pytorch-复现经典深度学习模型-LeNet5
Neural Networks
-
使用torch.nn包来构建神经网络。
nn包依赖autograd包来定义模型并求导。 一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。 -
一个简单的前馈神经网络,它接受一个输入,然后一层接着一层地传递,最后输出计算的结果。
-
神经网络的典型训练过程如下:
-
- 定义包含一些可学习的参数(或者叫权重)神经网络模型;
- 在数据集上迭代;
- 通过神经网络处理输入;
- 计算损失(输出结果和正确值的差值大小);
- 将梯度反向传播回网络的参数;
- 更新网络的参数,主要使用如下简单的更新原则:
weight = weight - learning_rate * gradient
-
开始定义一个Lenet5网络:
-
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 1 input image channel, 6 output channels, 5x5 square convolution# kernelself.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# Max pooling over a (2, 2) windowx = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# If the size is a square you can only specify a single numberx = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, self.num_flat_features(x))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):size = x.size()[1:] # all dimensions except the batch dimensionnum_features = 1for s in size:num_features *= sreturn num_features net = Net() print(net) -
Net((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True) ) -
在模型中必须要定义
forward函数,backward函数(用来计算梯度)会被autograd自动创建。 可以在forward函数中使用任何针对 Tensor 的操作。torch.nn只支持小批量输入。整个torch.nn包都只支持小批量样本,而不支持单个样本。 例如,nn.Conv2d接受一个4维的张量,每一维分别是sSamples * nChannels * Height * Width(样本数*通道数*高*宽)。 如果你有单个样本,只需使用input.unsqueeze(0)来添加其它的维数。net.parameters()返回可被学习的参数(权重)列表和值 -
params = list(net.parameters()) print(len(params)) for i in range(len(params)):print(f"第{i}层需要学习参数的参数量矩阵大小:",params[i].size()) ) -
10 第0层需要学习参数的参数量矩阵大小: torch.Size([6, 1, 5, 5]) 第1层需要学习参数的参数量矩阵大小: torch.Size([6]) 第2层需要学习参数的参数量矩阵大小: torch.Size([16, 6, 5, 5]) 第3层需要学习参数的参数量矩阵大小: torch.Size([16]) 第4层需要学习参数的参数量矩阵大小: torch.Size([120, 400]) 第5层需要学习参数的参数量矩阵大小: torch.Size([120]) 第6层需要学习参数的参数量矩阵大小: torch.Size([84, 120]) 第7层需要学习参数的参数量矩阵大小: torch.Size([84]) 第8层需要学习参数的参数量矩阵大小: torch.Size([10, 84]) 第9层需要学习参数的参数量矩阵大小: torch.Size([10]) -
测试随机输入32×32。 注:这个网络(LeNet)期望的输入大小是32×32,如果使用MNIST数据集来训练这个网络,请把图片大小重新调整到32×32。
-
input = torch.randn(1, 1, 32, 32) out = net(input) print(out) -
tensor([[ 0.0501, 0.1101, -0.0294, 0.0030, 0.0629, 0.0379, 0.0860, 0.0104,0.1108, 0.0916]], grad_fn=<AddmmBackward0>) -
将所有参数的梯度缓存清零,然后进行随机梯度的的反向传播:
-
net.zero_grad() out.backward(torch.randn(1, 10).data) print(out) -
tensor([[-0.0275, -0.0630, -0.0253, -0.0811, 0.0872, -0.0282, 0.0926, 0.1020,-0.1034, 0.0727]], grad_fn=<AddmmBackward0>) -
torch.Tensor:一个用过自动调用backward()实现支持自动梯度计算的 多维数组 , 并且保存关于这个向量的梯度 w.r.t. -
nn.Module:神经网络模块。封装参数、移动到GPU上运行、导出、加载等。 -
nn.Parameter:一种变量,当把它赋值给一个Module时,被 自动 地注册为一个参数。 -
autograd.Function:实现一个自动求导操作的前向和反向定义,每个变量操作至少创建一个函数节点,每一个Tensor的操作都回创建一个接到创建Tensor和 编码其历史 的函数的Function节点。
损失函数
-
一个损失函数接受一对 (output, target) 作为输入,计算一个值来估计网络的输出和目标值相差多少。nn包中有很多不同的损失函数。
nn.MSELoss是一个比较简单的损失函数,它计算输出和目标间的均方误差, 例如: -
output = net(input) target = torch.randn(10) # 随机值作为样例 target = target.view(1, -1) # 使target和output的shape相同 criterion = nn.MSELoss() loss = criterion(output, target) print(loss) -
tensor(0.8873, grad_fn=<MseLossBackward0>) -
反向过程中跟随
loss, 使用它的.grad_fn属性,将看到如下所示的计算图。 -
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d-> view -> linear -> relu -> linear -> relu -> linear-> MSELoss-> loss -
当我们调用
loss.backward()时,整张计算图都会 根据loss进行微分,而且图中所有设置为requires_grad=True的张量 将会拥有一个随着梯度累积的.grad张量。
反向传播
-
调用loss.backward()获得反向传播的误差。但是在调用前需要清除已存在的梯度,否则梯度将被累加到已存在的梯度。现在,我们将调用loss.backward(),并查看conv1层的偏差(bias)项在反向传播前后的梯度。
-
net.zero_grad() # 清除梯度 print('conv1.bias.grad before backward') print(net.conv1.bias.grad) loss.backward() print('conv1.bias.grad after backward') print(net.conv1.bias.grad) -
conv1.bias.grad before backward tensor([0., 0., 0., 0., 0., 0.]) conv1.bias.grad after backward tensor([-0.0136, 0.0067, 0.0111, 0.0210, 0.0111, -0.0072])
更新权重
-
当使用神经网络是想要使用各种不同的更新规则时,比如SGD、Nesterov-SGD、Adam、RMSPROP等,PyTorch中构建了一个包
torch.optim实现了所有的这些规则。 使用它们非常简单: -
import torch.optim as optim # create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01) # in your training loop: for i in range(10):optimizer.zero_grad() # zero the gradient buffersoutput = net(input)loss = criterion(output, target)loss.backward()optimizer.step() # Does the updateprint(f"第{i}轮训练:",loss) -
第0轮训练: tensor(0.8873, grad_fn=<MseLossBackward0>) 第1轮训练: tensor(0.8725, grad_fn=<MseLossBackward0>) 第2轮训练: tensor(0.8582, grad_fn=<MseLossBackward0>) 第3轮训练: tensor(0.8447, grad_fn=<MseLossBackward0>) 第4轮训练: tensor(0.8309, grad_fn=<MseLossBackward0>) 第5轮训练: tensor(0.8173, grad_fn=<MseLossBackward0>) 第6轮训练: tensor(0.8035, grad_fn=<MseLossBackward0>) 第7轮训练: tensor(0.7897, grad_fn=<MseLossBackward0>) 第8轮训练: tensor(0.7764, grad_fn=<MseLossBackward0>) 第9轮训练: tensor(0.7623, grad_fn=<MseLossBackward0>)
035, grad_fn=)
第7轮训练: tensor(0.7897, grad_fn=)
第8轮训练: tensor(0.7764, grad_fn=)
第9轮训练: tensor(0.7623, grad_fn=)
相关文章:

pytorch-复现经典深度学习模型-LeNet5
Neural Networks 使用torch.nn包来构建神经网络。nn包依赖autograd包来定义模型并求导。 一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。 一个简单的前馈神经网络,它接受一个输入,然后一层接着一层地传递,…...

【C++】类和对象(上)
文章目录对象的介绍类的介绍类的两种定义方式类的访问限定符及封装访问限定符封装类的作用域类的实例化类的对象模型对象的介绍 C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题; C是基于面向…...
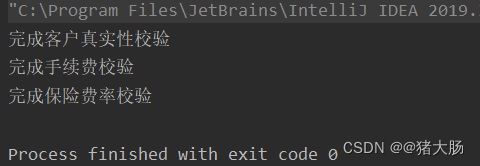
工作中责任链模式用法及其使用场景?
前言 笔者是金融保险行业,有这么一种场景,业务员录完单后提交核保,这时候系统会对保单数据进行校验,如不允许手续费超限校验,客户真实性校验、费率限额校验等等,当校验一多时,维护起来特别麻烦…...
三八女神节有哪些数码好物?2023年三八女神节数码好物清单
2023年的三八女神节就快到了,大家还在烦恼,不知道有哪些数码好物?在此,我来给大家分享几款三八女神节实用性强的数码好物,一起来看看吧。 一、蓝牙耳机:南卡小音舱 参考价:239 推荐理由&…...
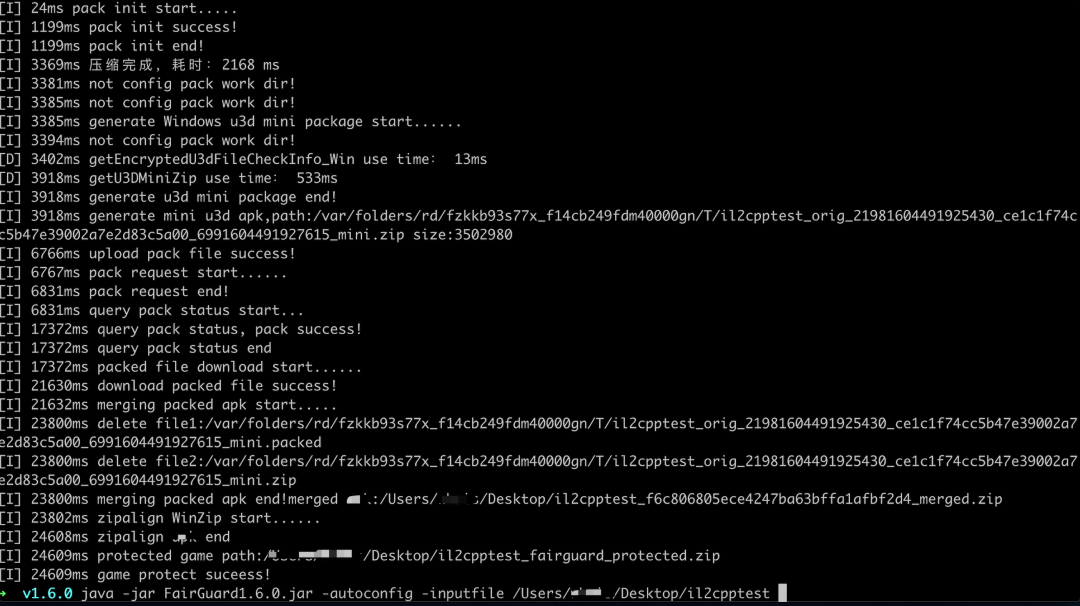
FairGuard-Windows加固工具版本更新日志
FairGuard-Windows加固工具1.2.2版本更新日志: ■ 增加Unity Resources资源加密的支持; ■ 增加单独Assetbundle资源加密,并同时支持压缩包和文件夹作为输入的方式; ■ 增加对游戏原文件夹加固的支持; Windows加固方案介绍 FairGuard专为游戏量身定…...

基于RT-Thread完整版搭建的极简Bootloader
项目背景Agile Upgrade: 用于快速构建 bootloader 的中间件。example 文件夹提供 PC 上的示例特性适配 RT-Thread 官方固件打包工具 (图形化工具及命令行工具)使用纯 C 开发,不涉及任何硬件接口,可在任何形式的硬件上直接使用加密、压缩支持如下…...

3.flinkDateStreamAPI介绍env与source
执行环境 Flink可以在不同的环境上下文中运行.可以本地集成开发环境中运行也可以提交到远程集群环境运行. 不同的运行环境对应的flink的运行过程不同,需要首先获取flink的运行环境,才能将具体的job调度到不同的TaskManager 在flink中可以通过StreamExecutionEnvironment类获取…...

$ 2 :数据类型
1.数据类型 1.1基本类型 a、整型int b、浮点型float c、字符型char 1.2构造类型 a、数组[ ] b、结构体struct 1.3指针类型 * 1.4空类型(void) 2.关键字 autoconstdoublefloatintshortstructunsignedbreakcontinueelseforlongsignedswitchvoidcasedefaultenumgotoregistersiz…...

类和对象 - 上
本文已收录至《C语言》专栏! 作者:ARMCSKGT 目录 前言 正文 面向过程与面向对象 面向过程的解决方法 面向对象的解决方法 面向对象的优势 类的引入 早期C类的实现 class定义类 class定义规则 类成员的两种定义方式 类的访问限定符及封装 访…...
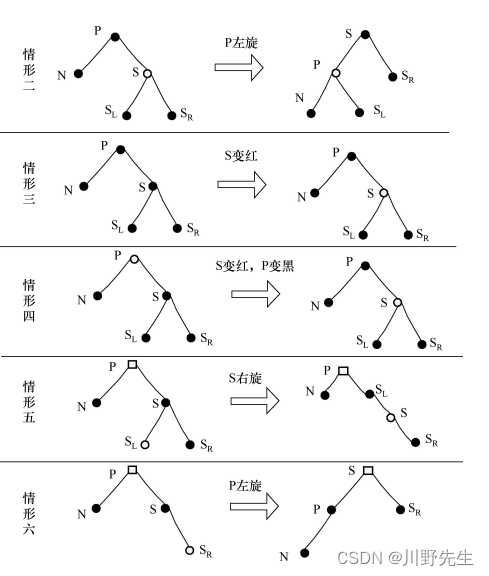
补档:红黑树代码实现+简略讲解
红黑树讲解和实现1 红黑树介绍1.1 红黑树特性1.2 红黑树的插入1.3 红黑树的删除2 完整代码实现2.1 rtbtree.h头文件2.2 main.c源文件1 红黑树介绍 红黑树( Red-Black tree,简称RB树)是一种自平衡二叉查找树,是计算机科学中常见的一种数据结构,…...
FirePower X2 14.0.1 for RAD Studio Alexandria
介绍 FirePower X2 FirePower X2 集成了 RAD Studio 11.0 Alexandria 中的新功能,并预览了我们的新特色组件 TwwDataGrouper。 FirePower X2 还允许您为 Apple 的新 M1 芯片构建应用程序,这样您就可以进一步利用 M1 芯片来提高本机应用程序的性能&#x…...
)
二十九、MongoDB 恢复数据( mongorestore )
MongoDB mongorestore 脚本命令可以用来恢复备份的数据 语法 MongoDB mongorestore 命令脚本语法如下 $ mongorestore -h <hostname><:port> -d dbname <path> 参数说明 -h <:port>, -h<:port> MongoDB 所在服务器地址,默认为 l…...

【数据分析】缺失数据如何处理?pandas
本文目录1. 基础概念1.1. 缺失值分类1.2. 缺失值处理方法2. 缺失观测及其类型2.1. 了解缺失信息2.2. 三种缺失符号2.3. Nullable类型与NA符号2.4. NA的特性2.5. convert_dtypes方法3. 缺失数据的运算与分组 3.1. 加号与乘号规则3.2. groupby方法中的缺失值4. 填充与剔除4.1. fi…...
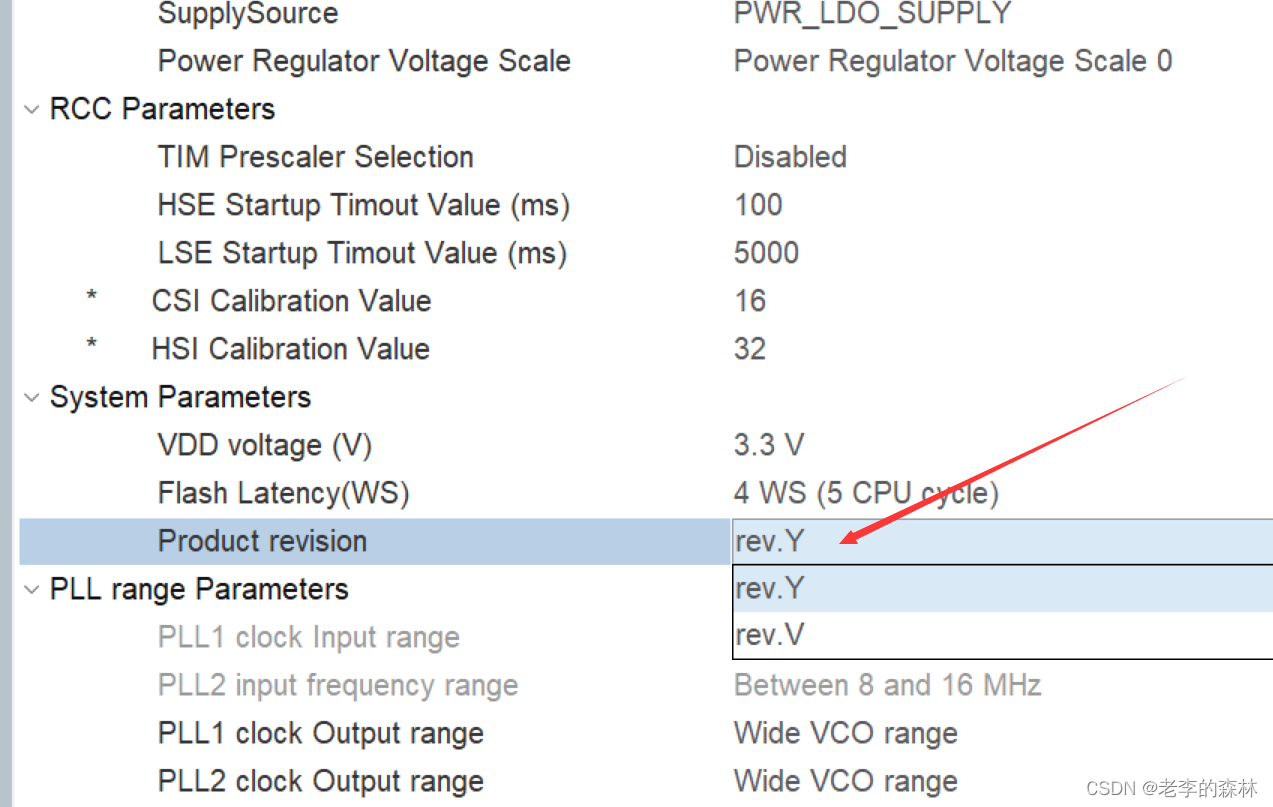
嵌入式开发--STM32H750VBT6开发中,新版本CubeMX的时钟问题,不能设置到最高速度480MHZ
嵌入式开发–STM32H750VBT6开发中,新版本CubeMX的时钟问题,不能设置到最高速度480MHZ 问题描述 之前开发的项目,开发环境是CubeMX6.6.1,H7系列的支持包版本是1.10.0。跑得没问题,最近需要对项目做修改,同…...

一文读懂PaddleSpeech中英混合语音识别技术
语音识别技术能够让计算机理解人类的语音,从而支持多种语音交互的场景,如手机应用、人车协同、机器人对话、语音转写等。然而,在这些场景中,语音识别的输入并不总是单一的语言,有时会出现多语言混合的情况。例如&#…...

问题三十四:傅立叶变换——高通滤波
高通滤波器是一种可以通过去除图像低频信息来增强高频信息的滤波器。在图像处理中,高通滤波器常常用于去除模糊或平滑效果,以及增强边缘或细节。在本篇回答中,我们将使用Python和OpenCV实现高通滤波器。 Step 1:加载图像并进行傅…...
)
flink 键控状态(keyed state)
github开源项目flink-note的笔记。本博客的实现代码都写在项目的flink-state/src/main/java/state/keyed/KeyedStateDemo.java文件中。 项目github地址: github 1. flink键控状态 flink键控状态是作用与flink KeyedStream上的,也就是说需要将DataStream先进行keyby之后才能使…...
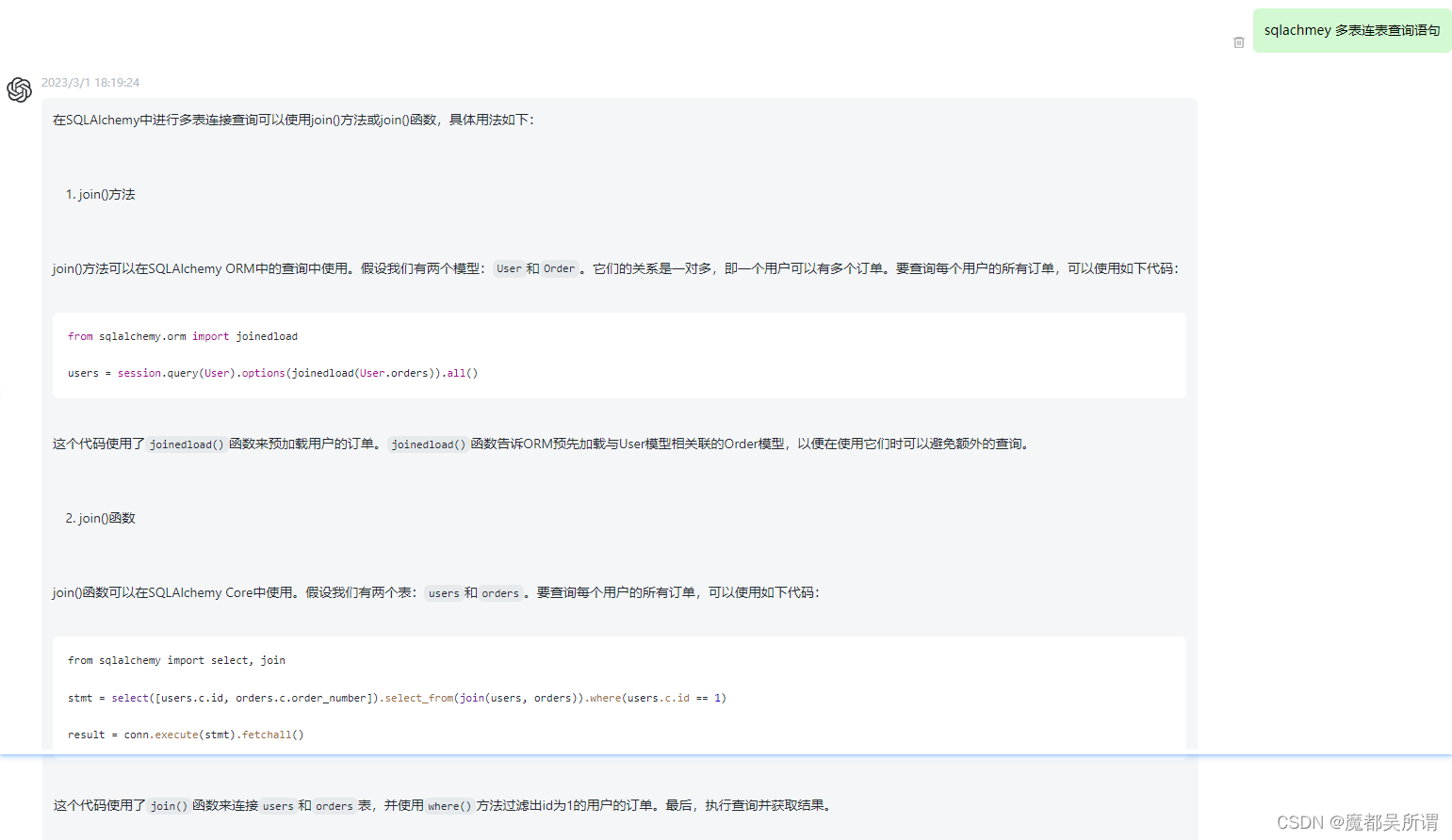
【ChatGPT】sqlachmey 多表连表查询语句
感受下科技带来的魅力,这篇文章是通过ChatGPT自动生成的,不得不说技术强大!!! 在SQLAlchemy中进行多表连接查询可以使用join()方法或join()函数,具体用法如下: join()方法 join()方法可以在SQLAlchemy ORM中的查询中使用。假设…...

win11 系统登录问题,PIN 设置问题
我的电脑配置是华为MateBook X Pro 12,i7处理器,16G,1T,win11 系统通过微软账户登录,下午一直登录不进去,网络能连外网,分析应该是连微软服务器不行。连续登录几十次,偶尔可能有一次…...
数据结构六大排序
1.插入排序 思路: 从第一个元素开始认为是有序的,去一个元素tem从有序序列从后往前扫描,如果该元素大于tem,将该元素一刀下一位,循环步骤3知道找到有序序列中小于等于的元素将tem插入到该元素后,如果已排序…...

Hermes-Agent 智能体核心能力与实战效能深度评测
在构建自动化工作流或智能客服系统时,开发者最常遇到的痛点往往不是模型本身不够聪明,而是“记不住”和“乱执行”。很多时候,一个智能体在前几轮对话中还逻辑清晰,一旦上下文拉长,就开始遗忘关键约束,或者…...

Taotoken CLI工具一键配置开发环境与团队密钥共享指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具一键配置开发环境与团队密钥共享指南 在团队协作开发中,统一大模型API的接入配置是一个常见痛点。每位…...

CircuitMaker免费PCB设计工具:从开源协议到实战避坑指南
1. 从“Freemium”到“全免费”:CircuitMaker的定位之变与我的选择时间过得真快,距离Altium首次推出免费的CircuitMaker工具,仿佛就在昨天。我记得当时业界一片哗然,大家都在讨论这家以高端、专业的Altium Designer闻名的公司&…...

从泡泡实验室到阿木社区:PX4开发者如何在国内技术圈子里快速成长?
从泡泡实验室到阿木社区:PX4开发者如何在国内技术圈子里快速成长? 在无人机开源飞控领域,PX4和Pixhawk已经成为开发者绕不开的技术栈。但相比国外活跃的开发者社区,国内的技术生态往往让新手感到无从下手——百度贴吧的讨论碎片化…...
来了!)
一句话就能“劫持”你的AI?DZS 分层式自适应提示词注入攻击的防御机制框架 (HAA)来了!
本文所展示的提示词技术已在Research square 发表论文预印本。DOI:https://doi.org/10.21203/rs.3.rs-9653510/v1 作者“抖知书(douzhishu),涉及到相关测试数据是本人自行测试的,并未通过多专家评审,所以仅…...

3个战略理由选择ES-Client作为您的Elasticsearch管理平台
3个战略理由选择ES-Client作为您的Elasticsearch管理平台 【免费下载链接】es-client elasticsearch客户端,issue请前往码云:https://gitee.com/qiaoshengda/es-client 项目地址: https://gitcode.com/gh_mirrors/es/es-client 在当今数据驱动的业…...

第八部分-企业级实践——39. 私有镜像仓库
39. 私有镜像仓库 1. 私有镜像仓库概述 私有镜像仓库用于存储和管理企业内部 Docker 镜像,提供镜像存储、分发、安全扫描、访问控制等功能。 ┌────────────────────────────────────────────────────────…...

全球扩张加剧法律复杂性,但仅有7%的企业实现全面合规
• 47%的总法律顾问表示,实际控制人规则对法律运营构成了最大的风险 • 44%的企业对能否满足跨境数据安全要求缺乏信心 随着企业在2026年加速全球扩张,合规工作却未能跟上步伐。事实上,根据全球领先的商业管理与合规解决方案提供商CSC的一项最…...

LLM Wiki Bridge:将Markdown知识库编译为AI可操作的概念图谱
1. 项目概述:将你的知识库变成AI的“第二大脑” 如果你和我一样,是个重度笔记用户,大概率也经历过这样的场景:在Obsidian、Logseq或者任何你喜欢的Markdown编辑器里,日积月累了成百上千篇笔记。你清楚地记得自己写过某…...

终端里的编程副驾:DeepSeek-TUI-项目深度拆解,实测与原理分析
刷 GitHub Trending 又看到一个挺有意思的东西:DeepSeek-TUI。说白了,就是把 DeepSeek V4 这个编程大模型,直接塞进了你的终端里。 这玩意儿不是简单的 CLI 包装。我跑了一下 curl 看 README,发现他们搞了个完整的 TUI(…...