自定义类型-结构体,联合体和枚举-C语言
引言
能看到结构体,说明C语言想必学习的时间也不少了,在之前肯定也学习过基本数据类型,包括整型int,浮点型float等等。可是在日常生活中,想要描述一个事物并没有那么简单。比如,你要描述一本书,关于本书需要描述出书名,定价,以及作者等信息,单靠整数,或者是字符数组都没办法一次性描述清楚,这里就引申出了一种新的可自定义类型——结构体。在一个结构体中,可以定义多种相同或者不同的数据类型,有了结构体,我们便可以根据需要创建自己的数据类型,来描述一些复杂的事物了。同时,本篇还要介绍以下另外两种自定义类型,联合体和枚举。
结构体struct
结构体的创建以及应用
下面写出结构体基本定义
struct tag //tag为类型名称
{member-list;//这里可以定义多行数据类型
}variable-list; //变量创建,可以在此创建结构体变量在描述完上方定义后可能你会有些疑惑,但别急,接下来给大家举个例子,现在我们定义一个关于学生的结构体
struct Stu //这是创建了一个结构体类型
{char name[30];int age;char number[30];
};
struct Stu student={"zhangsan",19,"2003020102"};
//这时在创建结构体类型后运用其创建结构体变量,同时对变量初始化struct Stu //这时创建类型的同时创建了三个结构体变量
{char name[30];int age;char number[30];
}student1, student2, student3;
像上方这样, 我们的结构体类型以及变量就创建好了,在创建的同时,还可以进行初始化。下面代码将应用这些变量。以(结构体变量.成员)的形式来访问结构体变量中的元素。
#include <stdio.h>
struct Stu
{char name[30];int age;char number[30];
};
int main()
{struct Stu student = { "zhangsan",19,"2001040302" };printf("%s\n%d\n%s\n", student.name, student.age, student.number);return 0;
}

结构体指针形式访问
运用一个指针指向结构体,通过->符号可以直接访问元素,下面是使用样例。
#include <stdio.h>
struct Stu
{char name[30];int age;char number[30];
};
int main()
{struct Stu student = { "zhangsan",19,"2001040302" };//printf("%s\n%d\n%s\n", student.name, student.age, student.number);struct Stu* p;p = &student;printf("%s\n%d\n%s\n", p->name, p->age, p->number);return 0;
}

结果依然相同
结构体传参
现在看下面这样一组代码
#include<stdio.h>
struct S
{int data[1000];int num;
};
void print1(struct S t)
{printf("%d %d\n", t.data[1], t.num);
}
void print2(struct S* ps)
{printf("%d %d\n", ps->data[1], ps->num);
}
int main()
{struct S s = { {1,2,3,4,5},100 };print1(s); //传递结构体print2(&s);//传递结构体地址return 0;
}
这两种传递的方式都是正确的,但是直接传递结构体的方式却有很大的弊端,就是直接传递传递结构体需要重新开辟一片新的空间,当结构体变量比较大的时候,是极其消耗栈的内存空间的,因此会降低计算机运行效率。但是传递结构体的过程中有时并不想改变其中元素怎么办呢?我们可以给结构体加上const从而保护其中元素,使其在函数中无法通过指针改变结构体中的变量。
#include<stdio.h>//此代码很好的在运行函数时保护了结构体变量s
struct S
{int data[1000];int num;
};
void print2(const struct S* ps)
{printf("%d %d\n", ps->data[1], ps->num);
}
int main()
{struct S s = { {1,2,3,4,5},100 };print2(&s);//传递结构体地址return 0;
}
结构体特殊声明
在结构体声明中,有一些特殊的声明,它们没有类型名,同时没有对应类型,也被称作匿名结构体。这种结构体的变量只能在声明时创建。
#include<stdio.h>
struct
{int a;char b;
}x;
struct
{int a;char b;
}*p;
int main()
{p = &x;return 0;
}当你写出上方这样的代码时,编译器会报错,因为匿名结构体没有对应的类型,就算元素相同,编译器也会将它们当成不同类型。
给结构体类型起名typedef
#include<stdio.h>
typedef struct
{int a;char b;
}S;//此时类型名为S
int main()
{S data = { 20,'x' };//此时,可以用类型名S来这样初始化结构体变量return 0;
}结构体的自引用
奇思妙想一下,能否将结构体的元素定义成定义的结构体呢? 像以下这种方式
struct Node
{int data;struct Node next;
};其中data表示的是存储在节点Node中的元素,而next放置的是下一个结构体元素,其中包含的元素同样是一个data和一个Node。这样的想法很美好,但如果将结构体自己定义成自己的元素,那么一层一层套下去,最后导致的结果就是使Node的大小无法被定义,故此方式不可行。
不过我们可以采取另一种方式,将next定义成一个结构体指针,指向下一个结构体,像下面这样
struct Node
{int data;struct Node* next;
};data是节点存储的数据,而next指向下一个结构体的地址,就像一个链条一样将结构体串联了起来,这就是数据结构中链表的内容了,不是本篇内容的重点,不做深究。
结构体内存对齐
在学习结构体中,不知道你是否考虑过这样的问题,结构体是怎么分配内存的,接下来我们将通过一个代码引入这个问题
#include<stdio.h>
struct s1
{char c1;char c2;int i;
};
struct s2
{char c1;int i;char c2;
};
int main()
{printf("%zd %zd\n", sizeof(struct s1), sizeof(struct s2));return 0;
}试着猜猜上面代码会打印什么结果呢?

看看有没有出乎你的意料?
是的, 由于平台存在内存对齐,故按我们假象所计算的结果与真实编译器实现不同。
下面讲讲对齐规则
对齐规则:
1.结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处;
2.其他成员变量要对齐到某个数字(对齐数,这里的对齐是成员变量元素所占地址大小,比如char的对齐数是1,而int的对齐数为4)的整数倍的地址处。
注意:对齐数=min{编译器默认对齐数,该成员变量大小},即两者的较小值。VS2022的默认对齐数是8,而Linux中gcc没有默认对齐数,即对齐数是成员变量自身大小。
3.结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
根据上述的规则,我们可以再来看看代码,跟具规则来计算开辟的空间
先来分析第一个,首先char c1,由对齐规则1,可知开辟到0地址处,然后到了char c2,char对齐到1的整数倍,所以开辟在1地址处,当开始开辟int类型i的内存时,由于i的对齐数是4,所以要对到4的整数倍上,所以最后在4的位置开辟空间,而地址2,3的内存就被浪费了,所以是空。开辟结束时所占内存大小为8,刚好是最大对齐数4的整数倍,所以最终结构体s1所占内存为8。结果见下图左方。
再来分析第二个结构体,首先还是开辟char c1在0处,然后开辟int类型i的空间,因为要与int所占内存大小4,对齐数为4,所以在4处开辟空间,1,2,3被浪费。再开辟c2,其对齐数为1,所以在8处开辟空间,在开辟完之后所占内存为9,不是最大对齐数的整数倍,所以还要再多开辟三个空间,9,10,11被浪费。最后开辟空间数为12。见下图右方。

到了这里,大家可能又有了一些疑问,为社么会存在内存对齐?下面是一些参考资料给出的解答
为什么存在内存对齐?
1.平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据;某些硬件平台只能从某些特定地址处取某些特定的数据,否则抛出硬件异常
2.性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要做两次内存访问;而对齐的内存访问仅需一次。假设一个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型数据的地址都对齐为8的倍数,那么就可以用一个内存操作来读写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分别放在8个字节内存块中。
总的来说:结构体的内存对齐是拿空间换取时间的做法
修改默认对齐数
#include<stdio.h>
#pragma pack(1)//修改默认对齐数为1
struct S
{char c1;char c2;int i;
};//此时sizeof(struct S)的值为6#pragma pack()//取消设置的对齐数,还原为默认对齐数结构体实现位段
C语言中,位段是一种数据结构,允许你为结构体中的成员分配一个特定数量的位(bit),而不是分配完整的字节。这在需要精确控制内存分布或减少内存占用时很有用,比如硬件访问和网络协议设计。对于字段的声明与结构体类似,但也有不同:位段通过在结构体定义中为成员后添加一个冒号和位数(比特位)来创建的,例如:
struct A
{int _a : 2;int _b : 5;int _c : 10;int _d : 30;
};位段的内存分配
1.位段的成员可以是int,unsigned int,signed int或者是char类型
2.空间按照四个字节(int)/一个字节(char)的方式来开辟的
3.位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段
位段的成员是顺序放置的,但当当前存储单元没有足够的空间容纳下一个位段时,编译器可能(会不会跳转取决于编译器)会跳转到下一个存储单元。这可能导致在存储单元有未使用的位。
编译器可能在位段的末尾添加填充,现在让我们假设一下VS2022的字段分配方式
现在有以下代码
#include<stdio.h>
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
int main()
{struct S s = { 0 };s.a = 10;s.b = 12;s.c = 3;s.d = 4;
}位段中的成员在内存中从左向右,还是从右向左尚未定义。
假设为从右向左分配,char中首先为8个比特位,首先a占三个比特位,我们赋a的值为10,二进制为1010,经三个比特位截断得010,也就是二

当赋值b的时候,b占4个比特位,赋值b为12,二进制1100,刚好取四位1100

下一个c占5个比特位,由于无法放下,跳转下一个位段放置的值为3,二进制00011

最后d占4个比特位,在第二个位段放入会超范围条赋值跳到下一个位段,4二进制0100放入,最终结果为下图

我们断点调试一下,验证一下结果,先取出结构体s的地址,开始内存中存的都是0,当走过s.a赋值语句时,内存中的值发生了变化
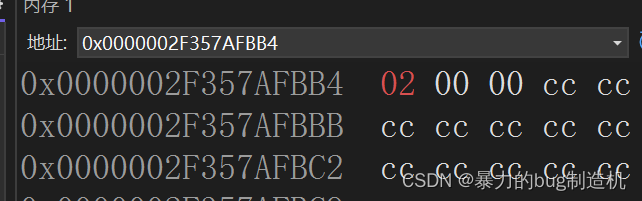
当运行过s.b后

运行s.c后

运行完s.d后

经过调试验证,得到最终结果,假设正确(注意:在调试时显示的值都是以四个比特位的形式显示的,故显示的值不一定等于存入的值)
十六进制0x 62 03 04的二进制为:01110010 000000110 00000100
位段的跨平台问题
位段的内存布局:不同的编译器可能会以不同的顺序排列位段。有些编译器可能会按照声明的顺序排列位段,而其他编译器可能会重新排序以优化空间或访问率
位段中的存储单元:位段通常储存在整型存储单元中,但不同的编译器可能会选择不同的类型作为存储单元
C中位段内存从左向右和从右向左是没有确切定义的,端序影响在大端和小端中,位段的物理存储顺序可能不同
注:由于bit位没有地址,所以位段的几个成员公用一个字节,这样有些成员的起始位置并不是某些字节的起始位置,那么这些位置是没有地址的,所以无法通过取地址的方式为其赋值
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
int main()
{struct S s = { 0 };//scanf("%d",&s.a);<---wrong,结构体位段不可取地址//以下赋值方式均正确s.a = 10;s.b = 12;s.c = 3;s.d = 4;
}联合体union
什么是联合体
与结构体很相似,联合体也是由一个或多个成员构成,这些成员可以是不同的类型,来看看下面这段代码会打印什么
#include<stdio.h>
union u
{char c;int num;
};
int main()
{union u uu;printf("%zd\n", sizeof(uu));printf("%p\n", &uu);printf("%p\n", &(uu.c));printf("%p\n", &(uu.num));return 0;
} 
可以发现,uu占用的空间只有4个字节,而且后面三个地址是相同的,这意味着什么呢?uu.c和uu.num占用的空间在相同的位置,共用一块空间,当一个元素被赋值时,另一个元素的值会被覆盖。因为联合体的这种特性,我们还叫他共用体。
联合体与共用体比较
struct s //结构体
{char c;int i;
};
union u //联合体
{char c;int i;
};
上图中粉色的是被浪费的空间
联合体占用内存
关于占用内存这里要严谨一点,很多教课书和课程里都说联合体的大小是最大成员的大小,实际上这样说是错的,在联合体中也存在和结构体一样的对齐数,当最大元素所需的的空间不是对齐数的倍数时,会自动将其矫正为对齐数倍数,见下图,附上代码
#include<stdio.h>
union u
{char c[5];int i;
};
int main()
{union u uu;printf("%zd\n", sizeof(uu));return 0;
}
联合体的应用
也许你会问计算机内存这么大,联合体节省那一点空间真的有必要吗,但是联合体并不主要用于计算机中,在内存极其宝贵的硬件中,节省这样一些空间是很有必要的。
大小端判断(共用体版)
在上一篇博客讲到计算机内存时,曾讲过一段判断大小端的代码,链接放这里,可以去看,里面还有讲解大小端是什么。数据在内存中的存储-CSDN博客
今天我们要用联合体编写一段代码来判断大小端,见下代码
#include<stdio.h>
//n和s共用一块空间
//当给n赋值后用s可以随意取每个字节上的元素
int check_sys()
{union{char c;int i;}u;u.i = 1;return u.c;
}
int main()
{if (check_sys()) {printf("小端\n");}elseprintf("大端\n");return 0;
}
这样的代码是不是让人眼前一亮,当一个人对代码有很强的掌控力时,打代码便成了一种艺术。
枚举enum
定义枚举
通过关键字enum定义。eg:
enum Sex
{//这里列举枚举类型 性别 的可能取值MALE, //男FEMALE, //女SECRET //保密
};默认情况下,枚举的第一个成员的值是0,后续成员值依次递增,但同时我们可以给其指定值:
enum Sex
{//这里列举枚举类型 性别 的可能取值MALE = 3, //男FEMALE = 5, //女SECRET = 9 //保密
};枚举和#define定义常量很像,枚举变量里定义的值是符号常量。
故可以这样使用
#include<stdio.h>
enum Sex
{//这里列举枚举类型 性别 的可能取值MALE, //男FEMALE, //女SECRET //保密
};
int main()
{enum Sex zhangsan = MALE;if (zhangsan == MALE) {printf("张三是男的\n");}else printf("张三是女的\n");return 0;
} 
枚举的优点
1.代码可读性:枚举常量的使用可以提高代码的可读性和可维护性
2.类型安全:枚举提供了一个类型安全的方法来表示一组整数值
3.调试方便:调试时,枚举变量可同时显示其字符常量和其值,便于观察
结语
到了这里,结构体,联合体和枚举就介绍完了,一篇博客费时费力,画图也是一大难点,看在我这么辛辛苦苦写博客的份上,给个小小的赞不过分吧。如果感觉这篇博客对你有帮助的话,还请给个小小的赞再走啊!比心---♥
相关文章:
自定义类型-结构体,联合体和枚举-C语言
引言 能看到结构体,说明C语言想必学习的时间也不少了,在之前肯定也学习过基本数据类型,包括整型int,浮点型float等等。可是在日常生活中,想要描述一个事物并没有那么简单。比如,你要描述一本书,…...

Windows 安装redis,设置开机自启动
Windows 安装redis,设置开机自启动 文章目录 Windows 安装redis,设置开机自启动下载, 解压到指定目录设置redis密码启动redis服务端停止redis服务端设置自启动 下载, 解压到指定目录 官网地址: https://redis.io/ 安装包下载地址: https://github.com/tporadowski/redis/relea…...

Windows安装Mysql Workbench及常用操作
Mysql Workbench是mysql自带的可视化操作界面,功能是强大的,但界面和navicat比,就是觉得别扭,但其实用惯了也还好,各有特色吧。这里记录一下常用的操作。 官方手册:MySQL Workbench 一、安装 1. 下载 官方…...
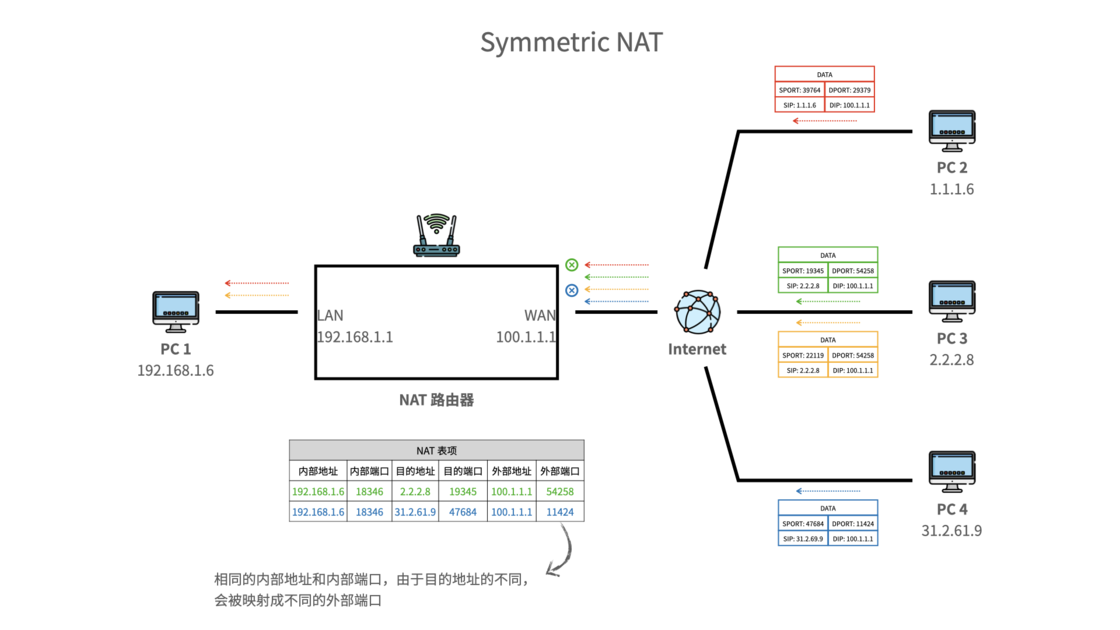
【计算机网络】15、NAT、NAPT 网络地址转换、打洞
文章目录 一、概念二、分类(主要是传统 NAT)2.1 基本 NAT2.2 NAPT 三、访问NAT下的内网设备的方式3.1 多拨3.2 端口转发、DMZ3.3 UPnP IGD、NAT-PMP3.4 服务器中转:frp 内网穿透3.4.1 NAT 打洞3.4.2 NAT 类型与打洞成功率3.4.2.1 完全圆锥形 …...

【送书活动三期】解决docker服务假死问题
工作中使用docker-compose部署容器,有时候会出现使用docker-compose stop或docker-compose down命令想停掉容器,但是依然无法停止或者一直卡顿在停止中的阶段,这种问题很让人头疼啊! 目录 问题描述问题排查问题解决终极杀招-最粗暴…...

【每日一题】拼车+【差分数组】
文章目录 Tag题目来源解题思路方法一:差分 写在最后 Tag 【差分数组】【数组】【2023-12-02】 题目来源 1094. 拼车 解题思路 本题朴素的解题思路是统计题目中提到的每一个站点的车上人数,如果某个站点的车上人数大于车上的座位数直接返回 false&…...

【开源】基于JAVA的农村物流配送系统
项目编号: S 024 ,文末获取源码。 \color{red}{项目编号:S024,文末获取源码。} 项目编号:S024,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 系统登录、注册界面2.2 系统功能2.2…...
7、Jenkins+Nexus3+Docker+K8s实现CICD
文章目录 基本环境配置一、Jenkins安装必要插件二、Jenkins系统配置三、新建流水线四、在项目工程里添加Jenkinsfile、deploy.yml五、在项目工程里添加Dockerfile在这里插入图片描述 总结 提示:本章主要记录各基本环境搭建好后如何配置Jenkins流水线部署微服务到K8s…...
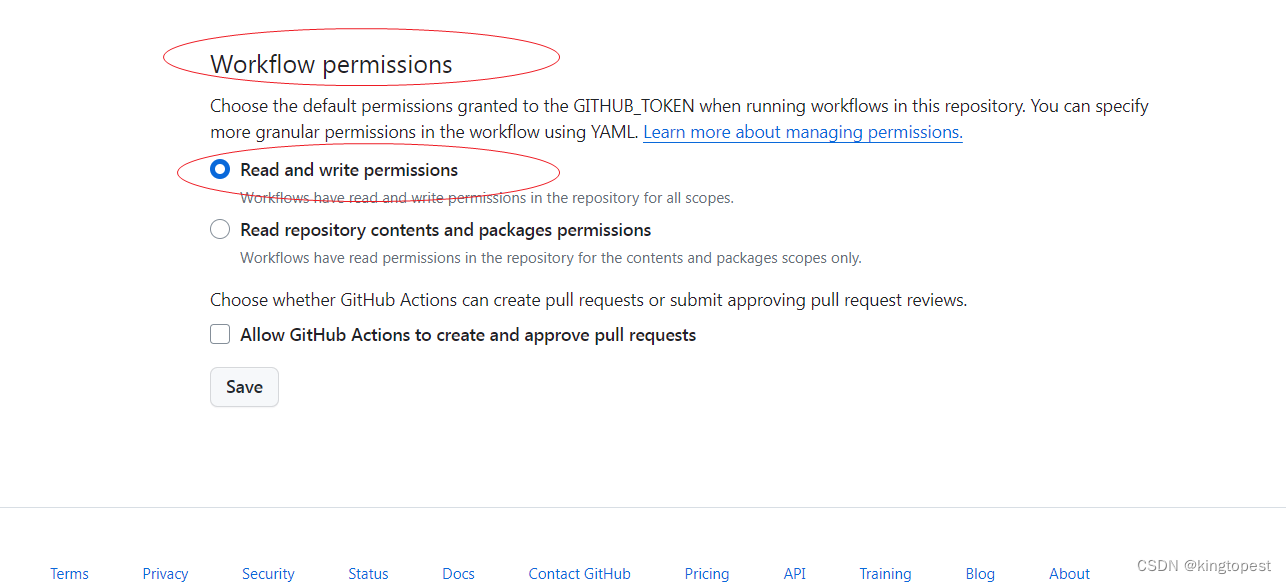
解决git action发布失败报错:Error: Resource not accessible by integration
现象: 网上说的解决方法都是什么到github个人中心setting里面的action设置里面去找。 可这玩意根本就没有! 正确解决办法: 在你的仓库页面,注意是仓库页面的setting里面: Actions> General>Workflow permisss…...

[传智杯 #2 决赛] 补刀
题目描述 UIM 在写程序的空闲玩一款 MOBA 游戏。 当敌方的小兵进入到我方防御塔的范围内,就会持续受到防御塔造成的伤害;当然我方英雄也可以对它造成伤害。当小兵的血量降到了 0 或者更低,就会被击杀。为了获得经验,UIM 希望在防…...

C语言:求Sn=a+aa+aaa+aaaa+……(n个a)之值,其中a表示一个数字,n表示a的位数,n由键盘录入。
分析: 在主函数 main 中,程序首先定义四个整型变量 a、n、i 和 sn,并初始化 a、n 和 i 的值,其中 sn 用于记录数列的和。然后使用 scanf 函数从标准输入中读取用户输入的两个整数 a 和 n。 接下来,程序通过 while …...
)
【nlp】4.1 fasttext工具介绍(文本分类、训练词向量、词向量迁移)
fasttext工具介绍与文本分类 1 fasttext介绍1.1 fasttext作用1.2 fasttext工具包的优势1.3 fasttext的安装1.4 验证安装2 fasttext文本分类2.1 文本分类概念2.2 文本分类种类2.3 文本分类的过程2.4 文本分类代码实现2.4.1 获取数据2.4.2 训练集与验证集的划分2.4.3 训练模型2.4…...

Spring中的事务管理
1 基本概念 事务:将一组操作抽象成一个不可再分的单位,这组操作可以有很多个,但是它们要么就全部都执行成功,这时算作事务执行成功;要不其中有操作执行失败,则其余操作都视为执行失败,这时候需…...

量子光学的进步:光子学的“下一件小事”
量子光学是量子力学和光学交叉领域中发展迅速的一门学科,探索光的基本特性及其与物质在量子水平上的相互作用。通过利用光的独特特性,量子光学为通信、计算、密码学和传感等各个学科的变革性进步铺平了道路。 如今,量子光学领域的研究人员和工…...

微信小程序获取定位显示在百度地图上位置出现偏差
项目场景: 背景: 微信小程序端获取手机定位坐标,以及正确展示位置通过详细地址解析为定位坐标显示在小程序端以及PC后台小程序获取的地理坐标与百度地图坐标相互转化 相关知识 目前国内主要有以下三种坐标系: WGS84:…...
 数据结构设计)
【LeetCode 0170】【哈希】两数之和(3) 数据结构设计
https://leetcode.com/problems/two-sum-iii-data-structure-design/ 描述 Design and implement a TwoSum class. It should support the following operations: add and find. add(input) – Add the number input to an internal data structure. find(value) – Find if …...
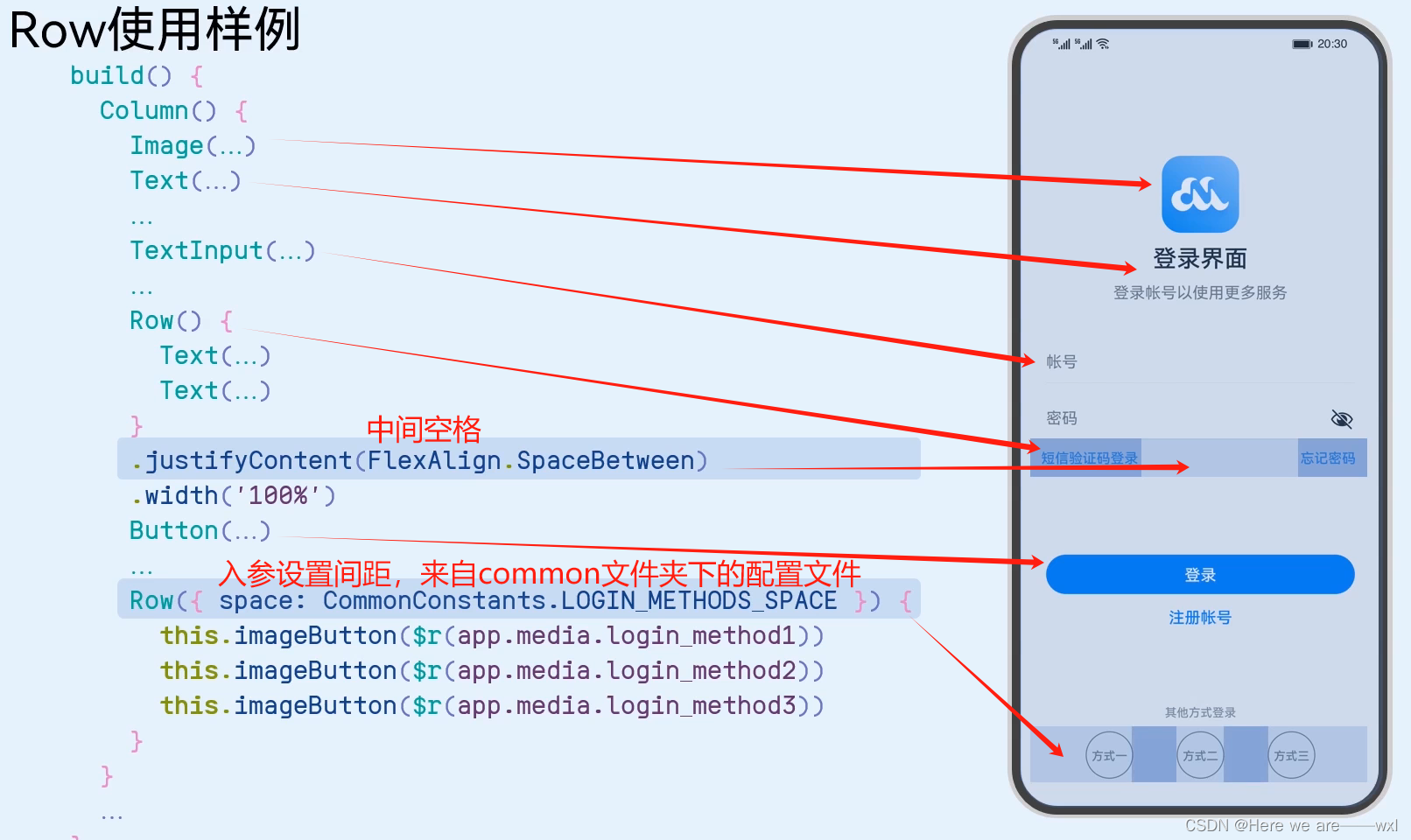
005、简单页面-容器组件
之——布局 目录 之——布局 杂谈 正文 1.布局基础知识 2.Column 3.Row 4.实践 杂谈 布局容器组件。 一个丰富的页面需要很多组件组成,那么,我们如何才能让这些组件有条不紊地在页面上布局呢?这就需要借助容器组件来实现。 容器组件是…...

stm32中断调用流程
USART1_IRQHandler(void)(中断服务函数) -> HAL_UART_IRQHandler(UART_HandleTypeDef *huart)(中断处理函数) -> UART_Receive_IT(UART_HandleTypeDef *huart) (接收函数) -> HAL_UART_RxCpltCallback(huart);(中断回调函数) HAL_UART_IRQHandler(UART_HandleTypeDef…...
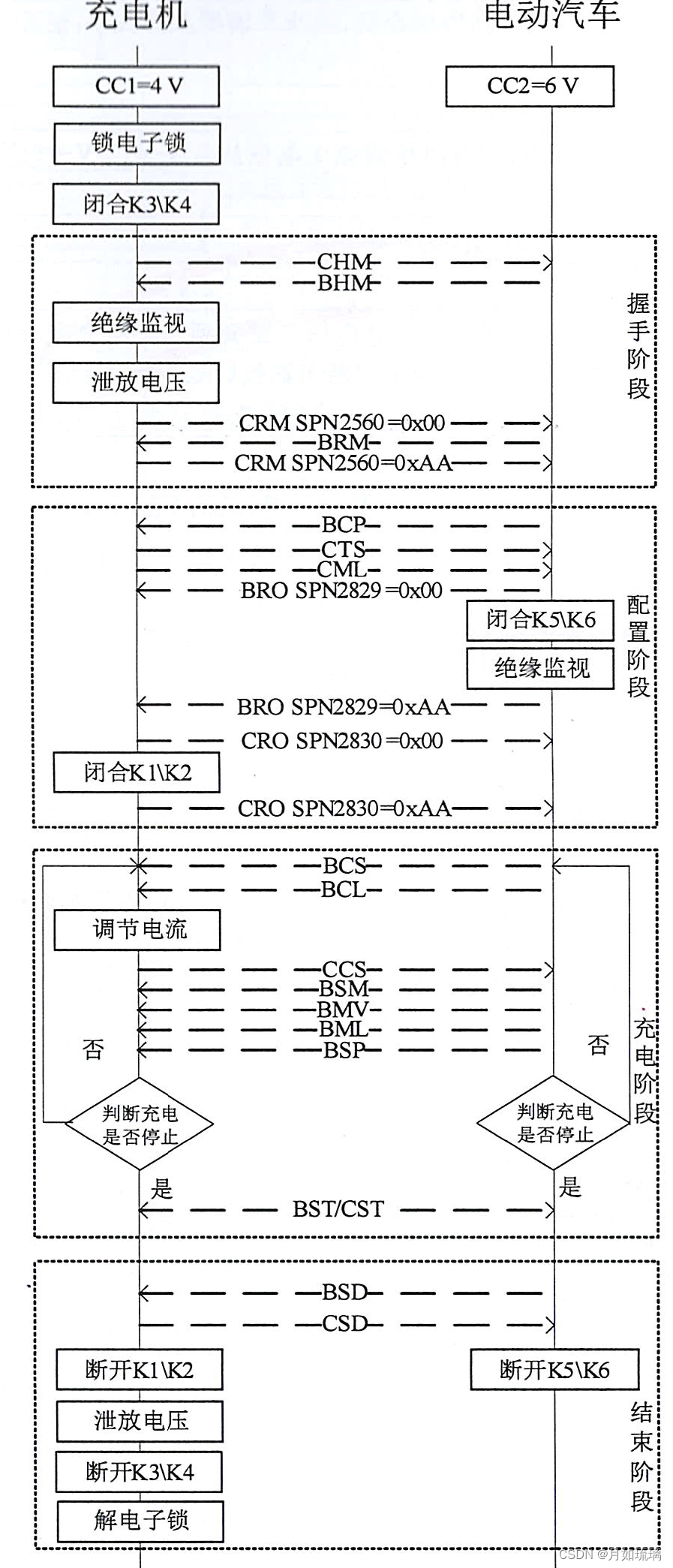
18487.1 - 2015 电动汽车充电系统标准 第1部分 关键点梳理
一、部分知识介绍 1、连接方式 使用电缆和连接器将电动汽车接入电网(电源)的方法。 1.1、连接方式A 1.2、连接方式B 1.3、连接方式C 2、电动汽车控电设备 2.1、按照输出电压分类 1)交流 单相 220V,三相 380V. 2)…...
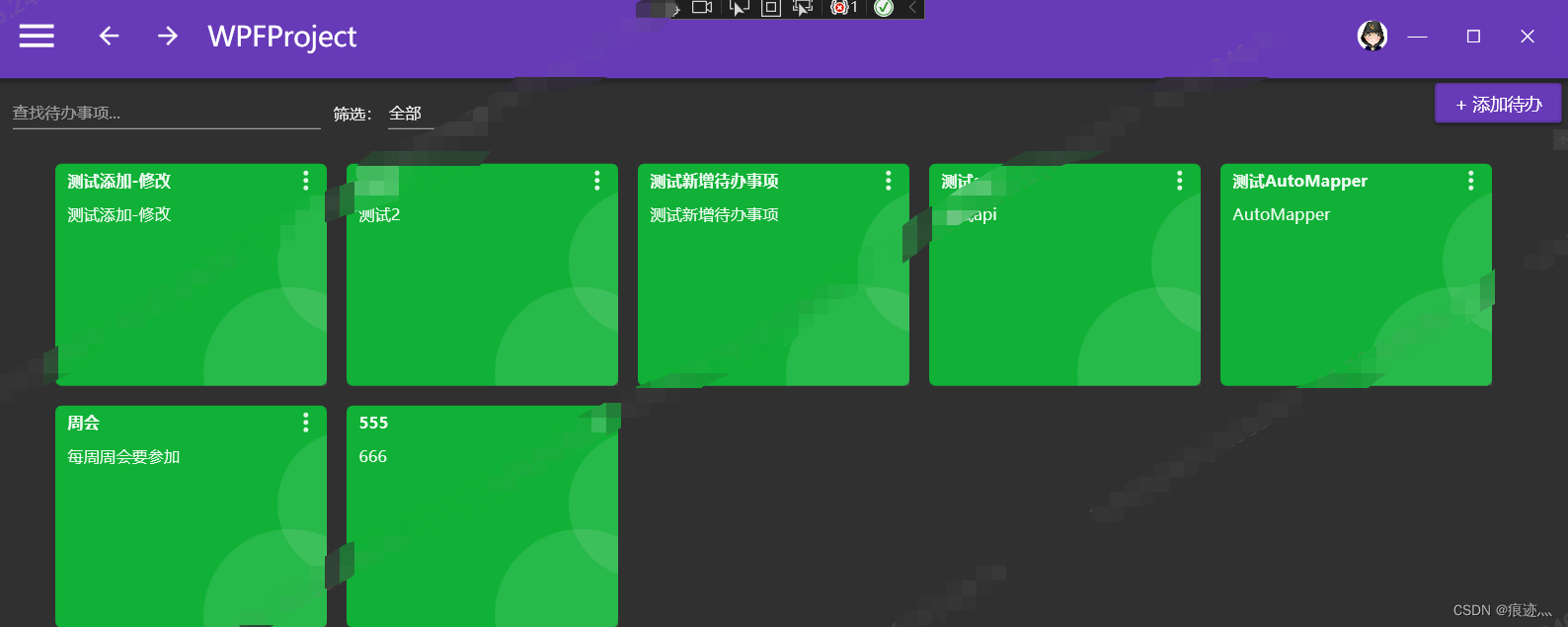
WPF实战项目十八(客户端):添加新增、查询、编辑功能
1、ToDoView.xmal添加引用,添加微软的行为类 xmlns:i"http://schemas.microsoft.com/xaml/behaviors" 2、给项目添加行为 <i:Interaction.Triggers><i:EventTrigger EventName"MouseLeftButtonUp"><i:InvokeCommandAction Com…...

从参数化几何到气动分析:OpenVSP航空设计工具深度解析
从参数化几何到气动分析:OpenVSP航空设计工具深度解析 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP 在航空工程领域,如何将概念设计快速转化为可分析的几何模型一直是技…...

Qwen-Image-Layered快速部署:ComfyUI镜像一键启动与配置
Qwen-Image-Layered快速部署:ComfyUI镜像一键启动与配置 1. 引言:图像分层的革命性突破 1.1 传统图像编辑的痛点 在常规的图像处理流程中,我们常常遇到一个根本性难题:图像一旦生成或拍摄完成,就变成了一个"不…...

如何通过GitHub配置Resume简历:无需代码的终极解决方案
如何通过GitHub配置Resume简历:无需代码的终极解决方案 【免费下载链接】resume 🚀 在线简历生成器 项目地址: https://gitcode.com/gh_mirrors/resu/resume Resume是一款功能强大的在线简历生成器,让你无需编写代码即可轻松创建专业简…...

Phi-4-mini-reasoning效果验证:在MMLU-Pro数学子集上的实际推理准确率展示
Phi-4-mini-reasoning效果验证:在MMLU-Pro数学子集上的实际推理准确率展示 1. 模型概述 Phi-4-mini-reasoning是一款3.8B参数的轻量级开源模型,由微软Azure AI Foundry团队开发。这款模型专为数学推理、逻辑推导和多步解题等强逻辑任务设计,…...

3个高效网页资源捕获方案:猫抓插件技术解析与实战指南
3个高效网页资源捕获方案:猫抓插件技术解析与实战指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&…...

SEO_为什么你的网站需要持续进行SEO优化?
SEO优化的重要性:为什么你的网站需要持续进行SEO优化 在当前竞争激烈的互联网市场中,网站的流量和用户参与度直接影响着企业的成功与否。为什么你的网站需要持续进行SEO优化呢?SEO(搜索引擎优化)不仅是提升网站在搜索…...
)
Vue3+TS+Vite项目实战:5分钟搞定Mock数据接入(附完整代码)
Vue3TSVite项目实战:5分钟实现动态权限Mock系统 最近在重构后台管理系统时,遇到一个典型痛点:前端页面都开发完了,后端接口还在设计中。这种前后端进度不匹配的情况,相信每个前端开发者都深有体会。今天分享的这套Mock…...

光伏储能并网仿真实战手记:PQ控制与扰动观察法的那些事儿
光伏储能三相PQ恒功率并网控制仿真(附参考文献及文档)①网侧 光伏储能三相PQ恒功率并网控制仿真(附参考文献及文档)①网侧:采用PQ恒功率控制,参考文献《微电网及其逆变器控制技术的研究》②储能控制:直流母线电压外环,电池电流内环双闭环控制策略直流母线…...

利用 Worker Threads 优化 Vite 构建性能的实战
背景在我们的前端工程化实践中,随着项目规模的扩大,构建效率问题逐渐凸显。特别是在生产环境构建流程中,为了保护源码逻辑,我们通常会引入 JavaScript 混淆工具(如 javascript-obfuscator)。这一步虽然必要…...

Antigravity Skills 全局安装与配置指南
1. 核心概念在 Antigravity 中,技能系统分为两层:Skills (全局库):实际的代码、脚本和指南,存储在系统级目录(如 ~/.gemini/antigravity/skills)。它们是“能力”的本体。Workflows (项目级):存…...