《数据结构与测绘程序设计》试题详细解析(仅供参考)
一. 选择题(每空2分,本题共30分)
(1)在一个单链表中,已知q所指结点是p所指结点的前驱结点,若在q和p之间插入结点s,则执行( B )。
A. s->next=p->next; p->next=s;
B. q->next=s; s->next=p;
C. p->next=s->next; s->next=p;
D. p->next=s; s->next=q;
【解析】:
在单链表中插入结点s,需要调整相关结点的指针指向。根据题目中给出的信息,q所指结点是p所指结点的前驱结点,因此需要先将q的next指针指向s,即q->next=s,然后将s的next指针指向p,即s->next=p。这样就完成了结点s的插入操作,同时保持了链表的正确连接关系。所以选项B是正确的语句。
(2)对于一个头指针为head的带头结点的单链表,判定该表为空表的条件是( B );对于不带头结点的单链表,判定空表的条件为( A )。
A. head= =NULL
B. head->next= =NULL
C. head->next= =head
D. head!=NULL
【解析】:
对于一个带头结点的单链表,判定该表为空表的条件是头结点的 next 指针为空,即 head->next == NULL。对于一个不带头结点的单链表,判定空表的条件是单链表的头指针为空,即 head == NULL。因为在不带头结点的单链表中,头指针指向第一个元素,如果头指针为空,则说明链表中没有任何元素。
(3)向一个栈顶指针为top的链栈中插入一个x结点,则执行( B )。
A. top->next=x
B. x->next=top; top=x
C. x->next=top->next; top->next=x
D. x->next=top, top=top->next
【解析】:
链栈是一种特殊的链表结构,插入结点时需要更新栈顶指针。在向链栈中插入结点x时,需要将x插入到栈顶位置,并更新栈顶指针top。
选项B中的语句x->next=top表示将结点x的next指针指向当前的栈顶元素,即将x插入到栈顶位置。同时,top=x将栈顶指针top更新为新插入的结点x。这样就完成了结点x的插入操作,并且正确地更新了栈顶指针。
所以选项B是正确的语句。
(4)链栈执行Pop操作,并将出栈的元素存在x中,应该执行( D )。
A. x=top; top=top->next
B. top=top->next; x=top->data
C. x=top->data
D. x=top->data; top=top->next
【解析】:
在链栈执行Pop操作时,需要将栈顶元素出栈,并将其数据域保存到x中。然后,更新栈顶指针top,使其指向下一个元素,完成出栈操作。
选项D中的语句x=top->data表示将栈顶元素的数据域保存到x中,而top=top->next表示将栈顶指针top更新为下一个元素的地址,即完成出栈操作。
所以选项D是正确的语句。
(5)设有一个顺序共享栈Share[0:n-1],其中第一个栈顶指针top1的初值为-1,第二个栈顶指针top2的初值为n,则判断共享栈满的条件是( A )。
A. top2-top1= =1
B. topl-top2= =1
C. top1= =top2
D.以上都不对
【解析】:
共享栈满的条件是两个栈顶指针之间相隔一个元素,因此,当两个栈满时,它们的栈顶指针相邻,即top2 - top1 == 1。
(6)用链式存储方式的队列进行删除操作时需要( D )。
A. 仅修改头指针
B. 头尾指针都要修改
C. 仅修改尾指针
D. 头尾指针可能都要修改
【解析】:
在链式存储方式的队列中,删除操作是从队列头部删除元素。如果删除的是队列中唯一的元素(即队列只有一个节点),那么删除后队列为空,需要同时修改头指针和尾指针,使它们都指向空。
另外,在某些特殊情况下,头指针和尾指针可能都需要被修改。例如,在循环队列中,当删除的是队列的最后一个元素时,需要将头指针和尾指针都指向空。
所以选项D. 头尾指针可能都要修改 是正确的。
(7)在一个链队列中,假设队头指针为front,队尾指针为rear,x所指向的元素需要入队,则需要执行的操作为( D )。
A. front=x, front=front->next
B. rear->next=x, rear=x
C. x->next=front->next, front=x
D. rear->next=x, x->next=null, rear=x
【解析】:
在链式存储方式的队列中,入队操作是在队列尾部插入元素。因此,需要修改队尾指针rear的指向,使其指向新插入的节点x,同时修改该节点的指针域next,使其指向空。
所以选项D. rear->next=x, x->next=null, rear=x 是正确的。而其他选项中,选项A中仅修改了front的指向,选项B中仅修改了rear的指向,选项C中修改了front和x的指向,这些都是不正确的。
(8)若一棵二叉树有126个结点,在第7层(根结点在第1层)至多有( B )个结点。
A. 32
B. 63
C. 64
D.不存在第7层
【解析】:
由于根结点在第 1 层,所以在第 7 层至多有 2^(7−1)−1=63 个结点。即,在第 7 层最多只有 63 个结点。
(9)已知一棵二叉树的后序序列为DABEC,中序序列为DEBAC ,则先序序列为( D )。
A. ACBED
B. DEABC
C. DECAB
D. CEDBA
【解析】:
- 后序序列的最后一个元素一定是根节点,即 C 是根节点。
- 在中序序列中找到根节点 C,根据根节点将中序序列划分为左子树和右子树。根据中序序列,可以得到左子树序列为 DEBA,右子树序列为空。
- 根据左子树序列 DEBA,结合后序序列,可以得到左子树的根结点为 E。
- 重复上述步骤,对左子树和右子树进行递归分析即可得到该二叉树的结构图。
(10)一个栈的入栈序列为 1,2,3,…,n,出栈序列是P1,P2,P3,…,Pn。若P2=3 ,则P3 可能取值的个数是( C )。
A. n-3
B. n-2
C. n-1
D.无法确定
【解析】:
根据题目描述,入栈序列为 1,2,3,…,n,出栈序列为 P1,P2,P3,…,Pn。如果 P2=3,则 P3 可能取值的个数可以通过观察入栈和出栈的过程来确定。
在这个例子中,元素 1 入栈后,P1 不会立即出栈,因为 P2=3,所以元素 3 入栈后,P3 才会出栈。也就是说,对于元素 3 来说,在它入栈之前,至少有两个元素(1 和 2)在它上面,所以 P3 可能的取值个数为 n-1。
因此,答案是 C. n-1。
(11)链式栈结点为 (data, link),top 指向栈顶,若想摘除栈顶结点,并将删除结点的值保存到x中,则应执行操作( A )。
A. x=top->data; top=top->link;
B. x=top; top=top->link;
C. top=top->link; x=top->link;
D. x=top->link;
【解析】:
在链式栈中,栈顶指针top指向栈顶结点。如果要摘除栈顶结点并将删除结点的值保存到x中,需要先保存栈顶结点的值,然后修改栈顶指针top,使其指向下一个结点。
所以选项A. x=top->data; top=top->link; 是正确的。它首先将栈顶结点的值保存到x中,然后将栈顶指针top移动到下一个结点。
其他选项中,选项B中将x直接指向top,而不是保存栈顶结点的值,选项C中修改top后再将x指向top的link域,选项D中将x指向top的link域,这些都是不正确的。
(12)设栈 S 和队列 Q 的初始状态为空,元素 e1、e2、e3、e4、e5 和 e6 依次进入栈 S,一个元素出栈后即进入 Q,若 6 个元素出队的序列是 e2、e4、e3、e6、e5 和 e1,则栈 S 的容量至少应该是( B )。
A. 2
B. 3
C. 4
D. 6
【解析】:
根据题目描述,元素依次进入栈 S,然后一个元素出栈后即进入队列 Q。那么来模拟一下这个过程:
- e1 进入栈 S
- e2 进入栈 S
- e3 进入栈 S
- e4 进入栈 S
此时栈 S 中的元素为 e1、e2、e3、e4,栈的容量至少应该是 4。
- e4 出栈并进入队列 Q
- e3 出栈并进入队列 Q
- e2 出栈并进入队列 Q
此时栈 S 中的元素为 e1,栈的容量可以为 1。
- e5 进入栈 S
- e6 进入栈 S
此时栈 S 中的元素为 e1、e5、e6,栈的容量至少应该是 3。
因此,根据题目给出的出队序列,栈 S 的容量至少应该是 3,所以答案是 B. 3。
(13)若一个栈以向量 V[1,…,n] 存储,初始栈顶指针 top 设为 n+1,则元素x进栈的正确操作是( C )。
A. top++; V[top]=x;
B. V[top]=x; top++;
C. top--; V[top]=x;
D. V[top]=x; top--;
【解析】:
根据题目描述,栈以向量 V[1,…,n] 存储,并且初始栈顶指针 top 设为 n+1。这意味着栈的存储空间是从下标 1 到 n 的连续向量,初始时栈为空,栈顶指针指向 n+1。
当元素 x 进栈时,需要先将栈顶指针 top 向下移动一位,然后将元素 x 存储到栈顶位置 V[top]。所以选项 C. top--; V[top]=x; 是正确的。
其他选项中,选项 A 中先将栈顶指针 top 向上移动一位,然后再将元素 x 存储到栈顶位置 V[top],这样会导致栈顶指针指向错误的位置;选项 B 中先将元素 x 存储到栈顶位置 V[top],然后再将栈顶指针 top 向上移动一位,这样会导致元素 x 存储在了错误的位置;选项 D 中先将元素 x 存储到栈顶位置 V[top],然后再将栈顶指针 top 向下移动一位,这样会导致栈顶指针指向错误的位置。
因此,正确的语句是 C. top--; V[top]=x;
(14)设有一个 10 阶的对称矩阵 A,采用压缩存储方式,以行序为主存储,a11 为第一元素,其存储地址为 1,每个元素占一个地址空问,则 a85 的地址为( C )。
A. 13
B. 32
C. 33
D. 40
【解析】:
根据题目描述,对称矩阵 A 采用压缩存储方式,以行序为主存储。矩阵 A 是 10 阶的,即有 10 行和 10 列。
在压缩存储方式中,只需要存储矩阵的上三角或下三角部分(不包括对角线),因为对称矩阵的上下三角是对称的。
根据这种压缩存储方式,矩阵 A 的第一行(从 a11 到 a1n)的元素将依次存储在地址 1 到 n-1 的位置上。第二行(从 a22 到 a2n)的元素将依次存储在地址 n 到 2n-3 的位置上。
依此类推,矩阵 A 的第十行(从 a101 到 a10n)的元素将依次存储在地址 9n-8 到 9n-9 的位置上。
所以,a85 的地址为 33 是正确的。
二. 算法设计题(每小题5分,本题共20分)
(1)已知某二叉树的先序序列和中序序列分别为ABDEHCFIMGJKL和DBHEAIMFCGKLJ,请画出这棵二叉树,并画出二叉树对应的森林。
【标答】:

【解析】:
首先,根据先序序列和中序序列构造二叉树的步骤如下:
- 先序序列的第一个节点为整棵树的根节点,这里根据先序序列可以确定根节点为 A。
- 在中序序列中找到根节点所在位置,根节点将中序序列分为左子树和右子树的中序序列。可以确定左子树为 DBHE, 右子树为 IMFCGKLJ。
- 根据左子树可以确定左子树的根节点为 B, 根据右子树可以确定右子树的根节点为 C。
- 重复以上步骤,对左子树和右子树分别进行递归,直到得到整棵树的结构。
根据上述步骤,可以得到以上二叉树的结构。
(2)回文是指正读反读均相同的字符序列,如“abba”和“abdba”均是回文,但“good”不是回文。试写一个算法(伪码)判定给定的字符序列是否为回文。(提示:将一半字符入栈。)
【标答】:

【解析】:
以下是一个“用于判断给定的字符序列是否为回文”的C语言代码:
#include <stdio.h>
#include <string.h>#define MAX_SIZE 100// 定义栈结构
struct Stack {int top;char items[MAX_SIZE];
};// 初始化栈
void initialize(struct Stack *s) {s->top = -1;
}// 将元素压入栈
void push(struct Stack *s, char c) {s->items[++(s->top)] = c;
}// 从栈中弹出元素
char pop(struct Stack *s) {return s->items[(s->top)--];
}// 判断字符序列是否为回文
int isPalindrome(char *str) {int length = strlen(str);int i, mid = length / 2;struct Stack s;// 初始化栈initialize(&s);// 将前一半字符入栈for (i = 0; i < mid; i++) {push(&s, str[i]);}// 比较栈中的字符与字符串的后一半字符for (i = mid + length % 2; i < length; i++) {if (str[i] != pop(&s)) {return 0;}}return 1;
}int main() {char str[MAX_SIZE];printf("请输入一个字符序列:");scanf("%s", str);if (isPalindrome(str)) {printf("是回文。\n");} else {printf("不是回文。\n");}return 0;
}
在上述代码中,首先定义了一个栈的结构和相关操作函数,并且使用这些操作函数来实现判断回文的功能。主要步骤包括:
- 初始化栈并定义栈操作函数。
- 将给定字符序列的前一半字符依次入栈。
- 依次比较栈中的字符与字符序列的后一半字符,如果全部相同则判定为回文。
这个算法的时间复杂度为 O(n),其中 n 是字符序列的长度。
(3)设L为带头结点的单链表,编写算法(伪码)实现从尾到头反向输出每个结点的值。
【标答】:

【解析】:
以下是实现“从尾到头反向输出每个结点的值”的C语言代码:
#include <stdio.h>
#include <stdlib.h>struct ListNode {int val;struct ListNode* next;
};void printListReverse(struct ListNode* head) {if (head == NULL) {return;}printListReverse(head->next);printf("%d ", head->val);
}int main() {struct ListNode* head = (struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* current = head;// 创建带有20个节点的链表for (int i = 1; i <= 20; i++) {struct ListNode* newNode = (struct ListNode*)malloc(sizeof(struct ListNode));newNode->val = i;newNode->next = NULL;current->next = newNode;current = newNode;}printListReverse(head->next);current = head;struct ListNode* temp;while (current != NULL) {temp = current;current = current->next;free(temp);}return 0;
}
这个算法使用递归来实现从尾到头反向输出每个结点的值。首先定义了一个printListReverse函数,它接收链表的头结点指针作为参数。
在函数中,首先判断头结点是否为空,如果为空则直接返回。如果头结点不为空,那么先递归调用printListReverse函数,传入头结点的下一个结点作为参数,实现从尾到头的输出。然后再输出当前头结点的值。
在main函数中,创建了一个带头结点的单链表,并调用printListReverse函数来反向输出每个结点的值。
最后,为了防止内存泄漏,在程序的末尾释放了动态分配的内存。
(4)已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法(伪码)求出两个集合A和B 的差集(即仅由在A中出现而不在B中出现的元素所构成的集合),并以同样的形式存储,同时返回该集合的元素个数。

【解析】:
以下是实现“求两个递增排列链表A和B的差集,并返回差集元素个数”的C语言代码:
#include <stdio.h>
#include <stdlib.h>// 定义链表节点结构
struct ListNode {int val;struct ListNode *next;
};// 求两个递增排列链表的差集
int difference(struct ListNode *A, struct ListNode *B) {struct ListNode *head = (struct ListNode *)malloc(sizeof(struct ListNode));head->next = NULL;struct ListNode *current = head;while (A != NULL && B != NULL) {if (A->val < B->val) {struct ListNode *newNode = (struct ListNode *)malloc(sizeof(struct ListNode));newNode->val = A->val;newNode->next = NULL;current->next = newNode;current = newNode;A = A->next;} else if (A->val > B->val) {B = B->next;} else {A = A->next;B = B->next;}}while (A != NULL) {struct ListNode *newNode = (struct ListNode *)malloc(sizeof(struct ListNode));newNode->val = A->val;newNode->next = NULL;current->next = newNode;current = newNode;A = A->next;}int count = 0;current = head->next;while (current != NULL) {count++;current = current->next;}// 释放内存struct ListNode *temp;current = head->next;while (current != NULL) {temp = current;current = current->next;free(temp);}free(head);return count;
}int main() {// 构建两个递增排列的链表A和B用于测试struct ListNode *A = (struct ListNode *)malloc(sizeof(struct ListNode));A->next = NULL;struct ListNode *B = (struct ListNode *)malloc(sizeof(struct ListNode));B->next = NULL;// 在链表A中添加元素struct ListNode *currentA = A;for (int i = 1; i <= 5; i++) {struct ListNode *newNode = (struct ListNode *)malloc(sizeof(struct ListNode));newNode->val = i * 2;newNode->next = NULL;currentA->next = newNode;currentA = newNode;}// 在链表B中添加元素struct ListNode *currentB = B;for (int i = 1; i <= 5; i++) {struct ListNode *newNode = (struct ListNode *)malloc(sizeof(struct ListNode));newNode->val = i * 3;newNode->next = NULL;currentB->next = newNode;currentB = newNode;}// 求链表A和B的差集,并返回差集元素个数int count = difference(A->next, B->next);// 输出差集元素个数printf("差集元素个数: %d\n", count);// 释放内存struct ListNode *temp;currentA = A;while (currentA != NULL) {temp = currentA;currentA = currentA->next;free(temp);}currentB = B;while (currentB != NULL) {temp = currentB;currentB = currentB->next;free(temp);}return 0;
}
上述代码是用C语言实现的一个求两个递增排列链表A和B的差集,并返回差集元素个数的程序。
代码首先定义了链表节点结构struct ListNode,包含一个整数值val和指向下一个节点的指针next。
接下来定义了求差集的函数difference,该函数接收两个参数:链表A的头节点指针和链表B的头节点指针。
在函数内部,创建了一个新的头节点head,并将其指针赋给变量current,用于构建存储差集的新链表。
接下来使用while循环遍历链表A和B的元素,直到其中一个链表为空。在循环中,根据当前节点的值的大小关系,判断是否将该节点加入到新链表中。如果节点的值小于B链表的当前节点值,则将该节点加入到新链表中,并更新current指针和A指针;如果节点的值大于B链表的当前节点值,则说明该节点不在差集中,将B指针向后移动;如果节点的值等于B链表的当前节点值,则说明该节点既在A链表中又在B链表中,将A和B指针都向后移动。
当其中一个链表遍历完后,再将剩余的节点加入到新链表中。
接下来使用循环统计新链表的节点个数,并将其返回。
在main函数中,构建了两个递增排列的链表A和B,并调用difference函数求差集,并将差集元素个数存储在变量count中。
最后输出差集元素个数。
为了防止内存泄漏,在程序的末尾释放了动态分配的内存。
这段代码主要通过遍历链表A和B的方法,找出只在A链表中出现的节点,构建一个新的链表来存储差集,并返回差集元素个数。
三. 编程题(本题共20分)
阅读以下C#代码,将序号所指的方框内代码进行解释说明。
【标答】:


四. 工程案例分析题(本题共30分)
选取一个测绘程序设计与开发案例,详细阐述面向对象设计方法的优势,并详细分析该程序所包含的类的构建、对象、属性、方法及构造函数设计与实现的步骤和流程图。
根据自行选定的测量程序题目,介绍程序需要实现的功能,使用面向对象的设计方法,分析程序所需的对象、类、属性、方法、及继承关系等,列出该程序的功能结构图,展示类和对象之间的层次关系。(15分)
开发实施流程:①系统分析②系统设计③系统详细设计④编码实施,详细介绍各阶段的操作步骤和结果。(15分)
【解析】:
下面是一个关于“四等水准测量”测绘程序设计与开发的案例:
一、程序功能介绍: 该测绘程序旨在通过实施四等水准测量来确定地面高程。程序的主要功能包括:
-
数据输入:用户可以输入测量数据,包括观测点的坐标和测量结果。
-
数据处理:根据输入的观测数据,程序将计算出各观测点的高程值。
-
数据输出:程序将输出计算得到的观测点的高程值,并可以生成高程图或其他相关报告。
二、面向对象设计方法的优势: 面向对象设计方法可以将整个测绘程序划分为多个对象,每个对象负责完成特定的任务。这种设计方法的优势在于:
-
模块化:通过将系统划分为独立的对象,可以实现模块化开发和维护。每个对象只关注自己的功能,降低了代码的复杂性。
-
可扩展性:通过定义类和对象之间的继承关系,可以轻松地扩展系统功能。例如,可以通过创建新的子类来支持不同类型的水准测量。
-
代码重用:通过使用继承和多态的概念,可以将通用的功能封装在基类中,并在子类中重写或扩展特定的功能。这样可以提高代码的重用性和可维护性。
-
系统灵活性:面向对象设计方法允许对象之间的松耦合关系,当需求变化时,可以更容易地修改或替换特定的对象,而不会影响到整个系统的其他部分。
三、类的构建、对象、属性和方法设计: 在“四等水准测量”测绘程序中,可以考虑以下类的构建、对象、属性和方法设计:
-
类:Point(点)
- 属性:高程
- 方法:获取坐标、设置高程
-
类:Observation(观测)
- 属性:观测结果
- 方法:添加观测结果、计算高程差
-
类:Survey(测量)
- 属性:观测点集合
- 方法:添加观测、计算高程、生成报告
四、功能结构图和类层次关系: 以下是一个简化的功能结构图,展示了类和对象之间的层次关系:
+-------+| Point |+-------+| \| \ (has-a)| \+---------+ +--------------+| | | Observation || Survey | +--------------+| | | - StartPoint |+---------+ | - EndPoint || - Result |+--------------+
在此类层次结构中,Survey 包含多个 Observation,每个 Observation 包含两个 Point(StartPoint 和 EndPoint)以及测量结果。 Survey 类负责管理观测点集合,并通过调用 Observation 的方法来计算高程。
五、开发实施流程:
-
系统分析:
- 确定需求:明确系统需要支持的功能和用户需求。
- 分析数据结构:确定需要的数据类型和数据结构,如 Point、Observation 和 Survey。
- 划分模块:将系统划分为独立的模块和类。
-
系统设计:
- 定义类和对象:根据分析结果,定义类和对象,并确定它们之间的关系。
- 设计属性和方法:为每个类定义合适的属性和方法,以支持程序的功能。
-
系统详细设计:
- 编写类的详细设计文档:描述每个类的属性、方法和关系,包括输入输出参数、函数调用关系等。
- 绘制类图:使用UML或其他工具,绘制类之间的关系图和继承关系。
-
编码实施:
- 根据系统详细设计文档,逐个实现每个类和对象。
- 进行单元测试:测试每个类的功能是否正常运行,确保代码质量和功能正确性。
- 进行集成测试:将各个模块整合到一个完整的系统中,并进行系统级别的测试。
以上是基于面向对象设计方法的测绘程序设计与开发案例的一般步骤和思路。具体的实现细节和流程可能因具体需求和编程语言而有所不同。在实际开发中,还需要考虑异常处理、数据存储和用户界面等方面的设计和实现。
【关于BF算法(Brute Force Algorithm)】:
BF算法(Brute Force Algorithm)是一种简单直观的字符串匹配算法,也称为暴力匹配算法。它的基本思想是通过对主串和模式串逐个字符进行比较,以找到匹配的子串。虽然BF算法的时间复杂度较高,但在一些简单的应用场景中仍然具有一定的实用价值。
下面是C语言实现的BF算法代码:
#include <stdio.h>
#include <string.h>int BF(char *text, char *pattern) {int i = 0, j = 0;int text_len = strlen(text);int pattern_len = strlen(pattern);while (i < text_len && j < pattern_len) {if (text[i] == pattern[j]) {i++;j++;} else {i = i - j + 1; // 主串回溯到上次匹配的下一个位置j = 0; // 模式串回溯到开头}}if (j == pattern_len) {return i - j; // 返回匹配的子串在主串中的起始位置} else {return -1; // 未找到匹配的子串}
}int main() {char text[] = "hello, world!";char pattern[] = "world";int index = BF(text, pattern);if (index != -1) {printf("Pattern found at index: %d\n", index);} else {printf("Pattern not found\n");}return 0;
}
在上面的代码中,BF函数用于实现BF算法的字符串匹配过程。主要思路是通过两个循环对主串和模式串进行逐个字符的比较,并在不匹配时进行回溯。最后的main函数演示了如何使用BF函数进行字符串匹配。
需要注意的是,BF算法的时间复杂度为O(m*n),其中m为主串长度,n为模式串长度。在实际应用中,对于较长的字符串,BF算法可能效率较低,可以考虑其他更高效的字符串匹配算法,如KMP算法、Boyer-Moore算法等。
【关于图在C语言中的矩阵存储算法和单链表存储算法】:
图的矩阵存储算法(邻接矩阵):
邻接矩阵是一种常见的图的表示方法,使用一个二维数组来表示图中各顶点之间的关系。该二维数组的行和列分别对应图中的顶点,数组元素的值表示对应顶点之间是否存在边或弧。
下面是在C语言中实现图的邻接矩阵存储算法的代码:
#include <stdio.h>#define MAX_VERTICES 100typedef struct {int matrix[MAX_VERTICES][MAX_VERTICES];int numVertices;
} Graph;void initializeGraph(Graph *graph, int numVertices) {graph->numVertices = numVertices;for (int i = 0; i < numVertices; i++) {for (int j = 0; j < numVertices; j++) {graph->matrix[i][j] = 0; // 初始化矩阵元素为0,表示没有边}}
}void addEdge(Graph *graph, int startVertex, int endVertex) {graph->matrix[startVertex][endVertex] = 1; // 添加边,将对应位置置为1// 如果是有向图,只需上述一行代码// 如果是无向图,还需添加下面一行代码graph->matrix[endVertex][startVertex] = 1;
}void printGraph(Graph *graph) {printf("Adjacency Matrix:\n");for (int i = 0; i < graph->numVertices; i++) {for (int j = 0; j < graph->numVertices; j++) {printf("%d ", graph->matrix[i][j]);}printf("\n");}
}int main() {Graph graph;int numVertices = 5;initializeGraph(&graph, numVertices);addEdge(&graph, 0, 1);addEdge(&graph, 1, 2);addEdge(&graph, 2, 3);addEdge(&graph, 3, 4);addEdge(&graph, 4, 0);printGraph(&graph);return 0;
}
在上述代码中,首先定义了一个Graph结构体,其中的matrix数组就是邻接矩阵。initializeGraph函数用于初始化图,将所有矩阵元素都置为0。addEdge函数用于添加边,将对应位置的矩阵元素置为1。printGraph函数用于打印邻接矩阵。
图的单链表存储算法(邻接表):
邻接表是另一种常见的图的表示方法,使用一个数组和链表结构来表示图中各顶点之间的关系。数组的每个元素对应一个顶点,而每个元素中的链表存储该顶点的邻接顶点。
下面是在C语言中实现图的邻接表存储算法的代码:
#include <stdio.h>
#include <stdlib.h>typedef struct Node {int vertex;struct Node *next;
} Node;typedef struct {Node *head;
} AdjList;typedef struct {int numVertices;AdjList *array;
} Graph;Node *createNode(int vertex) {Node *newNode = (Node*)malloc(sizeof(Node));newNode->vertex = vertex;newNode->next = NULL;return newNode;
}Graph *createGraph(int numVertices) {Graph *graph = (Graph*)malloc(sizeof(Graph));graph->numVertices = numVertices;graph->array = (AdjList*)malloc(numVertices * sizeof(AdjList));for (int i = 0; i < numVertices; i++) {graph->array[i].head = NULL;}return graph;
}void addEdge(Graph *graph, int startVertex, int endVertex) {// 添加边,将邻接顶点添加到对应的链表中Node *newNode = createNode(endVertex);newNode->next = graph->array[startVertex].head;graph->array[startVertex].head = newNode;// 如果是有向图,只需上述代码// 如果是无向图,还需添加下面一行代码newNode = createNode(startVertex);newNode->next = graph->array[endVertex].head;graph->array[endVertex].head = newNode;
}void printGraph(Graph *graph) {printf("Adjacency List:\n");for (int i = 0; i < graph->numVertices; i++) {Node *temp = graph->array[i].head;printf("Vertex %d: ", i);while (temp) {printf("%d -> ", temp->vertex);temp = temp->next;}printf("NULL\n");}
}int main() {int numVertices = 5;Graph *graph = createGraph(numVertices);addEdge(graph, 0, 1);addEdge(graph, 1, 2);addEdge(graph, 2, 3);addEdge(graph, 3, 4);addEdge(graph, 4, 0);printGraph(graph);return 0;
}
在上述代码中,首先定义了Node结构体,表示邻接表中的链表节点;AdjList结构体,表示邻接表中的链表头节点;Graph结构体,表示图。createNode函数用于创建节点;createGraph函数用于创建图,并初始化邻接表;addEdge函数用于添加边,将邻接顶点添加到对应的链表中;printGraph函数用于打印邻接表。
以上两种算法分别适用于不同的场景,邻接矩阵适用于稠密图,邻接表适用于稀疏图。根据实际需求选择合适的存储算法可以提高程序的效率。
相关文章:
《数据结构与测绘程序设计》试题详细解析(仅供参考)
一. 选择题(每空2分,本题共30分) (1)在一个单链表中,已知q所指结点是p所指结点的前驱结点,若在q和p之间插入结点s,则执行( B )。 A. s->nextp->next; p->nexts; B. q…...
Raft 算法
Raft 算法 1 背景 当今的数据中心和应用程序在高度动态的环境中运行,为了应对高度动态的环境,它们通过额外的服务器进行横向扩展,并且根据需求进行扩展和收缩。同时,服务器和网络故障也很常见。 因此,系统必须在正常…...

Redis队列stream,Redis多线程详解
Redis 目前最新版本为 Redis-6.2.6 ,会以 CentOS7 下 Redis-6.2.4 版本进行讲解。 下载地址: https://redis.io/download 安装运行 Redis 很简单,在 Linux 下执行上面的 4 条命令即可 ,同时前面的 课程已经有完整的视…...

ThinkPHP的方法接收json数据问题
第一次接触到前后端分离开发,需要在后端接收前端ajax提交的json数据,开发基于ThinkPHP3.2.3框架。于是一开始习惯性的直接用I()方法接收到前端发送的json数据,然后用json_decode()解析发现结果为空!但是打印出还未解析的值却打印得…...

简单理解算法
简单理解算法 前言算法衡量一个好的算法具备的标准算法的应用场景 数据结构数据结构的组成方式 前言 hello,宝宝们~来分享我从一本书中理解的算法。《漫画算法》感觉对我这种算法小白比较友好。看完感觉对算法有了新的理解,计算机学习这么多年ÿ…...

C/C++ 内存管理(2)
文章目录 new 和 delet 概念new 和 delet 的使用new与 delete 底层原理malloc/free和new/delete的区别new / opera new / 构造函数 之间的关系定位new表达式(placement-new)内存泄漏内存泄漏分类如何对待内存泄漏 new 和 delet 概念 new和delete是用于动态内存管理的运算符&am…...

Net6.0或Net7.0项目升级到Net8.0 并 消除.Net8中SqlSugar的警告
本文基于NetCore3.1或Net6.0项目升级到Net7.0,参考连接:NetCore3.1或Net6.0项目升级到Net7.0-CSDN博客 所有项目按照此步骤操作一遍,完成后再将所有引用的包(即 *.dll)更新升级到最新版(注意:有…...

力扣题:字符串的反转-11.22
力扣题-11.22 [力扣刷题攻略] Re:从零开始的力扣刷题生活 力扣题1:541. 反转字符串 II 解题思想:进行遍历翻转即可 class Solution(object):def reverseStr(self, s, k):""":type s: str:type k: int:rtype: str"&quo…...
:对象的初始化)
Effective C++(二):对象的初始化
文章目录 一、类的初始化二、全局静态对象的初始化 一、类的初始化 对于类中的成员变量的初始化,一般有两种方法,一种是在类中定义的时候直接赋予初值: class CTextBlock { private:std::size_t textLength{ 0 };bool lenisValid{ false }:…...

云原生高级--shell自动化脚本备份
shell自动化脚本实战---备份 数据库备份: 结合计划任务 MySQL、 Oracle 网站备份: tar,异地保存--ftp、rsync 一、数据库备份 1.利用自带工具mysqldump 实现数据库分库备份 分库备份: 1> 如何获取备份的…...
Spring Boot实现热部署
Spring Boot提供了一个名为spring-boot-devtools的开发工具,它可以实现热部署功能。通过使用spring-boot-devtools,可以在修改了resources目录下的内容后,自动重新加载应用程序,而无需手动重启。 以下是使用spring-boot-devtools…...

MVCC-
文章目录 1. 什么是MVCC2. 快照读和当前读3. 复习4. MVCC实现原理之ReadView5. 总结 文章目录 1. 什么是MVCC2. 快照读和当前读3. 复习4. MVCC实现原理之ReadView5. 总结 1. 什么是MVCC 口述:MVCC其实他是解决这种读-写的情况的,当然读-写也可以用 锁来…...

键盘打字盲打练习系列之刻意练习——1
一.欢迎来到我的酒馆 盲打,刻意练习! 目录 一.欢迎来到我的酒馆二.选择一款工具三.刻意练习第一步:基准键位练习第二步:字母键位练习第三步:数字符号键位练习 四.矫正坐姿 二.选择一款工具 工欲善其事必先利其器。在开始之前&…...

某公司前端笔试题(12.30)
1、对象数组去重: 数组去重: const a[{a:1,b:2},{a:2},{a:2},{a:1,c:3},{b:2,a:1}] 结果:[{a:1,b:2},{a:2},{a:1,c:3}] // 判断两个对象的属性值是否一致 const a [{ a: 1, b: 2 }, { a: 2 }, { a: 2 }, { a: 1, c: 3 }, { b: 2, a: 1 }] co…...
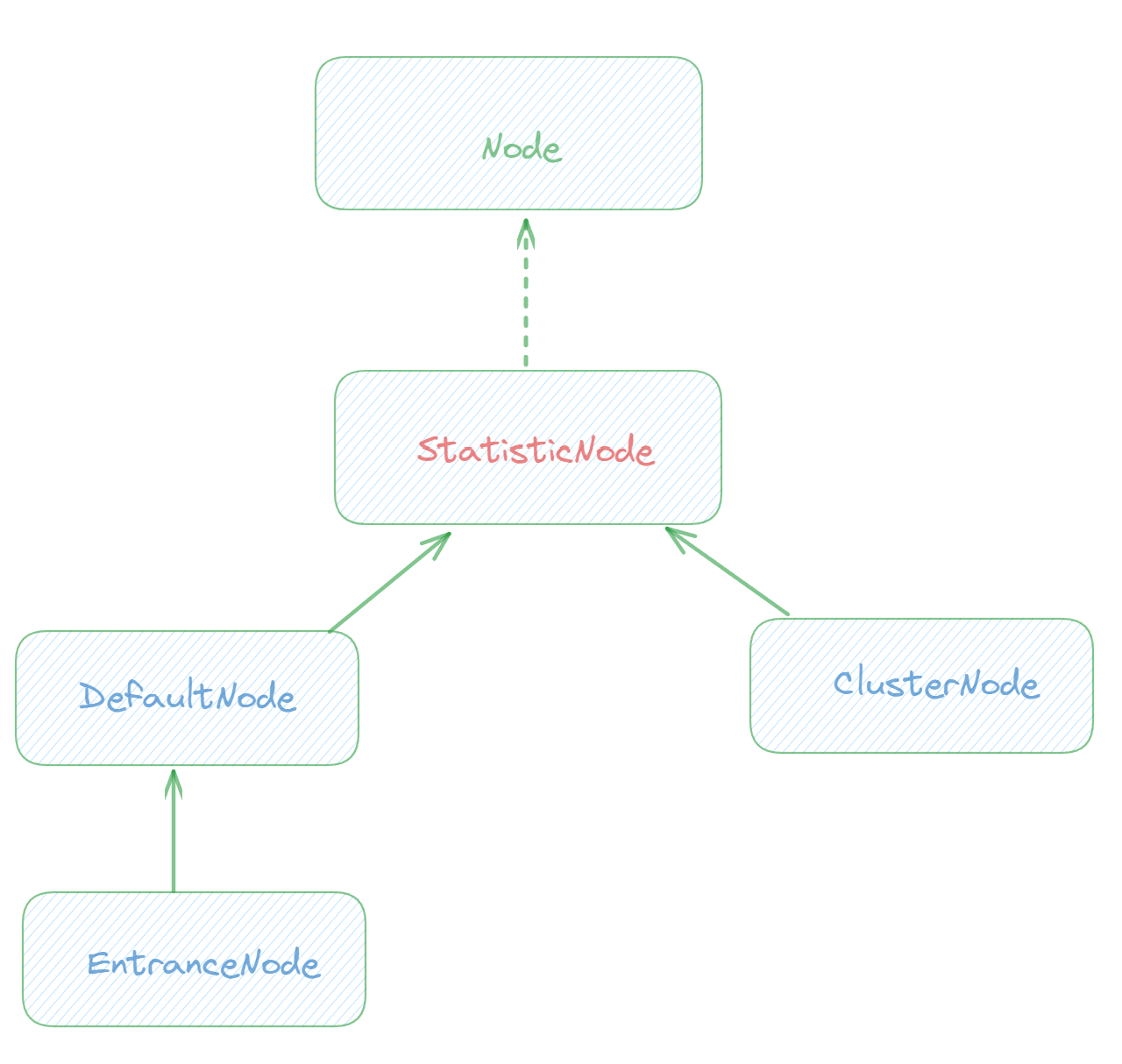
Sentinel核心类解读:Node
基本介绍 Sentinel中的簇点链路是由一个个的Node组成的,Node是一个接口。Node中保存了对资源的实时数据的统计,Sentinel中的限流或者降级等功能就是通过Node中的数据进行判断的。 Sentinel中是这样描述Node的: Holds real-time statistics…...

网络安全领域的12个大语言模型用例
网络安全是人工智能最大的细分市场,过去几年网络安全厂商纷纷宣称整合了人工智能技术(当然也有很多仅仅是炒作),其中大部分是基于基线和统计异常的机器学习。 随着ChatGPT和类似生成式人工智能技术的飞速发展,基于大语…...

十大网络攻击手段解析,助您建立坚固的网络防线
在互联网高度发达的今天,网络安全问题愈发严峻。 了解网络攻击手段,掌握防御策略,对保障网络安全至关重要。 本文将为您介绍常见的十大网络攻击手段,以及如何应对和防御这些攻击手段,确保网络安全。 一、DDoS攻击 …...

jvm 调优参数
-XX:AlwaysPreTouch 指定JVM启动时即刻分配整个堆内存空间;应用启动会变慢,但是运行时变快。 -XX:MaxRAMPercentage60.0 指定JVM最大堆内存使用比例为60%;适用于容器部署 -XX:MinRAMPercentage60.0 指定JVM最小堆内存使用比例为60%࿱…...
OpenCV-Python:计算机视觉介绍
目录 1.背景 2.计算机视觉发展历史 3.计算机视觉主要任务 4.计算机视觉应用场景 5.知识笔记 1.背景 OpenCV是计算机视觉的一个框架,想要学习OpenCV,需要对计算机视觉有一个大致的了解。计算机视觉是指通过计算机技术和算法来模拟人类视觉系统的能力…...
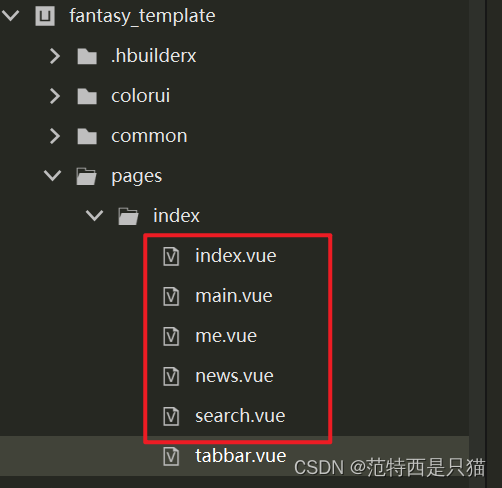
uni-app 微信小程序之自定义中间圆形tabbar
文章目录 1. 自定义tabbar效果2. pages新建tabbar页面3. tabbar 页面结构4. tabbar 页面完整代码 1. 自定义tabbar效果 2. pages新建tabbar页面 首先在 pages.json 文件中,新建一个 tabbar 页面 "pages": [ //pages数组中第一项表示应用启动页ÿ…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

Fast-GitHub:打破GitHub访问壁垒的智能加速方案
Fast-GitHub:打破GitHub访问壁垒的智能加速方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾因GitHub仓库克…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...

Go语言实现跨平台系统更新检查器:自动化运维与安全监控实践
1. 项目概述:一个被低估的系统运维“哨兵”在服务器和桌面系统的日常运维中,有一个场景大家一定不陌生:某天,你管理的服务器突然因为一个已知漏洞被攻击,事后排查发现,相关的安全补丁其实在几周前就已经发布…...

从零构建可定制对话系统:架构设计、RAG与智能体实战
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“customized-chat”。这名字听起来可能有点泛,但它的核心目标非常明确:打造一个完全由你自己掌控、能深度融入你特定业务逻辑或知识体系的对话…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

Claude API封装项目深度解析:从安全评估到自主构建代码助手
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫 ashish200729/claude-code-source-code 。光看这个标题,很多开发者朋友可能会心头一热,以为这是某个AI模型的源代码被开源了。但作为一个在开源社区混迹多年的老码农&…...