算法工程师面试八股(搜广推方向)
文章目录
- 机器学习
- 线性和逻辑回归模型
- 逻辑回归
- 二分类和多分类的损失函数
- 二分类为什么用交叉熵损失而不用MSE损失?
- 偏差与方差
- Layer Normalization 和 Batch Normalization
- SVM
- 数据不均衡
- 特征选择
- 排序模型
- 树模型进行特征工程的原因
- GBDT
- LR和GBDT
- RF和GBDT
- XGBoost
- 二阶泰勒展开优势
- 为什么快
- 防止过拟合
- 处理缺失值
- 树停止生长条件
- 处理不平衡数据
- 树剪枝
- 选择最佳分裂点
- Scalable性
- 特征重要性
- 调参步骤
- 过拟合解决方案
- 对缺失值不敏感
- XGBoost和RF单棵树哪个更深?
- XGBoost和GBDT
- XGBoost和LightGBM
- AUC
- 深度学习
- 激活函数
- Softmax函数及求导
- 优化器
- 残差连接
- DNN,CNN,RNN对比
- 池化层反向传播
- 浅层、深层神经网络差别
- 防止过拟合
- BN层的计算
- 负梯度方向是函数局部值最快的方向
- softmax loss和cross entropy
- 全连接层作用
- RNN和LSTM
- Transformer相对LSTM的优势
- RNN不用Relu要用tanh函数?
- Transformer
- 位置编码
- head降维
- 自注意力比例系数
- 预测与推理阶段都使用mask原因
- 代码
- BERT和GPT区别
- 深度学习模型和树模型的优缺点
- 计算机视觉
- 图像处理中一般用最大池化而不用平均池化
- 计算感受野
- 大数据处理
- Spark的核心构件
- Spark数据倾斜
- MapReduce
- 其他
- 树结构在操作系统中的应用
- TensorFlow和PyTorch区别及优缺点对比
机器学习
线性和逻辑回归模型
经典的机器学习模型,用于解决分类和回归问题。
- 线性模型(Linear Models):一种基本的统计模型,用于建立输入特征与输出之间的线性关系。基本形式是:
y = w₁x₁ + ... + wₙxₙ + b,y表示输出变量,x₁, ..., xₙ表示输入特征,w₁, ..., wₙ表示特征的权重,b表示偏差或截距。模型通过学习特征的权重和偏差,以最小化预测值与真实值之间的差距。线性模型简单、可解释性强、计算效率高,适用于特征与输出之间存在线性关系的问题。 - 逻辑回归模型(Logistic Regression):一种用于二分类问题的线性模型,通过逻辑函数(sigmoid函数)将线性模型的输出转化为概率值,从而进行分类。逻辑回归模型的基本形式是:
p = 1 / (1 + exp(-(w₁x₁ + ... + wₙxₙ + b)))其中,p表示样本属于某个类别的概率。模型通过学习特征的权重和偏差,以最大化似然函数或最小化对数损失函数来拟合训练数据,并进行分类预测。逻辑回归模型模型简单、可解释性强、计算效率高,广泛应用于二分类问题。逻辑回归模型还可以通过正则化技术来防止过拟合。 - 区别:
- 输出类型:线性模型常用于回归问题,输出是连续值。逻辑回归模型用于二分类问题,输出是概率值或类别标签。
- 输出转换:线性模型直接使用线性函数进行预测。逻辑回归模型通过逻辑函数(sigmoid函数)将线性模型的输出转化为概率值,从而进行分类。
- 损失函数:线性模型通常使用均方误差MSE或平均绝对误差等回归损失函数。逻辑回归模型使用对数损失函数或交叉熵损失函数来最小化分类误差。
- 联系:
- 线性模型是逻辑回归模型的一种特例。当逻辑回归模型中只有一个二分类输出变量,并且特征与输出之间存在线性关系时,逻辑回归模型退化为线性模型。
- 逻辑回归模型可以使用线性模型的方法进行参数估计。逻辑回归模型的参数估计可以通过最大似然估计或梯度下降等方法来获得,类似于线性模型的参数估计。
逻辑回归
逻辑回归假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。
假设:
- 假设数据服从伯努利分布(非正即反,概率和为1)。
- 假设模型的输出值是样本为正例的概率。
损失函数:
逻辑回归中用到sigmoid函数,若用均方误差则为非凸函数,有多个极小值,采用梯度下降法容易陷入局部最优解中。
逻辑回归其实是概率类模型,通过极大似然估计(MLE)推导逻辑回归损失函数。目的是将所得似然函数极大化,而损失函数是最小化。
求解:
最小二乘法的误差符合正态分布,而逻辑回归的误差符合的是二项分布,所以不能用最小二乘法来作为损失函数,那么能够用最大似然预计来做。使用梯度下降法求解。
- 如果用最小二乘法,目标函数就是 E w , b = ∑ i = 1 m ( y i − 1 1 + e − ( w T x i + b ) ) 2 E_{w,b}=\sum_{i=1}^{m}\left ( y_{i}-\frac{1}{1+e^{-\left ( w^{T}x_{i}+b \right )}}\right )^2 Ew,b=∑i=1m(yi−1+e−(wTxi+b)1)2 ,是非凸的,不容易求解,会得到局部最优。
- 如果用最大似然估计,目标函数就是对数似然函数: l w , b = ∑ i = 1 m ( − y i ( w T x i + b ) + l n ( 1 + e w T x i + b ) ) l_{w,b}=\sum_{i=1}^{m}\left ( -y_{i}\left ( w^{T}x_{i}+b \right )+ln\left ( 1+e^{w^{T}x_{i}+b} \right ) \right ) lw,b=∑i=1m(−yi(wTxi+b)+ln(1+ewTxi+b)) ,是关于 (w,b) 的高阶连续可导凸函数,可以方便通过一些凸优化算法求解,比如梯度下降法、牛顿法等。
优点:
- 直接对分类可能性进行建模,无需实现假设数据分布,这样就避免了假设分布不准确所带来的问题。
- 形式简单,模型的可解释性非常好,特征的权重可以看到不同的特征对最后结果的影响。
- 除了类别,还能得到近似概率预测,这对许多需利用概率辅助决策的任务很有用。
缺点:
- 准确率不是很高,因为形势非常的简单,很难去拟合数据的真实分布。
- 本身无法筛选特征。
推导:

从零开始学会逻辑回归(一)
二分类和多分类的损失函数
| 分类问题 | 输出层激活函数 | 损失函数 | 说明 |
|---|---|---|---|
| 二分类 | Sigmoid | 二分类交叉熵损失函数(binary_crossentropy) | sigmoid作为最后一层输出,不能把最后一层的输出看作成一个分布,因为加起来不为1。应将最后一层的每个神经元看作一个分布 |
| 多分类 | Softmax | 多类别交叉熵损失函数(categorical_crossentropy) | Softmax后最后一层输出概率相加为1 |
| 多标签分类 | Sigmoid | 二分类交叉熵损失函数(binary_crossentropy) | 计算一个样本各个标签的损失取平均值。把一个多标签问题转化为在每个标签上的二分类问题 |
- BCE Loss: L = 1 N ∑ i L i = 1 N ∑ i [ y i l o g ( p i ) + ( 1 − y i ) l o g ( 1 − p i ) ] L=\frac{1}{N}\sum_iL_i=\frac{1}{N}\sum_i[y_ilog(p_i)+(1-y_i)log(1-p_i)] L=N1∑iLi=N1∑i[yilog(pi)+(1−yi)log(1−pi)]
- CE Loss: L = 1 N ∑ i L i = − 1 N ∑ i ∑ c = 1 M y i c l o g ( p i c ) L=\frac{1}{N}\sum_iL_i=-\frac{1}{N}\sum_i \sum^M_{c=1}y_{ic}log(p_{ic}) L=N1∑iLi=−N1∑i∑c=1Myiclog(pic)
二分类和多分类的激活函数和损失
二分类为什么用交叉熵损失而不用MSE损失?
- 对概率分布更敏感: 交叉熵损失更适用于概率分布的比较,而二分类问题通常涉及到概率的预测。交叉熵损失能够衡量实际概率分布与预测概率分布之间的差异,更加敏感和有效。
- 梯度更新更好: 在分类问题中,交叉熵损失函数的梯度更为明确和稳定,相比之下,均方误差损失可能会导致训练过程中梯度消失或梯度爆炸的问题。
- 更好地表达分类目标: 交叉熵损失更加关注正确类别的预测概率,而均方误差对所有类别的预测概率都进行了平方差的计算,可能会导致对错误类别的概率影响不够明显。
偏差与方差
令y表示数据的label,f(x)表示测试数据的预测值, f ( x ) ‾ \overline{f(x)} f(x)表示学习算法对所有数据集的期望预测值。则偏差表示期望预测值 f ( x ) ‾ \overline{f(x)} f(x)与标记y之间的差距,差距越大说明偏差越大;而方差是测试预测值f(x)与预测值的期望值 f ( x ) ‾ \overline{f(x)} f(x)之间的差距,差距越大说明方差越大。偏差表征模型对数据的拟合能力;而方差表征数据集的变动导致的学习性能的变化,也就是泛化能力。
Layer Normalization 和 Batch Normalization
“独立同分布”的数据能让人很快地发觉数据之间的关系,因为不会出现像过拟合等问题。为了解决ICS(internal covarivate shift内部协变量漂移)问题,即数据分布会发生变化,对下一层网络的学习带来困难。一般在模型训练之前,需要对数据做归一化。
LayerNorm,对单个样本的所有维度特征做归一化,对模型中每个子层的输入归一化处理,使得每个特征的均值为0,方差为1。有助于缓解内部协变量偏移的问题,提高模型的训练效率和鲁棒性。
batch normalization是对一批样本的同一纬度特征做归一化。强行将数据转为均值为0,方差为1的正态分布,使得数据分布一致,并且避免梯度消失。而梯度变大意味着学习收敛速度快,能够提高训练速度。设batch_size为m,网络在向前传播时,网络 中每个神经元都有m个输出,BN就是将每个神经元的m个输出进行归一化处理。
- 标准化:求得均值为0,方差为1的标准正态分布 x ˉ i \bar{x}_{i} xˉi
- 尺度变换和偏移:获得新的分布 y i y_i yi。均值为 β,方差为 γ(其中偏移 β 和尺度变换 γ 为需要学习的参数)。该过程有利于数据分布和权重的互相协调。
区别:
- 从操作上看:BN是对同一个batch内的所有数据的同一个特征数据进行操作;而LN是对同一个样本进行操作。
- 从特征维度上看:BN中,特征维度数=均值or方差的个数;LN中,一个batch中有batch_size个均值和方差。
关系:
- BN 和 LN 都可以比较好的抑制梯度消失和梯度爆炸的情况。BN不适合RNN、transformer等序列网络,不适合文本长度不定和batchsize较小的情况,适合于CV中的CNN等网络;
- 而LN适合用于NLP中的RNN、transformer等网络,因为sequence的长度可能是不一致的。
- 如果把一批文本组成一个batch,BN就是对每句话的第一个词进行操作,BN针对每个位置进行缩放就不符合NLP的规律了。
小结:
- 经过BN的归一化再输入激活函数,得到的值大部分会落入非线性函数的线性区,导数远离导数饱和区,避免了梯度消失,这样来加速训练收敛过程。
- 归一化技术就是让每一层的分布稳定下来,让后面的层能在前面层的基础上“安心学习”。BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来(但是BN没有解决ISC问题)。LayerNorm则是通过对Hidden size这个维度归一。
【深度学习】batch normalization和layer normalization区别
SVM
为什么要从原问题转换为对偶问题求解?
- 不等式约束方程需要写成min max的形式来得到最优解。而这种写成这种形式对x不能求导,这种形式只能对拉格朗日乘子 α \alpha α求导,所以我们需要转换成max min的形式,这时候,x就在里面了,这样就能对x求导了。而为了满足这种对偶变换成立,就需要满足KKT条件(KKT条件是原问题与对偶问题等价的必要条件,当原问题是凸优化问题时,变为充要条件)。只用求解 α \alpha α系数,而 α \alpha α系数只有支持向里才非0,其它全部为0。
- 对偶问题将原始问题中的约束转为了对偶问题中的等式约束
- 方便核函数的引入,推广到非线性分类问题
- 改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关。
SVM从原始问题到对偶问题的转换及原因
SVM中,高斯核为什么会把原始维度映射到无穷多维?
数据不均衡
数据不均衡(如正例很少,负例很多)解决办法:
- 欠采样:对负例进行欠采样。一种代表性算法是将负例分成很多份,每次用其中一份和正例一起训练,最后用集成学习综合结果。
- 过采样:对正例进行过采样。一种代表性方法是对正例进行线性插值来获得更多的正例。
- 调整损失函数:训练时正常训练,分类时将数据不均衡问题加入到决策过程中。例如在我做的文本检测项目中,正常训练,但是判断某个像素是否是文本时 L o s s = − β Y l o g Y ^ − ( 1 − β ) ( 1 − Y ) l o g ( 1 − Y ^ ) Loss=-\beta{Y}log\hat{Y}-(1-\beta)(1-Y)log(1-\hat{Y}) Loss=−βYlogY^−(1−β)(1−Y)log(1−Y^),其中Y是样本的标记, Y ^ \hat{Y} Y^是预测值,β是负样本和总体样本的比值。通过加入 β和1−β使得数量较少的正样本得到更多的关注,不至于被大量的负样本掩盖。
- 组合/集成学习:例如正负样本比例1:100,则将负样本分成100份,正样本每次有放回采样至与负样本数相同,然后取100次结果进行平均。
- 数据增强:单样本增强如几何变换、颜色变换、增加噪声;多样本组合增强如Smote类、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值样本;基于深度学习数据增强
特征选择
目标是从原始特征集中选择最相关、最有用的特征,以提高模型性能和泛化能力。常用特征选择方法:
- 过滤式:独立于学习算法,据特征的统计属性对特征评估和排序。包括相关系数、卡方检验、信息增益、互信息法等。过滤式方法计算快速、简单,适用于高维数据,但可能忽略特征之间的相互关系。
- 方差选择:计算特征在数据中的方差来判断是否保留。特征方差低于预先设定的阈值,这个特征可能没有足够的变化,对分类回归任务可能没有太大贡献,可以被移除。
- 相关系数:用来衡量两个变量之间线性关系强度的指标。计算特征与目标变量之间的相关系数,选择与目标变量具有较高相关性的特征。
- 卡方检验:适用于分类问题中的特征选择。计算特征与目标变量之间的卡方统计量,来衡量特征和目标之间的独立性。选择卡方值较大的特征,与目标变量更相关。
- 互信息:衡量两个变量之间相关性的指标。计算特征与目标变量之间的互信息,选择与目标变量具有较高互信息的特征。
- 嵌入式(Embedded):特征选择与学习算法的训练过程结合,特征选择作为学习算法的一部分。在学习算法中直接考虑特征的重要性,通过正则化、惩罚项或决策树剪枝等方式选择特征。嵌入式方法包括L1正则化(Lasso)、决策树的特征重要性、正则化的线性模型等。嵌入式方法可以在模型训练过程中自动选择特征,减少了特征选择的额外计算开销。
- 包裹式(Wrapper):使用机器学习模型评估特征的重要性。在特征子集上进行交叉验证,选择性能最好的特征子集进行特征选择。基于树模型的方法(如决策树和随机森林)可以评估特征的重要性。树模型通过计算特征在树中的分裂次数和平均分裂增益衡量特征对模型的贡献。它直接使用最终学习算法对每个特征子集进行评估,可以更好地捕捉特征之间的相互作用。包裹式方法包括递归特征消除和遗传算法等。包裹式方法计算开销大、耗时长,适用于小规模数据和特定问题。
排序模型
旨在根据用户偏好和上下文信息,预测每个项目的相关性或排名,为用户提供最相关和个性化的结果。模型输入包括:
- 特征:描述每个项目的属性和上下文信息,如项目标签、关键词、评分、发布时间、用户特征等。特征可以是离散的、连续的或文本类型的。
- 用户信息:包括用户历史行为、兴趣偏好、地理位置等,用于个性化推荐和排序。
- 上下文信息:指在排序过程中可能影响用户偏好的其他因素,如时间、设备类型、浏览环境等。
常见排序模型包括:
- 点击率预测模型:通过预测用户点击每个项目的概率进行排序。包括逻辑回归、梯度提升树、神经网络等。
- 排序神经网络:使用神经网络来学习项目之间的相对排名关系。包括RankNet、LambdaRank和ListNet等。
- 线性模型和特征工程:基于线性模型结合特征工程技术学习特征权重和组合。包括线性回归、排序SVM等。
- 排序树模型:使用决策树排序,如LambdaMART和GBDT等。
模型训练中常用损失函数包括交叉熵损失函数、均方误差损失函数、排序损失函数(如NDCG)等。为提高排序模型性能,可以采用特征选择、特征组合、正则化等技术。
树模型进行特征工程的原因
- 改善模型性能: 特征工程有助于提取更具预测性的特征,可以帮助模型更好地拟合数据,提升模型的预测性能。
- 降低过拟合风险: 合适的特征工程可以帮助模型更好地泛化到新的数据集上,降低过拟合的风险,提高模型的稳定性和泛化能力。
- 减少计算复杂度: 特征工程有助于减少特征空间的维度,从而减少计算复杂度,并加速模型的训练和预测过程。
- 提高可解释性: 通过合理的特征工程,可以使得模型更易于解释和理解,有助于深入理解数据特征对模型预测的影响。
- 解决特征相关性和噪音问题: 特征工程有助于发现和处理特征之间的相关性和噪音,使模型更加健壮。
GBDT
一种基于boosting增强策略的加法模型,训练时采用前向分布算法进行贪婪学习,迭代地训练一系列弱学习器,并将它们组合成一个强大的集成模型。每次迭代都学习一棵CART树来拟合之前t-1棵树的预测结果与训练样本真实值的残差。
LR和GBDT
LR是线性模型,可解释性强,很容易并行化,但学习能力有限,需要大量的人工特征工程。GBDT是非线性模型,具有天然的特征组合优势,特征表达能力强,但是树与树之间无法并行训练,且树模型很容易过拟合;当在高维稀疏特征的场景下,LR的效果一般会比GBDT好。
RF和GBDT
相同点:都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:
- 集成学习:RF属于bagging思想,而GBDT是boosting思想
- 偏差-方差权衡:RF不断的降低模型的方差,而GBDT不断的降低模型的偏差
- 训练样本:RF每次迭代的样本是从全部训练集中有放回抽样形成的,而GBDT每次使用全部样本
- 并行性:RF的树可以并行生成,而GBDT只能顺序生成(需要等上一棵树完全生成)
- 最终结果:RF最终是多棵树进行多数表决(回归问题是取平均),而GBDT是加权融合
- 数据敏感性:RF对异常值不敏感,而GBDT对异常值比较敏感
- 泛化能力:RF不易过拟合,而GBDT容易过拟合
XGBoost
eXtreme Gradient Boosting用于解决分类和回归问题。基于梯度提升框架,集成多个弱学习器(决策树)逐步改善模型的预测能力。原理:
- 损失函数:回归问题常用平方损失函数;分类问题常用对数损失函数。
- 弱学习器:用决策树作弱学习器。决策树是一种基于特征的分层划分,每个节点对应一个特征及其划分条件。XGBoost中决策树通过贪婪算法生成,每次选择最大程度降低损失函数的特征和划分点。
- 梯度提升:使用梯度提升法集成多个弱学习器。每轮迭代中根据当前模型的预测结果计算损失函数的梯度,并将其作为新目标训练。新弱学习器通过拟合当前目标逐步改进模型预测能力。为控制每个弱学习器的贡献,引入了学习率缩小每轮迭代的步长。
- 正则化:防止模型过拟合。正则化项由两部分组成:L1正则化(Lasso)和L2正则化(Ridge)。L1正则化使部分特征权重变零,实现特征选择;L2正则化对权重惩罚,降低模型的复杂度。
- 树剪枝:构建决策树采用自动树剪枝策略。计算每个叶节点的分数与正则化项比较,决定是否剪枝。剪枝过程从树的底部开始,逐步向上剪除对模型贡献较小的分支。
- 特征重要性评估:提供一种度量特征重要性的方法,评估每个特征对模型预测的贡献程度。训练中会跟踪每个特征被用于划分的次数及划分后带来的增益。计算特征的重要性得分。
二阶泰勒展开优势
- xgboost是以MSE为基础推导出来的,xgboost的目标函数展开就是一阶项(残差)+二阶项的形式,而其他类似logloss这样的目标函数不能表示成这种形式。为了后续推导的统一,将目标函数进行二阶泰勒展开,就可以直接自定义损失函数了,只要二阶可导即可,增强了模型的扩展性。
- 二阶信息能够让梯度收敛的更快更准确,类似牛顿法比SGD收敛更快。一阶信息描述梯度变化方向,二阶信息可以描述梯度变化方向是如何变化的。
xgboost是用二阶泰勒展开的优势在哪?
为什么快
- 分块并行:训练前每个特征按特征值进行排序并存储为Block结构,后面查找特征分割点时重复使用,并且支持并行查找每个特征的分割点
- 候选分位点:每个特征采用常数个分位点作为候选分割点
- CPU cache 命中优化: 使用缓存预取的方法,对每个线程分配一个连续的buffer,读取每个block中样本的梯度信息并存入连续的Buffer中。
- Block 处理优化:Block预先放入内存;Block按列进行解压缩;将Block划分到不同硬盘来提高吞吐
防止过拟合
- 目标函数添加正则项:叶子节点个数+叶子节点权重的L2正则化
- 列抽样:训练的时候只用一部分特征(不考虑剩余的block块即可)
- 子采样:每轮计算可以不使用全部样本,使算法更加保守
- shrinkage: 可以叫学习率或步长,为了给后面的训练留出更多的学习空间
处理缺失值
- XGBoost允许特征存在缺失值。在特征k上寻找最佳 split point 时,不会对该列特征 missing 的样本进行遍历,而只对该列特征值为 non-missing 的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找 split point 的时间开销。
- 在逻辑实现上,为了保证完备性,会将该特征值missing的样本分别分配到左叶子结点和右叶子结点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。
树停止生长条件
- 当新引入的一次分裂所带来的增益Gain<0时,放弃当前的分裂。这是训练损失和模型结构复杂度的博弈过程。
- 当树达到最大深度时,停止建树,树深度太深容易过拟合,需要设置一个超参数max_depth。
- 引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值,也会放弃此次分裂。这涉及到一个超参数:最小样本权重和,是指如果一个叶子节点包含的样本数量太少也会放弃分裂,防止树分的太细。
处理不平衡数据
- 如采用AUC评估模型性能,可以通过设置scale_pos_weight参数来平衡正样本和负样本的权重。如正负样本比例为1:10时,scale_pos_weight可以取10;
- 如果在意预测概率(预测得分的合理性),不能重新平衡数据集(会破坏数据的真实分布),应该设置max_delta_step参数为一个有限数字(如1)来帮助收敛。max_delta_step参数通常不进行使用,二分类下的样本不均衡问题是这个参数唯一的用途。
树剪枝
- 在目标函数中增加了正则项:使用叶子结点的数目和叶子结点权重的L2模的平方,控制树的复杂度。
- 在结点分裂时,定义了一个阈值,如果分裂后目标函数的增益小于该阈值,则不分裂。
- 当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值(最小样本权重和),也会放弃此次分裂。
- XGBoost 先从顶到底建立树直到最大深度,再从底到顶反向检查是否有不满足分裂条件的结点,进行剪枝。
选择最佳分裂点
XGBoost在训练前预先将特征按照特征值进行了排序,并存储为block结构,以后在结点分裂时可以重复使用该结构。因此,可以采用特征并行的方法利用多个线程分别计算每个特征的最佳分割点,根据每次分裂后产生的增益,最终选择增益最大的那个特征的特征值作为最佳分裂点。
如果在计算每个特征的最佳分割点时,对每个样本都进行遍历,计算复杂度会很大,这种全局扫描的方法并不适用大数据的场景。
XGBoost提供了一种直方图近似算法,使用weighted quantile sketch算法近似地找到best split,对特征排序后仅选择常数个候选分裂位置作为候选分裂点。
按比例来选择,从n个样本中抽取k个样本来进行计算,取k个样本中的最优值作为split value,这样就大大减少了运算数量。按样本均分会导致loss分布不均匀,取到的分位点会有偏差。我们要均分的是loss,而不是样本的数量。将样本对应的残差二阶导h作为划分依据,将同范围h占比的特征值划分到同一范围内。残差二阶导差异越大的地方,样本分布越稀疏,反之则稠密。加权意义在于把候选节点选取的机会更多地让于二阶导更大的地方,同时忽略导数差异小的节点。
Scalable性
- 基分类器的scalability:弱分类器可以支持CART决策树,也可以支持LR和Linear。
- 目标函数的scalability:支持自定义loss function,只需要其一阶、二阶可导。有这个特性是因为泰勒二阶展开,得到通用的目标函数形式。
- 学习方法的scalability:Block结构支持并行化,支持Out-of-core计算。
当数据量太大不能全部放入主内存的时候,为了使得out-of-core计算称为可能,将数据划分为多个Block并存放在磁盘上。计算时使用独立的线程预先将Block放入主内存,因此可以在计算的同时读取磁盘。但是由于磁盘IO速度太慢,通常更不上计算的速度。因此,需要提升磁盘IO的销量。Xgboost采用了2个策略:
- Block压缩(Block Compression):将Block按列压缩,读取的时候用另外的线程解压。对于行索引,只保存第一个索引值,然后只保存该数据与第一个索引值之差(offset),一共用16个bits来保存offset,因此,一个block一般有2的16次方个样本。
- Block拆分(Block Sharding):将数据划分到不同磁盘上,为每个磁盘分配一个预取(pre-fetcher)线程,并将数据提取到内存缓冲区中。然后,训练线程交替地从每个缓冲区读取数据。这有助于在多个磁盘可用时增加磁盘读取的吞吐量。
特征重要性
- weight :该特征在所有树中被用作分割样本的特征的总次数。
- gain :该特征在其出现过的所有树中产生的平均增益。
- cover :该特征在其出现过的所有树中的平均覆盖范围。
注意:覆盖范围这里指的是一个特征用作分割点后,其影响的样本数量,即有多少样本经过该特征分割到两个子节点。
调参步骤
首先需初始化一些基本变量,如:max_depth = 5, min_child_weight = 1, gamma = 0, subsample, colsample_bytree = 0.8, scale_pos_weight = 1,确定learning rate和estimator的数量 lr可先用0.1,用xgboost.cv()来寻找最优的estimators。
max_depth, min_child_weight: 首先将这两个参数设置为较大的数,通过迭代方式不断修正,缩小范围。max_depth每棵子树的最大深度,check from range(3,10,2)。min_child_weight子节点的权重阈值,check from range(1,6,2)。 如果一个结点分裂后,它的所有子节点的权重之和都大于该阈值,该叶子节点才可以划分。gamma: 最小划分损失min_split_loss,check from 0.1 to 0.5,对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值。如果大于该阈值,则该叶子节点值得继续划分。如果小于该阈值,则该叶子节点不值得继续划分。subsample, colsample_bytree: subsample是对训练的采样比例,colsample_bytree是对特征的采样比例,both check from 0.6 to 0.9- 正则化参数。alpha 是L1正则化系数,try 1e-5, 1e-2, 0.1, 1, 100。lambda 是L2正则化系数
- 降低学习率:降低学习率的同时增加树的数量,通常最后设置学习率为0.01~0.1
过拟合解决方案
有两类参数可以缓解:
- 用于直接控制模型的复杂度。包括max_depth,min_child_weight,gamma 等参数
- 用于增加随机性,从而使得模型在训练时对于噪音不敏感。包括subsample,colsample_bytree
直接减小learning rate,但需要同时增加estimator参数。
对缺失值不敏感
对存在缺失值的特征,一般的解决方法是:
- 离散型变量:用出现次数最多的特征值填充;
- 连续型变量:用中位数或均值填充;
一些模型如SVM和KNN,其模型原理中涉及到了对样本距离的度量,如果缺失值处理不当,最终会导致模型预测效果很差。而树模型对缺失值的敏感度低,大部分时候可以在数据缺失时时使用。原因是,一棵树中每个结点在分裂时,寻找的是某个特征的最佳分裂点(特征值),完全可以不考虑存在特征值缺失的样本,如果某些样本缺失的特征值缺失,对寻找最佳分割点的影响不是很大。
XGBoost对缺失数据有特定的处理方法, 因此,对于有缺失值的数据在经过缺失处理后:
- 当数据量很小时,优先用朴素贝叶斯
- 数据量适中或者较大,用树模型,优先XGBoost
- 数据量较大,也可以用神经网络
- 避免使用距离度量相关的模型,如KNN和SVM
XGBoost和RF单棵树哪个更深?
RF单颗树更深。Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
Bagging算法会并行地训练很多不同的分类器来降低方差variance: E [ h − E ( h ) ] E[h−E(h)] E[h−E(h)],因为采用了相互独立的基分类器多了以后,h的值自然就会靠近E(h)。所以对于每个基分类器来说,目标就是降低偏差bias,所以会采用深度很深甚至不剪枝的决策树。对于Boosting来说,每一步会在上一轮的基础上更加拟合原数据,所以可以保证偏差bias,所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
XGBoost和GBDT
- 梯度提升决策树:都属于梯度提升决策树算法。集成学习方法,组合多个决策树逐步减小预测误差,提高模型性能。
- 目标函数:使用相同的目标函数,通过最小化残差的平方和优化模型。每一轮迭代中,都会构建一个新的决策树来拟合前面模型的残差,以纠正之前模型的预测误差。
- 特征工程:都支持类别型特征和缺失值的处理。在构建决策树时能自动处理类别型特征,不需要独热编码等转换。
区别:
- 基分类器:XGBoost基分类器不仅支持CART决策树,还支持线性分类器,此时XGBoost相当于带L1和L2正则化项的Logistic回归(分类问题)或者线性回归(回归问题)。
- 正则化策略:XGBoost引入正则化防止过拟合,包括L1和L2正则化控制模型的复杂度。
- 算法优化:XGBoost使用近似贪心算法选择最佳分裂点,使用二阶导数信息更精准逼近真实的损失函数,来提高模型的拟合能力。支持自定义损失函数,只要损失函数一阶、二阶可导,可扩展性好。
- 样本权重:XGBoost引入样本权重概念,对不同样本赋予不同权重,从而对模型训练产生不同影响。在处理不平衡数据集或处理样本噪声时非常有用。
- 并行计算:XGBoost在多个线程上同时进行模型训练,使用并行计算和缓存优化加速训练过程。不是tree维度的并行,而是特征维度的并行。XGBoost预先将每个特征按特征值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大提升训练速度。GBDT通常是顺序训练的,无法直接进行并行化。
- 列抽样:XGBoost支持列采样,与随机森林类似,用于防止过拟合。
XGBoost和LightGBM
- 梯度提升决策树:都属于梯度提升决策树算法。集成学习方法,组合多个决策树逐步减小预测误差,提高模型性能。
- 特征工程:都支持类别型特征和缺失值的处理。在构建决策树时能自动处理类别型特征,不需要独热编码等转换。还能处理带缺失值的数据。
- 分布式训练:都支持分布式训练,可在分布式计算框架(如Spark)上运行。
区别:
- 算法速度:LightGBM在训练和预测速度上更快。LightGBM采用基于梯度的直方图决策树算法来加速训练过程,减少内存使用和计算复杂度。
- 内存占用:LightGBM具有更低的内存占用,适用于处理大规模数据集。使用了互斥特征捆绑算法和直方图算法来减少内存使用,提高了算法的扩展性。
- 正则化策略:都支持正则化策略来防止过拟合。XGBoost采用基于树的正则化(如最大深度、最小子样本权重等),LightGBM采用基于叶子节点的正则化(如叶子数、最小叶子权重等)。
- 数据并行和特征并行:XGBoost使用数据并行化,将数据划分为多个子集,每个子集在不同的计算节点上进行训练。LightGBM使用特征并行化,将特征划分为多个子集,每个子集在不同的计算节点上进行训练。
- 树生长策略:XGB采用level-wise(按层生长)的分裂策略,LGB采用leaf-wise的分裂策略。XGB对每一层所有节点做无差别分裂,但是可能有些节点增益非常小,对结果影响不大,带来不必要的开销。Leaf-wise是在所有叶子节点中选取分裂收益最大的节点进行的,但是很容易出现过拟合问题,所以需要对最大深度做限制 。
- 分割点查找算法:XGB使用特征预排序算法,LGB使用基于直方图的切分点算法,优势如下:
- 减少内存占用,比如离散为256个bin时,只需要用8位整形就可以保存一个样本被映射为哪个bin(这个bin可以说就是转换后的特征),对比预排序的exact greedy算法来说(用int_32来存储索引+ 用float_32保存特征值),可以节省7/8的空间。
- 计算效率提高,预排序的Exact greedy对每个特征都需要遍历一遍数据,并计算增益,复杂度为𝑂(#𝑓𝑒𝑎𝑡𝑢𝑟𝑒×#𝑑𝑎𝑡𝑎)。而直方图算法在建立完直方图后,只需要对每个特征遍历直方图即可,复杂度为𝑂(#𝑓𝑒𝑎𝑡𝑢𝑟𝑒×#𝑏𝑖𝑛𝑠)。
- LGB还可以使用直方图做差加速,一个节点的直方图可以通过父节点的直方图减去兄弟节点的直方图得到,从而加速计算。实际上xgboost的近似直方图算法也类似于LGB这里的直方图算法,但xgboost的近似算法比LGB慢很多。XGB在每一层都动态构建直方图,XGB的直方图算法不是针对某个特定的feature,而是所有feature共享一个直方图(每个样本的权重是二阶导),所以每一层都要重新构建直方图,而LGB中对每个特征都有一个直方图,所以构建一次直方图就够
- 支持离散变量:XGB无法直接输入类别型变量,需要事先对类别型变量进行编码(如独热编码),而LightGBM可以直接处理类别型变量。
- 缓存命中率:XGB使用Block结构的缺点是取梯度时,是通过索引来获取的,而这些梯度的获取顺序是按照特征的大小顺序,导致非连续的内存访问,使得CPU cache缓存命中率低,影响算法效率。而LGB是基于直方图分裂特征的,梯度信息都存储在一个个bin中,所以访问梯度是连续的,缓存命中率高。
- 并行策略不同:
- 特征并行 :LGB特征并行的前提是每个worker留有一份完整的数据集,但是每个worker仅在特征子集上进行最佳切分点的寻找;worker之间需要相互通信,通过比对损失来确定最佳切分点;然后将这个最佳切分点的位置进行全局广播,每个worker进行切分即可。XGB的特征并行与LGB的最大不同在于XGB每个worker节点中仅有部分的列数据,也就是垂直切分,每个worker寻找局部最佳切分点,worker之间相互通信,然后在具有最佳切分点的worker上进行节点分裂,再由这个节点广播一下被切分到左右节点的样本索引号,其他worker才能开始分裂。二者的区别就导致了LGB中worker间通信成本明显降低,只需通信一个特征分裂点即可,而XGB中要广播样本索引。
- 数据并行 :当数据量很大,特征相对较少时,可采用数据并行策略。LGB中先对数据水平切分,每个worker上的数据先建立起局部的直方图,然后合并成全局的直方图,采用直方图相减的方式,先计算样本量少的节点的样本索引,然后直接相减得到另一子节点的样本索引,这个直方图算法使得worker间的通信成本降低一倍,因为只用通信以此样本量少的节点。XGB中的数据并行也是水平切分,然后单个worker建立局部直方图,再合并为全局,不同在于根据全局直方图进行各个worker上的节点分裂时会单独计算子节点的样本索引,因此效率贼慢,每个worker间的通信量也就变得很大。
- 投票并行(LGB):当数据量和维度都很大时,选用投票并行,该方法是数据并行的一个改进。数据并行中的合并直方图的代价相对较大,尤其是当特征维度很大时。大致思想是:每个worker首先会找到本地的一些优秀的特征,然后进行全局投票,根据投票结果,选择top的特征进行直方图的合并,再寻求全局的最优分割点。
XGBoost面试题整理
AUC
- 定义:ROC曲线下的面积(横坐标为假阳性率FPR,纵坐标为真阳性率TPR/召回),ROC曲线对于模型预估的一个正例,如果真实标签是正例,就往上走,如果是负例,就往左走,遍历完所有样本形成的曲线就是ROC曲线。
- 含义:随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
- 计算方法:
- KaTeX parse error: Undefined control sequence: \* at position 38: …本}, P_{负样本})}{M\̲*̲N}。在KaTeX parse error: Undefined control sequence: \* at position 2: M\̲*̲N对样本里( M M M和 N N N分别表示正负样本的数量),统计正样本的预测概率大于负样本的预测概率的个数。
- A U C = ∑ i ∈ 正样本 r a n k ( i ) − M ( M + 1 ) 2 M ∗ N AUC=\frac{\sum_{i\in 正样本}rank(i)-\frac{M(M+1)}{2}}{M*N} AUC=M∗N∑i∈正样本rank(i)−2M(M+1)。 r a n k ( i ) rank(i) rank(i)表示按照预估概率升序排序后正样本 i i i的排序编号。对预估概率得分相同,将其排序编号取平均作为新的排序编号。
- 参考:
- 【回归基础】深入理解AUC指标
- AUC的计算方法
深度学习
激活函数
激活函数的主要作用是引入非线性变换,没有激活函数,神经网络层数再多,也只是简单的线性变换,无法处理复杂任务。
- 阶跃函数:用于二分类,但导数始终为0,不能用于反向传播,理论意义大于实际意义。
- sigmoid函数: f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1,用于二分类,X靠近0的时候,一点小小的值变化也能引起Y很大变化,说明函数区域将数值推向极值,很适合二分类。X远离0时,X值变化对Y起作用很小,函数的导数变化也很小,在反向传播中几乎起不到更新梯度的作用;且sigmoid函数只能得到正值,在很多情况下不适用。
- tanh函数: f ( x ) = e x − e − x e x + e − x f(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} f(x)=ex+e−xex−e−x,对sigmoid函数的改进,函数值在(-1, 1)之间,改善了sigmoid函数只能得到正值的缺点,其他特点与sigmoid函数一模一样。
- ReLU函数:近年使用广泛,优点是当输入值是负值时,输出值为0,意味着一段时间内只有部分神经元被激活,神经网络的这种稀疏性使其变得高效且易于计算。但X小于0时函数梯度为0,意味着反向传播时权重得不到更新,那么正向传播过程中输出值为0的神经元永远得不到激活,变成了死神经元。
- Leaky ReLU函数:解决了死神经元的问题。
- Softmax函数:可以看作是用作多分类的激活函数,将神经网络的输出值变成概率。
- 线性激活函数:效果等同于未激活,在Keras中不激活时就是用f(x)=x这一激活函数。二分类时用sigmoid函数和tanh函数,但存在梯度消失问题时应避免使用这两种函数。ReLU函数适用于绝大多数情况,如果存在梯度不更新的问题时可以用Leaky ReLU函数替代。
Softmax函数及求导
Softmax函数通常用于多分类问题中,它将一个包含任意实数的 K 维向量(K 是类别数量)映射为一个概率分布,每个类别的预测概率值都在 0 到 1 之间,所有类别的概率总和为 1。Softmax函数的作用是将原始得分转换为概率值,使得模型的输出更符合实际的概率分布。函数公式: S i = e a i ∑ k = 1 K e a k S_i=\frac{e^{a_i}}{\sum ^K_{k=1} e^{a_k}} Si=∑k=1Keakeai
其中, a a a 是输入向量,上述公式表示第 i i i 个类别的输出概率。函数求导分类讨论:
- 当 i = j i=j i=j时: ∂ S i ∂ a j = e a i ∑ − e a j e a i ∑ 2 = S i − S i S j \frac{\partial S_i}{\partial a_j}=\frac{e^{a_i}\sum-e^{a_j}e^{a_i}}{\sum ^2}=S_i-S_iS_j ∂aj∂Si=∑2eai∑−eajeai=Si−SiSj
- 当 i ≠ j i\not =j i=j时: ∂ S i ∂ a j = 0 − e a j e a i ∑ 2 = − S i S j \frac{\partial S_i}{\partial a_j}=\frac{0-e^{a_j}e^{a_i}}{\sum ^2}=-S_iS_j ∂aj∂Si=∑20−eajeai=−SiSj
Softmax函数及其导数
优化器
- 梯度下降法(Gradient Descent):最基本最常用的优化算法。通过计算损失函数关于参数的梯度,以负梯度方向更新参数,使损失函数最小化。梯度下降法有多个变种,如批量梯度下降、随机梯度下降和小批量梯度下降。
- g t = ▽ f ( θ t − 1 ) , △ θ t = − η ∗ g t g_t=▽f(θ_{t−1}), △θ_t=−η∗g_t gt=▽f(θt−1),△θt=−η∗gt
- 批梯度下降:每次使用所有数据用于更新梯度,使得梯度总是朝着最小的方向更新,但数据量很大的时候更新速度太慢,容易陷入局部最优。
- 随机梯度下降:每次使用一条数据来更新梯度,在梯度更新过程中梯度可能上升也可能下降,但总的来说梯度还是朝着最低的方向前进;最后梯度会在极小值附近徘徊。随机梯度下降的梯度更新速度快于批梯度下降,且由于每次梯度的更新方向不确定,陷入局部最优的时候有可能能跳出该局部极小值。
- mini-batch梯度下降:介于批梯度下降和随机梯度下降之间,每次用若干条数据更新梯度。mini-batch梯度下降可以使用矩阵的方式来计算梯度,因此速度快于随机梯度下降,且同样具有跳出局部最优的特点。
- 动量优化器(Momentum):引入动量项加速收敛过程。在参数更新时考虑之前的更新方向,在梯度方向上积累速度。如果本次梯度衰减方向与上一次相同,则可以加速梯度下降;如果不一致,则抑制梯度的改变。有助于在平坦区域中加快学习速度并减少震荡。
- m t = μ ∗ m t − 1 + ( 1 − μ ) g t m_t=μ∗m_{t−1}+(1−μ)g_t mt=μ∗mt−1+(1−μ)gt
- △ θ t = − η ∗ m t △θ_t=−η∗m_t △θt=−η∗mt
- 自适应动量估计(Adaptive Moment Estimation,Adam):基于一阶矩估计和二阶矩估计的自适应优化器。结合了动量和学习率衰减机制,并具有自适应学习率调整。在很多情况下能快速收敛。
- 自适应学习率优化器(Adagrad、RMSProp):Adagrad和RMSProp是常用的自适应学习率优化器。Adagrad适应性地调整参数的学习率,对于稀疏梯度的问题表现较好。RMSProp通过指数加权平均的方式动态调整学习率,适用于非平稳或具有较大梯度变化的问题。用初始学习率除以通过衰减系数控制的梯度平方和的平方根,相当于给每个参数赋予了各自的学习率。梯度相对平缓的地方,累积梯度小,学习率会增大;梯度相对陡峭的地方,累积梯度大,学习率会减小。从而加速训练。
- RMSprop: n t = ν n t − 1 + ( 1 − ν ) g t 2 n_t=νn_{t−1}+(1−ν)g_t^2 nt=νnt−1+(1−ν)gt2
- △ θ t = − η n t + ϵ ∗ g t △θ_t=−\frac{η}{\sqrt{n_t+ϵ}}*g_t △θt=−nt+ϵη∗gt
- Adam:本质上是带有动量项的RMSprop,结合了两者的优点,可以为不同的参数计算不同的自适应学习率,实践中常用。
- m t = μ m t − 1 + ( 1 − μ ) g t m_t=μm_{t−1}+(1−μ)g_t mt=μmt−1+(1−μ)gt
- n t = ν n t − 1 + ( 1 − ν ) g t 2 n_t=νn_{t−1}+(1−ν)g_t^2 nt=νnt−1+(1−ν)gt2
- m ^ t = m t 1 − μ t \hat m_t=\frac{m_t}{1−μ^t} m^t=1−μtmt
- n ^ t = n t 1 − ν t \hat n_t=\frac{n_t}{1−ν^t} n^t=1−νtnt
- △ θ t = − η n ^ t + ϵ △θ_t=-\frac{η}{\sqrt{\hat n_t+ϵ}} △θt=−n^t+ϵη
- AdamW:Adam的变种,主要用于解决权重衰减(weight decay)在Adam中的问题。在计算梯度更新时,将权重衰减的计算从梯度中分离出来,并将其应用于参数更新之前。使得权重衰减仅影响参数的更新方向,而不会降低参数的更新速度。优势在于更好地控制权重衰减的影响,减轻过度正则化的问题,使模型更易优化和训练。
残差连接
Residual Connection跳跃连接技术,在模型中将输入信号与输出信号进行直接连接。作用:
- 促进信息传递:使模型更容易传递信息和梯度,避免梯度消失或梯度爆炸,特别是在处理深层网络时。
- 简化优化问题:可以简化优化问题,使模型更易于优化和训练。
- 提高模型表达能力:允许模型保留更多的低层特征信息,使模型更好地捕捉输入序列中的细节和上下文信息。
DNN,CNN,RNN对比

池化层反向传播
反向传播在经过池化层的时候梯度的数量发生了变化。如2*2的池化操作,第L+1层梯度数量是L层的1/4,所以每个梯度要对应回4个梯度。
- mean_pooling:正向传播时取周围4个像素的均值,所以反向传播将梯度平均分成4分,再分给上一层。
- max_pooling:正向传播时取周围4个像素的最大值保留,其余的值丢弃,所以反向传播时将梯度对应回最大值的位置,其他位置取0。一般来说,为了知道最大值的位置,深度学习框架在正向传播时就用max_id来记录4个像素中最大值的位置。
浅层、深层神经网络差别
神经网络中,权重参数是给数据做线性变换,而激活函数给数据带来的非线性变换。增加某一层神经元数量是在增加线性变换的复杂性,而增加网络层数是在增加非线性变换的复杂性。理论上,浅层神经网络就能模拟任何函数,但需要巨大的数据量,而深层神经网络可以用更少的数据量来学习到更好的拟合。
防止过拟合
过拟合是模型学习能力太强大,把部分数据的不太一般的特性都学到了,并当成了整个样本空间的特性。防过拟合方法:
- L2正则化。原loss是 L 0 L_0 L0,加入L2正则化后loss是 L 0 + λ 2 n ∣ ∣ W ∣ ∣ 2 L_0+\frac{\lambda}{2n}||W||^2 L0+2nλ∣∣W∣∣2,L的梯度是 ∂ L ∂ W = ∂ L 0 ∂ W + λ n W \frac{\partial{L}}{\partial{W}}=\frac{\partial{L_0}}{\partial{W}}+\frac{\lambda}{n}{W} ∂W∂L=∂W∂L0+nλW, ∂ L ∂ b = ∂ L 0 ∂ b \frac{\partial{L}}{\partial{b}}=\frac{\partial{L_0}}{\partial{b}} ∂b∂L=∂b∂L0,可以看出,L2正则化只对W有影响,对b没有影响。而加入L2正则化后的梯度更新: W = W − α ( ∂ L 0 ∂ W + λ n W ) = ( 1 − α λ n ) W − α ∂ L 0 ∂ W W=W-\alpha(\frac{\partial{L_0}}{\partial{W}}+\frac{\lambda}{n}{W})=(1-\frac{\alpha\lambda}{n})W-\alpha\frac{\partial{L_0}}{\partial{W}} W=W−α(∂W∂L0+nλW)=(1−nαλ)W−α∂W∂L0,相比于原梯度更新公式,改变的是 ( 1 − 2 α λ ) W (1-2\alpha\lambda)W (1−2αλ)W这里,而由于 α 、 λ 、 n \alpha、\lambda、n α、λ、n都是正数,所以 ( 1 − α λ n ) < 1 (1-\frac{\alpha\lambda}{n})<1 (1−nαλ)<1。因此,L2正则化使得反向传播更新参数时W参数比不添加正则项更小。在过拟合中,由于对每个数据都拟合得很好,所以函数的变化在小范围内往往很剧烈,而要使函数在小范围内剧烈变化,就是要W参数值很大。L2正则化抑制了这种小范围剧烈变化,使得拟合程度“刚刚好”。
- L1正则化。原loss是 L 0 L_0 L0,加入L1正则化后loss是 L = L 0 + λ n ∣ W ∣ L=L_0+\frac{\lambda}{n}|W| L=L0+nλ∣W∣, L的梯度是 ∂ L ∂ W = ∂ L 0 ∂ W + λ n ∣ W ∣ \frac{\partial{L}}{\partial{W}}=\frac{\partial{L_0}}{\partial{W}}+\frac{\lambda}{n}|W| ∂W∂L=∂W∂L0+nλ∣W∣, ∂ L ∂ b = ∂ L 0 ∂ b \frac{\partial{L}}{\partial{b}}=\frac{\partial{L_0}}{\partial{b}} ∂b∂L=∂b∂L0, 可以看出,L1正则化只对W有影响,对b没有影响。而加入L1正则化后的梯度更新: W = W − α ( ∂ L 0 ∂ W + λ n ∣ W ∣ ) = W − λ n ∣ W ∣ − α ∂ L 0 ∂ W W=W-\alpha(\frac{\partial{L_0}}{\partial{W}}+\frac{\lambda}{n}{|W|})=W-\frac{\lambda}{n}|W|-\alpha\frac{\partial{L_0}}{\partial{W}} W=W−α(∂W∂L0+nλ∣W∣)=W−nλ∣W∣−α∂W∂L0, 如果W为正,相对于原梯度就减小;如W为负,相对于原梯度就增大。所以,L1正则化使得参数W在更新时向0靠近使得参数W具有稀疏性。而权重趋近0,也就相当于减小了网络复杂度,防止过拟合。
- Dropout。每次训练时,有一部分神经元不参与更新,而且每次不参与更新的神经元是随机的。随着训练的进行,每次用神经元就能拟合出较好的效果,少数拟合效果不好的也不会对结果造成太大的影响。
- 增大数据量。过拟合是学习到了部分数据集的特有特征,那么增大数据集就能有效的防止这种情况出现。
- Early stop。数据分为训练集、验证集和测试集,每个epoch后都用验证集验证一下,如果随着训练的进行训练集loss持续下降,而验证集loss先下降后上升,说明出现了过拟合,应该立即停止训练。
- Batch Normalization。每次都用一个mini_batch的数据来计算均值和反差,这与整体的均值和方差存在一定偏差,从而带来了随机噪声,起到了与Dropout类似的效果,从而减轻过拟合。
- L1 / L2对比:
- L1(拉格朗日Lasso)正则假设参数先验分布是Laplace分布,可以使权重稀疏,保证模型的稀疏性,某些参数等于0,产生稀疏权值矩阵,用于特征选择;
- L2(岭回归Ridge)正则假设参数先验分布是Gaussian分布,可以使权重平滑,保证模型的稳定性,也就是参数的值不会太大或太小。
- 在实际使用中,如果特征是高维稀疏的,则使用L1正则;如果特征是低维稠密的,则使用L2正则
BN层的计算
神经网络反向传播后每一层的参数都会发生变化,在下一轮正向传播时第 l l l 层的输出值 Z l = W ⋅ A l − 1 + b Z^l=W\cdot{A}^{l-1}+b Zl=W⋅Al−1+b 也会发生变化,导致第 l l l 层的 A l = r e l u ( Z l ) A^l=relu(Z^l) Al=relu(Zl) 发生变化。而 A l A^l Al 作为第 l + 1 l+1 l+1 层的输入, l + 1 l+1 l+1 就需要去适应适应这种数据分布的变化,这就是神经网络难以训练的原因之一。
为此,Batch Normalization的做法是调整数据的分布来改变这一现象,具体做法如下:
- 训练: 一般每次训练数据都是一个batch,假设 m = b a t c h _ s i z e m=batch\_size m=batch_size,则:
- 计算各个特征均值 μ = 1 m ∑ i = 1 m z i \mu=\frac{1}{m}\sum_{i=1}^{m}z^i μ=m1∑i=1mzi,其中 z i z^i zi 表示第 i i i 条数据
- 计算方差 σ 2 = 1 m ∑ i = 1 m ( z i − μ ) 2 \sigma^2=\frac{1}{m}\sum_{i=1}^{m}(z^i-\mu)^2 σ2=m1∑i=1m(zi−μ)2
- 归一化后的 Z n o r m i = z i − μ σ 2 + ϵ Z_{norm}^i=\frac{z^i-\mu}{\sqrt{\sigma^2+\epsilon}} Znormi=σ2+ϵzi−μ, ϵ \epsilon ϵ 表示一个极小值,防止计算出现Nan
- 这样调整分布后能加速训练,但之前层学习到的参数信息可能会丢失,所以加入参数 γ \gamma γ、 β \beta β 调整: Z ~ i = γ Z n o r m i + β \widetilde{Z}^i=\gamma{Z_{norm}^i}+\beta Z i=γZnormi+β
- 反向传播:
∂ L ∂ Z n o r m i = ∂ L ∂ Z ~ i λ \frac{\partial{L}}{\partial{Z_{norm}^i}}=\frac{\partial{L}}{\partial{\widetilde{Z}^i}}\lambda ∂Znormi∂L=∂Z i∂Lλ
∂ L ∂ λ = ∂ L ∂ Z ~ i Z n o r m i \frac{\partial{L}}{\partial\lambda}=\frac{\partial{L}}{\partial{\widetilde{Z}^i}}Z_{norm}^i ∂λ∂L=∂Z i∂LZnormi
∂ L ∂ β = ∂ L ∂ Z ~ i \frac{\partial{L}}{\partial\beta}=\frac{\partial{L}}{\partial{\widetilde{Z}^i}} ∂β∂L=∂Z i∂L
∂ L ∂ σ 2 = ∂ L ∂ Z n o r m i ∂ Z n o r m i ∂ σ 2 = ∂ L ∂ Z n o r m i ( − 1 2 ) ( σ 2 + ϵ ) − 3 2 \frac{\partial{L}}{\partial\sigma^2}=\frac{\partial{L}}{\partial{Z_{norm}^i}}\frac{\partial{Z_{norm}^i}}{\partial\sigma^2}=\frac{\partial{L}}{\partial{Z_{norm}^i}}(-\frac{1}{2})(\sigma^2+\epsilon)^{\frac{-3}{2}} ∂σ2∂L=∂Znormi∂L∂σ2∂Znormi=∂Znormi∂L(−21)(σ2+ϵ)2−3
∂ L ∂ μ = ∂ L ∂ Z n o r m i ∂ Z n o r m i ∂ μ + ∂ L ∂ σ 2 ∂ σ 2 ∂ μ = ∂ L ∂ Z n o r m i − 1 σ 2 + ϵ + ∂ L ∂ σ 2 − 2 ∑ i = 1 m ( z i − μ ) m \frac{\partial{L}}{\partial\mu}=\frac{\partial{L}}{\partial{Z_{norm}^i}}\frac{\partial{Z_{norm}^i}}{\partial\mu}+\frac{\partial{L}}{\partial\sigma^2}\frac{\partial{\sigma^2}}{\partial{\mu}}=\frac{\partial{L}}{\partial{Z_{norm}^i}}\frac{-1}{\sqrt{\sigma^2+\epsilon}}+\frac{\partial{L}}{\partial\sigma^2}\frac{-2\sum_{i=1}^{m}(z^i-\mu)}{m} ∂μ∂L=∂Znormi∂L∂μ∂Znormi+∂σ2∂L∂μ∂σ2=∂Znormi∂Lσ2+ϵ−1+∂σ2∂Lm−2∑i=1m(zi−μ)
∂ L ∂ Z i = ∂ L ∂ Z n o r m i ∂ Z n o r m i ∂ Z i + ∂ L ∂ σ 2 ∂ σ 2 ∂ Z i + ∂ L ∂ μ ∂ μ ∂ Z i = ∂ L ∂ Z n o r m i 1 σ 2 + ϵ + ∂ L ∂ σ 2 2 ( Z i − μ ) m + ∂ L ∂ μ 1 m \frac{\partial{L}}{\partial{Z^i}}=\frac{\partial{L}}{\partial{Z_{norm}^i}}\frac{\partial{Z_{norm}^i}}{\partial{Z^i}}+\frac{\partial{L}}{\partial\sigma^2}\frac{\partial{\sigma^2}}{\partial{Z^i}}+\frac{\partial{L}}{\partial\mu}\frac{\partial\mu}{\partial{Z^i}}=\frac{\partial{L}}{\partial{Z_{norm}^i}}\frac{1}{\sqrt{\sigma^2+\epsilon}}+\frac{\partial{L}}{\partial\sigma^2}\frac{2(Z^i-\mu)}{m}+\frac{\partial{L}}{\partial\mu}\frac{1}{m} ∂Zi∂L=∂Znormi∂L∂Zi∂Znormi+∂σ2∂L∂Zi∂σ2+∂μ∂L∂Zi∂μ=∂Znormi∂Lσ2+ϵ1+∂σ2∂Lm2(Zi−μ)+∂μ∂Lm1 - 测试: 测试时一般每次只送入一个数据,计算其均值和方差都是有偏估计,但训练过程中保存了每一组batch每一层的均值和方差,则对每一层都可以使用均值和方差的无偏估计:
μ t e s t = E ( μ b a t c h ) \mu_{test}=E(\mu_{batch}) μtest=E(μbatch)
σ t e s t 2 = m m − 1 E ( σ b a t c h 2 ) \sigma^2_{test}=\frac{m}{m-1}E(\sigma^2_{batch}) σtest2=m−1mE(σbatch2)
然后计算该层的输出: Z ~ i = γ Z t e s t i − μ σ t e s t 2 + ϵ + β \widetilde{Z}^i=\gamma{\frac{Z^i_{test}-\mu}{\sqrt{\sigma_{test}^2+\epsilon}}}+\beta Z i=γσtest2+ϵZtesti−μ+β - 加在哪里: 原始论文中加在激活函数前面,但改论文部分作者主张加在激活函数后面,从实践上来说也是加在激活函数后面效果更好。
- 局限: 实验表明,当batch_size小于8时,BN反而会带来负面作用;不适用于RNN
负梯度方向是函数局部值最快的方向
假设存在函数f(x),l是任意方向的单位向量,要现在的目的就是要找到一个l使得f(x+l)−f(x)的变化值最大。根据公式有 f ( x + l ) − f ( x ) = < g r a d f , l > f(x+l)-f(x)=<grad_f, l> f(x+l)−f(x)=<gradf,l>,所以原问题变为找到l使得 ∣ g r a d f ∣ ∗ ∣ l ∣ ∗ c o s ( θ ) |grad_f|*|l|*cos(\theta) ∣gradf∣∗∣l∣∗cos(θ)最大,其中θ是 l与 g r a d f grad_f gradf的夹角),很明显 θ = 0 \theta=0 θ=0时该值最大,也就是说l方向就是 g r a d f grad_f gradf的方向,从而证明梯度方向是使得函数局布值变化最快的方向。
softmax loss和cross entropy
输入数据经过神经网络后得到的logits是一个[n, 1]向量(n表示进行n分类),此时向量中的数字可以是负无穷到正无穷的任意数字,经过softmax函数后才转换为概率。交叉熵函数形式与softmax loss函数几乎一样,当cross entropy的输入是softmax函数函数的输出时,二者就完全一样。将网络输出的预测值logit先用使用Softmax转换为预测概率值再传入 Cross Entropy Loss,就得到了最终的Softmax Loss。
- softmax: P i = e i ∑ k = 1 n e k P_i=\frac{e^i}{\sum_{k=1}^{n}e^k} Pi=∑k=1nekei
- softmax loss: L = − ∑ i = 1 n y i l o g p i L=-\sum_{i=1}^{n}y_ilogp_i L=−∑i=1nyilogpi
- cross entropy: L = − ∑ i = 1 n y i l o g p i L=-\sum_{i=1}^{n}y_ilogp_i L=−∑i=1nyilogpi
- logistic regression: L = − y i l o g p i − ( 1 − y i ) l o g ( 1 − p i ) L=-y_ilogp_i-(1-y_i)log(1-p_i) L=−yilogpi−(1−yi)log(1−pi)
全连接层作用
- “分类”,将卷积层提取到的特征进行维数调整,同时融合各通道之间的信息。
- 在迁移学习的过程中,有全连接层的模型比没有全连接层的表现更好。
RNN和LSTM
RNN的优缺点:
- 优点:
- 参数共享: RNN在每个时间步都使用相同的参数,因此在训练和预测时具有较小的计算负担。
- 灵活性: RNN可以处理各种长度的序列输入,并且可以用于不同的任务,如语言模型、时间序列预测等。
- 缺点:
- 梯度消失或爆炸: RNN在处理长期依赖关系时容易出现梯度消失或爆炸的问题,导致难以捕捉远距离的依赖关系。
- 短期记忆限制: RNN的短期记忆相对较弱,难以有效地记住较长的历史信息。
LSTM的优缺点:
- 优点:
- 长期依赖关系: LSTM通过门控机制(遗忘门、输入门、输出门)有效地解决了长期依赖问题,能够更好地捕捉长距离的序列依赖关系。
- 记忆单元: LSTM引入了记忆单元,可以保留和更新信息,有助于记住长序列中的重要信息。
- 防止梯度消失: LSTM通过门控机制可以更有效地控制梯度的流动,减少了梯度消失或爆炸的问题。
- 缺点:
- 计算复杂度高: LSTM相对于普通的RNN计算量更大,因为它包含更多的门控单元和参数。
- 可能出现过拟合: LSTM模型相对复杂,可能在小样本数据上容易出现过拟合的情况。
Transformer相对LSTM的优势
- Transformer更快,对较长的序列建模效果更好,减少了对顺序信息的依赖性,不需要前面的信息来更新后面的隐状态。Transformer能更好的处理长期依赖问题,使得它在生成式任务中的表现尤为突出。
- Transformer需要更多的数据来训练。但是transformer并行训练,速度更快;用更多的数据训练lstm,表现却不会再提升,上限低;很多efficient transformer减少了计算复杂度,或者加入一些先验信息来减少对预训练的依赖,都取得了很好的performance。
RNN不用Relu要用tanh函数?
CNN中用ReLU函数能解决梯度消失的问题是因为Relu函数梯度为1,能解决梯度爆炸的问题是因为反向传播时W互不相同,它们连乘很大程度上能抵消梯度爆炸的效果;而RNN中用Relu是若干个W连乘,不能解决梯度爆炸的问题。所以想要解决RNN中的梯度消失问题,一般都是用LSTM。
Transformer
一种基于自注意力机制的序列到序列(Sequence-to-Sequence)模型,用于处理NLP任务,解决长依赖问题和并行计算效率的平衡。相比于RNN模型Transformer使用全局的自注意力机制,使模型可以同时关注输入序列的所有位置,更好地捕捉长距离依赖关系。Transformer引入多头注意力机制提高了模型的表达能力。Transformer两个关键组件组成:Encoder和Decoder。编码器将输入序列编码为一系列上下文相关的表示,解码器用这些表示生成目标序列。
- 编码器,输入序列经过多层自注意力层和前馈神经网络层处理。自注意力层中输入序列的每个位置都与其他位置进行注意力计算,以获取位置之间的相关性。使得模型能够在不同位置之间建立上下文关联,能够处理长距离的依赖关系。
- 解码器,除自注意力层和前馈神经网络层,还包含一个编码器-解码器注意力层。交叉注意力层将编码器中的信息与解码器的当前位置关联,在生成目标序列时获得更好的上下文信息。
- Transformer端到端训练,最大化目标序列的条件概率来进行模型优化。训练中使用掩码注意力(Masked Attention)确保解码器只能看到当前位置之前输入,避免信息泄露。
Transformer优点:
- 能处理长距离依赖关系,适用于处理包含长序列的任务。
- 并行计算效率高,使得模型在GPU上能够进行高效训练和推理。
- 具有较好的表示能力和泛化能力,在多个NLP任务上取得了优异的性能。
Transformer对大规模数据和计算资源的需求较高,对某些任务可能需要更多的参数调优和数据预处理。
位置编码
单词在句子中的位置以及排列顺序是非常重要的,引入词序信息有助于理解语义。循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
好的位置编码方案需满足:
- 能为每个时间步输出一个独一无二的编码;
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致;
- 模型应该能毫不费力地泛化到更长的句子。它的值应该是有界的;
- 必须是确定性的。
Transformer位置编码不是单一的一个数值,而是包含句子中特定位置信息的d维向量(非常像词向量)。编码没有整合进模型,而是用这个向量让每个词具有它在句子中的位置的信息。换句话说,通过注入词的顺序信息来增强模型输入。
把512维的向量两两一组,每组都是一个sin和一个cos,这两个函数共享同一个频率 w i w_i wi,共256组,从0开始编号,最后一组编号是255。sin/cos函数的波长(由 w i w_i wi决定)则从 2π 增长到 2π * 10000。位置编码性质:
- 两个位置编码的点积(dot product)仅取决于偏移量 △t,也即两个位置编码的点积可以反应出两个位置编码间的距离。
- 位置编码的点积是无向的,即KaTeX parse error: Undefined control sequence: \* at position 7: PE_t^T\̲*̲PE_{t+△t}=PE_t^…
Transformer学习笔记一:Positional Encoding(位置编码)
一文读懂Transformer模型的位置编码
head降维
Transformer的多头注意力看上去是借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息。即希望每个注意力头只关注最终输出序列中一个子空间,互相独立。核心思想在于抽取到更加丰富的特征信息。如果只使用 one head 并且维度为 d m o d e l d_{model} dmodel ,相较于 8 head 并且维度为 d m o d e l / 8 d_{model} / 8 dmodel/8,存在高维空间下学习难度较大的问题,文中实验也证实了这一点,于是将原有的高维空间转化为多个低维子空间并再最后进行拼接,取得了更好的效果,十分巧妙。
transformer中multi-head attention中每个head为什么要进行降维?
自注意力比例系数
d k d_k dk是词向量/隐藏层的维度,QK的维度也是 d k d_k dk,QK越大,相乘后的varience越大,除以 d k d_k dk来平衡。
- 除以根号 d k d_k dk防止输入softmax的值过大,导致偏导数趋近于0
- 选择根号 d k d_k dk可以使得Q*K的结果满足期望为0,方差为1的分布,类似于归一化。
预测与推理阶段都使用mask原因
- 训练阶段:训练时计算loss,是用当前decoder输入所有单词对应位置的输出 y 1 , y 2 , . . . , y t y_1,y_2,...,y_t y1,y2,...,yt与真实的翻译结果ground truth去分别算cross entropy loss,然后把t个loss加起来,如果使用self-attention,那么 y 1 y_1 y1这个输出里包含了 x 1 x_1 x1右侧单词信息(包含要预测下一个单词 x 2 x_2 x2的信息),用到了未来信息,属于信息泄露。
- 预测阶段:预测阶段要保持重复单词预测结果是一样的,这样不仅合理,而且可以增量更新(预测时会选择性忽略重复的预测词,只摘取最新预测的单词拼接到输入序列中),如果关掉dropout,那么当预测序列是 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3时的输出结果,应该是和预测序列是 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4的前3个位置结果是一样的(增量更新);同时与训练时的模型架构保持一致,前向传播的方式是一致的。
从训练和预测角度来理解Transformer中Masked Self-Attention的原理
代码
通过pytorch深入理解transformer中的自注意力(self attention)
BERT和GPT区别
二者都是采用「预训练+微调」的范式,
- BERT:几乎就是为「无监督预训练+下游任务微调」的范式量身定制的模型。BERT使用的掩码语言模型任务没有生成文本的能力,但换来的是双向编码的能力,这让模型拥有了更强的文本编码性能。主要用于解决语言理解相关的任务,如问答、语义关系抽取等。BERT更适用于在已有标注数据上微调的场景。
- GPT:基于生成式预训练的思想开发,为了保留生成文本的能力,只能采用单向编码。主要用于解决语言生成相关的任务,如文本生成、机器翻译等。GPT更适用于在大量未标注数据上预训练的场景。
深度学习模型和树模型的优缺点
深度学习模型的优缺点:
- 优点:
- 擅长处理复杂数据: 对于大规模数据、高维数据和非线性关系,深度学习模型通常能够提供更好的拟合能力。
- 特征学习能力强: 能够自动学习和提取数据的特征,减少对特征工程的需求。
- 泛化能力强: 在大数据集上训练时,深度学习模型可能会产生更好的泛化效果,适用于更广泛的场景。
- 缺点:
- 需要大量数据和计算资源: 深度学习模型对于大规模数据集和复杂模型的训练需要大量的数据和高性能计算资源。
- 需要调参和调优: 模型架构复杂,需要仔细调整超参数和优化模型结构。
- 可解释性差
树模型的优缺点:
- 优点:
- 易解释性强:能够直观地展示特征重要性和决策过程。
- 对少量数据处理得当: 在数据较少或者数据质量较差的情况下,树模型表现通常较好。
- 训练和预测速度快: 相对于深度学习模型,树模型的训练速度快,适合于处理中小规模的数据集。
- 缺点:
- 容易过拟合: 在某些情况下,树模型容易过拟合,尤其是当树的深度较大或没有采用适当的剪枝措施时。
- 不擅长处理复杂关系: 对于复杂的非线性关系,树模型可能不如深度学习模型表现得好。
- 需要人工特征工程: 对于传统的决策树模型,通常需要手动进行特征工程,挑选和构建合适的特征。
计算机视觉
图像处理中一般用最大池化而不用平均池化
池化的主要目的:
- 保持主要特征不变的同时减小了参数
- 保持平移、旋转、尺度不变性,增强了神经网络的鲁棒性
最大池化更能捕捉图像上的变化、梯度的变化,带来更大的局部信息差异化,从而更好地捕捉边缘、纹理等特征。
计算感受野
卷积层(conv)和池化层(pooling)都会影响感受野,激活函数层通常对于感受野没有影响,当前层的步长并不影响当前层的感受野,感受野和填补(padding)没有关系, 计算当层感受野的公式如下:
R F i + 1 = R F i + ( k − 1 ) × S i RF_{i+1}=RF_i+(k-1) \times S_i RFi+1=RFi+(k−1)×Si
其中, R F i + 1 RF_{i+1} RFi+1 表示当前层的感受野, R F i RF_i RFi 表示上一层的感受野, k k k 表示卷积核的大小, S i S_i Si 表示之前所有层的步长的乘积(不包括本层),公式如下:
S i = ∏ i + 1 i S t r i d e i S_i=\prod^i_{i+1}Stride_i Si=i+1∏iStridei
感受野(Receptive Field)的理解与计算
大数据处理
Spark的核心构件
Spark是一个通用的、分布式计算框架,用于大规模数据处理和分析。它提供了许多核心构件用于构建高性能、可扩展的分布式应用程序。核心构件:
- 基础模块Spark Core,提供分布式任务调度、内存管理、错误恢复、存储管理和与底层资源管理系统的交互等功能。定义了RDD(弹性分布式数据集)抽象,支持数据的并行处理和分布式计算。
- Spark SQL,用于处理结构化数据。提供了对结构化数据的高级查询、SQL查询、数据集的操作和集成的机器学习功能。Spark SQL支持多种数据源,包括Hive、Avro、Parquet等,并提供了DataFrame和DataSet两种API。
- 流处理模块Spark Streaming,用于实时数据的处理和分析。支持从各种数据源(如Kafka、Flume、HDFS等)读取实时数据流,并提供高级API来进行数据处理和转换。Spark Streaming使用微批处理的方式,将实时数据划分为小批量进行处理,实现低延迟的流处理。
- 机器学习库MLlib,提供一组分布式的机器学习算法和工具。包括常见机器学习算法(如分类、回归、聚类、推荐等),特征提取、模型评估和调优等功能。MLlib支持使用DataFrame和DataSet进行数据操作和特征工程,并提供分布式计算能力。
- 图处理库GraphX,用于处理大规模图数据。提供图的创建、转换、操作和算法等功能,支持基于顶点和边属性的图分析。GraphX提供高效的分布式图计算引擎,与Spark其他模块集成,使图计算和图分析更加高效和灵活。
- Spark还提供了一些其他扩展模块和工具,如SparkR(用于R语言的接口)、Spark on Kubernetes(在Kubernetes上运行Spark应用程序)等。
Spark数据倾斜
原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,如按照key聚合或join。如果某个key对应的数据量特别大的话,就会发生数据倾斜。整个Spark作业的运行进度是由运行时间最长的那个task决定的。
原因:常用的且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能是代码中使用了这些算子中的某一个所导致的。
解决方案:由于Spark都是基于RDD的特性,所以可以用纯RDD的方法,实现和Spark SQL一模一样的功能。在Spark Core中的数据倾斜的七种解决方案,全部都可以直接套用在Spark SQL上。
- 聚合源数据:
- 原理:使用 Hive ETL 预处理数据,对数据按照key进行聚合,或预先和其他表进行join,然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join,在Spark作业中就不需要使用原先的shuffle类算子执行这类操作。
- 优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
- 缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
- 过滤导致倾斜的key:在sql中用where条件
- 原理: 动态判定哪些key的数据量最多然后再进行过滤,可以使用sample算子对RDD进行采样,计算出每个key的数量,取数据量最多的key过滤掉即可。
- 优点:实现简单,效果好,可以完全规避掉数据倾斜。
- 缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。s
- 提高shuffle并行度:groupByKey(1000),spark.sql.shuffle.partitions(默认是200)
- 原理:该参数设置了shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,如group by、join需要设置一个参数,即spark.sql.shuffle.partitions,代表了shuffle read task的并行度。增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。
- 优点:实现起来简单,可以有效缓解和减轻数据倾斜的影响。
- 缺点:只是缓解了数据倾斜,没有彻底根除问题,效果有限。
- 两阶段聚合(局部聚合+全局聚合):双重groupBy,改写SQL,两次groupBy
- 原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,可以让原本被一个task处理的数据分散到多个task上去做局部聚合,解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,得到最终的结果。
- 优点:对于聚合类的shuffle操作导致的数据倾斜,效果不错。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
- 缺点:仅仅适用于聚合类的shuffle操作,适用范围较窄。如果是join类的shuffle操作,还得用其他的解决方案。
- reduce join转换为map join:
- 原理:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用需要的方式连接起来。
- 优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
- 缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。需要将小表进行广播会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
- 采样倾斜key并分拆join操作:纯Spark Core的一种方式,sample、filter等算子
- 原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。
- 优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
- 缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,这种方式也不适合。
- 使用随机前缀和扩容RDD进行join
- 原理:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方案六”的不同之处就在于,上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
- 优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
- 缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
万字详解 Spark 数据倾斜及解决方案
MapReduce
MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一是分布式计算框,就是MapReduce。MapReduce的思想就是“分而治之”。
- Mapper负责“分”,把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
- Reducer负责对map阶段的结果进行汇总。用户可以根据具体问题设置Reducer数量,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
其他
树结构在操作系统中的应用
数据结构与算法中,树一般会应用在哪些方面?为什么?
TensorFlow和PyTorch区别及优缺点对比
两者之间最重要的区别是这些框架定义计算图的方式。Tensorflow1.0 创建的是静态图(2.0为动态图),PyTorch 是动态图。Tensorflow1.0 中,必须定义模型的整个计算图,然后运行 ML 模型。在 PyTorch 中,可以随时随地定义/操作图形。这在 RNN 中使用可变长度输入时比较有用。
- 模型可用性:PyTorch 在研究领域占据主导地位。虽然 TensorFlow 2 解决了研究者使用该框架进行研究的一些痛点,但 PyTorch 却没有给研究者回头的理由。此外,TensorFlow 两大版本之间的向后兼容性问题只会让这种趋势愈演愈烈。
- 部署便捷性:TensorFlow 胜出。TensorFlow 依然在部署方面占有优势。Serving 和 TFLite 比 PyTorch 的同类型工具要稳健一些。而且,将 TFLite 与谷歌的 Coral 设备一起用于本地 AI 的能力是许多行业的必备条件。PyTorch Live 只专注于移动平台,而 TorchServe 仍处于起步阶段。
- 生态系统:TensorFlow 更胜一筹。尽管 PyTorch (Facebook) 和 TensorFlow (Google) 有很多相似和共享的资源,。谷歌投入巨资确保深度学习的每个相关领域都有完善的产品。与 Google Cloud 和 TFX 的紧密集成使端到端的开发过程变得轻而易举,而将模型移植到 Google Coral 设备的便利性让 TensorFlow 在某些行业取得了压倒性的胜利。
- 参考:
- PyTorch VS TensorFlow:细数两者的不同之处
- 2022 年了,PyTorch 和 TensorFlow 你选哪个?
相关文章:
算法工程师面试八股(搜广推方向)
文章目录 机器学习线性和逻辑回归模型逻辑回归二分类和多分类的损失函数二分类为什么用交叉熵损失而不用MSE损失?偏差与方差Layer Normalization 和 Batch NormalizationSVM数据不均衡特征选择排序模型树模型进行特征工程的原因GBDTLR和GBDTRF和GBDTXGBoost二阶泰勒…...
)
学习TypeScrip4(数组类型)
数组的类型 1.定义方法:类型[ ] //类型加中括号 let arr:number[] [123] //这样会报错定义了数字类型出现字符串是不允许的 let arr:number[] [1,2,3,1] //操作方法添加也是不允许的 let arr:number[] [1,2,3,] arr.unshift(1)var arr: number[] [1, 2, 3]; /…...
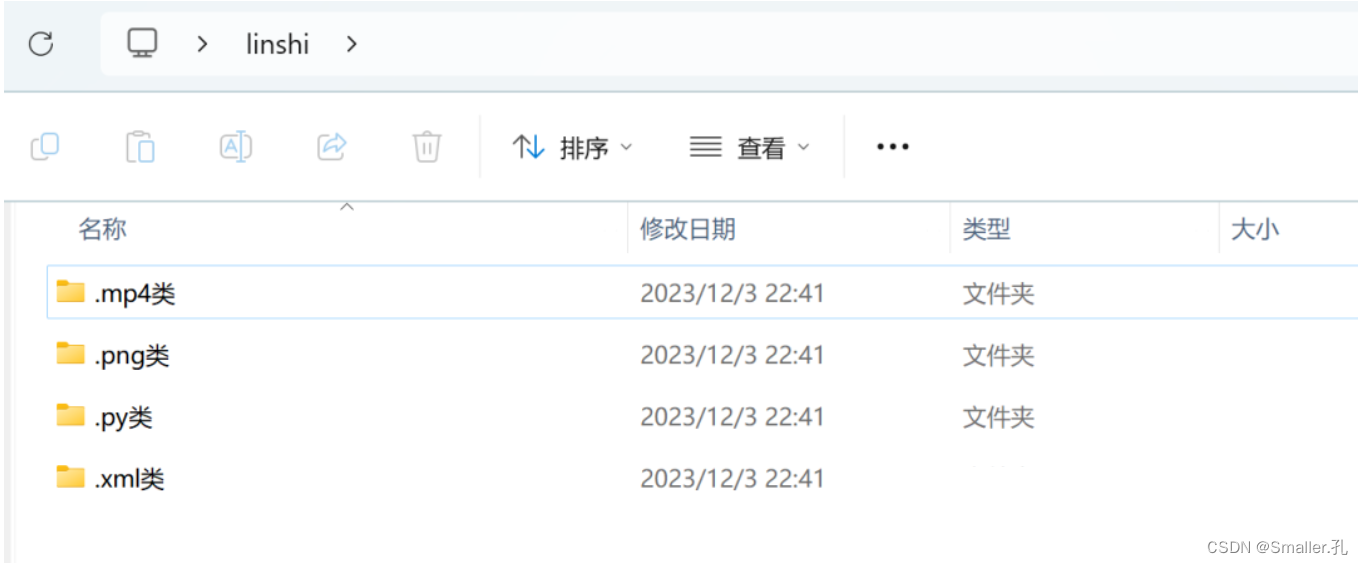
Python文件打包成exe可执行文件
我们平常用python写些脚本可以方便我们的学习办公,但限制就是需要有python环境才能运行。 那能不能直接在没有python环境的电脑上运行我们的脚本呢? 当然可以,那就是直接把python脚本打包成exe可执行程序(注针对win系统…...
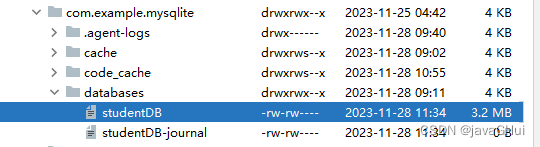
Android : SQLite 增删改查—简单应用
示例图: 学生实体类 Student.java package com.example.mysqlite.dto;public class Student {public Long id;public String name;public String sex;public int age;public String clazz;public String creatDate;//头像public byte[] logoHead;Overridepublic St…...

【蓝桥杯】马的遍历
马的遍历 题目描述 有一个 n m n \times m nm 的棋盘,在某个点 ( x , y ) (x, y) (x,y) 上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。 输入格式 输入只有一行四个整数,分别为 n , m , x , y n, m, x, y n,m,x,y。 …...

导入JSON到xmind
写在前面 这只是一个思路,解决大量树状数据,创建xmind低效问题。 函数可以根据你的实际情况优化 1. 转换json格式 function formatToXimd(atd, str) {if (atd) {for (let index 0; index < atd.length; index) {console.log(str - atd[index].…...
DataGrip 2023.2.3(IDE数据库开发)
DataGrip是一款数据库集成开发环境(IDE),用于数据库管理和开发。 DataGrip提供了许多强大的功能,如SQL语句编辑、数据库连接管理、数据导入和导出、数据库比较和同步等等。它支持多种数据库,如MySQL、PostgreSQL、Ora…...

身为 Go 程序员,我为啥更喜欢用 Zig?
Zig 是一种比较新的编程语言,于 2016 年首次推出。Zig 社区将其描述为“一种用于维护稳固的、可优化和可重用软件的通用编程语言”。 看似一句简单的描述,却隐藏着远大的抱负。Zig被看作是可与C语言一较高下的编程语言。此外,Zig 也是一个编…...
Amazon CodeWhisperer 使用体验
文章作者:STRIVE Amazon CodeWhisperer 是最新的代码生成工具,支持多种编程语言,如 java,js,Python 等,能减少开发人员手敲代码时间,提升工作效率。PS:本人是一名 CodeWhisperer 业余爱好者 亚马逊云科技开发者社区为开…...
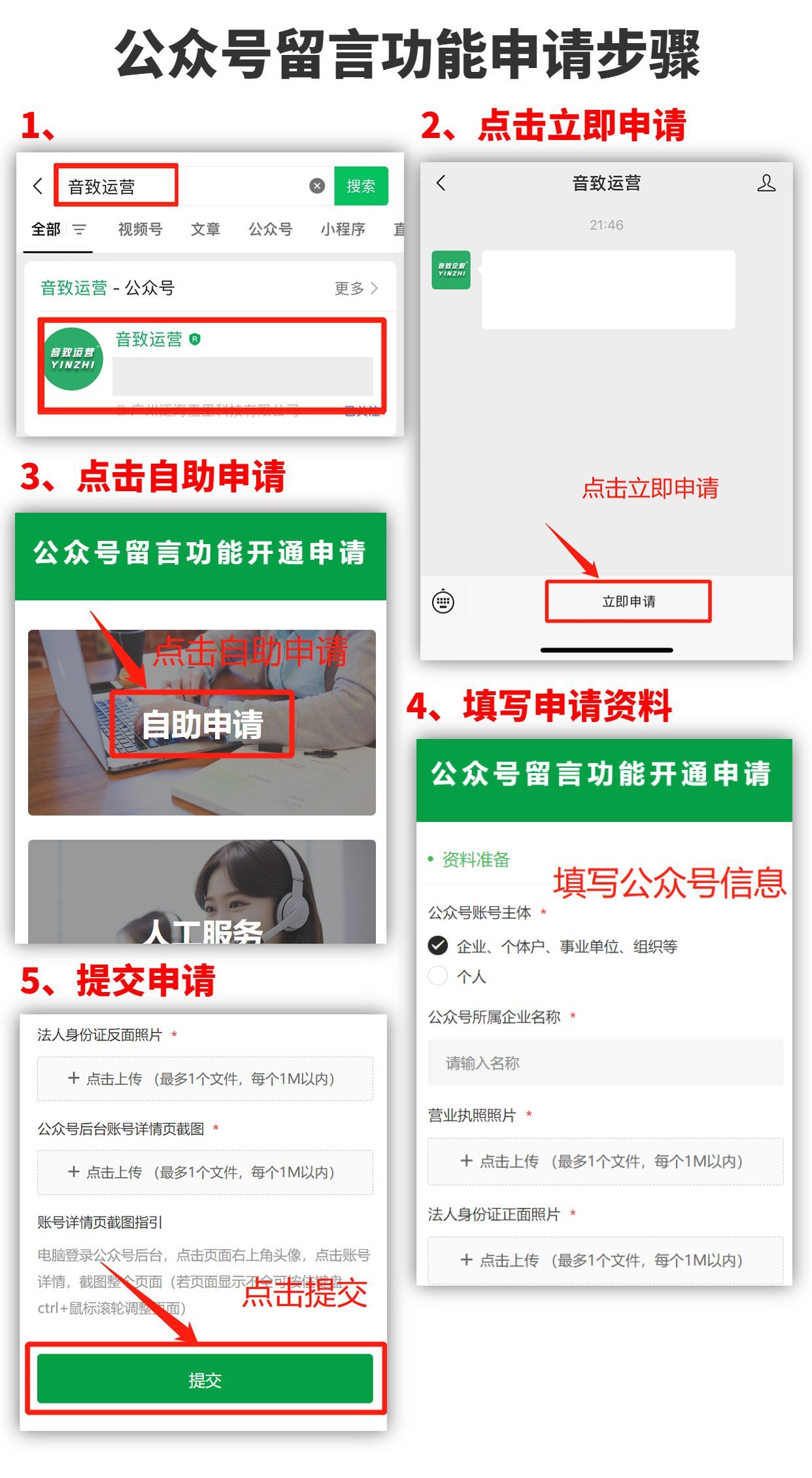
公众号留言功能怎么申请?
为什么公众号没有留言功能?2018年2月12日,TX新规出台:根据相关规定和平台规则要求,我们暂时调整留言功能开放规则,后续新注册帐号无留言功能。这就意味着2018年2月12日号之后注册的公众号不论个人主体还是组织主体&…...
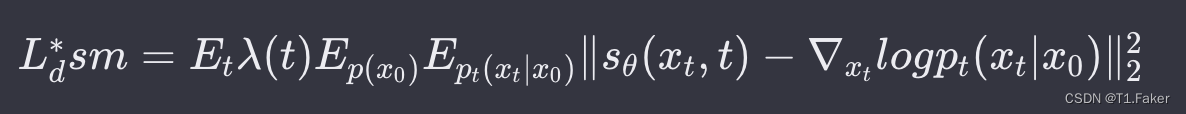
探索三种生成模型:基于DDPMs、NCSNs和SDEs方法的Diffusion
探索三种生成模型:基于DDPMs、NCSNs和SDEs方法的Diffusion 去噪扩散概率模型(DDPMs)正向过程反向过程 噪声条件得分网络(NCSNs)正向过程初始化训练 NCSNs生成样本 反向过程 随机微分方程(SDEs)原…...
)
Linux随记(七)
一、欧拉bclinux 21.10安装zabbix-5.0.37.tar.gz (zbx-客户端) #系统环境: BigCloud Enterprise Linux For Euler 21.10 LTS #软件信息: zabbix-5.0.37.tar.gz , pcre-devel-8.44-2.oe1.x86_64.rpm , inst…...

RESTful API,以及如何使用它构建 web 应用程序。
RESTful API是一种基于REST(Representational State Transfer)架构风格的API(Application Programming Interface),它采用HTTP协议中的GET、POST、PUT、DELETE等方法,对资源进行操作。RESTful API的核心思想…...
【华为OD题库-075】拼接URL-Java
题目 题目描述: 给定一个url前缀和url后缀,通过,分割。需要将其连接为一个完整的url。 如果前缀结尾和后缀开头都没有/,需要自动补上/连接符 如果前缀结尾和后缀开头都为/,需要自动去重 约束:不用考虑前后缀URL不合法情况 输入描述: url前缀(一个长度小于…...
【Unity动画】为一个动画片段添加事件Events
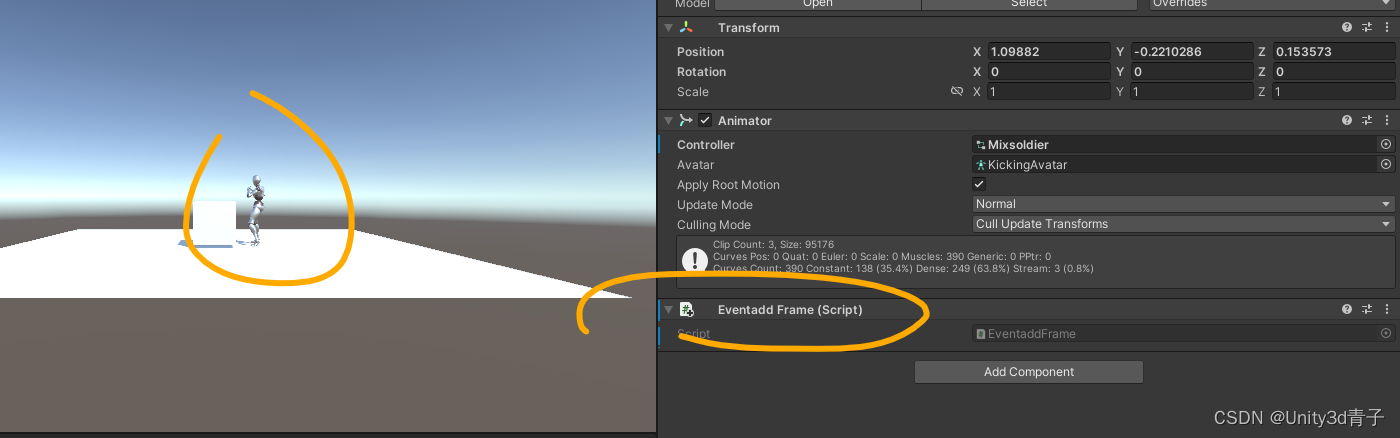
动画不管播放到那一帧,我们都可以在这里“埋伏”一个事件(调用一个函数并且给函数传递一个参数,参数在外部设置,甚至传递一个物体)! 嗨,亲爱的Unity小伙伴们!你是否曾想过为你的动画…...
CoDeF视频处理——视频风格转化部署使用与源码解析
一、算法简介与功能 CoDef是作为一种新型的视频表示形式,它包括一个规范内容场,聚合整个视频中的静态内容,以及一个时间变形场,记录了从规范图像(即从规范内容场渲染而成)到每个单独帧的变换过程。针对目标…...

ubuntu server 20.04 备份和恢复 系统 LTS
ubuntu server 20.04 备份和恢复 系统 LTS tar命令系统备份与恢复(还原or新装) 备份系统 cd / su root tar cvpzf backup.tgz --exclude/tmp --exclude/run --exclude/dev --exclude/snap --exclude/proc --exclude/lostfound --exclude/backup.tgz …...

NFC对物联网开发的影响及用途
当谈到NFC对物联网的影响时,不得不提它的几个重要的优势,可能在未来几年影响着物联网的发展方向。 全球智能手机的普及是其中一个重要因素:市面上已有数十亿部支持NFC的智能手机,专家们相信这个数字还会大幅增长。智能手机用户已…...
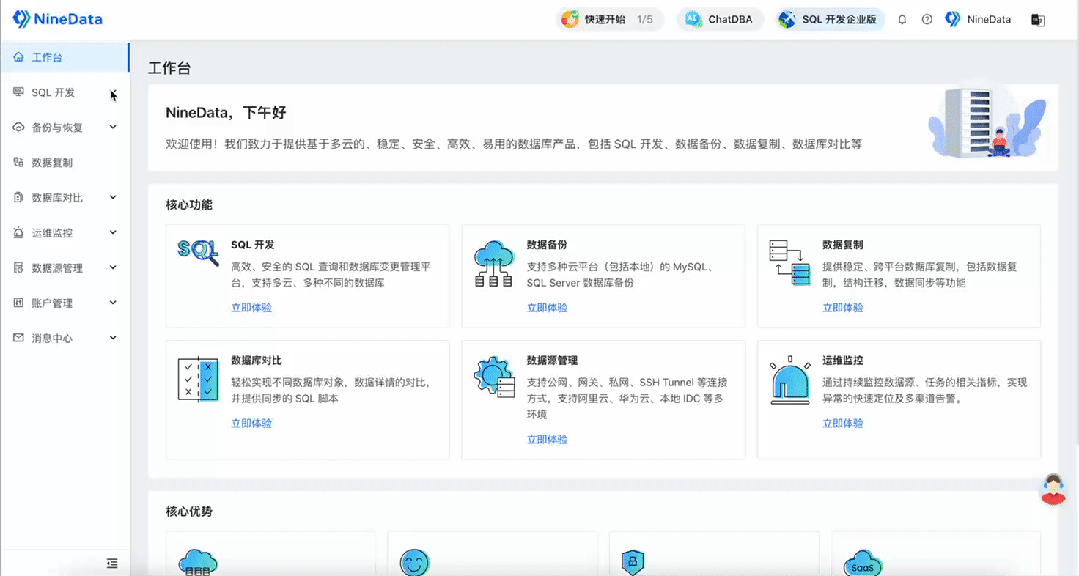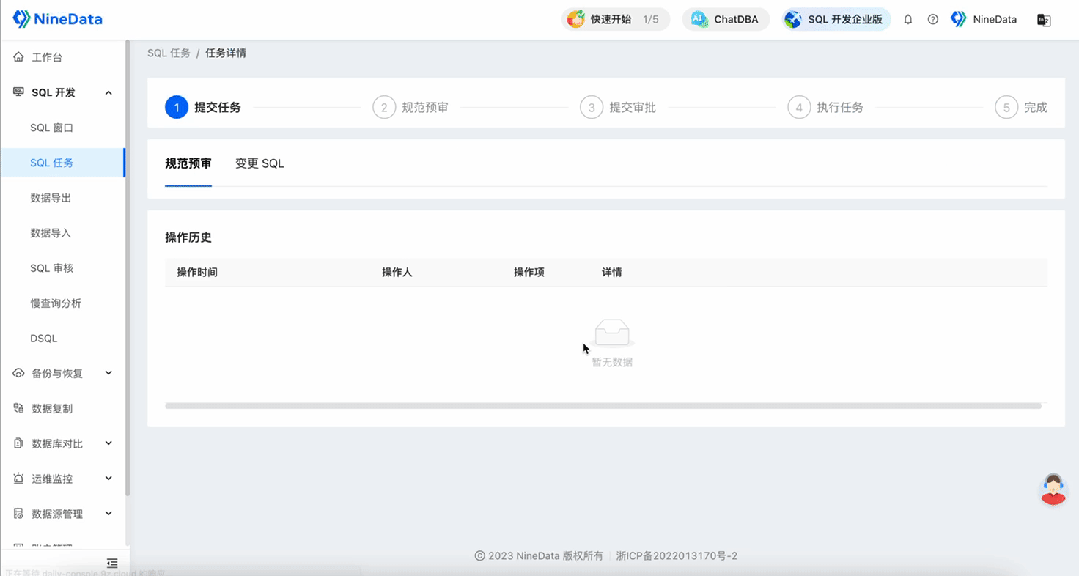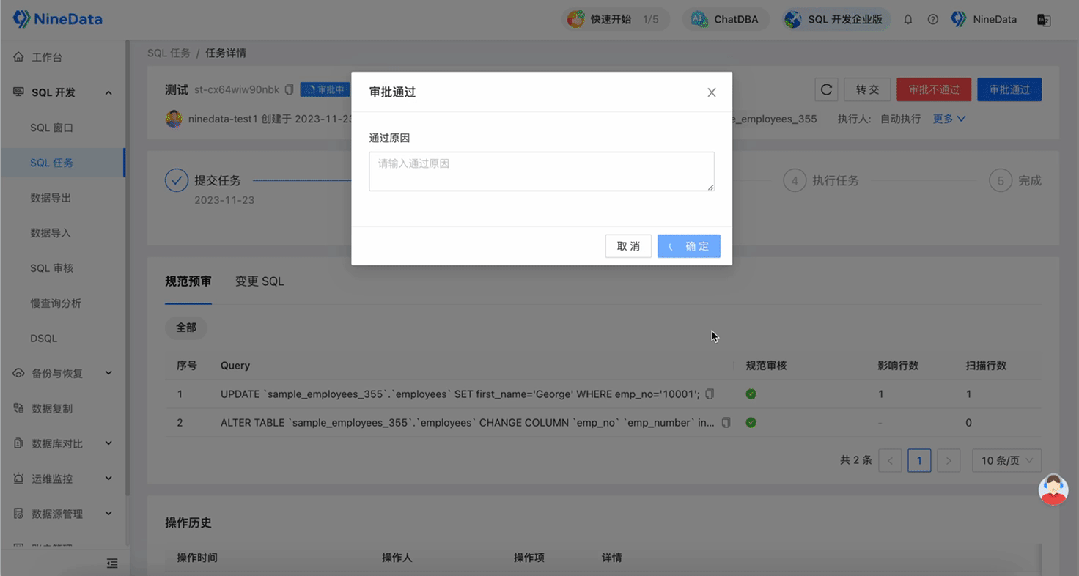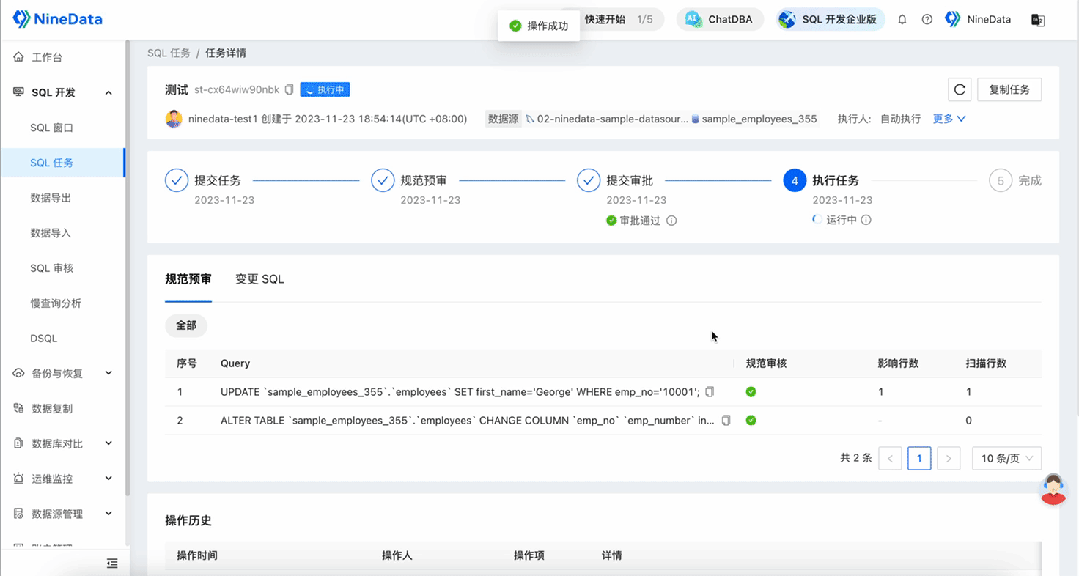
企业级SQL开发:如何审核发布到生产环境的SQL性能
自从上世纪 70 年代数据库开始普及以来,DBA 们就不停地遭遇各种各样的数据库管理难题,其中最为显著的,可能就是日常的开发任务中,研发人员们对于核心库进行变更带来的一系列风险。由于针对数据库的数据变更是一项非常常见的任务&a…...
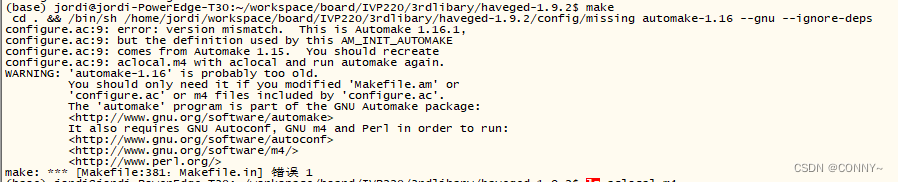
linux 手动安装移植 haveged,解决随机数初始化慢的问题
文章目录 1、问题描述2、安装 haveged3、问题解决4、将安装好的文件跟库移植到开发板下 Haveged是一个软件工具,用于生成高质量的熵(Entropy)源,以供计算机系统使用。熵在计算机科学中指的是一种随机性或不可预测性的度量…...

Linux服务器安全加固第一步:用好chattr隐藏权限和umask默认值
Linux服务器安全加固实战:chattr与umask的防御艺术 当一台裸机Linux服务器首次上线时,大多数管理员会立即部署防火墙、更新补丁和配置SSH密钥登录——这些确实是安全基础。但真正经历过服务器入侵事件的老手都知道,攻击者往往从最不起眼的文件…...

告别卡顿!CXPatcher:让Mac上的Windows游戏性能飙升的终极修复工具
告别卡顿!CXPatcher:让Mac上的Windows游戏性能飙升的终极修复工具 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 你是否曾在Mac上…...

赣州 GEO 科普|AI 时代品牌信息基建,七文 GEO 助力品牌长效可见
赣州GEO科普|AI时代品牌信息基建,读懂生成式引擎优化逻辑人工智能全面普及的当下,生成式AI正在重塑大众的信息获取方式。如今多数用户习惯借助文心一言等AI工具检索品牌、查询行业服务,人工智能会整合全网信息进行智能作答。在此行…...

基于RT-Thread与PSoC 6的智能环境监测系统设计与实现
1. 项目概述:当嵌入式RTOS遇上混合信号MCU最近在捣鼓一个智能环境监测的小玩意儿,核心需求很简单:实时采集环境的温湿度数据,一旦超过预设的阈值,就通过声光或者网络的方式发出警报。听起来像是毕业设计的经典题目&…...

SpringBoot配置加载顺序实战:从踩坑到精通,搞懂spring.profiles.active和spring.config.location
SpringBoot配置加载顺序实战:从踩坑到精通 在SpringBoot项目的开发与部署过程中,配置加载顺序往往是开发者最容易踩坑的环节之一。你是否遇到过本地测试正常,但打包部署后配置突然失效的情况?或者在不同环境间切换时,某…...

深入JPEG文件结构:用Python和十六进制编辑器‘解剖’一张图片,理解tiny_jpeg.h的写入逻辑
逆向工程JPEG:用Python和十六进制工具解析tiny_jpeg.h的编码逻辑 当你用手机拍下一张照片,或是从网上下载一张图片时,这些图像大多以JPEG格式存储。但你是否好奇过,这个看似简单的.jpg文件内部究竟隐藏着怎样的结构?本…...

3个技巧让LaTeX参考文献自动符合GB/T 7714国标:告别手动排版烦恼
3个技巧让LaTeX参考文献自动符合GB/T 7714国标:告别手动排版烦恼 【免费下载链接】gbt7714-bibtex-style BibTeX styles for Chinese National Standard GB/T 7714 项目地址: https://gitcode.com/gh_mirrors/gb/gbt7714-bibtex-style 还在为毕业论文、学术论…...

无感定位技术白皮书——传统ReID跨镜跟踪局限重重,无短板碾压式突破
前言在智慧安防、智慧园区、工业物联网等数字化转型核心场景中,跨摄像头目标追踪与精准定位是支撑场景智能化升级的关键底座。长期以来,ReID(行人重识别)技术因无需额外硬件部署、可依托目标外观特征实现跨镜身份关联,…...

研扬EPIC-RPS9工控主板解析:4英寸板载13代酷睿,赋能边缘AI与机器视觉
1. 项目概述:当“小钢炮”遇上工业严苛环境在工业自动化、边缘计算和嵌入式视觉这些领域里,我们常常面临一个经典矛盾:既要强大的算力来处理海量数据、运行复杂算法,又要设备足够紧凑、坚固,能塞进各种空间受限、环境恶…...
)
Discord Bot自动分发+CSV任务编排+状态回写看板——Midjourney批量工作流工业级落地(仅限内部团队验证过)
更多请点击: https://intelliparadigm.com 第一章:Discord Bot自动分发CSV任务编排状态回写看板——Midjourney批量工作流工业级落地(仅限内部团队验证过) 该方案已在 3 个百人级创意协作团队中稳定运行超 180 天,日均…...