[GPT-1]论文实现:Improving Language Understanding by Generative Pre-Training
Efficient Graph-Based Image Segmentation
- 一、完整代码
- 二、论文解读
- 2.1 GPT架构
- 2.2 GPT的训练方式
- Unsupervised pre_training
- Supervised fine_training
- 三、过程实现
- 3.1 导包
- 3.2 数据处理
- 3.3 模型构建
- 3.4 模型配置
- 四、整体总结
论文:Improving Language Understanding by Generative Pre-Training
作者:Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever
时间:2018
一、完整代码
这里我们使用tensorflow代码进行实现
# 完整代码在这里
import tensorflow as tf
import keras_nlp
import jsondef get_merges():with open('./data/GPT_merges.txt') as f:merges = f.read().split('\n')return mergesmerges = get_merges()
vocabulary = json.load(open('./data/GPT_vocab.json'))tokenizer = keras_nlp.tokenizers.BytePairTokenizer(vocabulary=vocabulary,merges=merges
)pad = tokenizer.vocabulary_size()
start = tokenizer.vocabulary_size() + 1
end = tokenizer.vocabulary_size() + 2corpus = open('./data/shakespeare.txt').read()
data = tokenizer(corpus)
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(63, drop_remainder=True)
def process_data(x):x = tf.concat([tf.constant(start)[tf.newaxis], x, tf.constant(end)[tf.newaxis]], axis=-1)return x[:-1], x[1:]dataset = dataset.map(process_data).batch(16)inputs, outputs = dataset.take(1).get_single_element()class GPT(tf.keras.Model):def __init__(self, vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads, dropout=0.1):super().__init__()self.embedding = keras_nlp.layers.TokenAndPositionEmbedding(vocabulary_size=vocabulary_size,sequence_length=sequence_length,embedding_dim=embedding_dim,)self.lst = [keras_nlp.layers.TransformerDecoder(intermediate_dim=intermediate_dim,num_heads=num_heads,dropout=dropout,) for _ in range(num_layers)]self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, x):decoder_padding_mask = x!= 0 output = self.embedding(x)for item in self.lst:output = item(output, decoder_padding_mask=decoder_padding_mask)output = self.dense(output)return outputvocabulary_size = tokenizer.vocabulary_size() + 3
sequence_length= 64
embedding_dim=512
num_layers=12
intermediate_dim=1024
num_heads=8gpt = GPT(vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads)gpt(inputs)
gpt.summary()def masked_loss(label, pred):mask = label != padloss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')loss = loss_object(label, pred)mask = tf.cast(mask, dtype=loss.dtype)loss *= maskloss = tf.reduce_sum(loss)/tf.reduce_sum(mask)return lossdef masked_accuracy(label, pred):pred = tf.argmax(pred, axis=2)label = tf.cast(label, pred.dtype)match = label == predmask = label != padmatch = match & maskmatch = tf.cast(match, dtype=tf.float32)mask = tf.cast(mask, dtype=tf.float32)return tf.reduce_sum(match)/tf.reduce_sum(mask)gpt.compile(loss=masked_loss,optimizer='adam',metrics=[masked_accuracy]
)gpt.fit(dataset, epochs=3)
二、论文解读
GPT全称为Generative Pre-Training,即生成式的预训练模型;
2.1 GPT架构
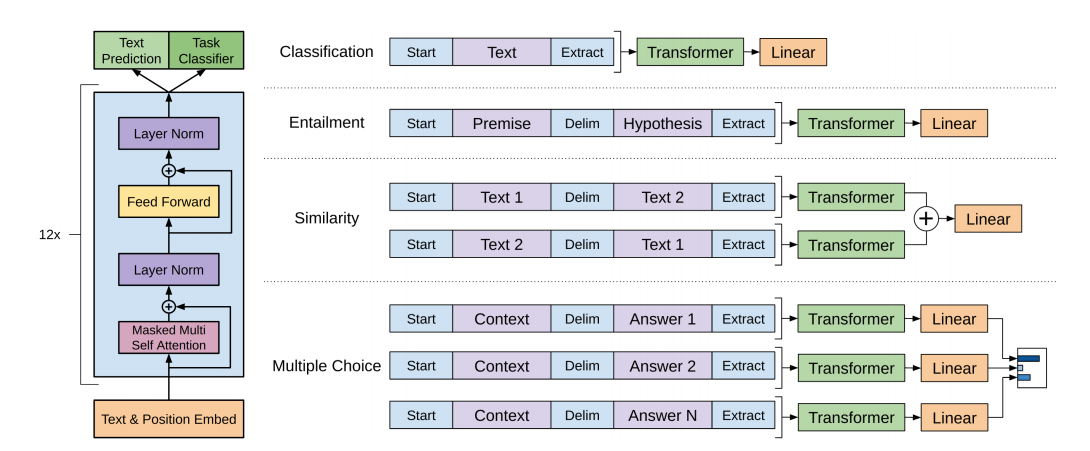
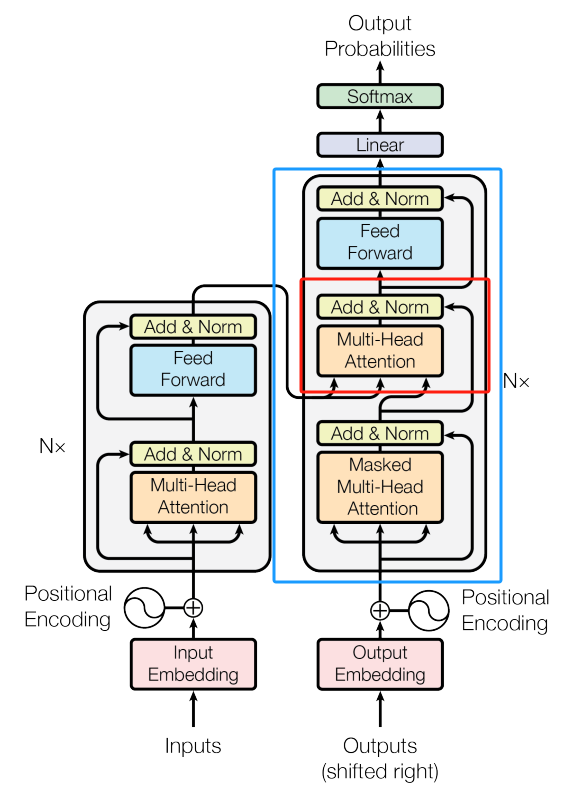
其模型架构非常简单,就是Transformer的decoder修正后的叠加,因为这是文本生成任务,并没有类似于seq2seq翻译模型的对应句子,GPT的处理方式是直接把Transformer中的decoder中的CrossAtention直接删除;
如图所示:蓝色方框部分为Transformer的decoder层,其中红色方框部分为被删除的多头注意力层;
得到的模型如下:
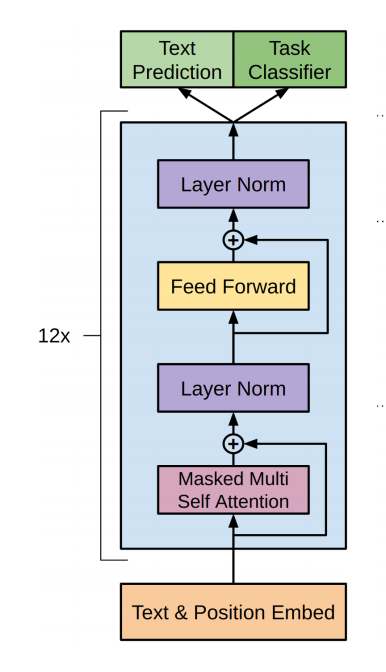
是不是特别简单;
2.2 GPT的训练方式
首先要声明的是GPT采用的是semi-supervised即半监督学习方法,其本质是一个两阶段的训练过程,第一阶段是无监督学习,就是单纯的利用Transformer的decoder来做预测下一个词的任务;第二阶段是有监督学习,利用带标签的语料信息对模型进行训练;
接下来对这两个过程进行详细的分析;
Unsupervised pre_training
原文如图所示:

其根本目的是最大化语言模型的极大似然估计,其本质就是一个链式法则取对数;
L 1 ( u ) = l o g ( P ( u i , u i − 1 , … , u 1 ) ) P ( u i , u i − 1 , … , u 1 ) = P ( u 1 ) ⋅ P ( u 2 ∣ u 1 ) ⋅ P ( u 3 ∣ u 2 , u 1 ) ⋅ ⋅ ⋅ P ( u i ∣ u i − 1 , … , u 1 ) \begin{aligned} & L_1(u) = log(P(u_i,u_{i-1},\dots,u_1)) \\ \\ & P(u_i,u_{i-1},\dots,u_1) = P(u_1)·P(u_2|u_1)·P(u_3|u_2,u_1)···P(u_i|u_{i-1},\dots,u_1) \end{aligned} L1(u)=log(P(ui,ui−1,…,u1))P(ui,ui−1,…,u1)=P(u1)⋅P(u2∣u1)⋅P(u3∣u2,u1)⋅⋅⋅P(ui∣ui−1,…,u1)
而下面计算 P P P 的过程,就是利用 mask 的机制来制造类似于RNN的过程;
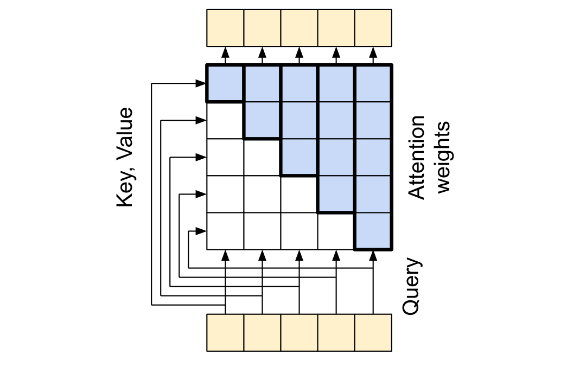
如果对注意力机制不理解的,可以去看一下Attention Is All You Need这篇论文,我也在其他博客中简单介绍了一下;
Supervised fine_training
原文如图所示:

与unsupervised pre_training不同的是,其去掉了最后一层的 W e W_e We换成了一个新的参数 W y W_y Wy,利用新的参数去预测新的标签;这里我的理解是这样的,在unsupervised pre_training中,我们相当于在大炮不停调整弹药量,大炮的对准方向 W e W_e We也在不停的向下一个单词调整;当弹药合理时,方向正确时,我们调整大炮方向去攻打supervised fine_tuning;
这里的目标函数进行了一次正则化处理,避免一味的调整方向而忽略了弹药量;
L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3(C) = L_2(C) + \lambda L_1(C) L3(C)=L2(C)+λL1(C)
至此,模型的训练就结束了;
三、过程实现
3.1 导包
这里使用tensorflow,keras_nlp和json三个包进行过程实现;
import tensorflow as tf
import keras_nlp
import json
3.2 数据处理
第一部分是无监督训练,我们需要导入一段长文本构建数据集进行训练即可,这里我们使用莎士比亚的作品 storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt;
第二部分是有监督训练,我们可以使用CoLA语料进行文本分类,CoLA语料来自GLUE Benchmark中的The Corpus of Linguistic Acceptability;
def get_merges():with open('./data/GPT_merges.txt') as f:merges = f.read().split('\n')return mergesmerges = get_merges()
vocabulary = json.load(open('./data/GPT_vocab.json'))tokenizer = keras_nlp.tokenizers.BytePairTokenizer(vocabulary=vocabulary,merges=merges
)pad = tokenizer.vocabulary_size()
start = tokenizer.vocabulary_size() + 1
end = tokenizer.vocabulary_size() + 2corpus = open('./data/shakespeare.txt').read()
data = tokenizer(corpus)
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(63, drop_remainder=True)
def process_data(x):x = tf.concat([tf.constant(start)[tf.newaxis], x, tf.constant(end)[tf.newaxis]], axis=-1)return x[:-1], x[1:]dataset = dataset.map(process_data).batch(16)inputs, outputs = dataset.take(1).get_single_element()
# inputs
# <tf.Tensor: shape=(16, 64), dtype=int32, numpy=
# array([[50258, 5962, 220, ..., 14813, 220, 1462],
# [50258, 220, 44769, ..., 220, 732, 220],
# [50258, 16275, 470, ..., 220, 1616, 220],
# ...,
# [50258, 220, 1350, ..., 220, 19205, 198],
# [50258, 271, 220, ..., 54, 18906, 220],
# [50258, 10418, 268, ..., 40, 2937, 25]])>3.3 模型构建
在这里构建模型:
class GPT(tf.keras.Model):def __init__(self, vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads, dropout=0.1):super().__init__()self.embedding = keras_nlp.layers.TokenAndPositionEmbedding(vocabulary_size=vocabulary_size,sequence_length=sequence_length,embedding_dim=embedding_dim,)self.lst = [keras_nlp.layers.TransformerDecoder(intermediate_dim=intermediate_dim,num_heads=num_heads,dropout=dropout,) for _ in range(num_layers)]self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, x):decoder_padding_mask = x!= 0 output = self.embedding(x)for item in self.lst:output = item(output, decoder_padding_mask=decoder_padding_mask)output = self.dense(output)return outputvocabulary_size = tokenizer.vocabulary_size() + 3
sequence_length= 64
embedding_dim=512
num_layers=12
intermediate_dim=1024
num_heads=8gpt = GPT(vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads)gpt(inputs)
gpt.summary()
构建模型结构如下:
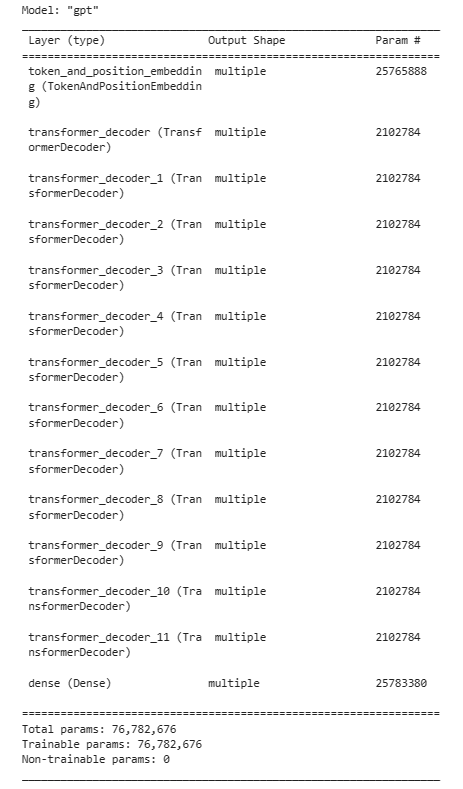
3.4 模型配置
模型配置如下:
def masked_loss(label, pred):mask = label != padloss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')loss = loss_object(label, pred)mask = tf.cast(mask, dtype=loss.dtype)loss *= maskloss = tf.reduce_sum(loss)/tf.reduce_sum(mask)return lossdef masked_accuracy(label, pred):pred = tf.argmax(pred, axis=2)label = tf.cast(label, pred.dtype)match = label == predmask = label != padmatch = match & maskmatch = tf.cast(match, dtype=tf.float32)mask = tf.cast(mask, dtype=tf.float32)return tf.reduce_sum(match)/tf.reduce_sum(mask)gpt.compile(loss=masked_loss,optimizer='adam',metrics=[masked_accuracy]
)gpt.fit(dataset, epochs=3)
训练过程不知道为什么masked_accuracy一直不变,需要分析;

四、整体总结
模型结构很简单,但是在实现过程中出现了和Bert一样的问题;
相关文章:
[GPT-1]论文实现:Improving Language Understanding by Generative Pre-Training
Efficient Graph-Based Image Segmentation 一、完整代码二、论文解读2.1 GPT架构2.2 GPT的训练方式Unsupervised pre_trainingSupervised fine_training 三、过程实现3.1 导包3.2 数据处理3.3 模型构建3.4 模型配置 四、整体总结 论文:Improving Language Understa…...

23种设计模式之C++实践(一)
23种设计模式之C++实践 1. 简介2. 基础知识3. 设计模式(一)创建型模式1. 单例模式——确保对象的唯一性1.2 饿汉式单例模式1.3 懒汉式单例模式比较IoDH单例模式总结2. 简单工厂模式——集中式工厂的实现简单工厂模式总结3. 工厂方法模式——多态工厂的实现工厂方法模式总结4.…...
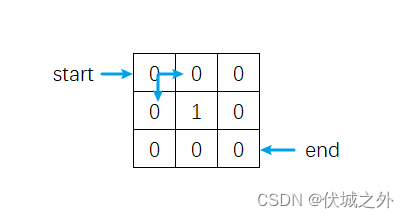
华为OD机试 - 园区参观路径(Java JS Python C)
题目描述 园区某部门举办了Family Day,邀请员工及其家属参加; 将公司园区视为一个矩形,起始园区设置在左上角,终点园区设置在右下角; 家属参观园区时,只能向右和向下园区前进,求从起始园区到终点园区会有多少条不同的参观路径。 输入描述 第一行为园区的长和宽; 后…...
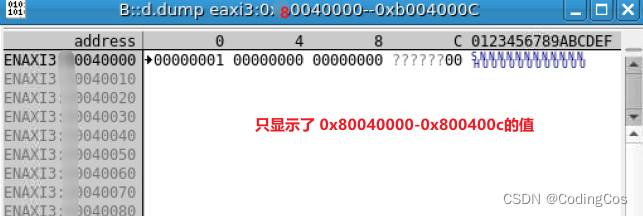
【ARM Trace32(劳特巴赫) 使用介绍 12 -- Trace32 常用命令之 d.dump | data.dump 介绍】
文章目录 Trace32 常用命令之 d.dump | data.dump 介绍1 字节显示 (Byte)4 字节显示(word)8 字节显示(通常long)十进制显示显示指定列数显示地址范围内的值 Trace32 常用命令之 d.dump | data.dump 介绍 在 TRACE32 调试环境中&a…...

【Git】Git撤销操作
记录一下,方便后续查找,不全,后续再做补充。 丢弃当前工作区未提交的修改 # 丢弃所有修改 git checkout .# 丢弃某个文件修改 git checkout 文件名丢弃本地已经提交的代码 (1)撤销最近一次提交 如果我们在最近一次提…...
改造python3中的http.server为简单的文件上传下载服务
改造 修改python3中的http.server.SimpleHTTPRequestHandler,实现简单的文件上传下载服务 simple_http_file_server.py: # !/usr/bin/env python3import datetime import email import html import http.server import io import mimetypes import os …...

Fiddler抓包工具之fiddler的composer可以简单发送http协议的请求
一,composer的详解 右侧Composer区域,是测试接口的界面: 相关说明: 1.请求方式:点开可以勾选请求协议是get、post等 2.url地址栏:输入请求的url地址 3.请求头:第三块区域可以输入请求头信息…...

14、pytest像用参数一样使用fixture
官方实例 # content of test_fruit.py import pytestclass Fruit:def __init__(self, name):self.name nameself.cubed Falsedef cube(self):self.cubed Trueclass FruitSalad:def __init__(self, *fruit_bowl):self.fruit fruit_bowlself._cube_fruit()def _cube_fruit(s…...

C++ Primer Plus第十三章笔记
目录 基类 构造函数:访问权限的考虑 1.2 派生类和基类之间的特殊关系 继承:is-a关系 多态公有继承 静态联编和动态联编 指针和引用类型的兼容性 虚成员函数和动态联编 虚函数的注意事项 构造函数 析构函数 友元 没有重新定义 重新定义将隐…...

【JavaEE】单例模式
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...
)
第十五届蓝桥杯模拟赛(第二期 C++)
俺自己做的噢,还未核实答案,若有差错,望斧正。 第一题 小蓝要在屏幕上放置一行文字,每个字的宽度相同。小蓝发现,如果每个字的宽为 36 像素,一行正好放下 30 个字,字符之间和前后都没有任何空隙…...
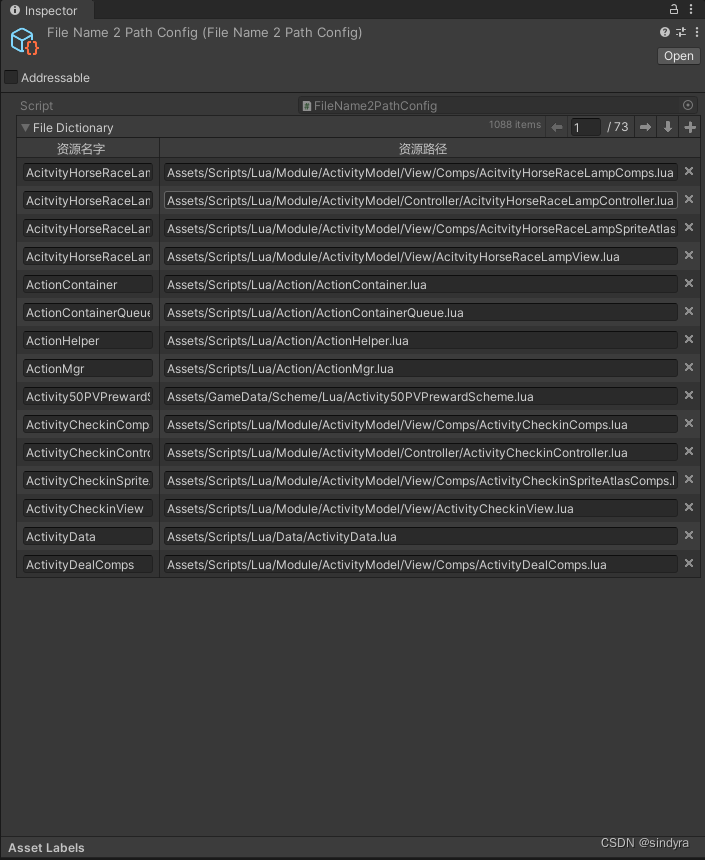
关于Unity中字典在Inspector的显示
字典在Inspector的显示 方法一:实现ISerializationCallbackReceiver接口 《unity3D游戏开发第二版》记录 在编辑面板中可以利用序列化监听接口特性对字典进行序列化。 主要继承ISerializationCallbackReceiver接口 实现OnAfterDeserialize() OnBeforeSerialize() …...
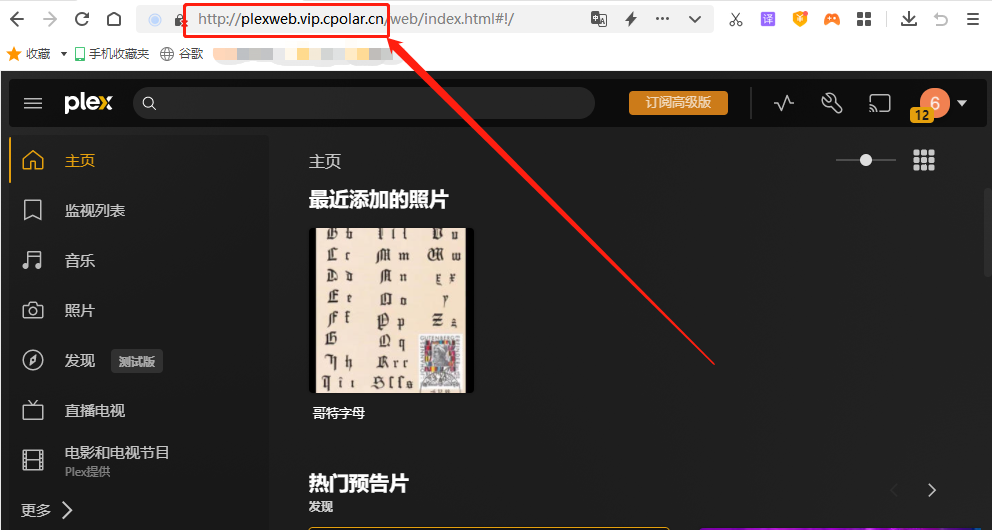
使用Plex结合cpolar搭建本地私人媒体站并实现远程访问
文章目录 1.前言2. Plex网站搭建2.1 Plex下载和安装2.2 Plex网页测试2.3 cpolar的安装和注册 3. 本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1.前言 用手机或者平板电脑看视频,已经算是生活中稀松平常的场景了,特别是各…...
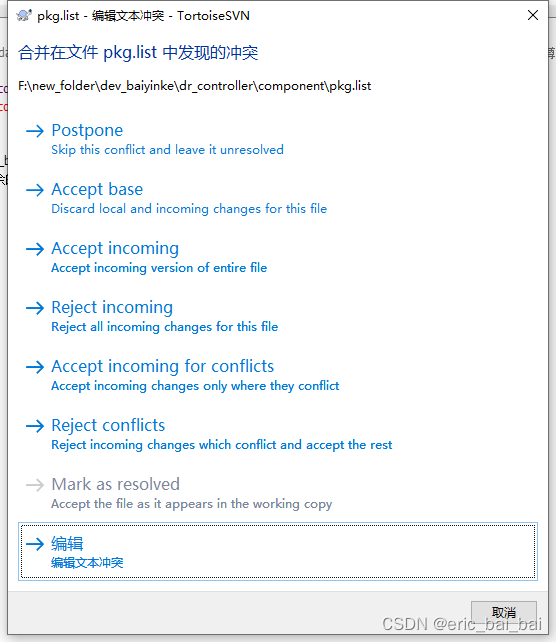
svn合并冲突时每个选项的含义
合并冲突时每个选项的含义 - 这个图片是 TortoiseSVN(一个Subversion(SVN)客户端)的合并冲突解决对话框。当你尝试合并两个版本的文件并且出现差异时,你需要解决这些差异。这个对话框提供了几个选项来处理合并冲突&…...

指针、数组与函数例题3
1、字符串复制 题目描述 设计函数实现字符串复制功能,每个字符串长度不超过100,不要使用系统提供的strcpy函数 输入要求 从键盘读入一个字符串到数组b中,以换行符结束 输出要求 将内容复制到另一个数组a中,并分别输出数组a和…...

ThreeJs样例 webgl_shadow_contact 分析
webgl_shadow_contact 官方样例中,对阴影的渲染比较特殊,很值得借鉴,学习渲染阴影的思路;这个例子中对阴影的渲染,并没有使用任何光源,没有用shadowmap的常规方式 渲染阴影;而是使用了深度材质T…...
)
Nginx(缓冲区)
先来思考一个问题,接入Nginx的项目一般请求流程为:“客户端→Nginx→服务端”,在这个过程中存在两个连接:“客户端→Nginx、Nginx→服务端”,那么两个不同的连接速度不一致,就会影响用户的体验(…...

MQTT协议理解并实践
MQTT是一个轻量的发布订阅模式消息传输协议,专门针对低带宽和不稳定网络环境的物联网应用设计 MQTT协议根据主题来分发消息进行通信,支持通配符匹配,可以低开销的使用数百万Topic进行一对一,一对多双向通信。 协议特点 1. 开放…...
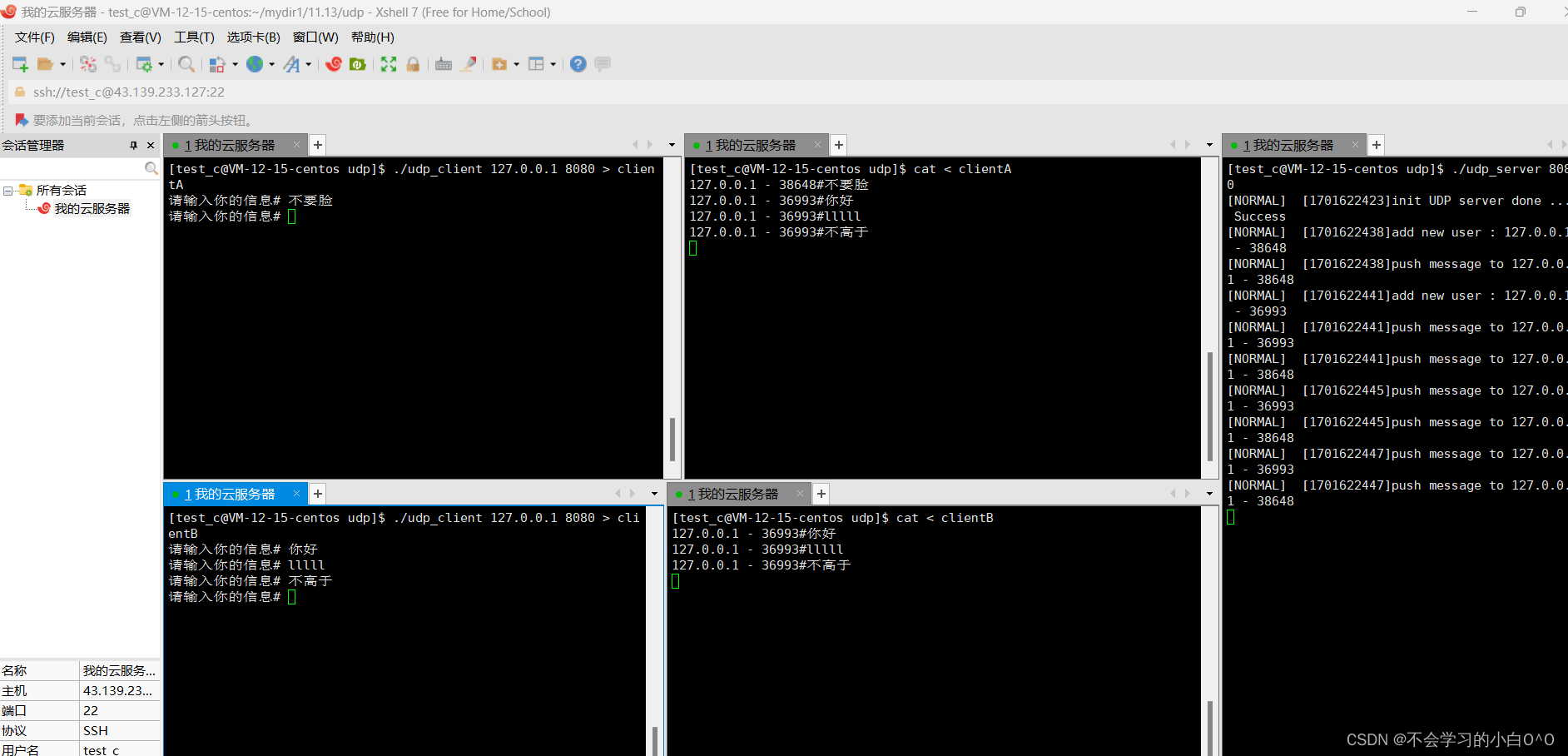
实现一个简单的网络通信下(udp)
时间过去好久了,先回忆一下上一篇博客的代码!! 目前来看,我们客户端发一条消息,我服务器收到这一条消息之后呢,服务器也知道了是谁给我发来的消息,紧接这就把这条消息放进buffer当中,…...

Linux中office环境LibreOffice_7.6.2下载
阿里云盘:LibreOffice_7.6.2 使用:下载的文件为exe文件,双击exe文件即可获取到文件 LibreOffice_7.6.2安装: 解压:tar -zxvf LibreOffice_7.6.2_Linux_x86-64_rpm.tar.gz 移动到RPMS目录:cd LibreOffice_7…...
)
从「LLM 使用者」到「LLM 驾驭者」:小白程序员必备的大模型核心知识体系与实战指南(收藏版)
本文将从底层原理、工程落地、应用优化三个维度,系统拆解大语言模型的核心知识体系,既保证技术深度,又用通俗的语言和实战案例降低理解门槛,适合所有想要从「LLM 使用者」进阶为「LLM 驾驭者」的读者。 一、LLM 核心原理入门&…...
)
Gemini Deep Research调用失败?5类报错代码详解+官方未公开的API绕过方案(限时技术内参)
更多请点击: https://intelliparadigm.com 第一章:Gemini Deep Research功能怎么用 Gemini Deep Research 是 Google 推出的面向专业研究者的增强型推理能力模块,专为长上下文分析、跨文档信息整合与假设验证设计。启用该功能需通过 Gemini …...

海棠山铁哥:我写《凰标》,就是要打破资本定价权@凤凰标志
凰标宣言——夺回中国人的文化定价权流量高低决定作品好坏,资金投入定义内容价值。 当资本垄断审美、定价与生死, 创作者便只剩一条出路:宣战。一、资本逻辑:三座大山权力资本如何行使对创作者的结果审美话语权用流量模板批量复制…...

知识图谱与量化LLM协同架构解析与应用
1. 知识图谱与量化LLM协同架构解析在自然语言处理领域,知识图谱(KG)与大型语言模型(LLM)的协同正展现出独特价值。这种架构的核心在于发挥两者的互补优势:KG提供结构化、可验证的语义网络,而LLM…...

别再花钱买板卡了!手把手教你用NI MAX免费创建虚拟PCI6224,搞定LabVIEW数字IO
零成本搭建LabVIEW开发环境:虚拟PCI6224板卡实战指南 当我在大学实验室第一次接触LabVIEW时,面对动辄上万的NI板卡价格标签,几乎浇灭了我的学习热情。直到发现NI MAX的虚拟设备功能——这个隐藏的宝藏工具,让我在没有物理硬件的情…...
)
从零到一:用MMDetection在Ubuntu 20.04上搭建Faster R-CNN模型(含完整配置与避坑指南)
从零到一:Ubuntu 20.04下MMDetection与Faster R-CNN实战全解析 当目标检测技术遇上PyTorch生态,MMDetection框架正在成为工业界和学术界的新宠。本文将带您完成从裸机到完整训练Faster R-CNN模型的实战旅程,特别针对Ubuntu 20.04系统和NVIDIA…...
)
Midjourney未来三年风格演进路径图(2024–2026关键拐点全标注)
更多请点击: https://intelliparadigm.com 第一章:Midjourney 2026年审美趋势总览 2026年,Midjourney 的视觉语言正经历一场由技术理性与人文温度共同驱动的范式迁移。V7引擎全面启用动态语义权重调节(DSWR)ÿ…...

隐写术:把秘密藏在你眼皮底下
你有没有想过,秘密不一定非要“加密”,还可以“藏起来”?这就是隐写术的思想——让别人根本不知道这里藏了信息。早在公元前5世纪,一位希腊人为了把情报传回祖国,把文字写在刮去蜡的木板上,再用新蜡覆盖。收…...

Flutter Provider 状态管理完全指南
Flutter Provider 状态管理完全指南 引言 Provider 是 Flutter 中最流行的状态管理方案之一,它基于 InheritedWidget 实现,提供了简单而强大的状态管理方式。本文将深入探讨 Provider 的各种用法和高级技巧。 基础概念回顾 Provider 类型 Provider - 最基…...
)
DIY焊台实战:用STM32F070F6P6的Encoder模式搞定EC11编码器(附完整CubeMX配置)
DIY焊台实战:用STM32F070F6P6的Encoder模式搞定EC11编码器(附完整CubeMX配置) 在电子DIY的世界里,焊台是每个硬件爱好者的必备工具。而一个精准可控的T12焊台,不仅能提升焊接效率,更能让整个DIY过程充满乐趣…...