oneApi实现并⾏排序算法
零、OneApi简介
oneAPI是由英特尔推出的一个开放、统一的编程模型和工具集合,旨在简化跨不同硬件架构的并行计算。oneAPI的目标是提供一个统一的编程模型,使开发人员能够使用相同的代码在不同类型的硬件上进行并行计算,包括CPU、GPU、FPGA和其他加速器。
oneAPI的核心理念是使用标准的C++编程语言和库来实现并行计算,而不需要特定于硬件的编程语言或库。通过oneAPI,开发人员可以利用硬件加速器的性能优势,同时保持代码的可移植性和可维护性。
oneAPI提供了一系列的工具和库,包括DPC++编程语言、oneDNN深度学习库、oneMKL数学库等,这些工具和库可以帮助开发人员更轻松地实现并行计算和加速应用程序的性能。
总的来说,oneAPI旨在简化并行计算的开发,并提供一种统一的编程模型,使开发人员能够更好地利用不同类型硬件的性能优势。通过使用oneAPI,开发人员可以更高效地开发并行应用程序,并在不同硬件上实现更好的性能和可移植性。
一、oneApi入门教程
1.1oneApi的简单使用
以下是一个简单的oneAPI入门教程,介绍如何使用oneAPI进行向量加法操作。
-
安装oneAPI:首先,需要安装oneAPI工具包。可以从英特尔官方网站上下载适用于操作系统的oneAPI工具包,并按照说明进行安装。
-
创建一个新的C++项目:使用喜欢的集成开发环境(IDE)或文本编辑器创建一个新的C++项目。
-
包含头文件:在C++源文件中,包含以下头文件:
#include <CL/sycl.hpp>
#include <iostream>
- 使用命名空间:在源文件中使用SYCL命名空间,以便使用SYCL的功能:
namespace sycl = cl::sycl;
- 定义向量加法内核:在main函数之前,定义一个SYCL内核函数,用于执行向量加法操作。例如,以下是一个简单的向量加法内核函数:
class vector_addition {
public:void operator()(sycl::id<1> idx, sycl::accessor<int, 1, sycl::access::mode::read_write> a,sycl::accessor<int, 1, sycl::access::mode::read_write> b,sycl::accessor<int, 1, sycl::access::mode::read_write> c) {c[idx] = a[idx] + b[idx];}
};
- 编写主函数:在main函数中,首先创建一个SYCL队列对象,用于选择并管理设备。然后,创建输入向量a和b,并创建输出向量c。接下来,使用queue.submit()函数提交一个命令组,其中包含向量加法操作。最后,使用queue.wait()函数等待命令组完成,并从设备端读取结果。
int main() {// 创建一个SYCL队列对象sycl::queue queue(sycl::default_selector{});// 定义输入向量a和bstd::vector<int> a = {1, 2, 3, 4, 5};std::vector<int> b = {6, 7, 8, 9, 10};// 创建输出向量cstd::vector<int> c(a.size());// 创建缓冲区sycl::buffer<int, 1> bufA(a.data(), sycl::range<1>(a.size()));sycl::buffer<int, 1> bufB(b.data(), sycl::range<1>(b.size()));sycl::buffer<int, 1> bufC(c.data(), sycl::range<1>(c.size()));// 提交命令组queue.submit([&](sycl::handler& cgh) {auto accessorA = bufA.get_access<sycl::access::mode::read>(cgh);auto accessorB = bufB.get_access<sycl::access::mode::read>(cgh);auto accessorC = bufC.get_access<sycl::access::mode::write>(cgh);cgh.parallel_for<class vector_addition>(sycl::range<1>(a.size()), [=](sycl::id<1> idx) {vector_addition()(idx, accessorA, accessorB, accessorC);});});// 等待命令组完成queue.wait();// 从设备端读取结果auto result = bufC.get_access<sycl::access::mode::read>();// 输出结果for (int i = 0; i < c.size(); i++) {std::cout << result[i] << " ";}std::cout << std::endl;return 0;
}
- 编译和运行:使用适当的编译器将代码编译为可执行文件,并运行程序。应该会看到输出结果为"7 9 11 13 15",这是输入向量a和b的对应元素相加的结果。
1.2并行运算教程
以下是一个简单的并行计算入门教程,介绍如何使用SYCL编程模型进行向量加法的并行运算。
1. 创建一个新的C++项目:使用喜欢的集成开发环境(IDE)或文本编辑器创建一个新的C++项目。
2. C++源文件中,包含以下头文件:
#include <CL/sycl.hpp>
#include <iostream>
3. 使用命名空间:在源文件中使用SYCL命名空间,以便使用SYCL的功能:
namespace sycl = cl::sycl;
4. 定义并行计算内核:在main函数之前,定义一个SYCL内核函数,用于执行并行计算操作。例如,以下是一个简单的向量加法并行计算内核函数:
class vector_addition {
public:void operator()(sycl::nd_item<1> item, sycl::accessor<int, 1, sycl::access::mode::read_write> a,sycl::accessor<int, 1, sycl::access::mode::read_write> b,sycl::accessor<int, 1, sycl::access::mode::read_write> c) {int idx = item.get_global_id(0);c[idx] = a[idx] + b[idx];}
};
5.编写主函数:在main函数中,首先创建一个SYCL队列对象,用于选择并管理设备。然后,创建输入向量a和b,并创建输出向量c。接下来,使用queue.submit()函数提交一个命令组,其中包含并行计算操作。最后,使用queue.wait()函数等待命令组完成,并从设备端读取结果。
int main() {// 创建一个SYCL队列对象sycl::queue queue(sycl::default_selector{});// 定义输入向量a和bstd::vector<int> a = {1, 2, 3, 4, 5};std::vector<int> b = {6, 7, 8, 9, 10};// 创建输出向量cstd::vector<int> c(a.size());// 创建缓冲区sycl::buffer<int, 1> bufA(a.data(), sycl::range<1>(a.size()));sycl::buffer<int, 1> bufB(b.data(), sycl::range<1>(b.size()));sycl::buffer<int, 1> bufC(c.data(), sycl::range<1>(c.size()));// 提交命令组queue.submit([&](sycl::handler& cgh) {auto accessorA = bufA.get_access<sycl::access::mode::read>(cgh);auto accessorB = bufB.get_access<sycl::access::mode::read>(cgh);auto accessorC = bufC.get_access<sycl::access::mode::write>(cgh);cgh.parallel_for<class vector_addition>(sycl::range<1>(a.size()), [=](sycl::nd_item<1> item) {vector_addition()(item, accessorA, accessorB, accessorC);});});// 等待命令组完成queue.wait();// 从设备端读取结果auto result = bufC.get_access<sycl::access::mode::read>();// 输出结果for (int i = 0; i < c.size(); i++) {std::cout << result[i] << " ";}std::cout << std::endl;return 0;
}
6.编译和运行:使用适当的编译器将代码编译为可执行文件,并运行程序。应该会看到输出结果为"7 9 11 13 15",这是输入向量a和b的对应元素相加的结果。
这只是一个简单的并行计算入门教程,介绍了如何使用SYCL编程模型进行向量加法的并行运算。通过学习和实践,可以进一步探索并行计算的概念和技术,并在不同类型的硬件上实现更复杂的并行算法和应用程序。
二、并⾏排序算法题目描述
2.1题目描述:描述
使用基于oneAPI的C++/SYCL实现⼀个高效的并行归并排序。需要考虑数据的分割和合并以及线程之间的协作。
2.2分析&示例
归并排序是⼀种分治算法,其基本原理是将待排序的数组分成两部分,分别对这两部分进行排序,然后将已排
序的子数组合并为⼀个有序数组。可考虑利用了异构并行计算的特点,将排序和合并操作分配给多个线程同时
执行,以提高排序效率。具体实现过程如下:
-
将待排序的数组分割成多个较小的子数组,并将这些⼦数组分配给不同的线程块进行处理。
-
每个线程块内部的线程协作完成子数组的局部排序。
-
通过多次迭代,不断合并相邻的有序⼦数组,直到整个数组有序。
在实际实现中,归并排序可使用共享内存来加速排序过程。具体来说,可以利用共享内存来存储临时数据,减
少对全局内存的访问次数,从而提高排序的效率。另外,在合并操作中,需要考虑同步机制来保证多个线程之
间的数据⼀致性。
需要注意的是,在实际应用中,要考虑到数组大小、线程块大小、数据访问模式等因素,来设计合适的算法和
参数设置,以充分利用目标计算硬件GPU的并行计算能力,提高排序的效率和性能。
2.3实现方案
首先,代码包含了一些必要的头文件,并引入了SYCL命名空间。
接下来,定义了归并排序的合并操作函数merge()和递归操作函数mergeSort()。merge()函数用于将两个有序数组合并为一个有序数组,mergeSort()函数用于递归地对数组进行归并排序。
在main()函数中,首先定义了一个vector来存储待排序的浮点数数据,并从文件中读取数据。
然后,通过创建一个SYCL队列对象queue来选择默认的设备,并使用sycl::buffer来创建一个缓冲区来存储待排序的数组。
接下来,使用queue.submit()函数提交一个命令组。在命令组中,首先通过buf.get_access()函数获取对缓冲区的访问权限,并在设备上进行归并排序。使用cgh.parallel_for()函数来指定并行执行的范围和操作。
最后,使用queue.wait()函数等待命令组完成,并通过buf.get_access()函数从设备端读取排序后的数组。
最后,使用for循环遍历输出排序后的数组。
如果在执行过程中捕获到SYCL异常,将输出异常信息并返回1。
最后,返回0表示程序正常结束。
2.4代码实现
#include <CL/sycl.hpp>
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>namespace sycl = cl::sycl;// 归并排序的合并操作
template<typename T>
void merge(T* arr, size_t left, size_t mid, size_t right) {size_t i = left;size_t j = mid + 1;std::vector<T> temp(right - left + 1);size_t k = 0;while (i <= mid && j <= right) {if (arr[i] <= arr[j]) {temp[k++] = arr[i++];} else {temp[k++] = arr[j++];}}while (i <= mid) {temp[k++] = arr[i++];}while (j <= right) {temp[k++] = arr[j++];}for (size_t p = 0; p < k; ++p) {arr[left + p] = temp[p];}
}// 归并排序的递归操作
template<typename T>
void mergeSort(T* arr, size_t left, size_t right) {if (left < right) {size_t mid = left + (right - left) / 2;mergeSort(arr, left, mid);mergeSort(arr, mid + 1, right);merge(arr, left, mid, right);}
}int main() {std::vector<float> data;// 从文件中读取浮点数数据std::ifstream file("input.txt");float value;while (file >> value) {data.push_back(value);}try {sycl::queue queue(sycl::default_selector{});// 创建缓冲区来存储待排序的数组sycl::buffer<float, 1> buf(data.data(), sycl::range<1>(data.size()));// 提交命令组queue.submit([&](sycl::handler& cgh) {auto acc = buf.get_access<sycl::access::mode::read_write>(cgh);// 在设备上进行归并排序cgh.parallel_for<class merge_sort>(sycl::range<1>(data.size()), [=](sycl::id<1> idx) {size_t i = idx[0];size_t left = i * (data.size() / sycl::max_compute_units(queue.get_device()));size_t right = (i + 1) * (data.size() / sycl::max_compute_units(queue.get_device())) - 1;mergeSort(acc.get_pointer(), left, right);});});// 等待命令组完成queue.wait();// 从设备端读取排序后的数组std::vector<float> result = buf.get_access<sycl::access::mode::read>();// 输出排序后的数据for (size_t i = 0; i < data.size(); ++i) {std::cout << result[i] << " ";}std::cout << std::endl;} catch (sycl::exception& e) {std::cerr << "SYCL exception caught: " << e.what() << std::endl;return 1;}return 0;
}
三、收获与总结
通过编写并行排序算法,学到了以下与oneAPI相关的知识:
-
SYCL编程模型:oneAPI基于SYCL(异构计算接口语言)编程模型,能够在不同类型的硬件上实现并行计算。通过编写并行排序算法,了解了如何使用SYCL的功能和语法,例如内核函数、命名空间和访问器。
-
数据并行性:并行排序算法涉及将输入数据分配给不同的处理单元,并在并行执行的内核函数中对数据进行处理。使我解如何利用数据并行性来提高算法的性能,并充分利用多个计算单元。
-
内存管理:在并行排序算法中,需要管理输入和输出数据的内存。oneAPI提供了缓冲区(buffer)和访问器(accessor)的概念,用于在主机和设备之间传输数据。通过编写并行排序算法,学习如何创建和使用缓冲区和访问器来实现数据的高效传输和访问。
-
设备选择和任务调度:oneAPI允许选择适合的硬件的设备,并使用队列(queue)来管理和调度任务。通过编写并行排序算法,了解如何选择设备、创建队列,并使用队列的submit和wait函数来提交和等待任务的完成。
-
性能优化:并行排序算法是一个常见的性能优化问题。通过使用oneAPI,可以利用并行计算和硬件加速来提高排序算法的性能。可以尝试不同的优化技术,如工作组大小的调整、局部内存的使用和向量化指令的应用,以进一步提高算法的性能。
通过编写并行排序算法,我获得关于oneAPI的实际经验,并学习如何在不同类型的硬件上实现高效的并行计算。这将使我能够更好地理解和应用oneAPI的功能和优势,并在其他并行计算问题上应用这些知识。
相关文章:

oneApi实现并⾏排序算法
零、OneApi简介 oneAPI是由英特尔推出的一个开放、统一的编程模型和工具集合,旨在简化跨不同硬件架构的并行计算。oneAPI的目标是提供一个统一的编程模型,使开发人员能够使用相同的代码在不同类型的硬件上进行并行计算,包括CPU、GPU、FPGA和…...

语音芯片的BUSY状态指示功能特征:提升用户体验与系统稳定性的关键
在电子产品的音频系统中,语音芯片扮演着至关重要的角色。为了保证音频的流畅播放和功能的正常运行,语音芯片的各种状态指示功能变得尤为重要。其中,BUSY状态指示功能是语音芯片中的一项关键特征,它对于提升用户体验和系统稳定性具…...
Leetcode2661. 找出叠涂元素
Every day a Leetcode 题目来源:2661. 找出叠涂元素 解法1:哈希 题目很绕,理解题意后就很简单。 由于矩阵 mat 中每一个元素都不同,并且都在数组 arr 中,所以首先我们用一个哈希表 hash 来存储 mat 中每一个元素的…...

免费最新6款热门SEO优化排名工具
网站的存在感对于业务和品牌的成功至关重要。在众多网站推广方法中,搜索引擎优化(SEO)是提高网站可见性的关键。而SEO的核心之一就是关键词排名。为了更好地帮助您优化网站。 SEO关键词排名工具 在如今信息过载的互联网时代,用户…...
绝地求生在steam叫什么?
绝地求生在Steam的全名是《PlayerUnknowns Battlegrounds》,简称为PUBG。作为一款风靡全球的多人在线游戏,PUBG于2017年3月23日正式上线Steam平台,并迅速成为一部热门游戏。 PUBG以生存竞技为核心玩法,玩家将被投放到一个辽阔的荒…...
Elasticsearch:什么是大语言模型(LLM)?
大语言模型定义 大语言模型 (LLM) 是一种深度学习算法,可以执行各种自然语言处理 (natural language processing - NLP) 任务。 大型语言模型使用 Transformer 模型,并使用大量数据集进行训练 —— 因此规模很大。 这使他们能够识别、翻译、预测或生成文…...
Kubernetes1.27容器化部署Prometheus
Kubernetes1.27容器化部署Prometheus GitHub链接根据自己的k8s版本选择对应的版本修改镜像地址部署命令对Etcd集群进行监控(云原生监控)创建Etcd Service创建Etcd证书的Secret创建Etcd ServiceMonitorgrafana导入模板成功截图 对MySQL进行监控࿰…...

fasterxml 注解组装实体
使用 FasterXML Jackson 的注解 JsonTypeInfo 和 JsonSubTypes 可以实现多态类型的处理。在你的 User 类上,你可以添加这些注解来指示 Jackson 如何处理多态类型。 以下是使用 JsonTypeInfo 和 JsonSubTypes 注解的 User 类的修改: import com.fasterx…...

自写一个函数将js对象转为Ts的Interface接口
如今的前端开发typescript 已经成为一项必不可以少的技能了,但是频繁的定义Interface接口会给我带来许多工作量,我想了想如何来减少这些非必要且费时的工作量呢,于是决定写一个函数,将对象放进它自动帮我们转换成Interface接口&am…...

【数据结构】拆分详解 - 二叉树的链式存储结构
文章目录 一、前置说明二、二叉树的遍历 1. 前序、中序以及后序遍历 1.1 前序遍历 1.2 中序遍历 1.3 后序遍历 2. 层序遍历 三、常见接口实现 0. 递归中的分治思想 1. 查找与节点个数 1.1 节点个数 1.2 叶子节点个数 1.3 第k层节…...
验证)
Laravel修改默认的auth模块为md5(password+salt)验证
首先声明:这里只是作为一个记录,实行拿来主义,懒得去记录那些分析源码的过程,不喜勿喷,可直接划走。 第一步:创建文件夹:app/Helpers/Hasher; 第二步:创建文件: app/Help…...

OpenStack-train版安装之安装Keystone(认证服务)、Glance(镜像服务)、Placement
安装Keystone(认证服务)、Glance(镜像服务)、Placement 安装Keystone(认证服务)安装Glance(镜像服务)安装Placement 安装Keystone(认证服务) 数据库创建、创…...

【九日集训】第九天:简单递归
递归就是自己调用自己,例如斐波那契数列就是可以用简单递归来实现。 第一题 172. 阶乘后的零 https://leetcode.cn/problems/factorial-trailing-zeroes/description/ 这一题纯粹考数学推理能力,我这种菜鸡看了好久都没有懂。 大概是这样的思路&#x…...
Prime 1.0
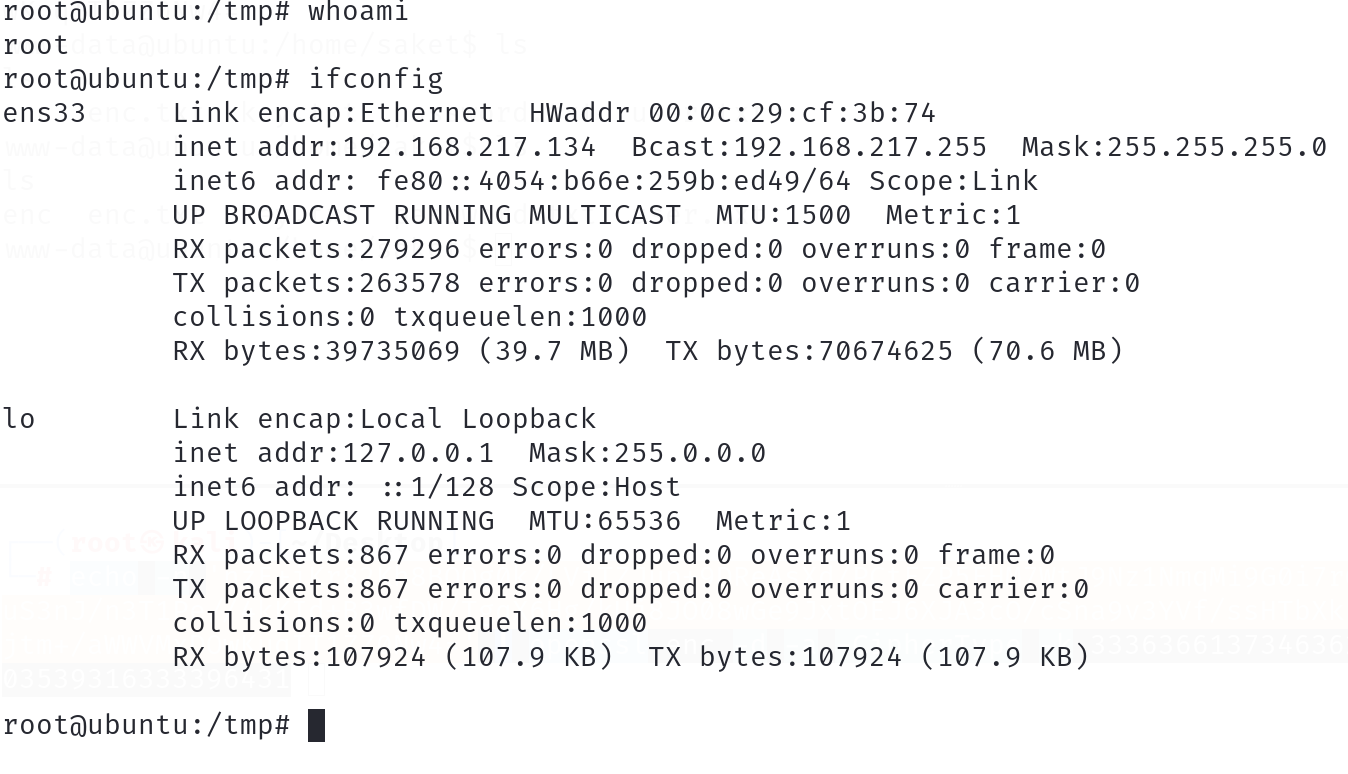
信息收集 存活主机探测 arp-scan -l 或者利用nmap nmap -sT --min-rate 10000 192.168.217.133 -oA ./hosts 可以看到存活主机IP地址为:192.168.217.134 端口探测 nmap -sT -p- 192.168.217.134 -oA ./ports UDP端口探测 详细服务等信息探测 开放端口22&#x…...

Java 如何正确比较两个浮点数
看下面这段代码,将 d1 和 d2 两个浮点数进行比较,输出的结果会是什么? double d1 .1 * 3; double d2 .3; System.out.println(d1 d2);按照正常逻辑来看,d1 经过计算之后的结果应该是 0.3,最后打印的结果应该是 tru…...
Qt 如何操作SQLite3数据库?数据库创建和表格的增删改查?
# 前言 项目源码下载 https://gitcode.com/m0_45463480/QSQLite3/tree/main # 第一步 项目配置 平台:windows10 Qt版本:Qt 5.14.2 在.pro添加 QT += sql 需要的头文件 #include <QSqlDatabase>#include <QSqlError>#include <QSqlQuery>#include &…...
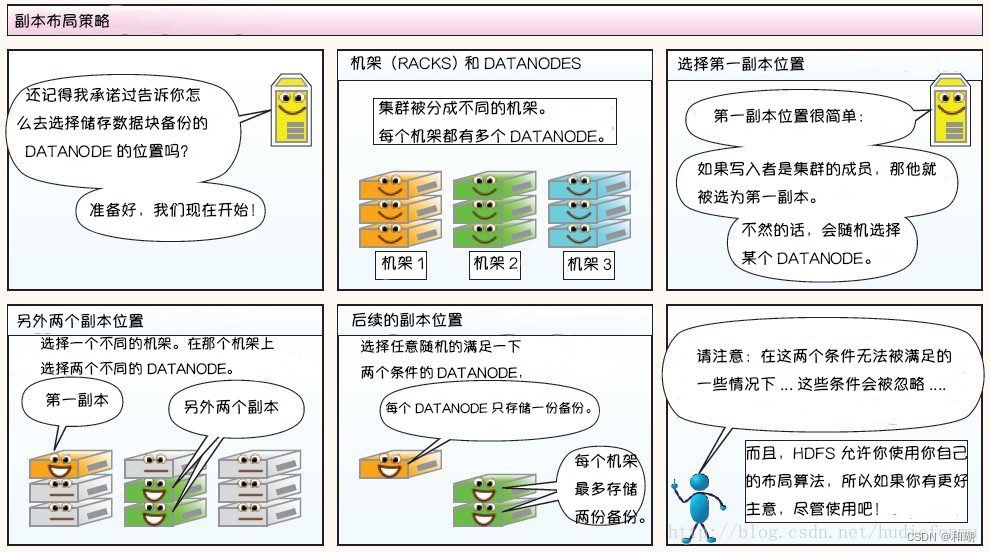
【Hadoop】分布式文件系统 HDFS
目录 一、介绍二、HDFS设计原理2.1 HDFS 架构2.2 数据复制复制的实现原理 三、HDFS的特点四、图解HDFS存储原理1. 写过程2. 读过程3. HDFS故障类型和其检测方法故障类型和其检测方法读写故障的处理DataNode 故障处理副本布局策略 一、介绍 HDFS (Hadoop Distribute…...

【Python-随笔】使用Python实现屏幕截图
使用Python实现屏幕截图 环境配置 下载pyautogui包 pip install pyautogui -i https://pypi.tuna.tsinghua.edu.cn/simple/下载OpenCV包 pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple/下载PyQT5包 pip install PyQt5 -i https://pypi.tuna.tsi…...

Sun Apr 16 00:00:00 CST 2023格式转换
Date date new Date(); log.info("当前时间为:{}",date); //yyyy-MM-dd HH:mm:ss SimpleDateFormat sdf new SimpleDateFormat(DateUtils.YYYY_MM_DD_HH_MM_SS); String dateTime s…...

使用mongodb实现简单的读写操作
本文适合初学者,特别是刚刚安装了mongodb数据库的朋友,或在atlas刚拿到免费集群的朋友。 拿到数据库,心情很激动,手痒难耐。特别想向数据库插入几条数据库试试。即使是深夜完成了安装,也忍不住想去完成这些操作。看到…...

通过环境变量管理多个 Taotoken API Key 以实现访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过环境变量管理多个 Taotoken API Key 以实现访问控制 在开发过程中,我们常常需要为不同的应用、不同的环境…...

终极指南:如何在Windows电脑上实现AirPlay 2无线投屏功能
终极指南:如何在Windows电脑上实现AirPlay 2无线投屏功能 【免费下载链接】airplay2-win Airplay2 for windows 项目地址: https://gitcode.com/gh_mirrors/ai/airplay2-win 还在为Windows电脑无法接收iPhone、iPad或Mac的屏幕镜像而烦恼吗?Airpl…...

如何让Windows资源管理器完美预览iPhone照片:HEIC缩略图插件全解析
如何让Windows资源管理器完美预览iPhone照片:HEIC缩略图插件全解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你…...

从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库
从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com…...

古典戏曲研究新范式,NotebookLM+《牡丹亭》原始刻本实测:自动生成曲牌-情感-舞台调度三维映射表
更多请点击: https://intelliparadigm.com 第一章:NotebookLM戏剧研究辅助的范式革命 传统戏剧研究长期依赖人工文本细读、跨剧目比对与历史语境重建,耗时冗长且易受主观经验局限。NotebookLM 的引入,标志着从“线性阅读—笔记摘…...

深入解析Enso:构建高性能可编程代理与API网关的Go框架
1. 项目概述:一个被低估的“瑞士军刀”如果你在开源社区里混迹过一段时间,大概率见过这样的场景:一个项目仓库,名字起得挺酷,比如“Enso”,简介里写着“一个现代化的代理工具”,但点进去一看&am…...

终极指南:在Windows上直接安装安卓APK的3大优势与6个实用技巧
终极指南:在Windows上直接安装安卓APK的3大优势与6个实用技巧 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK Installer是一款专为Windows系统设计的安…...

【多智能体】基于matlab多智能体多视角三维空间定位的神经动力学方法【含Matlab源码 15447期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

B站视频解析API架构解析:PHP实现的高效视频流获取方案
B站视频解析API架构解析:PHP实现的高效视频流获取方案 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 在视频内容生态蓬勃发展的今天,开发者经常面临一个技术挑战:…...

Dify工作流实战指南:零代码构建企业级应用系统的终极方案
Dify工作流实战指南:零代码构建企业级应用系统的终极方案 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Di…...