hive 命令记录(随时更新)
1.进入 hive 数据库:
hive
2.查看hive中的所有数据库:
show databases;
3.用 default 数据库
use default;
4.查看所有的表
show tables;
5.查询 book 表结构:
desc book ;
6.查询 book 表数据
select * from book;
7.创建 shop 数据库
create database shop;
create database if not exists shop;
创建 shop 数据库 并指定在hdfs的位置
create database shop localtion ‘/test/1’;
8.删除 shop 数据库
drop dtatbase if exists shop ;
dorp schema shop;
全部删除相应的表,在删除数据库之前:
drop database if exists shop cascade;
9.创建表tb_employee
create table if not exists tb_employee
( id int ,
name string,
dept string
) comment ‘员工信息表’
row format DELIMTED
fields terminated by ‘\t’
lines terminated by ‘\n’
stored as textfile;
如果要增加分区必须在创建表的时候就创建分区,不然就得删掉重新建表
create table if not exists tb_employee
( id int ,
name string,
dept string
) comment ‘员工信息表’
partitioned by (year int)
row format DELIMTED
fields terminated by ‘\t’
lines terminated by ‘\n’
stored as textfile;
stored as textfile 文件格式,文件格式在hive中有三种:textfile,RCfile,Sequencefile
10.添加数据到表中
load data local inpath ‘/usr/hadoop/hive/employee.txt’
overwrite into tb_employee;
如果table 是个分区表,则必须在添加时指定分区
load data local inpath ‘/usr/hadoop/hive/employee.txt’ overwrite
into tb_employee partition(year=2023);
load data : 加载数据
local: 本地数据
inpath: 文件地址
overwrite:覆盖表中的数据,不加overwrite是追加数据
插入表数据
insert into tb_employee(id,name) values(‘1’,‘wcz’);
11.重命名表格
alter table tb_temployee rename to emp;
12.修改emp 表中 name 字段 为 user_name
alter table emp change name user_name string;
13.修改 emp 表中 salary 的数据类型从 float 改为 double
alter table emp change salary salary double;
14.删除emp 表
drop talbe emp;
15.创建视图
create view emp_view as select * from emp where salary > 3000;
16.不同的连接
join
left outer join
right outer join
full outer join
left semi join on
只在on设置右表的查询条件且查询只包含左表的结果
17.创建外部表
create external table out_employee
( id int ,
name string,
dept string
) ;
18.查询外部表信息
desc formatted out_employee ;
19.获取字符串第一个字符
1.SUBSTRING(cloumn_name,1,1)
2.LEFT (cloumn_name,1,1)
3.REGEXP_EXTRACT(cloumn_name,‘^(.)’,1)
20.排序
1.order by : 全局排序,只会有一个reduce,不建议
默认升序: ASC 降序 : DESC
在hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
2.sort by : 局部排序,保证每个reduce上是有序的,但全局不一定
3..distribute by 分区排序,可以将相同的key放到同一个reduce进行处理,但不保证有序
想要保证有序 distribute by 语句后面加上 sort by
4.cluster by score = distribute by score sort by score
但是默认升序,不支持指定
21.备份一个表
1.先备份表结构,再备份表数据
create table if not exists borrow_log_bak like borrow_log;
insert into borrow_log_bak select * from borrow_log;
以下摘抄 点击跳转到原文 https://zhuanlan.zhihu.com/p/662539681
22.分组 group by
使用 group by 分组后面只能跟 字段 或者聚合函数 后面也可以是使用 having 对数据进行进行筛选
23.聚合函数
count(*) 包含null值,统计所有行数
count(name) 不包含null值
min 求最小值,不包含null值,除非所有值都是null
avg 求平均值,不包括null值var_pop(col) 统计结果集中col非空集合的总体变量(忽略NULL),返回值 double var_samp(col)
统计结果集中col费空集合的样本变量(忽略NULL)返回值 double stddev_pop
该函数计算总体标准偏离,并返回总体变量的平方根,其返回值与var_pop函数的平方根相同 percentile(BIGINT col,p)
求准确的第pth个百分数,p必须介于0和1之间,但是col字段目前只支持整数,不支持浮点类型
24.关系运算符
等于 =
不等于 != 或者 <>
小于 <
小于等于 <=
大于 >
大于等于 >=
判断为空 is null
判断非空 is not null
25.数值运算
取整: round(double a) 遵循四舍五入原则
指定精度取整:round(double a,int b)
向下取整:floor(double a)
向上取整:ceil(double a)
取随机数:rand() 或者 rand(int seed) 返回0-1内的随机数,如果指定了seed,那每次返回的结果都是一样的
自然指数: exp(double a) 返回自然对数e的a次方
以10为底的对数函数:log10(double a) 返回以10为底a的对数
幂运算:pow(double a,double b) 返回 a 的 b 次幂
开平方:sqrt(double a) 返回 a 的平方根
二进制数:bin(BIGINT a) 返回 a 的二进制表示
。。。。
十六进制函数: hex()、将十六进制转化为字符串函数: unhex()
进制转换函数: conv(bigint num, int from_base, int to_base) 说明: 将数值num从from_base进制转化到to_base进制
此外还有很多数学函数:绝对值函数: abs()、正取余函数:
pmod()、正弦函数: sin()、反正弦函数: asin()、余弦函数: cos()、反余弦函数: acos()、positive函数:
positive()、negative函数: negative()
26.条件函数
If函数: if
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值: T
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
hive> select if(1=2,100,200) ;
200
hive> select if(1=1,100,200) ;
100
非空查找函数: coalesce
语法: coalesce(T v1, T v2, …)
返回值: T
说明: 返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
hive> select coalesce(null,‘100’,‘50’) ;
100
条件判断函数:case when (两种写法,其一)
语法: case when a then b [when c then d]* [else e] end
返回值: T
说明:如果a为TRUE,则返回b;如果c为TRUE,则返回d;否则返回e
hive> select case when 1=2 then ‘tom’ when 2=2 then ‘mary’ else ‘tim’ end from tableName;
mary
条件判断函数:case when (两种写法,其二)
语法: case a when b then c [when d then e]* [else f] end
返回值: T
说明:如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f
hive> Select case 100 when 50 then ‘tom’ when 100 then ‘mary’ else ‘tim’ end from tableName;
mary
27.日期函数
注:以下SQL语句中的 from tableName 可去掉,不影响查询结果
获取当前UNIX时间戳函数: unix_timestamp
语法: unix_timestamp()
返回值: bigint
说明: 获得当前时区的UNIX时间戳
hive> select unix_timestamp() from tableName;
1616906976
UNIX时间戳转日期函数: from_unixtime
语法: from_unixtime(bigint unixtime[, string format])
返回值: string
说明: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式
hive> select from_unixtime(1616906976,‘yyyyMMdd’) from tableName;
20210328
日期转UNIX时间戳函数: unix_timestamp
语法: unix_timestamp(string date)
返回值: bigint
说明: 转换格式为"yyyy-MM-dd HH:mm:ss"的日期到UNIX时间戳。如果转化失败,则返回0。
hive> select unix_timestamp(‘2021-03-08 14:21:15’) from tableName;
1615184475
指定格式日期转UNIX时间戳函数: unix_timestamp
语法: unix_timestamp(string date, string pattern)
返回值: bigint
说明: 转换pattern格式的日期到UNIX时间戳。如果转化失败,则返回0。
hive> select unix_timestamp(‘2021-03-08 14:21:15’,‘yyyyMMdd HH:mm:ss’) from tableName;
1615184475
日期时间转日期函数: to_date
语法: to_date(string timestamp)
返回值: string
说明: 返回日期时间字段中的日期部分。
hive> select to_date(‘2021-03-28 14:03:01’) from tableName;
2021-03-28
日期转年函数: year
语法: year(string date)
返回值: int
说明: 返回日期中的年。
hive> select year(‘2021-03-28 10:03:01’) from tableName;
2021
hive> select year(‘2021-03-28’) from tableName;
2021
日期转月函数: month
语法: month (string date)
返回值: int
说明: 返回日期中的月份。
hive> select month(‘2020-12-28 12:03:01’) from tableName;
12
hive> select month(‘2021-03-08’) from tableName;
8
日期转天函数: day
语法: day (string date)
返回值: int
说明: 返回日期中的天。
hive> select day(‘2020-12-08 10:03:01’) from tableName;
8
hive> select day(‘2020-12-24’) from tableName;
24
日期转小时函数: hour
语法: hour (string date)
返回值: int
说明: 返回日期中的小时。
hive> select hour(‘2020-12-08 10:03:01’) from tableName;
10
日期转分钟函数: minute
语法: minute (string date)
返回值: int
说明: 返回日期中的分钟。
hive> select minute(‘2020-12-08 10:03:01’) from tableName;
3
日期转秒函数: second
语法: second (string date)
返回值: int
说明: 返回日期中的秒。
hive> select second(‘2020-12-08 10:03:01’) from tableName;
1
日期转周函数: weekofyear
语法: weekofyear (string date)
返回值: int
说明: 返回日期在当前的周数。
hive> select weekofyear(‘2020-12-08 10:03:01’) from tableName;
49
日期比较函数: datediff
语法: datediff(string enddate, string startdate)
返回值: int
说明: 返回结束日期减去开始日期的天数。
hive> select datediff(‘2020-12-08’,‘2012-05-09’) from tableName;
213
日期增加函数: date_add
语法: date_add(string startdate, int days)
返回值: string
说明: 返回开始日期startdate增加days天后的日期。
hive> select date_add(‘2020-12-08’,10) from tableName;
2020-12-18
日期减少函数: date_sub
语法: date_sub (string startdate, int days)
返回值: string
说明: 返回开始日期startdate减少days天后的日期。
hive> select date_sub(‘2020-12-08’,10) from tableName;
2020-11-28
28.字符串函数
字符串长度函数:length
语法: length(string A)
返回值: int
说明:返回字符串A的长度
hive> select length(‘abcedfg’) from tableName;
7
字符串反转函数:reverse
语法: reverse(string A)
返回值: string
说明:返回字符串A的反转结果
hive> select reverse(‘abcedfg’) from tableName;
gfdecba
字符串连接函数:concat
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
hive> select concat(‘abc’,'def’,‘gh’)from tableName;
abcdefgh
带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
hive> select concat_ws(‘,’,‘abc’,‘def’,‘gh’)from tableName;
abc,def,gh
字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
hive> select substr(‘abcde’,3) from tableName;
cde
hive> select substring(‘abcde’,3) from tableName;
cde
hive> select substr(‘abcde’,-1) from tableName; (和ORACLE相同)
e
字符串截取函数:substr,substring
语法: substr(string A, int start, int len),substring(string A, int start, int len)
返回值: string
说明:返回字符串A从start位置开始,长度为len的字符串
hive> select substr(‘abcde’,3,2) from tableName;
cd
hive> select substring(‘abcde’,3,2) from tableName;
cd
hive>select substring(‘abcde’,-2,2) from tableName;
de
字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A)
返回值: string
说明:返回字符串A的大写格式
hive> select upper(‘abSEd’) from tableName;
ABSED
hive> select ucase(‘abSEd’) from tableName;
ABSED
字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A)
返回值: string
说明:返回字符串A的小写格式
hive> select lower(‘abSEd’) from tableName;
absed
hive> select lcase(‘abSEd’) from tableName;
absed
去空格函数:trim
语法: trim(string A)
返回值: string
说明:去除字符串两边的空格
hive> select trim(’ abc ') from tableName;
abc
左边去空格函数:ltrim
语法: ltrim(string A)
返回值: string
说明:去除字符串左边的空格
hive> select ltrim(’ abc ') from tableName;
abc
右边去空格函数:rtrim
语法: rtrim(string A)
返回值: string
说明:去除字符串右边的空格
hive> select rtrim(’ abc ') from tableName;
abc
正则表达式替换函数:regexp_replace
语法: regexp_replace(string A, string B, string C)
返回值: string
说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。
hive> select regexp_replace(‘foobar’, ‘oo|ar’, ‘’) from tableName;
fb
正则表达式解析函数:regexp_extract
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
hive> select regexp_extract(‘foothebar’, ‘foo(.?)(bar)', 1) from tableName;
the
hive> select regexp_extract(‘foothebar’, 'foo(.?)(bar)’, 2) from tableName;
bar
hive> select regexp_extract(‘foothebar’, ‘foo(.?)(bar)‘, 0) from tableName;
foothebar
strong>注意,在有些情况下要使用转义字符,下面的等号要用双竖线转义,这是java正则表达式的规则。
select data_field,
regexp_extract(data_field,’.?bgStart\=([^&]+)’,1) as aaa,
regexp_extract(data_field,‘.?contentLoaded_headStart\=([^&]+)‘,1) as bbb,
regexp_extract(data_field,’.?AppLoad2Req\=([^&]+)’,1) as ccc
from pt_nginx_loginlog_st
where pt = ‘2021-03-28’ limit 2;
URL解析函数:parse_url
语法: parse_url(string urlString, string partToExtract [, string keyToExtract])
返回值: string
说明:返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO.
hive> select parse_url
(‘https://www.tableName.com/path1/p.php?k1=v1&k2=v2#Ref1’, ‘HOST’)
from tableName;
www.tableName.com
hive> select parse_url
(‘https://www.tableName.com/path1/p.php?k1=v1&k2=v2#Ref1’, ‘QUERY’, ‘k1’)
from tableName;
v1
json解析函数:get_json_object
语法: get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
hive> select get_json_object(‘{“store”:{“fruit”:[{“weight”:8,“type”:“apple”},{“weight”:9,“type”:“pear”}], “bicycle”:{“price”:19.95,“color”:“red”} },“email”:“amy@only_for_json_udf_test.net”,“owner”:“amy”}’,‘$.owner’) from tableName;
空格字符串函数:space
语法: space(int n)
返回值: string
说明:返回长度为n的字符串
hive> select space(10) from tableName;
hive> select length(space(10)) from tableName;
10
重复字符串函数:repeat
语法: repeat(string str, int n)
返回值: string
说明:返回重复n次后的str字符串
hive> select repeat(‘abc’,5) from tableName;
abcabcabcabcabc
首字符ascii函数:ascii
语法: ascii(string str)
返回值: int
说明:返回字符串str第一个字符的ascii码
hive> select ascii(‘abcde’) from tableName;
97
左补足函数:lpad
语法: lpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行左补足到len位
hive> select lpad(‘abc’,10,‘td’) from tableName;
tdtdtdtabc
注意:与GP,ORACLE不同,pad 不能默认
右补足函数:rpad
语法: rpad(string str, int len, string pad)
返回值: string
说明:将str进行用pad进行右补足到len位
hive> select rpad(‘abc’,10,‘td’) from tableName;
abctdtdtdt
分割字符串函数: split
语法: split(string str, string pat)
返回值: array
说明: 按照pat字符串分割str,会返回分割后的字符串数组
hive> select split(‘abtcdtef’,‘t’) from tableName;
[“ab”,“cd”,“ef”]
集合查找函数: find_in_set
语法: find_in_set(string str, string strList)
返回值: int
说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
hive> select find_in_set(‘ab’,‘ef,ab,de’) from tableName;
2
hive> select find_in_set(‘at’,‘ef,ab,de’) from tableName;
0
29.内置函数
NVL
给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL
select nvl(column, 0) from xxx;
行转列
函数 描述
CONCAT(string A/col, string B/col…) 返回输入字符串连接后的结果,支持任意个输入字符串
CONCAT_WS(separator, str1, str2,…) 第一个参数参数间的分隔符,如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间。
COLLECT_SET(col) 将某字段的值进行去重汇总,产生array类型字段
COLLECT_LIST(col) 函数只接受基本数据类型,它的主要作用是将某字段的值进行不去重汇总,产生array类型字段。
列转行(一列转多行)
Split(str, separator): 将字符串按照后面的分隔符切割,转换成字符array。
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法:
LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
lateral view首先为原始表的每行调用UDTF,UDTF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
准备数据源测试
| movie | category |
|---|---|
| 《功勋》 | 记录,剧情 |
| 《战狼2》 | 战争,动作,灾难 |
SQL:
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,“,”)) movie_info_tmp AS category_name ;
测试结果
《功勋》 记录
《功勋》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
相关文章:
)
hive 命令记录(随时更新)
1.进入 hive 数据库: hive 2.查看hive中的所有数据库: show databases; 3.用 default 数据库 use default; 4.查看所有的表 show tables; 5.查询 book 表结构: desc book ; 6.查询 book 表数据 select * from book; 7.创建 shop 数据库 creat…...
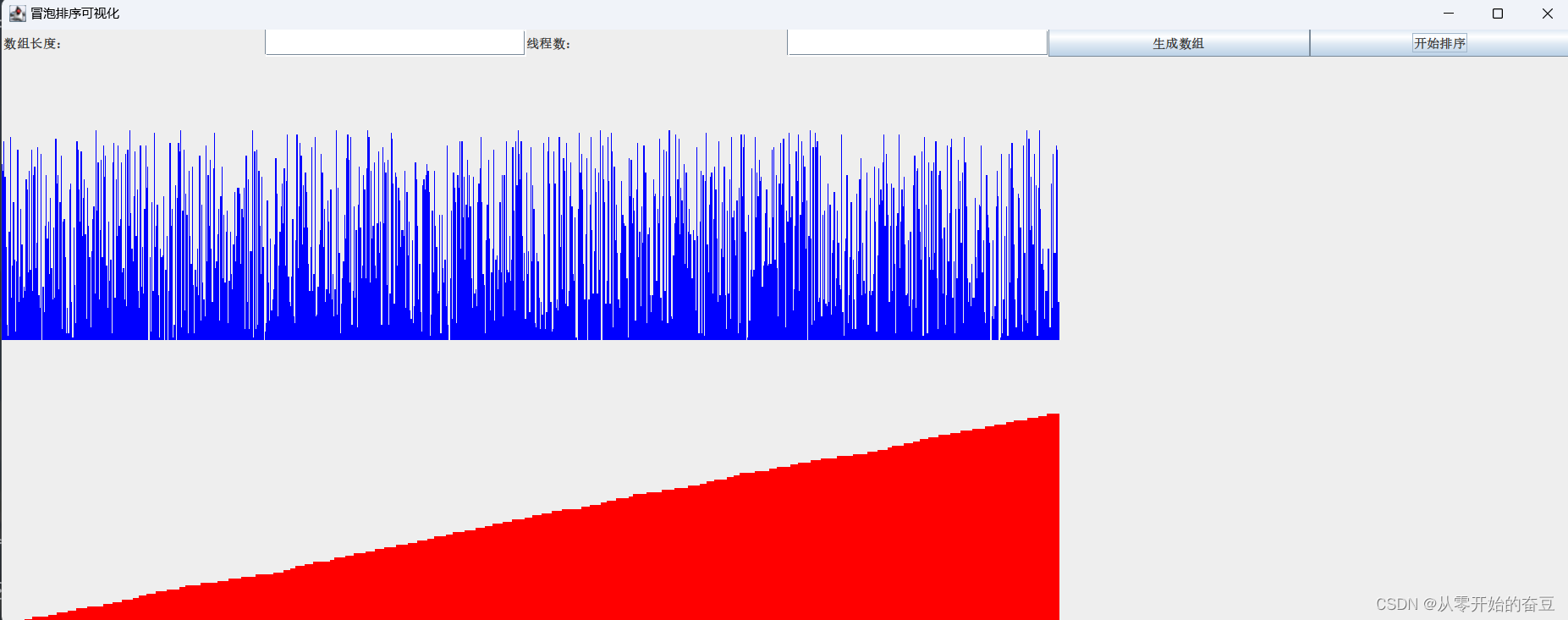
java实战(五):理解多线程与多线程实现冒泡排序及可视化
多线程 1.多线程理解1.1线程概念1.2线程的创建和启动1.3线程的同步与互斥1.4线程的状态和生命周期1.5线程间的通信1.6处理线程的异常和错误1.7实践 2.效果3.代码 1.多线程理解 1.1线程概念 线程:计算机中能够执行独立任务的最小单位。在操作系统中,每个…...

mysql-binlog,redolog 和 undolog区别
binlog MySQL的binlog(二进制日志 或 归档日志)是一种记录数据库的更改操作的日志。它包含了对数据库进行的插入、更新和删除操作的详细信息。binlog是以二进制格式存储,可以用于恢复数据库、数据复制和数据同步等操作。具体来说,…...
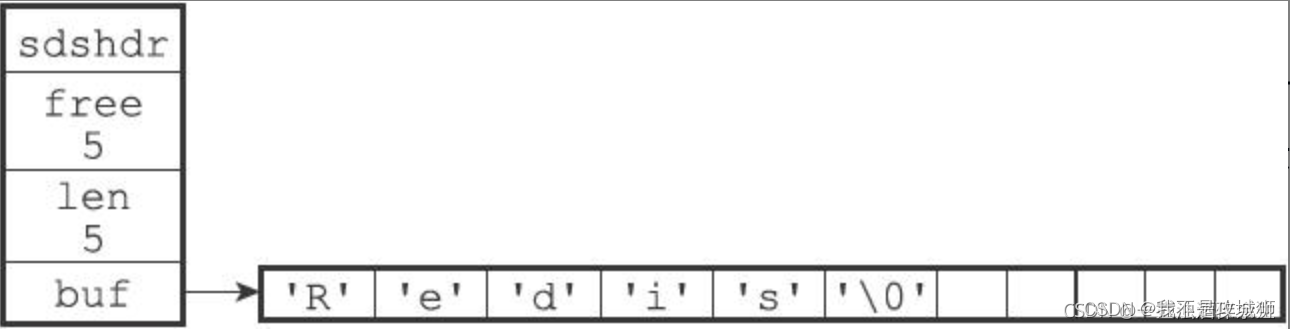
Redis SDS 源码
struct sdshdr {int len;int free;char buf[]; }; 底层数据结构的好处: 杜绝缓冲区溢出。减少修改字符串长度时所需的内存重分配次数。二进制安全。兼容部分C字符串函数。 常用命令: set key value、get key 等 应用场景:共享 session、分…...
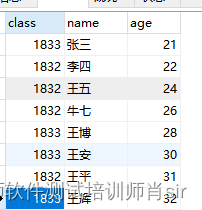
肖sir__mysql之单表练习题2__(2)
mysql之单表练习题 一.建表语句 create table grade(class int(4),chinese int(8),english int(4),math int(8),name varchar(20),age int(8),sid int(4)primary key auto_increment) DEFAULT charsetutf8; insert into grade(class,chinese,english,math,name,age)values(1833…...
nuxt、vue实现PDF和视频文件的上传、下载、预览
上传 上传页面 <el-form-item :label"(form.ququ3 1 ? 参培 : form.ququ3 2 ? 授课 : ) 证明材料" prop"ququ6"><PdfUpload v-model"form.ququ6" :fileType"[pdf, mp4, avi, ts]"></PdfUpload> </el-form-i…...

c++ 写成.h .cpp main.cpp 多文件形式
1 .h 声明方法/函数 用于连接定义和实例使用 // max.h #ifndef MAX_H #define MAX_Hint max(int a, int b);#endif /* 在#ifndef和#define中使用的MAX_H就是指的max.h这个头文件的名字。具体来说,#ifndef MAX_H中MAX_H代表了max.h这个头文件的一个唯一的标识符。#define MAX_H…...
)
组合总和(回溯)
题目描述 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 样例输入 示例 1: 输入: k 3, n 7 …...
【代码】微电网两阶段鲁棒优化经济调度方法(完美复现)matlab-yalmip-cplex/gurobi
程序名称:两阶段鲁棒优化—微电网两阶段鲁棒优化经济调度方法_刘一欣 实现平台:matlab-yalmip-cplex/gurobi 简介:针对微电网内可再生能源和负荷的不确定性,建立了 min-max-min 结构的两阶段鲁棒优化模型,可得到最恶…...

关于无线测温系统在海上石油平台的应用探讨-安科瑞 蒋静
摘要:海上石油平台的封闭式中高压配电盘在平台电力系统起着十分重要的作用,通过统计其配电盘的 大部分故障为前期的热效应引起,由于配电盘内部空间封闭狭小,所以无法进行人工巡查测温,这给油田的供电系统埋下了一定的潜…...

CSS 滚动捕获 scroll-padding
scroll-padding 非滚动捕获容器滚动捕获容器语法兼容性 CSS 滚动捕获 scroll-padding 设置元素的滚动内边距, 就像 padding 所做的那样. 但并不影响布局. 非滚动捕获容器 我们先来看看不影响布局到底是什么意思. 我们平时会见到左侧是内容, 右侧是内容导航的页面, 比如下图 这…...

asp.net core webpi 结合jwt实现登录鉴权
1.安装jwt nuget包 <PackageReference Include"Microsoft.AspNetCore.Authentication.JwtBearer" Version"6.0.25" /><PackageReference Include"System.IdentityModel.Tokens.Jwt" Version"7.0.3" />1.1创建jwt配置类 n…...

【香橙派】实战记录2——烧录安卓镜像及基本功能
文章目录 一、安卓烧录二、安卓基本功能1、蓝牙2、相机功能3、投屏 一、安卓烧录 检查环境:检查PC系统,确保有Microsoft Visual C 2008 Redistrbutable - x86,否则在官网下载的官方工具 - 安卓镜像烧录工具里运行vcredist_x86.exe。 插入存储…...
【spring(六)】WebSocket网络传输协议
🌈键盘敲烂,年薪30万🌈 目录 核心概要: 概念介绍: 对比HTTP协议:⭐ WebSocket入门案例:⭐ 核心概要: websocket对比http 概念介绍: WebSocket是Web服务器的一个组件…...
MidJourney笔记(6)-Niji模式
Niji模式 回顾一下,在讲解settings命令时,我们可以看到一个Niji字眼。 而且是在Midjourney V4之后才有的,那Niji到底是什么? Niji是MidJourney中用于绘制二次元/动漫风格的模型,那Niji的V4和V5有什么区别呢?...
之ab)
Linux命令(139)之ab
linux命令之ab 1.ab介绍 linux命令ab(E.g:apachebench)是apache自带的压力测试工具。ab命令会创建多个并发访问线程,模拟多个访问者同时对某一URL进行访问。由于ab命令测试是基于URL的,因此,它既可以用来测试apache httpd的负载压力&#x…...
笔记----单纯剖分----1
笔记----单纯剖分 定义 线性组合仿射组合: 线性组合的系数为1凸组合: 仿射组合所有的系数都是正数 凸集 R^m 的 任意有限个点的凸组合仍在其中的子集仿射子空间 R^m 的 任意有限个点的仿射组合仍在其中的子集凸包 conv(A) A是R^m的一个子集 A的所有有限凸…...
mybatis源码(五)springboot pagehelper实现查询分页
1、背景 springboot的pagehelper插件能够实现对mybatis查询的分页管理,而且在使用时只需要提前声明即可,不需要修改已有的查询语句。使用如下: 之前对这个功能一直很感兴趣,但是一直没完整看过,今天准备详细梳理下。按…...

【BUG】SpringBoot项目Long类型数据返回前端精度丢失问题
问题描述 后端再给前端返回数据,使用Long类型的时候存在精度丢失问题。 原因分析: 分布式项目中广泛使用雪花算法生成ID作为数据库表的主键,Long类型的雪花ID有19位,而前端接收Long类型用的是number类型,但是number…...

UI自动化Selenium find_elements和find_element的区别
# 如果获取的element是list,那么需要用find_elements方法;此方法会返回list,然后使用len() 方法,计算对象的个数; # find_element方法返回的不是list对象,所以导致没办法计算对象个数 # 1.返回值类型不同…...

DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入![特殊字符]
DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入!🚀 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 还在为繁琐的验证码输入而烦恼吗?…...

手把手教你配置STC15F2K60S2的PCA引脚映射,灵活切换P1/P3/P2口输出PWM信号
STC15F2K60S2单片机PCA模块实战:三端口PWM信号自由切换指南 当你在蓝桥杯CT107D开发板上调试电机控制时,是否遇到过P1口被数码管占用却需要输出PWM的困境?STC15F2K60S2的PCA模块引脚重映射功能正是解决这类硬件冲突的利器。本文将带你深入掌…...

ComfyUI-Impact-Pack V8:AI图像增强的模块化革命与智能内存管理
ComfyUI-Impact-Pack V8:AI图像增强的模块化革命与智能内存管理 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址:…...

openpilot深度解析:开源驾驶辅助系统的技术实现与架构设计
openpilot深度解析:开源驾驶辅助系统的技术实现与架构设计 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

从手机信号到CT扫描:一张图看懂电磁波如何改变我们的生活
从手机信号到CT扫描:一张图看懂电磁波如何改变我们的生活 清晨醒来,你按下智能手机的闹钟关闭按钮,这个简单的动作背后是无线电波在基站与设备间的无声对话;早餐时微波炉加热牛奶的嗡嗡声,本质上是特定频率电磁场对水分…...
)
别再死记硬背了!用一张图帮你彻底搞懂FC协议栈(从FC-0到FC-4)
用视觉化思维拆解FC协议栈:从物理层到应用层的全景指南 当你第一次接触光纤通道(FC)协议时,那些从FC-0到FC-4的层级、各种端口类型和封装结构是否让你感到头晕目眩?别担心,这篇文章将用全新的视觉化方法&am…...
)
基于SSM的在线预约导游系统(10068)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

长沙自动变速箱维修哪家强?这些公司口碑好
好的,遵照您的指示,我将以资深变速箱维修领域分析者的身份,围绕“长沙自动变速箱维修哪家强”这一核心问题,撰写一篇客观、实用、合规的深度分析文章。车主选维修店,最怕被“宰”与被“拖”在长沙,如果你的…...

数据架构演进:从数据仓库到湖仓一体与流批融合实战
1. 从“数据仓库”到“数据湖”:一场思维范式的革命干了十几年数据,从最早的Oracle报表,到后来的Hadoop集群,再到现在的云原生数据平台,我亲眼见证了数据架构这十几年的风云变幻。如果说大数据时代的开启是一声惊雷&am…...

工业级AI计算机如何支撑机场eGate系统:BOXER-6646-ADP硬件与部署解析
1. 项目概述:当“刷脸通关”成为现实,背后是谁在支撑?每次在机场国际出发或到达大厅,看到那些排着长队等待人工查验护照、盖章的队伍,你是不是也幻想过能像科幻电影里那样,走到一个闸机前,刷一下…...