毕设:《基于hive的音乐数据分析系统的设计与实现》
文章目录
- 环境启动
- 一、爬取数据
- 1.1、歌单信息
- 1.2、每首歌前20条评论
- 1.3、排行榜
- 二、搭建环境
- 1.1、搭建JAVA
- 1.2、配置hadoop
- 1.3、配置Hadoop环境:YARN
- 1.4、MYSQL
- 1.5、HIVE(数据仓库)
- 1.6、Sqoop(关系数据库数据迁移)
- 三、hadoop配置内存
- 四、导入数据到hive
环境启动
启动hadoop图形化界面
cd /opt/server/hadoop-3.1.0/sbin/./start-dfs.sh
./start-yarn.sh# 或者
./start-all.sh
启动hive
hive
一、爬取数据
1.1、歌单信息
CREATE TABLE playlist (PlaylistID INT AUTO_INCREMENT PRIMARY KEY,Type VARCHAR(255),Title VARCHAR(255),PlayCount VARCHAR(255),Contributor VARCHAR(255)
);
# _*_ coding : utf-8 _*_
# @Time : 2023/11/15 10:26
# @Author : Laptoy
# @File : 01_playlist
# @Project : finalDesign
import requests
import time
from bs4 import BeautifulSoup
import pymysqldb_connection = pymysql.connect(host="localhost",user="root",password="root",database="music"
)
cursor = db_connection.cursor()headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}types = ['华语', '欧美', '日语', '韩语', '粤语']for type in types:# 按类型获取歌单for i in range(0, 1295, 35):url = 'https://music.163.com/discover/playlist/?cat=' + type + '&order=hot&limit=35&offset=' + str(i)response = requests.get(url=url, headers=headers)html = response.textsoup = BeautifulSoup(html, 'html.parser')# 获取包含歌单详情页网址的标签ids = soup.select('.dec a')# 获取包含歌单索引页信息的标签lis = soup.select('#m-pl-container li')print(len(lis))print('类型', '标题', '播放量', '歌单贡献者', '歌单链接')for j in range(len(lis)):# 标准歌单类型type = type# 获取歌单标题,替换英文分割符title = ids[j]['title'].replace(',', ',')# 获取歌单播放量playCount = lis[j].select('.nb')[0].get_text()# 获取歌单贡献者名字contributor = lis[j].select('p')[1].select('a')[0].get_text()# 输出歌单索引页信息print(type, title, playCount, contributor)insert_query = "INSERT INTO playlist (Type, Title, PlayCount, Contributor) VALUES (%s, %s, %s, %s)"playlist_data = (type, title, playCount, contributor)cursor.execute(insert_query, playlist_data)db_connection.commit()time.sleep(0.1)
cursor.close()
db_connection.close()
1.2、每首歌前20条评论
CREATE TABLE `comment` (`song_id` varchar(20),`song_name` varchar(255),`comment` varchar(255),`nickname` varchar(50)
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci ROW_FORMAT = Dynamic;
# _*_ coding : utf-8 _*_
# @Time : 2023/11/15 15:09
# @Author : Laptoy
# @File : ces
# @Project : finalDesign
import requests
from Crypto.Cipher import AES
from lxml import etree
from binascii import b2a_base64
import json
import time
import pymysql
from pymysql.converters import escape_stringheaders = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
e = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'g = '0CoJUm6Qyw8W8jud'
# 随机值
i = 'vDIsXMJJZqADRVBP'def get_163():# 热歌榜URLtoplist_url = 'https://music.163.com/discover/toplist?id=3778678'response = requests.get(toplist_url, headers=headers)html = response.content.decode()html = etree.HTML(html)namelist = html.xpath("//div[@id='song-list-pre-cache']/ul[@class='f-hide']/li")# 可选择保存到文件# f = open('./wangyi_hotcomments.txt',mode='a',encoding='utf-8')for name in namelist:song_name = name.xpath('./a/text()')[0]song_id = name.xpath('./a/@href')[0].split('=')[1]content = get_hotConmments(song_id)print(song_name, song_id)save_mysql(song_id, song_name, content)# f.writelines(song_id+song_name)# f.write('\n')# f.write(str(content))# f.close()def get_encSecKey():encSecKey = "516070c7404b42f34c24ef20b659add657c39e9c52125e9e9f7f5441b4381833a407e5ed302cac5d24beea1c1629b17ccb86e0d9d57f6508db5fb7a6df660089ac57b093d19421d386101676a1c8d1e312e099a3463f81fbe91f28211f9eccccfbfc64148fdd65e2b9f5fcf439a865b95fb656e36f75091957f0a1d39ca8ddd3"return encSecKeydef get_params(data):first = enconda_params(data, g)second = enconda_params(first, i)return second# 加密params
def enconda_params(data, key):d = 16 - len(data) % 16data += chr(d) * ddata = data.encode('utf-8')aes = AES.new(key=key.encode('utf-8'), IV='0102030405060708'.encode('utf-8'), mode=AES.MODE_CBC)bs = aes.encrypt(data)# b64解码params = b2a_base64(bs).decode('utf-8')# params = b64decode(bs)return paramsdef get_hotConmments(id):# print(id)# 提交的信息data = {'cursor': '-1','offset': '0','orderType': '1','pageNo': '1','pageSize': '20','rid': f'R_SO_4_{id}','threadId': f'R_SO_4_{id}'}post_data = {'params': get_params(json.dumps(data)),'encSecKey': get_encSecKey()}# 获取评论的URLsong_url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=ce10dc34c626dc6aef3e07c86be16d70'response = requests.post(url=song_url, data=post_data, headers=headers)# time.sleep(1)json_dict = json.loads(response.content)# print(json_dict)hotcontent = {}for content in json_dict['data']['hotComments']:content_text = content['content']content_id = content['user']['nickname']hotcontent[content_id] = content_textreturn hotcontent# 保存到MySQL数据库
def save_mysql(song_id, song_name, content):connect = pymysql.Connect(host='localhost',port=3306,user='root',passwd='root',db='music',# charset='utf8mb4')cursor = connect.cursor()# sql = "inster into music_163 velues(%d,'%s','%s','%s')"sql = """INSERT INTO comment(song_id, song_name, comment,nickname)VALUES(%d, '%s', '%s', '%s')"""for nikename in content:data = (int(song_id), escape_string(song_name), escape_string(content[nikename]), escape_string(nikename))print(data)cursor.execute(sql % data)connect.commit()if __name__ == '__main__':get_163()
1.3、排行榜
CREATE TABLE `chart` (`Chart` varchar(255),`Rank` varchar(255),`Title` varchar(255),`Times` varchar(255),`Singer` varchar(255)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
# _*_ coding : utf-8 _*_
# @Time : 2023/11/15 14:20
# @Author : Laptoy
# @File : 02_musicChart
# @Project : finalDesign
from selenium import webdriver
from selenium.webdriver.common.by import By
import pymysql
import timedb_connection = pymysql.connect(host="localhost",user="root",password="root",database="music"
)
cursor = db_connection.cursor()driver = webdriver.Chrome()
ids = ['19723756', '3779629', '2884035', '3778678']
charts = ['飙升榜', '新歌榜', '原创榜', '热歌榜']for id, chart in zip(ids, charts):driver.get('https://music.163.com/#/discover/toplist?id=' + id)driver.switch_to.frame('contentFrame')time.sleep(1)divs = driver.find_elements(By.XPATH, '//*[@class="g-wrap12"]//tr[contains(@id,"1")]')for div in divs:# 榜单类型chart = chart# 标题title = div.find_element(By.XPATH, './/div[@class="ttc"]//b').get_attribute('title')# 排名rank = div.find_element(By.XPATH, './/span[@class="num"]').text# 时长times = div.find_element(By.XPATH, './/span[@class="u-dur "]').text# 歌手singer = div.find_element(By.XPATH, './td/div[@class="text"]/span').get_attribute('title')print(chart, title, rank, times, singer)insert_query = "INSERT INTO chart(chart, title, rank, times,singer) VALUES (%s, %s, %s, %s, %s)"chart_data = (chart, title, rank, times, singer)cursor.execute(insert_query, chart_data)db_connection.commit()time.sleep(1)
cursor.close()
db_connection.close()
二、搭建环境
1.1、搭建JAVA
mkdir /opt/tools
mkdir /opt/servertar -zvxf jdk-8u131-linux-x64.tar.gz -C /opt/server
vim /etc/profile# 文件末尾增加
export JAVA_HOME=/opt/server/jdk1.8.0_131
export PATH=${JAVA_HOME}/bin:$PATHsource /etc/profilejava -version
1、配置免密登录
vim /etc/hosts
# 文件末尾增加
192.168.88.110 [主机名]
ssh-keygen -t rsacd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
1.2、配置hadoop
tar -zvxf hadoop-3.1.0.tar.gz -C /opt/server/
# 进入/opt/server/hadoop-3.1.0/etc/hadoop
vim hadoop-env.sh
# 文件添加
export JAVA_HOME=/opt/server/jdk1.8.0_131
vim core-site.xml
<configuration><property><!--指定 namenode 的 hdfs 协议文件系统的通信地址--><name>fs.defaultFS</name><value>hdfs://[主机名]:8020</value></property><property><!--指定 hadoop 数据文件存储目录--><name>hadoop.tmp.dir</name><value>/home/hadoop/data</value></property>
</configuration>
hdfs-site.xml
<configuration><property><!--由于我们这里搭建是单机版本,所以指定 dfs 的副本系数为 1--><name>dfs.replication</name><value>1</value></property>
</configuration>
vim workers
# 配置所有从属节点的主机名或 IP 地址,由于是单机版本,所以指定本机即可:
server
1、关闭防火墙
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld
# 禁止开机启动
sudo systemctl disable firewalld
2、初始化
cd /opt/server/hadoop-3.1.0/bin
./hdfs namenode -format
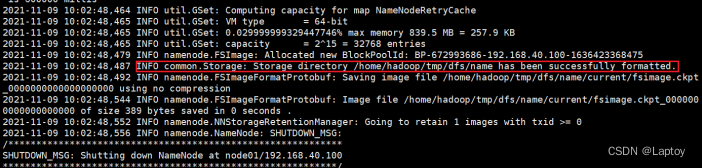
3、配置启动用户
cd /opt/server/hadoop-3.1.0/sbin/
# 编辑start-dfs.sh、stop-dfs.sh,在顶部加入以下内容
# 编辑start-all.sh、stop-all.sh,在顶部加入以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
4、启动
cd /opt/server/hadoop-3.1.0/sbin/
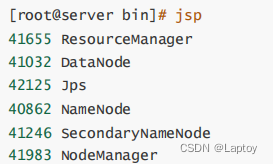
./start-dfs.shjps
5、访问
192.168.88.110:9870
6、配置环境变量方便启动
vim /etc/profile
export HADOOP_HOME=/opt/server/hadoop-3.1.0
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
source /etc/profile
1.3、配置Hadoop环境:YARN
# 进入/opt/server/hadoop-3.1.0/etc/hadoop
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
vim yarn-site.xml
<configuration><property><!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在Yarn 上运行 MapRedvimuce 程序。--><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
cd /opt/server/hadoop-3.1.0/sbin/
# start-yarn.sh stop-yarn.sh在两个文件顶部添加以下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
./start-yarn.sh

1.4、MYSQL
# 用于存放安装包
mkdir /opt/tools
# 用于存放解压后的文件
mkdir /opt/server
卸载Centos7自带mariadb
# 查找
rpm -qa|grep mariadb
# mariadb-libs-5.5.52-1.el7.x86_64
# 卸载
rpm -e mariadb-libs-5.5.52-1.el7.x86_64 --nodeps
# 创建mysql安装包存放点
mkdir /opt/server/mysql
# 解压
tar xvf mysql-5.7.34-1.el7.x86_64.rpm-bundle.tar -C /opt/server/mysql/
# 安装依赖
yum -y install libaio
yum -y install libncurses*
yum -y install perl perl-devel
# 切换到安装目录
cd /opt/server/mysql/
# 安装
rpm -ivh mysql-community-common-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.34-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.34-1.el7.x86_64.rpm
#启动mysql
systemctl start mysqld.service
#查看生成的临时root密码
cat /var/log/mysqld.log | grep password

# 登录mysql
mysql -u root -p
Enter password: #输入在日志中生成的临时密码
# 更新root密码 设置为root
set global validate_password_policy=0;
set global validate_password_length=1;
set password=password('root');
grant all privileges on *.* to 'root' @'%' identified by 'root';
# 刷新
flush privileges;
#mysql的启动和关闭 状态查看
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
#建议设置为开机自启动服务
systemctl enable mysqld
#查看是否已经设置自启动成功
systemctl list-unit-files | grep mysqld
1.5、HIVE(数据仓库)
# 切换到安装包目录
cd /opt/tools
# 解压到/root/server目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/server/
# 上传mysql-connector-java-5.1.38.jar到下面目录
cd /opt/server/apache-hive-3.1.2-bin/lib
配置文件
cd /opt/server/apache-hive-3.1.2-bin/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
# 加入以下内容
HADOOP_HOME=/opt/server/hadoop-3.1.0
cd /opt/server/apache-hive-3.1.2-bin/conf
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 存储元数据mysql相关配置 /etc/hosts --><property><name>javax.jdo.option.ConnectionURL</name><value> jdbc:mysql://[主机名]:3306/hive?
createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&chara
cterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property>
</configuration>
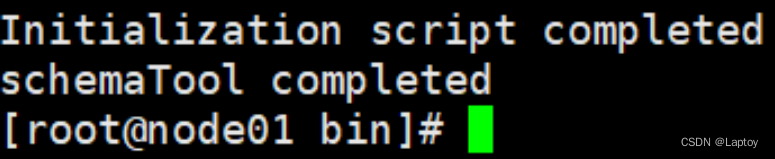
初始化表
cd /opt/server/apache-hive-3.1.2-bin/bin
./schematool -dbType mysql -initSchema
1.6、Sqoop(关系数据库数据迁移)
1、拉取sqoop
# /opt/tools
wget https://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gztar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/server/
2、配置
cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/conf
cp sqoop-env-template.sh sqoop-env.shvim sqoop-env.sh
# 加入以下内容
export HADOOP_COMMON_HOME=/opt/server/hadoop-3.1.0
export HADOOP_MAPRED_HOME=/opt/server/hadoop-3.1.0
export HIVE_HOME=/opt/server/apache-hive-3.1.2-bin
3、加入mysql的jdbc驱动包
cd /opt/server/sqoop-1.4.7.bin__hadoop-2.6.0/lib
# mysql-connector-java-5.1.38.jar
三、hadoop配置内存
修改yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value></property>
</configuration>
重启
cd /opt/server/hadoop-3.1.0/sbin
./stop-all.sh
./start-all.sh
四、导入数据到hive
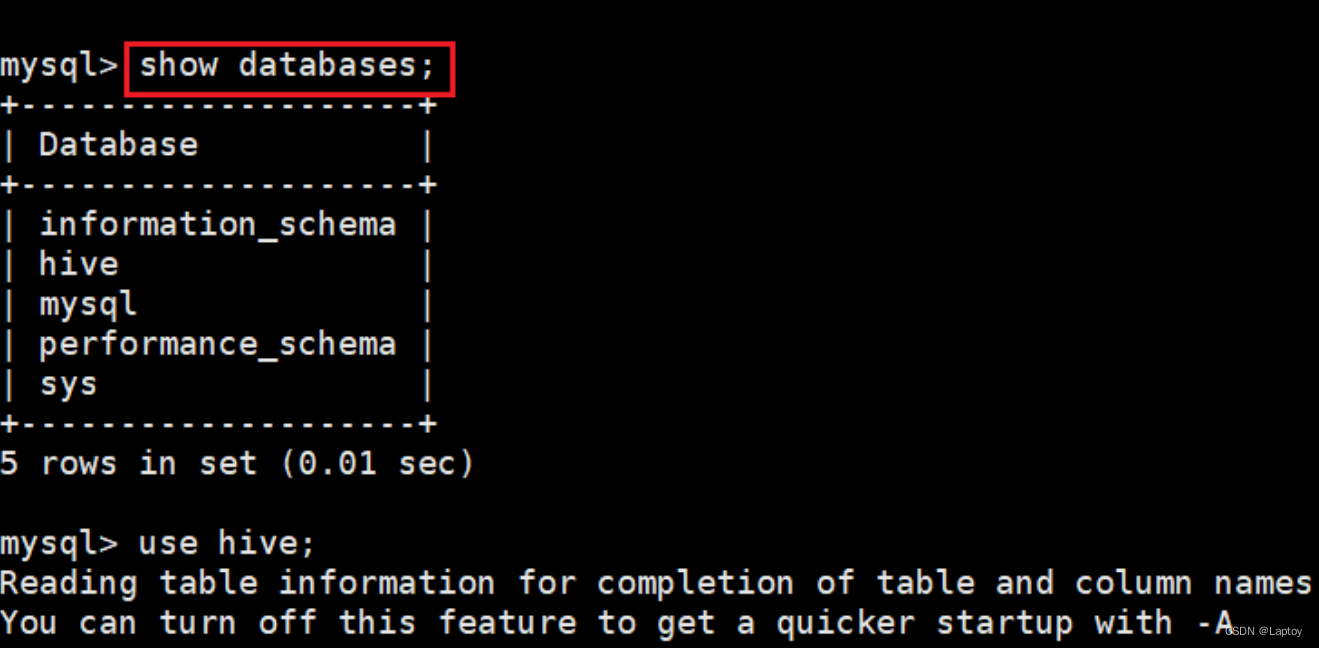
1、hive创建数据库
create database music;
use music;
2、hive创建数据表
# -- 将数据当做一列放入表中,后续再使用sql进行分割处理
CREATE TABLE chart_content(content STRING
);
CREATE TABLE playlist_content (content STRING
);
3、hive加载csv文件进hive表
load data local inpath '/opt/data/chart.csv' into table chart_content;
load data local inpath '/opt/data/playlist.csv' into table playlist;
4、创建表
CREATE TABLE `chart` (`Chart` string,`Rank` string,`Title` string,`Times` string,`Singer` string
);CREATE TABLE `playlist` (`PlaylistID` string,`Type` string,`Title` string,`PlayCount` string,`Contributor` string
);CREATE TABLE playlist (`PlaylistID` string,`Type` string,`Title` string,`PlayCount` string,`Contributor` string
)
row format delimited
fields terminated by ',';
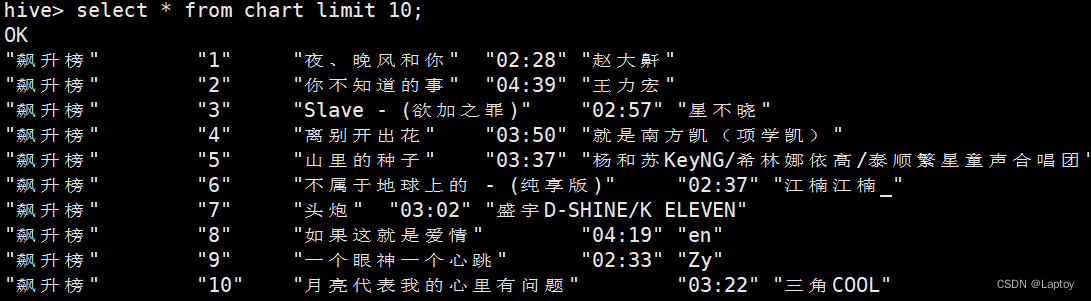
5、将数据插入表中去掉","
INSERT INTO TABLE `chart`
SELECTsplit(content, ',')[0] AS `Chart`,split(content, ',')[1] AS `Rank`,split(content, ',')[2] AS `Title`,split(content, ',')[3] AS `Times`,split(content, ',')[4] AS `Singer`
FROM `chart_content`;INSERT INTO TABLE `playlist`
SELECTsplit(content, ',')[0] AS `PlaylistID`,split(content, ',')[1] AS `Type`,split(content, ',')[2] AS `Title`,split(content, ',')[3] AS `PlayCount`,split(content, ',')[4] AS `Contributor`
FROM `playlist_content`;

SELECTPlaylistID,Type,Title,CAST(PlayCount AS int) AS PlayCount,Contributor
FROM playlist;
SELECTREGEXP_REPLACE(Contributor, '"', '')
FROM playlist;
相关文章:
毕设:《基于hive的音乐数据分析系统的设计与实现》
文章目录 环境启动一、爬取数据1.1、歌单信息1.2、每首歌前20条评论1.3、排行榜 二、搭建环境1.1、搭建JAVA1.2、配置hadoop1.3、配置Hadoop环境:YARN1.4、MYSQL1.5、HIVE(数据仓库)1.6、Sqoop(关系数据库数据迁移) 三、hadoop配置内存四、导…...

PHP使用HTTP代码示例模板
PHP是一种广泛用于服务器端的编程语言,它提供了许多内置的函数和扩展,以便开发人员能够轻松地处理HTTP请求和响应。在PHP中,您可以使用以下代码示例模板来处理HTTP请求和生成HTTP响应。 php复制代码 <?php // 处理GET请求 if ($…...
头歌题目-数组
任务描述 题目描述:找出具有m行n列二维数组Array的“鞍点”,即该位置上的元素在该行上最大,在该列上最小,其中1<m,n<10。 相关知识(略) 编程要求 输入 输入数据有多行,第一行有两个数m和n&#…...

C++ vector基本操作
目录 一、介绍 二、定义 三、迭代器 四、容量操作 1、size 2、capacity 3、empty 4、resize 5、reserve 总结(扩容机制) 五、增删查改 1、push_back & pop_back 2、find 3、insert 4、erase 5、swap 6、operator[] 一、介绍 vector…...
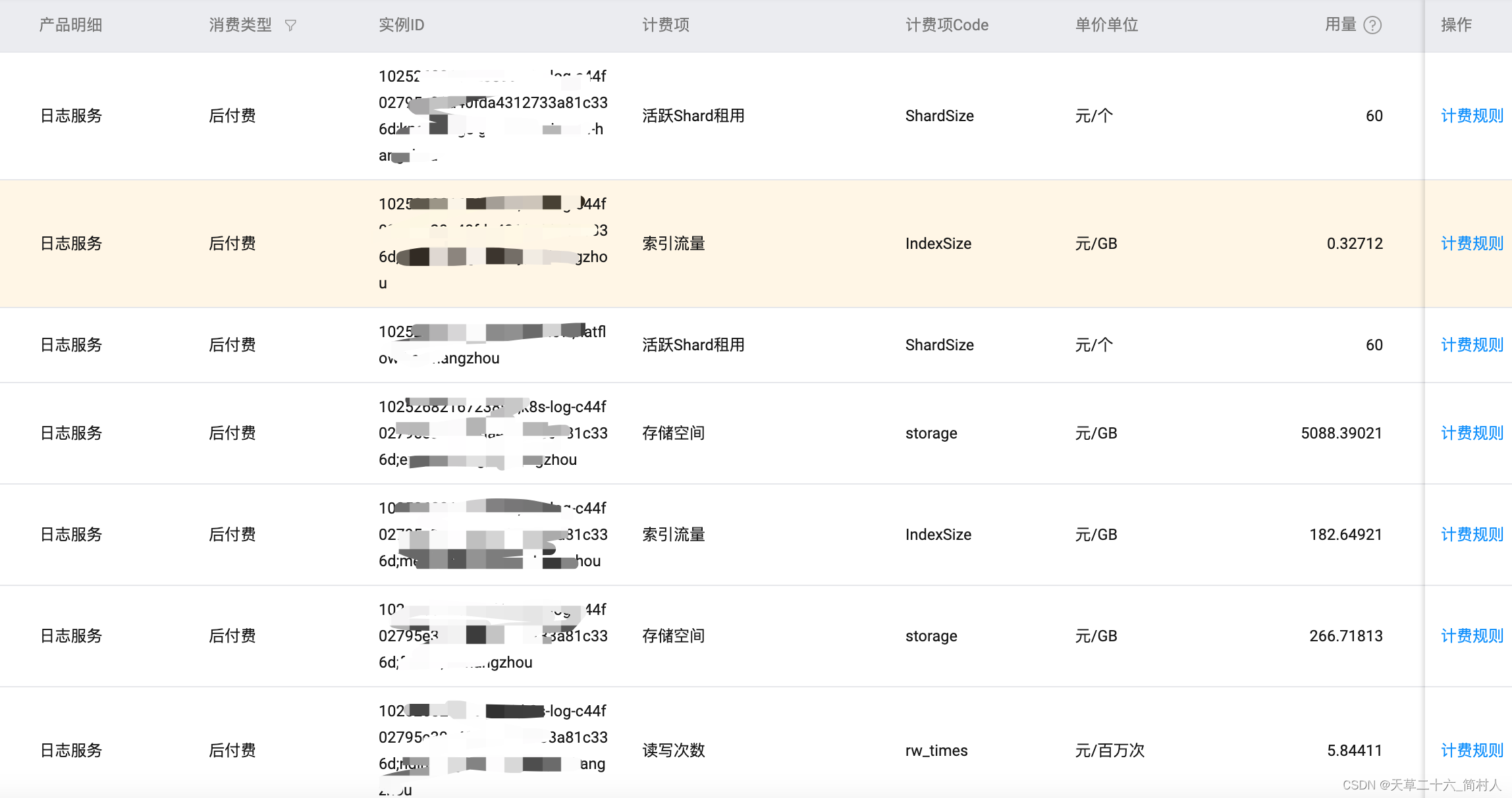
使用SLS日志服务采集Kong网关的日志
一、阿里云SLS 官方的接入文档已比较丰富了,本文不意重复说明此事。 站在使用的角度,以采集Kong的日志为示例,说明我们应该如何治理日志。 说白了,本文是想给你怎么省钱作一个建议,希望不会让你公司也“降本增笑”。…...
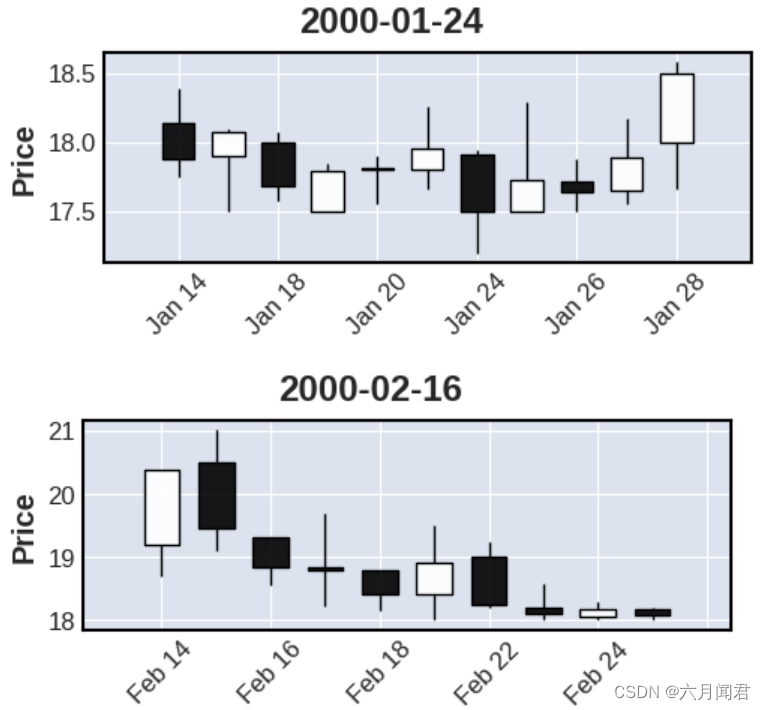
TA-Lib学习研究笔记(九)——Pattern Recognition (1)
TA-Lib学习研究笔记(九)——Pattern Recognition (1) 0.程序代码 形态识别的函数的应用,通过使用A股实际的数据,验证形态识别函数,用K线显示出现标志的形态走势,由于入口参数基本上…...
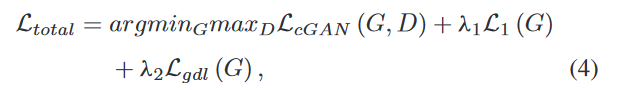
基于GAN的多尺度门合并多模态MRI图像合成
Multi-Modal MRI Image Synthesis via GAN With Multi-Scale Gate Mergence 基于GAN的多尺度门合并多模态MRI图像合成背景贡献实验方法生成器gate mergence (GM) strategy(门控融合策略)判别器 损失函数Thinking 基于GAN的多尺度门合并多模态MRI图像合成…...
浅谈https
1.网络传输的安全性 http 协议:不安全,未加密https 协议:安全,对请求报文和响应报文做加密 2.对称加密与非对称加密 2.1 对称加密 特点: 加解密使用 相同 秘钥 高效,适用于大量数据的加密场景 算法公开&a…...
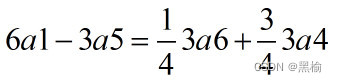
计算两个结构的差
平面上有6个点,以6a1的方式运动 1 1 1 1 - - - 1 - - - 1 现在有一个点逃逸,剩下的5个点将如何运动? 2 2 2 3 - - - 3 - - - 3 将6a1的6个点减去1个点,只有两种可能,或者变成5a2,…...

class037 二叉树高频题目-下-不含树型dp【算法】
class037 二叉树高频题目-下-不含树型dp【算法】 code1 236. 二叉树的最近公共祖先 // 普通二叉树上寻找两个节点的最近公共祖先 // 测试链接 : https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/ package class037;// 普通二叉树上寻找两个节点的最近…...
使用cpolar完成内网穿刺
cpolar官网上有一句评论:cpolar是用过最简单的内网穿刺工具! 实际体验下来,cpolar确实是能够非常简单地实现内网穿刺 先说弊端,免费版的cpolar提供的穿刺地址,有效期为一天,进程连接数有限,如…...

git的使用:基础配置和命令行
前言 代码管理工具,任何开发都离不开的话题。 到了任何公司,第一件事肯定是配置个人的电脑。主要就是三点,配置对应的开发环境,配置各类开发工具和配置git等代码管理工具拉取代码。 这篇文章主要是git的配置和最常用(我指的是最常用)的命令行使用 git基础配置 git的安装 …...
若依微服务项目整合rocketMq
原文链接:ttps://mp.weixin.qq.com/s/IYdo_suKvvReqCiEKjCeHw 第一步下载若依项目 第二步安装rocketMq(推荐在linux使用docker部署比较快) 第二步新建一个生产者模块儿,再建一个消费者模块 第四步在getway模块中配置接口映射规…...

连接服务器的ssh终端自动断开解放方法
在Linux中,SSH连接在一段时间内没有活动时可能会自动断开,这是为了安全性考虑的一种默认行为,以防止未经授权的访问。这个时间限制通常由SSH服务器的配置决定。你可以通过以下几种方式来处理这个问题: 1.使用SSH配置文件…...
指定IP)
Windows+WSL开发环境下微服务注册(Consul)指定IP
Win11下安装一个WSL2,做开发环境,简直是爽到不要不要的,相当于既有Windows下的完善生态,又有linux的便利。特别是,在linux下运行的服务端口号,完全和windows是相通的,直接在windows下浏览访问&a…...
通过K8S安装人大金仓数据库
1. 离线下载镜像,请点击 2. 官网下载镜像 https://www.kingbase.com.cn/xzzx/index.htm,根据自己的需求下载对应版本。 3. K8S需要的yaml清单 cat > kingbase.yaml << EOF apiVersion: apps/v1 kind: Deployment metadata:name: kingbase-…...

正则表达式(3):入门
正则表达式(3):入门 小结 本博文转载自 从这篇文章开始,我们将介绍怎样在Linux中使用”正则表达式”,如果你想要学习怎样在Linux中使用正则表达式,这些文章就是你所需要的。 在认识”正则表达式”之前&am…...
》第2章-计算机系统基础知识-01-计算机硬件)
《系统架构设计师教程(第2版)》第2章-计算机系统基础知识-01-计算机硬件
文章目录 1. 计算机系统概述2. 计算机硬件2.1 处理器(CPU)2.2 存储器2.2.1 概述2.2.2 按硬件结构分类2.2.3 按与处理器距离分2.3 总线(Bus)2.3.1 概念2.3.2 分类2.3.3 串行总线和并行总线2.4 接口2.4.1 概念2.4.2 常见接口2.5 外部设备1. 计算机系统概述 #mermaid-svg-IcU0sR…...
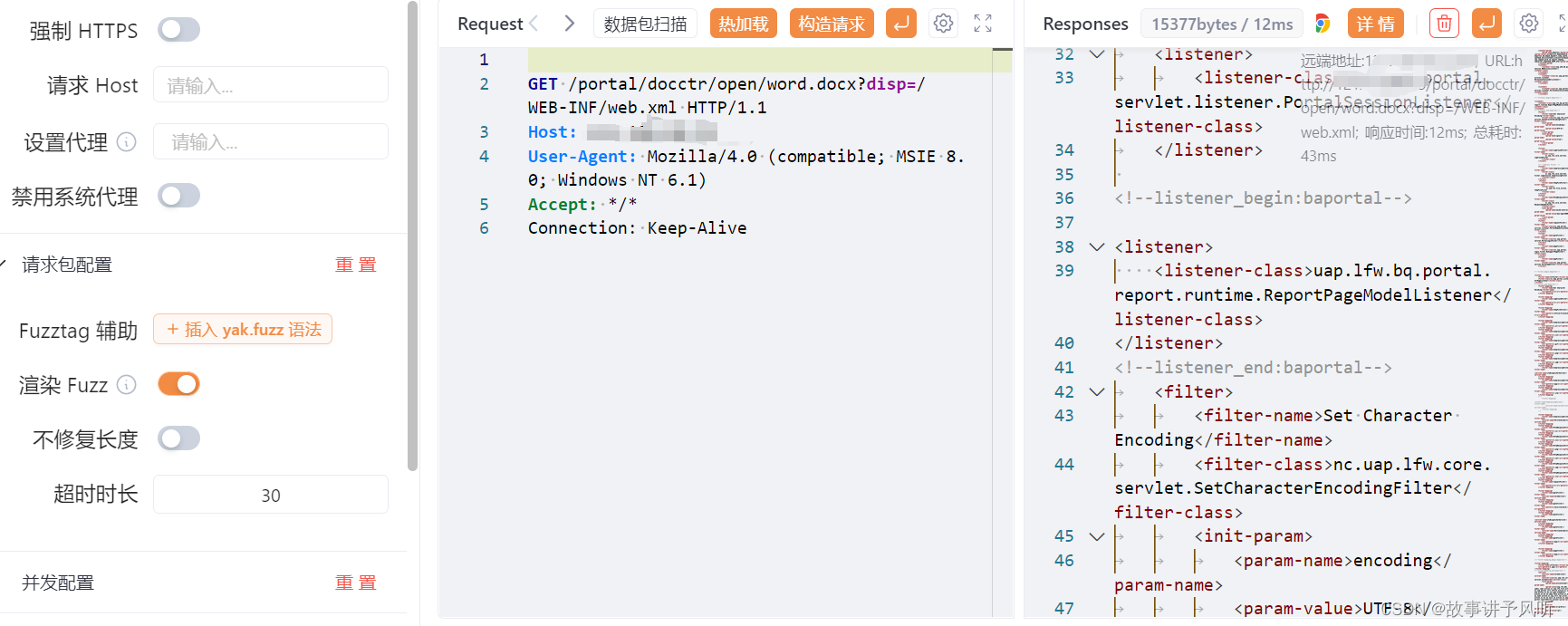
用友NC word.docx接口存在任意文件读取漏洞
声明 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 一、产品介绍 用友 NC Cloud,大型企业数字化平台ÿ…...
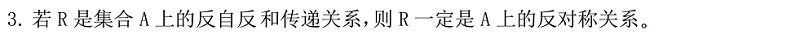
【离散数学】——期末刷题题库(等价关系与划分)
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...
Translumo完整指南:5分钟掌握Windows实时屏幕翻译神器,彻底告别语言障碍
Translumo完整指南:5分钟掌握Windows实时屏幕翻译神器,彻底告别语言障碍 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirro…...

STM32H743实战笔记:用SN65HVD230驱动14个伺服电机,1M波特率稳不稳?
STM32H743工业级CAN总线实战:14伺服电机集群控制与SN65HVD230极限测试 在工业机器人关节控制领域,多电机协同作业对总线通讯的实时性和稳定性提出严苛要求。最近完成的一个AGV底盘项目让我对STM32H743的CANopen主站性能有了全新认识——当需要同时驱动14…...

如何3步掌握MultiFunPlayer:专业设备同步工具快速入门指南
如何3步掌握MultiFunPlayer:专业设备同步工具快速入门指南 【免费下载链接】MultiFunPlayer flexible application to synchronize various devices with media playback 项目地址: https://gitcode.com/gh_mirrors/mu/MultiFunPlayer MultiFunPlayer是一款专…...
前,这5个NDR和约束设置没做好,后期时序肯定崩)
ICC II时钟树综合(CTS)前,这5个NDR和约束设置没做好,后期时序肯定崩
ICC II时钟树综合前的5个致命陷阱:NDR与约束设置实战指南 时钟树综合(CTS)是数字后端设计中最关键的阶段之一,而90%的后期时序问题往往源于CTS前的配置疏漏。本文将深入剖析五个最容易被忽视却影响深远的设置环节,结合…...

专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案
专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案 【免费下载链接】glogg A fast, advanced log explorer. 项目地址: https://gitcode.com/gh_mirrors/gl/glogg 在当今的分布式系统和微服务架构中,日志分析已成为系统运维、故障排…...

VIO实战:从理论到代码,详解相机与IMU时间戳软同步的两种核心算法
1. 时间戳同步:VIO系统的隐形守护者 第一次接触VIO系统时,我被一个看似简单的问题困扰了很久:为什么明明IMU和相机数据都对,但融合结果总是出现微妙的偏差?直到某天深夜调试代码时,突然发现两个传感器的时…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...