Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection 论文阅读
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection
- 摘要
- 1.介绍
- 2.相关工作
- 异常检测
- Memory networks
- 3. Memory-augmented Autoencoder
- 3.1概述
- 3.2. Encoder and Decoder
- 3.3. Memory Module with Attention-based Sparse Addressing
- 3.3.1 Memory-based Representation
- 3.3.2 Attention for Memory Addressing
- 3.3.3 Hard Shrinkage for Sparse Addressing
- 3.4. Training
- 4.实验
- 4.1. Experiments on Image Data
- 4.2. Experiments on Video Anomaly Detection
- 4.3. Experiments on Cybersecurity Data
- 4.4. Ablation Studies
- 5.总结
- 6.阅读总结
文章信息:

发表于ICCV 2019
原文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Gong_Memorizing_Normality_to_Detect_Anomaly_Memory-Augmented_Deep_Autoencoder_for_Unsupervised_ICCV_2019_paper.pdf
源码链接:https://github.com/donggong1/memae-anomaly-detection
摘要
提出了一种改进的自编码器(Memory-Augmented Autoencoder,MemAE),用于异常检测。传统的深度自编码器在正常数据上训练,期望对于异常输入产生更高的重构误差,以此作为鉴别异常的标准。然而,在实践中,这个假设并不总是成立,有时自编码器的“泛化”效果很好,甚至可以很好地重构异常数据,导致漏检。为了克服这一自编码器异常检测方法的缺陷,文章提出了将自编码器与内存模块相结合的MemAE。
MemAE的基本思想是在训练阶段通过memory来存储和表示正常数据的原型元素,从而引入了对正常数据的更深层次的学习。具体而言,对于给定的输入,MemAE首先通过编码器获取编码,然后将其用作查询以检索用于重构的最相关的memory项。在训练阶段,memory内容会被更新,并被鼓励表示正常数据的原型元素。在测试阶段,学到的memory将保持固定,重构将从少数选择的正常数据的memory记录中获得。因此,重构将倾向于接近正常样本,从而增强了对异常的检测。
MemAE摆脱了对数据类型的假设,因此具有广泛适用性,可应用于不同的任务。实验证明了MemAE在各种数据集上的出色泛化能力和高效性。通过引入内存模块,MemAE在异常检测中取得了更好的性能,克服了传统自编码器在某些情况下过度泛化的问题。
1.介绍
异常检测是一项具有关键应用的重要任务,例如在视频监控领域。在无监督异常检测中,任务是仅根据正常数据示例学习正常模式,然后识别不符合正常模式的样本作为异常。这是一项具有挑战性的任务,因为缺乏人为监督。特别是当数据点位于高维空间(例如视频)时,问题变得更加困难,因为对高维数据建模通常非常具有挑战性。
深度自编码器(AE)是在无监督设置中对高维数据进行建模的强大工具。它包括一个编码器,用于从输入中获取压缩编码,以及一个解码器,可以从编码中重构数据。编码实质上充当了信息瓶颈,迫使网络提取高维数据的典型模式。在异常检测的背景下,AE通常通过最小化正常数据上的重构误差进行训练,然后使用重构误差作为异常的指标。通常假设重构误差对于正常输入会更低,因为它们接近训练数据,而对于异常输入则会更高。然而,这个假设并不总是成立,有时AE的“泛化”效果很好,甚至可以很好地重构异常输入。
为了缓解AE的缺点,文章提出了通过memory模块增强深度自编码器的方法,并引入了一种新模型,即Memory-Augmented Autoencoder(MemAE)。在MemAE中,给定一个输入,不直接将其编码馈送到解码器,而是将其用作查询以检索memory中最相关的项目。这些项目然后被聚合并传递给解码器。具体来说,这个过程通过使用基于注意力的memory寻址实现。作者进一步提出使用可微分的硬收缩运算符来引入memory寻址权重的稀疏性,这隐含地鼓励memory项在特征空间中接近查询。在MemAE的训练阶段,memory内容将与编码器和解码器一起进行更新。由于稀疏寻址策略,MemAE模型被鼓励以最优和高效的方式使用有限数量的内存槽,使memory记录充当正常训练数据中原型正常模式的记录,从而获得低平均重构误差。在测试阶段,学到的memory内容是固定的,重构将使用少数选择的正常内存项进行,这些项被选为输入编码的邻域。由于重构是从memory中的正常模式获得的,因此它倾向于接近正常数据。因此,如果输入与正常数据不相似,即异常,重构误差趋于突出。
提出的MemAE不受数据类型的假设限制,因此可以广泛应用于解决不同任务。在各种来自不同应用领域的公共异常检测数据集上,作者进行了广泛的实验证明了MemAE的出色泛化能力和高效性。
总结:通过memory模块自编码器,同时memory使用稀疏寻址的方式,简单来说就弱化一些特征,只取强的特征。
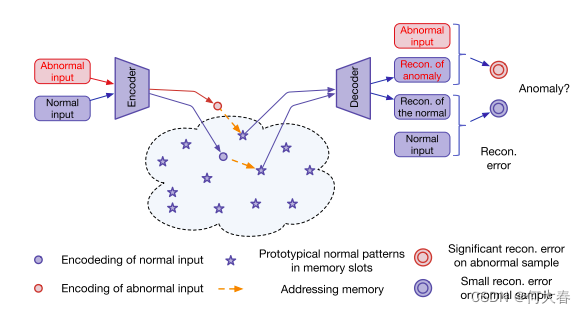
图1:MemAE架构(在训练完之后,memory记录了正常视频的正常模式)
2.相关工作
异常检测
这个不多说了
Memory networks
记忆增强网络已经引起了越来越多的关注,用于解决不同的问题[8, 38, 32]。Graves等人[8]使用外部memory扩展神经网络的能力,其中使用基于内容的注意力来寻址内存。考虑到memory可以稳定地记录信息,Santoro等人[32]使用memory网络来处理一次性学习的问题。外部memory还被用于多模态数据生成[14, 20],以规避模式崩溃问题并保留详细的数据结构。
3. Memory-augmented Autoencoder
3.1概述
提出的MemAE模型由三个主要组件组成 - 编码器(用于对输入进行编码和生成查询),解码器(用于重构)和memory模块(带有内存和相关内存寻址运算符)。如图2所示,给定一个输入,编码器首先获取输入的编码。通过使用编码表示作为查询,memory模块通过基于注意力的寻址运算符检索memory中最相关的项目,然后将它们传递给解码器进行重构。在训练期间,编码器和解码器被优化以最小化重构误差。同时更新memory内容以记录编码正常数据的原型元素。给定一个测试样本,模型仅使用memory中记录的有限数量的正常模式进行重构。因此,重构倾向于接近正常样本,导致正常样本的重构误差较小,而异常样本的误差较大,这将被用作检测异常的标准。
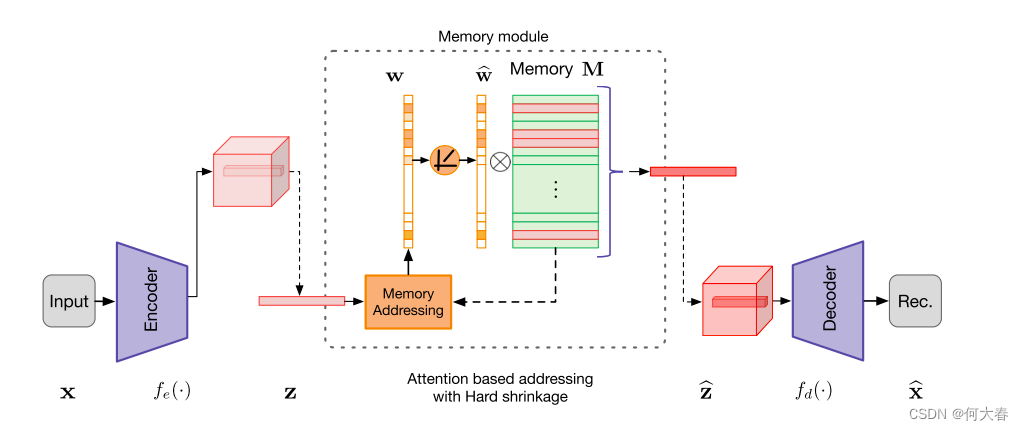
图2:拟建MemAE示意图。存储器寻址单元以编码z作为查询,得到软寻址权值。内存槽可以用于对整个编码或编码的一个像素上的特征进行建模(如图所示)。请注意 w ^ \widehat{w} w 在硬收缩操作之后被归一化。
3.2. Encoder and Decoder
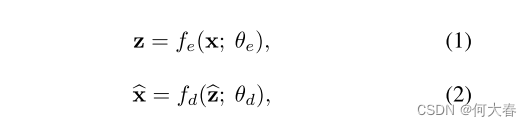
结合图2: f e ( ⋅ ) f_e(·) fe(⋅)表示编码器, f d ( ⋅ ) f_d(·) fd(⋅)表示解码器。x为输入, z ^ \widehat{z} z 为z经过memory处理过后的结果, θ e θ_e θe和 θ d θ_d θd分别为编码器和解码器的参数。
3.3. Memory Module with Attention-based Sparse Addressing
所提出的存储器模块由一个用于记录原型编码模式的存储器和一个用于访问存储器的基于注意力的寻址算子组成。
3.3.1 Memory-based Representation
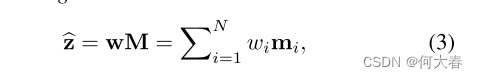
给定一个查询),经过存储器网络得到 z ^ \widehat{z} z
其中w是具有和为1的非负条目的行向量, w i w_i wi表示w的第i个条目。根据z计算权重向量w。如等式(3)所示,访问存储器需要寻址权重w。超参数N定义了存储器的最大容量。作者的实验表明,MemAE对N,也就是memory的存储大小并不是很敏感。
3.3.2 Attention for Memory Addressing
在MemAE中,存储器M被设计为明确记录训练期间的原型正常模式。我们将存储器定义为具有寻址方案的内容可寻址存储器[38,29],该寻址方案基于存储器项和查询z的相似性来计算注意力权重w。如图1所示,我们通过softmax运算来计算每个权重 w i w_i wi:
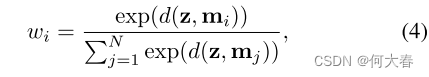
d ( ⋅ , ⋅ ) d(·,·) d(⋅,⋅)是余弦相似度,定义如下:
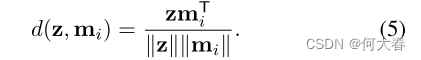
在训练阶段,MemAE中的解码器被限制为仅使用极少数被寻址的存储器项来执行重构,从而满足了对存储器项的有效利用的要求。因此,重建监督迫使存储器记录输入正常模式中最具代表性的原型模式
在测试阶段,给定训练过的存储器,只能检索存储器中的正常模式进行重建。因此,正常样本自然可以很好地重建。相反,异常输入的编码将被检索到的正常模式所取代,从而导致异常的显著重建错误。
3.3.3 Hard Shrinkage for Sparse Addressing
一些异常可能依旧会重构的非常好,对此作者对w采用了稀疏压缩策略,如公式所示:
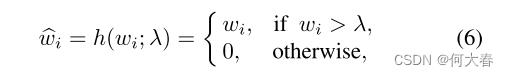
就是将权重向量 w i w_i wi如果小于等于 λ \lambda λ,则置为。排除一些特征。如图,抹去一些相关性低的特征:
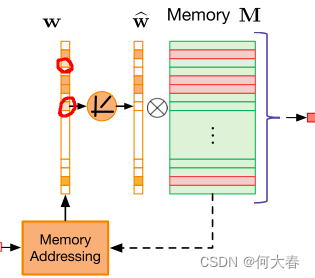
w ^ i \widehat{w}_i w i为压缩后的权重向量。
考虑到w都是非负的,使用RULE函数更简单,公式变成下面的了:
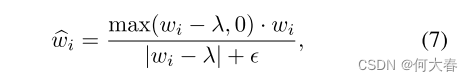
这种寻址方式只需要前向传播就可以更新了,而不需要反向传播。
3.4. Training
损失函数有两部分组成
重构误差
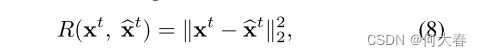
最小化 w ^ i \widehat{w}_i w i的熵
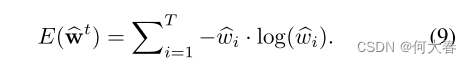
目的是:通过调整或优化 w ^ i \widehat{w}_i w i的值,使得相关的概率分布变得更加确定或不那么随机。
4.实验
作者做了三个实验,一个是在图像上异常检测,一个是在视频上的异常检测、还有一个实在网络安全方面的异常检测,这个不太了解。
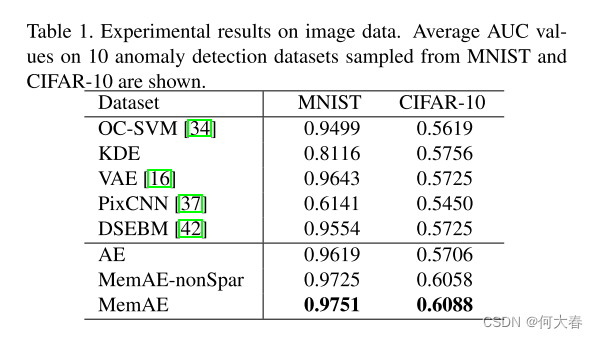
4.1. Experiments on Image Data
分别在MNIST和CIFAR-10两个数据集上进行了测试。具体实验设置参考原论文,效果如下:
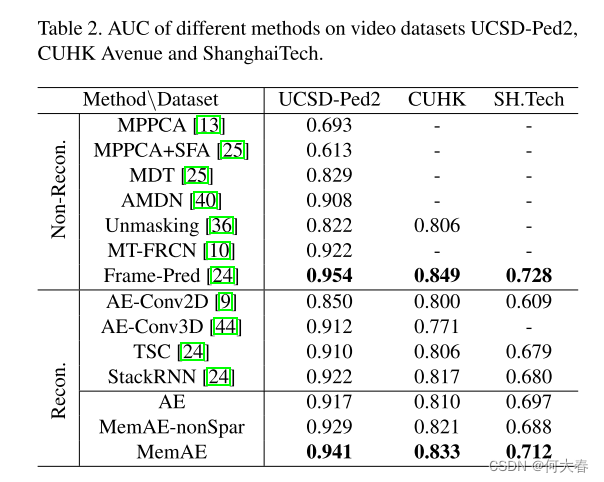
4.2. Experiments on Video Anomaly Detection
分别在Ped2、CUHK、SH.Tech三个数据集上进行了测试。效果如下
4.3. Experiments on Cybersecurity Data
略
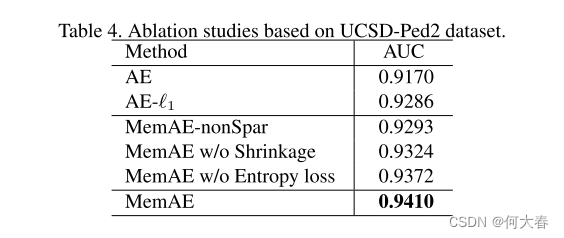
4.4. Ablation Studies
作者对自己提出的模块进行了消融实验,分别对memory和稀疏压缩、熵loss进行了控制变量,结果如下:
5.总结
- 提出了一个memory moudle模块
- 提出了一个稀疏性压缩
- 使用了熵减loss
6.阅读总结
这篇和前面的两篇思想都是有很大相似性的:引入memory moudle模块,在memory moudle所在的位置和更新策略上有不同的点,损失函数也有一些变化。
2020 cvpr Learning Memory-guided Normality for Anomaly Detection 论文阅读
2021 cvpr Learning Normal Dynamics in Videos with Meta Prototype Network 论文阅读
相关文章:
Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection 论文阅读
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection 摘要1.介绍2.相关工作异常检测Memory networks 3. Memory-augmented Autoencoder3.1概述3.2. Encoder and Decoder3.3. Memory Module with Attention-based S…...
Mac端 DevEco Preview 窗口无法展示,提示文件中的node.dir错误
语雀知识库地址:语雀HarmonyOS知识库 飞书知识库地址:飞书HarmonyOS知识库 DevEco版本:Build Version: 3.1.0.501, built on June 20, 2023 环境信息 问题描述 打开 Preview 标签窗口后,提示Preview failed。 Run窗口提示如下 F…...
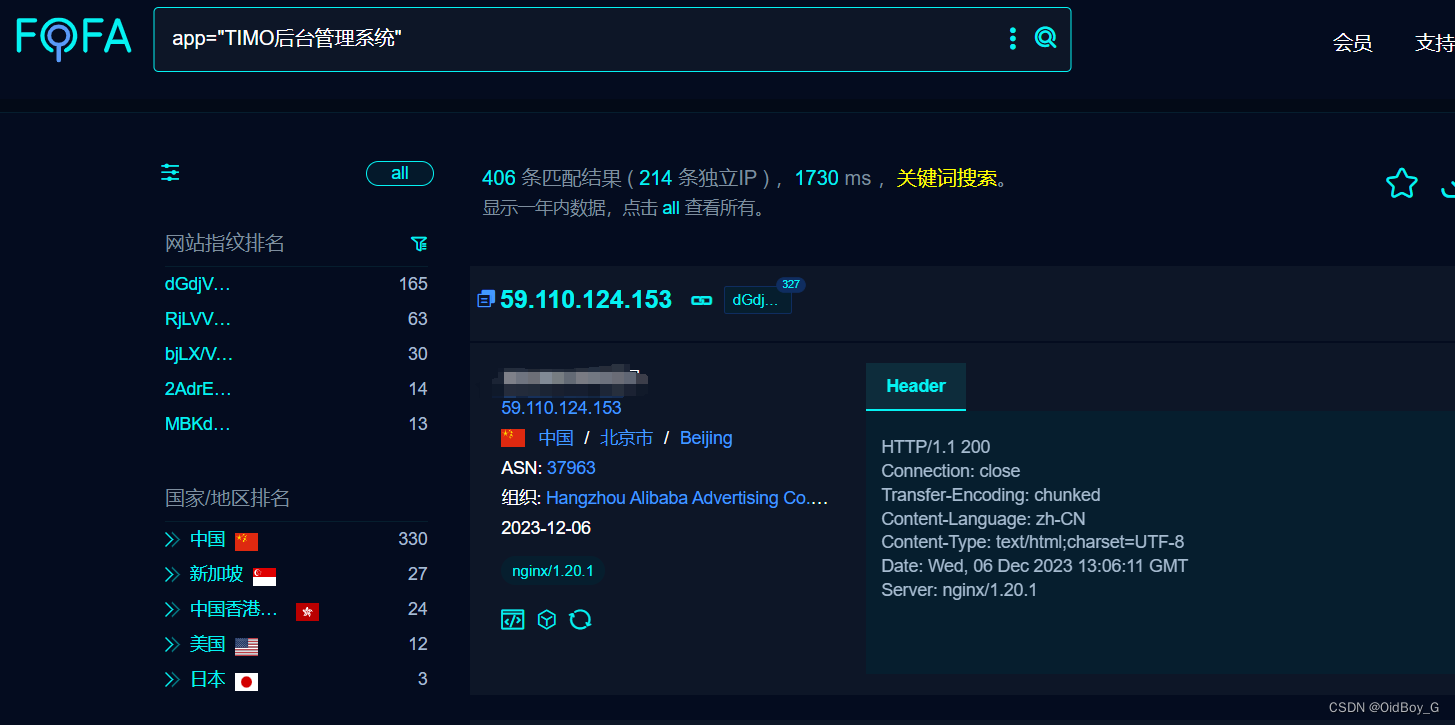
TIMO后台管理系统 Shiro 反序列化漏洞复现
0x01 产品简介 TIMO 后台管理系统,基于SpringBoot2.0 + Spring Data Jpa + Thymeleaf + Shiro 开发的后台管理系统,采用分模块的方式便于开发和维护,支持前后台模块分别部署,目前支持的功能有:权限管理、部门管理、字典管理、日志记录、文件上传、代码生成等,为快速开发后…...

3.4_1 java自制小工具 - pdf批量转图片
相关链接 目录参考文章:pdf转图片(apache pdfbox)参考文章:GUI界面-awt参考文章:jar包转exe(exe4j)参考文章:IDEA导入GIT项目参考文章:IDEA中使用Gitee管理代码gitee项目链接:pdf_2_image网盘地址…...

vue中实现数字+英文字母组合键盘
完整代码 <template><div class"login"><div click"setFileClick">欢迎使用员工自助终端</div><el-dialog title"初始化设置文件打印消耗品配置密码" :visible.sync"dialogSetFile" width"600px&quo…...
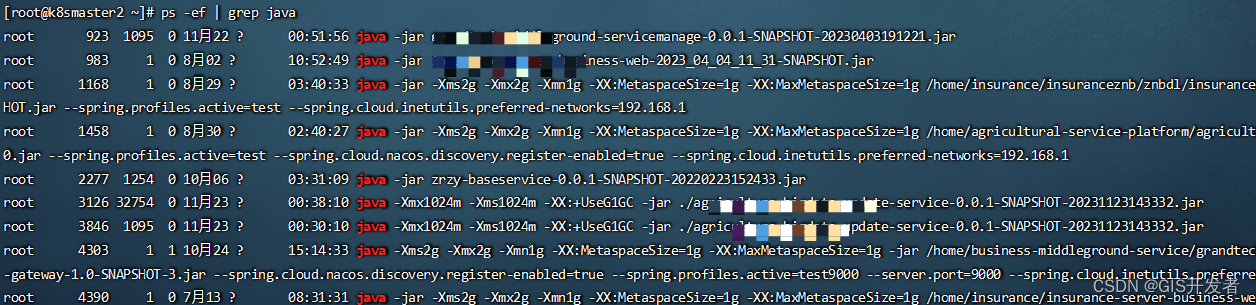
Centos服务器上根据端口号查询jar包,根据jar包查端口号
在开发springboot服务器时,经常会遇到其他人部署的java服务,需要自己维护,留下的信息又非常少。经常面临找不到jar包位置,或者不知道占用端口,不知道启动命令的问题。这里记录一下常用的centos服务器上的命令ÿ…...

数据仓库与数据挖掘复习资料
一、题型与考点[第一种] 1、解释基本概念(中英互译解释简单的含义); 2、简答题(每个10分有两个一定要记住): ① 考时间序列Time series(第六章)的基本概念含义解释作用(序列模式挖掘的作用); ② 考聚类(第五章)重点考…...

限流算法,基于go的gRPC 实现的
目录 一、单机限流 1、令牌桶算法 3、固定窗口限流算法 4、滑动窗口 二、集群限流 1、分布式固定窗口 (基于redis) 2、分布式滑动窗口 一、单机限流 1、令牌桶算法 令牌桶算法是当流量进入系统前需要获取令牌,没有令牌那么就要进行限…...

Shell中HTTP变量和文本处理
在Shell中,HTTP变量和文本处理是常见的任务之一。Shell是一个命令行解释器,可以用来自动化执行各种系统任务。在Shell中,我们可以使用各种命令和工具来处理HTTP变量和文本。 首先,让我们来看看如何在Shell中处理HTTP变量。HTTP变…...

java学习part39map
159-集合框架-Map不同实现类的对比与HashMap中元素的特点_哔哩哔哩_bilibili 1.Map 2.Entry 个人理解是c的pair,代表一个键值对。Map就是entry的叠加 3.常用方法 4.TreeMap 5.Properties...

使用sqoop操作HDFS与MySQL之间的数据互传
一,数据从HDFS中导出至MySQL中 1)开启Hadoop、mysql进程 start-all.sh/etc/init.d/mysqld start/etc/init.d/mysqld status 2)将学生数据stu_data.csv传到HDFS的/local_student目录下 在hdfs中创建目录 hdfs dfs -mkdir /local_student 上…...

Kafka使用指南
Kafka简介架构设计Kafka的架构设计关键概念Kafka的架构设计关键机制 Partition介绍Partition工作机制 应用场景ACK机制介绍ACK机制原理ACK机制对性能的影响ACK控制粒度Kafka分区数对集群性能影响调整分区优化集群性能拓展Kafka数据全局有序 Kafka简介 Kafka是由Apache软件基金…...
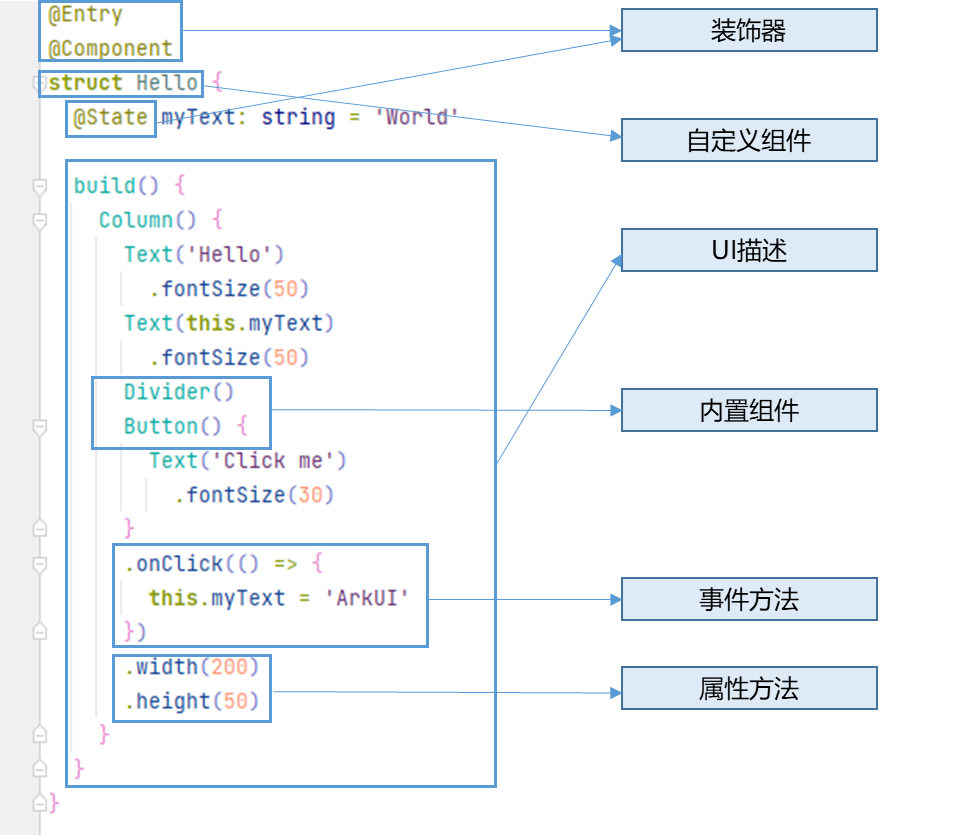
HarmonyOS4.0从零开始的开发教程03初识ArkTS开发语言(中)
HarmonyOS(二)初识ArkTS开发语言(中)之TypeScript入门 浅析ArkTS的起源和演进 1 引言 Mozilla创造了JS,Microsoft创建了TS,Huawei进一步推出了ArkTS。 从最初的基础的逻辑交互能力,到具备类…...

西工大计算机学院计算机系统基础实验一(函数编写1~10)
还是那句话,千万不要慌,千万不要着急,耐下性子慢慢来,一步一个脚印,把基础打的牢牢的,一样不比那些人差。回到实验本身,自从按照西工大计算机学院计算机系统基础实验一(…...

VMware 虚拟机 电脑重启后 NAT 模式连不上网络问题修复
问题描述: 昨天 VMware 安装centos7虚拟机,网络模式配置的是NAT模式,配置好后,当时能连上外网,今天电脑重启后,发现连不上外网了 检查下各个配置,都没变动,突然就连不上了 网上查了…...
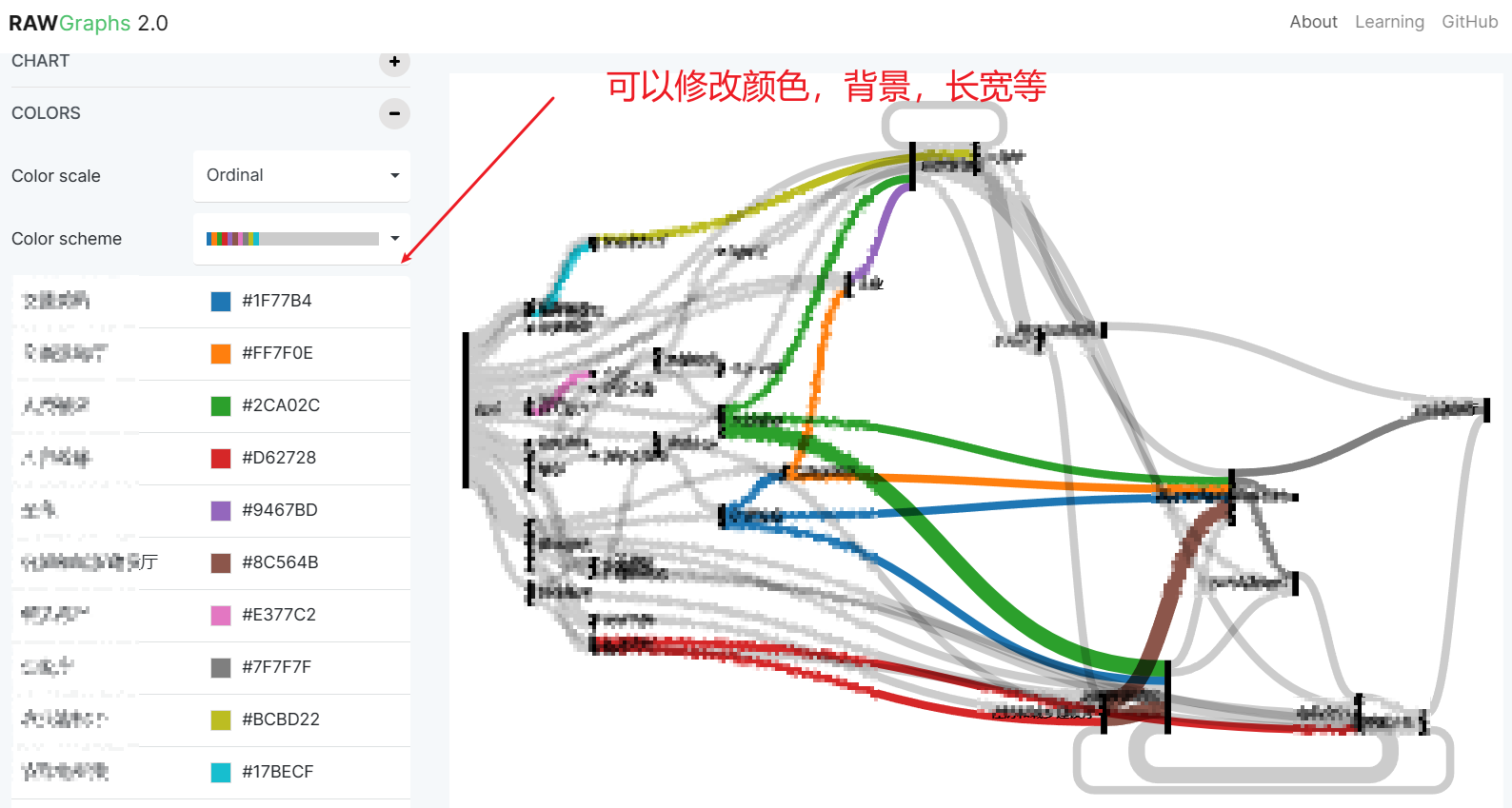
【桑基图】绘制桑基图
绘制桑基图 一、绘制桑基图(1)方法一:去在线网站直接绘制(2)方法二:写html之后在vscode上运行 二、遇到的问题(1)当导入一些excel的时候,无法绘制出桑基图 一、绘制桑基图…...
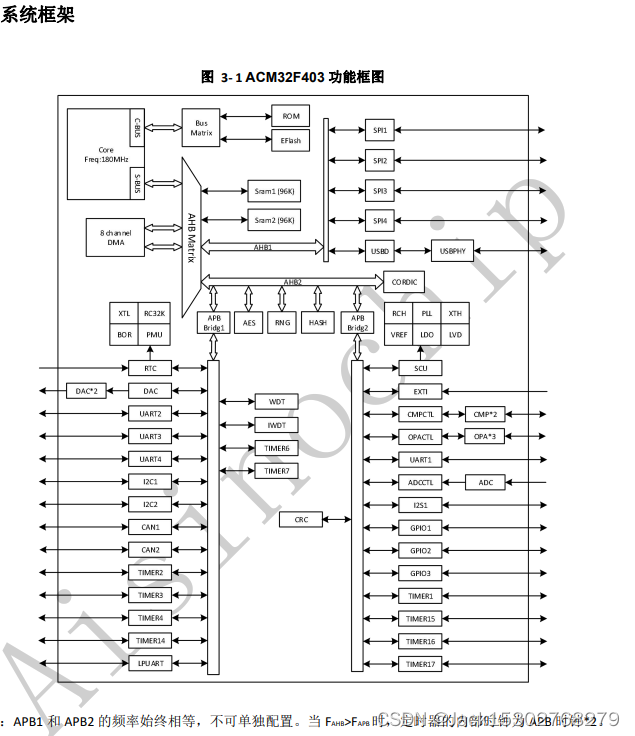
ACM32F403/F433 12 位多通道,支持 MPU 存储保护功能,应用于工业控制,智能家居等产品中
ACM32F403/F433 芯片的内核基于 ARMv8-M 架构,支持 Cortex-M33 和 Cortex-M4F 指令集。芯片内核 支持一整套DSP指令用于数字信号处理,支持单精度FPU处理浮点数据,同时还支持Memory Protection Unit (MPU)用于提升应用的…...
7. 从零用Rust编写正反向代理, HTTP及TCP内网穿透原理及运行篇
wmproxy wmproxy是由Rust编写,已实现http/https代理,socks5代理, 反向代理,静态文件服务器,内网穿透,配置热更新等, 后续将实现websocket代理等,同时会将实现过程分享出来ÿ…...
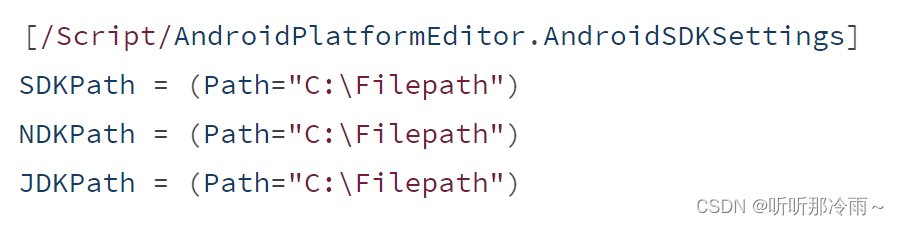
UE4.27-UE5.1设置打包Android环境
打包Android配置文件 1. 配置打包Android的SDK需求文件位于下面文件中: 2. 指定了对应的SDK环境变量名字以及NDK需求等: UE4.27-UE5.1--脚本自动配置 安装前提 1. 务必关闭虚幻编辑器和Epic Games Launcher,以确保NDK组件的安装或引擎环境…...

MySQL授权密码
mysql> crate databases school charcter set utf8; Query OK, 1 row affected, 1 warning (0.00 sec) 2.在school数据库中创建Student和Score表 mysql> use school Database changed mysql> create table student-> -> (id int(10) primary key auto_incremen…...

基于LLM与视觉模型融合的智能体框架:从原理到工业质检实践
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的落地场景时,我深度体验了landing-ai/vision-agent这个项目。它不是一个简单的图像识别工具,而是一个试图让AI具备“视觉推理”能力的智能体框架。简单来说,它让AI不仅…...
)
Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包)
更多请点击: https://intelliparadigm.com 第一章:Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包) Tea印相(TeaYinXiang)在 v…...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...

VR头显立体视觉姿态估计技术解析
1. 自我中心姿态估计的技术挑战与创新思路在虚拟现实和增强现实应用中,准确估计用户在三维空间中的身体姿态是实现自然交互的基础。传统基于外部摄像头的动作捕捉系统虽然精度较高,但存在设备复杂、使用场景受限等问题。相比之下,基于头戴设备…...
:精准匹配V6.6新渲染引擎底层纹理采样逻辑)
【仅剩47份】Midjourney湿版摄影风格训练数据包(含1851–1889年原始湿版扫描图谱×236张+ICC色彩配置文件×5):精准匹配V6.6新渲染引擎底层纹理采样逻辑
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格的历史溯源与数字再生价值 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由英国科学家弗雷德里克斯科特阿彻(Frederick Scott Archer…...

OneQuery:统一异构数据源查询的抽象层设计与实战
1. 项目概述:一个查询,无限可能最近在折腾一个数据聚合项目,需要从多个异构数据源里捞数据,然后统一处理。这活儿听起来简单,但真干起来,每个数据源都有自己的查询语法、连接方式和返回格式,光是…...

Hermes Agent 工具如何配置接入 Taotoken 提供的模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 工具如何配置接入 Taotoken 提供的模型服务 Hermes Agent 是一个流行的开源智能体框架,它允许开发者通过…...

【开源实践】从零构建Voronoi泡沫结构:多胞材料建模的简易路径
1. Voronoi泡沫结构:从自然现象到工程应用 第一次看到Voronoi结构是在一块龟甲上——那些不规则的六边形图案让我着迷。后来才知道,这种被称为"泰森多边形"的几何结构不仅存在于生物组织中,从蜂巢到干燥的泥地,从植物细…...

AURIX Tricore TC397开发实战:基于UDE的仿真调试与问题排查指南
1. 环境准备与工具安装 第一次接触AURIX Tricore TC397的开发板时,我完全被它强大的多核架构吸引住了。这款芯片在汽车电子领域应用广泛,但调试过程确实让不少新手头疼。经过几个项目的实战,我总结出一套基于UDE的调试方法,能帮你…...