pytorch bert实现文本分类
以imdb公开数据集为例,bert模型可以在huggingface上自行挑选
1.导入必要的库
import os
import torch
from torch.utils.data import DataLoader, TensorDataset, random_split
from transformers import BertTokenizer, BertModel, BertConfig
from torch import nn
from torch.optim import AdamW
import numpy as np
from sklearn.metrics import accuracy_score
import pandas as pd
from tqdm import tqdmdevice = torch.device("cuda:0")
print(device)
2.加载和预处理数据:读取数据,将其转换为适合BERT的格式,并将评分映射到三个类别。
import random
def load_imdb_dataset_and_create_multiclass_labels(path_to_data, split="train"):print(f"load start: {split}")reviews = []labels = [] # 0 for low, 1 for medium, 2 for highfor label in ["pos", "neg"]:labeled_path = os.path.join(path_to_data, split, label)for file in os.listdir(labeled_path):if file.endswith('.txt'):with open(os.path.join(labeled_path, file), 'r', encoding='utf-8') as f:reviews.append(f.read())if label == "neg":# Randomly assign negative reviews to low or mediumlabels.append(random.choice([0, 1])) else:labels.append(2) # Assign positive reviews to highreturn reviews[:1000], labels[:1000]
#加载数据集
train_texts, train_labels = load_imdb_dataset_and_create_multiclass_labels("./data/aclImdb", split="train")
test_texts, test_labels = load_imdb_dataset_and_create_multiclass_labels("./data/aclImdb", split="test")
print("load okk")
#样本数量
print("train_texts: ",len(train_texts))
print("test_texts: ",len(test_texts))
3.文本转换为BERT的输入格式
tokenizer = BertTokenizer.from_pretrained('./bert_pretrain')def encode_texts(tokenizer, texts, max_len=512):input_ids = []attention_masks = []for text in texts:encoded = tokenizer.encode_plus(text,add_special_tokens=True,max_length=max_len,pad_to_max_length=True,return_attention_mask=True,return_tensors='pt',)input_ids.append(encoded['input_ids'])attention_masks.append(encoded['attention_mask'])return torch.cat(input_ids, dim=0), torch.cat(attention_masks, dim=0)train_inputs, train_masks = encode_texts(tokenizer, train_texts)
test_inputs, test_masks = encode_texts(tokenizer, test_texts)
print("input transfromer encode done")
4.创建TensorDataset和DataLoader
train_labels = torch.tensor(train_labels)
test_labels = torch.tensor(test_labels)train_dataset = TensorDataset(train_inputs, train_masks, train_labels)
test_dataset = TensorDataset(test_inputs, test_masks, test_labels)# Split the dataset into train and validation sets
train_size = int(0.9 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=128, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)
5.构建模型:使用BERT进行多分类任务
class BertForMultiLabelClassification(nn.Module):def __init__(self):super(BertForMultiLabelClassification, self).__init__()self.bert = BertModel.from_pretrained('./bert_pretrain')self.dropout = nn.Dropout(0.1)self.classifier = nn.Linear(self.bert.config.hidden_size, 3) # 3类def forward(self, input_ids, attention_mask):_, pooled_output = self.bert(input_ids=input_ids, attention_mask=attention_mask, return_dict=False)pooled_output = self.dropout(pooled_output)return self.classifier(pooled_output)
6.训练和评估模型
# 初始化模型、优化器和损失函数
model = BertForMultiLabelClassification()
# 使用多GPU
# if MULTI_GPU:
# model = nn.DataParallel(model)
model.to(device)optimizer = AdamW(model.parameters(), lr=2e-5)
loss_fn = nn.CrossEntropyLoss()# 训练函数
def train(model, dataloader, optimizer, loss_fn, device):model.train()total_loss = 0for batch in dataloader:batch = tuple(b.to(device) for b in batch)inputs, masks, labels = batchoptimizer.zero_grad()outputs = model(input_ids=inputs, attention_mask=masks)loss = loss_fn(outputs, labels)total_loss += loss.item()loss.backward()optimizer.step()average_loss = total_loss / len(dataloader)return average_loss# 评估函数
def evaluate(model, dataloader, loss_fn, device):model.eval()total_loss = 0predictions, true_labels = [], []with torch.no_grad():for batch in dataloader:batch = tuple(b.to(device) for b in batch)inputs, masks, labels = batchoutputs = model(input_ids=inputs, attention_mask=masks)loss = loss_fn(outputs, labels)total_loss += loss.item()logits = outputs.detach().cpu().numpy()label_ids = labels.to('cpu').numpy()predictions.append(logits)true_labels.append(label_ids)average_loss = total_loss / len(dataloader)flat_predictions = np.concatenate(predictions, axis=0)flat_predictions = np.argmax(flat_predictions, axis=1).flatten()flat_true_labels = np.concatenate(true_labels, axis=0)accuracy = accuracy_score(flat_true_labels, flat_predictions)return average_loss, accuracy# 训练和评估循环
for epoch in range(3): # 假设训练3个周期train_loss = train(model, train_dataloader, optimizer, loss_fn, device)val_loss, val_accuracy = evaluate(model, val_dataloader, loss_fn, device)print(f"Epoch {epoch+1}")print(f"Train Loss: {train_loss:.3f}")print(f"Validation Loss: {val_loss:.3f}, Accuracy: {val_accuracy:.3f}")# 在测试集上评估模型性能
test_loss, test_accuracy = evaluate(model, test_dataloader, loss_fn, device)
print(f"Test Loss: {test_loss:.3f}, Accuracy: {test_accuracy:.3f}")
#保存模型
torch.save(model.state_dict(), "./model/bert_multiclass_imdb_model.pt")
7.模型预测
from transformers import BertModel
import torchdef predict(texts, model, tokenizer, device, max_len=128):# 将文本编码为BERT的输入格式def encode_texts(tokenizer, texts, max_len):input_ids = []attention_masks = []for text in texts:encoded = tokenizer.encode_plus(text,add_special_tokens=True,max_length=max_len,pad_to_max_length=True,return_attention_mask=True,return_tensors='pt',)input_ids.append(encoded['input_ids'])attention_masks.append(encoded['attention_mask'])return torch.cat(input_ids, dim=0), torch.cat(attention_masks, dim=0)model.eval() # 将模型设置为评估模式predictions = []input_ids, attention_masks = encode_texts(tokenizer, texts, max_len)input_ids = input_ids.to(device)attention_masks = attention_masks.to(device)with torch.no_grad():outputs = model(input_ids, attention_mask=attention_masks)logits = outputs.detach().cpu().numpy()predictions = np.argmax(logits, axis=1)return predictions# 示例文本
texts = ["I very like the movie", "the movie is so bad"]# 调用预测函数# 初始化模型
device = torch.device("cuda:0")
model = BertForMultiLabelClassification()
model.to(device)# 加载模型状态
model.load_state_dict(torch.load('./model/bert_multiclass_imdb_model.pt'))# 将模型设置为评估模式
model.eval()# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('./bert_pretrain')predictions = predict(texts, model, tokenizer, device)# 输出预测结果
for text, pred in zip(texts, predictions):print(f"Text: {text}, Predicted category: {pred}")
相关文章:

pytorch bert实现文本分类
以imdb公开数据集为例,bert模型可以在huggingface上自行挑选 1.导入必要的库 import os import torch from torch.utils.data import DataLoader, TensorDataset, random_split from transformers import BertTokenizer, BertModel, BertConfig from torch import…...

《开箱元宇宙》:Madballs 解锁炫酷新境界,人物化身系列大卖
你是否曾想过,元宇宙是如何融入世界上最具代表性的品牌和名人的战略中的?在本期的《开箱元宇宙》 系列中,我们与 Madballs 的战略顾问 Derek Roberto 一起聊聊 Madballs 如何在 90 分钟内售罄 2,000 个人物化身系列,以及是什么原…...

4K-Resolution Photo Exposure Correction at 125 FPS with ~8K Parameters
MSLTNet开源 | 4K分辨率125FPS8K的参数量,怎养才可以拒绝这样的模型呢? 错误的曝光照片的校正已经被广泛使用深度卷积神经网络或Transformer进行广泛修正。尽管这些方法具有令人鼓舞的表现,但它们通常在高分辨率照片上具有大量的参数数量和沉…...
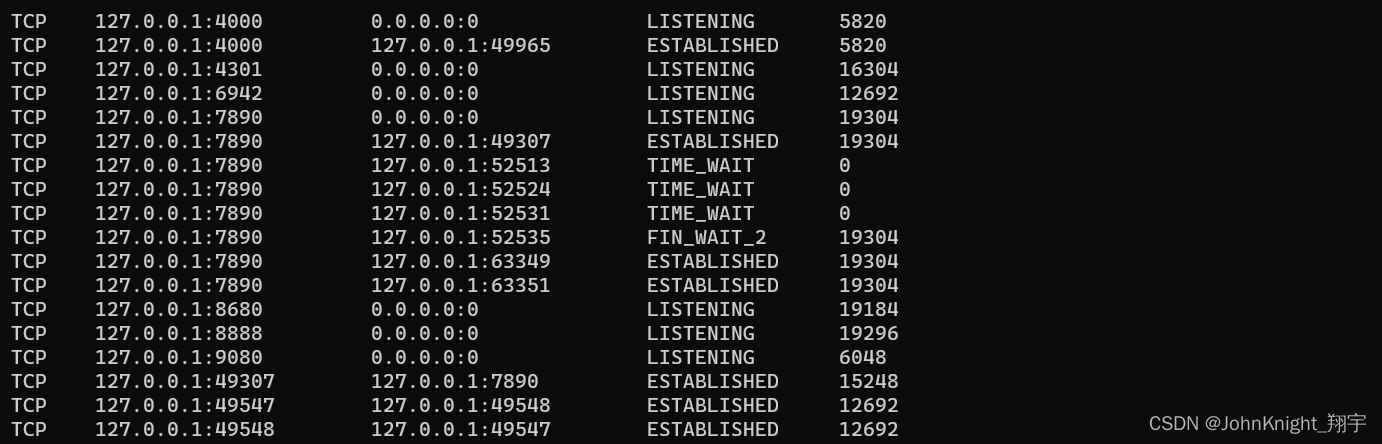
网络初识:局域网广域网网络通信基础
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、局域网LAN是什么?二、广域网是什么:三. IP地址四.端口号五.认识协议5.1五元组 总结 前言 一、局域网LAN是什么? 局域网…...

JVM之jps虚拟机进程状态工具
jps虚拟机进程状态工具 1、jps jps:(JVM Process Status Tool),虚拟机进程状态工具,可以列出正在运行的虚拟机进程,并显示虚拟机执 行主类(Main Class,main()函数所在的类)的名称,…...
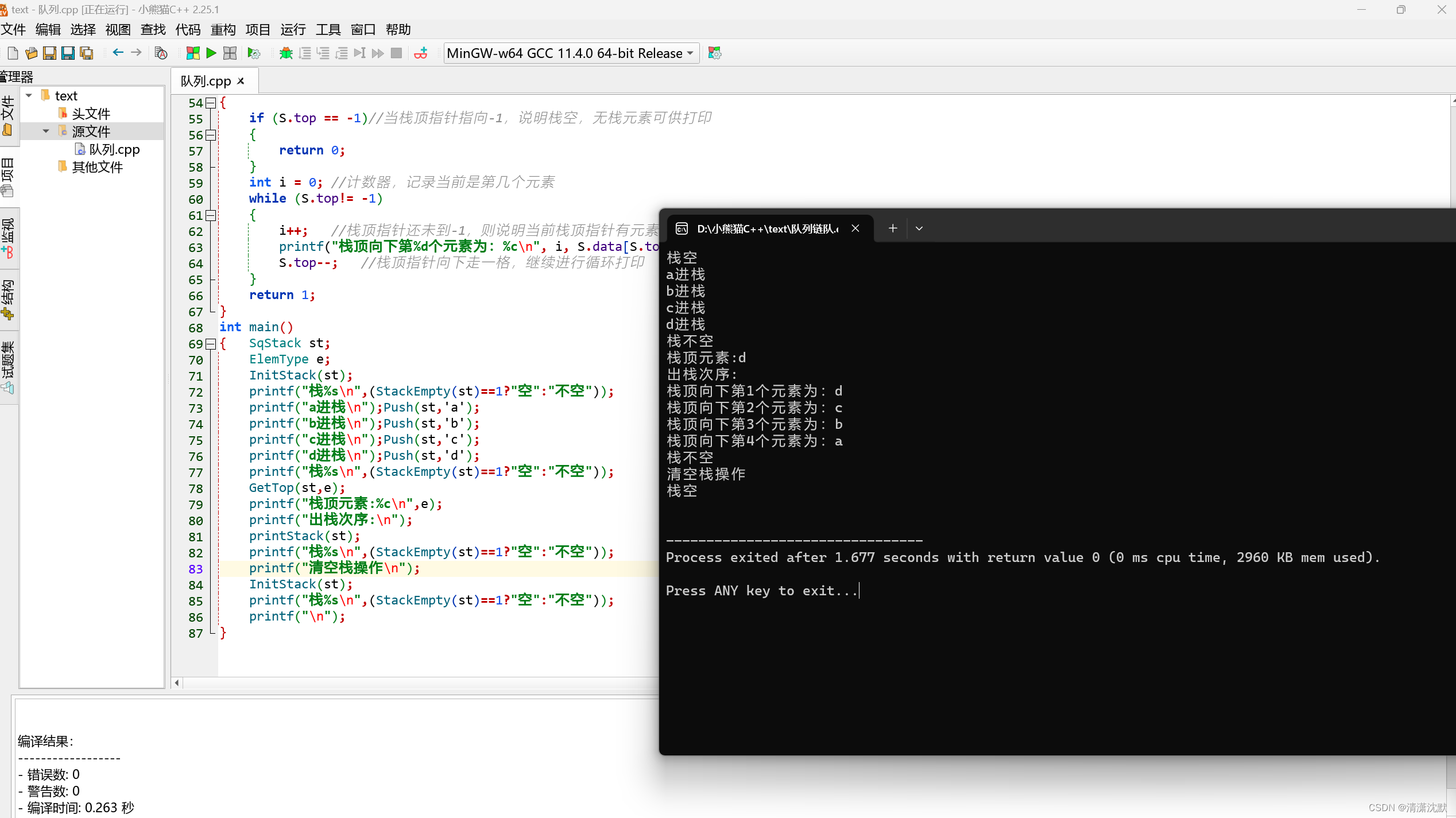
C++实现顺序栈的基本操作(扩展)
#include <stdio.h> typedef char ElemType; #define StackSize 100 /*顺序栈的初始分配空间*/ typedef struct { ElemType data[StackSize]; /*保存栈中元素*/int top; /*栈顶指针*/ } SqStack; void InitStack(SqStack &st) {st.top-1; } …...
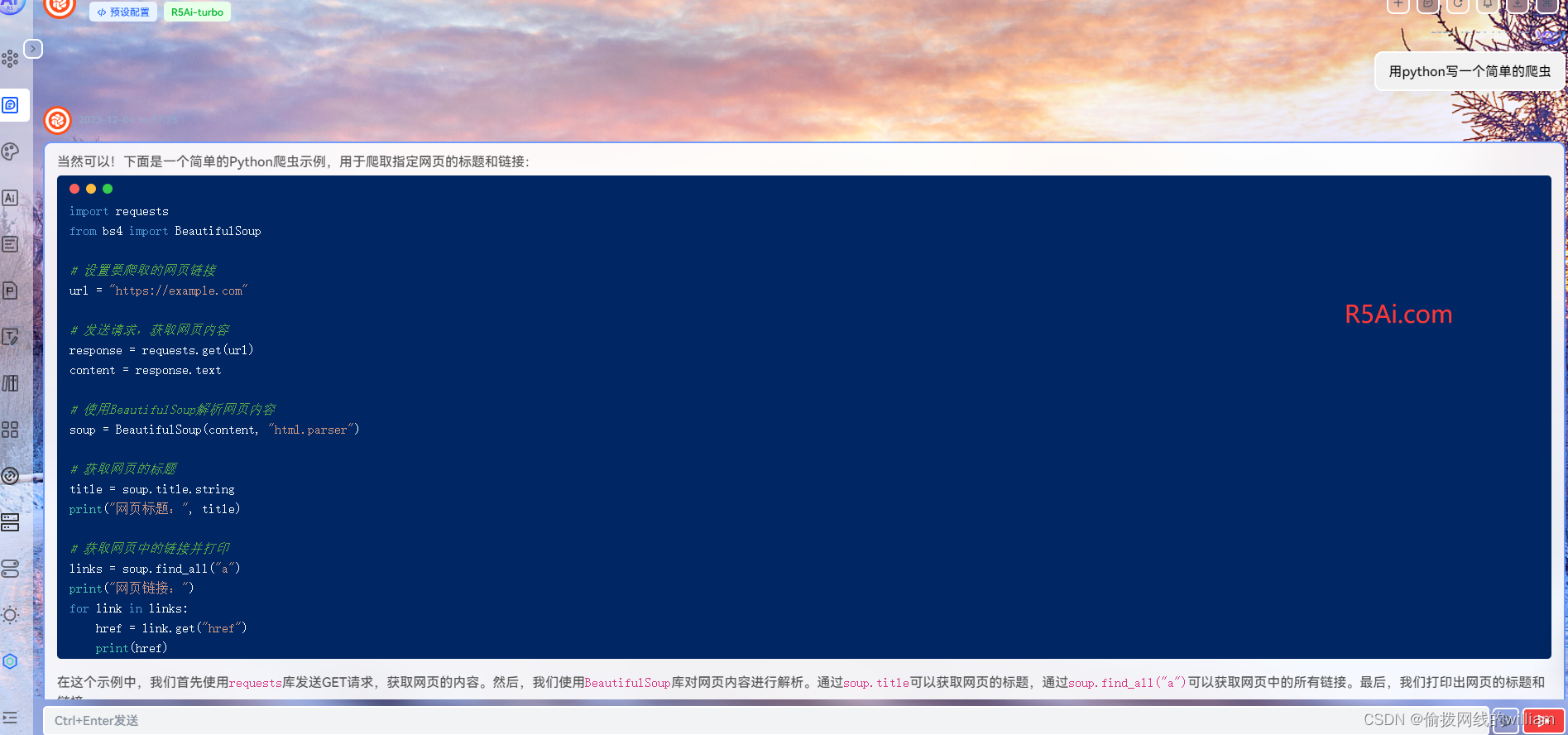
用python写一个简单的爬虫
爬虫是一种自动化程序,用于从互联网上获取数据。它能够模拟人类浏览网页的行为,访问网页并提取所需的信息。爬虫在很多领域都有广泛的应用,例如数据采集、信息监控、搜索引擎索引等。 下面是一个使用Python编写的简单爬虫示例: …...

分布式追踪
目录 文章目录 目录自定义指标1.删除标签2.添加指标3.禁用指标 分布式追踪上下文传递Jaeger 关于我最后最后 自定义指标 除了 Istio 自带的指标外,我们还可以自定义指标,要自定指标需要用到 Istio 提供的 Telemetry API,该 API 能够灵活地配…...

make -c VS make -f
make 是一个用于构建(编译)项目的工具,它通过读取一个名为 Makefile 的文件来执行构建任务。make 命令有很多选项和参数,其中包括 -c 和 -f。 make -c: 作用:指定进入指定的目录并执行相应的 Makefile。 示…...

Unity 代码控制Color无变化
Unity中,我们给Color的赋值比较常用的方法是: 1、使用预定义颜色常量: Color color Color.white; //白色 Color color Color.black; //黑色 Color color Color.red; //红色 Color color Color.green; //绿色 Color color Color.blue; …...

【Erlang进阶学习】2、匿名函数
受到其它一些函数式编程开发语言的影响,在Erlang语言中,将函数作为一个对象,赋予其“变量”的属性,即为我们的匿名函数 或 简称 fun,它具有以下特性: (匿名函数:不是定义在Erlang模…...

肖sir__mysql之视图__009
mysql之视图 一、什么是视图 视图是一个虚拟表(逻辑表),它不在数据库中以存储形式保存(本身包含数据),是在使用视图的时候动态生成。 二、视图作用 1、查询数据库中的非常复的数据 例如:多表&a…...
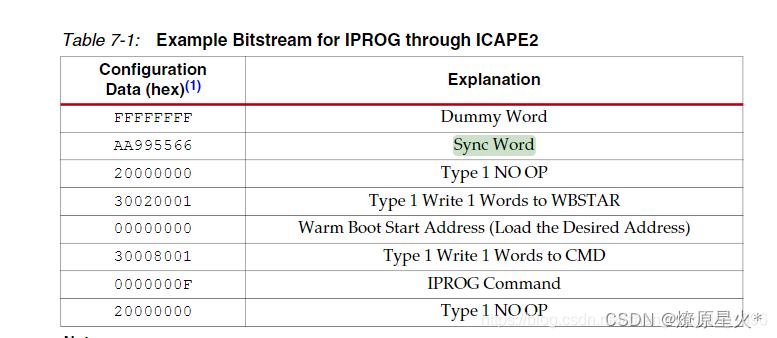
FPGA falsh相关知识总结
1.存储容量是128M/8 Mb16MB 2.有256个sector扇区*每个扇区64KB16MB 3.一页256Byte 4.页编程地址0256 5:在调试SPI时序的时候一定注意,miso和mosi两个管脚只要没发送数据就一定要悬空(处于高组态),不然指令会通过两…...
升辉清洁IPO:广东清洁服务“一哥”还需要讲好全国化的故事
近日,广东物业清洁服务“一哥”升辉清洁第四次冲击IPO成功,拟于12月5日在香港主板挂牌上市。自2021年4月第一次递交招股书,时隔两年半,升辉清洁终于拿到了上市的门票。 天眼查显示,升辉清洁成立于2000年,主…...

Python自动化办公:PDF文件的分割与合并
我们平时办公中,可能需要对pdf进行合并或者分割,但奈何没有可以白嫖的工具,此时python就是一个万能工具库。 其中PyPDF2是一个用于处理PDF文件的Python库,它提供了分割和合并PDF文件的功能。 在本篇博客中,我们将详细…...

破解app思路
1.会看smali代码逻辑 一.快速定位关键代码 1.分析流程 搜索特征字符串 搜索关键 api 通过方法名来判断方法的功能 2.快速定位关键代码 反编译 APK 程序 AndroidManifest.xml>包名/系统版本/组件 程序的主 activity(程序入口界面) 每个 Android 程序…...


36.位运算符
一.什么是位运算符 按照二进制位来进行运算的运算符叫做位运算符,所以要先将操作数转换成二进制(补码)的形式在运算。C语言的中的位运算符有: 运算符作用举例结果& 按位与(and) 0&00; 0&10; …...

C#异常处理-throw语句
throw语句是我们手动引发异常的一个语句。 在程序执行过程中,当某些条件不符合我们的要求时,那么我们就可以使用throw语句手动抛出异常,那么就可以在异常发生的地方终止当前代码块的执行,此时我们就可以把控制权传递给调用堆栈中…...
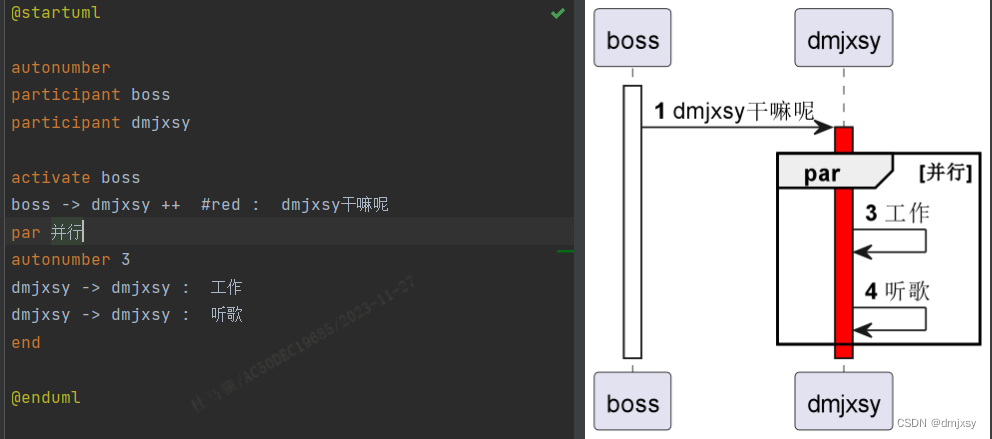
PlantUML语法(全)及使用教程-时序图
目录 1. 参与者1.1、参与者说明1.2、背景色1.3、参与者顺序 2. 消息和箭头2.1、 文本对其方式2.2、响应信息显示在箭头下面2.3、箭头设置2.4、修改箭头颜色2.5、对消息排序 3. 页面标题、眉角、页脚4. 分割页面5. 生命线6. 填充区设置7. 注释8. 移除脚注9. 组合信息9.1、alt/el…...

iOS 27 开放 AI 生态@ACP#专业视频处理新标杆 ——GSV9001E/S 赋能 iPhone AI 多屏智能显示
一、iOS 27 开放 AI:引爆专业视频处理与多屏显示刚需iOS 27 全面开放第三方 AI 模型,iPhone 成为 AI 内容生成、多源信号整合、智能交互核心,直接催生AI 多屏拼接、无缝切换、画中画、HDR/SDR 转换、车载 / 工控多视图、医疗 AI 显示六大专业…...
像素映射天地 视频解构空间 ——以Pixel2Geo™核心技术,开启数字孪生与视频孪生无感感知新时代
像素映射天地 视频解构空间——以Pixel2Geo™核心技术,开启数字孪生与视频孪生无感感知新时代一、企业核心定位:无感感知赛道开创者,实景孪生技术定义者镜像视界(浙江)科技有限公司深耕数字孪生与视频孪生领域底层创新…...

如何在老旧电视上实现流畅的1080P直播?MyTV-Android原生应用深度解析
如何在老旧电视上实现流畅的1080P直播?MyTV-Android原生应用深度解析 【免费下载链接】mytv-android 使用Android原生开发的视频播放软件 项目地址: https://gitcode.com/gh_mirrors/my/mytv-android 你是否曾为家中老旧智能电视的卡顿直播体验而烦恼&#x…...

PacketStreamer传感器工作原理:深入解析BPF过滤机制
PacketStreamer传感器工作原理:深入解析BPF过滤机制 【免费下载链接】PacketStreamer :star: :star: Distributed tcpdump for cloud native environments :star: :star: 项目地址: https://gitcode.com/gh_mirrors/pa/PacketStreamer PacketStreamer是一款专…...

PX4 Firmware V1.14.4 开源支持
PX4 官方固件版本迭代迅猛,这往往导致开发者在硬件兼容性、环境搭建及软件依赖性上遭遇重重挑战。为彻底解决这一问题,Kerloud 推出固件与文档长期支持(LTS)计划。我们将对飞控固件代码、技术文档及参数调优指南实施持续性维护&am…...
和滚动统计为预测模型打好基础)
你的时间序列真的平稳吗?手把手教你用ADF检验(Dickey-Fuller)和滚动统计为预测模型打好基础
时间序列平稳性诊断实战:从理论到Python实现 时间序列分析中,平稳性检验是建模前的关键步骤。许多经典预测模型(如ARIMA)都建立在数据平稳的假设之上。但现实中的时间序列往往带有趋势或季节性,直接建模会导致预测失效…...

隐藏在闲鱼暗网的暴利生意
今天想跟大家说个颠覆认知的事儿——你平时用来卖旧衣服、砍价包邮的闲鱼,其实还有一张脸,那张脸长什么样呢?我管它叫“成年人最隐秘的交易所”。 你敢信吗?有人在那儿卖了10万单,一单实物都不发,纯利润&am…...

AI 短视频运营技能包|选题 + 爆款 + 增长全流程 AI 辅助
AI 短视频运营技能包:https://ai-skills.ai/?inviteCode=S2JV3NCK AIGC短视频制作教程:https://pan.baidu.com/s/1usF3eo43h2k91m6R6ycDpQ?pwd=ufkk 目录 摘要 前言 一、技能包概述 二、核心功能详解 1. 赛道定位分析 2. 内容方向规划 3. 热门趋势追踪 4. 优质选题…...

Visual Studio AI助手实战:Visual chatGPT Studio提升.NET开发效率
1. 项目概述:当AI助手住进你的IDE 如果你是一名.NET开发者,每天至少有8小时与Visual Studio为伴,那么你肯定体会过那种在代码海洋中寻找灵感的孤独感。调试一个古怪的Bug,重构一段陈年旧代码,或者为某个复杂业务逻辑编…...

终极指南:八大网盘直链下载助手完整使用教程,告别限速烦恼
终极指南:八大网盘直链下载助手完整使用教程,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国…...