VIT总结
关于transformer、VIT和Swin T的总结
1.transformer
1.1.注意力机制
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.[1]
输入是query和 key-value,注意力机制首先计算query与每个key的关联性(compatibility),每个关联性作为每个value的权重(weight),各个权重与value的乘积相加得到输出。
Attention Is All You Need 中用到的attention叫做“Scaled Dot-Product Attention”,具体过程如下图所示:
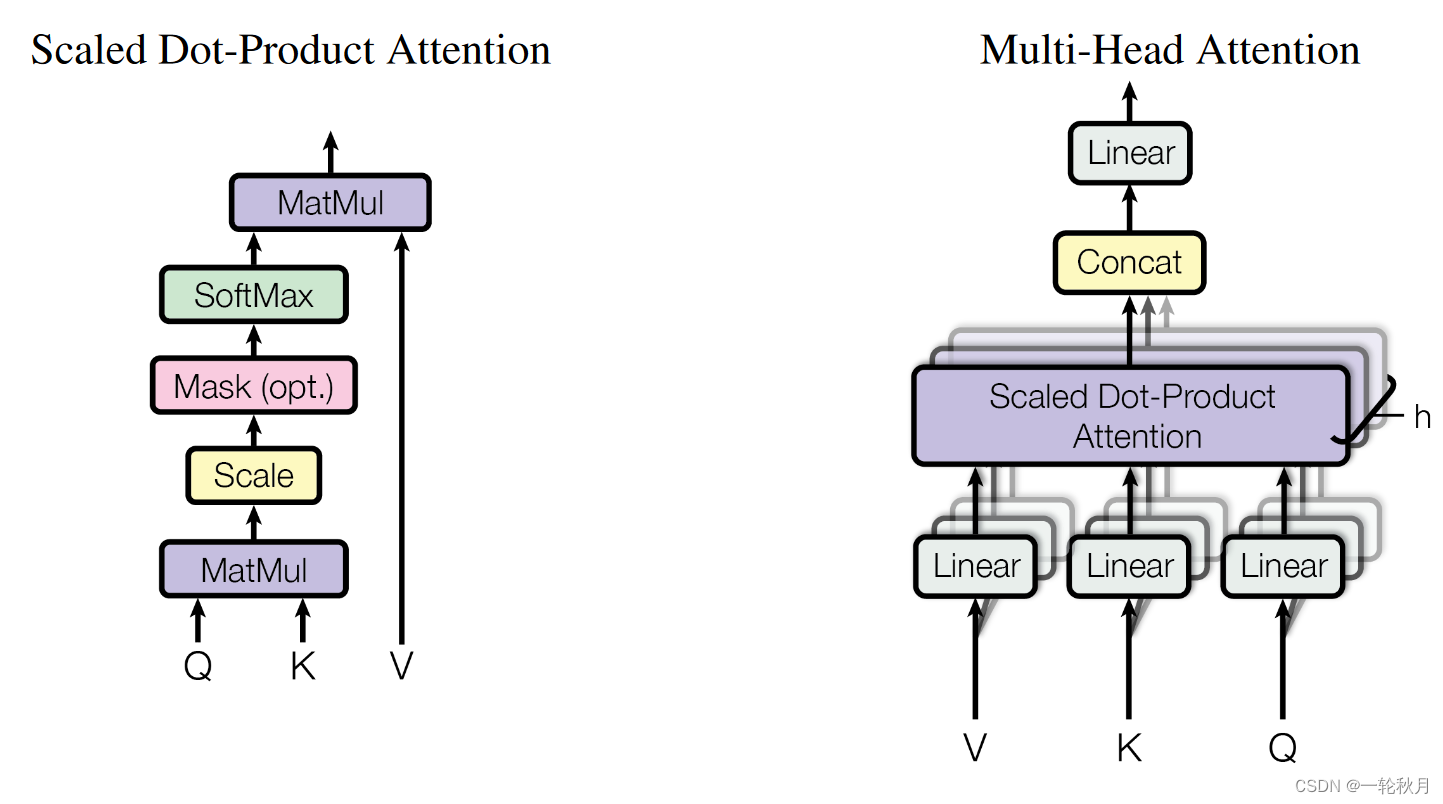
代码实现:
import torch
import torch.nn as nnclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0] # the number of training examplesvalue_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])# queries shape: (N, query_len, heads, heads_dim)# keys shape: (N, key_len, heads, heads_dim)# energy shape: (N, heads, query_len, key_len)if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))# Fills elements of self tensor with value where mask is Trueattention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)# attention shape: (N, heads, query_len, key_len)# values shape: (N, value_len, heads, head_dim)# after einsum (N, query_len, heads, head_dim) then flatten last two dimensionsout = self.fc_out(out)return out1.为什么有mask?
NLP处理不定长文本需要padding,但是padding的内容无意义,所以处理时需要mask.
2.关于qkv
qkv是相同的,需要查询的q,与每一个key相乘得到权重信息,权重与v相乘,这样结果受权重大的v影响
3.为什么除以根号dk
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients 4. To counteract this effect, we scale the dot products by 1 √dk
点积过大,经过softmax,进入饱和区,梯度很小
4.为什么需要多头

不同头部的output就是从不同层面(representation subspace)考虑关联性而得到的输出。
1.2.TransformerBlock
解码端的后面两部分和编码段一样,所以打包成一个类
class TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return out
1.3.Encoder
关键的就是位置编码
class Encoder(nn.Module):def __init__(self,src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_lengh = x.shapepositions = torch.arange(0, seq_lengh).expand(N, seq_lengh).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return out
2.VIT
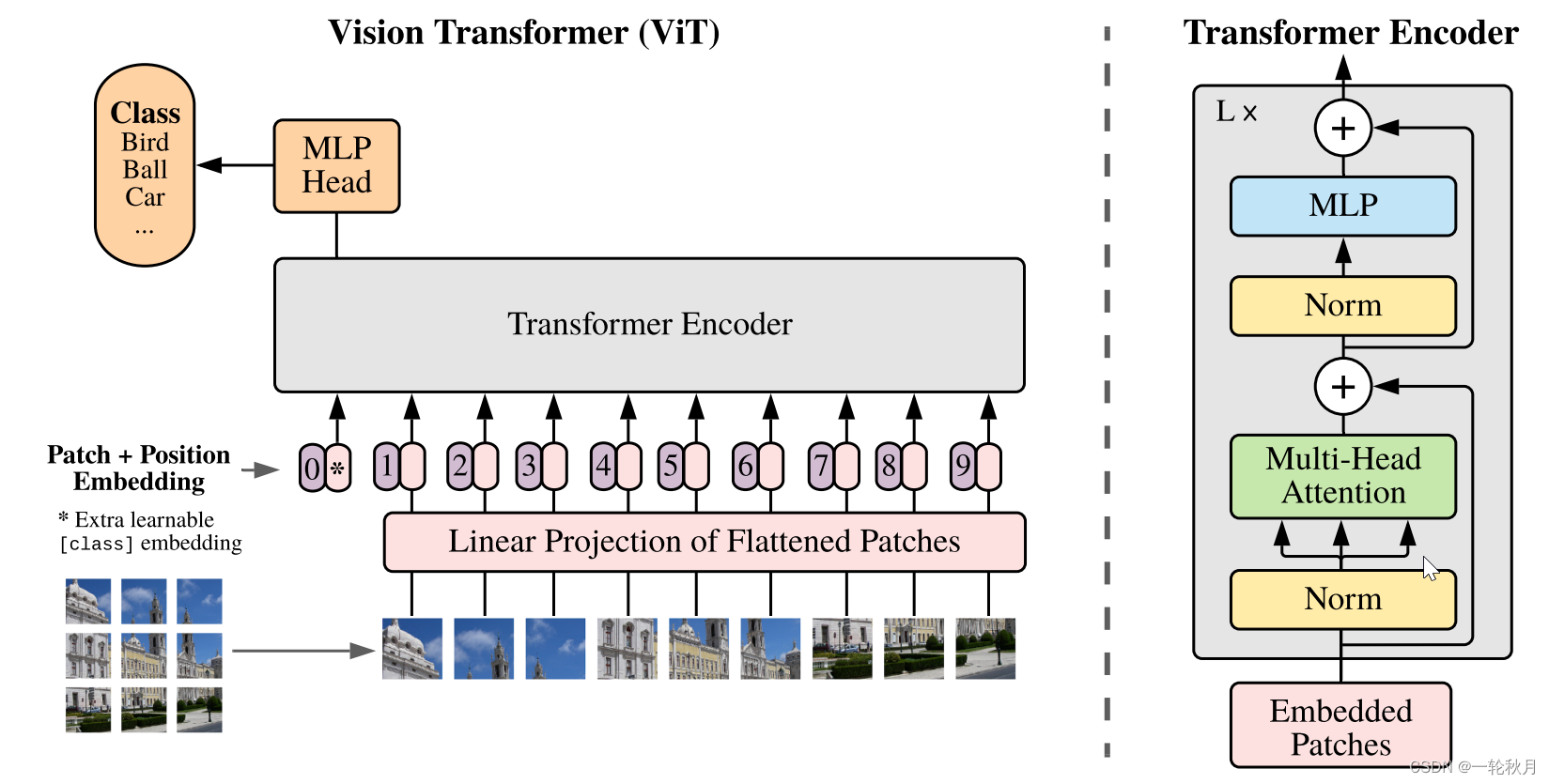
Reference:
[1].Attention Is All You Need
[2].https://zhuanlan.zhihu.com/p/366592542
[3].代码实现:https://zhuanlan.zhihu.com/p/653170203
[4].An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
相关文章:
VIT总结
关于transformer、VIT和Swin T的总结 1.transformer 1.1.注意力机制 An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a wei…...

C++11——initializer_list
initializer_list的简介 initializer_list是C11新出的一个类型,正如类型的简介所说,initializer_list一般用于作为构造函数的参数,来让我们更方便赋值 但是光看这些,我们还是不知道initializer_list到底是个什么类型,…...
数学字体 Mathematical fonts
Mathematical fonts 数学字体: ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzRQSZ \\ \mathcal{ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzRQSZ} \\ \mathfrak{ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzRQSZ} \\ \mathbb{ABC…...

Python简单模拟蓝牙车钥匙协议
本文设计一个简单的蓝牙车钥匙协议,协议包含DH密钥协商和基于RSA的身份认证功能,以及防重放与消息完整性验证。 1. 密钥协商过程: - 设定 DH 参数:素数 p 和生成元 g。 - 发送方(Alice)生成 DH 的私钥 a 并计算公钥 A…...

【Python3】【力扣题】383. 赎金信
【力扣题】题目描述: 题解: 两个字符串ransomNote和magazine,ransomNote中每个字母都在magazine中一一对应(顺序可以不同)。 即分别统计两个字符串中每个字母出现的次数,ransomNote中每个字母的个数小于等…...

外包搞了6年,技术退步明显......
先说情况,大专毕业,18年通过校招进入湖南某软件公司,干了接近6年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...
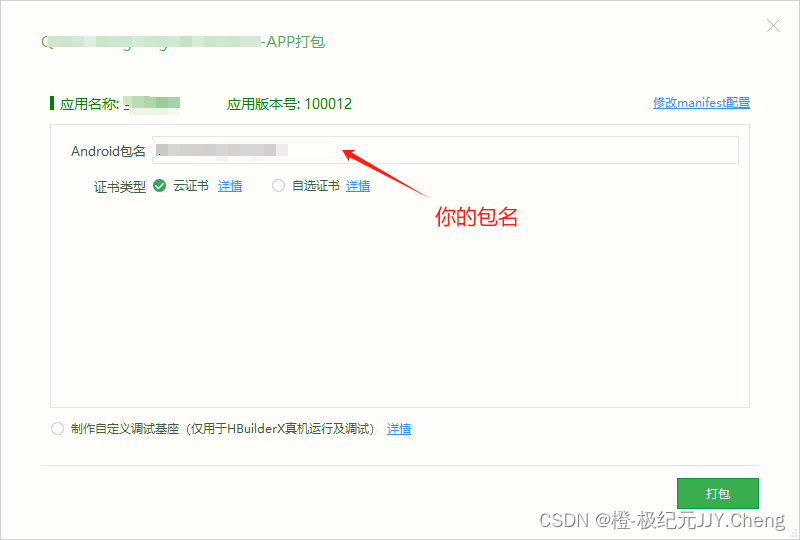
uni-app x生成的安卓包,安装时,提示不兼容。解决方案
找到 manifest.json 进入:源码视图 代码 {"name" : "xxx康养","appid" : "__xxx6","description" : "xxx康养","versionName" : "1.0.12","versionCode" : 100012,&…...

Screenshot To Code
序言 对于GPT-4我只是一个门外汉,至于我为什么要了解screenshot to code,只是因为我想知道,在我不懂前端设计的情况下,能不能通过一些工具辅助自己做一些简单的前端界面设计。如果你想通过此文深刻了解GPT-4或者该开源项目&#…...
SpringBoot 是如何启动一个内置的Tomcat
为什么说Spring Boot框架内置Tomcat 容器,Spring Boot框架又是怎么样去启动Tomcat的?我简单总结下学习过程。 一:简单了解SpringBoot的启动类 我们都知道Spring Boot框架的启动类上是需要使用 @SpringBootApplication 注解标注的, @SpringBootApplication 是一个复合注解…...
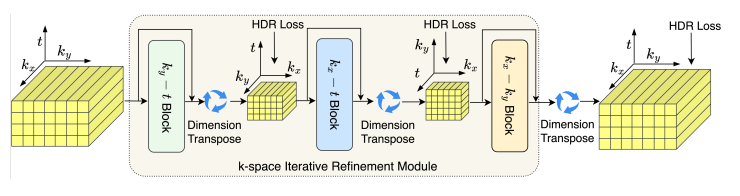
《功能磁共振多变量模式分析中空间分辨率对解码精度的影响》论文阅读
《The effect of spatial resolution on decoding accuracy in fMRI multivariate pattern analysis》 文章目录 一、简介论文的基本信息摘要 二、论文主要内容语音刺激的解码任务多变量模式分析(MVPA)K空间 空间分辨率和平滑对MVPA的影响平滑的具体过程…...
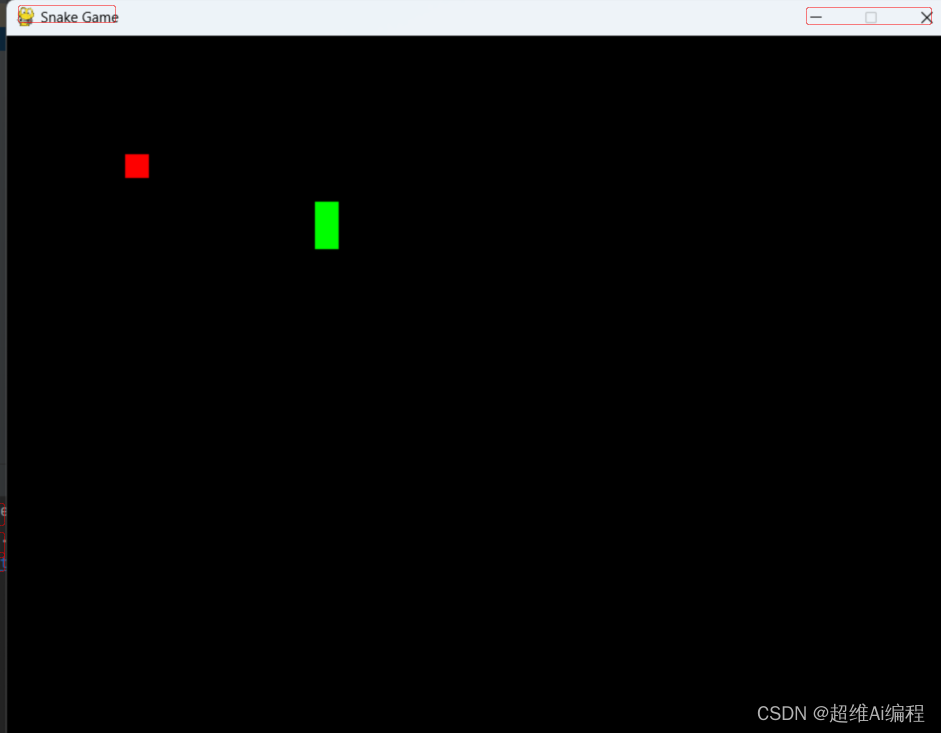
pygame实现贪吃蛇小游戏
import pygame import random# 游戏初始化 pygame.init()# 游戏窗口设置 win_width, win_height 800, 600 window pygame.display.set_mode((win_width, win_height)) pygame.display.set_caption("Snake Game")# 颜色设置 WHITE (255, 255, 255) BLACK (0, 0, 0…...
反序列化漏洞(二)
目录 pop链前置知识,魔术方法触发规则 pop构造链解释(开始烧脑了) 字符串逃逸基础 字符减少 字符串逃逸基础 字符增加 实例获取flag 字符串增多逃逸 字符串减少逃逸 延续反序列化漏洞(一)的内容 pop链前置知识,魔术方法触…...
【开箱即用】前后端同时开源!周末和AI用Go语言共同研发了一款笔记留言小程序!
大家好,我是豆小匠。 真的是当你在怀疑AI会不会取代人类的时候,别人已经用AI工具加速几倍的生产速度了… 周末体验了和AI共同开发的感受,小项目真的可以一人全干了… 本次实验使用的AI工具有两个:1. GitHub Copilot(…...

java对xml压缩
import java.util.*; import java.util.zip.GZIPOutputStream; import java.nio.charset.StandardCharsets; import org.apache.commons.codec.binary.Base64;/*** 模板压缩** param xml 模板xml* return* throws Exception*/public static String businessData(String xml) th…...
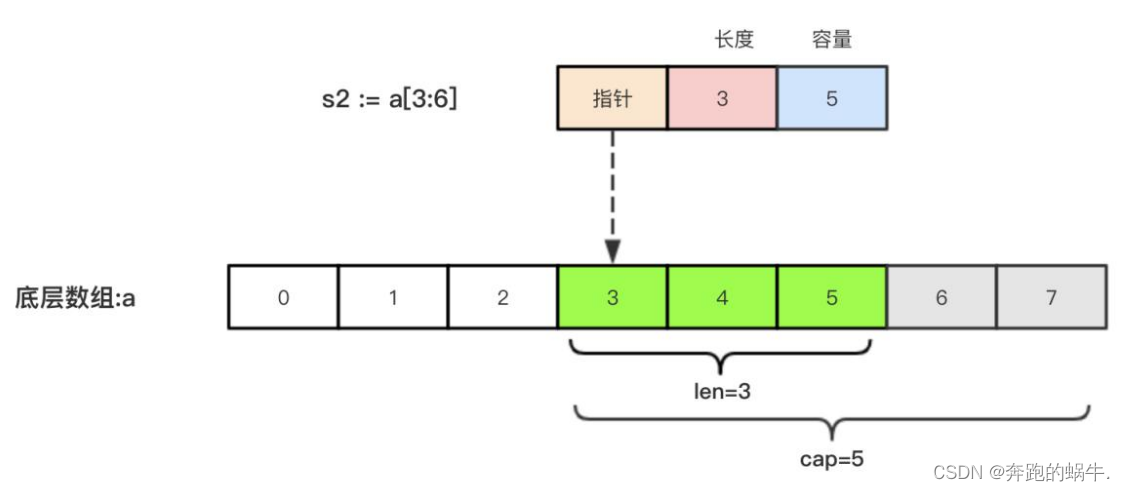
GoLang切片
一、切片基础 1、切片的定义 切片(Slice)是一个拥有相同类型元素的可变长度的序列它是基于数组类型做的一层封装它非常灵活,支持自动扩容切片是一个引用类型,它的内部结构包含地址、长度和容量声明切片类型的基本语法如下&#…...
前端入门(四)Ajax、Promise异步、Axios通信、vue-router路由、组件库
文章目录 AjaxAjax特点 Promise 异步编程(缺)Promise基本使用状态 - PromiseState结果 - PromiseResult AxiosVue中使用AxiosAxios请求方式getpostput和patchdelete并发请求 Vue路由 - vue-router单页面Web应用(single page web application&…...

正则表达式回溯陷阱
一、匹配场景 判断一个句子是不是正规英文句子 text "I am a student" 一个正常的英文句子如上,英文单词 空格隔开 英文单词 多个英文字符 [a-zA-Z] 空格用 \s 表示 那么一个句子就是单词 空格(一个或者多个,最后那个单词…...
MATLAB实战 | S函数的设计与应用
S函数用于开发新的Simulink通用功能模块,是一种对模块库进行扩展的工具。S函数可以采用MATLAB语言、C、C、FORTRAN、Ada等语言编写。在S函数中使用文本方式输入公式、方程,非常适合复杂动态系统的数学描述,并且在仿真过程中可以对仿真进行更精…...
Day41 使用listwidget制作简易图片播放器
1.简介 使用QlistWidget实现简易图片播放器,可以打开一个图片序列,通过item的单击事件实现图片的切换,通过设置list的各种属性实现图片预览的显示,美化滚动条即可实现一个简易图片播放器。 2.效果 3.实现步骤: 1.初始…...
matlab 基于卡尔曼滤波的GPS-INS的数据融合的导航
1、内容简介 略 25-可以交流、咨询、答疑 2、内容说明 基于卡尔曼滤波的GPS-INS的数据融合的导航 "基于卡尔曼滤波的GPS-INS的数据融合的导航 基于卡尔曼滤波实现GPS-INS组合导航系统" 卡尔曼滤波、GPS、INS、数据融合、导航 3、仿真分析 4、参考论文 略 …...

Win11终极IPX协议兼容方案:IPXWrapper完整配置与优化指南
Win11终极IPX协议兼容方案:IPXWrapper完整配置与优化指南 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 在现代Windows 11系统上重温《星际争霸》、《魔兽争霸》、《暗黑破坏神2》等经典游戏时,你是否遇…...

4步永久保存青春记忆:GetQzonehistory让QQ空间备份如此简单
4步永久保存青春记忆:GetQzonehistory让QQ空间备份如此简单 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的青春记忆常常散落在各种社交平台中…...

告别系统臃肿:Win11Debloat三步配置流程让Windows运行效率提升51%
告别系统臃肿:Win11Debloat三步配置流程让Windows运行效率提升51% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...

Windows DLL注入工具Xenos实战指南:问题解决与效能优化
Windows DLL注入工具Xenos实战指南:问题解决与效能优化 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 引言 在Windows系统开发与调试过程中,DLL注入技术扮演着重要角色,无论是插件…...

终极指南:五分钟让Win11老游戏重获联机能力的完整解决方案
终极指南:五分钟让Win11老游戏重获联机能力的完整解决方案 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 还在为Win11系统下无法联机玩《星际争霸》《魔兽争霸2》《暗黑破坏神》等经典游戏而烦恼吗?今天…...

FireRedASR-AED-L从零开始教程:无需Python环境,镜像开箱即用识别中英混合语音
FireRedASR-AED-L从零开始教程:无需Python环境,镜像开箱即用识别中英混合语音 你是不是经常遇到这样的场景?手头有一段重要的会议录音,里面既有中文讨论,又夹杂着几个英文专业术语,想把它转成文字却找不到…...

Janus-Pro-7B自主部署:从nvidia-smi监控到supervisor服务管理
Janus-Pro-7B自主部署:从nvidia-smi监控到supervisor服务管理 1. 项目概述 Janus-Pro-7B是DeepSeek发布的一款统一多模态理解与生成模型,它突破了传统模型在处理不同任务时的冲突问题。这个模型支持图像问答、OCR识别、图表分析等多模态理解功能&#…...

Phi-3-mini-4k-instruct-gguf在中小企业内容运营中的应用:自动摘要与文案改写实战
Phi-3-mini-4k-instruct-gguf在中小企业内容运营中的应用:自动摘要与文案改写实战 1. 中小企业内容运营的痛点与机遇 对于中小企业来说,内容运营是品牌建设和客户沟通的重要环节。然而,在实际操作中,我们常常面临以下挑战&#…...

Local AI MusicGen创意展示:由‘neon lights vibe’触发的都市夜景音乐
Local AI MusicGen创意展示:由‘neon lights vibe’触发的都市夜景音乐 1. 引言:当AI遇见音乐创作 你有没有想过,用一段简单的文字描述就能生成一段专属的背景音乐?Local AI MusicGen让这个想法变成了现实。这是一个基于Meta Mu…...

Graphormer一键部署与运维监控实战
Graphormer一键部署与运维监控实战 1. 企业级AI模型运维挑战 在AI技术快速落地的今天,Graphormer作为图神经网络领域的先进模型,已经在推荐系统、分子属性预测等场景展现出强大能力。但很多企业在实际部署后常常面临运维难题:服务突然崩溃找…...