SHAP(五):使用 XGBoost 进行人口普查收入分类
SHAP(五):使用 XGBoost 进行人口普查收入分类
本笔记本演示了如何使用 XGBoost 预测个人年收入超过 5 万美元的概率。 它使用标准 UCI 成人收入数据集。 要下载此笔记本的副本,请访问 github。
XGBoost 等梯度增强机方法对于具有多种形式的表格样式输入数据的此类预测问题来说是最先进的。 Tree SHAP(arXiv 论文)允许精确计算树集成方法的 SHAP 值,并已直接集成到 C++ XGBoost 代码库中。 这允许快速精确计算 SHAP 值,无需采样,也无需提供背景数据集(因为背景是从树木的覆盖范围推断出来的)。
在这里,我们演示如何使用 SHAP 值来理解 XGBoost 模型预测。
import matplotlib.pylab as pl
import numpy as np
import xgboost
from sklearn.model_selection import train_test_splitimport shap# print the JS visualization code to the notebook
shap.initjs()
1.加载数据集
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)# create a train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
d_train = xgboost.DMatrix(X_train, label=y_train)
d_test = xgboost.DMatrix(X_test, label=y_test)
2.训练模型
params = {"eta": 0.01,"objective": "binary:logistic","subsample": 0.5,"base_score": np.mean(y_train),"eval_metric": "logloss",
}
model = xgboost.train(params,d_train,5000,evals=[(d_test, "test")],verbose_eval=100,early_stopping_rounds=20,
)
[0] test-logloss:0.54663
[100] test-logloss:0.36373
[200] test-logloss:0.31793
[300] test-logloss:0.30061
[400] test-logloss:0.29207
[500] test-logloss:0.28678
[600] test-logloss:0.28381
[700] test-logloss:0.28181
[800] test-logloss:0.28064
[900] test-logloss:0.27992
[1000] test-logloss:0.27928
[1019] test-logloss:0.27935
3.经典特征归因
在这里,我们尝试 XGBoost 附带的全局特征重要性计算。 请注意,它们都是相互矛盾的,这激励了 SHAP 值的使用,因为它们具有一致性保证(意味着它们将正确排序特征)。
xgboost.plot_importance(model)
pl.title("xgboost.plot_importance(model)")
pl.show()
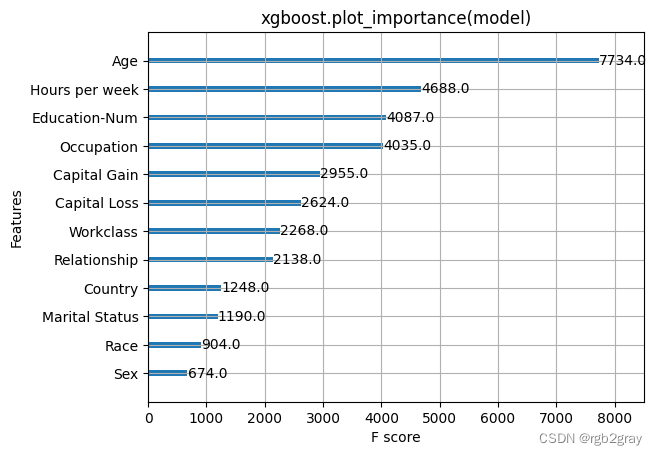
xgboost.plot_importance(model, importance_type="cover")
pl.title('xgboost.plot_importance(model, importance_type="cover")')
pl.show()
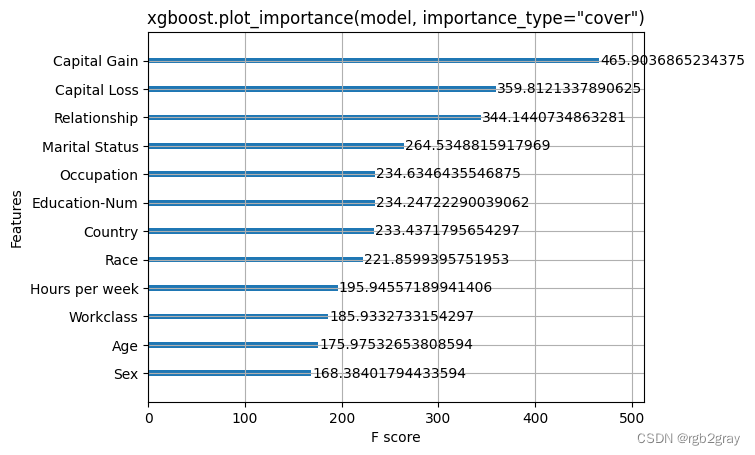
xgboost.plot_importance(model, importance_type="gain")
pl.title('xgboost.plot_importance(model, importance_type="gain")')
pl.show()
4,解释预测
在这里,我们使用集成到 XGBoost 中的 Tree SHAP 实现来解释整个数据集(32561 个样本)。
# this takes a minute or two since we are explaining over 30 thousand samples in a model with over a thousand trees
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
4.1 可视化单个预测
请注意,我们使用“显示值”数据框,因此我们得到了漂亮的字符串而不是类别代码。
shap.force_plot(explainer.expected_value, shap_values[0, :], X_display.iloc[0, :])

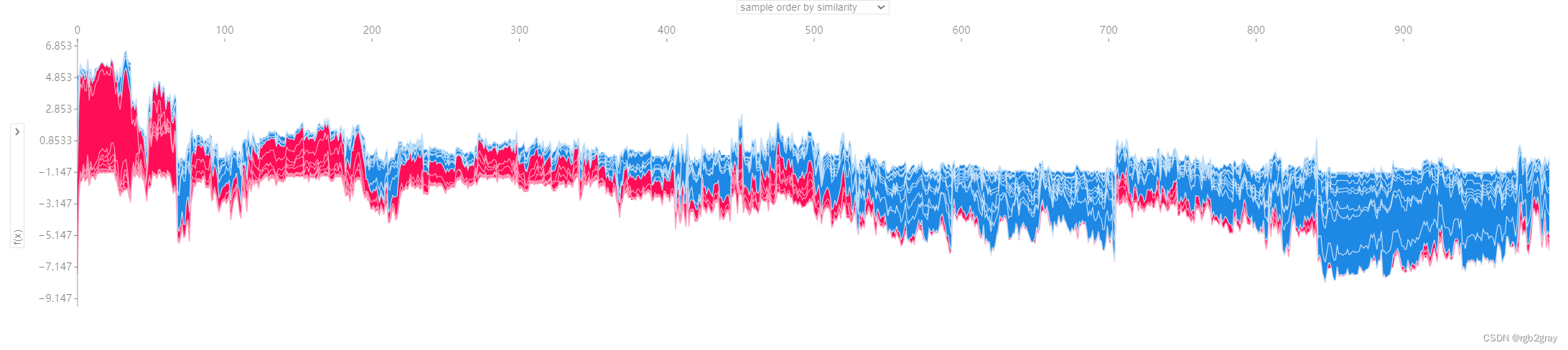
4.2 将许多预测可视化
为了让浏览器满意,我们只可视化 1,000 个人。
shap.force_plot(explainer.expected_value, shap_values[:1000, :], X_display.iloc[:1000, :]
)
5.平均重要性条形图
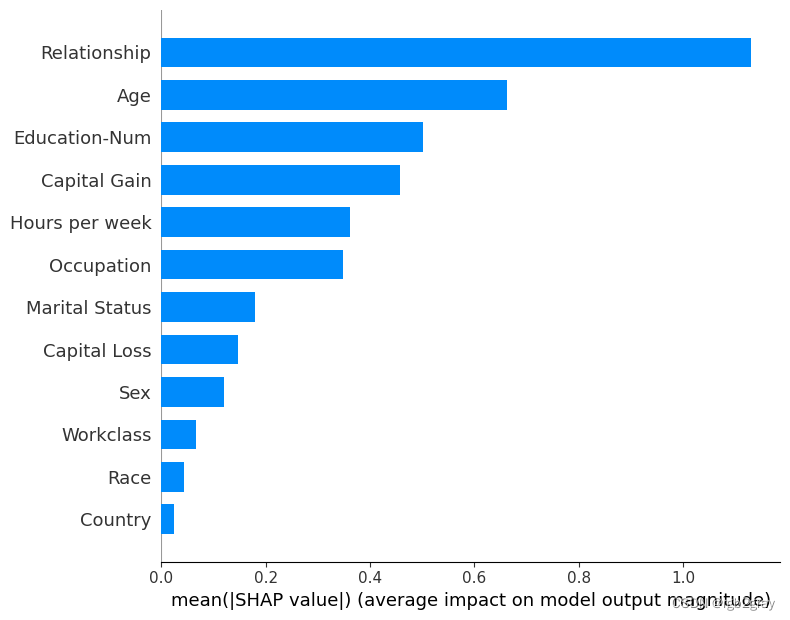
这取整个数据集中 SHAP 值大小的平均值,并将其绘制为简单的条形图。
shap.summary_plot(shap_values, X_display, plot_type="bar")
6.SHAP 概要图
我们没有使用典型的特征重要性条形图,而是使用每个特征的 SHAP 值的密度散点图来确定每个特征对验证数据集中个体的模型输出有多大影响。 特征按所有样本的 SHAP 值大小之和排序。 有趣的是,关系特征比资本收益特征具有更大的总体模型影响,但对于那些资本收益重要的样本,它比年龄具有更大的影响。 换句话说,资本收益对少数预测的影响较大,而年龄对所有预测的影响较小。
请注意,当散点不适合在线时,它们会堆积起来以显示密度,每个点的颜色代表该个体的特征值。
shap.summary_plot(shap_values, X)

7.SHAP 相关图
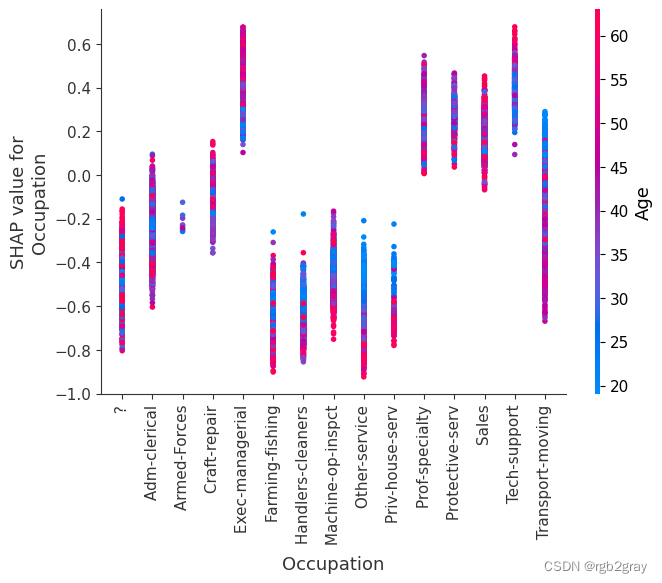
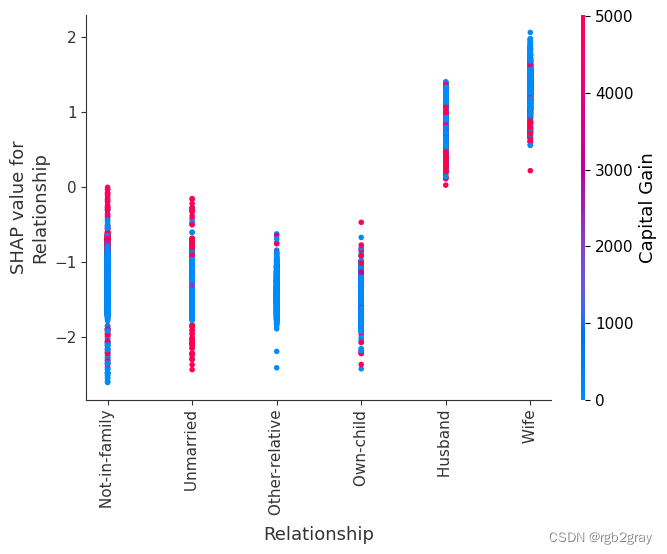
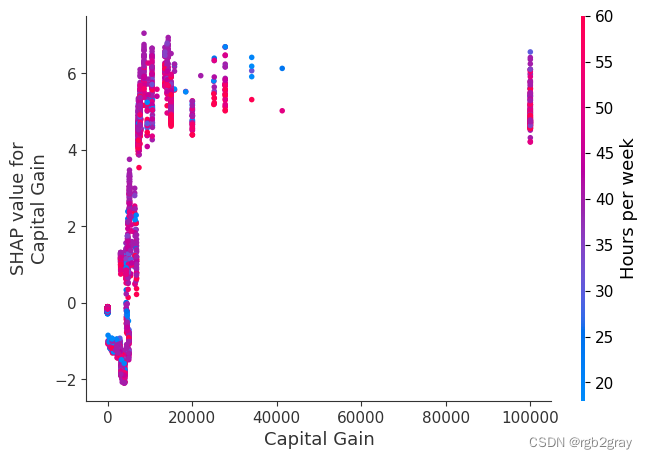
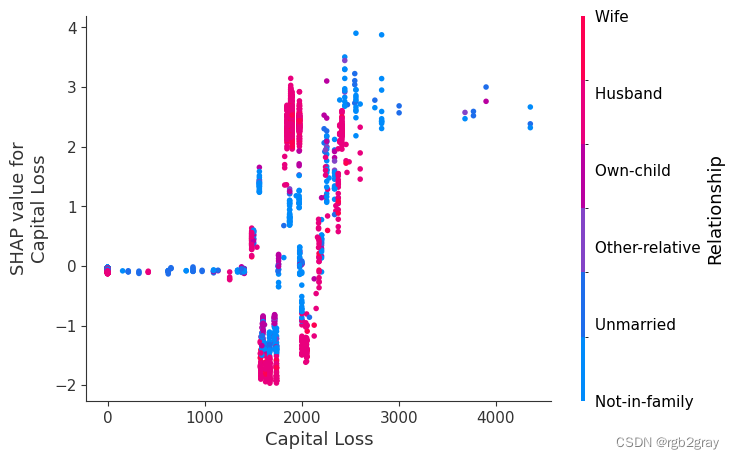
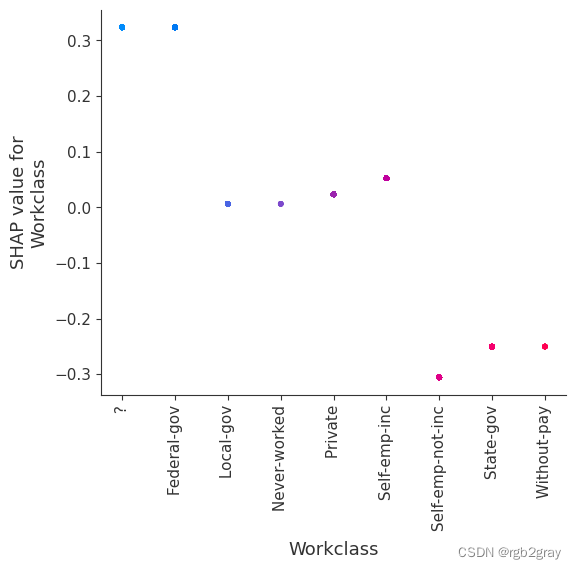
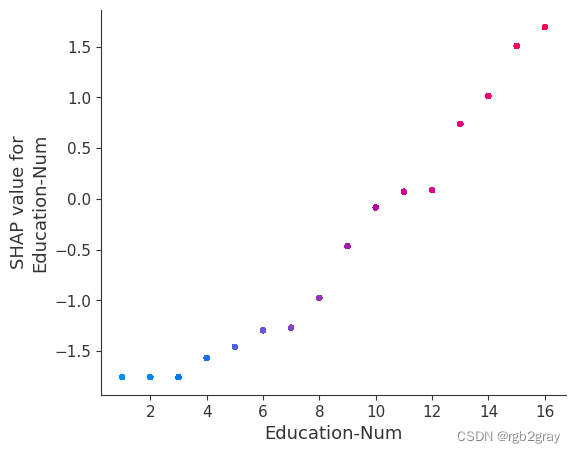
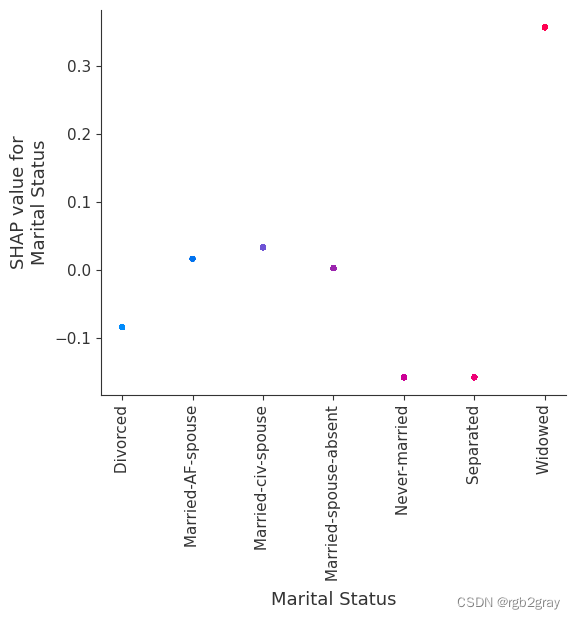
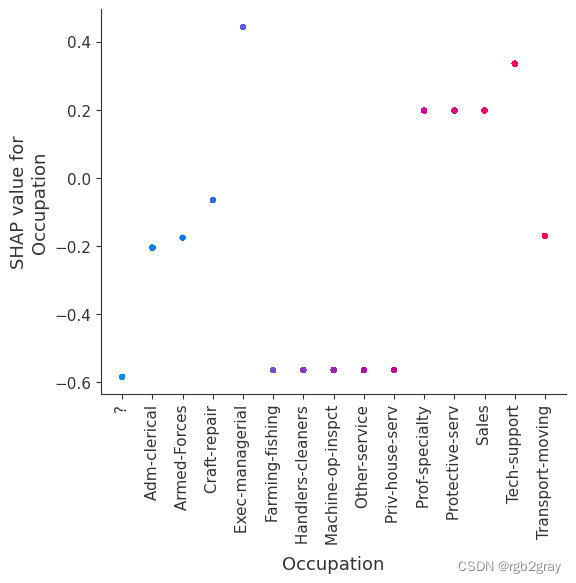
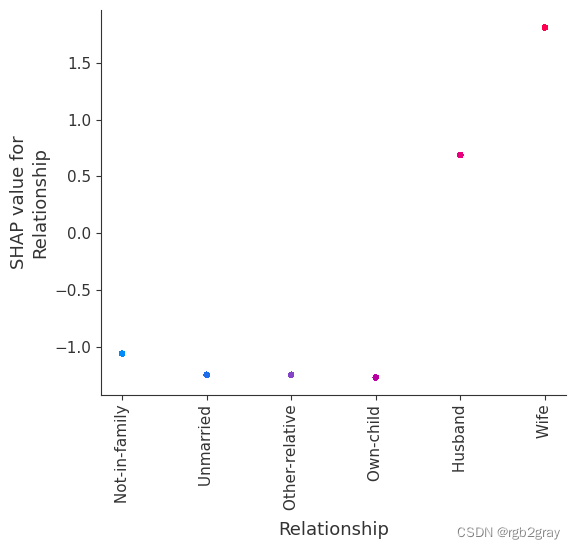
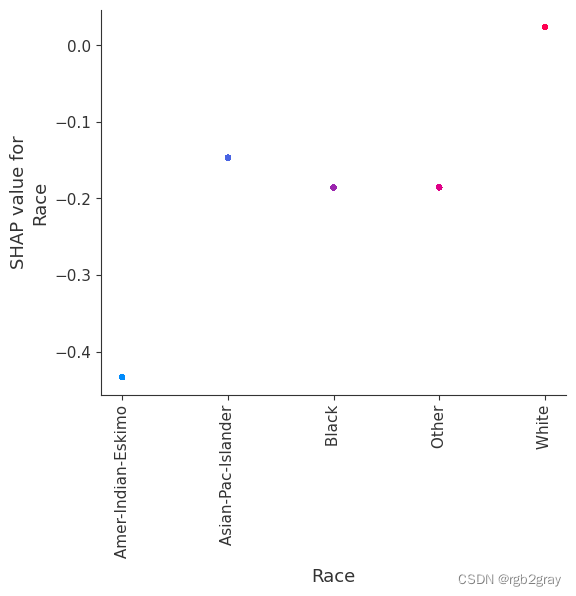
SHAP 依赖图显示单个特征对整个数据集的影响。 他们绘制了多个样本中某个特征的值与该特征的 SHA 值的关系图。 SHAP 依赖图与部分依赖图类似,但考虑了特征中存在的交互效应,并且仅在数据支持的输入空间区域中定义。 单个特征值处的 SHAP 值的垂直分散是由交互效应驱动的,并且选择另一个特征进行着色以突出可能的交互。
for name in X_train.columns:shap.dependence_plot(name, shap_values, X, display_features=X_display)

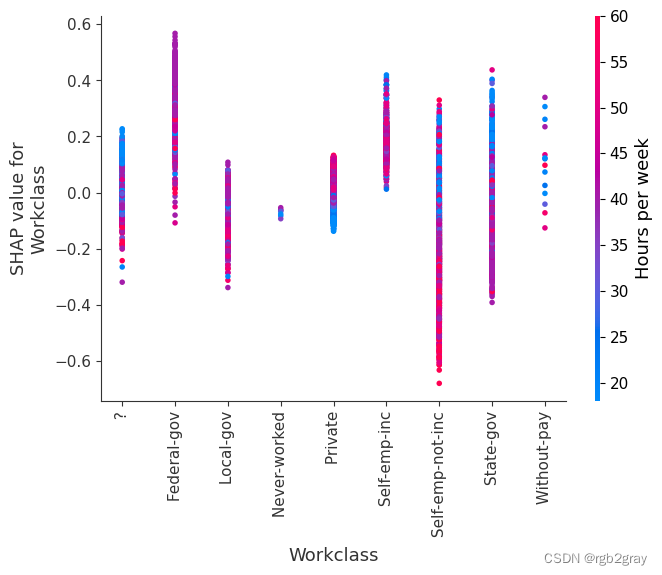
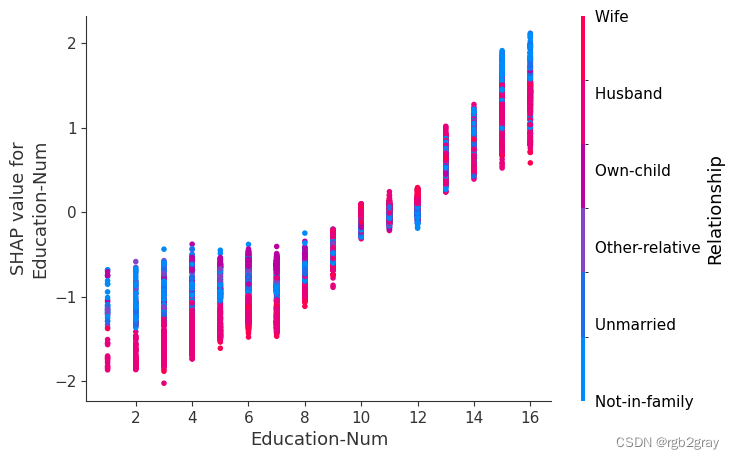
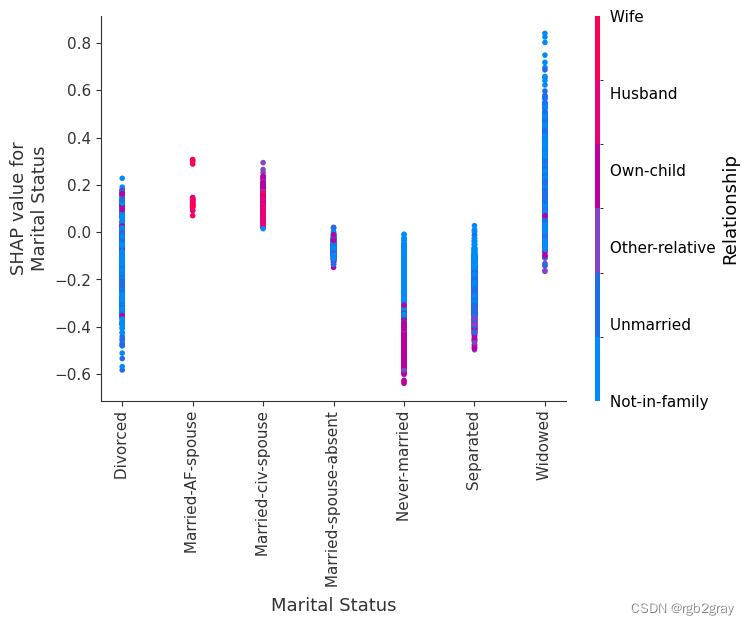
)



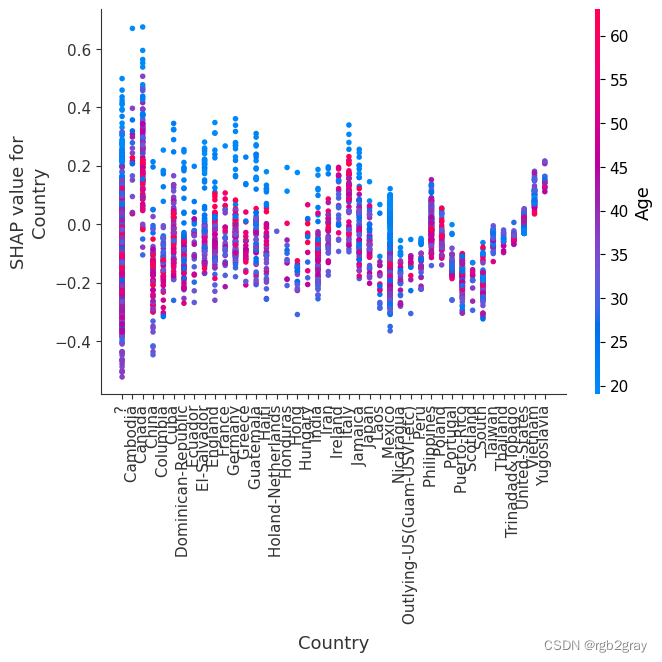
8.简单的监督聚类
按 shap_values 对人们进行聚类会导致与手头的预测任务相关的组(在本例中是他们的收入潜力)。
from sklearn.decomposition import PCA
from sklearn.manifold import TSNEshap_pca50 = PCA(n_components=12).fit_transform(shap_values[:1000, :])
shap_embedded = TSNE(n_components=2, perplexity=50).fit_transform(shap_values[:1000, :])
from matplotlib.colors import LinearSegmentedColormapcdict1 = {"red": ((0.0, 0.11764705882352941, 0.11764705882352941),(1.0, 0.9607843137254902, 0.9607843137254902),),"green": ((0.0, 0.5333333333333333, 0.5333333333333333),(1.0, 0.15294117647058825, 0.15294117647058825),),"blue": ((0.0, 0.8980392156862745, 0.8980392156862745),(1.0, 0.3411764705882353, 0.3411764705882353),),"alpha": ((0.0, 1, 1), (0.5, 1, 1), (1.0, 1, 1)),
} # #1E88E5 -> #ff0052
red_blue_solid = LinearSegmentedColormap("RedBlue", cdict1)
f = pl.figure(figsize=(5, 5))
pl.scatter(shap_embedded[:, 0],shap_embedded[:, 1],c=shap_values[:1000, :].sum(1).astype(np.float64),linewidth=0,alpha=1.0,cmap=red_blue_solid,
)
cb = pl.colorbar(label="Log odds of making > $50K", aspect=40, orientation="horizontal")
cb.set_alpha(1)
cb.outline.set_linewidth(0)
cb.ax.tick_params("x", length=0)
cb.ax.xaxis.set_label_position("top")
pl.gca().axis("off")
pl.show()

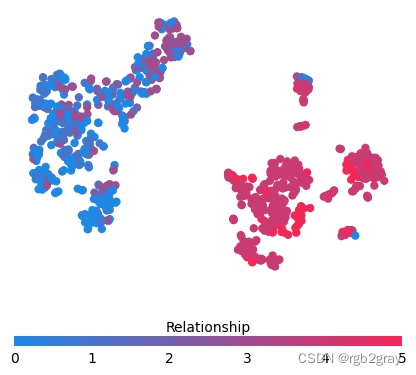
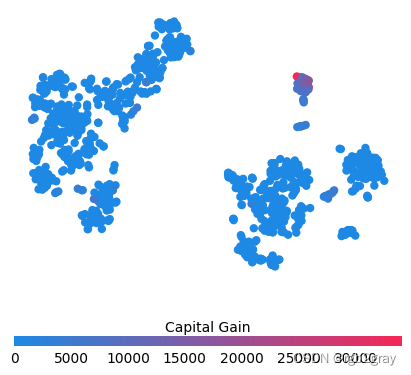
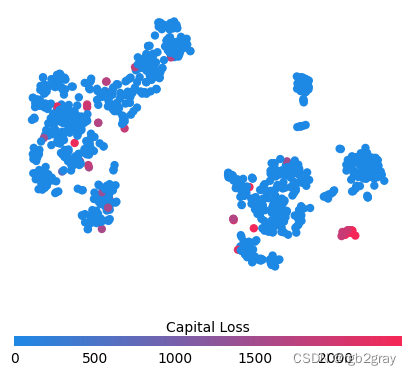
for feature in ["Relationship", "Capital Gain", "Capital Loss"]:f = pl.figure(figsize=(5, 5))pl.scatter(shap_embedded[:, 0],shap_embedded[:, 1],c=X[feature].values[:1000].astype(np.float64),linewidth=0,alpha=1.0,cmap=red_blue_solid,)cb = pl.colorbar(label=feature, aspect=40, orientation="horizontal")cb.set_alpha(1)cb.outline.set_linewidth(0)cb.ax.tick_params("x", length=0)cb.ax.xaxis.set_label_position("top")pl.gca().axis("off")pl.show()

训练每棵树只有两个叶子的模型,因此特征之间没有交互项
强制模型没有交互项意味着某个特征对结果的影响不依赖于任何其他特征的值。 这反映在下面的 SHAP 相关图中,因为没有垂直扩展。 垂直分布反映了一个特征的单个值可能对模型输出产生不同的影响,具体取决于个体呈现的其他特征的上下文。 然而,对于没有交互项的模型,无论个体可能具有哪些其他属性,特征总是具有相同的影响。
与传统的部分相关图相比,SHAP 相关图的优点之一是能够区分具有交互项和不具有交互项的模型。 换句话说,SHAP 相关图通过给定特征值处散点图的垂直方差给出了交互项大小的概念。
# train final model on the full data set
params = {"eta": 0.05,"max_depth": 1,"objective": "binary:logistic","subsample": 0.5,"base_score": np.mean(y_train),"eval_metric": "logloss",
}
model_ind = xgboost.train(params,d_train,5000,evals=[(d_test, "test")],verbose_eval=100,early_stopping_rounds=20,
)
[0] test-logloss:0.54113
[100] test-logloss:0.35499
[200] test-logloss:0.32848
[300] test-logloss:0.31901
[400] test-logloss:0.31331
[500] test-logloss:0.30930
[600] test-logloss:0.30619
[700] test-logloss:0.30371
[800] test-logloss:0.30184
[900] test-logloss:0.30035
[1000] test-logloss:0.29913
[1100] test-logloss:0.29796
[1200] test-logloss:0.29695
[1300] test-logloss:0.29606
[1400] test-logloss:0.29525
[1500] test-logloss:0.29471
[1565] test-logloss:0.29439
shap_values_ind = shap.TreeExplainer(model_ind).shap_values(X)
请注意,下面的交互颜色条对于该模型来说没有意义,因为它没有交互。
for name in X_train.columns:shap.dependence_plot(name, shap_values_ind, X, display_features=X_display)
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
invalid value encountered in divide
相关文章:
SHAP(五):使用 XGBoost 进行人口普查收入分类
SHAP(五):使用 XGBoost 进行人口普查收入分类 本笔记本演示了如何使用 XGBoost 预测个人年收入超过 5 万美元的概率。 它使用标准 UCI 成人收入数据集。 要下载此笔记本的副本,请访问 github。 XGBoost 等梯度增强机方法对于具有…...

LeetCode 8 字符串转整数
题目描述 字符串转换整数 (atoi) 请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C 中的 atoi 函数)。 函数 myAtoi(string s) 的算法如下: 读入字符串并丢弃无用的前导空格检查下一…...

前缀和 LeetCode1423. 可获得的最大点数
几张卡牌 排成一行,每张卡牌都有一个对应的点数。点数由整数数组 cardPoints 给出。 每次行动,你可以从行的开头或者末尾拿一张卡牌,最终你必须正好拿 k 张卡牌。 你的点数就是你拿到手中的所有卡牌的点数之和。 给你一个整数数组 cardPoi…...
探索意义的深度:自然语言处理中的语义相似性
一、说明 语义相似度,反应出计算机对相同内容,不同表达的识别能力。因而识别范围至少是个句子,最大范围就是文章,其研究方法有所区别。本文将按照目前高手的研究成绩,作为谈资介绍给诸位。 二、语义相似度简介 自然语言…...

WT2605-24SS高品质录音语音芯片:实时输出、不保存本地,引领音频技术新潮流
随着科技的快速发展,高品质音频技术成为了现代社会不可或缺的一部分。在这个追求高品质、高效率的时代,唯创知音推出的WT2605-24SS高品质录音芯片,以其独特的功能和卓越的性能,引领着音频技术的新潮流。 首先,WT2605-…...

Git 合并冲突解决步骤
Git 合并冲突解决步骤 1. 找到并打开冲突文件 定位到发生冲突的文件。可以通过 Git 的命令行输出找到这些文件。例如: pom.xmlsrc/main/java/com/zzm/config/SecurityConfig.javasrc/main/java/com/zzm/service/chat/UserConversationsServiceImpl.javasrc/main/…...
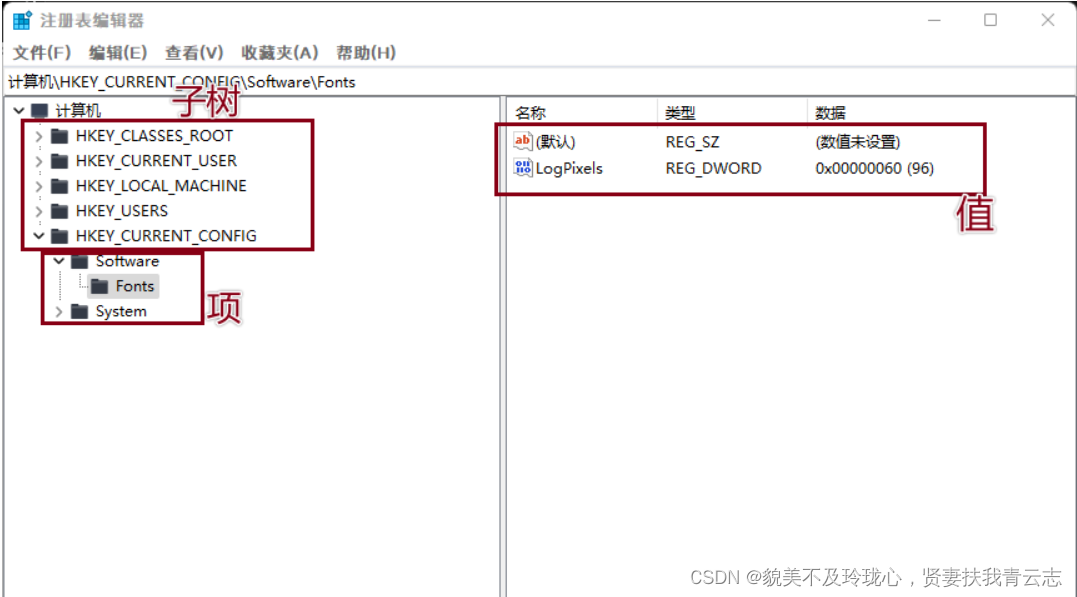
Windows核心编程 注册表
目录 注册表概述 打开关闭注册表 创建删除子健 查询写入删除键值 子健和键值的枚举 常用注册表操作 注册表概述 注册表是Windows操作系统、硬件设备以及客户应用程序得以正常运行和保存设置的核心"数据库",也可以说是一个非常巨大的树状分层结构的…...
【算法专题】二分查找
二分查找 二分查找1. 二分查找2. 在排序数组中查找元素的第一和最后一个位置3. 搜索插入位置4. x 的平方根5. 山脉数组的峰顶索引6. 寻找峰值7. 寻找旋转排序数组中的最小值8. 点名 二分查找 1. 二分查找 题目链接 -> Leetcode -704.二分查找 Leetcode -704.二分查找 题…...

中国消费电子行业发展趋势及消费者需求洞察|徐礼昭
一、引言 近年来,随着科技的飞速发展,消费电子行业面临着前所未有的挑战与机遇。本文将从行业发展趋势、消费者需求洞察以及企业数字化转型的方向和动作三个方面,对消费电子行业进行深入剖析。 二、消费电子行业发展趋势 5G技术的普及和应…...
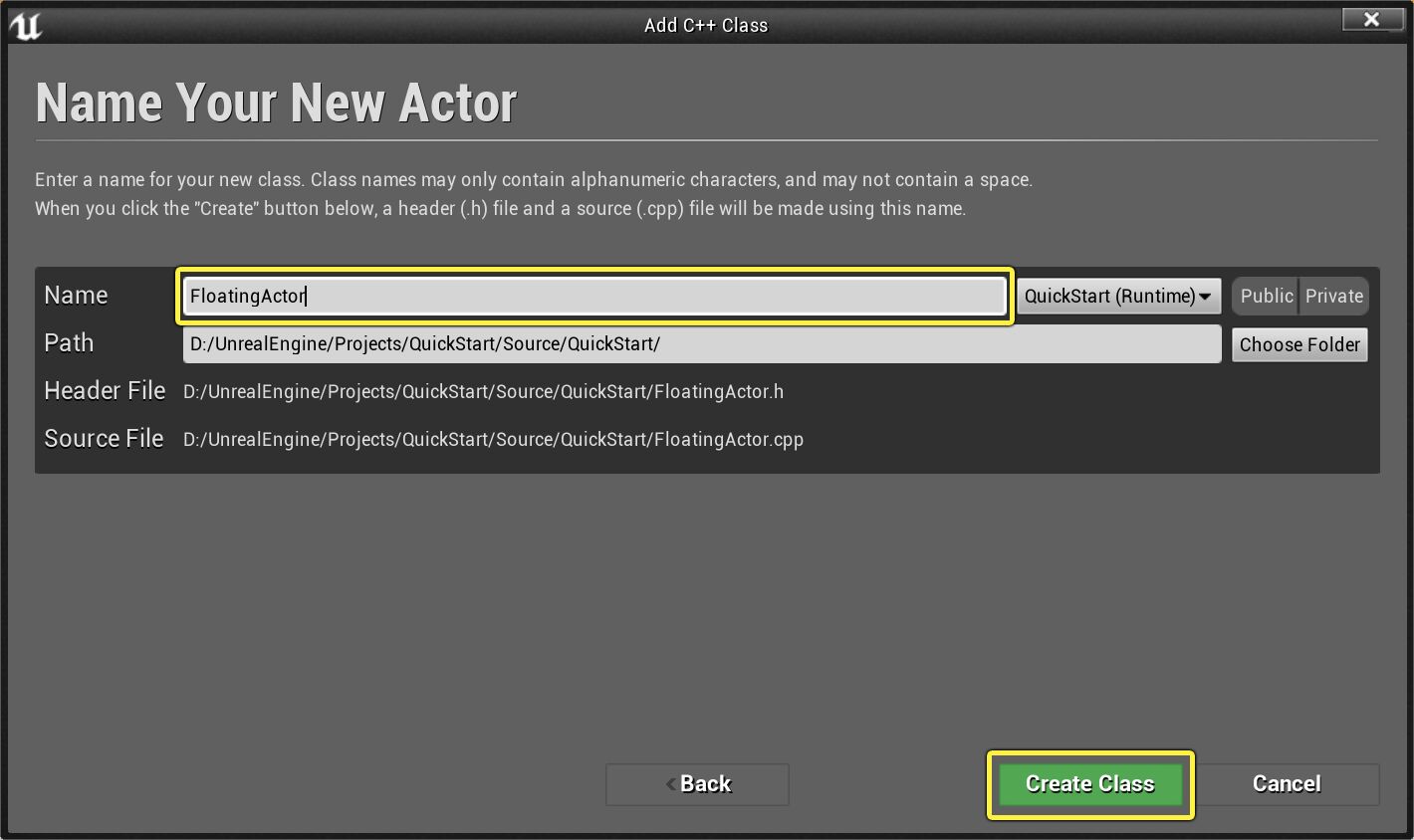
UE学习C++(1)创建actor
创建新C类 在 虚幻编辑器 中,点击 文件(File) 下拉菜单,然后选择 新建C类...(New C Class...) 命令: 此时将显示 选择父类(Choose Parent Class) 菜单。可以选择要扩展的…...

【CTA认证】Android8实现android6以下的应用运行时也要申请权限
需求 CTA入网认证,要求低版本比如Android6以下的应用,运行时,也需要有运行时权限(Runtime Permission)功能,不能默认就取到权限,必须人工在设置中打开才可。 环境 Android 8 实现 frameworks 修改思路是所有APP都…...

gRPC Java、Go、PHP使用例子
文章目录 1、Protocol Buffers定义接口1.1、编写接口服务1.2、Protobuf基础数据类型 2、服务器端实现2.1、生成gRPC服务类2.2、Java服务器端实现 3、java、go、php客户端实现3.1、Java客户端实现3.2、Go客户端实现3.3、PHP客户端实现 本文例子是在Window平台测试,Ja…...
———px,em,rem,vw,vh之间的区别)
前端知识笔记(十九)———px,em,rem,vw,vh之间的区别
一,px(像素):像素是屏幕上显示的最小单位,它是固定的,不随页面缩放而改变大小。在响应式设计中,使用像素单位可能会导致布局在不同屏幕尺寸上显示不一致。例如:现在在你电脑上一个字…...
docker部署frp穿透内网
文章目录 (1)部署frps服务器(2)部署frpc客户端(3)重启与访问frp(4)配置nginx反向代理 (1)部署frps服务器 docker安装参考文档:docker基本知识 1…...

使用pytorch从零开始实现迷你GPT
生成式建模知识回顾: [1] 生成式建模概述 [2] Transformer I,Transformer II [3] 变分自编码器 [4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II [5] 自回归模型 [6] 归一化流模型 [7] 基于能量的模型 [8] 扩散模型 I, 扩散模型 II…...

tp6框架 万级数据入库 php函数优化
将万级数据入库并判断有无 没有则新增 上篇是用mysql的replace into实现 本篇是另一种方法 这是我的数据格式: $data [ [ KCH > value1, other_column1 > value_other1_1, other_column2 > value_other2_1, ], [ KCH > value2, other_column…...
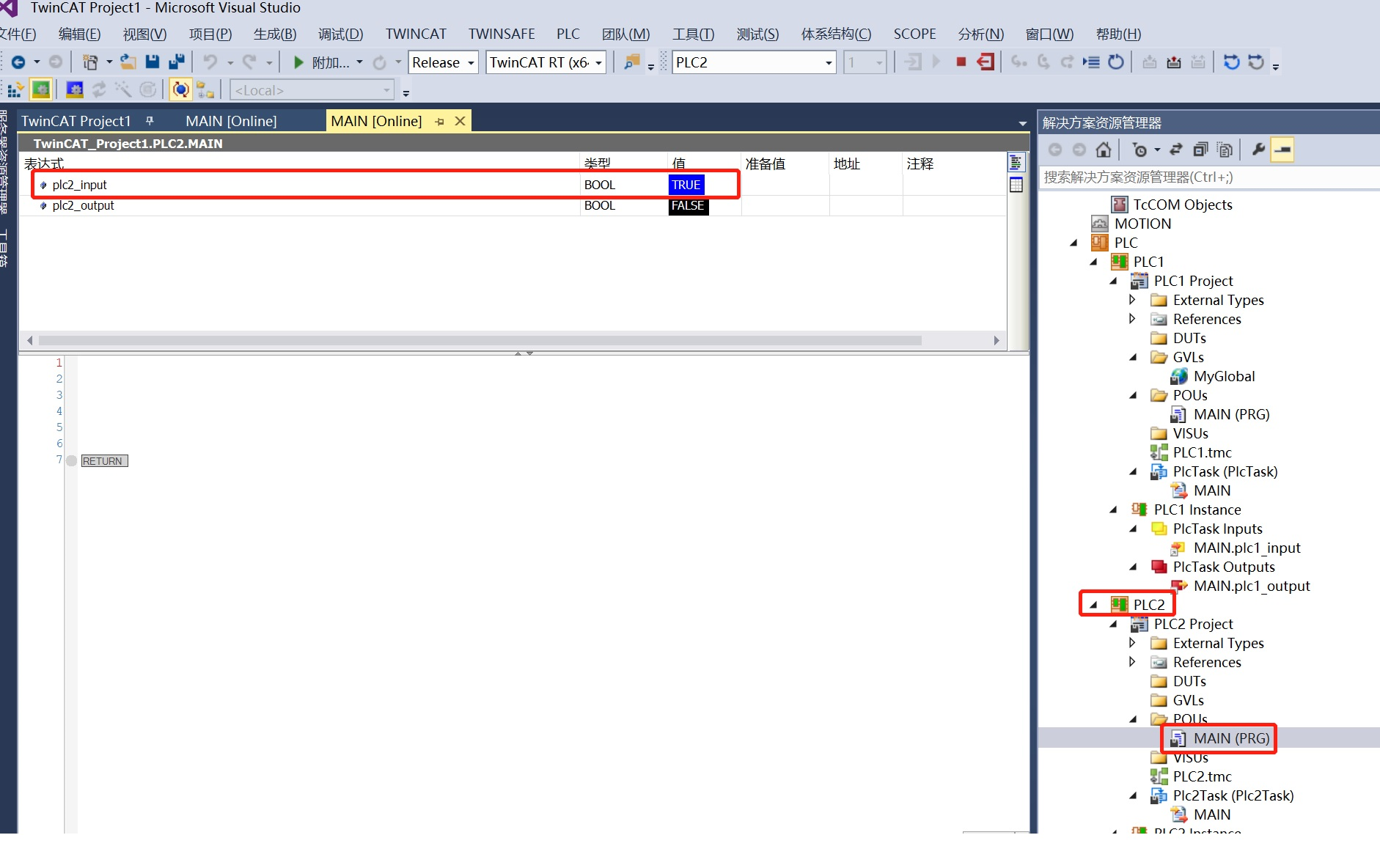
TwinCAT3一个PLC设备里多个程序工程之间通讯
目录 1、创建TwinCAT3工程,再分别创建两个PLC程序工程 2、PLC1工程中添加如下代码,然后编译重新生成PLC1工程 3、PLC2工程中添加如下代码,然后编译重新生成PLC2工程 4、变量关联 5、一个PLC运行多个PLC工程设置 7、工程下载链接 1、创建…...
python弹球小游戏
import pygame import random# 游戏窗口大小 WIDTH 800 HEIGHT 600# 定义颜色 WHITE (255, 255, 255) BLACK (0, 0, 0) RED (255, 0, 0) GREEN (0, 255, 0) BLUE (0, 0, 255)# 球的类 class Ball:def __init__(self):self.radius 10self.speed [random.randint(2, 4),…...
mongoose学习记录
mongoose安装和连接数据库 npm i mongoose导入mongoose const mongoose require(mongoose) mongoose.set("strictQuery",true)连接数据库 mongoose.connect(mongodb:127.0.0.1:27017/test)设置回调 mongoose.connection.on(open,()>{console.log("连接成…...

边缘与云或边缘加云:前进的方向是什么?
边缘计算使数据处理更接近数据源,以及由此产生的行动或决策的对象。通过设计,它可以改变数十亿物联网和其他设备存储、处理、分析和通信数据的方式。 边缘计算使数据处理更接近数据源,以及由此产生的行动或决策的对象。这与传统的体系结构形成…...

从六度空间到毫秒响应:HNSW图索引如何重塑向量检索
1. 从六度分隔到高维空间:HNSW的思想起源 1967年,社会心理学家斯坦利米尔格拉姆通过著名的"小世界实验"提出了六度分隔理论——地球上任意两个人之间平均只需要5-6个中间人就能建立联系。这个看似简单的社会学发现,却在半个世纪后成…...

AI教材生成神器来袭!低查重工具一键搞定30万字教材编写!
利用 AI 工具高效编写教材 整理教材的知识点真的需要“精雕细琢”,最难的地方在于平衡与衔接!我们要么会担忧重要的知识点遗漏,要么又很难掌握合适的难度梯度。小学教材常常内容晦涩难懂,学生们难以理解;而高中教材往…...

腾讯 Marvis 操作系统层 AI 助手内测:多场景显身手,“AI 打工人”雏形初现但仍待打磨
多场景显身手近日,腾讯开始内测一款名为 Marvis(马维斯)的操作系统层个人 AI 助手。这一 AI 助手通过多个 Agent 的协作完成 App 操作、EXE 操作、电脑操作、文件管理、文档生成以及各种复杂任务,24 小时持续在线,并支…...

Arduino程序心脏:从setup初始化到loop循环的实战解析
1. Arduino程序的双引擎:setup与loop初探 第一次接触Arduino编程时,很多人会被它独特的程序结构所吸引。与传统编程不同,Arduino程序没有复杂的main函数入口,而是由两个看似简单的函数构成整个程序的骨架——这就是setup()和loop(…...

手持设备串口屏应用指南:从架构解析到实战开发
1. 项目概述:为什么手持设备需要一块“聪明”的屏幕?在手持设备这个领域摸爬滚打了十几年,从早期的黑白点阵屏到后来的TFT彩屏,再到如今各种智能交互界面,我深刻感受到一个趋势:设备越来越“聪明”…...

用HSPICE玩转CMOS反相器:手把手教你分析尺寸、延迟与功耗的权衡
用HSPICE玩转CMOS反相器:手把手教你分析尺寸、延迟与功耗的权衡 在集成电路设计的浩瀚宇宙中,CMOS反相器就像是一颗不起眼却至关重要的基础星体。作为数字电路中最简单的构建模块,它的性能表现直接影响着整个系统的运行效率。对于已经掌握HS…...

为什么你的Midjourney胶片图总像数码后期?——从光子散射模型到显影时间算法的底层差异解析
更多请点击: https://intelliparadigm.com 第一章:胶片质感的视觉直觉与认知偏差 胶片质感并非单纯的技术残留,而是一种经由人类视觉系统长期训练形成的感知锚点——它将颗粒噪点、色偏渐变、边缘晕影等非理想光学特征,编码为“真…...

Noto Emoji终极指南:3种策略彻底解决跨平台表情符号显示难题
Noto Emoji终极指南:3种策略彻底解决跨平台表情符号显示难题 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji Noto Emoji是Google开发的开源表情符号字体库,旨在为全球用户提供完整、一致…...

开源AI助手插件:为HuluNote笔记软件集成智能文本处理与知识管理
1. 项目概述:一个为HuluNote设计的开源AI助手最近在GitHub上看到一个挺有意思的项目,叫openclaw-hulunote-assistant。光看这个名字,可能很多人会有点懵,这到底是干嘛的?简单来说,这是一个专门为笔记应用Hu…...

深度解析DS4Windows:让PS4手柄在Windows平台重获新生
深度解析DS4Windows:让PS4手柄在Windows平台重获新生 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾经为PS4手柄在PC上的兼容性问题而烦恼?游戏无法识别、…...