策略梯度简明教程
策略梯度方法 (PG:Policy Gradient) 是强化学习 (RL:Reinforcement Learning) 中常用的算法。
1、从库里的本能开始
PG的原理很简单:我们观察,然后行动。人类根据观察采取行动。 引用斯蒂芬·库里的一句话:
你必须依靠这样一个事实:你付出了努力来创造肌肉记忆,然后相信它会发挥作用。你如此多地练习和努力的原因是,在比赛过程中你的直觉会在一定程度上发挥作用。 如果你没有以正确的方式去做,就会感觉很奇怪。

不断的练习是运动员建立肌肉记忆的关键。 对于 PG,我们训练一个基于观察来采取行动的策略。 PG 中的训练使得高奖励的行动更有可能发生,反之亦然。
我们保留有效的,丢弃无效的。
在策略梯度方法中,库里是我们的代理人。
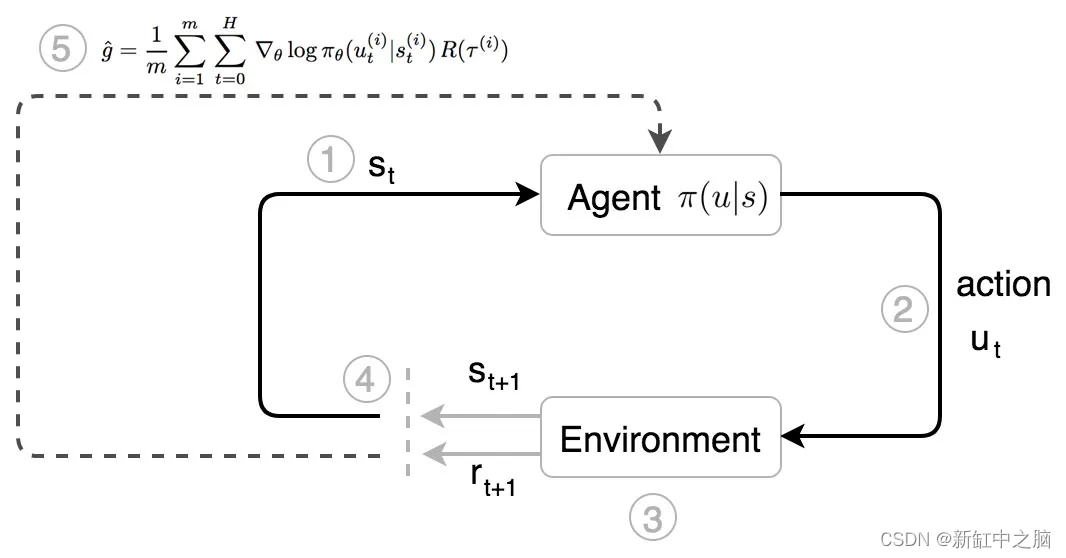
- 他观察环境的状态。
- 他根据自己对状态 s 的本能(策略 π)采取行动(u)。
- 他移动,对手做出反应。 一个新的状态形成了。
- 他根据观察到的状态采取进一步的行动。
- 经过 运动轨迹τ 后,他根据收到的总奖励 R(τ) 调整自己的本能。
库里看到了情况并立即知道该怎么做。 多年的训练完善了最大化回报的本能。 在强化学习中,本能可以在数学上描述为:
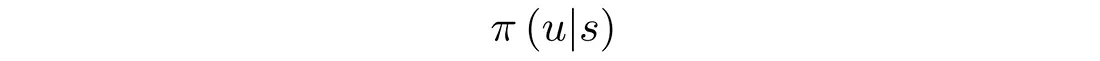
即在给定状态 s 的情况下采取动作 u 的概率。 π 是强化学习中的策略。 例如,当你看到前面有车时转弯或停车的机会有多大:

2、策略梯度的学习目标
我们如何用数学方式制定我们的目标? 期望得到的奖励等于轨迹的概率×相应奖励之和:
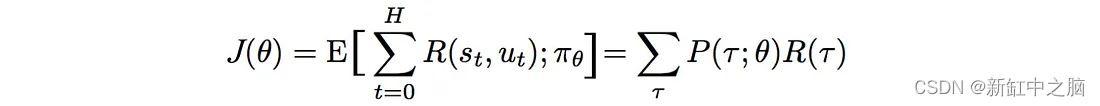
我们的目标是找到策略 θ,使其可以创建轨迹 τ :

而轨迹τ能够最大化预期回报:

3、输入特征和奖励
策略梯度方法的输入(即状态s)可以是手工制作的状态特征(如机械臂关节的角度、速度等),但在某些问题领域,强化学习已经足够成熟,可以直接处理原始图像。 π 可以是一个确定性策略,它输出要采取的确切操作(如向左或向右移动操纵杆),也可以是一个随机策略,它输出它可能采取的行动的可能性。
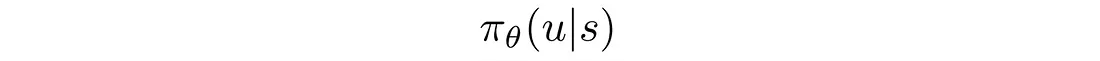
我们记录每个时间步给出的奖励 r。 在篮球比赛中,除了终止状态为0、1、2或3外,其他状态均为0。
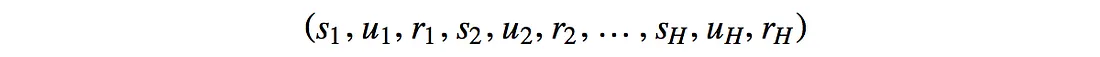
我们再引入一个术语 H,称为地平线。 我们可以无限期地运行模拟过程(h→∞),直到达到终止状态,或者我们对 H 步设置限制。
4、优化问题
首先,让我们回顾一下深度学习和强化学习中常见且重要的技巧,函数 f(x) (R.H.S.) 的偏微分等于 f(x) 乘以 log(f(x)) 的偏微分:
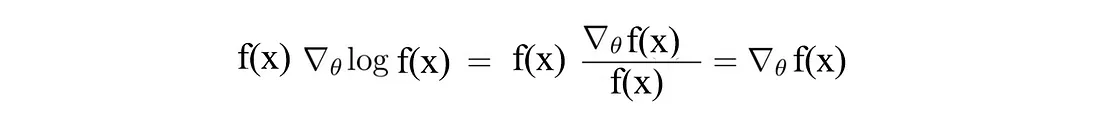
将 f(x) 替换为 π,得到:
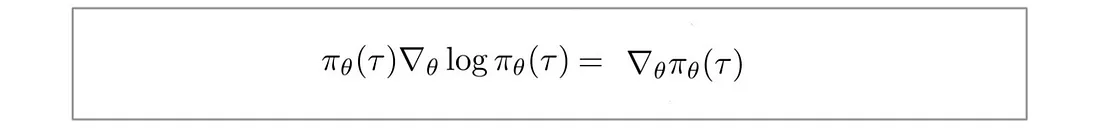
另外,对于连续空间,期望可以表示为:
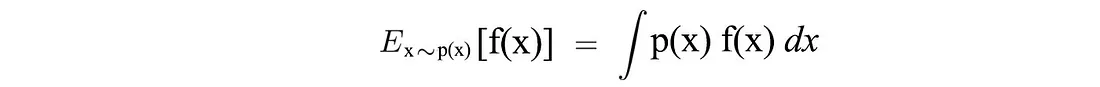
现在,让我们用数学形式形式化我们的优化问题。 我们想要建立一个策略模型,该模型能够产生最大化总回报的轨迹:
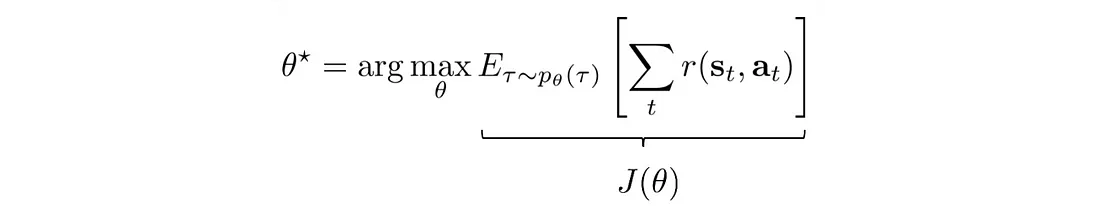
然而,要使用梯度下降来优化我们的问题,我们是否需要对奖励函数 r 求导,而该导数可能不可微分或形式化?
让我们将目标函数 J 重写为:

梯度(策略梯度)变成:
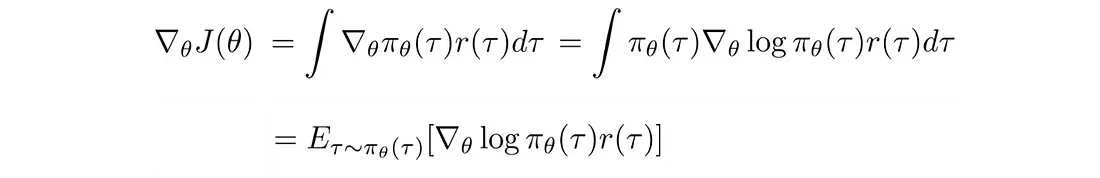
好消息! 策略梯度可以表示为期望, 这意味着我们可以使用采样来近似它。 此外,我们对 r 的值进行采样,但不对其进行微分。 这是有道理的,因为奖励并不直接取决于我们如何参数化模型,但轨迹 τ 是。 那么log π(τ) 的偏导数是多少。
π(τ) 定义为:
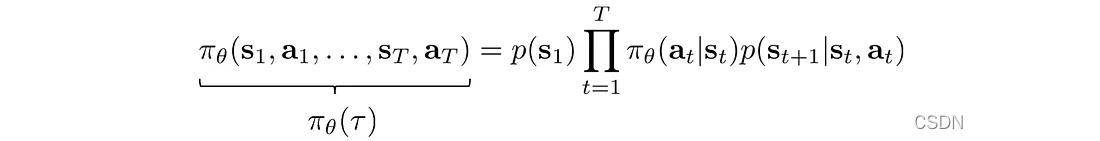
取对数:

第一项和最后一项不依赖于 θ,可以删除。

所以策略梯度:
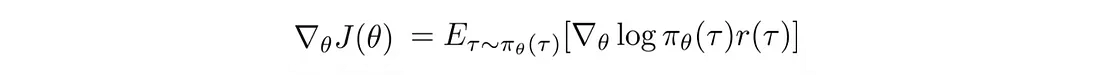
变成:
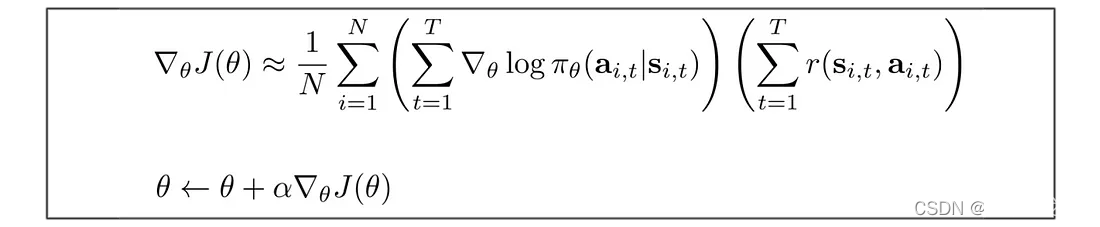
我们使用这个策略梯度来更新策略θ。
5、关于梯度更新的直觉
我们如何理解这些公式?

下划线项是最大对数似然。 在深度学习中,它测量观察到的数据的可能性。 在我们的背景下,它衡量当前策略下轨迹的可能性。 通过将其与奖励相乘,如果轨迹产生高额正奖励,我们希望增加策略的可能性。 相反,如果一个策略导致较高的负面回报,我们希望降低该策略的可能性。 简而言之,保留有效的,丢弃无效的。
如果爬上山意味着更高的奖励,我们将更改模型参数(策略)以增加轨迹向上移动的可能性:
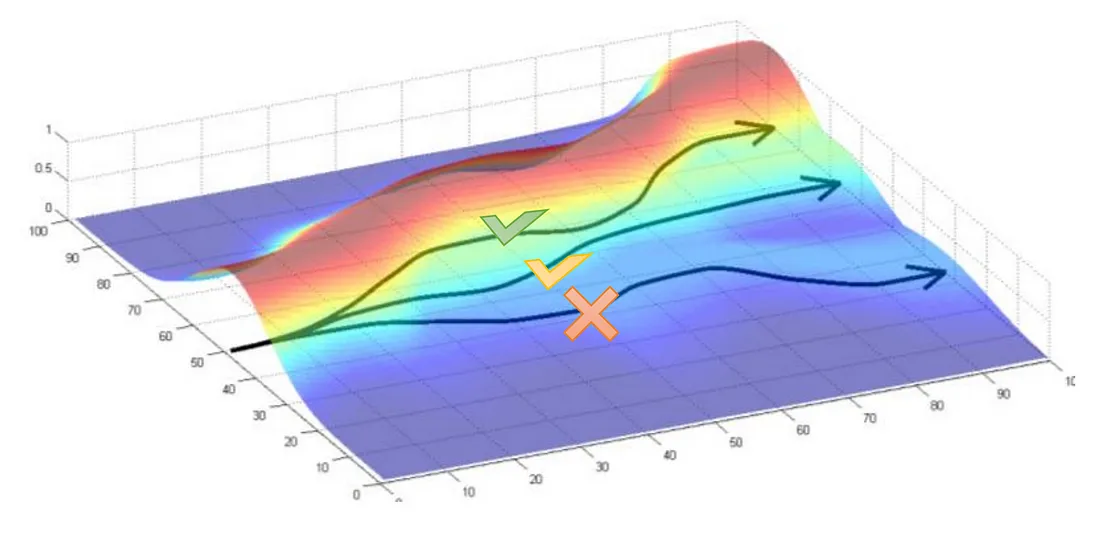
策略梯度有一件重要的事情。 轨迹的概率定义为:

轨迹中的状态密切相关。 在深度学习中,与强相关因子的长序列相乘很容易触发梯度消失或梯度爆炸。 然而,策略梯度只是对梯度进行求和,从而打破了长序列相乘的诅咒。
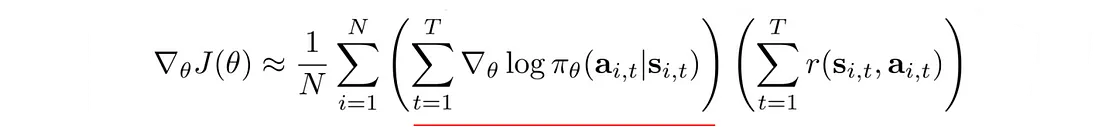
这使用了一个小技巧:

创建最大对数似然,并且对数打破了长链策略相乘的诅咒。
6、基于蒙特卡洛走子的策略梯度
下面是使用Monte Carlo rollouts来计算奖励的强化学习算法。 即播放整个情节(episode)来计算总奖励:

可以使用许多深度学习软件包轻松计算策略梯度。 例如,这是 TensorFlow 的部分代码:

是的,通常情况下,编码看起来比解释更简单。
7、使用高斯策略进行连续控制
我们如何建立连续控制模型?
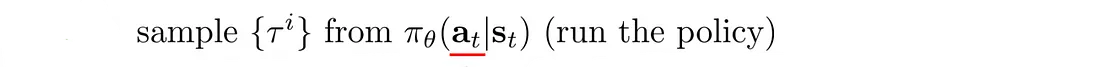
假设动作的值是高斯分布的:

该策略是使用高斯分布定义的,其平均值是根据深度网络计算得出的:
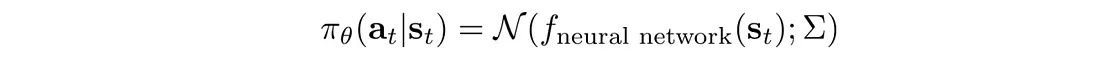
以及:
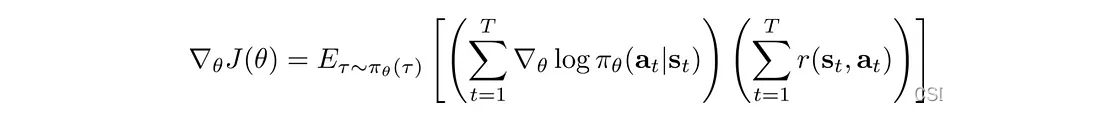
我们可以将 log π 的偏微分计算为:
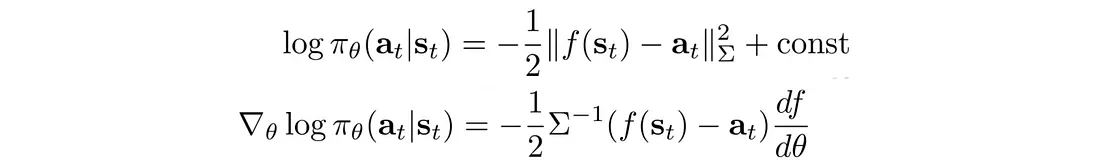
所以我们可以反向传播:

通过策略网络π来更新策略θ。 该算法看起来与以前完全相同。 只需以稍微不同的方式开始计算策略的对数即可:

8、策略梯度改进
策略梯度存在高方差和低收敛性的问题。
蒙特卡洛播放整个轨迹并记录轨迹的确切奖励。 然而,随机政策可能在不同时期采取不同的行动。 一个小转弯就可以完全改变结果。 所以蒙特卡罗没有偏差(bias),但方差(variance)很高。 方差会损害深度学习优化。 方差为模型学习提供了冲突的下降方向。 一个采样的奖励可能想要增加对数可能性,而另一个采样的奖励可能想要减少它。 这会损害收敛性。 为了减少由动作引起的方差,我们希望减少采样奖励的方差。
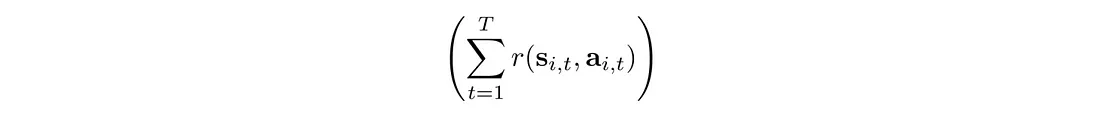
增加 PG 中的批大小可以减少方差。
然而,增加批大小会显着降低样本效率。 所以我们不能将其增加太多,我们需要额外的机制来减少方差。
8.1 基线
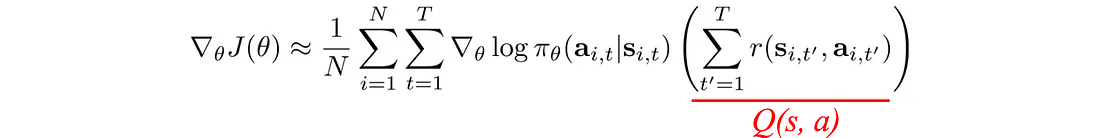
我们可以在优化问题中减去一项,只要该项与 θ 无关。 因此,我们不使用总奖励,而是用 V(s) 减去它。
我们定义优势函数 A 并根据 A 重写策略梯度:
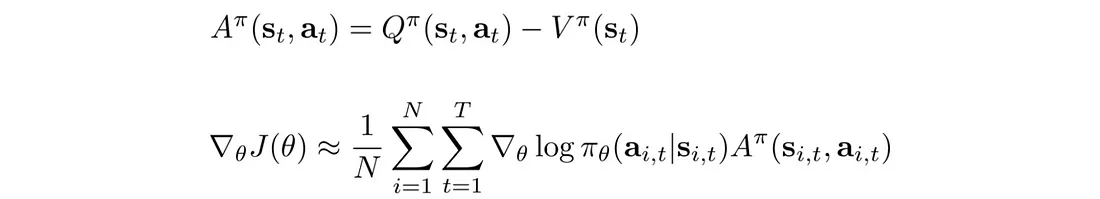
在深度学习中,我们希望输入特征以零为中心。 直观上,强化学习感兴趣的是了解某个动作是否执行得比平均值更好。 如果奖励总是正数(R>0),PG 总是尝试增加轨迹概率,即使它收到的奖励比其他人少得多。 考虑两种不同的情况:
- 情况1:轨迹A获得+10奖励,轨迹B获得-10奖励。
- 情况2:轨迹A获得+10奖励,轨迹B获得+1奖励。
在第一种情况下,PG会增加轨迹A的概率,同时减少B的概率。在第二种情况下,它将增加两者。 作为人类,我们可能会降低这两种情况下轨迹 B 的可能性。
通过引入 V 这样的基线,我们可以重新调整相对于平均动作的奖励。
8.2 普通策略梯度算法
这是使用基线 b 的策略梯度算法的通用算法。
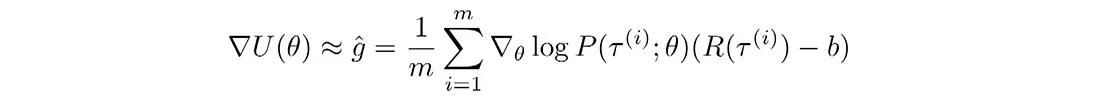

8.3 因果性
未来的行动不应改变过去的决定。 当前的行动只会影响未来。 因此,我们可以改变我们的目标函数来反映这一点:

8.4 奖励折扣
奖励折扣减少了差异,从而减少了远期操作的影响。 这里,使用不同的公式来计算总奖励:

相应的目标函数变为:
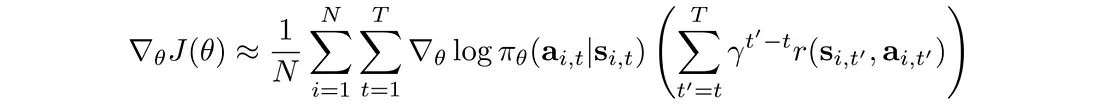
原文链接:策略梯度简明教程 - BimAnt
相关文章:
策略梯度简明教程
策略梯度方法 (PG:Policy Gradient) 是强化学习 (RL:Reinforcement Learning) 中常用的算法。 1、从库里的本能开始 PG的原理很简单:我们观察,然后行动。人类根据观察采取行动。 引用斯蒂芬库里的一句话: 你必须依靠…...

鸿蒙原生应用/元服务开发-利用picker选择器来多选相册图片
前言 在之前的时候,测试一个应用进入相册选择图片demo,利用了startAbilityForResult()方法,启动相对应的Ability来完成效果,但是这种方法有限制,一次只能获取一张图片,在完成某些功能测试的时候就很不方便。…...
java:封装统一的响应体code、data、msg、paging
背景 我们在写接口的时候一般不会直接返回给前端数据,而是会有响应体,比如 code、data、msg,这样就有一个统一的结构方便前端处理,那么今天就来封装一个统一的响应体 封装基本响应体 1、在 config 包里新建 ApiResponse.java …...

leetcode算法之栈
目录 1.删除字符串中的所有相邻重复项2.比较含退格的字符串3.基本计算器II4.字符串解码5.验证栈序列 1.删除字符串中的所有相邻重复项 删除字符串中的所有相邻重复项 class Solution { public:string removeDuplicates(string s) {string ret;//使用数组模拟栈操作for(auto …...
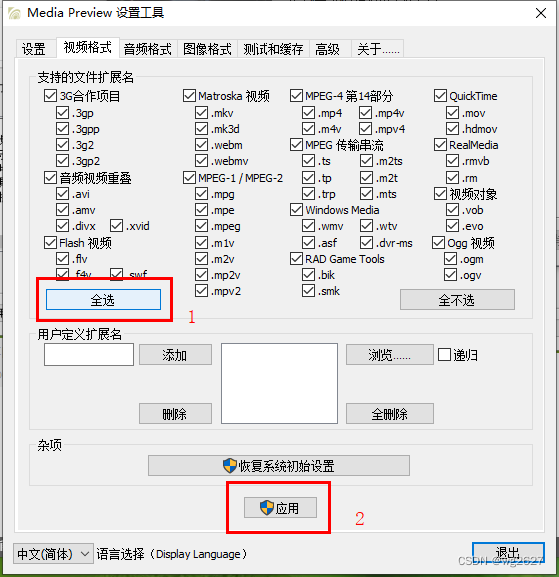
电脑上mp4视频文件无缩略图怎么办
前言:有时候电脑重装后电脑上的mp4视频文件无缩略图,视频文件数量比较多的时候查找比较麻烦 以下方法亲测有效: 1、下载MediaPreview软件 2、软件链接地址:https://pan.baidu.com/s/1bzVJpmcHyGxXNjnzltojtQ?pwdpma0 提取码&…...

【Centos8】配置网络镜像源
文章目录 配置 yum 源配置网络 yum 源备份下载阿里 centos-base.repo 到 /etc/yum.repos.d/安装 EPEL 源测试安装 配置 yum 源 # 检查是否安装了 yum rpm -qa|grep yum# 查看本地已安装的所有软件包 yum list installed# 查看软件包安装位置 # 查看某个东西的软件包 rpm -qa|g…...

深入学习Synchronized各种使用方法
文章目录 前言一、synchronized关键字通用在下面四个地方:1.1synchronized修饰实例方法1.2synchronized修饰静态方法:1.3synchronized修饰实例方法的代码块1.4synchronized修饰静态方法的代码块2.读入数据 二.Sychronized关键特性2.1互斥2.2 刷新内存2.3…...

【idea】设置鼠标滚轮控制缩放大小
1、点击file 选择Setting 2、点击Editor 下面的 General 3、勾选 Mouse Control 下面的 Change font size with CtrlMouse Wheel in 4、点级apply 5、按 ctrl键 鼠标滚轮缩放字体的大小...
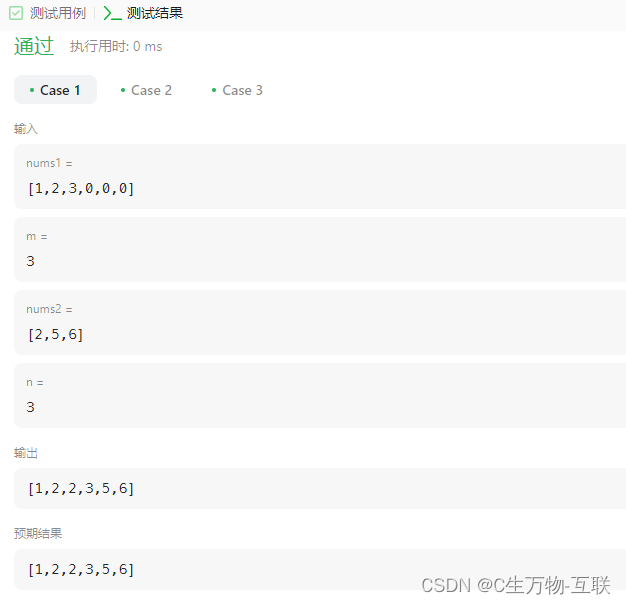
合并两个有序数组(leetcode_刷题1)
目录 题目:合并两个有序数组 题目分析方向1: 题目分析方向2: 题目:合并两个有序数组 题目要求: 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums…...
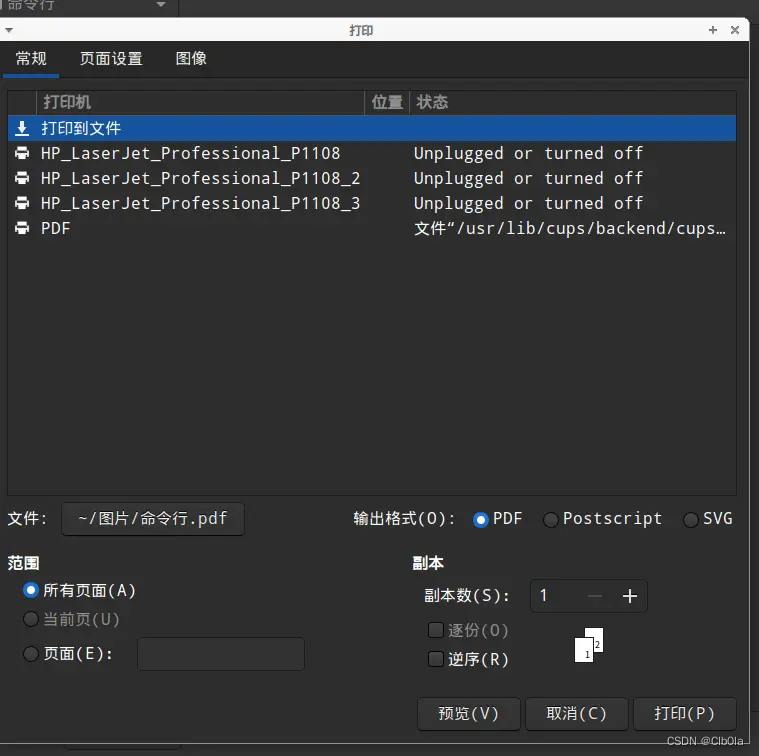
麒麟linux将图片批量生成PDF的方法
笔者手里有一批国产linu系统,目前开始用在日常的工作生产环境中,我这个老程序猿勉为其难的充当运维的或网管的角色。 国产linux系统常见的为麒麟Linux,统信UOS等,基本都是基于debian再开发的linux。 问题描述: wind…...
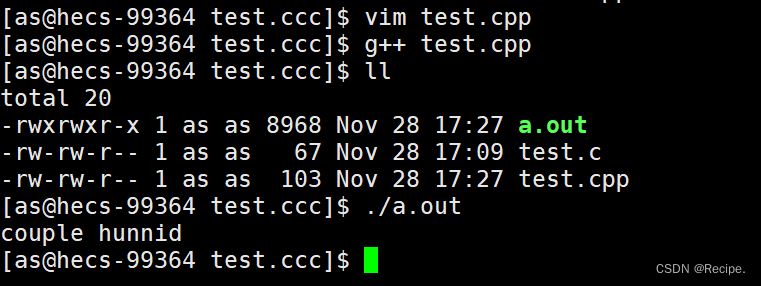
Linux——vim编辑文件时——.swp文件解决方案
test.cpp样例 当我们vim test.cpp进入编辑文件。 却忘记了保存退出 再次进入就会出现一下画面 当你摁下Enter键位 出现以下几个选项 O——是只读不写 E——是正常打开文件但不会载入磁盘内容 R——覆盖——是加载存储磁盘的文件(当我们忘记保存时,系统会自动帮我…...

【Maven】清理 maven 仓库
初始情况下,我们的本地仓库是没有任何jar包的,此时会从私服去下载(如果没有配置,就直接从中央仓库去下载)。 可能由于网络的原因,jar包下载不完全,这些不完整的jar包都是以lastUpdated结尾。此…...
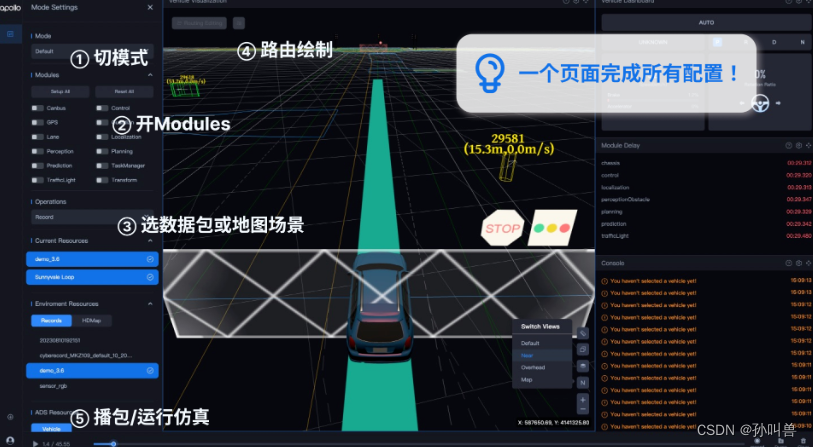
APOLLO自动驾驶技术沙龙:未来已来,共创智能交通新时代
在这次Apollo会议上,我深刻地感受到了人工智能自动驾驶技术领域的最新进展和未来趋势。作为一名从事软件开发工作的人员,我深感荣幸能够参加这次盛会。 前言 本次活动是百度Apollo社区工程师齐聚首钢Park,带来现场实操与技术分享。主要围绕Ap…...

Java面试题12
1.redis 怎么实现分布式锁? Redis可以通过以下方式实现分布式锁: 使用RedLock算法:多个Redis节点组合使用,通过竞争锁来达到分布式锁的效果。使用SETNX命令:利用SETNX(SET if Not eXists)命令…...

ubuntu上创建服务启动python脚本
场景 最近在使用ubuntu服务器部署MySQL和同步数据,同步数据使用的是python,但是我不能直接操作服务器,只能通过Xshell远程访问服务器,但是启动python脚本的时候如果关掉xshell会停止Python脚本,所以如果要让python脚本…...

51单片机制作数字频率计
文章目录 简介设计思路工作原理Proteus软件仿真软件程序实验现象测量误差和范围总结 简介 数字频率计是能实现对周期性变化信号频率测量的仪器。传统的频率计通常是用很多的逻辑电路和时序电路来实现的,这种电路一般运行较慢,而且测量频率的范围较小。这…...

java中强引用、软引用、弱引用、虚引用的区别是什么?
Java中的引用类型主要分为强引用、软引用、弱引用和虚引用,它们之间的区别主要体现在垃圾回收的行为上。 强引用(Strong Reference):这是使用最普遍和默认的引用类型。如果一个对象具有强引用,那么垃圾回收器就永远不会…...
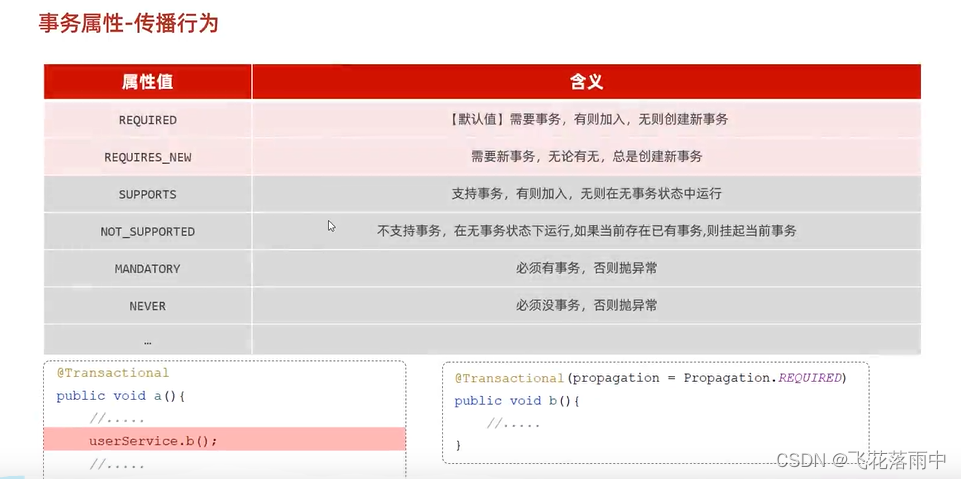
springboot -事务管理
事务 概念 事务是一组操作的集合,它是一个不可分割的工作单位,这些操作要么同时成功,要么同时失败。 操作 开启事务: start transaction / begin提交事务:commit回滚事务: rollback 注解 Transactional …...

商城系统通过Kafka消息队列,实现订单的处理和状态更新
以下是一个简单的Spring Boot应用程序示例,演示如何使用Kafka实现订单的处理和状态更新。 首先,我们创建一个名为“order”的topic,在application.yaml配置文件中添加Kafka的配置: spring:kafka:bootstrap-servers: localhost:9…...
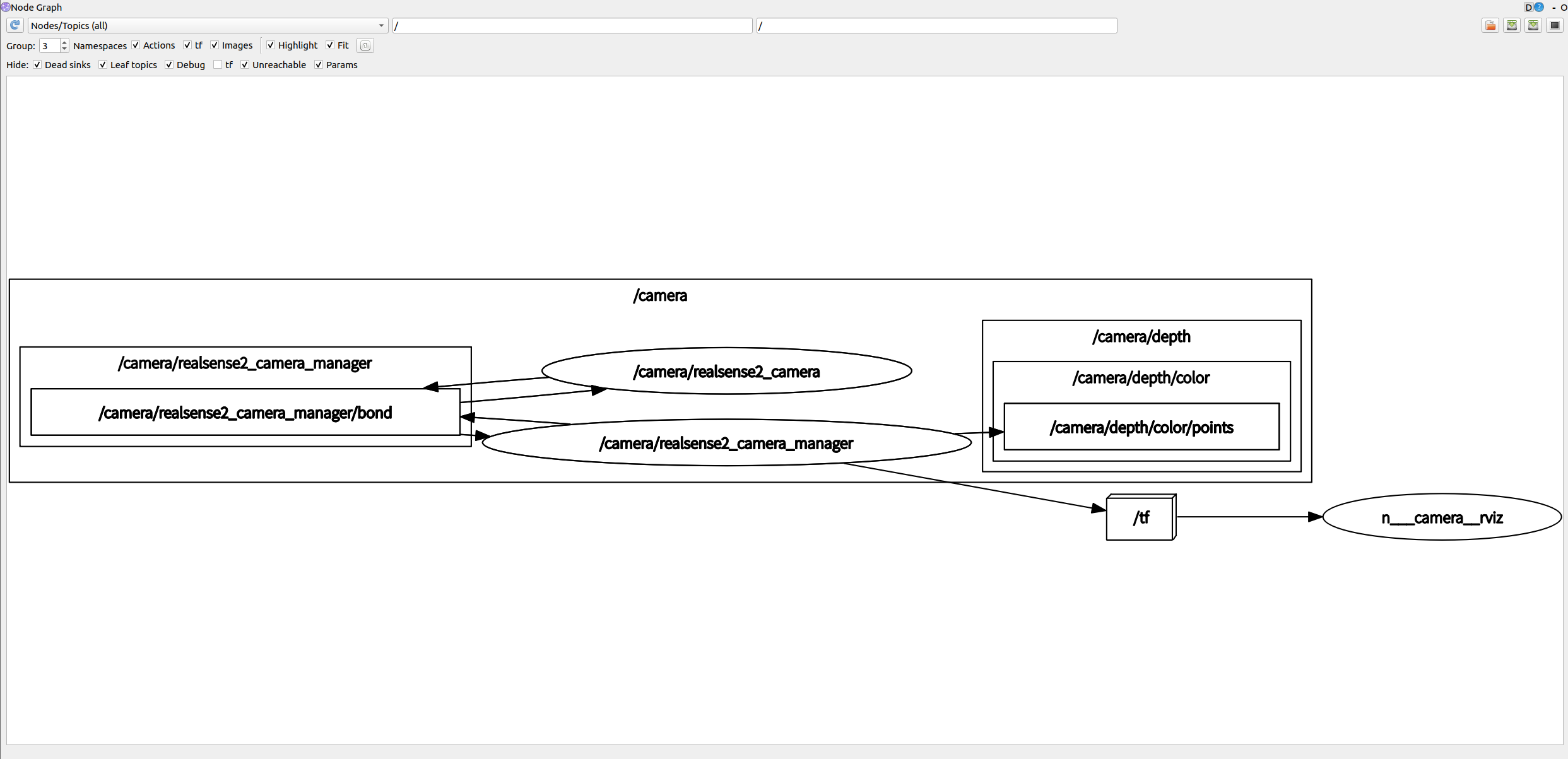
IntelRealSense深度相机D455在ROS1运行中的消息内容
IntelRealSense深度相机D455在ROS1运行中的消息内容 通过下面命令所有相关信息通过ros topic的方式发布出去rosnode查看rqt_graph查看rostopic查看通过下面命令直接查看RVIZ中点云信息rosnode查看rqt_graph查看rostopic查看 Physical Port:: /sys/devices/pci0000:0…...
在汽车电子中的关键技术解析)
数字信号控制器(DSC)在汽车电子中的关键技术解析
1. 数字信号控制器的技术演进与核心定位在嵌入式控制领域,我们正见证着一场处理器架构的静默革命。十年前当我第一次接触到Motorola 56F8300系列芯片时,就意识到这种融合了MCU和DSP特性的混合架构将彻底改变机电控制系统的设计范式。数字信号控制器&…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...

AI如何重塑科学创新:从构思成本坍塌到知识组合爆炸
1. 科学创新的范式转移:从“不确定性”到“风险”在过去的科研实践中,我们常常面临一个根本性的困境:不确定性。这并非指我们不知道某个实验的结果,而是指我们连可能的结果是什么、其发生的概率有多大,都无从知晓。这就…...

群晖NAS进阶指南:借助Docker容器部署全能DDNS服务,实现多平台域名与公网IP智能同步
1. 为什么需要全能DDNS服务? 家里有群晖NAS的朋友可能都遇到过这样的烦恼:明明设置了外网访问,但过几天就失效了。这是因为大多数家庭宽带分配的都是动态公网IP,运营商会定期更换你的IP地址。想象一下,这就像你的手机…...

Active Record Doctor与多数据库支持:MySQL、PostgreSQL、SQLite兼容性详解
Active Record Doctor与多数据库支持:MySQL、PostgreSQL、SQLite兼容性详解 【免费下载链接】active_record_doctor Identify database issues before they hit production. 项目地址: https://gitcode.com/gh_mirrors/ac/active_record_doctor Active Recor…...

Super IO插件终极指南:5分钟掌握Blender文件处理革命
Super IO插件终极指南:5分钟掌握Blender文件处理革命 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io Super IO是一款彻底改变Blender工作流程的革命性插件,它通…...

FanControl终极指南:5步解决Windows风扇噪音与过热难题
FanControl终极指南:5步解决Windows风扇噪音与过热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

热潮下的冷思考:从OpenClaw“龙虾”困境看AI Agent的理性选择与国产平替
2026年初,开源AI智能体项目OpenClaw(俗称“小龙虾”)以一种近乎野蛮的方式闯入大众视野。两天内GitHub星标突破17万,线下排队安装,甚至催生了“代装龙虾”的灰色产业。然而,这场技术狂欢的B面,却…...

终极ComfyUI视频插件指南:从零开始构建AI视频生成工作流
终极ComfyUI视频插件指南:从零开始构建AI视频生成工作流 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾梦想过让静态图片“活”起来,或者让文字描述直接变成生动…...
)
Cadence 17.4导出Gerber文件保姆级避坑指南(附TMC2300电机驱动板实战)
Cadence 17.4导出Gerber文件保姆级避坑指南(附TMC2300电机驱动板实战) 第一次用Cadence Allegro 17.4导出Gerber文件的新手,大概率会在某个环节卡住——要么是钻孔文件莫名报错,要么是板厂反馈光绘层对不齐。这种挫败感我太熟悉了…...