Ubuntu20.04部署TVM流程及编译优化模型示例
前言:记录自己安装TVM的流程,以及一个简单的利用TVM编译模型并执行的示例。
1,官网下载TVM源码
git clone --recursive https://github.com/apache/tvmgit submodule init
git submodule update
顺便完成准备工作,比如升级cmake版本需要3.18及以上版本。还有如下库:
sudo apt-get update
sudo apt-get install -y python3 python3-dev python3-setuptools gcc libtinfo-dev zlib1g-dev build-essential cmake libedit-dev libxml2-dev
2,安装clang,llvm,ninja
llvm安装依赖clang和ninja,所以直接安装llvm即可顺便完成全部的安装。
llvm ,clang安装参考:Linux系统无痛编译安装LLVM简明指南_linux安装llvm11-CSDN博客
步骤如下:
git clone git@github.com:llvm/llvm-project.gitcd llvm-project
mkdir buildcd buildsudo cmake ../llvm -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE=Debug
sudo make -j8
sudo make install检查版本:
clang --version
llvm-as --version
3,安装NNPACK
NNPACK是为了优化加速神经网络的框架,可以提高在CPU上的计算效率
git clone --recursive https://github.com/Maratyszcza/NNPACK.git
cd NNPACK
# Add PIC option in CFLAG and CXXFLAG to build NNPACK shared library
sed -i "s|gnu99|gnu99 -fPIC|g" CMakeLists.txt
sed -i "s|gnu++11|gnu++11 -fPIC|g" CMakeLists.txt
mkdir build
cd build
# Generate ninja build rule and add shared library in configuration
cmake -G Ninja -D BUILD_SHARED_LIBS=ON ..
ninja
sudo ninja install# Add NNPACK lib folder in your ldconfig
sudo sh -c "echo '/usr/local/lib'>> /etc/ld.so.conf.d/nnpack.conf"
sudo ldconfig
4,编译TVM
如下步骤,在tvm建立build文件夹,把config.cmake复制到build中
cd tvm
mkdir buildcp cmake/config.cmake buildbuild里的config.cmake是编译配置文件,可以按需打开关闭一些开关。下面是我修改的一些配置(TENSORRT和CUDNN我以为之前已经配置好了,结果编译报了这两个的错误,如果只是想跑流程,可以不打开这两个的开关,这样就能正常编译结束了)
set(USE_RELAY_DEBUG ON)
set(USE_CUDA ON)
set(USE_NNPACK ON)
set(USE_LLVM ON)
set(USE_TENSORRT_CODEGEN ON)
set(USE_TENSORRT_RUNTIME ON)
set(USE_CUDNN ON)编译代码:
cd build
cmake ..make -j12
5,配置python环境
从build文件夹出来进入到tvm/python文件夹下,执行如下命令,即可配置python中的tvm库了。
cd ../python
python setup.py installpython中使用tvm测试,导入tvm不出错即配置tvm安装成功
import tvmprint(tvm.__version__)
6,一个简单示例
该测试来自TVM官方文档的示例,包括编译一个测试执行一个分类网络和编译器自动调优测试。仅先直观的看到TVM如何作为一个工具对模型编译并部署的流程。
1) 下载onnx模型
wget https://github.com/onnx/models/raw/b9a54e89508f101a1611cd64f4ef56b9cb62c7cf/vision/classification/resnet/model/resnet50-v2-7.onnx
2) 编译onnx模型
python -m tvm.driver.tvmc compile --target "llvm" --input-shapes "data:[1,3,224,224]" --output resnet50-v2-7-tvm.tar resnet50-v2-7.onnx如果报这样的警告:
就在git上下载一份tophub,把整个文件夹tophub复制到 ~/.tvm/路径下
git clone git@github.com:tlc-pack/tophub.git
sudo cp -r tophub ~/.tvm/解压生成的tvm编译模型,得到3个文件:
-
mod.so作为一个C++库的编译模型, 能被 TVM runtime加载 -
mod.json TVM Relay计算图的文本表示 -
mod.paramsonnx模型的预训练权重参数
mkdir model
tar -xvf resnet50-v2-7-tvm.tar -C model
ls model3) 输入数据前处理
python preprocess.py图像处理代码文件:preprocess.py
#!python ./preprocess.py
from tvm.contrib.download import download_testdata
from PIL import Image
import numpy as npimg_url = "https://s3.amazonaws.com/model-server/inputs/kitten.jpg"
img_path = download_testdata(img_url, "imagenet_cat.png", module="data")# Resize it to 224x224
resized_image = Image.open(img_path).resize((224, 224))
img_data = np.asarray(resized_image).astype("float32")# ONNX expects NCHW input, so convert the array
img_data = np.transpose(img_data, (2, 0, 1))# Normalize according to ImageNet
imagenet_mean = np.array([0.485, 0.456, 0.406])
imagenet_stddev = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(img_data.shape).astype("float32")
for i in range(img_data.shape[0]):norm_img_data[i, :, :] = (img_data[i, :, :] / 255 - imagenet_mean[i]) / imagenet_stddev[i]# Add batch dimension
img_data = np.expand_dims(norm_img_data, axis=0)# Save to .npz (outputs imagenet_cat.npz)
np.savez("imagenet_cat", data=img_data)4) 运行编译模型
python -m tvm.driver.tvmc run --inputs imagenet_cat.npz --output predictions.npz resnet50-v2-7-tvm.tar5) 输出后处理
python postprocess.py执行之后得到分类结果的输出:
class='n02123045 tabby, tabby cat' with probability=0.621104
class='n02123159 tiger cat' with probability=0.356378
class='n02124075 Egyptian cat' with probability=0.019712
class='n02129604 tiger, Panthera tigris' with probability=0.001215
class='n04040759 radiator' with probability=0.000262
后处理代码:postprocess.py
#!python ./postprocess.py
import os.path
import numpy as npfrom scipy.special import softmaxfrom tvm.contrib.download import download_testdata# Download a list of labels
labels_url = "https://s3.amazonaws.com/onnx-model-zoo/synset.txt"
labels_path = download_testdata(labels_url, "synset.txt", module="data")with open(labels_path, "r") as f:labels = [l.rstrip() for l in f]output_file = "predictions.npz"# Open the output and read the output tensor
if os.path.exists(output_file):with np.load(output_file) as data:scores = softmax(data["output_0"])scores = np.squeeze(scores)ranks = np.argsort(scores)[::-1]for rank in ranks[0:5]:print("class='%s' with probability=%f" % (labels[rank], scores[rank]))6) 编译器自动调优
调优的算法使用的是xgboost,所以需要python安装一下这个库。
pip install xgboostpython -m tvm.driver.tvmc tune --target "llvm" --output resnet50-v2-7-autotuner_records.json resnet50-v2-7.onnx7) 重新编译并执行调优后的模型
python -m tvm.driver.tvmc compile --target "llvm" --tuning-records resnet50-v2-7-autotuner_records.json --output resnet50-v2-7-tvm_autotuned.tar resnet50-v2-7.onnxpython -m tvm.driver.tvmc run --inputs imagenet_cat.npz --output predictions.npz resnet50-v2-7-tvm_autotuned.tarpython postprocess.py预测结果:
class='n02123045 tabby, tabby cat' with probability=0.610552
class='n02123159 tiger cat' with probability=0.367180
class='n02124075 Egyptian cat' with probability=0.019365
class='n02129604 tiger, Panthera tigris' with probability=0.001273
class='n04040759 radiator' with probability=0.000261
8) 比较编译前后执行模型的速度
python -m tvm.driver.tvmc run --inputs imagenet_cat.npz --output predictions.npz --print-time --repeat 100 resnet50-v2-7-tvm_autotuned.tarpython -m tvm.driver.tvmc run --inputs imagenet_cat.npz --output predictions.npz --print-time --repeat 100 resnet50-v2-7-tvm.tar
执行时间如下,上面是自动调优过的的,可以明显看出推理时间上的优化效果。
Execution time summary:mean (ms) median (ms) max (ms) min (ms) std (ms) 84.6208 74.9435 143.9276 72.8249 19.0734 mean (ms) median (ms) max (ms) min (ms) std (ms) 131.1953 130.7819 140.6614 106.0725 3.5606比较了一下两个编译后模型的Relay计算图json文件的区别,就看到了算子数据layout的区别,更多细节还是要看源码吧
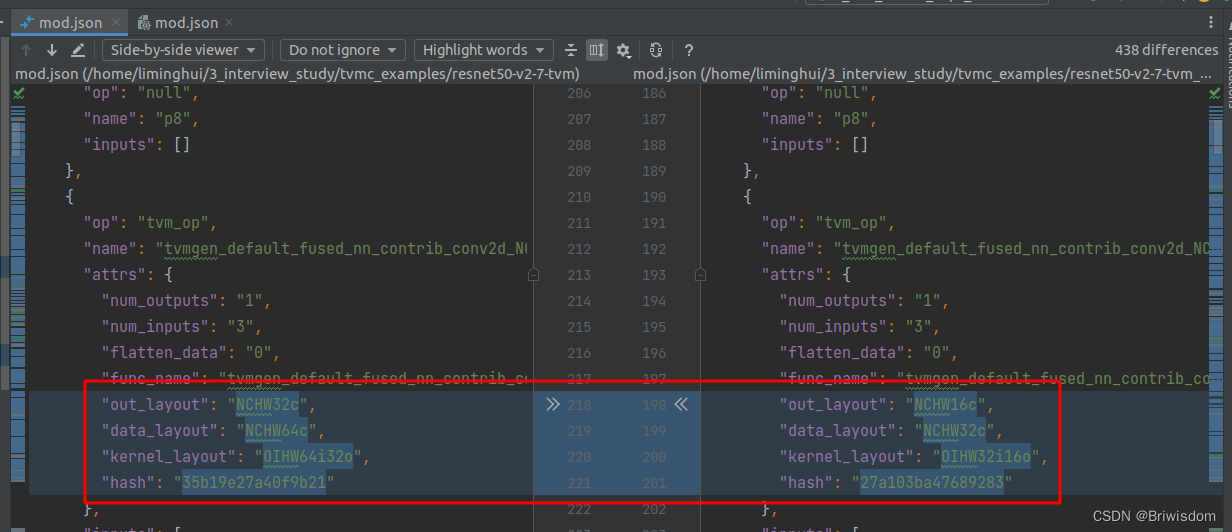
参考:TVM Ubuntu20安装_ubuntu20.04配置tvm_shelgi的博客-CSDN博客
相关文章:
Ubuntu20.04部署TVM流程及编译优化模型示例
前言:记录自己安装TVM的流程,以及一个简单的利用TVM编译模型并执行的示例。 1,官网下载TVM源码 git clone --recursive https://github.com/apache/tvmgit submodule init git submodule update顺便完成准备工作,比如升级cmake版本…...
)
华为OD机试真题-两个字符串间的最短路径问题-2023年OD统一考试(C卷)
题目描述: 给定两个字符串,分别为字符串A与字符串B。例如A字符串为ABCABBA,B字符串为CBABAC可以得到下图m*n的二维数组,定义原点为(0, 0),终点为(m, n),水平与垂直的每一条边距离为1,映射成坐标系如下图。 从原点(0, 0)到(0, A)为水平边,距离为1,从(0, A)到(A, C)为垂…...

python try-except
相比于直接raise ValueError,使用try-except可以使程序在发生异常后仍然能够运行。 在try的部分中,当遇到第一个Error,就跳转到except中寻找对应类型的error,后续代码不再执行,如果try中有多个Error,注意顺…...

flutter开发实战-ValueListenableBuilder实现局部刷新功能
flutter开发实战-ValueListenableBuilder实现局部刷新功能 在创建的新工程中,点击按钮更新counter后,通过setState可以出发本类的build方法进行更新。当我们只需要更新一小部分控件的时候,通过setState就不太合适了,这就需要进行…...
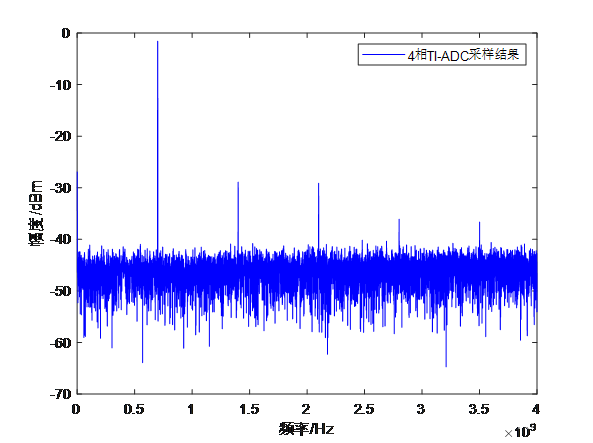
通过时间交织技术扩展ADC采样速率的简要原理
前言 数据采集是将自然界中存在的模拟信号通过模数转换器(ADC)转换成数字信号,再对该数字信号进行相应的接收和处理。数据采集系统作为数据采集的手段,在移动通信、图向采集、无线电等领域有重要作用。随着电子信息技术的飞速发展…...

FluxMQ—2.0.8版本更新内容
FluxMQ—2.0.8版本更新内容 前言 FLuxMQ是一款基于java开发,支持无限设备连接的云原生分布式物联网接入平台。FluxMQ基于Netty开发,底层采用Reactor3反应堆模型,具备低延迟,高吞吐量,千万、亿级别设备连接࿱…...
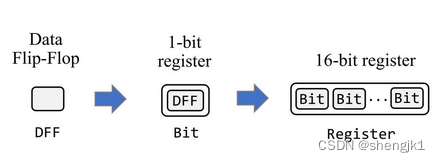
计算机寄存器是如何实现的
冯诺依曼体系 冯诺依曼体系为现代计算机的设计和发展奠定了基础,它的核心思想和原则在当今计算机体系结构中仍然被广泛采用和应用。所以只要谈论计算机的组成就离不开冯诺依曼体系 作为核心组成部分的CPU除了由运算器和控制器组成之外,还有一些寄存器…...

两数之和 三数之和 哈希方法
两数之和 package com; import java.util.*; public class Test5 { //两数之和 public static void main(String[] args) { int[] arr {1,2,3,4,5,6,7,94,42,35}; int target99; Arrays.sort(arr);//快速排序 for(int i0;i<arr.length;i) { int wtarget-arr[i]; int indexA…...

Object Detection in 20 Years: A Survey(2019.5)
文章目录 Abstract1. Introduction1.1. Difference from other related reviews1.2. Difficulties and Challenges in Object Detection 2. OBJECT DETECTION IN 20 YEARS2.1. 目标检测路线图2.1.1. 里程碑:传统探测器(粗略了解)2.1.2. 里程碑:基于CNN的…...

Springboot 设置时区与日期格式
1.配置文件修改(范围修改) spring:jackson:# 东8 北京时区time-zone: GMT8# 日期格式date-format: yyyy-MM-dd HH:mm:ss 2.Java代码修改(范围修改) 2.1 时区 import org.springframework.context.annotation.Bean; import org.…...

从零开始学Go web——第一天
文章目录 从零开始学Go web——第一天一、Go与web应用简介1.1 Go的可扩展性1.2 Go的模块化1.3 Go的可维护1.4 Go的高性能 二、web应用2.1 工作原理2.2 各个组成部分2.2.1 处理器2.2.2 模板引擎 三、HTTP简介四、HTTP请求4.1 请求的文本数据4.2 请求方法4.2.1 请求方法类型4.2.2…...
6.Eclipse里下载Subclipse插件
方法一:从Eclipse Marketplace里面下载 具体操作:打开Eclipse --> Help --> Eclipse Marketplace --> 在Find中输入subclipse搜索 --> 找到subclipse点击install 方法二:从Install New Software里下载 具体操作:打开…...

家用洗地机哪个品牌最好最实用?热门洗地机测评
随着社会的不断进步,我们逐渐意识到日常生活中的许多任务需要消耗大量的时间和体力。一个典型的例子是卫生清洁工作,尤其是在大面积地区,如大型建筑物、商场或工厂。这些任务不仅繁琐,还可能影响生活质量和工作效率。为了应对这一…...

【C语言:自定义类型(结构体、位段、共用体、枚举)】
文章目录 1.结构体1.1什么是结构体1.2结构体类型声明1.3结构体变量的定义和初始化1.4结构体的访问 2.结构体对齐2.1如何对齐2.2为什么存在内存对齐? 3.结构体实现位段3.1什么是位段3.2位段的内存分配3.3位段的跨平台问题3.4位段的应用3.5位段使用注意事项 4.联合体4…...

【1day】华天软件 OAworkFlowService接口SQL注入漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...
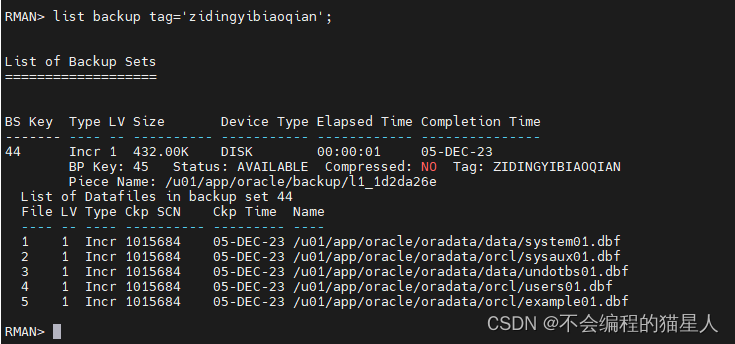
Oracle(2-11)RMAN Backups
文章目录 一、基础知识1、RMAN Backup Concepts RMAN备份概念2、RMAN Backup Modes RMAN备份的类型3、Backup File Types 备份文件类型4、RMAN Backup Destinations RMAN备份目标5、Backup Constraints 备份约束6、Recovery Manager Backups 恢复管理器备份7、Characteristics …...

使用docker搭建『Gitea』私有仓库
文章目录 一、安装 docker 环境1、移除以前的 docker 相关包2、配置yum源3、安装 docker4、启动 docker 二、安装 docker compose1、安装docker compose2、赋予下载的docker-compose执行权限 三、安装 gitea1. 创建工作目录2. 创建 Docker Compose 文件3. 启动 Gitea4. 访问 Gi…...

CopyOnWriteArrayList怎么用
什么是CopyOnWriteArrayListCopyOnWriteArrayList常用方法CopyOnWriteArrayList源码详解CopyOnWriteArrayList使用注意点CopyOnWriteArrayList存在的性能问题CopyOnWriteArrayList 使用实例基本应用实例并发应用实例 拓展写时复制 什么是CopyOnWriteArrayList CopyOnWriteArra…...

旋转设备状态监测与预测性维护:提高设备可靠性的关键
在工业领域的各个行业中,旋转设备都扮演着重要的角色。为了确保设备的可靠运行和预防潜在的故障,旋转设备状态监测及预测性维护变得至关重要。本文将介绍一些常见的旋转设备状态监测方法,并探讨如何利用这些方法来实施预测性维护,…...
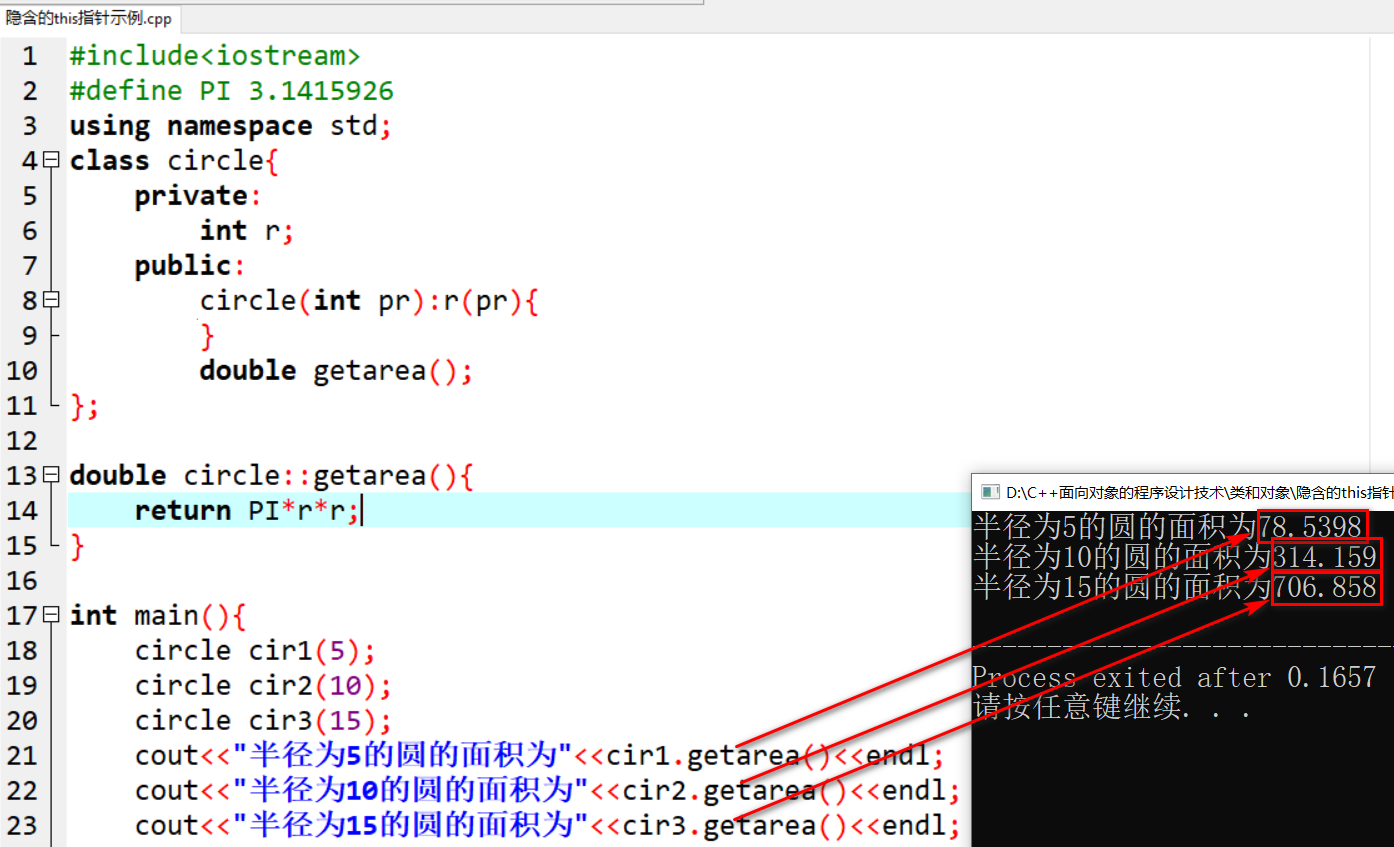
类和对象——(7)this指针
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍 收藏⭐ 留言📝 人生就像骑单车,想保持平衡…...
)
基于AI的MRI图像超分辨率重建与去噪,当AI遇见MRI:基于深度学习的超分辨率重建与去噪实战(从SwinIR到Diffusion)
目录 1. 问题的起点:MRI为什么需要超分和去噪? 2. 最新技术选型:为什么不用简单CNN? 3. 数据准备:模拟MRI的退化过程 4. SwinIR核心原理与MRI适配 简化的SwinIR模型结构(PyTorch实现) 5. 去噪专用:Restormer(Transformer for Restoration) 关键组件:MDTA(Mu…...

基于Terraform与Azure的Dify AI平台云原生自动化部署实践
1. 项目概述:一键部署AI应用平台的云原生方案最近在折腾AI应用开发平台,发现很多团队在从本地原型验证转向云端生产环境时,总会遇到一堆“部署地狱”的问题。环境配置不一致、资源管理混乱、成本不可控,这些问题在需要整合多个AI模…...

基于Circuit Playground Express与3D打印的机械心脏制作指南
1. 项目概述:一个会“呼吸”的机械心脏如果你对创客、STEAM教育或者互动艺术装置感兴趣,那么亲手制作一个能模拟真实心跳、并且心率可以手动调节的解剖心脏模型,绝对是一个能让你成就感爆棚的项目。这不仅仅是一个静态的展示品,它…...

构建AI涌现式判断系统:从智能体工作流到技术评审实践
1. 项目概述:当AI学会“判断”而非“计算”最近在GitHub上看到一个名为“emergent-judgment”的项目,由thebrierfox发起。初看标题,你可能会觉得这又是一个关于AI伦理或决策系统的抽象讨论。但深入探究后,我发现它指向了一个更具体…...

基于CRICKIT与CPX的交互式电子展板:从传感器到执行器的完整原型开发指南
1. 项目概述:打造一个会“思考”和“反应”的电子展板如果你对Arduino或树莓派这类微控制器项目感兴趣,但又觉得从零开始连接电机、灯带、传感器,还要处理复杂的电源和信号问题,过程太过繁琐和容易出错,那么这个项目可…...

Smoothieware 分支固件编译与配置项深度解析
1. Smoothieware分支固件编译全流程实战 第一次接触Smoothieware_best-for-pnp这个分支时,我完全没想到一个开源3D打印机固件能有这么多隐藏玩法。这个由社区开发者维护的分支,在保留官方核心功能的同时,针对OpenPNP应用场景做了大量优化。最…...

BQ34Z100-G1电量计配置不求人:用咸鱼EV2400+BqStudio完成电池组参数学习的保姆级教程
BQ34Z100-G1电量计配置实战:从零搭建高精度电池管理系统 在新能源和储能系统蓬勃发展的今天,精确的电池电量计量已成为电池管理系统(BMS)的核心竞争力。德州仪器(TI)的BQ34Z100-G1阻抗跟踪电量计凭借其出色的精度和稳定性,在工业储能、电动工…...

PCIe 6.0 Flit Mode 实战解析:从TLP到Flit,你的数据包到底经历了什么?
PCIe 6.0 Flit Mode 深度解析:数据包的奇幻漂流之旅 当一颗来自CPU的事务请求被封装成TLP(Transaction Layer Packet)时,它即将开始一段穿越PCIe 6.0协议栈的奇妙旅程。这段旅程不再是传统PCIe版本中的"自由行"…...
)
基于SSM框架的传统服饰文化平台体验(10034)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

达梦数据库主备集群手工搭建及主备切换演练
环境:DM8、Linux(CentOS 7 ),三台服务器。 本文记录从零搭一套"一主一备一监视" 式的主备集群,纯手工操作,不依赖图形化工具。 一、环境规划 1.1 IP规划 角色主机名业务IP心跳IP实例名主库&…...