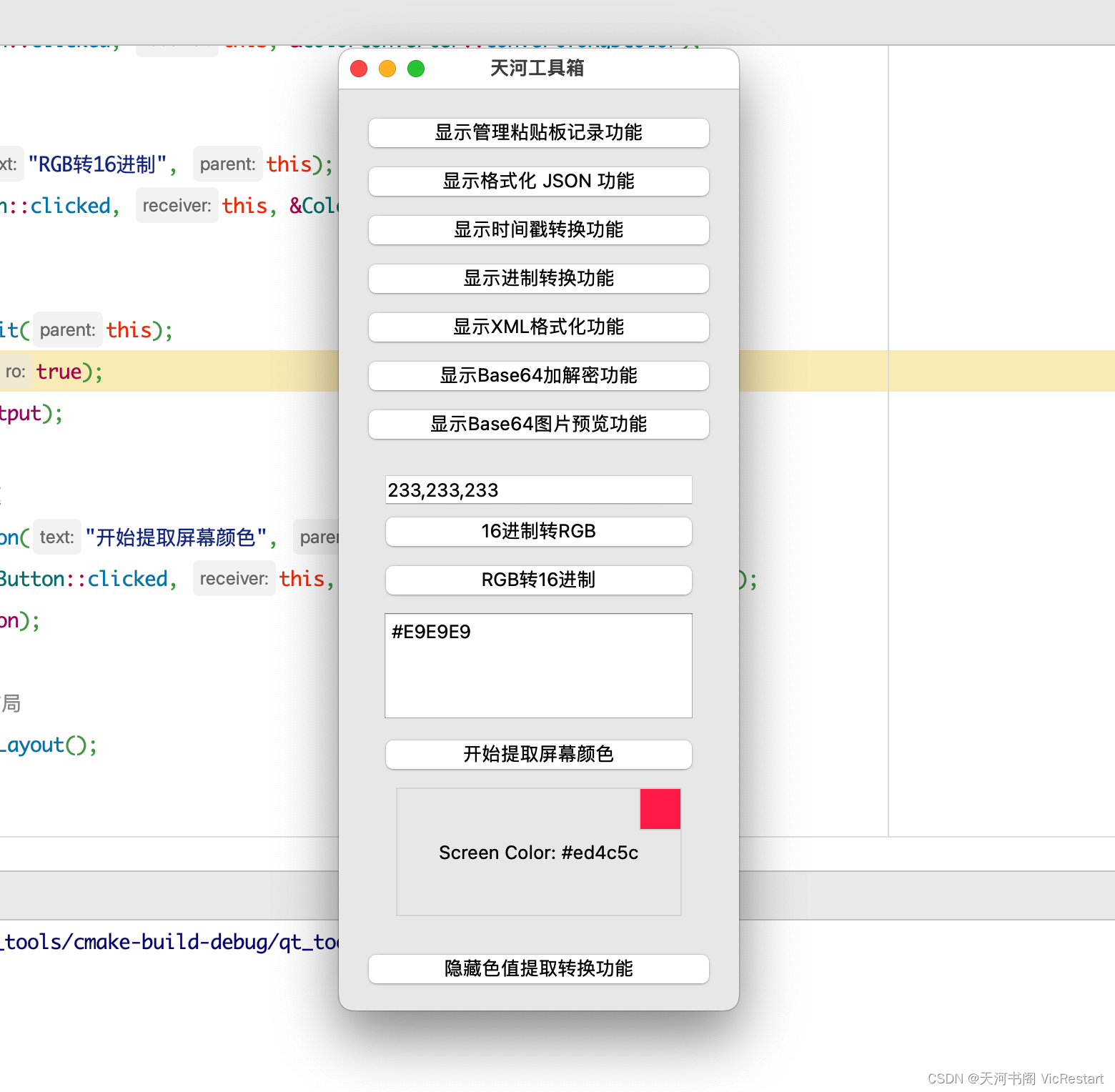
C++学习之路(十五)C++ 用Qt5实现一个工具箱(增加16进制颜色码转换和屏幕颜色提取功能)- 示例代码拆分讲解
上篇文章,我们用 Qt5 实现了在小工具箱中添加了《Base64图片编码预览功能》功能。为了继续丰富我们的工具箱,今天我们就再增加两个平时经常用到的功能吧,就是「 16进制颜色码转RGB文本 」和 「屏幕颜色提取」功能。下面我们就来看看如何来规划…...
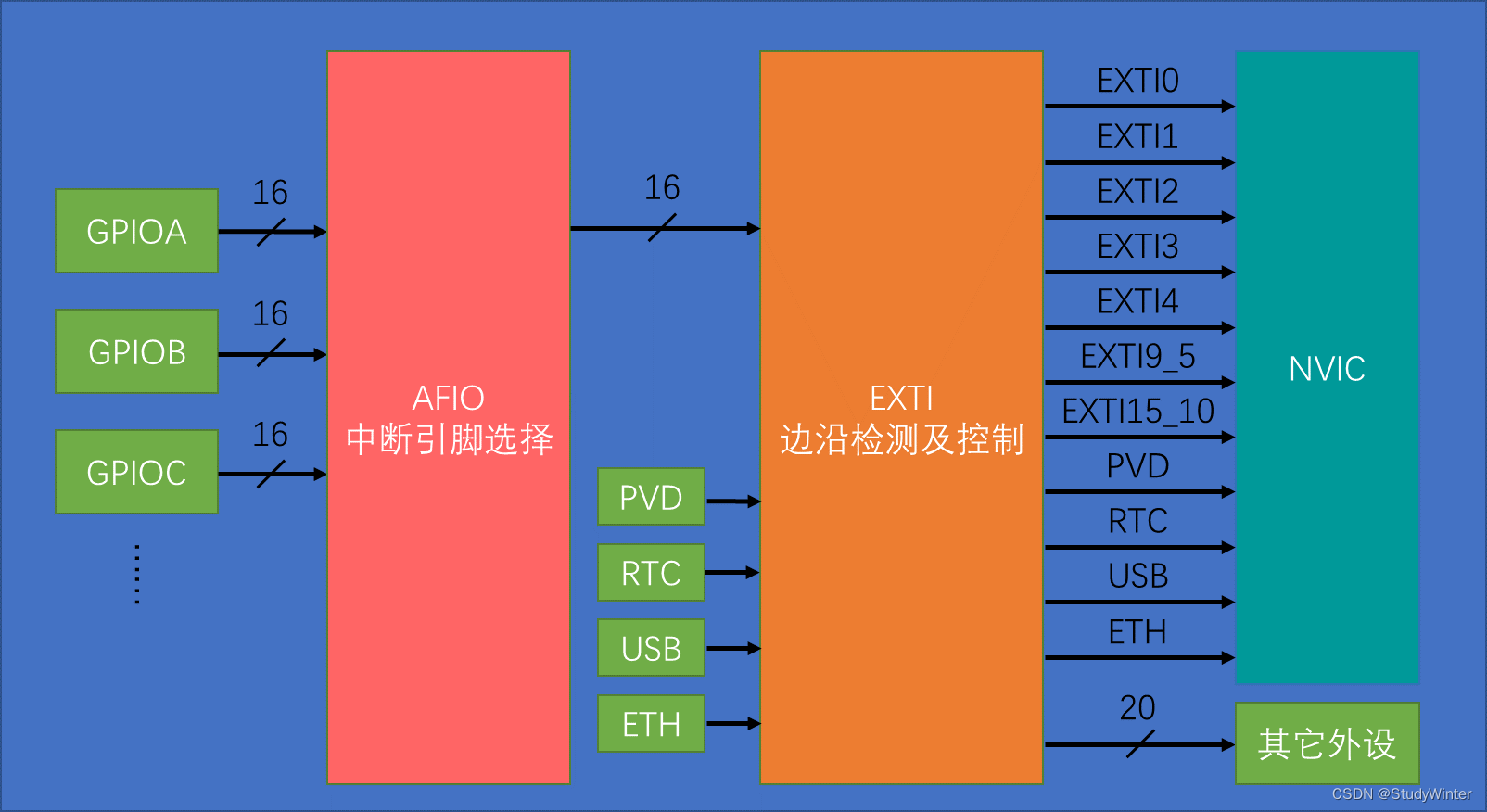
【STM32】EXTI外部中断
1 中断系统 1.1 中断简介 中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续运行。 比如&a…...
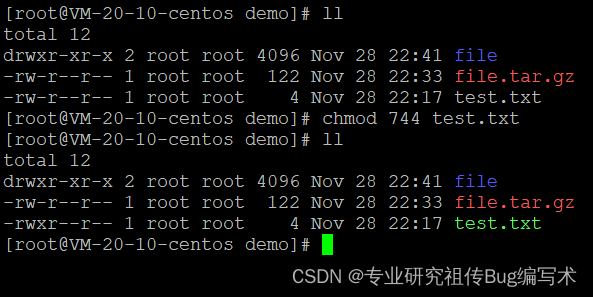
Linux系统的常见命令十三,显示系统进程状态、文件权限、修改文件或目录所有者和所属组命令(ps、chmod和chown)
本文主要介绍Linux系统的显示系统进程状态、文件权限、修改文件或目录所有者和所属组命令,(ps、chmod和chown) 目录 显示系统进程状态文件权限设置(chmod)修改文件或目录所有者和所属组(chown) …...

Python 批量修改文件名
主要步骤 通过os.listdir查看该文件夹下所有的文件(包括文件夹)遍历所有文件,如果是文件夹则跳过,或指定跳过指定文件获取文件扩展名按照需求生成新的文件路径文件名进行重命名 代码示例 # -*- coding: utf-8 -*- import osdef…...

git的基本命令操作超详细解析教程
Git基础教学 1、初始化配置2、初始化仓库3、工作区域和文件状态4、添加和提交文件5、git reset 回退版本6、git diff查看差异7、删除文件git rm8、.gitignore9、本地文件提交到远程仓库10、分支基础 Git:一个开源的分布式版本控制系统,它可以在本地和远程…...
【代码】两阶段鲁棒优化/微电网经济调度入门到编程
内容包括 matlab-yalmipcplex微电网两阶段鲁棒经济调度(刘) matlab-yalmipcplex两阶段鲁棒微电网容量经济优化调度 两阶段鲁棒优化CCG列于约束生成和Benders代码,可扩展改编,复现自原外文论文 【赠送】虚拟储能单元电动汽车建…...

5秒极速转换!m4s转换工具:B站缓存视频合并为MP4的完整指南
5秒极速转换!m4s转换工具:B站缓存视频合并为MP4的完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否在B站缓…...

利用Taotoken模型广场为不同AI应用场景挑选最合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI应用场景挑选最合适的模型 在构建AI驱动的应用时,一个常见的挑战是如何为不同的功能模块…...

Claude Code 架构深度解析:一文搞懂 Sub-Agent、Skill 与底层模型之间的协同机制
Claude Code 架构深度解析:一文搞懂 Sub-Agent、Skill 与底层模型之间的协同机制 Claude Code 凭什么成为 AI 编程工具市场占有率第一?本文深入拆解其内部四层架构——Skill 拦截层、Claude Code 编排器、Sub-Agent 执行层、底层大模型推理层——带你彻底…...

开源数据库 TimescaleDB 2.27.1 发布:性能改进与多项错误修复,官方建议尽快升级
开源数据库 TimescaleDB 2.27.1 版本正式发布,较 2.27.0 版本有性能改进和错误修复,官方建议用户尽快升级。 TimescaleDB 简介 TimescaleDB 是基于 PostgreSQL 构建的开源数据库,打包为 PostgreSQL 扩展程序,可让 SQL 扩展到时间序…...

告别臃肿:Win11Debloat让你的Windows 11系统焕然一新
告别臃肿:Win11Debloat让你的Windows 11系统焕然一新 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cus…...

私有化视频会议平台/视频高清直播点播EasyDSS构建智慧校园音视频协作新生态
在教育数字化转型的关键阶段,智慧校园对音视频协作系统的需求,已从基础的远程沟通,升级为安全可控、体验流畅、管理智能的一体化解决方案。视频直播点播平台EasyDSS凭借技术创新与场景深耕,成为智慧校园建设的核心支撑,…...

Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具
Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug 还在为…...

可变形卷积+深度可分离卷积:手把手复现DAS注意力,在自定义数据集上提升目标检测AP
可变形卷积与深度可分离卷积融合实战:从零实现DAS注意力模块提升目标检测性能 在目标检测领域,如何让模型更精准地聚焦关键区域一直是核心挑战。传统卷积神经网络(CNN)受限于固定感受野,难以动态适应不同目标的几何变…...
如何快速掌握Pixel设备刷机:新手完整教程与PixelFlasher刷机工具指南
如何快速掌握Pixel设备刷机:新手完整教程与PixelFlasher刷机工具指南 【免费下载链接】PixelFlasher Pixel™ phone flashing GUI utility with features. 项目地址: https://gitcode.com/gh_mirrors/pi/PixelFlasher 你是否曾经因为复杂的命令行刷机操作而感…...

终极指南:免费实现Zwift离线骑行模拟的完整方案
终极指南:免费实现Zwift离线骑行模拟的完整方案 【免费下载链接】zwift-offline Use Zwift offline 项目地址: https://gitcode.com/gh_mirrors/zw/zwift-offline 想要在没有网络连接的情况下享受Zwift专业骑行训练吗?Zwift-Offline开源项目为你提…...