大文件分片上传、分片进度以及整体进度、断点续传(一)
大文件分片上传
效果展示
前端
思路
前端的思路:将大文件切分成多个小文件,然后并发给后端。
页面构建
先在页面上写几个组件用来获取文件。
<body><input type="file" id="file" /><button id="uploadButton">点击上传</button>
</body>
功能函数:生成切片
切分文件的核心函数是 slice,没错,就是这么的神奇啊
我们把切好的 chunk 放到数组里,等待下一步的包装处理
/*** 默认切片大小 10 MB*/
const SIZE = 10 * 1024 * 1024;/*** 功能:生成切片*/
function handleCreateChunk(file, size = SIZE) {const fileChunkList = [];let cur = 0;while (cur < file.size) {fileChunkList.push({file: file.slice(cur, cur + size),});cur += size;}return fileChunkList;
}
功能函数:请求逻辑
在这里简单封装一下 XMLHttpRequest
/*** 功能:封装请求* @param {*} param0* @returns*/
function request({ url, method = 'post', data, header = {}, requestList }) {return new Promise((resolve, reject) => {let xhr = new XMLHttpRequest();xhr.open(method, url);Object.keys(header).forEach((item) => {xhr.setRequestHeader(item, header[item]);});xhr.onload = function (e) {resolve({data: e.target.response,});};xhr.send(data);});
}
功能函数:上传切片
/*** 功能: 上传切片* 包装好 FormData 之后通过 Promise.all() 并发所有切片*/
async function uploadChunks(hanldleData, fileName) {const requestList = hanldleData.map(({ chunk, hash }) => {const formData = new FormData();formData.append('chunk', chunk);formData.append('hash', hash);formData.append('filename', fileName);return formData;}).map((formData) => {request({// url: 'http://localhost:3001/upload',url: 'upload',data: formData,});});await Promise.all(requestList);
}/*** 功能:触发上传
*/
document.getElementById('uploadButton').onclick = async function () {// 切片const file = document.getElementById('file').files[0];console.log(file);const fileName = file.name;const fileChunkList = handleCreateChunk(file);// 包装const hanldleData = fileChunkList.map(({ file }, index) => {return {chunk: file,hash: `${fileName}_${index}`,};});await uploadChunks(hanldleData, fileName);
};
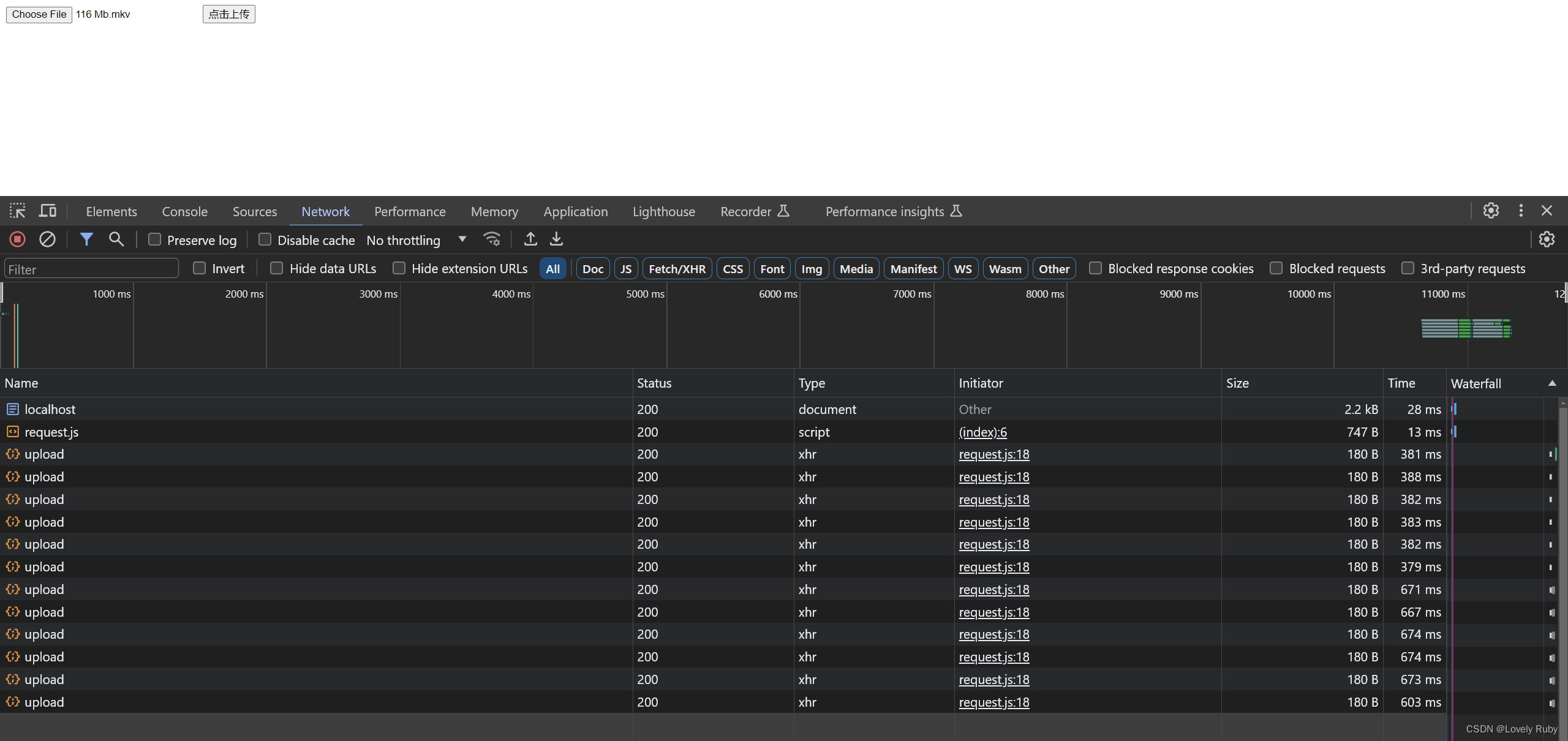
可以在请求中看到有很多个请求并发的上传
后端
后端的思路是:
- 把 Node 暂存的
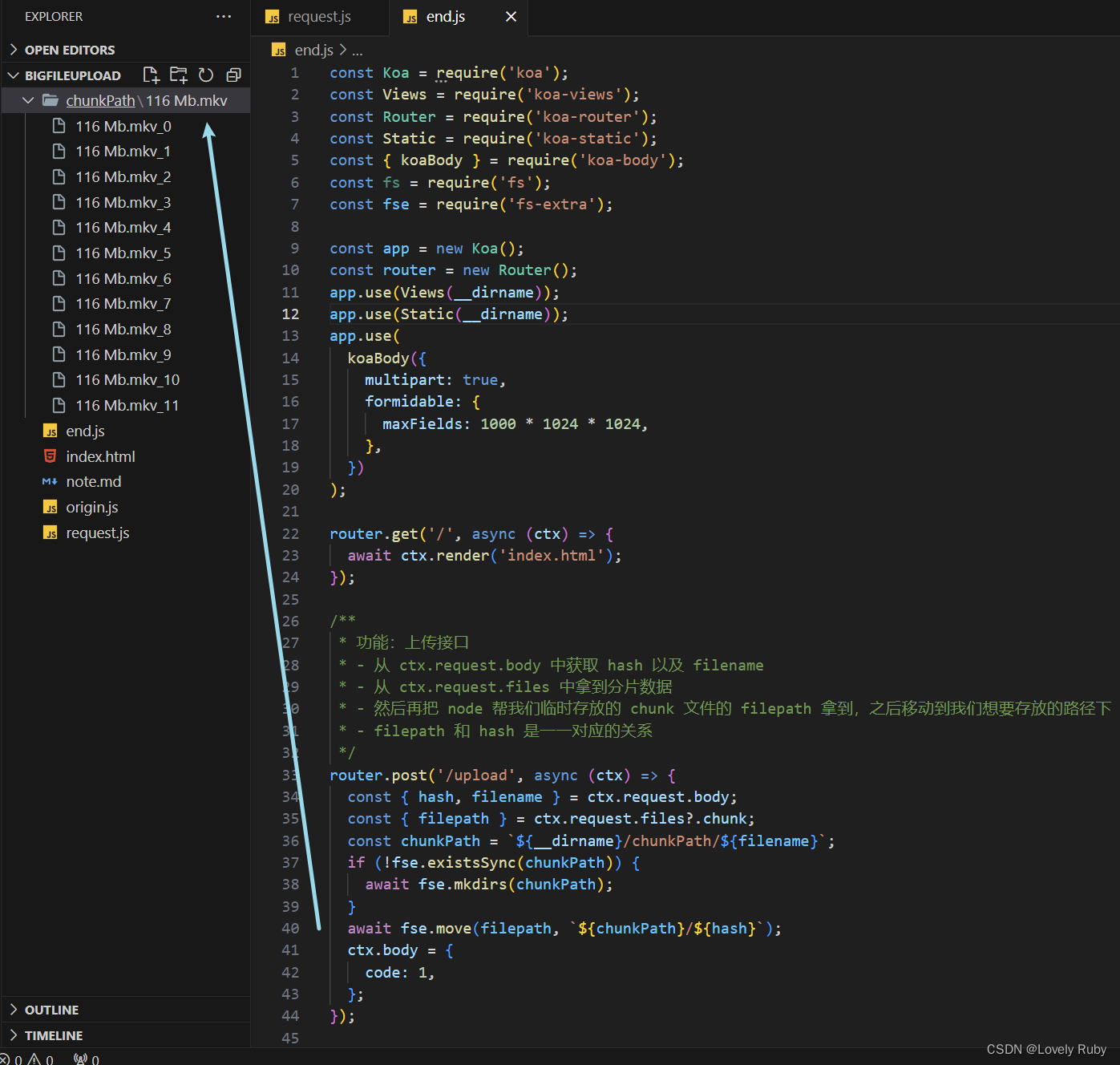
chunk文件转移到我想处理的地方(也可以直接处理,看你的)- 创建写入流,把各个
chunk合并,前端会给你每个 chunk 的大小,还有hash值来定位每个chunk的位置
获取 chunk 切片文件
先把上传的接口写好,
const Koa = require('koa');
const Views = require('koa-views');
const Router = require('koa-router');
const Static = require('koa-static');
const { koaBody } = require('koa-body');
const fs = require('fs');
const fse = require('fs-extra');const app = new Koa();
const router = new Router();
app.use(Views(__dirname));
app.use(Static(__dirname));
app.use(koaBody({multipart: true,formidable: {maxFields: 1000 * 1024 * 1024,},})
);router.get('/', async (ctx) => {await ctx.render('index.html');
});/*** 功能:上传接口* - 从 ctx.request.body 中获取 hash 以及 filename* - 从 ctx.request.files 中拿到分片数据* - 然后再把 node 帮我们临时存放的 chunk 文件的 filepath 拿到,之后移动到我们想要存放的路径下* - filepath 和 hash 是一一对应的关系*/
router.post('/upload', async (ctx) => {const { hash, filename } = ctx.request.body;const { filepath } = ctx.request.files?.chunk;const chunkPath = `${__dirname}/chunkPath/${filename}`;if (!fse.existsSync(chunkPath)) {await fse.mkdirs(chunkPath);}await fse.move(filepath, `${chunkPath}/${hash}`);ctx.body = {code: 1,};
});app.use(router.routes());
app.listen(3000, () => {console.log(`server start: http://localhost:3000`);
});
写完这些就可以拿到 chunk
合并接口
先写一个接口,用来拿到 hash、文件名
/*** 功能: merge 接口* - hasMergeChunk 变量是上面用来记录的* - mergePath 定义一下合并后的文件的路径*/
router.post('/merge', async (ctx) => {// console.log(ctx.request.body);const { fileName, size } = ctx.request.body;hasMergeChunk = {};const mergePath = `${__dirname}/merge/${fileName}`;if (!fse.existsSync(`${__dirname}/merge`)) {fse.mkdirSync(`${__dirname}/merge`);}await mergeChunk(mergePath, fileName, size);ctx.body = {data: '成功',};
});
合并分片的功能函数
然后开始合并
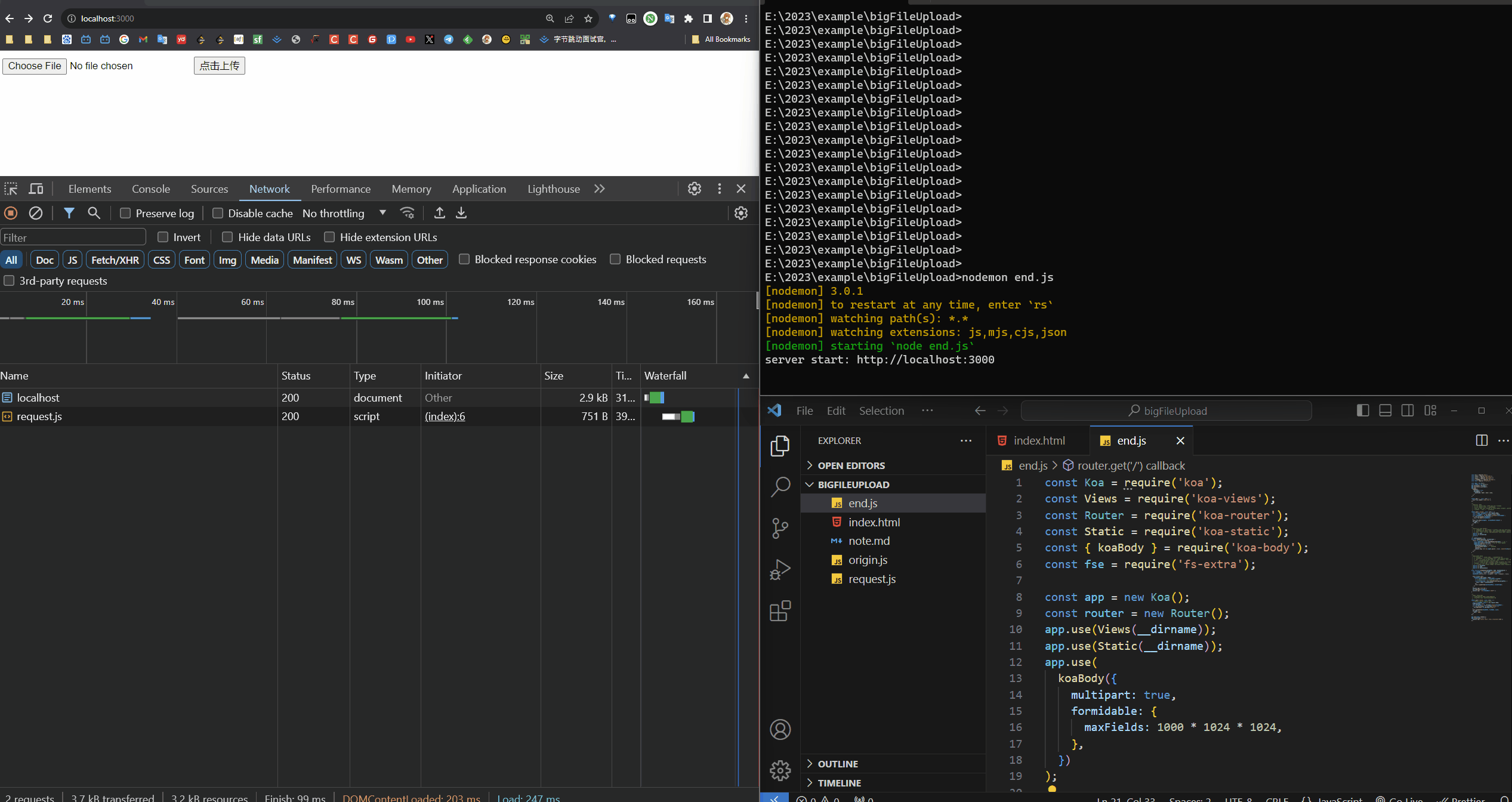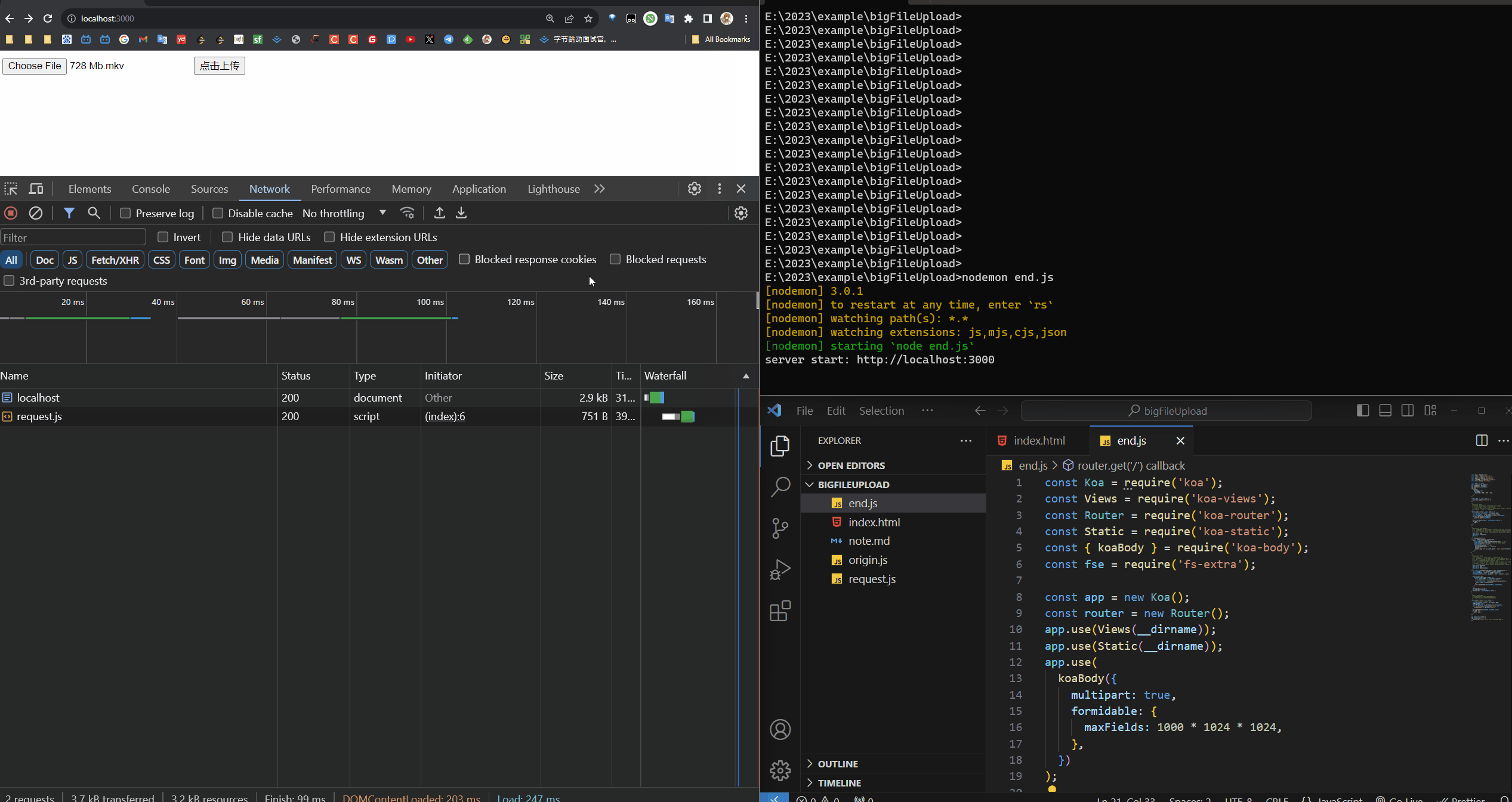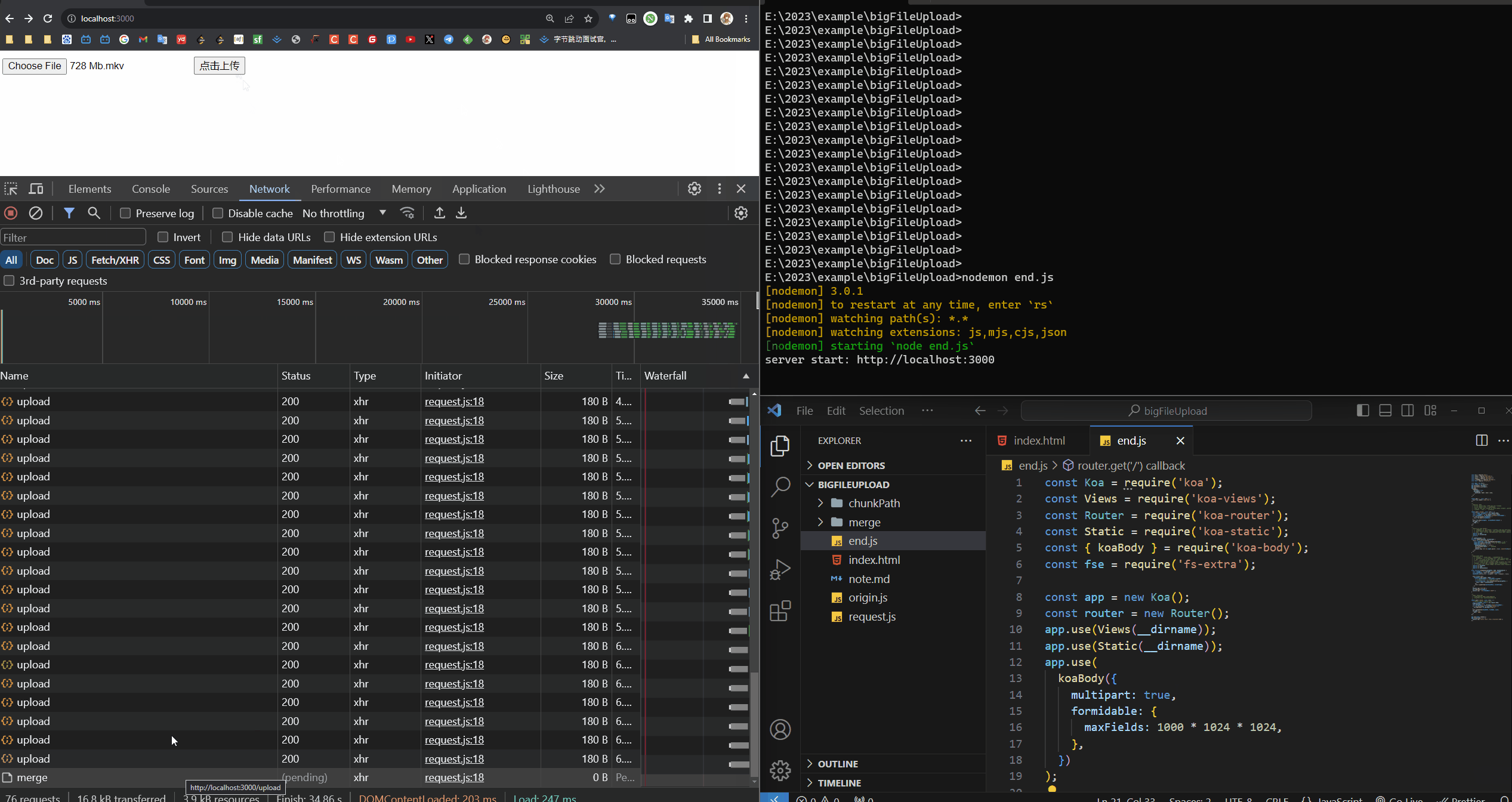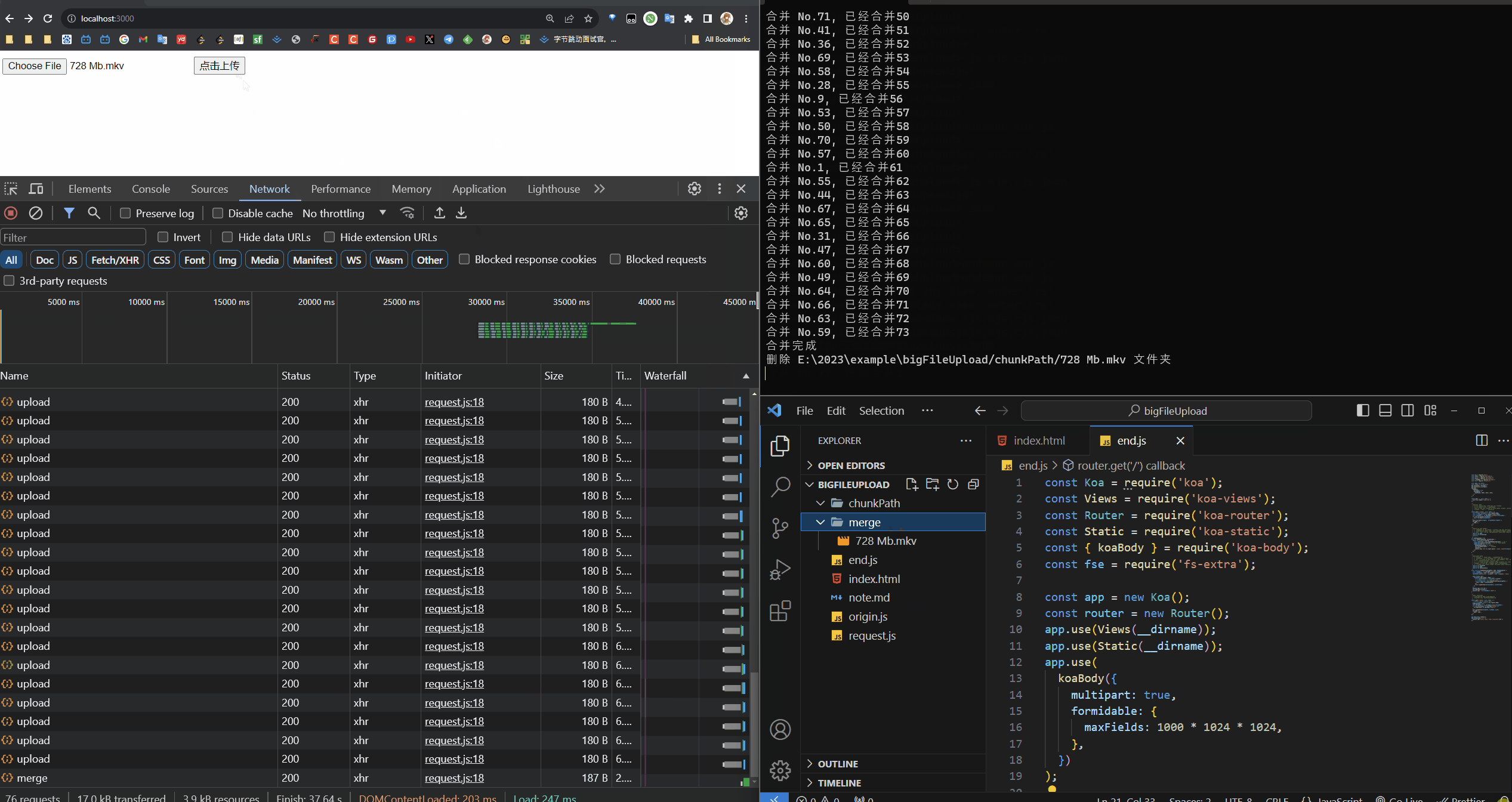
/*** 功能:合并 Chunk* - 1. chunkDir: 是 chunks 文件们所在的文件夹的路径* - 2. chunkPaths: 是个 Array,数组中包含所有的 chunk 的 path* - 3. 因为 每个 chunk 的 path 命名是通过 hash 组成的,所以我们先排序一下,* - 算是为 createWriteStream 中的 start 做准备* - 4. 为每个 chunk 的 path 创建写入流,写到 mergePath 这个路径下。因为已经* - 排序了,所以 start 就是每个文件的 index * eachChunkSize* @param {*} mergePath* @param {*} name* @param {*} eachChunkSize*/
async function mergeChunk(mergePath, name, eachChunkSize) {const chunkDir = `${__dirname}/chunkPath/${name}`;const chunkPaths = await fse.readdir(chunkDir);chunkPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);await Promise.all(chunkPaths.map((chunk, index) => {const eachChunkPath = `${chunkDir}/${chunk}`;const writeStream = fse.createWriteStream(mergePath, {start: index * eachChunkSize,});return pipeStream(eachChunkPath, writeStream);}));console.log('合并完成');fse.rmdirSync(chunkDir);console.log(`删除 ${chunkDir} 文件夹`);
}
接着就是写入流
/*** 功能:创建 pipe 写文件流* - 1. [首先了解一下什么是输入输出流](https://www.jmjc.tech/less/111)* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。* - 3. 可以检测输出流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。* @param {*} path* @param {*} writeStream* @returns*/
let hasMergeChunk = {};
function pipeStream(path, writeStream) {return new Promise((resolve) => {const readStream = fse.createReadStream(path); // 输出流readStream.pipe(writeStream); // 输出通过管道流向输入readStream.on('end', () => {hasMergeChunk[path] = 'finish';fse.unlinkSync(path); // 删除此文件resolve();console.log(`合并 No.${path.split('_')[1]}, 已经合并${Object.keys(hasMergeChunk).length}`);});});
}
至此一个基本的逻辑上传就做好了!
Q & A
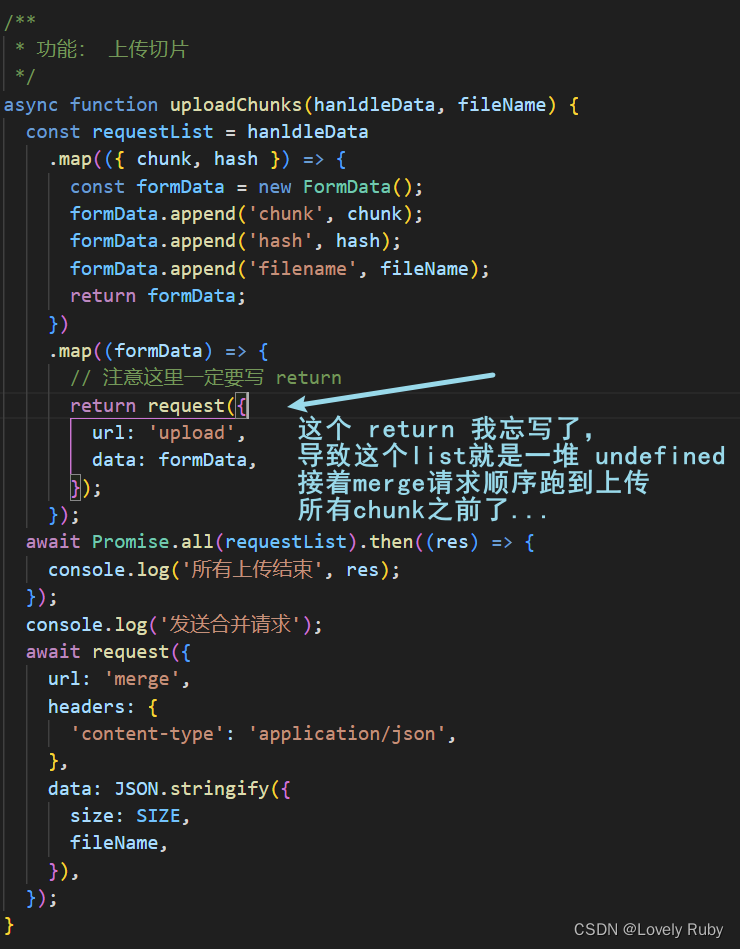
发送片段之后的合并可能出现错误
这个情况分析了一下是前端的锅啊,前端的 await Promise.all() 并不能保证后端的文件流都写完了。
完整代码
前端
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>Document</title><script src="request.js"></script></head><body><input type="file" id="file" /><button id="uploadButton">点击上传</button><button id="mergeButton">点击合并</button></body><script>/*** 默认切片大小 10 MB*/const SIZE = 10 * 1024 * 1024;/*** 功能:生成切片*/function handleCreateChunk(file, size = SIZE) {const fileChunkList = [];let cur = 0;while (cur < file.size) {fileChunkList.push({file: file.slice(cur, cur + size),});cur += size;}return fileChunkList;}/*** 功能: 上传切片* - 注意 map 里别忘了写 return*/async function uploadChunks(hanldleData, fileName) {const requestList = hanldleData.map(({ chunk, hash }) => {const formData = new FormData();formData.append('chunk', chunk);formData.append('hash', hash);formData.append('filename', fileName);return formData;}).map((formData) => {return request({url: 'upload',data: formData,});});await Promise.all(requestList).then((res) => {console.log('所有上传结束', res);});console.log('发送合并请求');await request({url: 'merge',headers: {'content-type': 'application/json',},data: JSON.stringify({size: SIZE,fileName,}),});}document.getElementById('uploadButton').onclick = async function () {// 切片const file = document.getElementById('file').files[0];const fileName = file.name;const fileChunkList = handleCreateChunk(file);// 包装const hanldleData = fileChunkList.map(({ file }, index) => {return {chunk: file,hash: `${fileName}_${index}`,};});await uploadChunks(hanldleData, fileName);};// document.getElementById('mergeButton').onclick = async function () {// await request({// url: 'merge',// headers: {// 'content-type': 'application/json',// },// data: JSON.stringify({// size: SIZE,// fileName: '116 Mb.mkv',// }),// });// };</script>
</html>
后端
const Koa = require('koa');
const Views = require('koa-views');
const Router = require('koa-router');
const Static = require('koa-static');
const { koaBody } = require('koa-body');
const fse = require('fs-extra');const app = new Koa();
const router = new Router();
app.use(Views(__dirname));
app.use(Static(__dirname));
app.use(koaBody({multipart: true,formidable: {maxFields: 1000 * 1024 * 1024,},})
);router.get('/', async (ctx) => {await ctx.render('index.html');
});/*** 功能:上传接口* - 从 ctx.request.body 中获取 hash 以及 filename* - 从 ctx.request.files 中拿到分片数据* - 然后再把 node 帮我们临时存放的 chunk 文件的 filepath 拿到,之后移动到我们想要存放的路径下* - filepath 和 hash 是一一对应的关系*/
router.post('/upload', async (ctx) => {const { hash, filename } = ctx.request.body;const { filepath } = ctx.request.files?.chunk;const chunkPath = `${__dirname}/chunkPath/${filename}`;if (!fse.existsSync(chunkPath)) {await fse.mkdirs(chunkPath);}await fse.move(filepath, `${chunkPath}/${hash}`);ctx.body = {code: 1,};
});/*** 功能:创建 pipe 写文件流* - 1. [首先了解一下什么是输入输出流](https://www.jmjc.tech/less/111)* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。* - 3. 可以检测输出流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。* @param {*} path* @param {*} writeStream* @returns*/
let hasMergeChunk = {};
function pipeStream(path, writeStream) {return new Promise((resolve) => {const readStream = fse.createReadStream(path); // 输出流readStream.pipe(writeStream); // 输出通过管道流向输入readStream.on('end', () => {hasMergeChunk[path] = 'finish';fse.unlinkSync(path); // 删除此文件resolve();console.log(`合并 No.${path.split('_')[1]}, 已经合并${Object.keys(hasMergeChunk).length}`);});});
}/*** 功能:合并 Chunk* - 1. chunkDir: 是 chunks 文件们所在的文件夹的路径* - 2. chunkPaths: 是个 Array,数组中包含所有的 chunk 的 path* - 3. 因为 每个 chunk 的 path 命名是通过 hash 组成的,所以我们先排序一下,* - 算是为 createWriteStream 中的 start 做准备* - 4. 为每个 chunk 的 path 创建写入流,写到 mergePath 这个路径下。因为已经* - 排序了,所以 start 就是每个文件的 index * eachChunkSize* - 5. 每个写入流都用 Promise 包装了一下,然后用 await Promise.all() 等待处理完* @param {*} mergePath* @param {*} name* @param {*} eachChunkSize*/
async function mergeChunk(mergePath, name, eachChunkSize) {const chunkDir = `${__dirname}/chunkPath/${name}`;const chunkPaths = await fse.readdir(chunkDir);chunkPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);await Promise.all(chunkPaths.map((chunk, index) => {const eachChunkPath = `${chunkDir}/${chunk}`;// 创建输入流,并为每个 chunk 定好位置const writeStream = fse.createWriteStream(mergePath, {start: index * eachChunkSize,});return pipeStream(eachChunkPath, writeStream);}));console.log('合并完成');fse.rmdirSync(chunkDir);console.log(`删除 ${chunkDir} 文件夹`);
}/*** 功能: merge 接口* - hasMergeChunk 变量是上面用来记录的* - mergePath 定义一下合并后的文件的路径*/
router.post('/merge', async (ctx) => {// console.log(ctx.request.body);const { fileName, size } = ctx.request.body;hasMergeChunk = {};const mergePath = `${__dirname}/merge/${fileName}`;if (!fse.existsSync(`${__dirname}/merge`)) {fse.mkdirSync(`${__dirname}/merge`);}await mergeChunk(mergePath, fileName, size);ctx.body = {data: '成功',};
});app.use(router.routes());
app.listen(3000, () => {console.log(`server start: http://localhost:3000`);
});request.js 的封装
/*** 功能:封装请求* @param {*} param0* @returns*/
function request({ url, method = 'post', data, headers = {}, requestList }) {return new Promise((resolve, reject) => {let xhr = new XMLHttpRequest();xhr.open(method, url);Object.keys(headers).forEach((item) => {xhr.setRequestHeader(item, headers[item]);});xhr.onloadend = function (e) {resolve({data: e.target.response,});};xhr.send(data);});
}相关文章:
大文件分片上传、分片进度以及整体进度、断点续传(一)
大文件分片上传 效果展示 前端 思路 前端的思路:将大文件切分成多个小文件,然后并发给后端。 页面构建 先在页面上写几个组件用来获取文件。 <body><input type"file" id"file" /><button id"uploadButton…...

Pytest 的小例子
一个简单的例子 下面代码保存到test_pytest.py 一个简单的例子 def inc(x):return x 1def test_answer():assert inc(3) 5def test_ask():assert inc(4) 5 pytest 需要安装一下 pip install pytest (Venv) D:\pythonwork>pip install pytest Collecting pytestDown…...
:概率统计基础)
大数据(十一):概率统计基础
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教程(0基础)》 再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对…...

web前端之TypeScript
MENU typescript类型别名、限制值的大小typescript使用class关键字定义一个类、static、readonlytypescript中class的constructor(构造函数)typescript中abstractClass(抽象类)、extends、abstracttypescript中的接口、type、interfacetypescript封装属性、public、private、pr…...

计网Lesson6 - IP 地址分类管理
文章目录 1. I P IP IP 地址定义2. I P v 4 IPv4 IPv4 的表示方法2.1 I P v 4 IPv4 IPv4 的分类编址法2.2 I P v 4 IPv4 IPv4 的划分子网法2.2.1 如何划分子网2.2.2 如何确定子网的借位数2.2.3 总结2.2.4 题目练习 2.3 I P v 4 IPv4 IPv4 的无分类编址法 1. I P IP IP 地…...
Nat. Mach. Intell. | 预测人工智能的未来:在指数级增长的知识网络中使用基于机器学习的链接预测
今天为大家介绍的是来自Mario Krenn团队的一篇论文。一个能够通过从科学文献中获取洞见来建议新的个性化研究方向和想法的工具,可以加速科学的进步。一个可能受益于这种工具的领域是人工智能(AI)研究,近年来科学出版物的数量呈指数…...

MySQL海量数据配置优化教程
1.缓存大小调整 缓存是数据库中用于减少磁盘 I/O 操作的重要机制。通过增加缓存大小,可以减少对磁盘的访问,从而提高查询性能。 可以使用 innodb_buffer_pool_size 参数来调整 InnoDB 缓存的大小。例如,将缓存大小设置为服务器内存的 70% my…...

Mac-idea快捷键操作
–以下是程序员在Mac中常用的快捷键 弹出程序坞ctrol f3 窗口满屏,半屏 ctrol command f 切换同一个程序的窗口 command ~ 打开最小化窗口 command tab option 拷文件路径 command option c 显示隐藏文件command shift . 显示所有窗口 control 向上箭头 chrome 全屏…...
HarmonyOS脚手架:UI组件之文本和图片
前言 关于HarmonyOS脚手架,本篇是系列的第二篇,主要实现UI组件文本和图片的常见效果查看,本身功能特别的简单,其目的也是很明确,方便大家根据效果查看相关代码实现,可以很方便的进行复制使用,当…...

详细学习Pyqt5中的6种按钮
Pyqt5相关文章: 快速掌握Pyqt5的三种主窗口 快速掌握Pyqt5的2种弹簧 快速掌握Pyqt5的5种布局 快速弄懂Pyqt5的5种项目视图(Item View) 快速弄懂Pyqt5的4种项目部件(Item Widget) 快速掌握Pyqt5的6种按钮 快速掌握Pyqt5的10种容器&…...

【工具】Zotero|使用Zotero向Word中插入引用文献(2023年)
版本:Word 2021,Zotero 6.0.30 前言:两年前我找网上插入文献的方式,网上的博客提示让我去官网下个插件然后才能装,非常麻烦,导致我对Zotero都产生了阴影。最近误打误撞发现Zotero自带了Word插件,…...

利用Python爬虫爬取豆瓣电影排名信息
可以使用第三方库Beautiful Soup和Requests来编写一个简单的爬虫,从豆瓣电影Top100页面获取信息 import requests from bs4 import BeautifulSoupdef get_douban_top100():url https://movie.douban.com/top250headers {User-Agent: Mozilla/5.0 (Windows NT 10.…...
灯光开不了了,是不是NVIDIA的问题
如果你跟我一样灯光亮度调节不了了,然后显示适配器又没有了,你看一下是不是和我这个大怨种一样把NVIDIA卸了,为了这个东西,这屏幕亮瞎我的眼镜😢😢。只需要进入官网,你就可以直接找到࿰…...

线性可分SVM摘记
线性可分SVM摘记 0. 线性可分1. 训练样本到分类面的距离2. 函数间隔和几何间隔、(硬)间隔最大化3. 支持向量 \qquad 线性可分的支持向量机是一种二分类模型,支持向量机通过核技巧可以成为非线性分类器。本文主要分析了线性可分的支持向量机模型,主要取自…...
LabVIEW在调用image.cpp或drawmgr.cpp因为DAbort而崩溃
LabVIEW在调用image.cpp或drawmgr.cpp因为DAbort而崩溃 出现下列问题,如何解决? 1. LabVIEW 程序因image.cpp或drawmgr.cpp中的错误而崩溃 2. 正在通过cRIO-9034运行独立的LabVIEW应用程序,但它因drawmgr.cpp中的错误而崩溃 …...
nodejs微信小程序+python+PHP贵州旅游系统的设计与实现-计算机毕业设计推荐MySQL
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...

WebUI自动化学习(Selenium+Python+Pytest框架)003
1.元素操作 在成功定位到元素之后,我们需要对元素进行一些操作动作。常用的元素操作动作有: (1)send_keys() 键盘动作:向浏览器发送一个内容,通常用于输入框输入内容或向浏览器发送快捷键 (2…...

python+Appium自动化:python多线程多并发启动appium服务
Python启动Appium 服务 使用Dos命令或者bat批处理来手动启动appium服务,启动效率低下。如何将启动Appium服务也实现自动化呢? 这里需要使用subprocess模块,该模块可以创建新的进程,并且连接到进程的输入、输出、错误等管道信息&…...
【计算机网络笔记】802.11无线局域网
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

用C++和python混合编写数据采集程序?
之前看过一篇文章,主要阐述的就是多种语言混合编写爬虫程序,结合各种语言自身优势写一个爬虫代码是否行得通?觉得挺有意思的,带着这样的问题,我尝试着利用我毕生所学写了一段C和python混合爬虫程序,目前运行…...

5个效率倍增技巧:ColorWanted如何解决设计师与开发者的颜色管理难题
5个效率倍增技巧:ColorWanted如何解决设计师与开发者的颜色管理难题 【免费下载链接】ColorWanted Screen color picker for Windows (Windows 上的屏幕取色器) 项目地址: https://gitcode.com/gh_mirrors/co/ColorWanted 在数字设计与开发工作中,…...

TCA9548A I²C多路复用器原理与嵌入式实战指南
1. TCA9548A IC多路复用器技术解析与嵌入式系统集成实践 1.1 器件定位与工程价值 TCA9548A是德州仪器(TI)推出的低电压8通道IC总线开关,其核心价值在于解决嵌入式系统中IC总线地址冲突这一经典工程难题。在STM32、ESP32、Raspberry Pi等主流…...

OpenClaw学习助手:Gemma-3-12b-it生成错题本与定制复习计划
OpenClaw学习助手:Gemma-3-12b-it生成错题本与定制复习计划 1. 为什么需要AI学习助手? 作为一名经常需要处理大量学习资料的开发者,我一直在寻找能够提升学习效率的工具。传统的错题本整理方式需要手动抄写题目、标注知识点、寻找同类练习题…...

2.Pandas在电商数据处理中的核心价值
第1章 Pandas在电商数据处理中应用 1.1 为什么Excel不够用,需要Pandas Pandas是Python里的数据分析核心库。它的名字来自“Panel Data”(面板数据),专门处理表格型数据。电商数据分析里,Pandas主要解决三类问题&#x…...

OpenClaw压力测试:Phi-3-mini-128k-instruct持续运行24小时稳定性报告
OpenClaw压力测试:Phi-3-mini-128k-instruct持续运行24小时稳定性报告 1. 测试背景与目标 上周在本地部署了OpenClawPhi-3-mini组合后,我一直在思考这套方案的稳定性边界。作为个人自动化助手,它能否胜任724小时不间断工作?当我…...

多层PCB内部结构与HDI技术深度解析
1. 多层PCB内部结构全解析作为一名硬件工程师,第一次拆解十层PCB板时,那种震撼感至今难忘。密密麻麻的过孔像微型城市的地下管网,精密排布的走线如同错综复杂的立体交通网。今天我就用最直观的立体解剖图,带你看透各种叠层结构的P…...

Linux安装中文+MySQL的详细过程
中文安装1. 清理环境变量打开终端执行:sed -i /fcitx/d ~/.bashrcsed -i /GTK_IM_MODULE/d ~/.bashrcsed -i /QT_IM_MODULE/d ~/.bashrcsed -i /XMODIFIERS/d ~/.bashrc2. 重新配置 ibus 环境变量echo export GTK_IM_MODULEibus >> ~/.bashrcecho export QT_I…...
:探讨 C++ 动态链接库在内存布局上的安全特性)
C++ 地址空间随机化(ASLR):探讨 C++ 动态链接库在内存布局上的安全特性
尊敬的各位同仁,各位对系统安全和C编程充满热情的开发者们,大家下午好!今天,我们齐聚一堂,共同探讨一个在现代软件安全领域至关重要的主题——地址空间布局随机化(ASLR),特别是它如何…...

新手入门指南:基于快马生成的代码理解设备配对功能实现
今天想和大家分享一个特别适合新手学习的设备配对功能实现案例。这个例子用最基础的HTML、CSS和原生JavaScript就能完成,特别适合刚接触前端开发的朋友理解交互逻辑。 项目结构设计 整个项目分为三个部分:两个模拟设备(用不同图标表示&#x…...

快马AI助力:十分钟用Python搭建免费股票行情网站原型
最近想验证一个股票行情网站的原型,但作为独立开发者,从零搭建前后端实在太耗时。尝试用PythonFlask快速实现,结合InsCode(快马)平台的AI辅助功能,居然十分钟就完成了基础框架。记录下关键实现思路: 数据获取层设计 选…...