实施工程师运维工程师面试题

Linux
1.请使用命令行拉取SFTP服务器/data/20221108/123.csv 文件,到本机一/data/20221108目录中。
使用命令行拉取SFTP服务器文件到本机指定目录,可以使用sftp命令。假设SFTP服务器的IP地址为192.168.1.100,用户名为username,密码为password,要拉取的文件路径为/data/20221108/123.csv,目标路径为本机/data/20221108目录中,可以执行以下命令:
bash
sftp username@192.168.1.100 -o password=password <<EOF
get /data/20221108/123.csv /data/20221108/
bye
EOF
其中,-o password=password指定密码,<<EOF和EOF之间的内容为sftp命令。
2.有一个备份程序mybackup,需要在周一至周五下午1点和晚上8点各运行一次,使用crontab来完成这项工作?
crontab -e
0 13 * * 1-5 mybackup
0 20 * * 1-5 mybackup
或者
crontab -e
0 13,20 1-5 mybackup
3.使用命令行查看linux服务器中,8080端口的占用情况
netstat -anp | grep 8080
或者
sudo lsof -i:8080
或者
netstat -tnlp | grep 8080
4.有一个java应用程序报错,报错信息为:“Caused by: MetaException(message:Filtering is supported only on partition keys of type string)”项目日志目录/app/bdmeth/QueryServer/logs/query.20221108.log如何查询报错的上下文信息。
grep "Caused by: MetaException(message:Filtering is supported only on partition keys of type string)" /app/bdmeth/QueryServer/logs/query.20221108.log
或者
grep -i "Caused by: MetaException" /app/bdmeth/QueryServer/logs/query.20221108.log
5、请简述linux服务器之间免密互信操作流程
第一步:生成密钥(包括公钥 id_rsa 和私钥 id_rsa.pub)
命令:ssh-keygen -t rsa
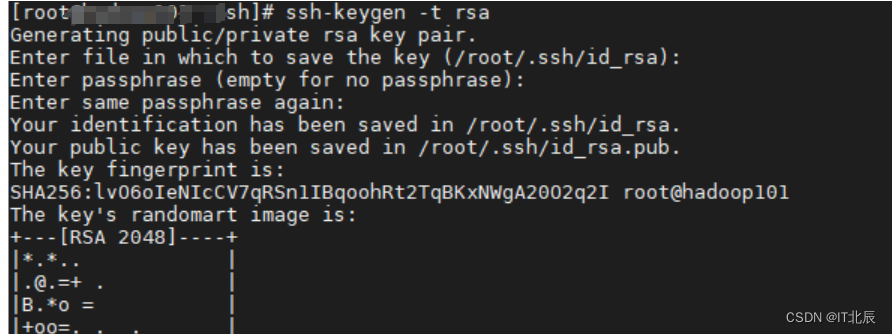
说明:
Enter file in which to save the key (/root/.ssh/id_rsa): 的意思是保存私钥的路径默认为
(/root/.ssh/id_rsa) 确定即可
Enter passphrase (empty for no passphrase): 给私钥加密, 默认为空
Enter same passphrase again: 确定上一步的密码
第二步:保存公钥到authorized_keys
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
可以继续输入命令:cat ~/.ssh/authorized_keys [进行查看公钥是否已经保存到这里]
此时继续输入命令:ssh hadoop101 [就能进行自连接]
说明:
这个authorized_key 文件夹本身是没有的 cat 过去就会有
那为什么要取这个名字 :系统认这个 。(暂时这么解释)
第三步:发送公钥到其他服务器
命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop102
输入命令:ssh hadoop102 [看看能不能连接]
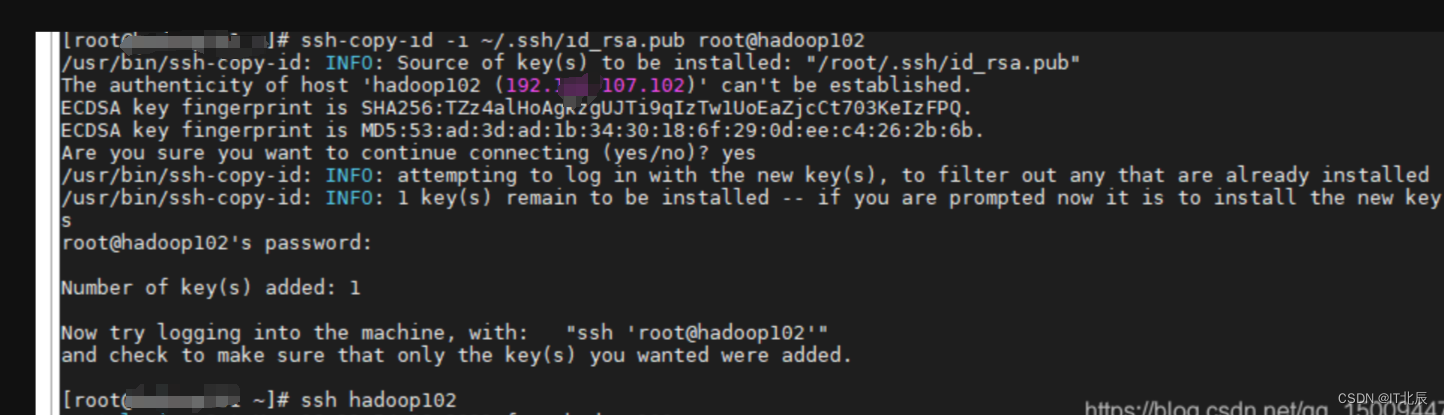
说明:
发送命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop102 的时候 在hadoop102服务器那边也会在家目录生成 .ssh/ authorized_keys
发送ssh hadoop102 请求的时候 会输入hadoop102的密码
后面再执行就不用输了
前三步实现了hadoop101的自连接 和 对 hadoop102的连接
第四步:hadoop102 进行自连接 和对 hadoop101的连接
命令:ssh-keygen -t rsa [生成hadoop102的公钥和私钥]
命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [保存公钥到authorized_keys,注意这边要用 >> 追加 而不能用 > 覆盖 因为 hadoop102 的authorized_keys 里面 已经有 第三步hadoop101发过来的公钥了 ]
输入命令: ssh hadoop102 [看看能不能自连]
输入命令:ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop101 [发送公钥到hadoop101的authorized_keys ,可以在hadoop101 服务器输入命令:cat ~/.ssh/authorized_keys 查看]
说明:
id_rsa // 私钥文件
id_rsa.pub // 公钥文件
authorized_keys // 存放客户端公钥的文件
known_hosts // 确认过公钥指纹的可信服务器列表的文件
以上几步完成了两个服务器之间的免密互连 多台之间的连接,也是差不多的 ,多台连接的本质还是两台两台连 。连接期间肯定会有很多异常和报错 要看清楚是什么原因 ,登录其他服务器之后 如果还要继续对本服务器操作的话 最好先exit 断开一下 操作比较干净。

二、SQL
1.编写一个SQL查询,查找Person表中所有重复的电子邮箱。
示例:
| Id | |
|---|---|
| 1 | apb.com |
| 2 | cod.com |
| 3 | apb.com |
根据以上输入,你的查询应返回议下结果
| apb.com |
说明:所有电子邮箱都是小写字母。
创建表:
CREATE TABLE `person` (`ID` int NOT NULL,`Email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,PRIMARY KEY (`ID`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;INSERT INTO `person` VALUES (1, 'apb.com');
INSERT INTO `person` VALUES (2, 'cod.com');
INSERT INTO `person` VALUES (3, 'apb.com');解决SQL:
SELECT Email
FROM Person
GROUP BY Email
HAVING COUNT(Email) > 1;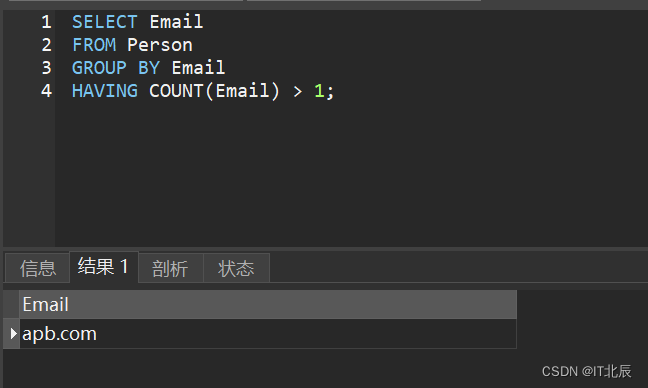
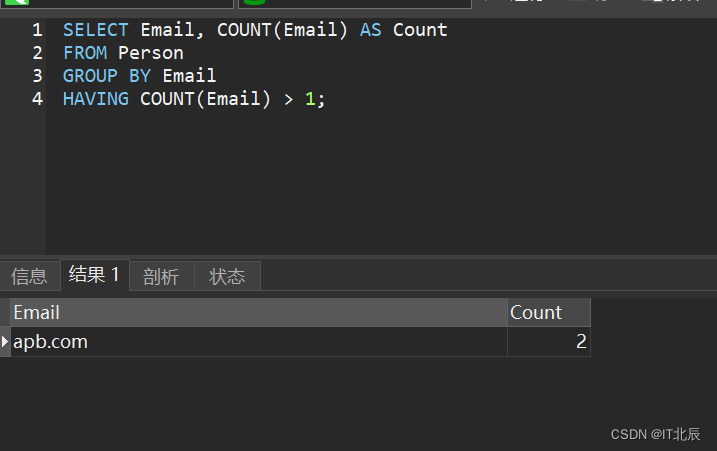
看一下统计数
SELECT Email, COUNT(Email) AS Count
FROM Person
GROUP BY Email
HAVING COUNT(Email) > 1;
2.编写 SQL 查询以查找每个部门中薪资最高的员工。按任意顺序返回结果表。
表:Employee
| 列名 | 类型 |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
id是此表的主键列。
departmentId是Department表中ID的外键。
此表的每一行都表示员工的ID、姓名和工资。它还包含他们所在部门的ID。
表:Department
| 列名 | 类型 |
|---|---|
| id | int |
| name | varchar |
id是此表的主键列。
此表的每一行都表示一个部门的ID及其名称。
CREATE TABLE Department ( id INT PRIMARY KEY, name VARCHAR(255)
);CREATE TABLE Employee ( id INT PRIMARY KEY, name VARCHAR(255), salary INT, departmentId INT, FOREIGN KEY (departmentId) REFERENCES Department(id)
);INSERT INTO Department (id, name) VALUES (1, 'Sales');
INSERT INTO Department (id, name) VALUES (2, 'Marketing');INSERT INTO Employee (id, name, salary, departmentId) VALUES (1, 'John Doe', 5000, 1);
INSERT INTO Employee (id, name, salary, departmentId) VALUES (2, 'Jane Smith', 6000, 1);
INSERT INTO Employee (id, name, salary, departmentId) VALUES (3, 'Mike Johnson', 5500, 2);
INSERT INTO Employee (id, name, salary, departmentId) VALUES (4, 'Emily Davis', 6500, 2)
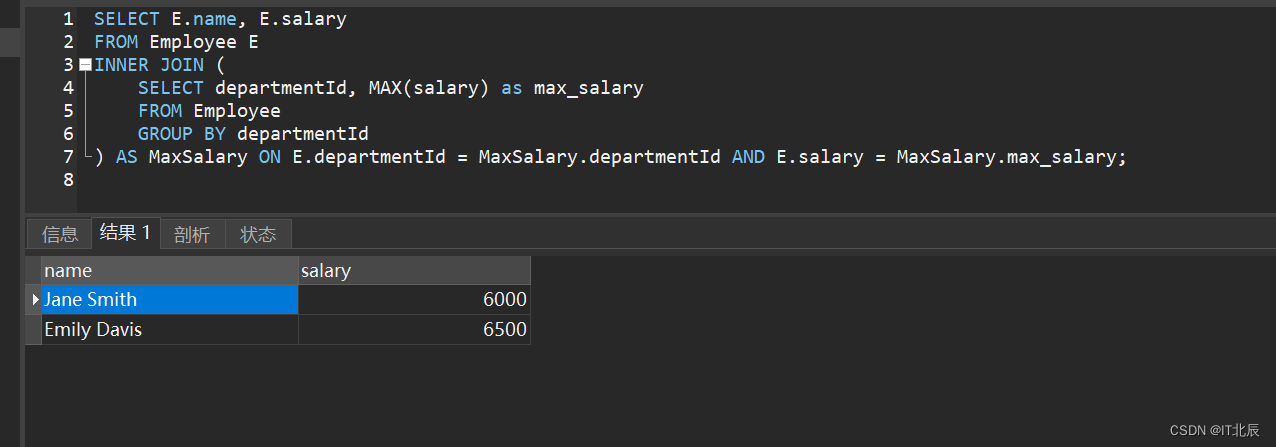
SELECT E.name, E.salary
FROM Employee E
INNER JOIN ( SELECT departmentId, MAX(salary) as max_salary FROM Employee GROUP BY departmentId
) AS MaxSalary ON E.departmentId = MaxSalary.departmentId AND E.salary = MaxSalary.max_salary;
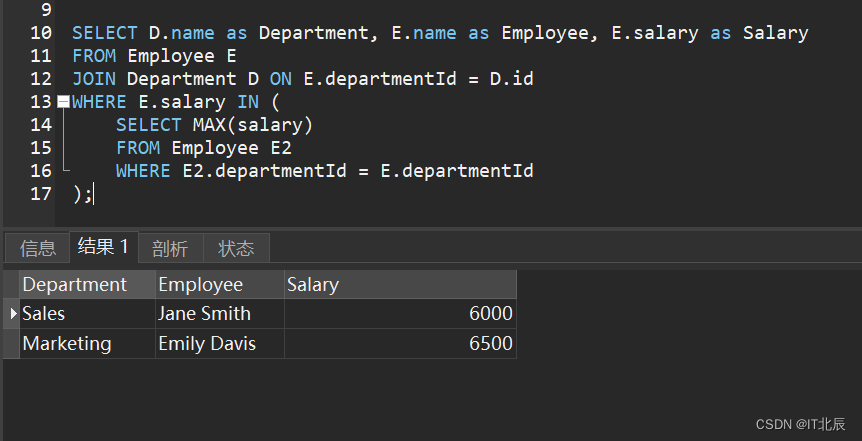
第二种:
SELECT D.name as Department, E.name as Employee, E.salary as Salary
FROM Employee E
JOIN Department D ON E.departmentId = D.id
WHERE E.salary IN (SELECT MAX(salary)FROM Employee E2WHERE E2.departmentId = E.departmentId
);解释:
SELECT D.name as Department, E.name as Employee, E.salary as Salary: 这一行表示我们想从查询结果中选择哪些字段。具体来说,我们想要获取Department的名称(别名为D.name),员工(别名为E.name)以及他们的工资(别名为E.salary)。FROM Employee E: 这一行说明我们将从名为Employee的表中开始查询,并为这个表设置了一个别名E。JOIN Department D ON E.departmentId = D.id: 这一行是一个JOIN操作,它用于将Employee表和Department表连接在一起。连接条件是员工表中的departmentId与部门表中的id相等。为Department表设置了一个别名D。WHERE E.salary IN ( ... ): 这一行是一个子查询,它筛选出工资最高的员工。子查询如下:SELECT MAX(salary) FROM Employee E2 WHERE E2.departmentId = E.departmentId: 这个子查询从Employee表中找出每个部门的最高工资。MAX(salary)会返回每个部门中最大的工资值。
总的来说,这个查询是为了找出每个部门中工资最高的员工及其工资。它首先通过子查询找出每个部门的最高工资,然后在主查询中根据这些最高工资值筛选出对应的员工信息。
相关文章:
实施工程师运维工程师面试题
Linux 1.请使用命令行拉取SFTP服务器/data/20221108/123.csv 文件,到本机一/data/20221108目录中。 使用命令行拉取SFTP服务器文件到本机指定目录,可以使用sftp命令。假设SFTP服务器的IP地址为192.168.1.100,用户名为username,密…...
6-13连接两个字符串
#include<stdio.h> int main(){int i0,j0;char s1[222],s2[333];printf("请输入第一个字符串:\n");gets(s1);//scanf("%s",s1);printf("请输入第二个字符串:\n");gets(s2);while(s1[i]!\0)i;while(s2[j]!\0)s1[i]s2…...
Linux中的文件IO
文章目录 C语言文件操作系统文件I/O接口介绍 open函数返回值文件描述符fd0 & 1 & 2文件描述符的分配规则 重定向使用 dup2 系统调用 FILE理解文件系统理解硬链接软链接acm 动态库和静态库静态库与动态库生成静态库生成动态库: C语言文件操作 先来段代码回顾…...

深度学习记录--初识向量化
什么是向量化? 之前计算logistic回归损失函数时,在代码实现时,讨论了for循环:过多的for循环会拖慢计算的速度(尤其当数据量很大时) 因此,为了加快计算,向量化是一种手段 运用python的numpy库,…...

树与二叉树堆:经典OJ题集(2)
目录 二叉树的性质及其问题: 二叉树的性质 问题: 一、对称的二叉树: 题目: 解题思路: 二、另一棵树: 题目: 解题思路: 三、翻转二叉树: 题目:…...
-------连载(40))
Java面试题(每天10题)-------连载(40)
目录 Mysql篇 1、表中有大字段X(例如:text类型),且字段X不会经常更新,将该字段拆成子表好处是什么? 2、Mysql中InnoDB引擎的行锁是通过加载什么上完成的? 3、Mysql中控制内存分配的全局参数…...

2023年【起重机司机(限桥式起重机)】报名考试及起重机司机(限桥式起重机)考试资料
题库来源:安全生产模拟考试一点通公众号小程序 2023年【起重机司机(限桥式起重机)】报名考试及起重机司机(限桥式起重机)考试资料,包含起重机司机(限桥式起重机)报名考试答案和解析及起重机司机(限桥式起重机)考试资料练习。安全生产模拟考试一点通结合…...
Linux的基本指令(3)
目录 制作小文件&查看 nano指令 cat指令 tac指令 制作大文件&查看 一切皆文件 echo指令 > 输出重定向 以写"w"的形式打开文件 以追加"a"的形式打开文件 cat指令 < 输入重定向 创建big.txt more指令 less指令(推…...

C语言memcpy,memmove的介绍及模拟实现
文章目录 每日一言memcpy介绍模拟实现 memmove介绍模拟实现思路代码 结语 每日一言 If you want to lift yourself up, lift up someone else. 如果你想振奋自己, 先振奋周遭的人。 memcpy 介绍 函数原型: void *memcpy(void *dest, const void *sr…...
克服.360勒索病毒:.360勒索病毒的解密和预防
导言: 在数字化的今天,数据安全问题变得愈发棘手。.360勒索病毒是当前网络空间的一场潜在灾难,对于这个威胁,了解应对之道和采取切实的预防措施至关重要。如果您正在经历勒索病毒的困境,欢迎联系我们的vx技术服务号(s…...

21、Resnet50 中包含哪些算法?
(本文已加入“计算机视觉入门与调优”专栏,点击专栏查看更多文章信息) 这一节汇总一下resnet50 中包含的算法,并且简单介绍。 总共卷积算法、激活算法(relu)、最大池化算法、加法(主要是为了实现残差结构)、全局平均池化、全连接和 softmax 算法这几种算法。 卷积 卷…...
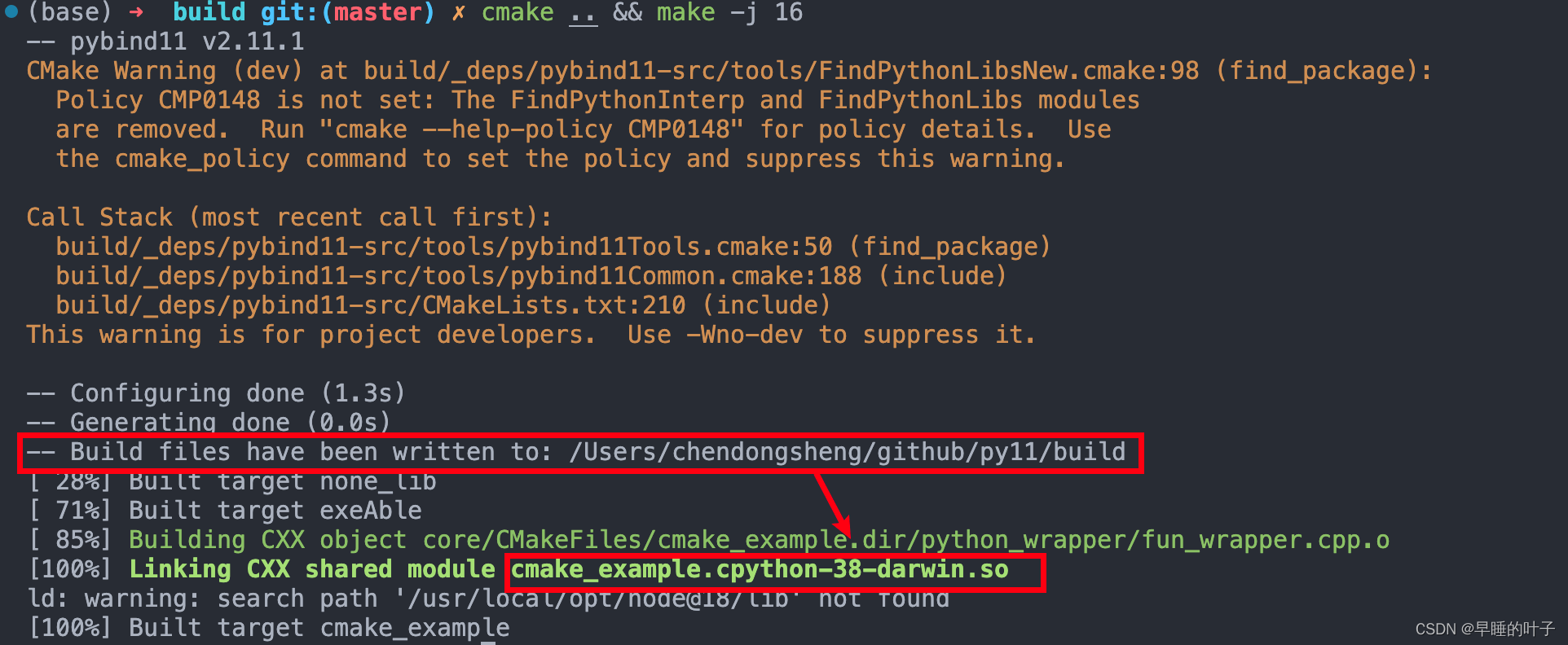
pybind11教程
pybind11教程 文章目录 pybind11教程1. pybind11简介2. cmake使用pybind11教程3. pybind11的历史 1. pybind11简介 项目的GitHub地址为: pybind11 pybind11 是一个轻量级的头文件库,用于在 Python 和 C 之间进行互操作。它允许 C 代码被 Python 调用&am…...

Java基础- 自定义类加载器
自定义类加载器 在 Java 中实现自定义类加载器通常涉及继承 ClassLoader 类并重写其 findClass 方法。自定义类加载器允许我们从非标准来源(如网络、加密文件或其他媒体)加载类。下面是实现自定义类加载器的基本步骤: 1. 继承 ClassLoader …...

2022年高校大数据挑战赛A题工业机械设备故障预测求解全过程论文及程序
2022年高校大数据挑战赛 A题 工业机械设备故障预测 原题再现: 制造业是国民经济的主体,近十年来,嫦娥探月、祝融探火、北斗组网,一大批重大标志性创新成果引领中国制造业不断攀上新高度。作为制造业的核心,机械设备在…...
洛谷 P1998 阶乘之和 C++代码
前言 今天我们来做洛谷上的一道题目。 网址:[NOIP1998 普及组] 阶乘之和 - 洛谷 西江月夜行黄沙道中 【宋】 辛弃疾 明月别枝惊鹊,清风半夜鸣蝉。稻花香里说丰年,听取WA声一片。 七八个星天外,两三点雨山前。旧时茅店社林边&…...
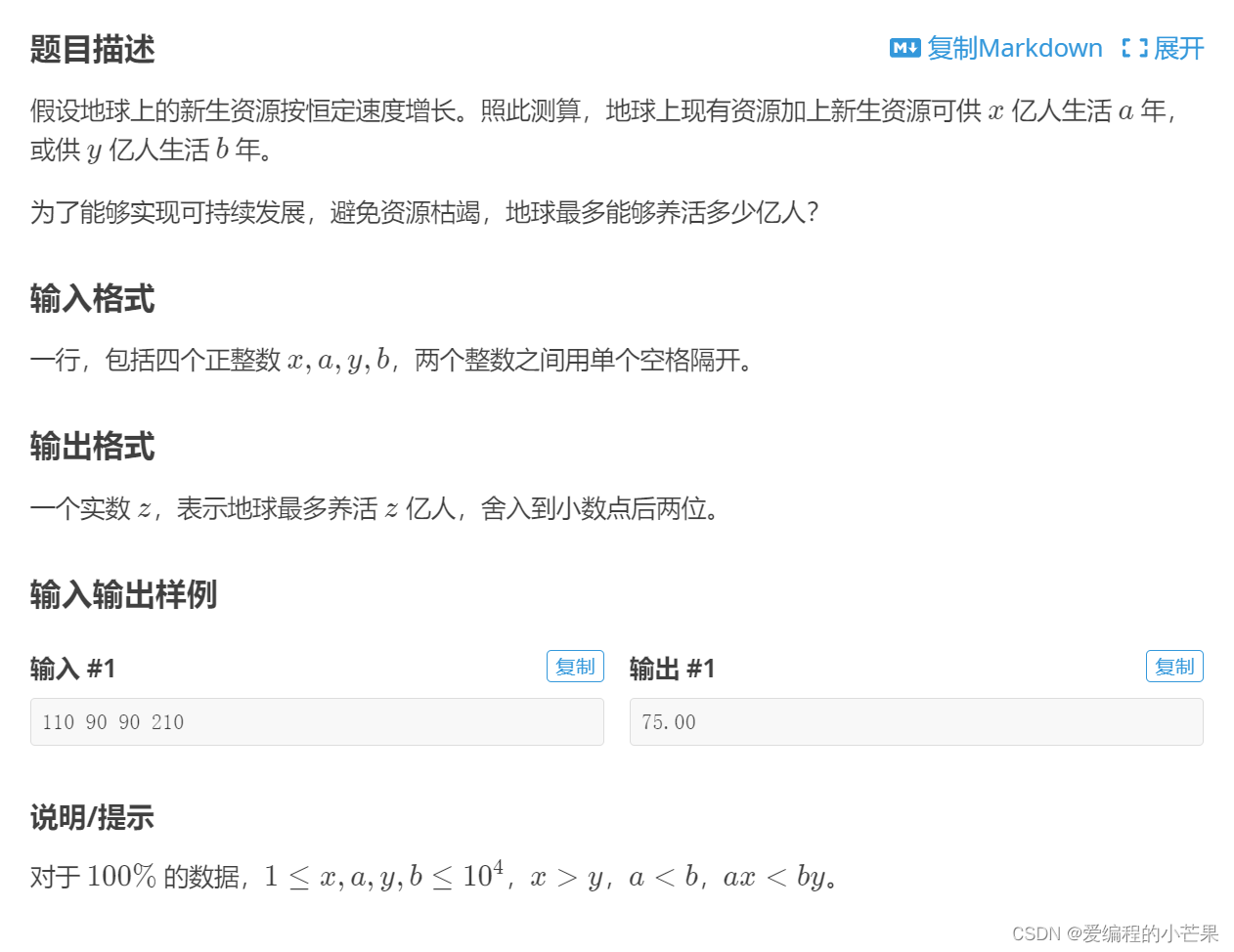
洛谷 B2006 地球人口承载力估计 C++代码
目录 前言 思路点拨 AC代码 结尾 前言 今天我们来做洛谷上的一道题目。 网址:地球人口承载力估计 - 洛谷 题目: 思路点拨 经典牛吃草问题。 解设一个人一年吃一份草。 则x*a-y*b为会多出的草,为什么会多呢?是因为每年都有…...

少走弯路:OpenCV、insightface 等多方案人脸推理和识别
脑壳有包又花时间折腾了一下,其实之前也折腾过,主要是新看了一个方法 在下图中查找脸部 第一种方案: 使用了opencv 的cv2.FaceDetectorYN. ,完整代码如下: import numpy as np import cv2imgcv2.imread("00000…...

github代码连接vercel 建立一个公用网站
Deploying to the Cloud using Vercel 前置任务 建立一个基于flask的web app代码库并上传至github repo Vercel用途 vercel有点像一个免费的cloud server,帮助你将flask框架下的程序运行在云端。可以public访问。 deploy流程 在主文件夹中建立requirements.tx…...

使用pandas将字符串格式数据转换为单独的行
有时在处理数据时,可能会遇到这样的情况,即数据框中的整个字符串条目需要拆分到不同的行中。这可能是一项具有挑战性的任务,特别是当数据庞大而复杂时。尽管如此,一个名为pandas的Python库提供了各种函数,使用这些函数…...
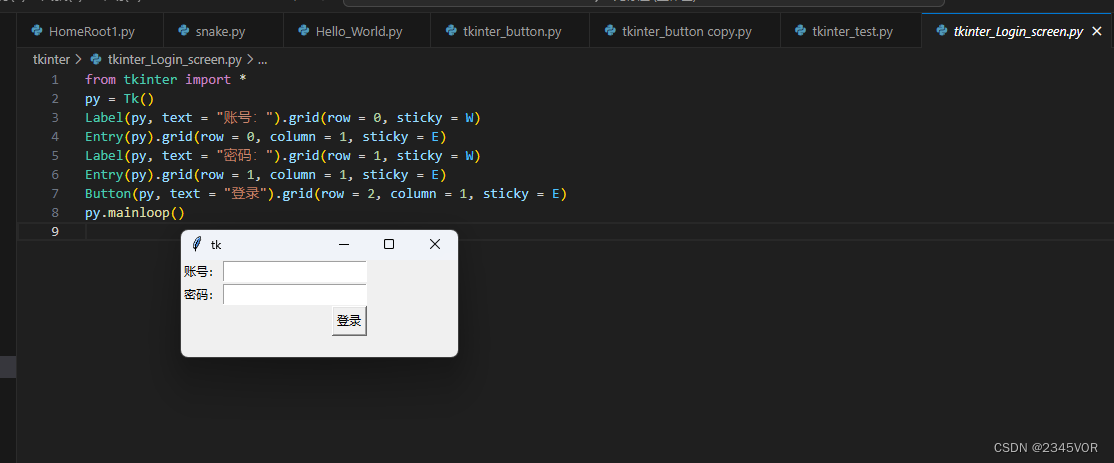
【Tkinter 入门教程】
【Tkinter 入门教程】 1. Tkinter库的简介:1.1 GUI编程1.2 Tkinter的定位 2. Hello word! 程序起飞2.1 第⼀个程序2.2 字体颜色主题 3. 组件讲解3.1 tkinter 的核⼼组件3.2 组件的使⽤3.3 标签Label3.3.1 标签显示内容3.3.2 多标签的应⽤程序3.3.3 总结 3.4 按钮but…...

Git多用户代理架构解析:实现细粒度权限管理与统一访问入口
1. 项目概述:从单兵作战到团队协作的代码管理跃迁如果你是一个独立开发者,或者在一个小团队里,你可能习惯了把代码往GitHub、Gitee这样的平台上一扔,设置个私有仓库,然后通过个人账号的SSH密钥来管理访问权限。这种方式…...

别再写for循环了!用Java8的groupingBy分组统计,5分钟搞定报表数据聚合
告别繁琐循环:Java8 groupingBy让数据聚合优雅如诗 当我们需要从数据库查询结果中生成各类业务报表时,那些重复的for循环是否已经让你感到厌倦?比如按地区统计销售额、按部门计算平均年龄,传统做法往往需要编写大量样板代码。而Ja…...

基于sagents框架的AI智能体开发:从核心原理到实战应用
1. 项目概述:一个面向开发者的AI智能体构建框架最近在AI应用开发圈子里,一个名为sagents的开源项目开始引起不少同行的注意。如果你正在寻找一个能帮你快速构建、测试和部署AI智能体(Agent)的框架,而不是从零开始造轮子…...

技术干货!!DeepSeek API 实战:从零到生产级的 Python 调用指南 — 流式、Function Calling、多轮对话、成本优化全覆盖
DeepSeek V3 的 API 性价比在 2026 年依然没有对手——同等能力价格只有 GPT-5.5 的 1/5。但翻了一圈中文技术社区,发现大多数「教程」只讲到第一段 chat.completions.create 就停了。生产环境真正需要的东西——流式输出怎么接、Function Calling 踩了什么坑、高并…...

基于Adafruit Trinket的光控互动玩具:嵌入式系统入门实战
1. 项目概述:给毛绒玩具注入灵魂几年前,我女儿的一个旧毛绒玩具被冷落在角落,除了偶尔被当作抱枕,几乎失去了“玩具”的活力。这让我萌生了一个想法:能不能用一些简单的电子元件,让这些静态的玩偶重新“活”…...

Kimi代码授权与自动化工具:逆向工程与协议模拟实践
1. 项目概述:一个面向Kimi的代码授权与自动化工具最近在GitHub上看到一个挺有意思的项目,叫FelipeOFF/openclaw-kimi-code-auth。光看名字,可能有点摸不着头脑,但如果你正在研究如何与Kimi这类大型语言模型进行更稳定、更自动化的…...

开发者技能图谱实战指南:从结构化知识到可执行代码的进阶之路
1. 项目概述:一个面向开发者的技能图谱与实战仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫GuDaStudio/skills。乍一看名字,你可能会觉得这又是一个普通的“技能清单”或者“学习路线图”项目。但点进去仔细研究后…...

VSCode性能优化实战:回归轻量编辑器,提升开发效率
1. 项目概述:为什么我们需要一个“经典体验”的VSCode? 如果你是一个从Sublime Text、Notepad或者更早的编辑器时代走过来的开发者,最近打开Visual Studio Code时,可能会感到一丝陌生。没错,VSCode变得越来越强大&…...

构建AI智能体安全护栏:AgentGuard多层防护架构与工程实践
1. 项目概述:构建AI应用的安全护栏最近在部署和调试一些基于大语言模型(LLM)的智能体(Agent)应用时,我遇到了一个挺头疼的问题:这些应用在自由发挥时,偶尔会“说错话”或者“做错事”…...

2026 断桥铝系统门窗选购指南:品牌综合实力榜与技术选型要点
2026 断桥铝系统门窗选购指南:品牌综合实力榜与技术选型要点行业发展背景与产品技术迭代中国住宅装饰装修产业正向品质化、精细化与绿色化深度转型,居住者对建筑外围护结构的综合性能要求持续攀升。传统非系统化断桥铝门窗因结构设计单一、性能指标离散、…...