【Windows下】Eclipse 尝试 Mapreduce 编程
文章目录
- 配置环境
- 环境准备
- 连接 Hadoop
- 查看 hadoop 文件
- 导入 Hadoop 包
- 创建 MapReduce 项目
- 测试 Mapreduce 编程代码
- 注意事项
- 常见报错
配置环境
环境准备
本次实验使用的 Hadoop 为 2.7.7 版本,实验可能会用到的文件
百度网盘链接:https://pan.baidu.com/s/1HZPOpg5MAiWXaN9DIcIUGg 提取码:gahr
迅雷云盘链接:https://pan.xunlei.com/s/VNkp2rp8az9m70YWCe5ifxm3A1?pwd=ggeq#
1)下载hadoop-eclipse-plugin-2.7.3.jar包
2)将jar包把放置到eclipse文件的plugins目录下
3)将hadoop解压到E盘
配置环境变量:添加用户变量HADOOP_HOME,值为E:\hadoop-2.7.7
Path新建%HADOOP_HOME%\bin、%HADOOP_HOME%\sbin
连接 Hadoop
1)打开 Eclipse ➡ Window ➡ Perspective ➡ Open Perspective ➡ other,

2)Map/Reduce ➡ Open,

3)进入界面后选择 Map/Reduce Locations,点击蓝色图标配置连接。

4)配置 hadoop 集群连接位置
Location name:myhadoop(随便填)
Host:192.168.88.102(填虚拟机IP地址)
Port:9000(填之前 Hadoop 中 core-site.xml 配置文件中,fs.defaultFS 对应的端口号)

查看 hadoop 文件
打开 myhadoop 查看文件内容,测试完全正确。

导入 Hadoop 包
选择:Window ➡ Perferencces ➡ Hadoop Map/Reduce ➡ Browse
选择所对应的 hadoop 安装包目录

创建 MapReduce 项目
1)创建 Project,File ➡ New ➡ Project

2)创建 MapReduce 项目

3)填写项目名 Wordcnt

4)打开引入的库可以看到 hadoop 的 jar 包已经导入,如图所示,不过我们此次要测试的 WordCount 类在测试包里面,我们现在需要先导入 hadoop 里自带的 examples 测试包。

5)构建路径配置步骤:Reference Libraries ➡ Build Path ➡ Configure Build Path

6)导入 jar 包:Java Build Path ➡ Add External JARs ➡ examples.jar ➡ Apply and Close 如图所示:

7)创建类


测试 Mapreduce 编程代码
1)Java 测试代码如下:
package org.apache.hadoop.examples;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.examples.WordCount.*;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class Wordcnt {public Wordcnt() {}public static void main(String[] args) throws Exception {// 使用 hadoop 的用户System.setProperty("HADOOP_USER_NAME", "user");Configuration conf = new Configuration();String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}// 每次运行前检查输出路径是否存在,存在就删除FileSystem fs = FileSystem.get(conf);Path outPath = new Path(otherArgs[1]);if(fs.exists(outPath)) {fs.delete(outPath, true);}// 启用跨平台,将应用程序从Windows客户端提交到Linux / Unix服务器conf.set("mapreduce.app-submission.cross-platform","true");Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for(int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
2)将 core-site.xml、hdfs-site.xml、log4.properties 三个文件下载放到 src 目录下

3)右击 java 文件 ➡ Run As ➡ Run Configurations

4)创建一个Java Application(双击就可以了) ➡ Arguments ➡ 第一个路径为 hadoop 上测试文件路径,第二个为输出文件路径(第二个路径用 jar 包中是不可以存在的,测试代码以更改可以存在)
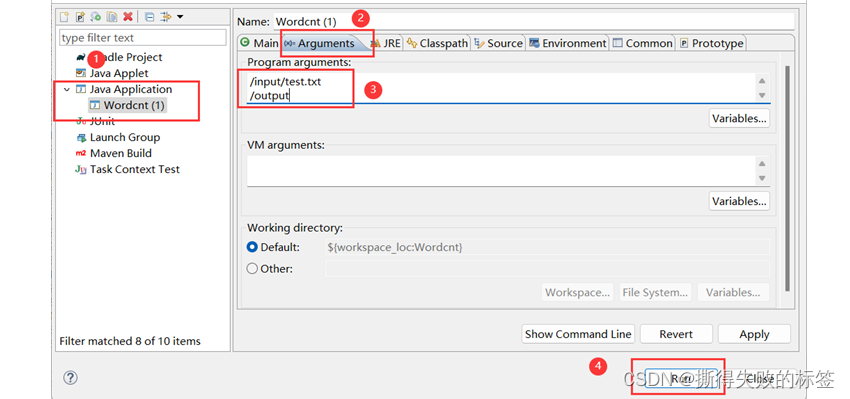
5)查看运行提示信息与结果,与 Linux 中结果一致

注意事项
1)这里的 user 需要改成自己所用的用户名
// 使用 hadoop 的用户
System.setProperty("HADOOP_USER_NAME", "user");
2)同系统中不需要这行代码(这里加上是因为我的 Hadoop 是部署在 Linux 系统上,代码是在 Windows 系统上运行的)
// 启用跨平台,将应用程序从Windows客户端提交到Linux / Unix服务器
conf.set("mapreduce.app-submission.cross-platform","true");
这个参数在 mapred-default.xml 文件里写到如果启用,用户可以跨平台提交应用程序,即从 Windows 客户端提交应用程序到 Linux/Unix 服务器,反之亦然。默认情况下是关闭的。链接:hadoop.apache.org/docs/r2.7.7/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
| name | value | description |
|---|---|---|
| mapreduce.app-submission.cross-platform | false | If enabled, user can submit an application cross-platform i.e. submit an application from a Windows client to a Linux/Unix server or vice versa. |
请注意,由于在 Windows 上使用 Eclipse 编写 MapReduce 程序,但实际运行是在 Linux 虚拟机上的 Hadoop 集群,所以需要 确保主机名和 IP 地址的映射 在虚拟机和 Windows 主机的 hosts 文件中都是正确的。
常见报错
1)报错内容如下:
Could not locate executable winutils.exe in the Hadoop binaries
这是因为 Hadoop 都是运行在 Linux 系统下的,在 Windows 下 Eclipse 中运行 Mapreduce 程序需要支持插件
下载 hadoop-common-2.2.0-bin-master 把其中的 winutils.exe 和 hadoop.dll 放到 windows 安装的 hadoop 的 bin 目录下,或者直接放到 C:\Windows\System32 目录下就可以了(版本最好对应)
2)报错内容如下:
INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/root/.staging/job_1510302622448_0003
出错原因:单机读取的是本地的文件,分布式环境下需要从hdfs 上读取文件。
解决方案:将本地的文件上传到 hdfs 上,然后再运行可以成功执行。
报错内容:
Output directory xxx already exists
出错原因:输出目录已存在
解决方案:修改输出目录,输出目录需要为空目录,所以在后面随便加上一个目录名,则会在 /output 目录下创建目录,如果是多次计算每次都需要指定不同的目录用于存储结果。
Hadoop文件系统命令参考:FileSystem Shell
下面给出几个常用命令
# 1 新建文件夹
hadoop dfs -mkdir [-p] <paths>
# 2 上传本地文件
hadoop fs -put localfile /hadoopdir
# 3 查看 hadoop 文件
hadoop fs -ls /hadoopfile
hadoop fs -ls -e /hadoopdir
# 4 修改文件夹权限
hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
# 5 删除文件夹
hadoop fs -rm -r /hadoopdir
相关文章:
【Windows下】Eclipse 尝试 Mapreduce 编程
文章目录 配置环境环境准备连接 Hadoop查看 hadoop 文件 导入 Hadoop 包创建 MapReduce 项目测试 Mapreduce 编程代码注意事项常见报错 配置环境 环境准备 本次实验使用的 Hadoop 为 2.7.7 版本,实验可能会用到的文件 百度网盘链接:https://pan.baidu…...

Python---time库
目录 时间获取 时间格式化 程序计时 time库包含三类函数: 时间获取:time() ctime() gmtime() 时间格式化:strtime() strptime() 程序计时:sleep() perf_counter() 下面逐一介绍&#…...
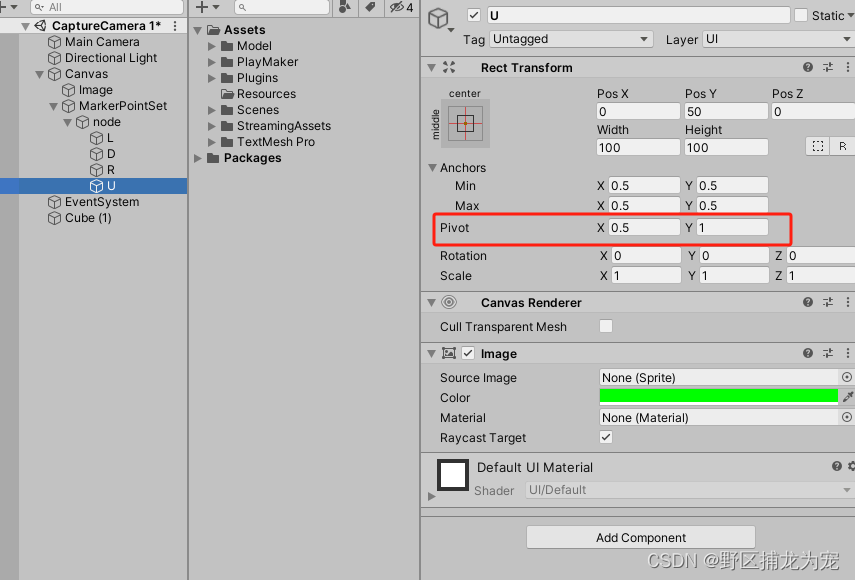
unity 自由框选截图(两种方法,亲测有效)
提示:文章有错误的地方,还望诸位大神不吝指教! 文章目录 前言一、第一种方法(1)简介GL(2) GL 用法:(3)具体代码 二、第二种方法第一步:第二步第三…...

项目代码规范
editorconfig EditorConfig 是一种用于统一不同编辑器和 IDE 的代码风格的文件格式和插件,帮助开发人员在不同的编辑器和 IDE 中保持一致的代码风格,从而提高代码的可读性和可维护性 # EditorConfig is awesome: https://EditorConfig.org root true[…...
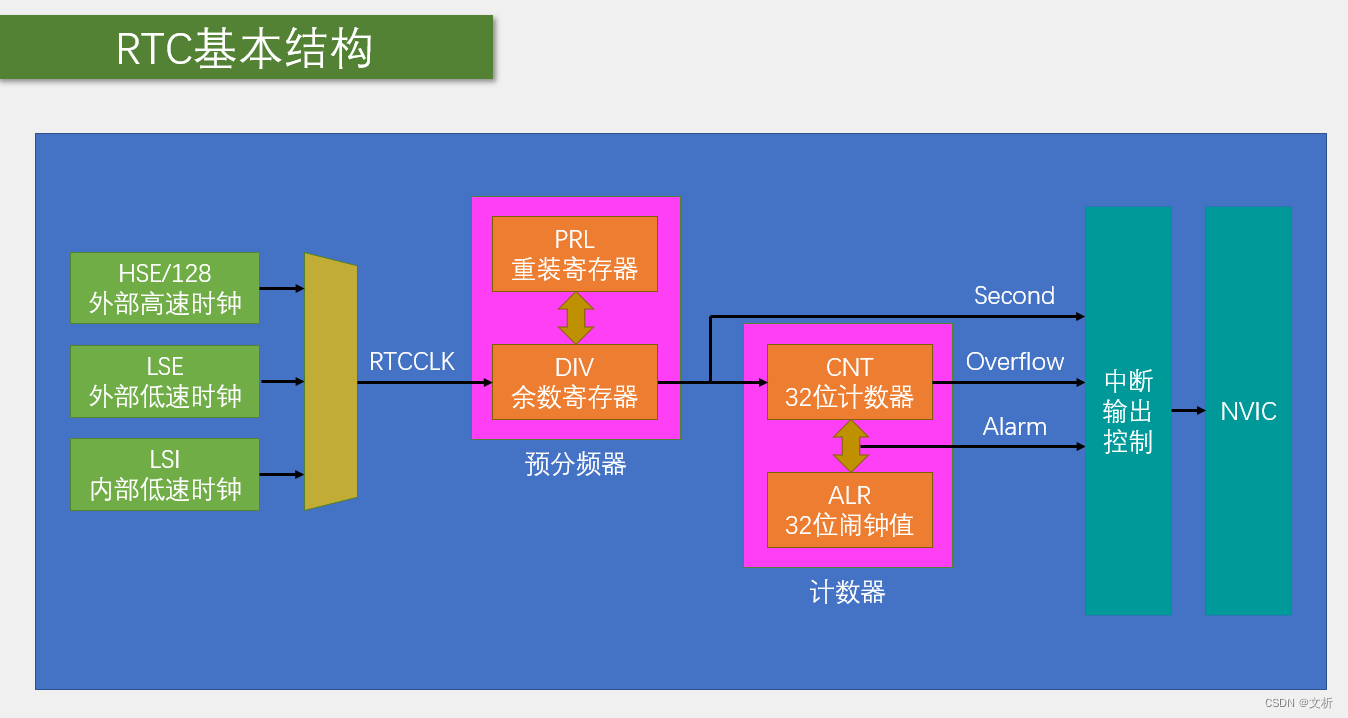
STM32的BKP与RTC简介
芯片的供电引脚 引脚表橙色的是芯片的供电引脚,其中VSS/VDD是芯片内部数字部分的供电,VSSA/VDDA是芯片内部模拟部分的供电,这4组以VDD开头的供电都是系统的主电源,正常使用时,全部都要接3.3V的电源上,VBAT是…...
11.Java安卓程序设计-基于SSM框架的Android平台健康管理系统的设计与实现
摘要 随着人们生活水平的提高和健康意识的增强,健康管理系统在日常生活中扮演着越来越重要的角色。本研究旨在设计并实现一款基于SSM框架的Android平台健康管理系统,为用户提供全面的健康监测和管理服务。 在需求分析阶段,我们明确了系统的…...
jetbrains卡顿(Pycharm等全家桶)终极解决方案,肯定解决!非常肯定!
话越短,越有用,一共四种方案,肯定能解决!!!非常肯定!! 下面四种解决方案,笔者按照实际体验后的结果,按照优先级从高到低排序。你只要按顺序试试就知道了。 m…...

c++的排序算法
一:merge 是 C STL 中的一个算法函数,用于将两个已排序的序列合并成一个有序序列。 template<class InputIterator1, class InputIterator2, class OutputIterator, class Compare> OutputIterator merge(InputIterator1 first1, InputIterator1 …...

YOLOv5独家原创改进:SPPF自研创新 | SPPF与感知大内核卷积UniRepLK结合,大kernel+非膨胀卷积提升感受野
💡💡💡本文自研创新改进:SPPF与感知大内核卷积UniRepLK结合,大kernel+非膨胀卷积,使SPPF增加大kernel,提升感受野,最终提升检测精度 收录 YOLOv5原创自研 https://blog.csdn.net/m0_63774211/category_12511931.html 💡💡💡全网独家首发创新(原创),…...

【C/PTA —— 15.结构体2(课外实践)】
C/PTA —— 15.结构体2(课外实践) 7-1 一帮一7-2 考试座位号7-3 新键表输出7-4 可怕的素质7-5 找出同龄者7-6 排队7-7 军训 7-1 一帮一 #include<stdio.h> #include<string.h>struct student {int a;char name[20]; };struct student1 {int …...

艾泊宇产品战略:适应新消费时代,产品战略指南以应对市场挑战和提升盈利
赚钱越来越难,这是许多企业和个人都感到困惑的问题。 然而,艾泊宇产品战略告诉大家,我们不能把这个问题简单地归咎于经济环境或市场竞争,而是需要从更深层次去思考和解决。 本文将从多个角度去剖析这个问题,并探讨在…...
使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度23 words/s
1,演示视频地址 https://www.bilibili.com/video/BV1Hu4y1L7BH/ 使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,用vllm优化,增加 --num-gpu 2,速度23 words/s 2,使用3090显卡 和…...
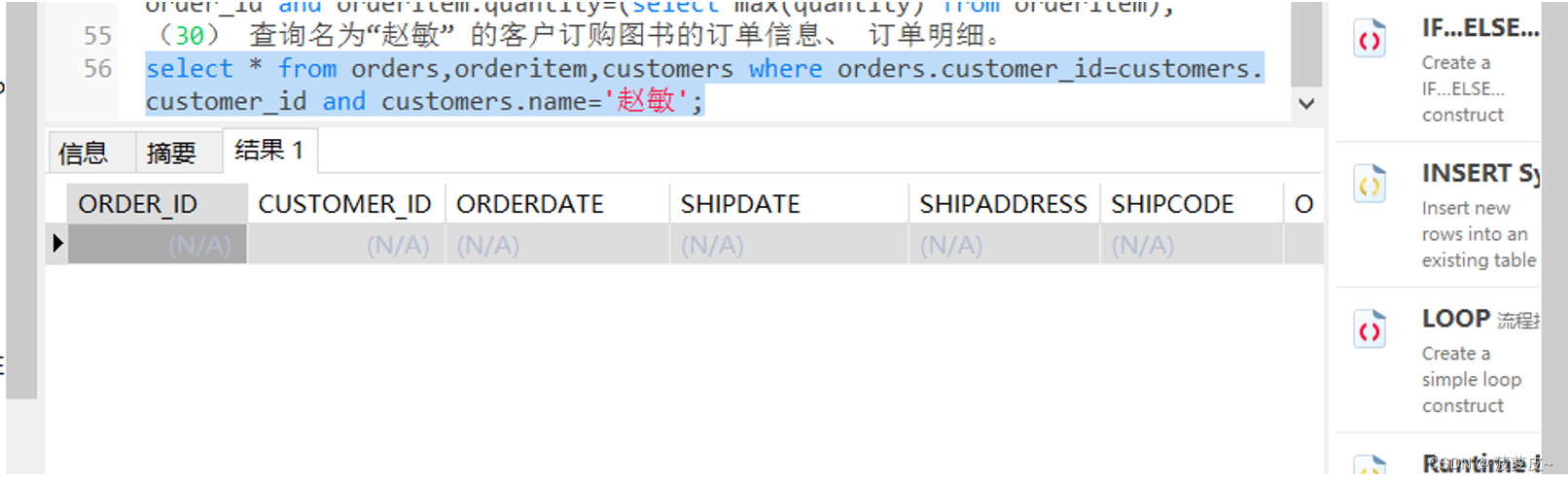
ORACLE数据库实验总集 实验六 SQL 语句应用
一、 实验目的 (1) 掌握数据的插入(INSERT)、 修改(UPDATE) 和删除(DELETE) 操作。 (2) 掌握不同类型的数据查询(SELECT) 操作。 二、…...

[FPGA 学习记录] 快速开发的法宝——IP核
快速开发的法宝——IP核 文章目录 1 IP 核是什么2 为什么要使用 IP 核3 IP 核的存在形式4 IP 核的缺点5 Quartus II 软件下 IP 核的调用6 Altera IP 核的分类 在本小节当中,我们来学习一下 IP 核的相关知识。 IP 核在 FPGA 开发当中应用十分广泛,它被称为…...
每日一题:LeetCode-11.盛水最多的容器
每日一题系列(day 13) 前言: 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🔎…...

查看电脑cuda版本
1.找到NVODIA控制面板 输入NVIDIA搜索即可 出现NVIDIA控制面板 点击系统信息 2.WINR 输入nvidia-smi 检查了一下,电脑没用过GPU,连驱动都没有 所以,装驱动…… 选版本,下载 下载后双击打开安装 重新输入nvidia-smi 显示如下…...
centos7 docker Mysql8 搭建主从
Mysql8 搭建主从 docker的安装docker-compose的安装安装mysql配置主从在master配置在slave中配置在master中创建同步用户在slave中连接 测试连接测试配置测试数据同步遇到的问题id重复错误执行事务出错,跳过错误my.cnf 不删除多余配置的错误可能用到的命令 docker的…...
CSS中 设置文字下划线 的几种方法
在网页设计和开发中,我们经常需要对文字进行样式设置,包括字体,颜色,大小等,其中,设置文字下划线是一种常见需求 一 、CSS种使用 text-decoration 属性来设置文字的装饰效果,包括下划线。 常用的取值&…...
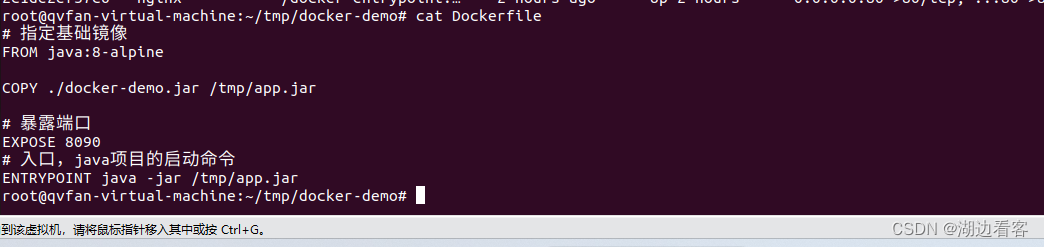
Docker构建自定义镜像
创建一个docker-demo的文件夹,放入需要构建的文件 主要是配置Dockerfile文件 第一种配置方法 # 指定基础镜像 FROM ubuntu:16.04 # 配置环境变量,JDK的安装目录 ENV JAVA_DIR/usr/local# 拷贝jdk和java项目的包 COPY ./jdk8.tar.gz $JAVA_DIR/ COPY ./docker-demo…...

C#生成Token字符串
Token字符串来保证数据安全性,如身份验证、跨域访问等。但是由于Token字符串的长度比较长,可能会占用过多的空间和带宽资源,因此我们需要生成短的Token字符串 方法一:使用Base64编码 Base64编码是一种常用的编码方式,…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...
在Windows下的详细评测与实战技巧)
Kafka运维新选择:Offset Explorer(Kafka Tool)在Windows下的详细评测与实战技巧
Kafka运维新选择:Offset Explorer在Windows下的深度评测与高阶实战 当Kafka集群规模从几个节点扩展到数十甚至上百个Broker时,命令行工具kafka-topics.sh和kafka-console-consumer.sh开始显得力不从心。这时,一个得力的可视化工具就像黑暗中的…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

基于LLM的长文本摘要工具SumGPT:从原理到本地化部署实战
1. 项目概述:一个为长文本摘要而生的智能工具最近在折腾一些文档处理的工作流,发现一个挺普遍但很烦人的痛点:面对动辄几十页的PDF报告、冗长的会议纪要或是海量的研究论文,想要快速抓住核心要点,简直像大海捞针。手动…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

基于Rust与Candle的AI推理引擎cria:简化大模型本地部署与优化
1. 项目概述:从“左移”到“创造”的AI推理引擎 最近在折腾AI模型本地部署和推理优化的朋友,可能都绕不开一个名字: cria 。这个由 leftmove 开源的项目,全称是“Cria: The AI Inference Engine”,直译过来就是“创…...

解锁Midjourney V6黑白摄影隐藏指令:5个未公开--stylize与--sref协同技法,92%用户至今不会用
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6黑白摄影的美学本质与技术觉醒 黑白摄影在 Midjourney V6 中已超越简单的色彩剥离,成为一场基于对比度张力、纹理显影与光影叙事的深度建模重构。V6 的隐式扩散架构强化了灰阶…...

基于Python/Flask的洗车店业务管理系统设计与实现
1. 项目概述:从“洗车”到“洗车服务”的数字化重构最近在GitHub上看到一个挺有意思的项目,叫“washing-cars”。光看名字,你可能会觉得这只是一个关于洗车的小工具或者记录表。但当我深入进去,才发现它远不止于此。这个项目本质上…...

如何永久保存微信聊天记录?三步实现完整备份与智能分析
如何永久保存微信聊天记录?三步实现完整备份与智能分析 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCh…...