YOLOv8改进 | 2023 | DiverseBranchBlock多元分支模块(有效涨点)
一、本文介绍
本文带来的改进机制是YOLOv8模型与多元分支模块(Diverse Branch Block)的结合,Diverse Branch Block (DBB) 是一种用于增强卷积神经网络性能的结构重新参数化技术。这种技术的核心在于结合多样化的分支,这些分支具有不同的尺度和复杂度,从而丰富特征空间。我将其放在了YOLOv8的不同位置上均有一定的涨点幅度,同时这个DBB模块的参数量并不会上涨太多,我添加三个该机制到模型中,GFLOPs上涨了0.4。
推荐指数:⭐⭐⭐⭐
打星原因:为什么打四颗星是因为我觉得这个机制的计算量会上涨,这是扣分点,其次涨幅效果也比较一般但是有涨点,当然可能是数据集的原因毕竟不同的数据集效果不同
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
训练结果对比图->
这次试验我用的数据集大概有七八百张照片训练了150个epochs,虽然没有完全拟合但是效果有一定的涨点幅度,所以大家可以进行尝试毕竟不同的数据集上效果也可能差很多,同时我在后面给了多种yaml文件大家可以分别进行实验来检验效果。
目录
一、本文介绍
二、Diverse Branch Block原理
2.1 Diverse Branch Block的基本原理
2.2 多样化分支结构
2.3 训练与推理分离
2.4 宏观架构不变
三、Diverse Branch Block的完整代码
3.1 Diverse Branch Block的核心代码
3.2 修改了Diverse Branch Block的C2f和Bottleneck(使用这个否则大家自己修改可能报错)
四、手把手教你添加Diverse Branch Block机制
4.1 Diverse Branch Block的添加教程
4.2 Diverse Branch Block的yaml文件和训练截图
4.2.1 Diverse Branch Block的yaml版本一(推荐)
4.2.2 Diverse Branch Block的yaml版本二
4.2.3Diverse Branch Block的yaml版本三
4.2.2 Diverse Branch Block的训练过程截图
五、Diverse Branch Block可添加的位置
5.1 推荐Diverse Branch Block可添加的位置
六、本文总结
二、Diverse Branch Block原理

论文地址:论文官方地址
代码地址:官方代码地址

2.1 Diverse Branch Block的基本原理
Diverse Branch Block(DBB)的基本原理是在训练阶段增加卷积层的复杂性,通过引入不同尺寸和结构的卷积分支来丰富网络的特征表示能力。我们可以将基本原理可以概括为以下几点:
1. 多样化分支结构:DBB 结合了不同尺度和复杂度的分支,如不同大小的卷积核和平均池化,以增加单个卷积的特征表达能力。
2. 训练与推理分离:在训练阶段,DBB 采用复杂的分支结构,而在推理阶段,这些分支可以被等效地转换为单个卷积层,以保持高效推理。
3. 宏观架构不变:DBB 允许在不改变整体网络架构的情况下,作为常规卷积层的替代品插入到现有网络中。
下面我将为大家展示Diverse Branch Block(DBB)的设计示例:
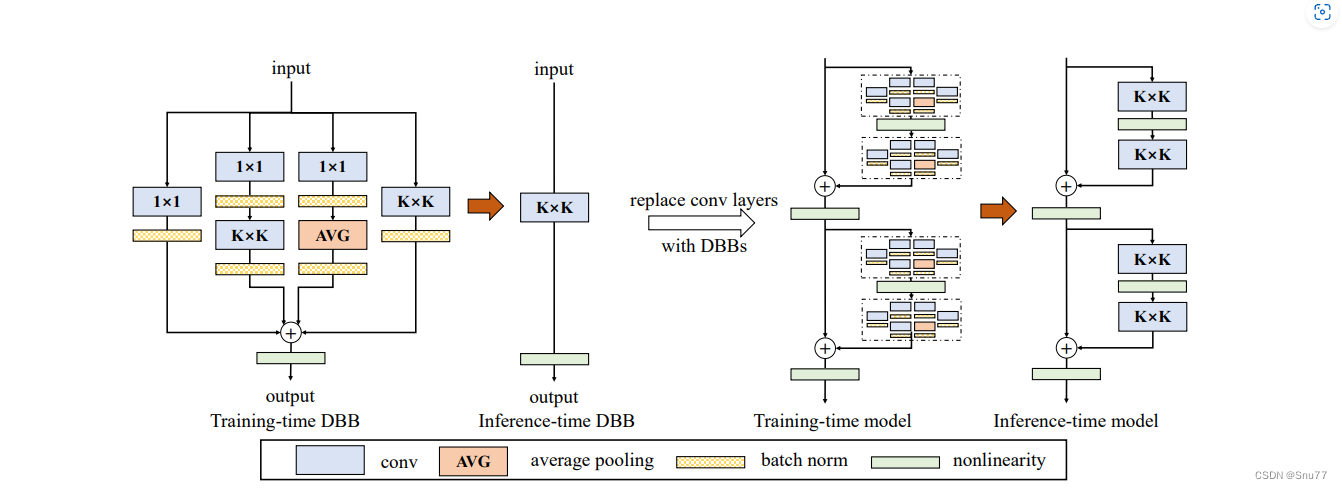
在训练时(左侧),DBB由不同大小的卷积层和平均池化层组成,这些层以一种复杂的方式并行排列,并最终合并输出。训练完成后,这些复杂的结构会转换成单个卷积层,用于模型的推理阶段(右侧),以此保持推理时的效率。这种转换允许DBB在保持宏观架构不变的同时,增加训练时的微观结构复杂性。
2.2 多样化分支结构
多样化分支结构是在卷积神经网络中引入的一种结构,旨在通过多样化的分支来增强模型的特征提取能力。这些分支包含不同尺寸的卷积层和池化层,以及其他潜在的操作,它们并行工作以捕获不同的特征表示。在训练完成后,这些复杂的结构可以合并并简化为单个的卷积层,以便在推理时不增加额外的计算负担。这种设计使得DBB可以作为现有卷积层的直接替换,增强了现有网络架构的性能,而不需要修改整体架构。
下面我详细展示了如何通过六种转换方法将训练时的Diverse Branch Block(DBB)转换为推理时的常规卷积层,每一种转换对应于一种特定的操作:

1. Transform I:将具有批量规范化(batch norm)的卷积层融合。
2. Transform II:合并具有相同配置的卷积层的输出。
3. Transform III:合并序列卷积层。
4. Transform IV:通过深度串联(concat)来合并卷积层。
5. Transform V:将平均池化(AVG)操作融入卷积操作中。
6. Transform VI:结合不同尺度的卷积层。
可以看到右侧的框显示了经过这些转换后,可以实现的推理时DBB,其中包含了常规卷积、平均池化和批量规范化操作。这些转换确保了在不增加推理时负担的同时,能够在训练时利用DBB的多样化特征提取能力。
2.3 训练与推理分离
训练与推理分离的概念是指在模型训练阶段使用复杂的DBB结构,而在模型推理阶段则转换为简化的卷积结构。这种设计允许模型在训练时利用DBB的多样性来增强特征提取和学习能力,而在实际应用中,即推理时,通过减少计算量来保持高效。这样,模型在保持高性能的同时,也保证了运行速度和资源效率。
上面我将展示在训练阶段如何通过不同的卷积组合(如图中的1x1和KxK卷积),以及在推理阶段如何将这些组合转换成一个简化的结构(如图中的转换IV所示的拼接操作):
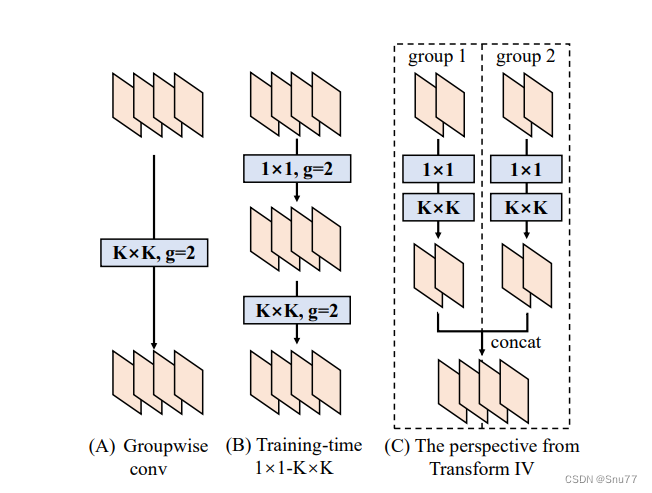
经过分析,我们可以发现它说明了三种不同的情况:
A)组卷积(Groupwise conv):将输入分成多个组,每个组使用不同的卷积核。
B)训练时的1x1-KxK结构:首先应用1x1的卷积(减少特征维度),然后是分组的KxK卷积。
C)从转换IV的角度看:这是将多个分组的卷积输出合并的视角。这里,组内卷积后的特征图先分别通过1x1卷积处理,然后再进行拼接(concat)。
2.4 宏观架构不变
宏观架构不变指的是DBB在设计时考虑到了与现有的网络架构兼容性,确保可以在不改变整体网络架构(如ResNet等流行架构)的前提下,将DBB作为一个模块嵌入。这意味着DBB增强了网络的特征提取能力,同时保持了原有网络结构的布局,确保了推理时的效率和性能。这样的设计允许研究者和开发者将DBB直接应用到现有的深度学习模型中,而无需进行大规模的架构调整。
三、Diverse Branch Block的完整代码
3.1 Diverse Branch Block的核心代码
Diverse Branch Block的本体代码,我们可以将其在'ultralytics/nn/modules'文件下面建立一个py文件复制粘贴进去,然后具体使用的方法可以看章节四。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from .conv import Conv, autopaddef transI_fusebn(kernel, bn):gamma = bn.weightstd = (bn.running_var + bn.eps).sqrt()return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / stddef transII_addbranch(kernels, biases):return sum(kernels), sum(biases)def transIII_1x1_kxk(k1, b1, k2, b2, groups):if groups == 1:k = F.conv2d(k2, k1.permute(1, 0, 2, 3)) #b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))else:k_slices = []b_slices = []k1_T = k1.permute(1, 0, 2, 3)k1_group_width = k1.size(0) // groupsk2_group_width = k2.size(0) // groupsfor g in range(groups):k1_T_slice = k1_T[:, g * k1_group_width:(g + 1) * k1_group_width, :, :]k2_slice = k2[g * k2_group_width:(g + 1) * k2_group_width, :, :, :]k_slices.append(F.conv2d(k2_slice, k1_T_slice))b_slices.append((k2_slice * b1[g * k1_group_width:(g + 1) * k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))k, b_hat = transIV_depthconcat(k_slices, b_slices)return k, b_hat + b2def transIV_depthconcat(kernels, biases):return torch.cat(kernels, dim=0), torch.cat(biases)def transV_avg(channels, kernel_size, groups):input_dim = channels // groupsk = torch.zeros((channels, input_dim, kernel_size, kernel_size))k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2return k# This has not been tested with non-square kernels (kernel.size(2) != kernel.size(3)) nor even-size kernels
def transVI_multiscale(kernel, target_kernel_size):H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,padding_mode='zeros'):conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups,bias=False, padding_mode=padding_mode)bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True)se = nn.Sequential()se.add_module('conv', conv_layer)se.add_module('bn', bn_layer)return seclass IdentityBasedConv1x1(nn.Conv2d):def __init__(self, channels, groups=1):super(IdentityBasedConv1x1, self).__init__(in_channels=channels, out_channels=channels, kernel_size=1, stride=1,padding=0, groups=groups, bias=False)assert channels % groups == 0input_dim = channels // groupsid_value = np.zeros((channels, input_dim, 1, 1))for i in range(channels):id_value[i, i % input_dim, 0, 0] = 1self.id_tensor = torch.from_numpy(id_value).type_as(self.weight)nn.init.zeros_(self.weight)def forward(self, input):kernel = self.weight + self.id_tensor.to(self.weight.device).type_as(self.weight)result = F.conv2d(input, kernel, None, stride=1, padding=0, dilation=self.dilation, groups=self.groups)return resultdef get_actual_kernel(self):return self.weight + self.id_tensor.to(self.weight.device)class BNAndPadLayer(nn.Module):def __init__(self,pad_pixels,num_features,eps=1e-5,momentum=0.1,affine=True,track_running_stats=True):super(BNAndPadLayer, self).__init__()self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats)self.pad_pixels = pad_pixelsdef forward(self, input):output = self.bn(input)if self.pad_pixels > 0:if self.bn.affine:pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(self.bn.running_var + self.bn.eps)else:pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps)output = F.pad(output, [self.pad_pixels] * 4)pad_values = pad_values.view(1, -1, 1, 1)output[:, :, 0:self.pad_pixels, :] = pad_valuesoutput[:, :, -self.pad_pixels:, :] = pad_valuesoutput[:, :, :, 0:self.pad_pixels] = pad_valuesoutput[:, :, :, -self.pad_pixels:] = pad_valuesreturn output@propertydef weight(self):return self.bn.weight@propertydef bias(self):return self.bn.bias@propertydef running_mean(self):return self.bn.running_mean@propertydef running_var(self):return self.bn.running_var@propertydef eps(self):return self.bn.epsclass DiverseBranchBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size,stride=1, padding=None, dilation=1, groups=1,internal_channels_1x1_3x3=None,deploy=False, single_init=False):super(DiverseBranchBlock, self).__init__()self.deploy = deployself.nonlinear = Conv.default_actself.kernel_size = kernel_sizeself.out_channels = out_channelsself.groups = groupsif padding is None:padding = autopad(kernel_size, padding, dilation)assert padding == kernel_size // 2if deploy:self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True)else:self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups)self.dbb_avg = nn.Sequential()if groups < out_channels:self.dbb_avg.add_module('conv',nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,stride=1, padding=0, groups=groups, bias=False))self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,padding=0, groups=groups)else:self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))if internal_channels_1x1_3x3 is None:internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channelsself.dbb_1x1_kxk = nn.Sequential()if internal_channels_1x1_3x3 == in_channels:self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))else:self.dbb_1x1_kxk.add_module('conv1',nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,kernel_size=1, stride=1, padding=0, groups=groups, bias=False))self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3,affine=True))self.dbb_1x1_kxk.add_module('conv2',nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=0, groups=groups,bias=False))self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.if single_init:# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.self.single_init()def get_equivalent_kernel_bias(self):k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)if hasattr(self, 'dbb_1x1'):k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)else:k_1x1, b_1x1 = 0, 0if hasattr(self.dbb_1x1_kxk, 'idconv1'):k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()else:k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weightk_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second,b_1x1_kxk_second, groups=self.groups)k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device),self.dbb_avg.avgbn)if hasattr(self.dbb_avg, 'conv'):k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second,b_1x1_avg_second, groups=self.groups)else:k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_secondreturn transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged),(b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))def switch_to_deploy(self):if hasattr(self, 'dbb_reparam'):returnkernel, bias = self.get_equivalent_kernel_bias()self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.conv.in_channels,out_channels=self.dbb_origin.conv.out_channels,kernel_size=self.dbb_origin.conv.kernel_size, stride=self.dbb_origin.conv.stride,padding=self.dbb_origin.conv.padding, dilation=self.dbb_origin.conv.dilation,groups=self.dbb_origin.conv.groups, bias=True)self.dbb_reparam.weight.data = kernelself.dbb_reparam.bias.data = biasfor para in self.parameters():para.detach_()self.__delattr__('dbb_origin')self.__delattr__('dbb_avg')if hasattr(self, 'dbb_1x1'):self.__delattr__('dbb_1x1')self.__delattr__('dbb_1x1_kxk')def forward(self, inputs):if hasattr(self, 'dbb_reparam'):return self.nonlinear(self.dbb_reparam(inputs))out = self.dbb_origin(inputs)if hasattr(self, 'dbb_1x1'):out += self.dbb_1x1(inputs)out += self.dbb_avg(inputs)out += self.dbb_1x1_kxk(inputs)return self.nonlinear(out)def init_gamma(self, gamma_value):if hasattr(self, "dbb_origin"):torch.nn.init.constant_(self.dbb_origin.bn.weight, gamma_value)if hasattr(self, "dbb_1x1"):torch.nn.init.constant_(self.dbb_1x1.bn.weight, gamma_value)if hasattr(self, "dbb_avg"):torch.nn.init.constant_(self.dbb_avg.avgbn.weight, gamma_value)if hasattr(self, "dbb_1x1_kxk"):torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight, gamma_value)def single_init(self):self.init_gamma(0.0)if hasattr(self, "dbb_origin"):torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)3.2 修改了Diverse Branch Block的C2f和Bottleneck(使用这个否则大家自己修改可能报错)
class Bottleneck_DBB(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = DiverseBranchBlock(c_, c2, k[1], 1, g)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C2f_DBB(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,expansion."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck_DBB(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""x = self.cv1(x)x = x.chunk(2, 1)y = list(x)# y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))四、手把手教你添加Diverse Branch Block机制
4.1 Diverse Branch Block的添加教程
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
这里需要注意的是我上面提供了两段代码一个是C2f-DBB一个是Diverse Branch Block的本体代码,这两种方法的添加方式有些不同。
最后强调一下Diverse Branch Block是一种可以替换卷积的模块,所以我们直接将其按照卷积的方式添加即可!!!
C2f-DBB按照正常C2f的机制进行添加即可!!!
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
4.2 Diverse Branch Block的yaml文件和训练截图
下面推荐几个版本的yaml文件给大家,大家可以复制进行训练,但是组合用很多具体那种最有效果都不一定,针对不同的数据集效果也不一样,我不可每一种都做实验,所以我下面推荐了三种我自己认为可能有效果的配合方式,你也可以自己进行组合。
4.2.1 Diverse Branch Block的yaml版本一(推荐)
下面的配置文件为我修改的C2f-DBB的位置(我的对比实验是用这个版本跑出来的)。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_DBB, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_DBB, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_DBB, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.2.2 Diverse Branch Block的yaml版本二
添加的版本二具体那种适合你需要大家自己多做实验来尝试。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_DBB, [256]] # 15 (P3/8-small)- [-1, 1, DiverseBranchBlock, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_DBB, [512]] # 18 (P4/16-medium)- [-1, 1, DiverseBranchBlock, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_DBB, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.2.3Diverse Branch Block的yaml版本三
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, DiverseBranchBlock, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, DiverseBranchBlock, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, DiverseBranchBlock, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, DiverseBranchBlock, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
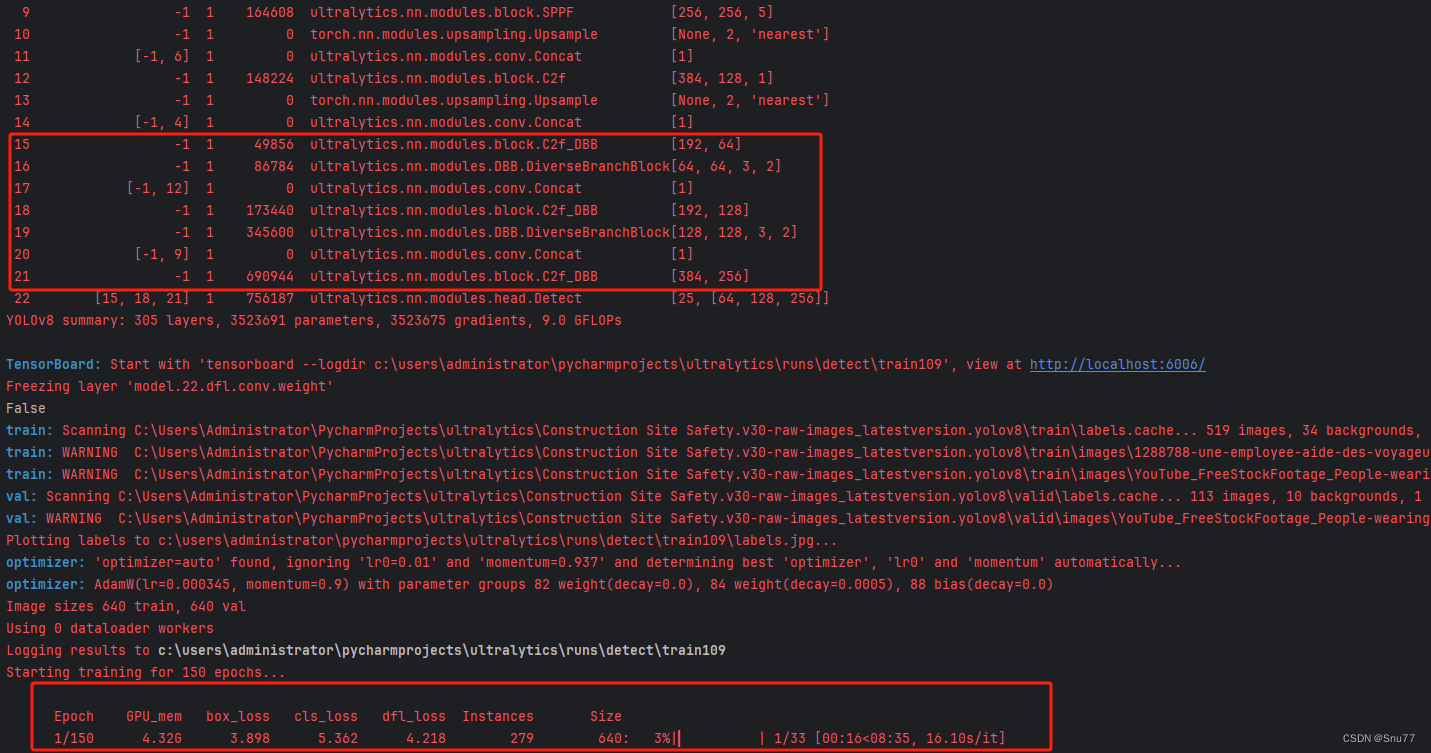
4.2.2 Diverse Branch Block的训练过程截图
下面是添加了Diverse Branch Block的训练截图。
(最近有人说我改的代码是没有发全的,我不知道这群人是怎么说出这种话的,希望大家如果用我的代码成功的可以在评论区支持一下,我也好发更多的改进毕竟免费给大家看。同时有问题皆可在评论区留言我看到都会回复)
大家可以看下面的运行结果和添加的未知所以不存在我发的代码不全或者运行不了的问题大家有问题也可以在评论区评论我看到都会为大家解答(我知道的)。
五、Diverse Branch Block可添加的位置
5.1 推荐Diverse Branch Block可添加的位置
Diverse Branch Block是一种即插即用的可替换卷积的模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入Diverse Branch Block(yaml文件一)。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加修改后的C2f_DBB可以帮助模型更有效地融合不同层次的特征(yaml文件二)。
Backbone:可以替换中干网络中的卷积部分(yaml文件三)
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

相关文章:
YOLOv8改进 | 2023 | DiverseBranchBlock多元分支模块(有效涨点)
一、本文介绍 本文带来的改进机制是YOLOv8模型与多元分支模块(Diverse Branch Block)的结合,Diverse Branch Block (DBB) 是一种用于增强卷积神经网络性能的结构重新参数化技术。这种技术的核心在于结合多样化的分支,这些分支具有…...
Spring Boot 3 整合 Spring Cache 与 Redis 缓存实战
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...

kubeadm 安装k8s1.28.x 底层走containerd 容器
1. k8s1.28.x 的概述 1.1 k8s 1.28.x 更新 Kubernetes v1.28 是 2023 年的第二个大版本更新,包含了 46 项主要的更新。 而今年发布的第一个版本 v1.27 有近 60 项,所以可以看出来,在发布节奏调整后, 每个 Kubernetes 版本中都会包…...

“分割“安卓用户,对标iOS,鸿蒙崛起~
近期关于**“华为于明年推出不兼容安卓的鸿蒙版本”**的消息传出,引起了业界的热议关注。自从2019年8月,美国制裁下,华为不再能够获得谷歌安卓操作系统相关付费服务,如此情况下,华为“备胎”鸿蒙操作系统一夜转正。 华…...
【Vulnhub 靶场】【hacksudo: ProximaCentauri】【简单 - 中等】【20210608】
1、环境介绍 靶场介绍:https://www.vulnhub.com/entry/hacksudo-proximacentauri,709/ 靶场下载:https://download.vulnhub.com/hacksudo/hacksudo-ProximaCentauri.zip 靶场难度:简单 - 中等 发布日期:2021年06月08日 文件大小&…...

share pool的组成
share pool的组成 3块区域:free,library cache,row cache 通过查看v$librarycache视图,可以监控library cache的活动情况,进一步衡量share pool设置是否合理; 其中reloads列,表示对象被重新加载的次数,在一个设置合…...

应用案例 | 基于三维视觉的汽车零件自动化拧紧解决方案
Part.1 引言 随着人们生活水平的提高,汽车作为理想的代步工具,逐渐成为人们生活中不可或缺的一部分。汽车的广泛应用,大大增加了汽车制造业的负荷。因此,如何提高生产效率和汽车性能,成为汽车制造业的首要关注话题。…...

Redis server启动源码
入口main函数 src/redis.c文件main函数 int main(int argc, char **argv) {struct timeval tv;/* We need to initialize our libraries, and the server configuration. */// 初始化库 #ifdef INIT_SETPROCTITLE_REPLACEMENTspt_init(argc, argv); #endif//设置本地时间setl…...

C++基础 强制转换
目录 static_cast:static_cast(expression) const_cast dynamic_cast reinterpret_cast C 提供以下几类转换 static_cast:static_cast<type-id>(expression) tatic_cast 主要用于以下几种情况: 用于显式地将一个表达式转换为另一…...
【python、opencv】opencv仿射变换原理及代码实现
opencv仿射变换原理 仿射变换是opencv的基本知识点,主要目的是将原始图片经过仿射变换矩阵,平移、缩放、旋转成目标图像。用数学公式表示就是坐标转换。 其中x,y是原始图像坐标,u,v是变换后的图像坐标。将公式转换为…...
mac本地部署stable-diffusion
下载Homebrew /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" ①输入“1”选择中科大版本,然后输入Y(YES),直接输入开机密码(不显示)然后回车确认,开始下载 ②…...
dockers安装rabbitmq
RabbitMQ: easy to use, flexible messaging and streaming — RabbitMQhttps://www.rabbitmq.com/ Downloading and Installing RabbitMQ — RabbitMQ docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.12-management 之后参照:dock…...
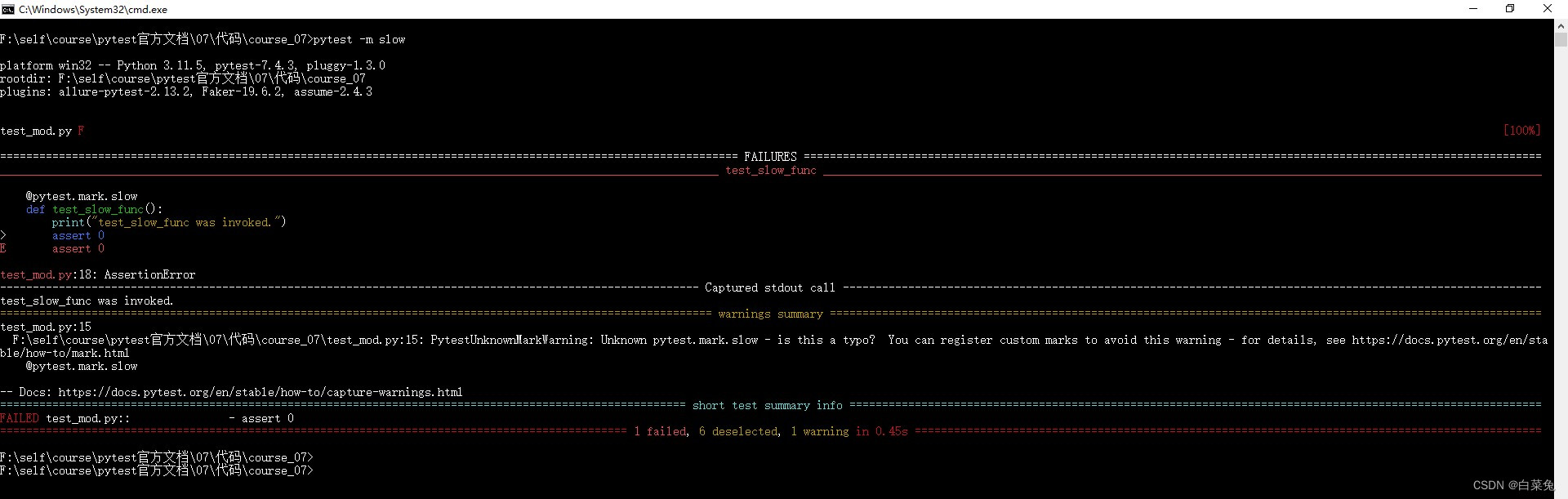
07、pytest指定要运行哪些用例
官方用例 # 目录结构 | |----test_mod.py | |----testing||----test_dir.py# content of test_mod.py import pytestdef func(x):return x 1def test_mod():print("test_mod function was invoked")assert func(3) 5def test_func():print("test_func was in…...

springboot集成cxf
<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://ma…...

快速认识什么是:Kubernetes
每次谈到容器的时候,除了Docker之外,都会说起 Kubernetes,那么什么是 Kubernetes呢?今天就来一起学快速入门一下 Kubernetes 吧!希望本文对您有所帮助。 Kubernetes,一种用于管理和自动化云中容器化工作负…...

YOLOv6 学习笔记
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、YOLOv6贡献和改进二、YOLOv6核心概念三、YOLOv6架构改进四、YOLOv6重参思想五、YOLOv6的损失函数总结 前言 在计算机视觉领域,目标检测技术一直…...

paypal贝宝怎么绑卡支付
一、PayPal是什么 PayPal是一个很多国家地区通用的支付渠道,我们可以把它理解为一项在线服务,相当于美国版的支付宝。你可以通过PayPal进行汇款和收款,相比传统的电汇和西联那类的汇款方式,PayPal更加简单和容易,被很…...

活动回顾|德州仪器嵌入式技术创新发展研讨会(上海站)成功举办,信驰达科技携手TI推动技术创新
2023年11月28日,德州仪器(TI)嵌入式技术创新发展研讨会在上海顺利举办。作为TI中国第三方IDH,深圳市信驰达科技有限公司受邀参加,并设置展位,展出CC2340系列低功耗蓝牙模块及TPMS、蓝牙数字钥匙解决方案,与众多业内伙伴…...

Vue 循环走马灯
1、使用 transform: translateX(),循环将滚动内容在容器内偏移,超出容器部分隐藏; 2、避免滚动到末尾时出现空白,需要预留多几个。 3、一次循环偏移的距离scrollLoopWidth 可能受样式影响需要做些微调,比如单个item的…...

<Linux>(极简关键、省时省力)《Linux操作系统原理分析之Linux文件管理(3)》(27)
《Linux操作系统原理分析之Linux文件管理(3)》(27) 8 Linux文件管理8.6 文件管理和操作8.6.1 系统对文件的管理8.6.2 进程对文件的管理 8 Linux文件管理 8.6 文件管理和操作 8.6.1 系统对文件的管理 Linux 系统把所有打开的活动…...

开源智能体技术解析:从LangChain到自主抓取,构建自动化工作流
1. 项目概述:从“Awesome”列表看开源智能体生态的演进 最近在梳理一些前沿的自动化工具链时,又翻到了 mergisi/awesome-openclaw-agents 这个仓库。对于长期关注AI Agent(智能体)和自动化工作流开发的同行来说,这类…...

计算机科学第三难题:“树映射”问题在文件、写作、建筑、生物分类中无处不在!
计算机科学第三难题:将通用图映射到层次结构,“树映射”问题无处不在 根据一个归属于 菲尔卡尔顿 的 经典笑话,计算机科学只有两个难题:命名和缓存失效。这两个问题之所以难,是因为没有算法可以解决它们:好…...

NVIDIA Profile Inspector完整指南:200+隐藏设置解锁显卡极致性能
NVIDIA Profile Inspector完整指南:200隐藏设置解锁显卡极致性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏画面撕裂、输入延迟过高而烦恼吗?想要彻底掌控NVIDIA…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案
ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...

基于双线性插值的AMG8833热成像分辨率提升方案与嵌入式实现
1. 项目概述:从8x8到15x15,一次软件驱动的热成像分辨率革命如果你玩过基于AMG8833这类低成本红外热成像传感器的项目,大概率会对它那8x8的“马赛克”图像印象深刻——64个像素点,勉强能看出个温度轮廓,但细节ÿ…...
)
【仅开放72小时】ElevenLabs德文语音生成高级提示词库(含137个Schwäbisch/Bavarian方言指令模板)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs德文语音生成技术概览与方言适配价值 ElevenLabs 的德语语音合成引擎基于多说话人、多风格的端到端扩散模型架构,支持高保真、低延迟的实时语音生成。其德语语音库覆盖标准高地德…...
嵌入式LED色彩校正:Gamma原理与Arduino NeoPixel实战
1. 项目概述:为什么你的NeoPixel灯带颜色总是不对劲?如果你玩过像NeoPixel、WS2812B这类可编程LED灯带,并且尝试过自己调色,大概率遇到过这样的困惑:你在代码里设定了一个“橙色”——比如红色满值255,绿色…...