数学建模-基于BL回归模型和决策树模型对早产危险因素的探究和预测
整体求解过程概述(摘要)
近年来,全球早产率总体呈上升趋势,在我国,早产儿以每年 20 万的数目逐年递增,目前早产已经成为重大的公共卫生问题之一。据研究,早产是威胁胎儿及新生儿健康的重要因素,可能会造成死亡或智力体力缺陷,因此研究早产的影响因素,建立预测早产的模型就显得极为重要。我们以问卷、面对面访谈的方式,收录了湖南省妇幼保健院 2013 年 5 月 13 日-2019 年 12 月 31 日妊娠 8-14周且接受首次产前护理的孕妇,共 18527 份样本,调查研究孕妇包括医学和社会学信息在内的 104 个变量。基于大样本、多变量的数据特征,对数据预处理后,首先基于传统的统计方法,依次通过 SMOTE 过采样均衡数据、x2 相似性检验剔除无关变量、二阶聚类(TwoStep Cluster)实现降维,用 Binary Logistic 建立早产预测模型,并通过 AUC-ROC 曲线对早产预测模型进行准确性检验;在此基础上,进一步探讨并合理利用机器学习的效力,用数据挖掘的方法,依次通过随机欠抽样平衡样本,特征选择变量实现变量降维,分别用决策树 C5.0 算法,推理集 C5.0算法,决策树 CHAID 算法建立早产预测模型,并通过 boosting 技术提高模型稳健性。
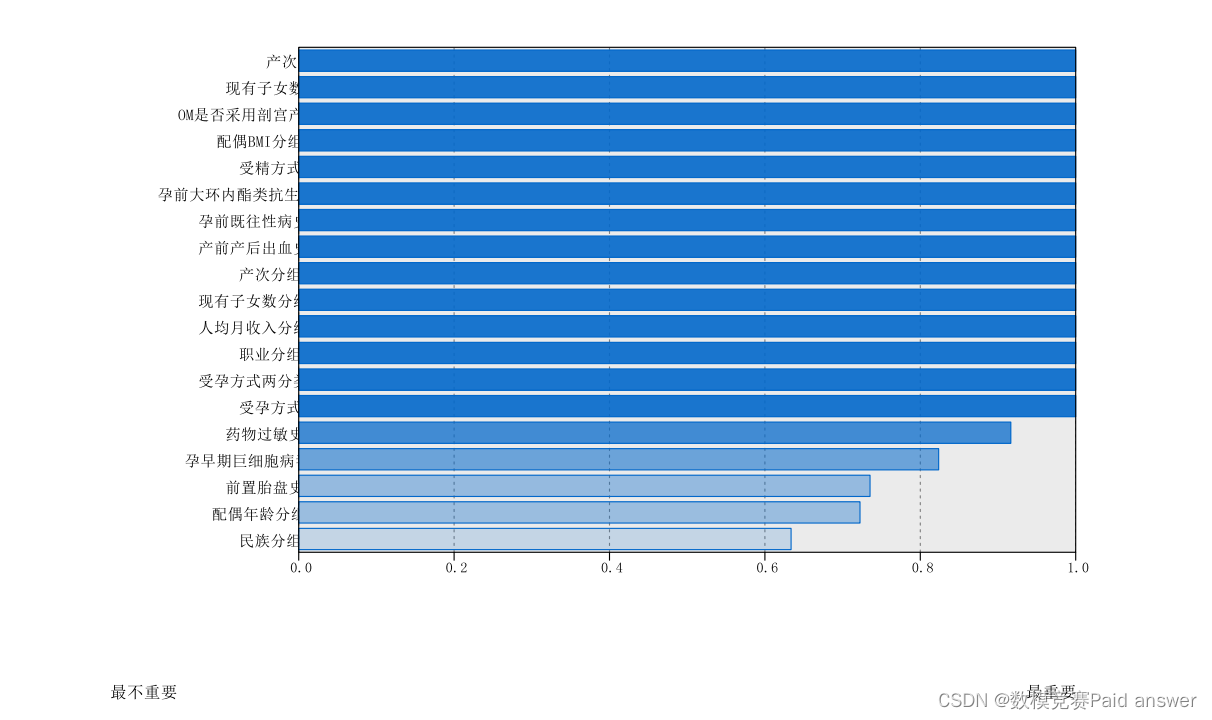
根据二阶聚类降维结果、Binary Logistic 建立的早产预测模型及检验结果,发现城乡分组、人均月收入、母亲孕前 BMI 分组、受精方式、受孕方式、孕次分组、孕早期柯萨奇病毒、孕前既往性病史、是否采用剖宫产、配偶 BMI 分组这 10 个变量与是否早产的相关性较强,且在经过哑变量处理后,适用于建立早产预测模型。通过 AUC-ROC 曲线,检验出该早产预测模型拟合度良好。在初步探索之后,进一步深入利用机器学习,即分别使用决策树 C5.0 算法,推理集 C5.0 算法,决策树 CHAID 算法建立三个早产预测模型。其中通过决策树 C5.0 算法建立的早产预测模型,在测试集上的准确性为 93.78%,平均正确性为 0.859、平均不正确性为 0.692;推理集 C5.0 算法的准确性为 95.92%,平均正确性为 0.824、平均不正确性为0.714;决策树 CHAID 算法建立的早产预测模型,在测试集上的准确性为79.58%,取置信度为 0.812。
数据预处理
(一)变量预处理
类别化处理及选择:将品质变量整理成 0-1 型数值变量,如民族;对于连续变量和其他可合并的变量进行整合,这样会得到有重复信息的变量,比如配偶BMI 值和配偶 BMI 值分组,受孕方式和受孕方式两分类。不做特别说明的情况下,本次研究将主要使用分类型变量,且选择使用分类型变量中分组较少的那一个,比如刚刚提到两组变量,均选择后一组变量进入样本。这是因为在本次研究中,分类型变量占绝大多数,而相同的数据类型有更方便建模的处理,投入到未来实际预测操作中也更加简单明了。
(二)样本处理
类别不平衡(class-imbalance):指分类任务中不同类别的训练样例数目差别很大的情况。在分类学习中方法,默认不同类别的训练样例数目基本相当。若样本类别数目差别很大,属于极端不均衡,会对学习过程(模型训练)造成困扰。这些学习算法的设计背后隐含的优化目标是数据集上的分类准确度,而这会导致学习算法在不平衡数据上更偏向于含更多样本的多数类。多数不平衡学习(imbalance learning)算法就是为解决这种“对多数类的偏好”而提出的。据实践经验表明,正负类样本类别不平衡比例超过 4:1 时,分类要求会因为数据不平衡而无法得到满足,分类器处理结果将变差,导致预测效果达不到预期要求。在本次研究项目中,早产 0:1 比约为 5:1(0 为不发生,1 为发生。本论文其他部分未做其他说明时,都按照该标签规则),因此在构建模型之前,需要对该分类不均衡性问题进行处理。
二阶聚类
实现步骤
步骤 1、建立树根 clusterfeature,树根在一开始每个节点中会放置一个数据集中的第一个记录,它就包含有这个数据存储集中每个变量的信息。相似性用的是距离数值测量,数据的相似性可以作为进行距离数值测量的主要标准。相似度高的变量位于同一节点,同时,相似度低的变量生成新节点。似然归类测度模型假设每个变量必须服从特定的概率分布,聚类模型要求分类型独立变量必须服从多项式概率分布,数值型独立变量必须服从正态概率分布。
步骤 2、合并聚类算法。生成的聚类方案具有不同聚类数,不同的聚类数是基于合并聚类算法下节点的组合成果。
步骤 3、选择最优聚类数。通过 BIC:Bayesian Information Criterion 准则对各聚类情况进行比较,选出最优聚类方案。
数值说明
①对数似然:这种度量方式用于研究某种以确定概率分布的独立变量。其中数值型变量服从正态分布,分类型变量服从多项式分布。
②Bayesian 信息准则( BIC):在只有部分信息时,要预测未知状态下的部分信息值,选用主观概率;修正发生概率时采用贝叶斯公式,将得到的修正概率与预期产出的值结合计算出最优决策。
计算公式:
BIC=ln(n)k–2ln(L)
其中:k 为模型参数个数;n 为样本数量;L 为似然函数
聚类结果
二阶聚类适用于多分类变量的降维问题。显然,本次研究数据可选用 SPSS 中的二阶聚类对变量进行降维,聚类效果为良好,并最终由 77 个自变量降维到 14个主要变量(该 14 个变量重要性都为 1)
模型的建立与求解整体论文缩略图



全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
from imblearn.over_sampling import SMOTE
import numpy as np
from sklearn.model_selection import train_test_split
data = pd.read_excel('1(2).xlsx') #读取数据集
data = data.dropna(axis = 1, how = 'any') # 丢弃有 NAN 的列
data = data.dropna(axis = 0, how = 'any') # 丢弃有 NAN 的行
data = data.drop(columns=['ID', '调查人署名']) # 丢弃 ID 和调查人属名,这两
个非 float,放在这里是无效的
var = data.columns
Y = data.iloc[:,-1] # 获得因变量数据
X = data.iloc[:,:-1] # 获得自变量数据
oversampler=SMOTE(random_state=2021) # 导入过采样库—SMOTE 算法
# x_train, x_valid_test, y_train, y_valid_test =
train_test_split(X,Y,test_size=0.3,random_state=2020) # 将数据集切分为 训练集和
验证+测试集
x_train,y_train=oversampler.fit_sample(X,Y) # 对训练集进行 SMOTE 过采样,
得到过采样后的自变量和因变量
#
x_valid,x_test,y_valid,y_test=train_test_split(x_valid_test,y_valid_test,test_size=0.3,r
andom_state=2020)
data_smote = pd.concat([x_train,y_train],axis = 1)
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
数学建模-基于BL回归模型和决策树模型对早产危险因素的探究和预测
整体求解过程概述(摘要) 近年来,全球早产率总体呈上升趋势,在我国,早产儿以每年 20 万的数目逐年递增,目前早产已经成为重大的公共卫生问题之一。据研究,早产是威胁胎儿及新生儿健康的重要因素,可能会造成死亡或智力体…...

接口测试 —— 接口测试的意义
1、接口测试的意义(优势) (1)更早的发现问题: 不少的测试资料中强调,测试应该更早的介入到项目开发中,因为越早的发现bug,修复的成本越低。 然而功能测试必须要等到系统提供可测试…...

一些常见的爬虫库
一些常见的爬虫库,并按功能和用途进行分类: 通用爬虫库: Beautiful Soup:用于解析HTML和XML文档,方便地提取数据。Requests:用于HTTP请求,获取网页内容。Scrapy:一个强大的爬虫框架…...
2023.12.2 做一个后台管理网页(左侧边栏实现手风琴和隐藏/出现效果)
2023.12.2 做一个后台管理网页(左侧边栏实现手风琴和隐藏/出现效果) 网页源码见附件,比较简单,之前用很多种方法实现过该效果,这次的效果相对更好。 实现功能: (1)实现左侧边栏的手…...

【EMFace】《EMface: Detecting Hard Faces by Exploring Receptive Field Pyramids》
arXiv-2021 文章目录 1 Background and Motivation2 Related Work3 Advantages / Contributions4 Method5 Experiments5.1 Datasets and Metrics5.2 Ablation Study5.3 Comparison with State-of-the-Arts 6 Conclusion(own) 1 Background and Motivatio…...
)
详细学习Pyqt5的20种输入控件(Input Widgets)
Pyqt5相关文章: 快速掌握Pyqt5的三种主窗口 快速掌握Pyqt5的2种弹簧 快速掌握Pyqt5的5种布局 快速弄懂Pyqt5的5种项目视图(Item View) 快速弄懂Pyqt5的4种项目部件(Item Widget) 快速掌握Pyqt5的6种按钮 快速掌握Pyqt5的10种容器&…...
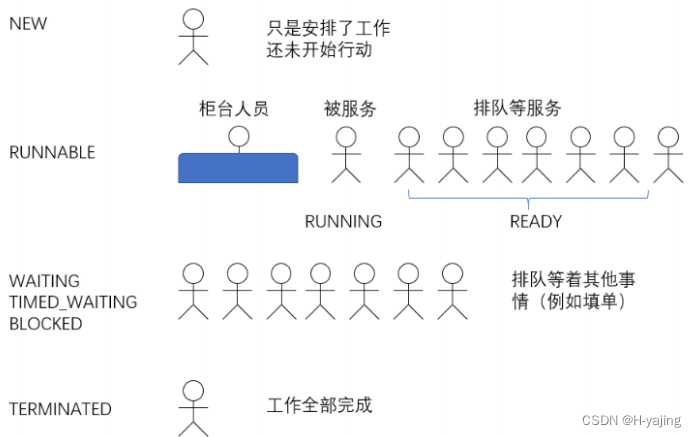
【JavaEE初阶】Thread 类及常见方法、线程的状态
目录 1、Thread 类及常见方法 1.1 Thread 的常见构造方法 1.2 Thread 的几个常见属性 1.3 启动⼀个线程 - start() 1.4 中断⼀个线程 1.5 等待⼀个线程 - join() 1.6 获取当前线程引用 1.7 休眠当前线程 2、线程的状态 2.1 观察线程的所有状态 2.2 线程状态和状…...
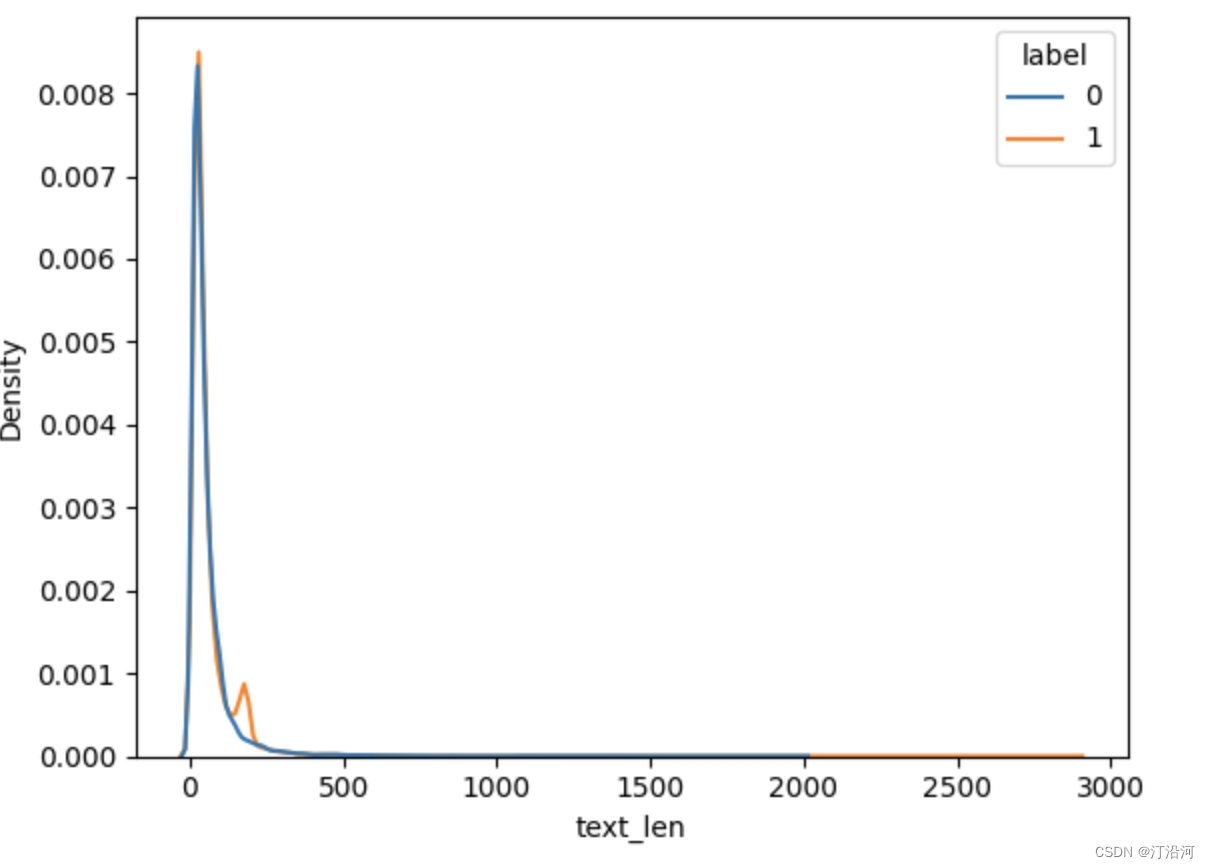
0 NLP: 数据获取与EDA
0数据准备与分析 二分类任务,正负样本共计6W; 数据集下载 https://github.com/SophonPlus/ChineseNlpCorpus/raw/master/datasets/online_shopping_10_cats/online_shopping_10_cats.zip 样本的分布 正负样本中评论字段的长度 ,超过500的都…...

159.库存管理(TOPk问题!)
思路:也是tok的问题,与上篇博客思路一样,只不过是求前k个小的元素! 基于快排分块思路的代码如下: class Solution { public:int getkey(vector<int>&nums,int left,int right){int rrand();return nums[r%…...
【开源】基于Vue+SpringBoot的康复中心管理系统
项目编号: S 056 ,文末获取源码。 \color{red}{项目编号:S056,文末获取源码。} 项目编号:S056,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 普通用户模块2.2 护工模块2.3 管理员…...

设计模式总览
一、设计模式 介绍 种一棵树最好的时间是十年前,其次是现在 《援助的死亡》-- 比萨莫约 The best time to plant a tree was 10 years ago。 The second best time is now。 《dead aid》-- Dambisa Moyo 1、创建型模式 1.1、单例模式 确保一个类最多只有一个实…...

数据链路层之VLAN基本概念和基本原理
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某技术知识点… 一个人摸索学习很难坚持,想组团高效学习… 想写博客但无从下手,急需…...
UVA11729 Commando War
UVA11729 Commando War 题面翻译 突击战 你有n个部下,每个部下需要完成一项任务。第i个部下需要你花Bj分钟交代任务,然后他就会立刻独立地、无间断地执行Ji分钟后完成任务。你需要选择交代任务的顺序,使得所有任务尽早执行完毕(…...

【数据库】数据库基于封锁机制的调度器,使冲突可串行化,保障事务和调度一致性
封锁使可串行化 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更…...
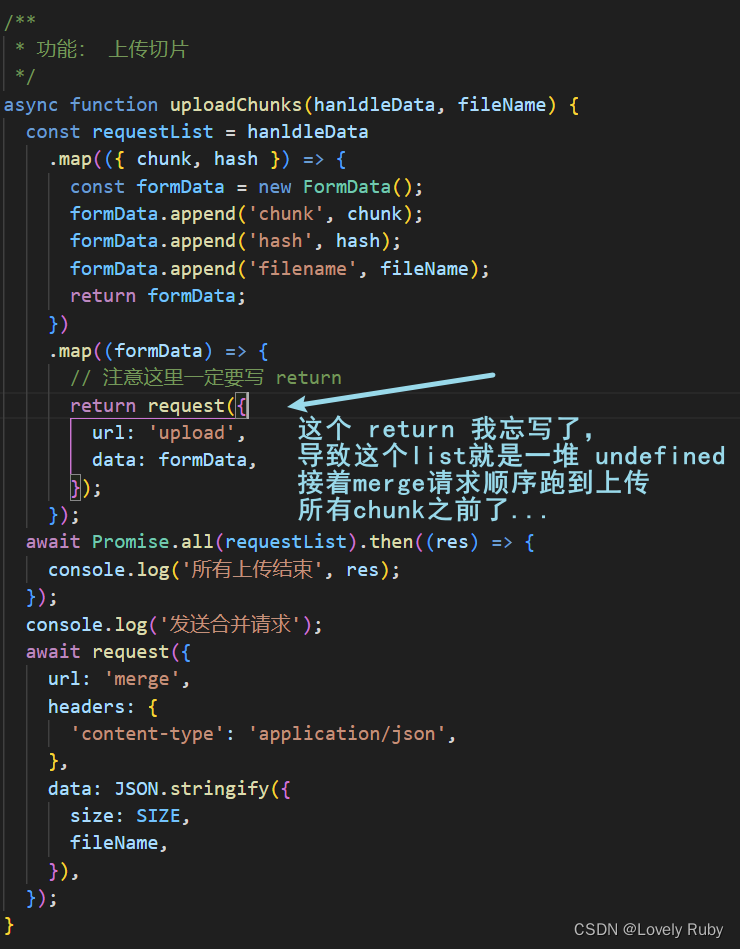
大文件分片上传、分片进度以及整体进度、断点续传(一)
大文件分片上传 效果展示 前端 思路 前端的思路:将大文件切分成多个小文件,然后并发给后端。 页面构建 先在页面上写几个组件用来获取文件。 <body><input type"file" id"file" /><button id"uploadButton…...

Pytest 的小例子
一个简单的例子 下面代码保存到test_pytest.py 一个简单的例子 def inc(x):return x 1def test_answer():assert inc(3) 5def test_ask():assert inc(4) 5 pytest 需要安装一下 pip install pytest (Venv) D:\pythonwork>pip install pytest Collecting pytestDown…...
:概率统计基础)
大数据(十一):概率统计基础
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教程(0基础)》 再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对…...

web前端之TypeScript
MENU typescript类型别名、限制值的大小typescript使用class关键字定义一个类、static、readonlytypescript中class的constructor(构造函数)typescript中abstractClass(抽象类)、extends、abstracttypescript中的接口、type、interfacetypescript封装属性、public、private、pr…...

计网Lesson6 - IP 地址分类管理
文章目录 1. I P IP IP 地址定义2. I P v 4 IPv4 IPv4 的表示方法2.1 I P v 4 IPv4 IPv4 的分类编址法2.2 I P v 4 IPv4 IPv4 的划分子网法2.2.1 如何划分子网2.2.2 如何确定子网的借位数2.2.3 总结2.2.4 题目练习 2.3 I P v 4 IPv4 IPv4 的无分类编址法 1. I P IP IP 地…...
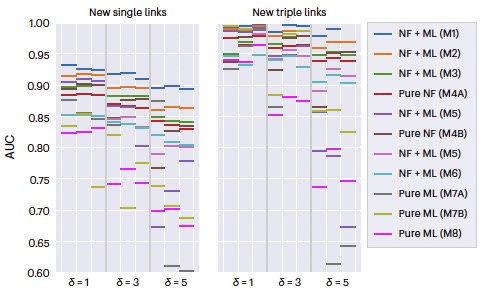
Nat. Mach. Intell. | 预测人工智能的未来:在指数级增长的知识网络中使用基于机器学习的链接预测
今天为大家介绍的是来自Mario Krenn团队的一篇论文。一个能够通过从科学文献中获取洞见来建议新的个性化研究方向和想法的工具,可以加速科学的进步。一个可能受益于这种工具的领域是人工智能(AI)研究,近年来科学出版物的数量呈指数…...

基于Helm Chart的JupyterHub生产级部署与运维实战指南
1. 项目概述:为什么我们需要一个可扩展的JupyterHub部署方案?如果你在团队里负责过数据科学或机器学习平台的搭建,大概率会为Jupyter Notebook的部署和管理头疼过。单个Jupyter Notebook服务给一两个人用还行,一旦团队规模扩大到十…...

MPLAB代码配置器实战:图形化配置PIC/AVR单片机外设,提升开发效率
1. 项目概述:为什么你需要关注MPLAB代码配置器如果你正在使用Microchip的PIC或AVR单片机,并且还在手动编写外设初始化代码、一遍遍翻阅数据手册核对寄存器位,那今天聊的这个工具,可能会让你有种“相见恨晚”的感觉。我说的就是MPL…...

基于WebSocket的机械爪远程控制桥接系统设计与实战
1. 项目概述:一个连接物理世界与数字世界的“机械爪”远程控制桥最近在捣鼓一个挺有意思的开源项目,叫lucas-jo/openclaw-bridge-remote。光看名字,你可能觉得这又是一个关于机器人或者机械臂的遥控项目,但实际深入进去࿰…...
:精准匹配V6.6新渲染引擎底层纹理采样逻辑)
【仅剩47份】Midjourney湿版摄影风格训练数据包(含1851–1889年原始湿版扫描图谱×236张+ICC色彩配置文件×5):精准匹配V6.6新渲染引擎底层纹理采样逻辑
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格的历史溯源与数字再生价值 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由英国科学家弗雷德里克斯科特阿彻(Frederick Scott Archer…...

DIY智能电机推子:从闭环控制到MIDI交互的硬件实战
1. 项目概述与核心价值如果你玩过专业的音频混音台,或者在一些高端的灯光控制台上见过那种会自己“嗖”一下滑到指定位置的推子,那你一定对电机推子(Motorized Fader)不陌生。这东西的魅力在于,它既是精准的模拟输入设…...

AI 能不能教孩子提问
AI 能不能教孩子提问 家长更该警惕的场景是:孩子一遇到卡点,就把题拍给 AI,等一个完整答案,然后连自己卡在哪里都说不出来。 这和用不用 AI 关系没那么简单。真正伤人的地方在于:孩子把困惑表达、假设尝试、错误修正这…...

AI编程助手用量追踪器:设计原理与本地化部署实践
1. 项目概述:一个专为编码代理设计的用量追踪器最近在折腾AI编程助手,发现一个挺实际的问题:当你把像Cursor、Claude Code、GitHub Copilot这类“编码代理”引入团队或者个人深度工作流后,怎么知道它们到底“吃”了多少资源&#…...

数据分析师GitHub作品集构建指南:从项目架构到技术实现
1. 项目概述:一个数据分析师的作品集仓库意味着什么? 在数据驱动的时代,简历上的“精通Python/SQL”已经不够看了。面试官,尤其是那些懂行的技术面试官,更想看到的是你如何用这些工具解决真实世界的问题。这就是为什么…...

深度神经网络参数安全与Hessian-aware训练防御技术
1. 深度神经网络参数安全威胁现状深度神经网络(DNN)在内存中的参数面临着严重的比特翻转安全威胁。这种威胁主要来自两个方面:自然发生的硬件故障和人为发起的攻击行为。在IEEE-754 32位浮点数表示中,一个比特的翻转可能导致参数值发生灾难性变化。例如&…...

HS2-HF Patch:3步安装HoneySelect2终极增强补丁完整指南
HS2-HF Patch:3步安装HoneySelect2终极增强补丁完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch是HoneySelect2玩家的游戏增强…...