SQL练习
建数据库:
mysql> create database worker;
Query OK, 1 row affected (0.00 sec)
mysql> CREATE TABLE worker (-> 部门号 int(11) NOT NULL,-> 职工号 int(11) NOT NULL,-> 工作时间 date NOT NULL,-> 工资 float(8,2) NOT NULL,-> 政治面貌 varchar(10) NOT NULL DEFAULT '群众',-> 姓名 varchar(20) NOT NULL,-> 出生日期 date NOT NULL,-> PRIMARY KEY (`职工号`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;mysql> insert into worker(部门号,职工号,工作时间,工资,政治面貌,姓名,出生日期)-> values (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1'),-> (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8'),-> (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8'),-> (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5'),-> (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30'),-> (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
1、显示所有职工的基本信息。
mysql> select * from worker;
+-----------+-----------+--------------+---------+--------------+--------+--------------+
| 部门号 | 职工号 | 工作时间 | 工资 | 政治面貌 | 姓名 | 出生日期 |
+-----------+-----------+--------------+---------+--------------+--------+--------------+
| 101 | 1001 | 2015-05-04 | 3500.00 | 群众 | 张三 | 1990-07-01 |
| 101 | 1002 | 2017-02-06 | 3200.00 | 团员 | 李四 | 1997-02-08 |
| 102 | 1003 | 2011-01-04 | 8500.00 | 党员 | 王亮 | 1983-06-08 |
| 102 | 1004 | 2016-10-10 | 5500.00 | 群众 | 赵六 | 1994-09-05 |
| 102 | 1005 | 2014-04-01 | 4800.00 | 党员 | 钱七 | 1992-12-30 |
| 102 | 1006 | 2017-05-05 | 4500.00 | 党员 | 孙八 | 1996-09-02 |
+-----------+-----------+--------------+---------+--------------+--------+--------------+
6 rows in set (0.01 sec)
2、查询所有职工所属部门的部门号,不显示重复的部门号。
mysql> select distinct 部门号 from worker;
+-----------+
| 部门号 |
+-----------+
| 101 |
| 102 |
+-----------+
2 rows in set (0.00 sec)
3、求出所有职工的人数。
mysql> select count(职工号) '总人数'from worker;
+-----------+
| 总人数 |
+-----------+
| 6 |
+-----------+
1 row in set (0.00 sec)
4、列出最高工资和最低工资。
mysql> select max(工资) '最高工资',min(工资) '最低工资' from worker;
+--------------+--------------+
| 最高工资 | 最低工资 |
+--------------+--------------+
| 8500.00 | 3200.00 |
+--------------+--------------+5、列出职工的平均工资和总工资。
mysql> select avg(工资) '平均工资',sum(工资) '总工资' from worker;
+--------------+-----------+
| 平均工资 | 总工资 |
+--------------+-----------+
| 5000.000000 | 30000.00 |
+--------------+-----------+6、创建一个只有职工号、姓名和工作时间的新表,名为工作日期表。
+-----------+--------+--------------+
| 职工号 | 姓名 | 工作时间 |
+-----------+--------+--------------+
| 1001 | 张三 | 2015-05-04 |
| 1002 | 李四 | 2017-02-06 |
| 1003 | 王亮 | 2011-01-04 |
| 1004 | 赵六 | 2016-10-10 |
| 1005 | 钱七 | 2014-04-01 |
| 1006 | 孙八 | 2017-05-05 |
+-----------+--------+--------------+
6 rows in set (0.00 sec)
8、列出所有姓刘的职工的职工号、姓名和出生日期。
mysql> select 职工号,姓名,出生日期 from worker-> where 姓名 like '刘%';
Empty set (0.00 sec)9、列出1960年以前出生的职工的姓名、参加工作日期。
mysql> select 姓名,工作时间 from worker where 出生日期<'1960-01-01';
Empty set (0.00 sec)
10、列出工资在1000-2000之间的所有职工姓名。
mysql> select 姓名 from worker where 工资>1000 and 工资<2000;
Empty set (0.00 sec)11、列出所有陈姓和李姓的职工姓名。
mysql> select 姓名 from worker where 姓名 like '陈%' or 姓名 like '李%';
+--------+
| 姓名 |
+--------+
| 李四 |
+--------+
1 row in set (0.00 sec)12、列出所有部门号为2和3的职工号、姓名、党员否。
mysql> select 职工号,姓名,政治面貌 from worker where 部门号='102' or 部门号='103';
+-----------+--------+--------------+
| 职工号 | 姓名 | 政治面貌 |
+-----------+--------+--------------+
| 1003 | 王亮 | 党员 |
| 1004 | 赵六 | 群众 |
| 1005 | 钱七 | 党员 |
| 1006 | 孙八 | 党员 |
+-----------+--------+--------------+
4 rows in set (0.00 sec)
13、将职工表worker中的职工按出生的先后顺序排序。
mysql> select 姓名 , 出生日期 from worker order by 出生日期;
+--------+--------------+
| 姓名 | 出生日期 |
+--------+--------------+
| 王亮 | 1983-06-08 |
| 张三 | 1990-07-01 |
| 钱七 | 1992-12-30 |
| 赵六 | 1994-09-05 |
| 孙八 | 1996-09-02 |
| 李四 | 1997-02-08 |
+--------+--------------+14、显示工资最高的前3名职工的职工号和姓名。
mysql> select 职工号,姓名 ,工资 from worker order by 工资 desc limit 3;
+-----------+--------+---------+
| 职工号 | 姓名 | 工资 |
+-----------+--------+---------+
| 1003 | 王亮 | 8500.00 |
| 1004 | 赵六 | 5500.00 |
| 1005 | 钱七 | 4800.00 |
+-----------+--------+---------+
3 rows in set (0.01 sec)15、求出各部门党员的人数。
mysql> select count( 政治面貌) ,部门号 from worker -> group by 部门号;
+----------------------+-----------+
| count( 政治面貌) | 部门号 |
+----------------------+-----------+
| 2 | 101 |
| 4 | 102 |
+----------------------+-----------+
2 rows in set (0.00 sec)16、统计各部门的工资和平均工资
mysql> select 部门号,sum(工资) 总工资,avg(工资) 平均工资 from worker group by 部门号;
+-----------+-----------+--------------+
| 部门号 | 总工资 | 平均工资 |
+-----------+-----------+--------------+
| 101 | 6700.00 | 3350.000000 |
| 102 | 23300.00 | 5825.000000 |
+-----------+-----------+--------------+
2 rows in set (0.00 sec)素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等
CREATE TABLE `worker` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
CREATE TABLE worker (
部门号 int(11) NOT NULL,
职工号 int(11) NOT NULL,
工作时间 date NOT NULL,
工资 float(8,2) NOT NULL,
政治面貌 varchar(10) NOT NULL DEFAULT '群众',
姓名 varchar(20) NOT NULL,
出生日期 date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出
生日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出
生日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出
生日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出
生日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出
生日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出
生日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
相关文章:

SQL练习
建数据库: mysql> create database worker; Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE worker (-> 部门号 int(11) NOT NULL,-> 职工号 int(11) NOT NULL,-> 工作时间 date NOT NULL,-> 工资 float(8,2) NOT NULL,-> 政治面貌…...
创始人于东来:胖东来员工不想上班,请假不允许不批假!
12月2日早晨,一则关于“胖东来员工不想上班请假不允许不批假”的新闻登上了热搜,引起了广泛关注。熟悉胖东来的网友们可能知道,这并不是这家企业第一次成为热搜的焦点。据白鹿视频12月1日报道,11月25日,河南许昌的胖东…...
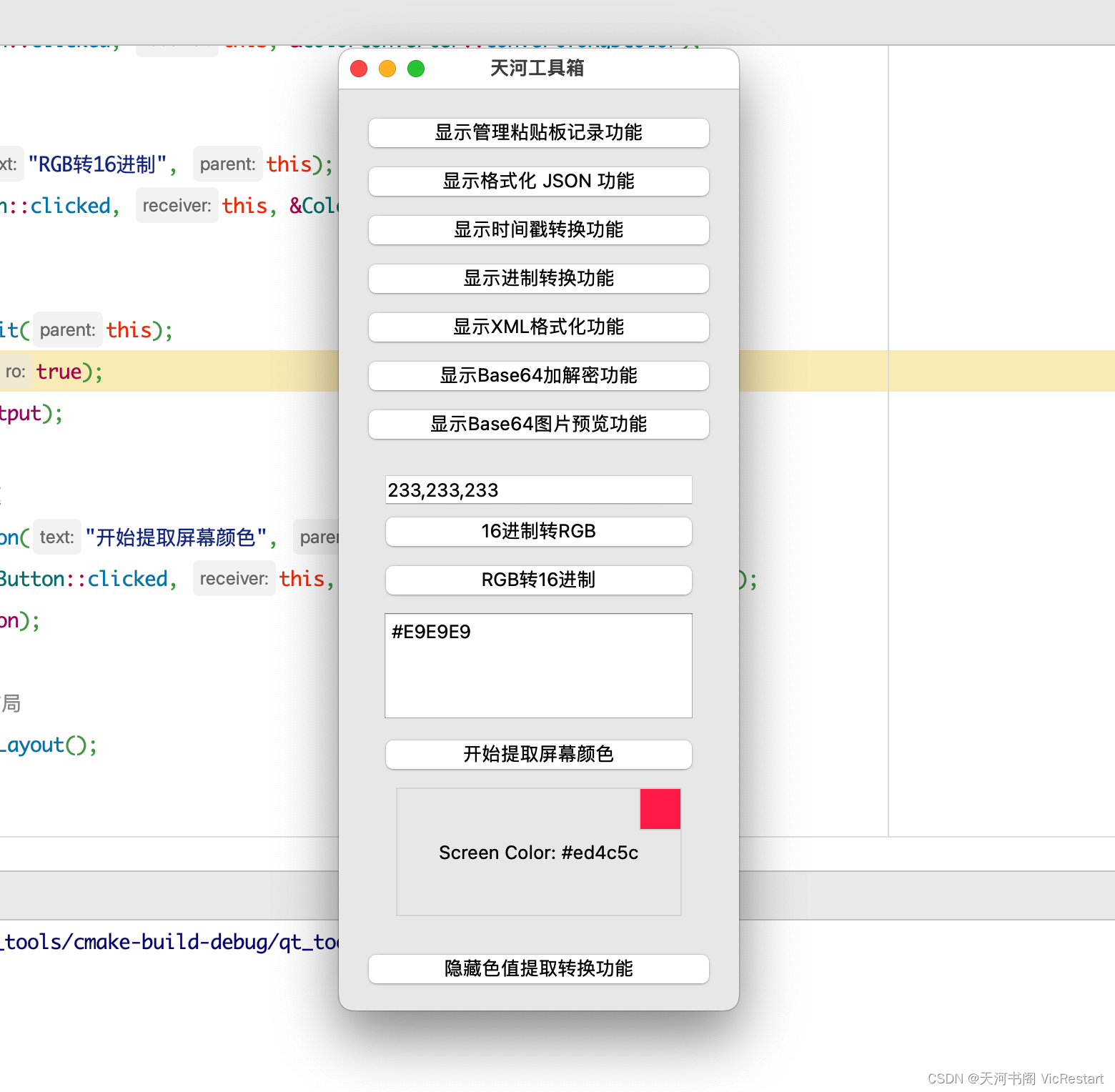
C++学习之路(十五)C++ 用Qt5实现一个工具箱(增加16进制颜色码转换和屏幕颜色提取功能)- 示例代码拆分讲解
上篇文章,我们用 Qt5 实现了在小工具箱中添加了《Base64图片编码预览功能》功能。为了继续丰富我们的工具箱,今天我们就再增加两个平时经常用到的功能吧,就是「 16进制颜色码转RGB文本 」和 「屏幕颜色提取」功能。下面我们就来看看如何来规划…...
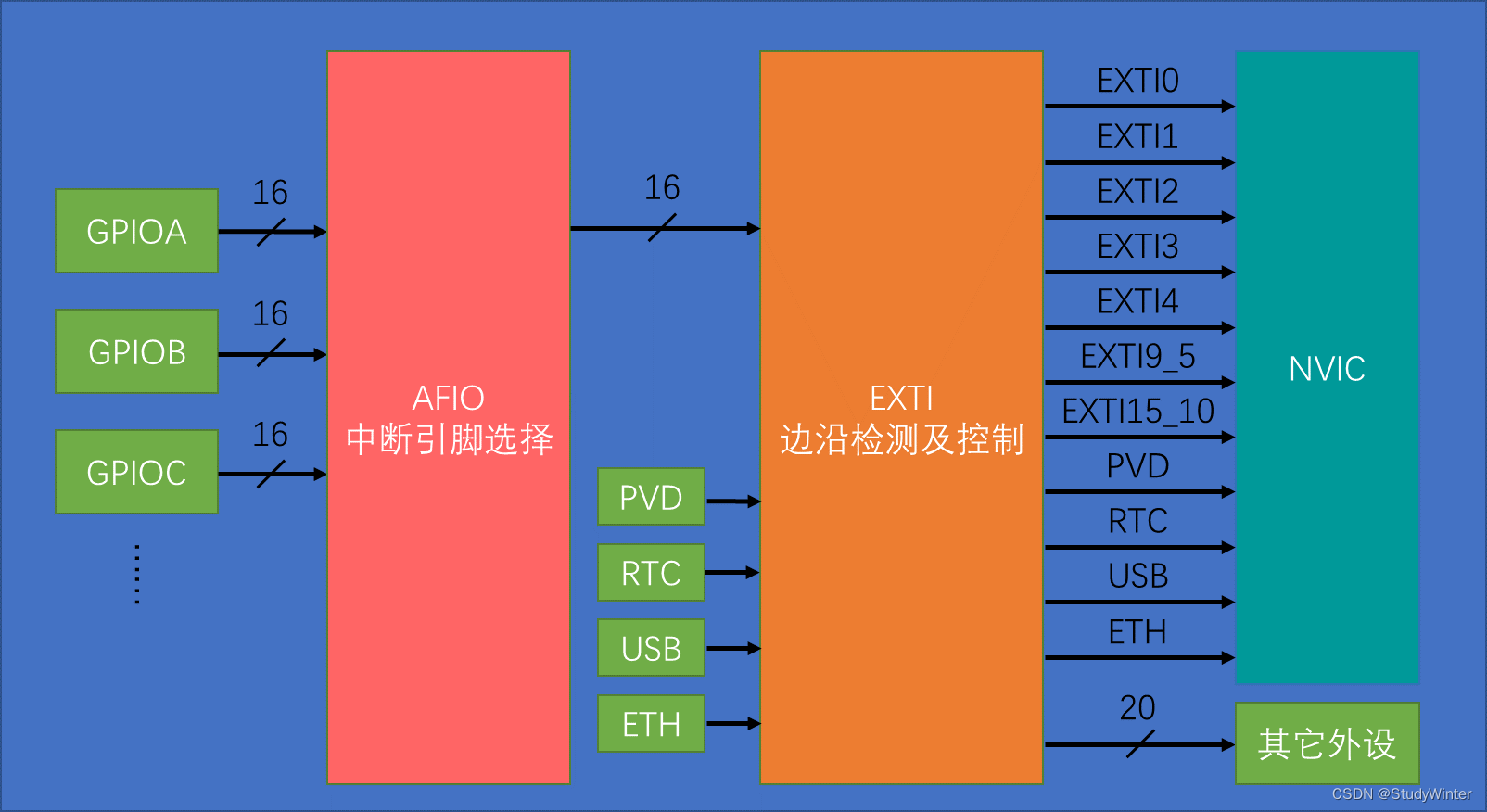
【STM32】EXTI外部中断
1 中断系统 1.1 中断简介 中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续运行。 比如&a…...
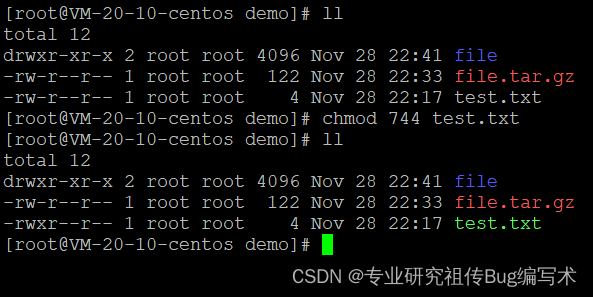
Linux系统的常见命令十三,显示系统进程状态、文件权限、修改文件或目录所有者和所属组命令(ps、chmod和chown)
本文主要介绍Linux系统的显示系统进程状态、文件权限、修改文件或目录所有者和所属组命令,(ps、chmod和chown) 目录 显示系统进程状态文件权限设置(chmod)修改文件或目录所有者和所属组(chown) …...

Python 批量修改文件名
主要步骤 通过os.listdir查看该文件夹下所有的文件(包括文件夹)遍历所有文件,如果是文件夹则跳过,或指定跳过指定文件获取文件扩展名按照需求生成新的文件路径文件名进行重命名 代码示例 # -*- coding: utf-8 -*- import osdef…...

git的基本命令操作超详细解析教程
Git基础教学 1、初始化配置2、初始化仓库3、工作区域和文件状态4、添加和提交文件5、git reset 回退版本6、git diff查看差异7、删除文件git rm8、.gitignore9、本地文件提交到远程仓库10、分支基础 Git:一个开源的分布式版本控制系统,它可以在本地和远程…...
【代码】两阶段鲁棒优化/微电网经济调度入门到编程
内容包括 matlab-yalmipcplex微电网两阶段鲁棒经济调度(刘) matlab-yalmipcplex两阶段鲁棒微电网容量经济优化调度 两阶段鲁棒优化CCG列于约束生成和Benders代码,可扩展改编,复现自原外文论文 【赠送】虚拟储能单元电动汽车建…...
(私人复习资料))
【图论】重庆大学图论与应用课程期末复习资料2-各章考点(填空证明部分)(私人复习资料)
图论各章考点 一、图与网络的基本概念二、树三、连通性四、路径算法五、匹配六、行遍性问题七、平面图 一、图与网络的基本概念 生成子图:生成子图 G ’ G’ G’中顶点个数V’必须和原图G中V的数量相同,而 E ’ ∈ E E’∈E E’∈E即可。顶点集导出子图…...

基于Intel® AI Analytics Toolkits的智能视频监控系统
【oneAPI DevSummit & OpenVINODevCon联合黑客松】 跳转链接:https://marketing.csdn.net/p/d2322260c8d99ae24795f727e70e4d3d 目录 1方案背景 2方案描述 3需求分析 4技术可行性分析 5详细设计5.1数据采集 5.2视频解码与帧提取 5.3人脸检测 5.4行为识别…...

深度学习中的注意力机制:原理、应用与实践
深度学习中的注意力机制:原理、应用与实践 摘要: 本文将深入探讨深度学习中的注意力机制,包括其原理、应用领域和实践方法。我们将通过详细的解析和代码示例,帮助读者更好地理解和应用注意力机制,从而提升深度学习模…...

将本地项目推送到github
欢迎大家到我的博客浏览。将本地项目推送到github | YinKais Blog 本地项目上传至 GitHub<!--more--> 1、进入项目根目录,初始化本地仓库 git init 2、创建密钥:创建 .ssh 文件夹,并进入 .ssh 文件夹 mkdir .ssh cd .ssh/ 3、生成…...

[读论文]meshGPT
概述 任务:无条件生成mesh (无颜色)数据集:shapenet v2方法:先trian一个auto encoder,用来获得code book;然后trian一个自回归的transformermesh表达:face序列。face按规定的顺序&a…...

反序列化漏洞详解(一)
目录 一、php面向对象 二、类 2.1 类的定义 2.2 类的修饰符介绍 三、序列化 3.1 序列化的作用 3.2 序列化之后的表达方式/格式 ① 简单序列化 ② 数组序列化 ③ 对象序列化 ④ 私有修饰符序列化 ⑤ 保护修饰符序列化 ⑥ 成员属性调用对象 序列化 四、反序列化 …...

键盘打字盲打练习系列之指法练习——2
一.欢迎来到我的酒馆 盲打,指法练习! 目录 一.欢迎来到我的酒馆二.开始练习 二.开始练习 前面一个章节简单地介绍了基准键位、字母键位和数字符号键位指法,在这个章节详细介绍指法。有了前面的章节的基础练习,相信大家对盲打也有了…...
小程序----使用图表显示数据--canvas
需求:在小程序上实现数据可视化 思路:本来想用的是echarts或者相关的可视化插件,但因为用的是vue3,大多数插件不支持,所以用了echarts,但最后打包的时候说包太大超过2M无法上传,百度了一下&…...
⭐ Unity 开发bug —— 打包后shader失效或者bug (我这里用Shader做两张图片的合并发现了问题)
1.这里我代码没啥问题~~~编辑器里也没毛病 void Start(){// 加载底图和上层图片string backgroundImagePath Application.streamingAssetsPath "/background.jpg";Texture2D backgroundTexture new Texture2D(2, 2);byte[] backgroundImageData System.IO.File.R…...

document
原贴连接 1.在整个文档范围内查询元素节点 功能API返回值根据id值查询document.getElementById(“id值”)一个具体的元素节根据标签名查询document.getElementsByTagName(“标签名”)元素节点数组根据name属性值查询document.getElementsByName(“name值”)元素节点数组根据类…...

NodeJS(二):npm包管理工具、yarn、npx、pnpm工具等
目录 (一)npm包管理工具 1.了解npm 2.npm的配置文件 常见的配置属性 scripts属性*** 依赖的版本管理 3.npm安装包的细节 4.package-lock文件 5.npm install原理** 6.npm的其他命令 (二) 其他包管理工具 1.yarn工具 基本指令 2.cnpm工具 3.npx工具 (1)执行本地…...

day3 移出链表中值为x的节点
ListNode* removeElements(ListNode* head, int val) { ListNode* dummyHead new ListNode(0); // 设置一个虚拟头结点 dummyHead->next head; // 将虚拟头结点指向head,这样方便后面做删除操作 ListNode* cur dummyHead; while (cur->next ! NULL…...

洛雪音乐六音音源修复完整指南:快速恢复音乐播放功能
洛雪音乐六音音源修复完整指南:快速恢复音乐播放功能 【免费下载链接】New_lxmusic_source 六音音源修复版 项目地址: https://gitcode.com/gh_mirrors/ne/New_lxmusic_source 洛雪音乐是一款广受欢迎的开源音乐播放器,但近期许多用户遇到了六音音…...

多账号流量内容运营的数据归因与ROI优化:从经验驱动到算法决策的技术转型
📌 当一个团队同时运营20个以上的新媒体账号时,最大的问题不是"怎么发",而是"发了之后怎么知道哪条有用"。本文从数据工程角度,拆解多账号流量内容矩阵如何通过数据归因模型实现ROI优化,以星链引擎…...

终极macOS Windows启动盘制作工具:WinDiskWriter完整指南
终极macOS Windows启动盘制作工具:WinDiskWriter完整指南 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI & Legac…...

美国签证预约神器:3步告别熬夜抢号,智能锁定更早面试时间
美国签证预约神器:3步告别熬夜抢号,智能锁定更早面试时间 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 还在为美国签证预约的漫长等待而焦虑吗?每天手动刷新页面却总是错过最佳…...

告别繁琐操作:Super IO插件实现Blender批量导入导出智能化解决方案
告别繁琐操作:Super IO插件实现Blender批量导入导出智能化解决方案 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 在3D建模工作流中,最耗时的往往不是创意设计…...

企业微信SCRM与客户管理系统推荐:2026年这12家值得关注
2026年,一个企业要选客户管理系统,第一个要回答的问题是:你的客户在哪里?如果答案是"微信",那企业微信SCRM就是最直接的路径——而在这个领域,微盛企微管家作为企业微信最大ISV,服务了…...

提升3倍效率的Windows桌面端酷安社区解决方案:基于UWP平台的高性能第三方客户端
提升3倍效率的Windows桌面端酷安社区解决方案:基于UWP平台的高性能第三方客户端 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP Coolapk-UWP是一款基于UWP平台的第三方酷安客户…...

多模态模型中图像生成器使用的扩散模型的组件
多模态模型中图像生成器使用的扩散模型组件 多模态模型中的图像生成器,通常不是一个单独网络,而是一套 条件扩散生成系统。典型输入是文本、图像、mask、bbox、姿态、深度图、边缘图、语义图、视频帧或多模态 embedding,输出是目标图像。 最常…...

Mac用户必看:3分钟解决NTFS硬盘读写难题,免费开源工具Nigate完整指南
Mac用户必看:3分钟解决NTFS硬盘读写难题,免费开源工具Nigate完整指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mo…...
)
Perplexity语法查询功能深度解析(官方未公开的7个语法边界场景)
更多请点击: https://codechina.net 第一章:Perplexity语法查询功能的核心定位与设计哲学 Perplexity语法查询功能并非通用搜索引擎的简单变体,而是面向技术深度用户的语义化推理引擎。其核心定位在于将自然语言提问转化为可执行、可验证、可…...