图注意网络GAT理解及Pytorch代码实现【PyGAT代码详细注释】
文章目录
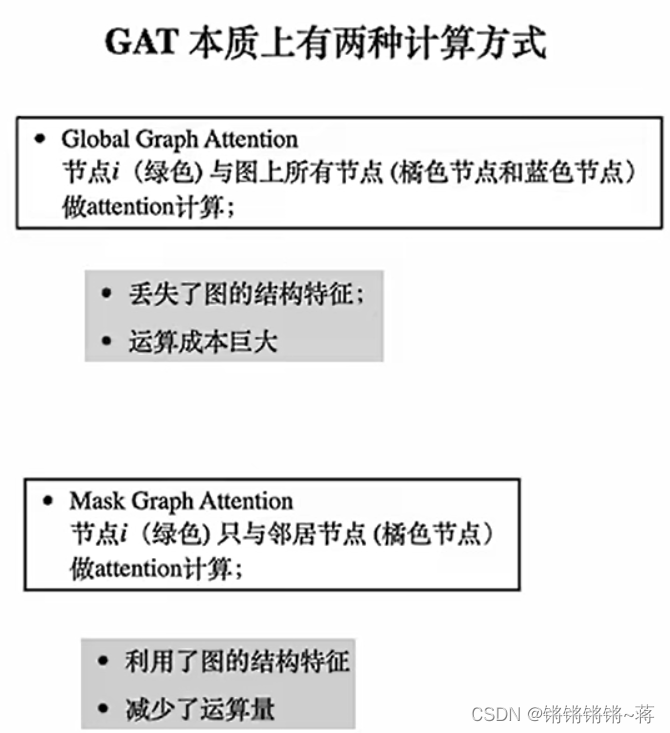
- GAT
- 代码实现【PyGAT】
- GraphAttentionLayer【一个图注意力层实现】
- 用上面实现的单层网络测试
- 加入Multi-head机制的GAT
- 对数据集Cora的处理
- csr_matrix()处理稀疏矩阵
- encode_onehot()对label编号
- build graph
- 邻接矩阵构造
- GAT的推广
GAT
题:Graph Attention Networks
摘要:
提出了图形注意网络(GAT) ,这是一种基于图结构数据的新型神经网络结构,利用掩蔽的自我注意层来解决基于图卷积或其近似的先前方法的缺点。通过叠加层,节点能够参与其邻域的特征,我们能够(隐式地)为邻域中的不同节点指定不同的权重,而不需要任何代价高昂的矩阵操作(如反演) ,或者依赖于预先知道图的结构。通过这种方法,我们同时解决了基于谱的图形神经网络的几个关键问题,并使我们的模型容易地适用于归纳和转导问题。我们的 GAT 模型已经实现或匹配了四个已建立的转导和归纳图基准的最新结果: Cora,Citeseer 和 Pubmed 引用网络数据集,以及protein-protein interaction dataset(其中测试图在训练期间保持不可见)。
在Paper with code 网址,可找到对应论文和github源码,原论文使用TensorFlow实现,本篇主要对Pytorch版本的 PyGAT附详细注释帮助理解和测试。
GitHUb: keras版本实现
Pytorch版本实现 PyGAT
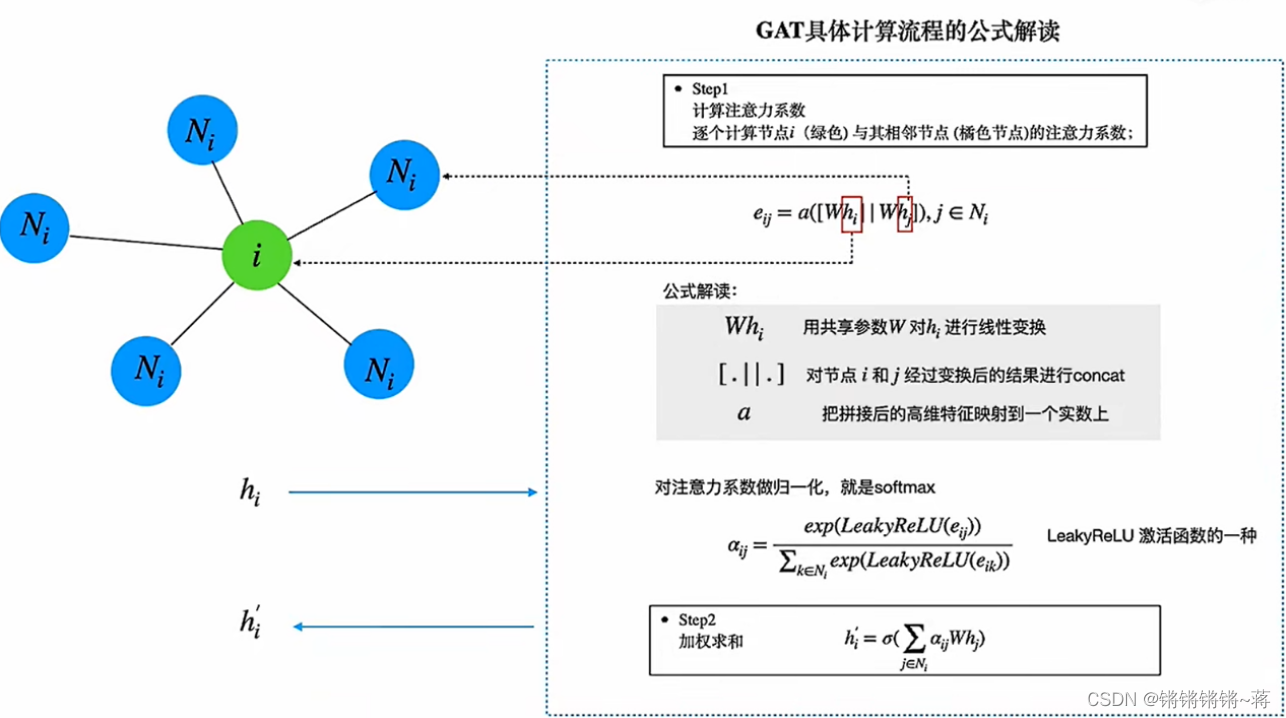
截图及下文代码注释参考自视频:GAT详解及代码实现
视频中的eij的实现与源码不同,视频中是先拼接两个W,再与a乘;
源码在_prepare_attentional_mechanism_input()函数中先分别与a乘,再拼接。
代码实现【PyGAT】
在PyGAT :
- layers.py中定义Simple GAT layer实现(GraphAttentionLayer)和Sparse version GAT layer实现(SpGraphAttentionLayer)。
- models.py 实现两个版本加入Multi-head机制
- trains.py 使用model定义的GAT构建模型进行训练,使用cora数据集
GraphAttentionLayer【一个图注意力层实现】
class GraphAttentionLayer(nn.Module):"""Simple GAT layer, similar to https://arxiv.org/abs/1710.10903"""def __init__(self, in_features, out_features, dropout, alpha, concat=True):super(GraphAttentionLayer, self).__init__()self.dropout = dropoutself.in_features = in_features#结点向量的特征维度self.out_features = out_features#经过GAT之后的特征维度self.alpha = alpha#dropout参数self.concat = concat#LeakyReLU参数# 定义可训练参数,即论文中的W和aself.W = nn.Parameter(torch.empty(size=(in_features, out_features)))nn.init.xavier_uniform_(self.W.data, gain=1.414)# xavier初始化self.a = nn.Parameter(torch.empty(size=(2*out_features, 1)))nn.init.xavier_uniform_(self.a.data, gain=1.414)# xavier初始化# 定义leakyReLU激活函数self.leakyrelu = nn.LeakyReLU(self.alpha)def forward(self, h, adj):'''adj图邻接矩阵,维度[N,N]非零即一h.shape: (N, in_features), self.W.shape:(in_features,out_features)Wh.shape: (N, out_features)'''Wh = torch.mm(h, self.W) # 对应eij的计算公式e = self._prepare_attentional_mechanism_input(Wh)#对应LeakyReLU(eij)计算公式zero_vec = -9e15*torch.ones_like(e)#将没有链接的边设置为负无穷attention = torch.where(adj > 0, e, zero_vec)#[N,N]# 表示如果邻接矩阵元素大于0时,则两个节点有连接,该位置的注意力系数保留# 否则需要mask设置为非常小的值,因为softmax的时候这个最小值会不考虑attention = F.softmax(attention, dim=1)# softmax形状保持不变[N,N],得到归一化的注意力全忠!attention = F.dropout(attention, self.dropout, training=self.training)# dropout,防止过拟合h_prime = torch.matmul(attention, Wh)#[N,N].[N,out_features]=>[N,out_features]# 得到由周围节点通过注意力权重进行更新后的表示if self.concat:return F.elu(h_prime)else:return h_primedef _prepare_attentional_mechanism_input(self, Wh):# Wh.shape (N, out_feature)# self.a.shape (2 * out_feature, 1)# Wh1&2.shape (N, 1)# e.shape (N, N)# 先分别与a相乘再进行拼接Wh1 = torch.matmul(Wh, self.a[:self.out_features, :])Wh2 = torch.matmul(Wh, self.a[self.out_features:, :])# broadcast adde = Wh1 + Wh2.Treturn self.leakyrelu(e)def __repr__(self):return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'用上面实现的单层网络测试
x = torch.randn(6,10)
adj=torch.tensor([[0,1,1,0,0,0],[1,0,1,0,0,0],[1,1,0,1,0,0],[0,0,1,0,1,1],[0,0,0,1,0,0,],[0,0,0,1,1,0]])
my_gat = GraphAttentionLayer(10,5,0.2,0.2)
print(my_gat(x,adj))
输出:
tensor([[-0.2965, 2.8110, -0.6680, -0.9643, -0.9882],[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[-0.4981, -0.7515, 1.1159, 0.3546, 1.3592],[ 0.4679, 1.7208, 0.3084, -0.5331, -0.1291],[-0.4375, -0.8778, 1.1767, -0.5869, 1.5154],[-0.2164, -0.5897, 0.4988, -0.3125, 0.6423]], grad_fn=<EluBackward>)
加入Multi-head机制的GAT
用不同head捕捉不同特征,使模型有更好的拟合能力。
class GAT(nn.Module):def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):"""Dense version of GAT."""super(GAT, self).__init__()self.dropout = dropout# 加入Multi-head机制self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]for i, attention in enumerate(self.attentions):self.add_module('attention_{}'.format(i), attention)self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False)def forward(self, x, adj):x = F.dropout(x, self.dropout, training=self.training)x = torch.cat([att(x, adj) for att in self.attentions], dim=1)x = F.dropout(x, self.dropout, training=self.training)x = F.elu(self.out_att(x, adj))return F.log_softmax(x, dim=1)对数据集Cora的处理
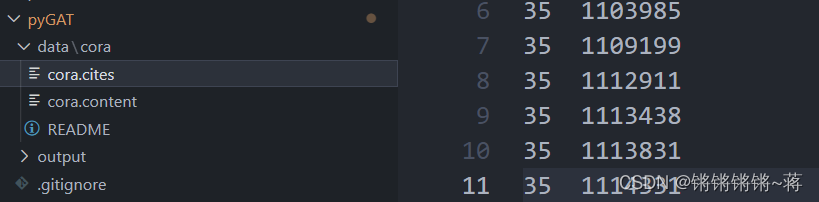
数据集中两个文件,cites:比如上图11行:编号25和编号1114331的文章
content文件:如下图,每篇文章的id、features及类别

csr_matrix()处理稀疏矩阵
utils.py中对数据进行的处理
#数据是稀疏的,csr_matrix操作从行开始将1的位置取出来,对数据进行压缩
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
labels = encode_onehot(idx_features_labels[:, -1])

encode_onehot()对label编号
有7个类别,通过classes_dict是7*7的对角阵把每个类别映射成不同向量,对所有label进行编号,再将编号转换为one_hot向量

def encode_onehot(labels):# The classes must be sorted before encoding to enable static class encoding.# In other words, make sure the first class always maps to index 0.classes = sorted(list(set(labels)))classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)}labels_onehot = np.array(list(map(classes_dict.get, labels)), dtype=np.int32)return labels_onehot
build graph
见注释:
# build graphidx = np.array(idx_features_labels[:, 0], dtype=np.int32)#获取所有文章ididx_map = {j: i for i, j in enumerate(idx)}#按文章数目,对id重新映射# 读取数据集中文章和文章直接的引用关系edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset), dtype=np.int32)# 根据idx_map,将文章引用关系也重新映射edges = np.array(list(map(idx_map.get, edges_unordered.flatten())), dtype=np.int32).reshape(edges_unordered.shape)adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), shape=(labels.shape[0], labels.shape[0]), dtype=np.float32)# build symmetric adjacency matrix 生成邻接矩阵adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)features = normalize_features(features)adj = normalize_adj(adj + sp.eye(adj.shape[0]))邻接矩阵构造
csr_matrix()只记录了(0,1)1,忽略了(1,0)1。所以需要coo_matrix()操作!才能还原出无向图的邻接矩阵!

本文的一些代码注释及截图还可见视频
一个拓展:
GAT的推广
GAT的推广
GAT仅仅是应用在了单层图结构网络上,我们是否可以将它推广到多层网络结构呢?
这里我们假设一个有N层网络的结构,每层网络都定义了相同的节点,但是节点之间的关系有所差异。举一个简单的例子,假设有一个用户关系型网络,每层网络的节点都被定义成了网络中的用户,网络的第一层视图的关系可以定义为,两个用户之间是否具有好友关系;网络的第二层视图可以定义为,你评论过我的动态;网络的第三层视图可以定义为你转发过我的动态;第四层关系可以定义为,你at过我等等。
通过这样的定义我们就完成了一个多层网络的构建,他们共享相同的节点,但又分别具有不同的邻边,如果我们分别处理每一层视图视图,然后将他们得出的节点表示单纯相加的话,就可能会失去不同视图之间的协作关系,降低分类(预测)的精度。
基于以上观点,我们提出了一种新的方法:首先在每一层单视图中应用GAT进行学习,并计算出每层视图的节点表示。之后再不同视图之间引入attention机制来让网络自行学习不同视图的权重。之后根据学习的权重,将各个视图加权相加得到全局节点表示并进行后续的诸如节点表示,链接预测等任务。
同时,因为不同视图共享同样的节点,即使每一层视图都表示了不同的节点关系,最终得到的每一层的节点嵌入表示应具有一定的相关性。基于以上理论,我们在每层GAT的网络参数间引入正则化项来约束参数,使其向互相相近的方向学习。大致的网络流程图如下:
这部分来源于 链接:https://www.jianshu.com/p/d5d366ba1a57 来源:简书
相关文章:
图注意网络GAT理解及Pytorch代码实现【PyGAT代码详细注释】
文章目录GAT代码实现【PyGAT】GraphAttentionLayer【一个图注意力层实现】用上面实现的单层网络测试加入Multi-head机制的GAT对数据集Cora的处理csr_matrix()处理稀疏矩阵encode_onehot()对label编号build graph邻接矩阵构造GAT的推广GAT 题:Graph Attention Netwo…...

项目成本管理中的常见误区及解决方案
做过项目的人都明白,项目实施时间一般很长,在实施期间总有很多项目结果不尽人意的问题。要使一个项目取得成功,就要结合很多因素一起才能作用,其中做好项目成本的管理就是最重要的步骤之一,下面列出了常见的项目成本管…...

墨天轮2022年度数据库获奖名单
2022年,国家相继从高位部署、省级试点布局、地市重点深入三个维度,颁布了多项中国数据库行业发展的利好政策。但是我们也能清晰地看到,中国数据库行业发展之路道阻且长,而道路上的“拦路虎”之一则是生态。中国数据库的发展需要多…...
仓储调度|库存管理系统
技术:Java、JSP等摘要:随着电子商务技术和网络技术的快速发展,现代物流技术也在不断进步。物流技术是指与物流要素活动有关的所有专业技术的总称,包括各种操作方法、管理技能等,物流业采用某些现代信息技术方面的成功经…...

Canvas入门-01
导读: 读完全文需要2min。通过这篇文章,你可以了解到以下内容: Canvas标签基本属性如何使用Canvas画矩形、圆形、线条、曲线、笑脸😊 如果你曾经了解过Canvas,可以对照目录回忆一下能否回答上来 毕竟带着问题学习最有效…...

运算符优先级
醋坛酸味罐,位落跳福豆 醋:初等运算符: () [] -> . 坛:单目运算符: - ~ – * & ! sizeof 右结合 酸:算术运算符: - * / % 味:位移运算符:>> << …...
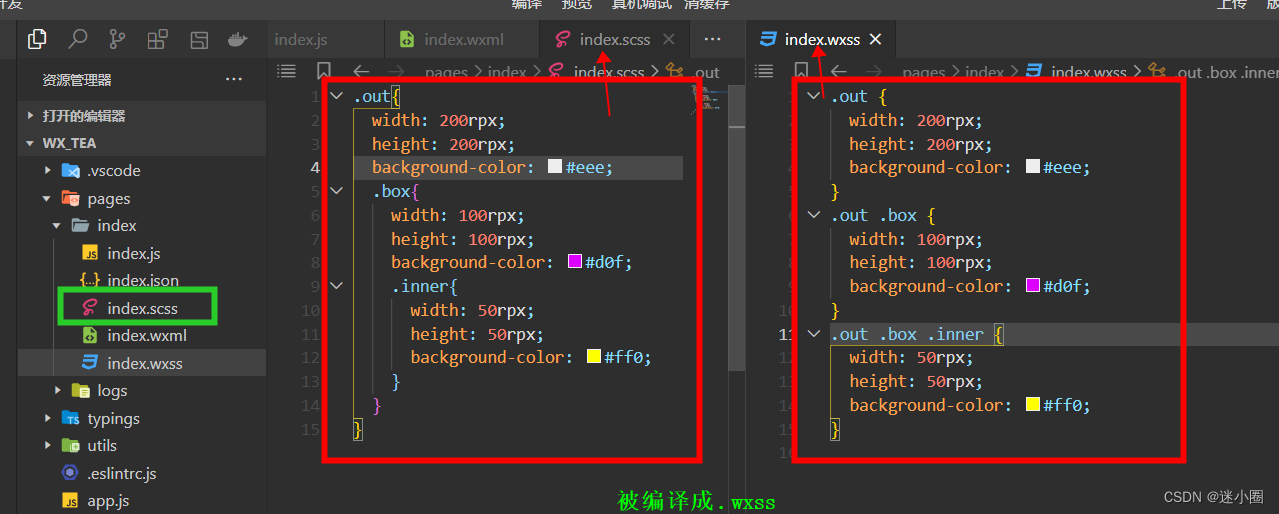
微信小程序使用scss编译wxss文件的配置步骤
文章目录1、在 vscode 中搜索 easysass 插件并安装2、在微信开发工具中导入安装的easysass插件3、修改 spook.easysass-0.0.6/package.json 文件中的配置4、重启开发者工具,就可用使用了微信小程序开发者工具集成了 vscode 编辑器,可以使用 vscode 中众多…...

一步一步教你如何使用 Visual Studio Code 编译一段 C# 代码
以下是一步一步教你如何使用 Visual Studio Code 编写使用 C# 语言输出当前日期和时间的代码: 1、下载并安装 .NET SDK。您可以从 Microsoft 官网下载并安装它。 2、打开 Visual Studio Code,并安装 C# 扩展。您可以在 Visual Studio Code 中通过扩展菜…...

vue-cli中的环境变量注意点
在客户端侧代码中使用环境变量只有以 VUE_APP_ 开头的变量会被 webpack.DefinePlugin 静态嵌入到客户端侧的包中。你可以在应用的代码中这样访问它们:console.log(process.env.VUE_APP_SECRET)在构建过程中,process.env.VUE_APP_SECRET 将会被相应的值所…...

2.3数据类型
文章目录1. 命名规则2.字符3.数字4.日期5.图片1. 命名规则 字段名必须以字母开头,尽量不要使用拼音长度不能超过30个字符(不同数据库,不同版本会有不同)不能使用SQL的保留字,如where,order,group只能使用如下字符a-z、…...
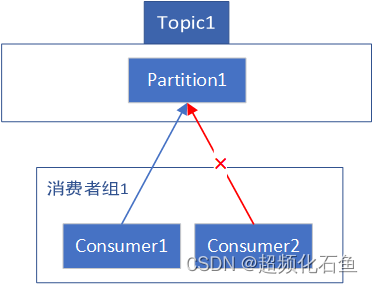
Kafka基本概念
什么是Kafka Kafka是一个消息系统。它可以集中收集生产者的消息,并由消费者按需获取。在Kafka中,也将消息称为日志(log)。 一个系统,若仅有一类或者少量的消息,可直接进行发送和接收。 随着业务量日益复杂,消息的种类…...

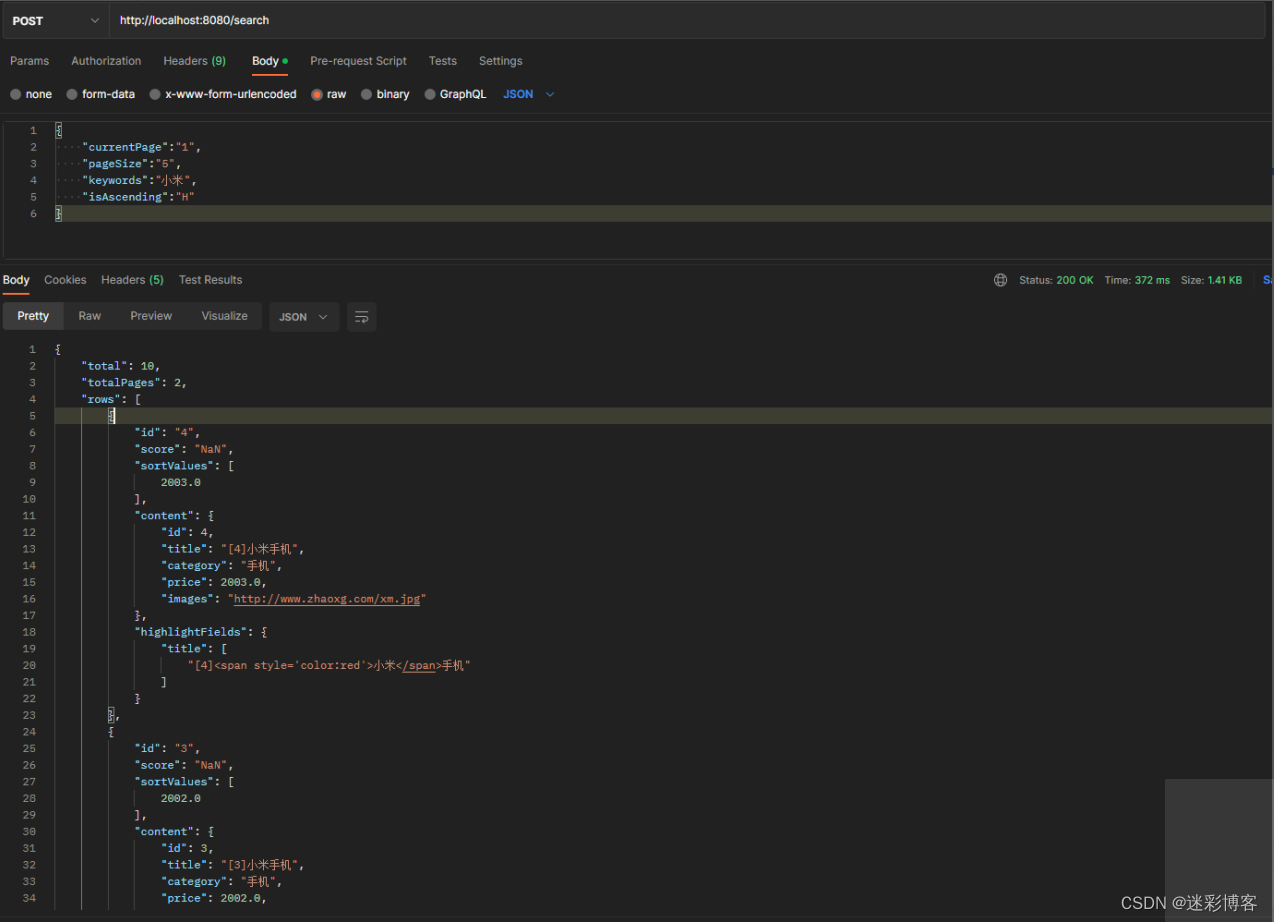
使用QueryBuilders、NativeSearchQuery实现复杂查询
使用QueryBuilders、NativeSearchQuery实现复杂查询 本文继续前面文章《ElasticSearch系列(二)springboot中集成使用ElasticSearch的Demo》,在前文中,我们介绍了使用springdata做一些简单查询,但是要实现一些高级的组…...

taobao.open.account.update( Open Account数据更新 )
¥开放平台免费API不需用户授权 Open Account数据更新 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 响应参数 点击获取key和secret 请求示例 TaobaoClient client new DefaultTaobaoClient(url, appkey, sec…...
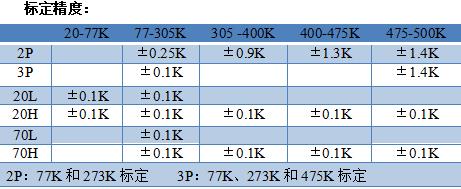
PT100铂电阻温度传感器
PT100温度传感器又叫做铂热电阻。 热电阻是中低温区﹡常用的一种温度检测器。它的主要特点是测量精度高,性能稳定。其中铂热电阻的测量精确度是﹡高的,它不仅广泛应用于工业测温,而且被制成标准的基准仪。金属热…...

蓝桥杯-本质上升序列
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 小蓝特别喜欢单调递增的事物 在一个字符串中如果取出若干个字符,按照在原来字符串中的顺序排列在一起,组成的新的字符串如果是单调递增的…...

synchronized锁重入验证
文章目录synchronized锁重入验证1. 可重入锁2. synchronized锁重入2.1 本类同步方法内部调用本类其它同步方法2.2 子类同步方法内部调用父类的同步方法2.3 A类的同步方法内部调用B类的同步方法3. synchronized修饰方法写法synchronized锁重入验证 1. 可重入锁 可重入锁&#…...

超简单的计数排序!!
假设给定混乱数据为:3,0,1,3,6,5,4,2,1,9。 下面我们将通过使用计数排序的思想来完成对上面数据的排序。(先不谈负数) 计数排序 该排序的思路和它的名字一样…...

发现新大陆——原来软件开发根本不需要会编码(看我10分钟应用上线)
目录 一、前言 二、官网基础功能及搭建 三、体验过程 01、连接数据源 02、设计表单 03、流程设计 04、图表呈现 05、组织架构设置 五、效率评价 六、小结 一、前言 众所周知,每家公司在发展过程中都需要构建大量的内部系统, 如运营使用的用户…...

【Leedcode】栈和队列必备的面试题(第二期)
【Leedcode】栈和队列必备的面试题(第二期) 文章目录【Leedcode】栈和队列必备的面试题(第二期)一、题目(用两个队列实现栈)二、思路图解1.定义两个队列2.初始化两个队列3.往两个队列中放入数据4.两个队列出…...
Elasticsearch实战之(商品搜索API实现)
Elasticsearch实战之(商品搜索API实现) 1、案例介绍 某医药电商H5商城基于Elasticsearch实现商品搜索 2、案例分析 2.1、数据来源 商品库 - 平台运营维护商品库 - 供应商维护 2.2、数据同步 2.2.1、同步双写 写入 MySQL,直接也同步往…...

Spring Boot条件装配原理
Spring Boot条件装配原理 引言 条件装配是Spring Boot自动配置的核心机制,通过Conditional及其派生注解,Spring能够根据当前环境、classpath、配置属性等因素智能地决定是否创建某个Bean。本文将深入剖析条件装配的实现原理、各种条件注解的使用方法以及…...

让框架跑得久一点:失败继续、日志、截图、HTML 与网络现场
摘要 前面几篇讲了框架如何执行 CSV、如何处理变量和状态、如何做网络断言。 到这里,框架已经能跑起来。 但自动化测试长期使用时,真正麻烦的不是失败,而是失败后看不懂。 这篇文章讲框架为了“失败后能排查”做了哪些设计:contin…...

利用Taotoken实现AI应用的高可用与容灾路由设计思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken实现AI应用的高可用与容灾路由设计思路 应用场景类,探讨在构建对稳定性要求高的生产级AI应用时࿰…...

基于Vercel AI SDK与Next.js 14构建智能编程助手:从架构到部署实战
1. 项目概述:一个面向开发者的AI编程助手脚手架最近在GitHub上看到一个挺有意思的项目,叫vercel-labs/coding-agent-template。光看名字,你大概能猜到,这是一个跟AI编程助手相关的模板项目。没错,它本质上是一个预先配…...

设计师核心能力框架:从思维策略到工程落地的系统化成长路径
1. 项目概述:一个设计师的“内功”修炼场如果你是一名设计师,或者对设计工作感兴趣,那么你一定有过这样的时刻:面对一个设计任务,脑子里有无数想法,但打开软件却不知从何下手;或者看到别人的优秀…...

从RStudio到VSCode:5个场景教你如何高效使用vscode-R插件进行R开发
从RStudio到VSCode:5个场景教你如何高效使用vscode-R插件进行R开发 【免费下载链接】vscode-R R Extension for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-R 你是否还在为RStudio的界面限制而烦恼?想要在更现代化的…...

AMD Ryzen SMU Debug Tool完全指南:揭秘硬件级调试的三大实战场景
AMD Ryzen SMU Debug Tool完全指南:揭秘硬件级调试的三大实战场景 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

Kubernetes API Server优化:提升集群管理效率
Kubernetes API Server优化:提升集群管理效率 一、Kubernetes API Server概述 1.1 API Server的角色 Kubernetes API Server是Kubernetes集群的核心组件,负责处理所有的REST API请求,是集群内部和外部通信的枢纽。它负责验证和处理请求&#…...

HoRain云--Skills 基本结构
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

基于ESP32与Pure Data的无线音乐控制器:从硬件到软件的完整实现
1. 项目概述与核心思路 如果你对用代码做音乐感兴趣,或者玩过像Pure Data、Max/MSP这样的可视化音频编程环境,那你肯定想过一个问题:能不能把物理世界里的动作,比如触摸、倾斜、敲击,直接变成控制音乐的声音参数&#…...