大模型上下文学习(ICL)训练和推理两个阶段31篇论文
大模型都火了这么久了,想必大家对LLM的上下文学习(In-Context Learning)能力都不陌生吧?
以防有的同学不太了解,今天我就来简单讲讲。
上下文学习(ICL)是一种依赖于大型语言模型的学习任务方式,近年来随着大模型能力的提高,它也成为了NLP的一种新范式。ICL无需对模型权重做任何改动,只需要给预训练模型展示一些输入-输出示例,就能解决对应场景下的新问题。
为了更高效地提示大模型,最近很多业内人士都在研究大模型的上下文学习能力,并且也有了不少值得关注的成果。这次我就整理了其中一部分来和大家分享,共31篇,主要分为2大类,包含训练和推理两个阶段。
篇幅原因,解析就不多写了,需要的同学看文末
训练
1.MetaICL: Learning to Learn In Context
学会在上下文中学习
简述:论文介绍了一种新的元训练框架,叫做MetaICL,用于少样本学习。这种框架通过调整预训练的语言模型进行上下文学习。实验证明,MetaICL优于其他基线模型,尤其对于有领域转移的任务。使用多样化的元训练任务能进一步提高性能。

2.OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
通过泛化的视角扩展语言模型指令元学习
简述:指令微调可以改善预训练语言模型对新任务的泛化能力。论文研究了微调过程中的决策对性能的影响,并创建了一个包含2000个任务的基准来评估模型。研究发现,微调决策如基准规模、任务采样、使用演示等都会影响性能。作者训练了两个版本的OPT-IML,它们在四个基准上都优于其他模型。

3.Finetuned Language Models are Zero-Shot Learners
微调语言模型是零样本学习器
简述:这篇文章探索了指令微调提高语言模型零样本学习能力的方法。作者发现,通过在指令描述的数据集上微调模型,可以显著提高对未见任务的性能。作者使用137B参数模型进行指令微调,并评估FLAN在未见任务上的表现,发现它优于零样本175B GPT-3。消融实验表明,指令微调的成功取决于微调数据集数量、模型规模和自然语言指令。

4.Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
通过1600多个NLP任务的声明性指令实现泛化
简述:作者创建了一个包含1616个任务和专家说明的基准测试,涵盖了76种不同的任务类型,并训练了一个transformer模型Tk-Instruct,该模型可以遵循各种上下文指令。尽管它小一个数量级,但作者发现它在基准测试中比现有的模型表现更好。作者进一步分析了泛化性能如何受到观察任务的数量、每个任务的实例数量和模型大小等因素的影响。

5.Scaling Instruction-Finetuned Language Models
扩展指令微调语言模型的规模
简述:论文探索了在不同任务数量、模型大小和提示设置下进行指令微调的效果。例如,在1.8K个任务上微调Flan-PaLM 540B模型后,性能得到了显著提升,并在多个基准测试中达到了最佳性能。作者还公开了Flan-T5检查点,这些检查点在少样本性能方面表现强劲。

6.Symbol tuning improves in-context learning in language models
符号微调提高了语言模型中的上下文学习效果
简述:论文提出了一种名为“符号微调”的新方法,它使用任意符号替换自然语言标签来微调语言模型。这种方法有助于模型更好地处理未见过且缺乏明确指令的任务,并提高其在算法推理任务上的表现。作者在大型Flan-PaLM模型上进行了实验,发现符号微调可以提高模型对上下文信息的利用能力。

7.Improving In-Context Few-Shot Learning via Self-Supervised Training
通过自我监督训练提高上下文少样本学习效果
简述:这篇论文提出了在预训练和下游少样本学习之间使用自监督学习的中间训练阶段,旨在教会模型进行上下文少样本学习。作者在两个基准测试中提出并评估了四种自监督目标,发现中间的自监督学习阶段产生的模型优于强大的基线。消融研究显示,几个因素影响下游表现,如训练数据量和自监督目标的多样性。人类注释的跨任务监督和自监督是互补的。

8.Pre-training to learn in context
通过预训练来学习上下文
简述:PICL是一种预训练语言模型的方法,旨在提高模型在上下文中的学习能力。通过在大量内在任务上使用简单的语言建模目标进行预训练,PICL鼓励模型根据上下文进行推断和执行任务,同时保持预训练模型的任务泛化能力。实验表明,PICL在各种NLP任务中表现优于其他基线方法,尤其在Super-NaturalInstrctions基准测试中,它优于更大的语言模型。

推理
1.What Makes Good In-Context Examples for GPT-3?
什么让GPT-3具有良好的上下文示例?
简述:GPT-3是一种强大的语言模型,适用于多种NLP任务,包括上下文学习。然而,如何选择上下文示例对于GPT-3的性能至关重要。作者发现,通过检索与测试查询样本语义相似的示例,可以更好地利用GPT-3的上下文学习能力。这种方法在多个基准测试中优于随机选择基线,并且在表格到文本生成和开放领域问答等任务中取得了显著成果。

2.Learning To Retrieve Prompts for In-Context Learning
学习检索上下文学习的提示
简述:上下文学习是一种自然语言理解的新方法,大型预训练语言模型观察测试实例和训练示例作为输入,直接解码输出而不更新参数。这种方法的效果取决于所选择的训练示例(提示)。本文提出了一种新方法,使用带标注的数据和LM来检索提示。给定输入-输出对,估计给定输入和候选训练示例作为提示时输出的概率,并根据该概率标记训练示例。然后训练一个高效的密集检索器,用于测试时检索训练示例作为提示。

3.Demystifying Prompts in Language Models via Perplexity Estimation
基于困惑度估计的语言模型提示解谜
简述:语言模型可以接受各种零样本和少样本学习任务的提示,但性能会因提示而异,我们还不明白原因或如何选择最佳提示。本文分析性能变化的因素,发现模型对提示语言的熟悉程度影响其性能。作者设计了一种新方法来创建提示:首先,使用GPT3和回译自动扩展手动创建的小提示集;然后,选择困惑度最低的提示可显著提高性能。
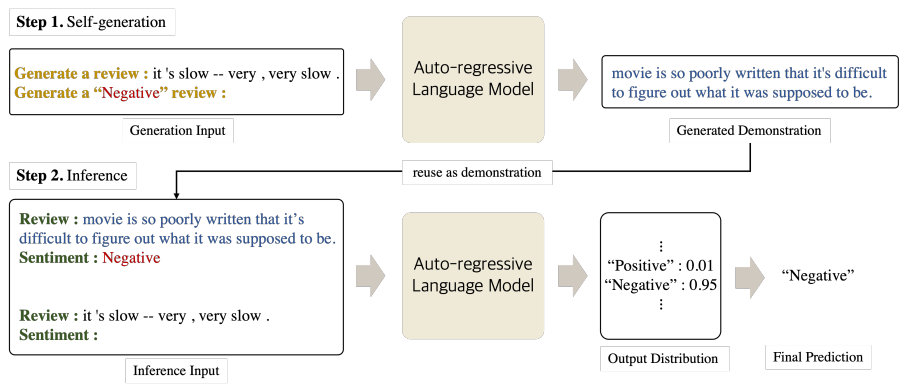
4.Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
利用自回归语言模型作为演示生成器
简述:本文提出了一种新的方法,即自生成上下文学习(SG-ICL),用于减少大规模预训练语言模型(PLM)对外部演示的依赖。SG-ICL从PLM本身生成演示,以进行上下文学习。作者在四个文本分类任务上进行了实验,并发现SG-ICL的表现优于零样本学习,大致相当于0.6个黄金训练样本。与从训练集中随机选择的演示相比,该生成的演示表现更一致,方差更低。
5.An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
无需真实标签的提示工程的信息论方法
简述:现有的提示工程方法需要大量标记数据和访问模型参数。论文介绍了一种新方法,无需标记示例或直接访问模型。作者选择最大化输入和模型输出之间互信息的模板。在8个数据集中,作者发现高互信息的模板任务准确度也高。在最大模型上,使用该方法可使准确度达到最佳的90%,无需真实标签。

6.Active Example Selection for In-Context Learning
上下文学习中的主动范例选择
简述:大型语言模型能够从少量示例中学习执行各种任务,无需微调。但是,上下文学习的性能在示例之间不稳定。论文提出了一种强化学习算法来选择示例,以实现更好的泛化性能。这种方法在GPT-2上表现良好,平均提高了5.8%的性能。尽管在更大的GPT-3模型上改进效果较小,但该方法仍然表明了大型语言模型的能力不断增强。
-
7.Finding supporting examples for in-context learning
-
8.Large language models are implicitly topic models: Explaining and finding good demonstrations for in-context learning
-
9.Unified Demonstration Retriever for In-Context Learning
-
10.Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
-
11.Instruction Induction: From Few Examples to Natural Language Task Descriptions
-
12.Large Language Models Are Human-Level Prompt Engineers
-
13.Self-Instruct: Aligning Language Models with Self-Generated Instructions
-
14.Complexity-based prompting for multi-step reasoning
-
15.Automatic Chain of Thought Prompting in Large Language Models
-
16.Measuring and Narrowing the Compositionality Gap in Language Models
-
17.Small models are valuable plug-ins for large language models
-
18.Iteratively prompt pre-trained language models for chain of thought
-
19.Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
-
20.Noisy Channel Language Model Prompting for Few-Shot Text Classification
-
21.Structured Prompting: Scaling In-Context Learning to 1,000 Examples
-
22.k nn prompting: Learning beyond the context with nearest neighbor inference
-
23.MoT: Memory-of-Thought Enables ChatGPT to Self-Improve
关注下方《学姐带你玩AI》🚀🚀🚀
回复“上下文学习”获取全部论文+代码合集
码字不易,欢迎大家点赞评论收藏
相关文章:
大模型上下文学习(ICL)训练和推理两个阶段31篇论文
大模型都火了这么久了,想必大家对LLM的上下文学习(In-Context Learning)能力都不陌生吧? 以防有的同学不太了解,今天我就来简单讲讲。 上下文学习(ICL)是一种依赖于大型语言模型的学习任务方式…...
zibll-7.5.1)
WordPress(安装比子主题文件)zibll-7.5.1
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、新建网站二、配置ssl三.配置伪静态四.上传文件五.添加本地访问前言 提示:这里可以添加本文要记录的大概内容: 首先,我们要先理解什么是授权原理。 原理就是我们大家运营网站,点击授权…...

蓝桥杯 动态规划
01 数字三角形 #include<bits/stdc.h> using namespace std; const int N105; using lllong long; ll a[N][N],dp[N][N]; int main(){int n;cin>>n;for(int i1;i<n;i){for(int j1;j<i;j){cin>>a[i][j];}}for(int i5;i>1;i--){for(int j1;j<i;j){…...
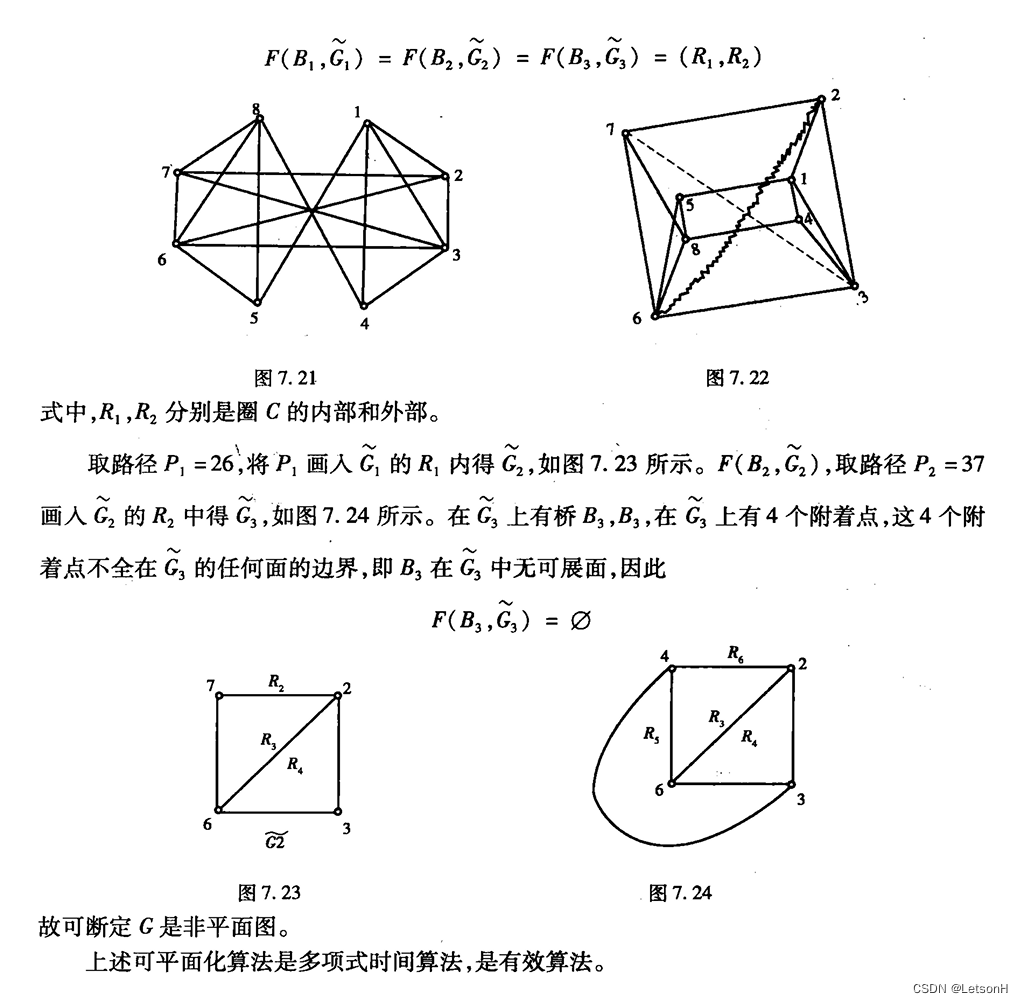
【图论】重庆大学图论与应用课程期末复习资料2-各章考点(计算部分)(私人复习资料)
图论各章考点 二、树1、避圈法(克鲁斯克尔算法)2、破圈法3、Prim算法 四、路径算法1、Dijkstra算法2、Floyd算法 五、匹配1、匈牙利算法(最大权理想匹配(最小权权值取反)) 六、行遍性问题1、Fleury算法&…...

整数和浮点数在内存中的存储(大小端详解)
目录 一、整数在内存中的存储 二、大小端字节序和字节序判断 2.1为什么有大小端? 2.2请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)-百度笔试题 方法一(char*强制类型转换)…...
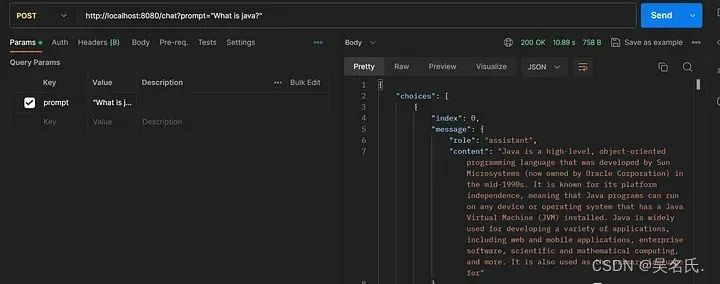
SpringBoot 集成 ChatGPT,实战附源码
1 前言 在本文中,我们将探索在 Spring Boot 应用程序中调用 OpenAI ChatGPT API 的过程。我们的目标是开发一个 Spring Boot 应用程序,能够利用 OpenAI ChatGPT API 生成对给定提示的响应。 您可能熟悉 ChatGPT 中的术语“提示”。在 ChatGPT 或类似语…...

数据结构——希尔排序(详解)
呀哈喽,我是结衣 不知不觉,我们的数据结构之路已经来到了,排序这个新的领域,虽然你会说我们还学过冒泡排序。但是冒泡排序的性能不高,今天我们要学习的希尔排序可就比冒泡快的多了。 希尔排序 希尔排序的前身是插入排…...
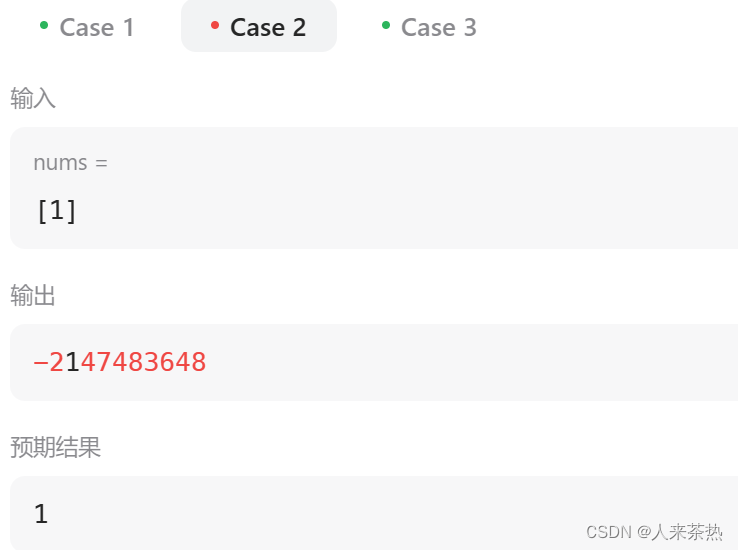
C++ day53 最长公共子序列 不相交的线 最大子序和
题目1:1143 最长公共子序列 题目链接:最长公共子序列 对题目的理解 返回两个字符串的最长公共子序列的长度,如果不存在公共子序列,返回0,注意返回的是最长公共子序列,与前一天的最后一道题不同的是子序…...

ubuntu中删除镜像和容器、ubuntu20.04配置静态ip
1 删除镜像 # 短id sudo docker rmi 镜像id # 完整id sudo docker rmi 镜像id# 镜像名【REPOSITORY:TAG】 sudo docker rmi redis:latest2 删除容器 # 删除某个具体容器 sudo docker rm 容器id# 删除Exited状态/未运行的容器,三种命令均可 sudo docker rm docker …...

华为手环 8 五款免费表盘已上线,请注意查收
华为手环 8,作为一款集时尚与实用于一体的智能手环,不仅具备强大的功能,还经常更新的表盘样式,让用户掌控时间与健康的同时,也能展现自己的时尚品味。这不,12 月官方免费表盘又上新了,推出了五款…...

JOSEF约瑟 同步检查继电器DT-13/200 100V柜内安装,板前接线
系列型号 DT-13/200同步检查继电器; DT-13/160同步检查继电器; DT-13/130同步检查继电器; DT-13/120同步检查继电器; DT-13/90同步检查继电器; DT-13/254同步检查继电器; 同步检查继电器DT-13/200 100V柜内板前接线 一、用途 DT-13型同步检查继电器用于两端供电线路的…...

龙迅#LT8311X3 USB中继器应用描述!
1. 概述 LT8311X3是一款USB 2.0高速信号中继器,用于补偿ISI引起的高速信号衰减。通过外部下拉电阻器选择的编程补偿增益有助于提高 USB 2.0 高速信号质量并通过 CTS 测试。 2. 特点 • 兼容 USB 2.0、OTG 2.0 和 BC 1.2• 支持 HS、FS、LS 信令 • 自动检测和补偿 U…...

eclipse jee中 如何建立动态网页及服务的设置问题
第一次打开eclipse 时,设置工作区时,一定是空目录 进入后 File-----NEW------Dynamic Web Project 填 项目名,不要有大写 m1 next next Generate前面打对勾 finish 第一大步: window----Preferences type filter text 处填 :Serve…...
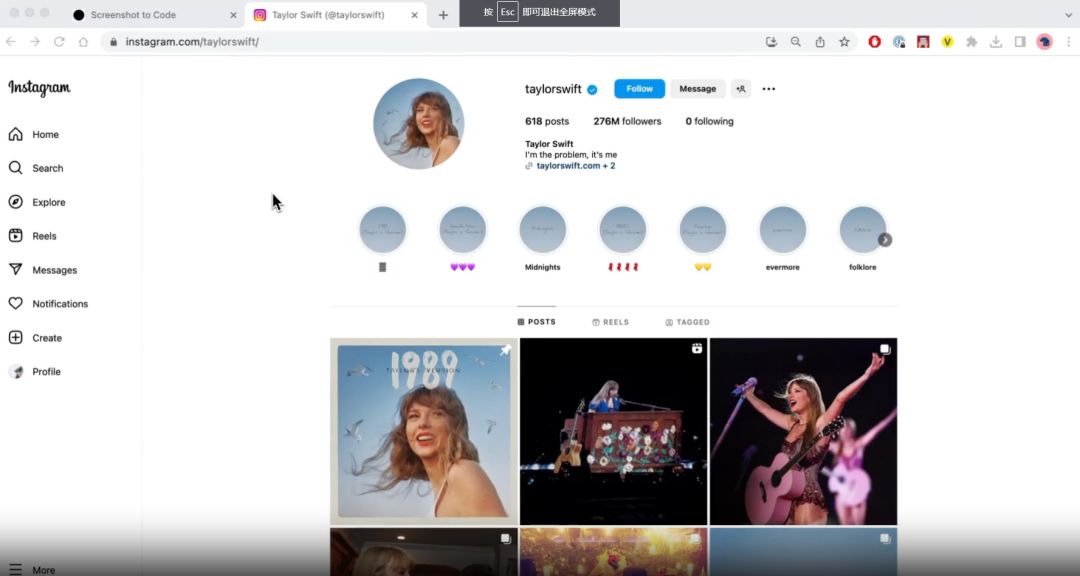
一张网页截图,AI帮你写前端代码,前端窃喜,终于不用干体力活了
简介 众所周知,作为一个前端开发来说,尤其是比较偏营销和页面频繁改版的项目,大部分的时间都在”套模板“,根本没有精力学习前端技术,那么这个项目可谓是让前端的小伙伴们看到了一丝丝的曙光。将屏幕截图转换为代码&a…...

处理k8s中创建ingress失败
创建ingress: 如果在创建过程中出错了: 处理方法就是: kubectl get ValidatingWebhookConfiguration kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission 然后再次创建,发现可以:...
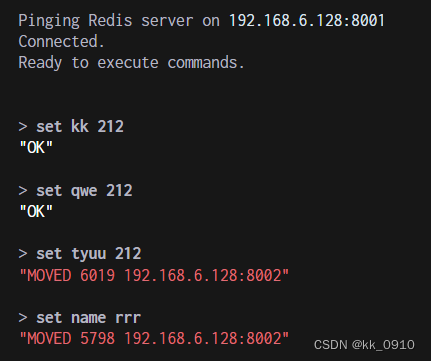
Redis高可用集群架构
高可用集群架构 哨兵模式缺点 主从切换阶段, redis服务不可用,高可用不太友好只有单个主节点对外服务,不能支持高并发单节点如果设置内存过大,导致持久化文件很大,影响数据恢复,主从同步性能 高可用集群…...

JAVA常见问题解答:解决Java 11新特性兼容性问题的六个步骤
引言: 随着技术的不断发展,Java作为一种被广泛使用的编程语言,也在不断更新和改进。Java 11作为Java的最新版本,带来了许多新的特性和改进。然而,对于一些老旧的Java应用程序来说,升级到Java 11可能会带来一…...
【C语言】深入理解指针(1)
目录 前言 (一)内存与地址 从实际生活出发 地址 内存 内存与地址关系密切 (二)指针变量 指针变量与取地址操作符 指针变量与解引用操作符 指针的大小 指针的运算 指针 - 整数 指针-指针 指针的关系运算 指针的类型的…...
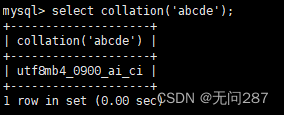
MySQL的系统信息函数
系统信息函数让你更好的使用MySQL数据库 1、version()函数 查看MySQL系统版本信息号 select version();2、connection_id()函数 查看当前登入用户的连接次数 直接调用CONNECTION_ID()函数--不需任何参数--就可以看到当下连接MySQL服务器的连接次数,不同时间段该…...
 方法)
python中.format() 方法
.format() 方法是一种用于格式化字符串的方法,它允许将变量的值插入到字符串中的占位符位置上。该方法可以接受一个或多个参数,并根据给定的格式规则将它们插入到字符串中。 下面是一些使用 .format() 方法的示例: # 基本用法 name "…...

从RISC-V到SSITH:构建下一代硬件安全架构的开放之路
1. 项目概述:从“亡羊补牢”到“未雨绸缪”的硬件安全范式转移在智能设备无处不在的今天,我们正面临一个尴尬的现实:许多产品的安全设计,更像是在一栋已经建好的毛坯房里,见缝插针地安装防盗门和监控摄像头。这种“事后…...

每天140万亿次“Token“在狂奔!这组数据背后,有人赚疯,有人焦虑到失眠
> 就在今天,你刷的每一条AI回复,都在创造历史。0101 你随口的一句话,正在"吃掉"一座超级计算机你有没有这种感觉——早上用豆包写了个周报,中午让Kimi帮你总结了一份PDF,下午在微信里让AI画了一张插画&am…...

如何使用日志实现业务全链路追踪
在现代分布式系统架构中,一个业务请求往往需要经过多个服务节点的协同处理,涉及网关、微服务、数据库、缓存、消息队列等多个组件。传统的日志记录方式通常局限于单个服务或模块,难以还原一个完整请求的流转路径,给问题排查、性能…...

从苹果FBI解锁案看现代加密技术与工程师伦理抉择
1. 事件背景与核心争议点2016年初,美国联邦调查局(FBI)向苹果公司提出了一项史无前例的要求:协助解锁一部属于圣贝纳迪诺枪击案枪手的iPhone 5c。这部手机设置了密码保护,并启用了“数据自毁”功能,即在连续…...

Next.js App Router 实战:从官方 Playground 探索现代 Web 开发最佳实践
1. 项目概述与定位最近在捣鼓 Next.js 的几个新特性,比如 Server Actions、并行路由、拦截路由这些,光看文档总觉得隔靴搔痒,想找个能上手实操、快速验证想法的环境。这时候,Vercel 官方维护的next-app-router-playground项目就成…...

移动端优化awesome-stock-resources:响应式素材适配终极指南
移动端优化awesome-stock-resources:响应式素材适配终极指南 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/aweso…...

RAG:嵌入模型评估与选型
在RAG系统中,嵌入模型是检索质量的关键组件,它决定了系统能否真正“理解”用户意图并从海量知识中精准召回相关信息,其语义匹配精度直接决定了整个RAG的性能上限。 一、嵌入模型评估指标 1.1 公开基准 MTEB v2 是目前全球公认最权威的大规…...

学术生产力革命已来,NotebookLM Agent如何把文献综述时间压缩83%?实测数据首次公开!
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Agent研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度理解与推理的 AI 助手,其内置的 Agent 能力可显著提升学术研究、技术调研与知识整合效率。当启用 Agent 模…...

大厂HR坦言:这3种“计算机巨坑”,90%的学生都在踩!如何逆袭成高薪抢手人?
文章指出,计算机专业就业难,但优秀人才依然稀缺。多数学生因方向错误导致努力白费。常见弯路包括:过度刷题缺乏项目、技术广博但不精、忽视GPA与实习。文章强调,学生需明确用人单位需求,重视项目与实习,夯实…...

TigerVNC终极指南:快速掌握跨平台远程桌面控制
TigerVNC终极指南:快速掌握跨平台远程桌面控制 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc TigerVNC是一款高性能、跨平台的VNC客户端和服务器软件࿰…...