PostgreSQL 技术内幕(十二) CloudberryDB 并行化查询之路
随着数据驱动的应用日益增多,数据查询和分析的量级和时效性要求也在不断提升,对数据库的查询性能提出了更高的要求。为了满足这一需求,数据库引擎不断经历创新,其中并行执行引擎是性能提升的重要手段之一,逐渐成为数据库系统的标配特性。
Cloudberry Database(简称为“CBDB”或“CloudberryDB”)是面向分析和AI场景打造的下一代统一型开源数据库,搭载了PostgreSQL 14.4内核,采用Apache License 2.0许可协议。CBDB在Postgres的基础之上,对已有的并行执行计划进行了大量的调整和优化,实现了显著的性能提升。
在这次的直播中,HashData数据库内核研发专家介绍了Postgres的并行化原理,CBDB在并行化上的优化与改进、功能特性及实践演示。以下内容根据直播文字整理。
并行化查询介绍
PostgreSQL在很多场景下会启用并行执行计划,创建多个并行工作子进程,提升查询效率。PostgreSQL的并行化包含三个重要组件:进程本身(leader进程)、gather、workers。没有开启并行化的时候,进程自身处理所有的数据;一旦计划器决定某个查询或查询中某个部分可以使用并行的时候,就会在查询的并行化部分添加一个gather节点,将gather节点作为子查询树的根节点。
HashData研发团队在对CloudberryDB实现并行化查询时,主要对查询执行算子、Join的实现以及存储引擎并行化扫描等进行了调整和优化。

图1:非并行化查询与并行并查询对比示例
如图1所示,以3个节点的集群为例,在不开启并行化进行Not in操作时,需要耗时50多秒;而在CBDB中开启并行化查询后,用时仅需119毫秒,效率大约提升600倍。
在开启并行化查询时,有以下几处变化:
- Gather Motion从3:1提升至12:1,意味着集群的每个节点上有4个进程在同时并行工作;
- Hash节点变为Parallel Hash;
- 新算子Broadcast Workers Motion 广播每一份数据到一组并行工作的进程中的一个,避免在共享Hash表的情况下出现数据重复。
- 底层的扫描由Seq Scan变为Parallel Seq Scan。
并行扫描原理
在PostgreSQL中,数据以Heap表的形式存储。在读取时,通常有顺序扫描(Seq Scan)、索引扫描(Index Scan)和位图扫描(Bitmap scan)三种扫描方式。接下来,我们对以上三种扫描方式的并行化进行介绍。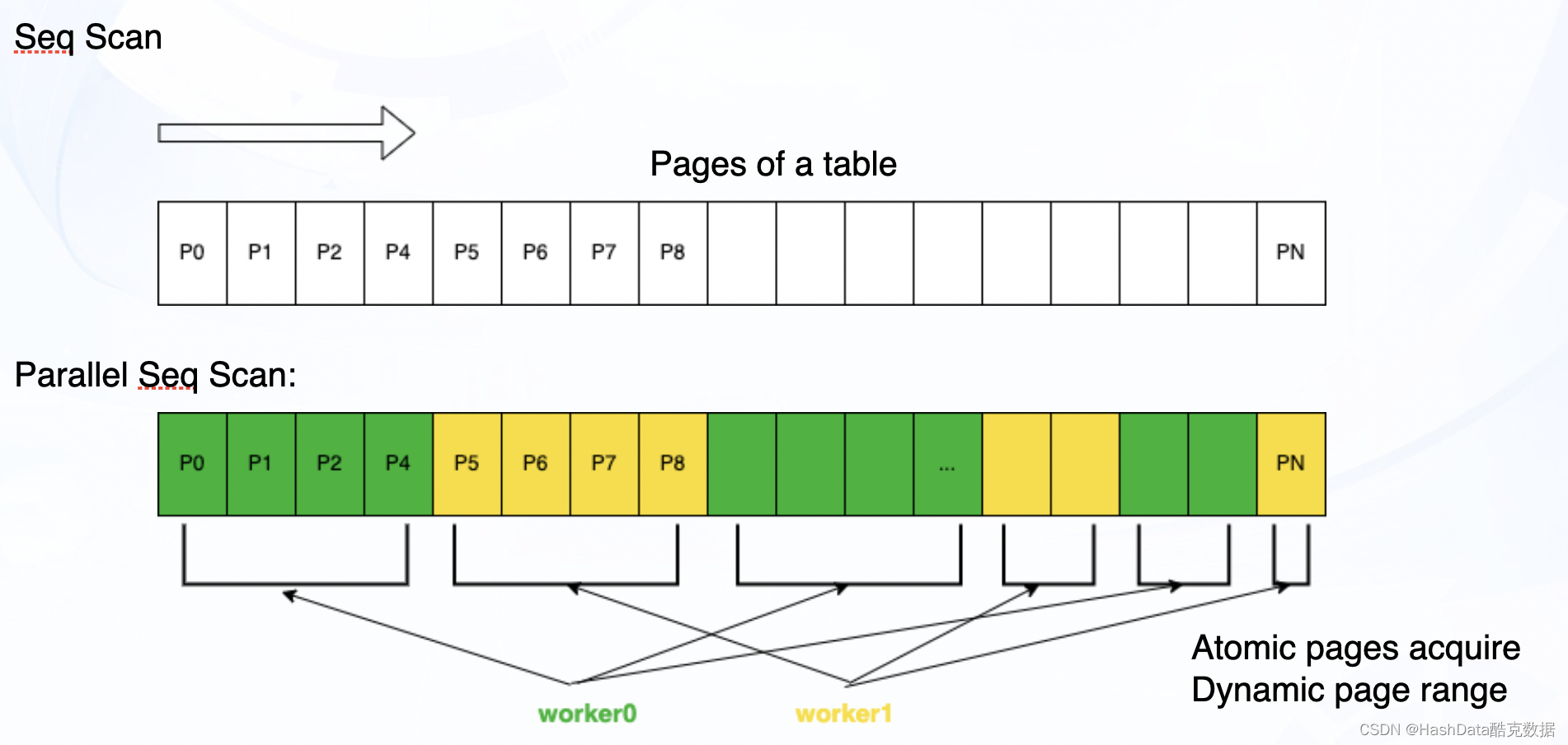
图2:PostgreSQL Heap表并行顺序扫描示意图
如图2所示,在并行顺序扫描时,两个子进程的快照是统一共享的。进程之间通过原子操作动态获得每次要读取的Page范围,避免频繁使用锁从而造成瓶颈。Page的范围并不固定,会根据数据量和读取进度进行动态调整,使得任务尽量均分在不同进程中,避免木桶效应。

图3:PostgreSQL 并行索引扫描示意图
使用索引扫描并行化查询时,子进程只需要读取对应索引的Page,每个进程每次只读取一个索引Page,再读取Heap表数据;如果Page为全体可见,可以不读取Heap表。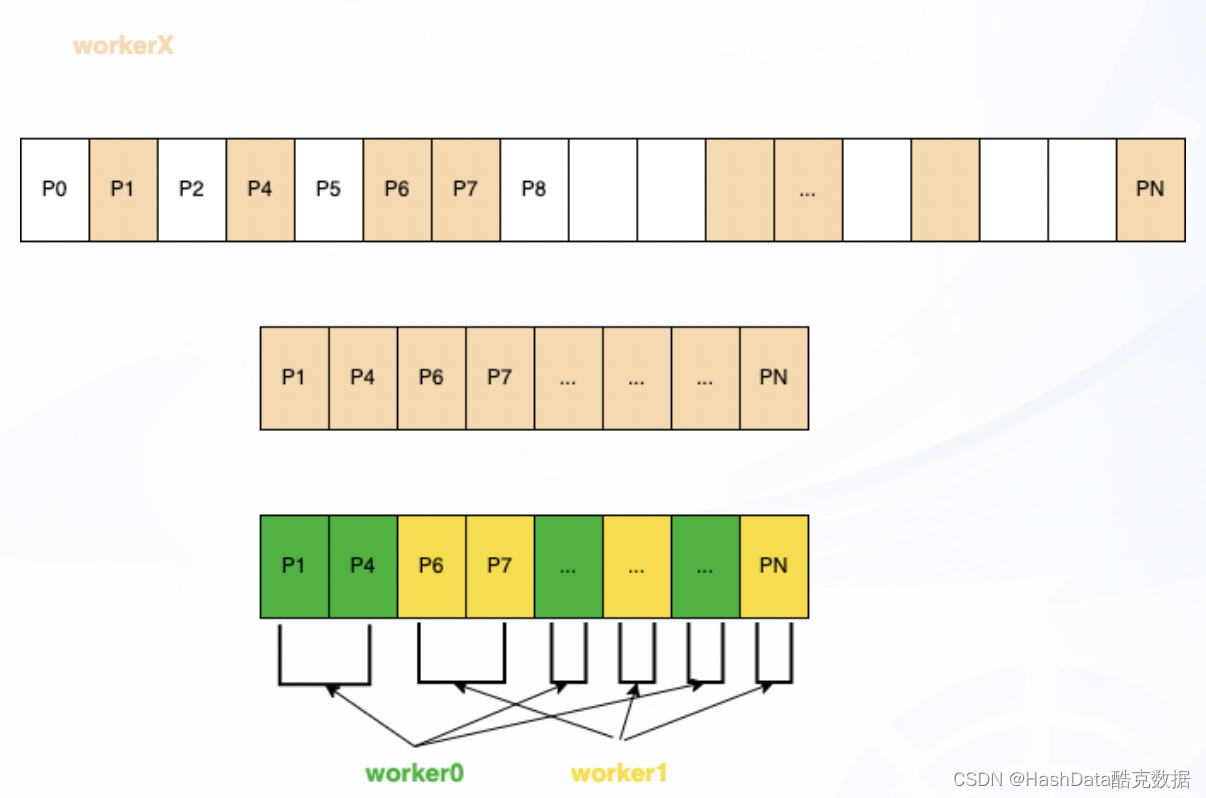
图4:PostgreSQL 并行位图扫描示意图
并行位图扫描在建立底层索引的Page范围时,只有一个进程,按照索引信息(CTID)进行顺序扫描。与PostgreSQL使用leader进程不同的是,CBDB在并行化查询时,会通过竞争的方式选择一个X进程,X进程负责建立位图,之后多个workers竞争读取数据。
图5:CloudberryDB AO表并行化查询示意图
除了Heap表之外,CBDB还引入了AO表,用来专门存储以追加方式插入的元组。如图5所示,AO表的并行扫描是通过原子操作获取Segfiles,让各个进程通过竞争的方式读取数据。
并行Join实现
并行能力的优化需要从多方面来实现,仅凭优化扫描方式能实现的性能提升有限,Join的并行化改造是另一个重要方向。
在PG中有三种Join,分别为Nestloop Join、Merge Join和Hash Join,CBDB对上述三种Join均实现了并行化。此外,一大特色是增加了共享内表的Hash Join(Parallel-aware Hash Join)。
Parallel-aware Hash Join与Hash Join相似,区别在于前者是可以共享的,进程之间相互协作共同建立共享的Hash内表。
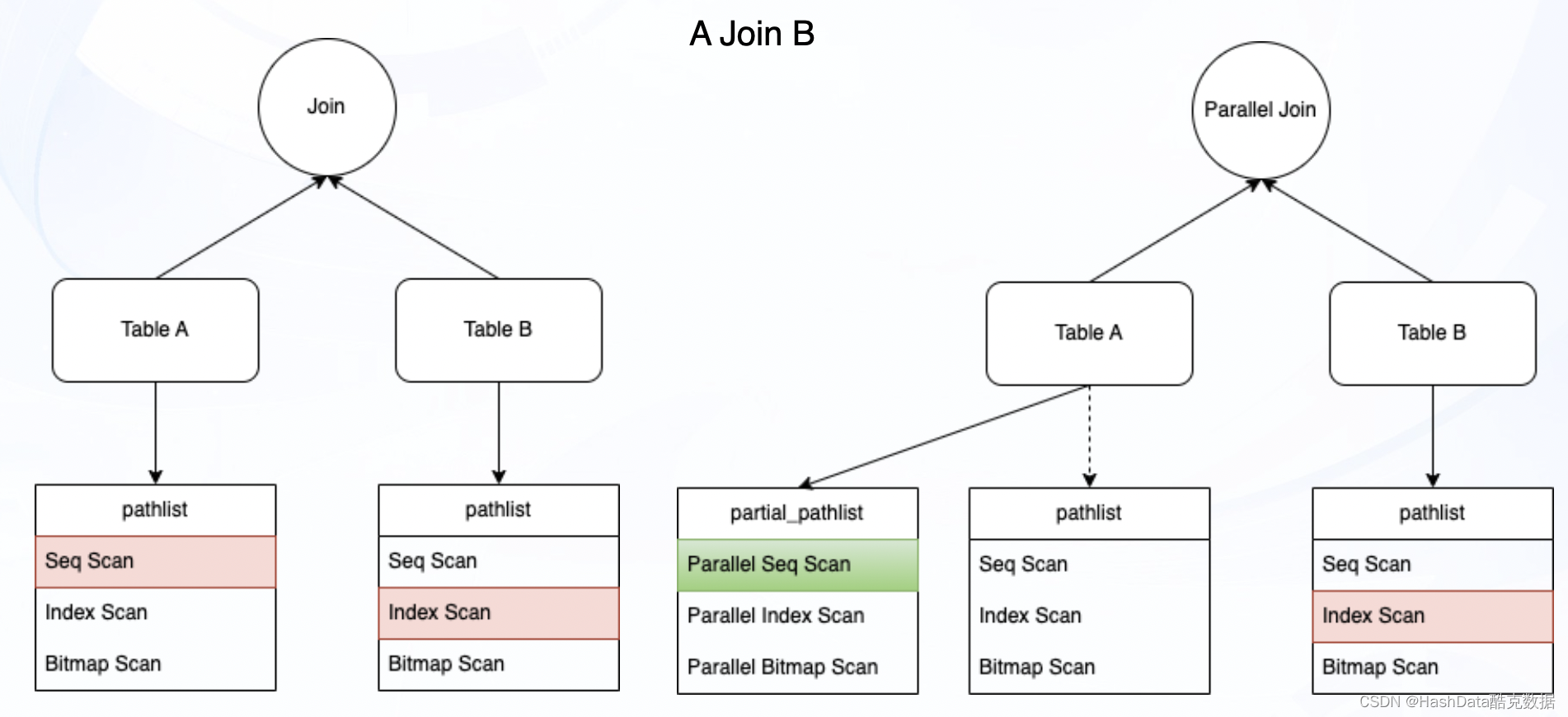
图6:Build a Join并行化实现流程示意图
如图6所示,在PG非并行的情况下,构建Join时从目标对象(Table A、Table B)各选取一条综合代价最低的执行路径,合成Join relations路径。在开启并行化后,会在上述情况下增加一条并行化最佳路径,与非并行化路径构建Join。
数据分布并行化
在Greenplum 中,数据分布有Partitioned、Replicated、Bottleneck三种情况,它们之间可以通过Motion改变Locus的属性进行互相转化,实现数据重分布,CBDB也沿用了这一特性。
图7:CBDB数据分布特性示意图
在CBDB构建Join的时候,可以通过改变Locus进行数据相容。在转化过程中遵循两个原则:
- 在Join时,要保证数据不重复、不丢失;
- 要选择代价最小的方式。
与Greenplum 不同的是,CBDB在开启并行化之后,新建了三个新的Locus 并行模式,实现不同的数据分布:HashedWorkers、SegmentGeneralWorkers和ReplicatedWorkers。 HashedWorkers Locus表示数据分布在同一组进程之间是随机的,但是合并后数据分布变成Hashed Locus。同理,SegmentGeneralWorkers 和ReplicatedWorkers也代表了数据在进程间随机,合并后满足各自的分布状态。
此外,CBDB还实现了并行刷新物化视图、并行Create Table AS、多阶段并行化Aggregation/Limit等。通过以上诸多并行优化措施后,CBDB性能得到大幅度的提升,在特定场景下甚至可以实现千百倍的查询效率提升,支持企业海量数据的复杂分析需求。
图8:CBDB并行化性能曲线图
并行化查询是CBDB在研发立项之初就确定的产品方向,我们希望能够通过多线程并行执行来充分释放现代多核大内存的硬件能力,降低包括IO以及CPU计算在内的处理时间,实现响应时间的大幅下降,更好地提升用户使用体验和业务敏捷度。
相关文章:
PostgreSQL 技术内幕(十二) CloudberryDB 并行化查询之路
随着数据驱动的应用日益增多,数据查询和分析的量级和时效性要求也在不断提升,对数据库的查询性能提出了更高的要求。为了满足这一需求,数据库引擎不断经历创新,其中并行执行引擎是性能提升的重要手段之一,逐渐成为数据…...

Vue学习计划-Vue2--Vue核心(七)生命周期
抛出问题:一进入页面就开启一个定时器,每隔1秒count就加1,如何实现 示例: <body> <div id"app">{{ n }}<button click"add">执行</button> </div><script>let vm new …...
———HBuilder的下载与使用(详细步骤))
前端知识笔记(三十四)———HBuilder的下载与使用(详细步骤)
一、HBuilder IDE的下载 HBuilder下载官网地址: 在地址栏中直接输入https://www.dcloud.io 或者直接点击下面的链接 DCloud - HBuilder、HBuilderX、uni-app、uniapp、5、5plus、mui、wap2app、流应用、HTML5、小程序开发、跨平台App、多端框架 进入官网&#x…...

stl容器
大部分容器的size的复杂度如下: std::vector: 时间复杂度为(1). std::deque: 时间复杂度为 O(1). 双端队列 std::list: 时间复杂度为 O(1)(C11 及以后的版本)。 std::forward_list: 时间复…...
android https 证书过期
有的时候 我们android https 证书过期 ,或者使用明文等方式去访问服务器 可能会碰到类似的 问题 : javax.net.ssl.SSLHandshakeException: Chain validation failed java.security.cert.CertPathValidatorException: Response is unreliable: its validi…...
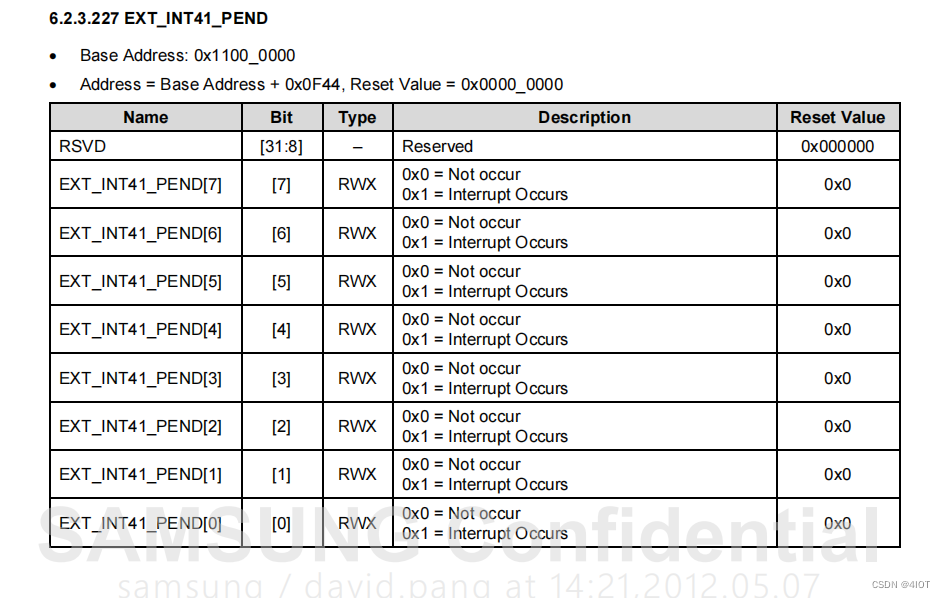
lv11 嵌入式开发 中断控制器14
目录 1 中断控制器 编辑 2 Exynos4412下的中断控制器 2.1 概述 2.2 特征 编辑 2.3 中断状态 2.4 中断类型 2.5 中断控制器GIC中断表 3 中断控制器寄存器详解 3.1 ICDDCR(Interrupt Controller Distributor Control Register) 3.2 ICDISER…...

IDEA 出现问题:Idea-操作多次commit,如何合并为一个并push解决方案
❤️作者主页:小虚竹 ❤️作者简介:大家好,我是小虚竹。2022年度博客之星评选TOP 10🏆,Java领域优质创作者🏆,CSDN博客专家🏆,华为云享专家🏆,掘金年度人气作…...
)
贝蒂的捣蛋小游戏~(C语言)
引言: 前面贝蒂已经给大家介绍了选择,循环结构~,今天贝蒂就基于这两种结构,为大家讲解一种捣蛋小游戏的设计思路和方法哦。 1.游戏要求 游戏要求: 1. 电脑⾃动⽣成1~100的随机数 2. 玩家猜数字,猜数字的过…...

c# 判断是否连接公网
有一个需求,软件需要在连接公网的状态下才能使用,否则弹出提示 我们判断一下网络不通情况 1.系统未开启网络:例如关掉了WIFI,拔掉网线 2.网络已连接无internet:连接了路由器,但路由器未连接外网 对于以上…...
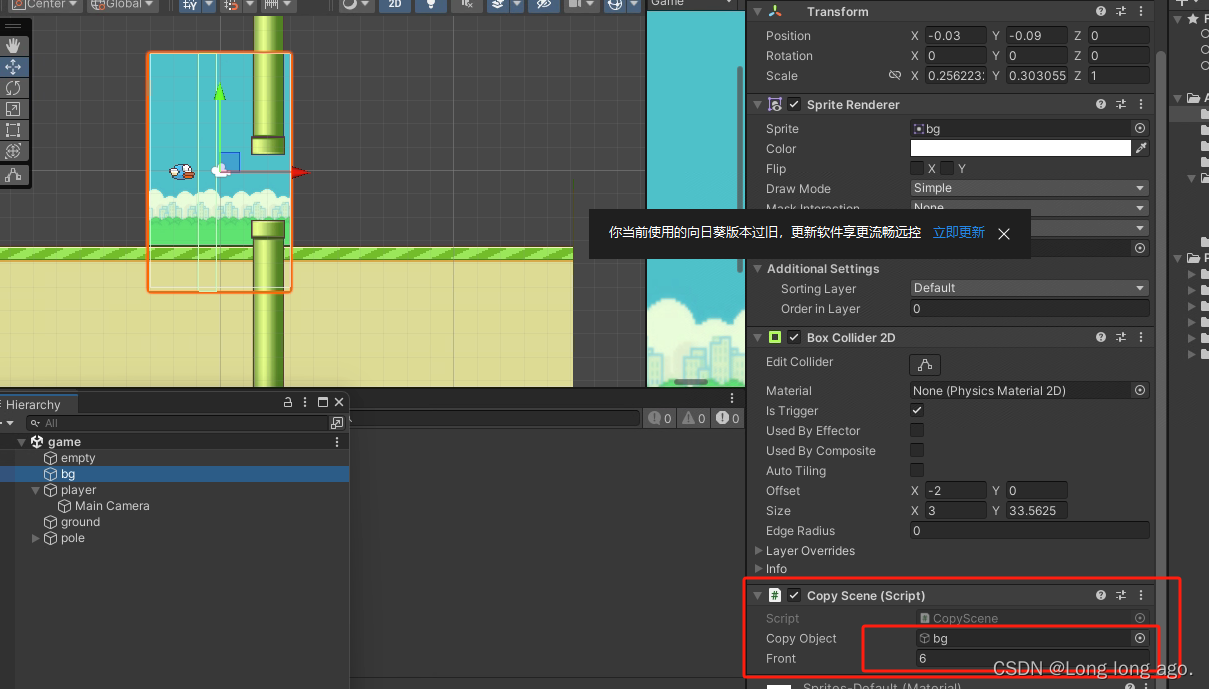
unity 2d 入门 飞翔小鸟 场景延续(八)
1、新建c#脚本如下 代码,在前方生成生成自身图片并3s后销毁自身,在碰撞物体后小鸟死亡后不删除自身 using System.Collections; using System.Collections.Generic; using UnityEngine;public class CopyScene : MonoBehaviour { //要复制的对象public…...

scrapy介绍,并创建第一个项目
一、scrapy简介 scrapy的概念 Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。 Scrapy 使用了Twisted异步网络框架,可以加快我们的下载速度。 Scrapy文档地址:http://scrapy-chs.readthedocs.io/z…...
 - 胜利与失败)
Rust语言项目实战(九 - 完结) - 胜利与失败
回顾 在前面的章节中,我们已经实现了这个游戏中大部分的模块和功能,我们可以指挥我们的战机左右移动,并发射子弹;我们还创造了一堆的侵略者,从屏幕上方缓缓降落,试图到达屏幕的底部。 本章中,我们将对游戏的输赢作出最后的裁决,到底是我们的保卫者英勇无敌,还是侵略…...
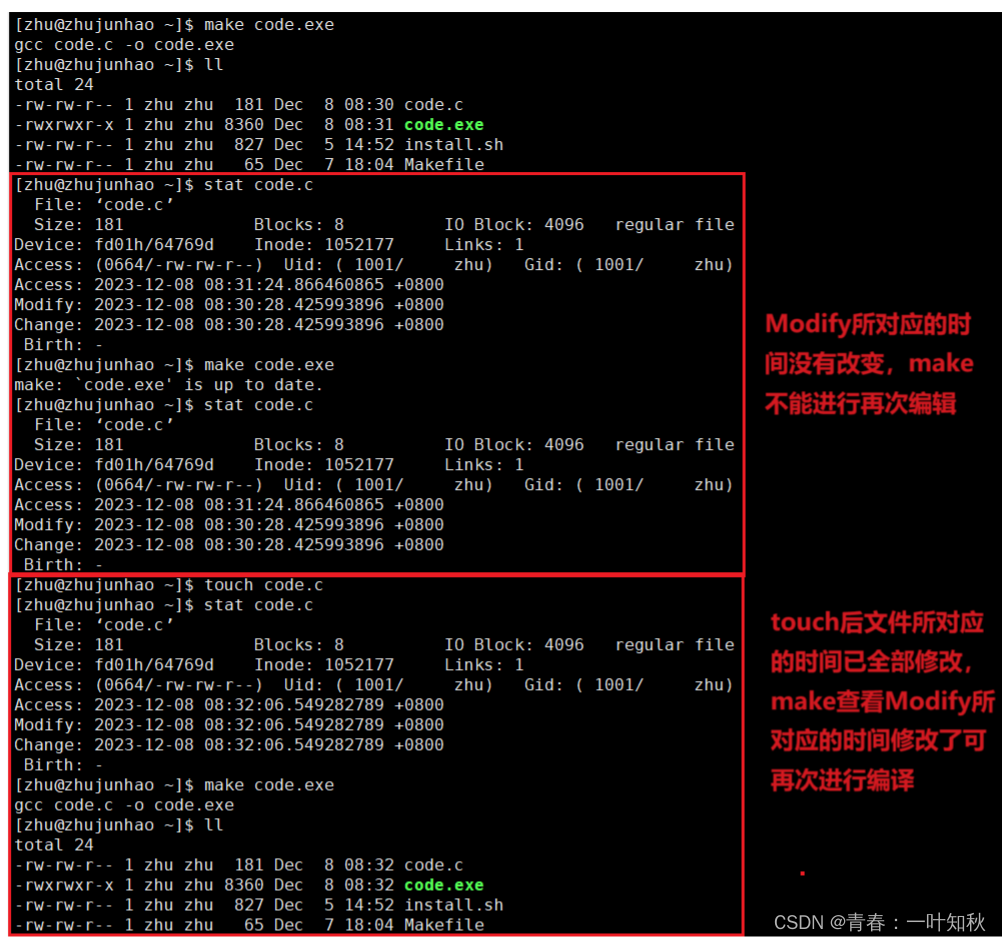
【Linux系统编程】项目自动化构建工具make/Makefile
介绍: make和Makefile是用于编译和构建C/C程序的工具和文件。Makefile是一个文本文件,其中包含了编译和构建程序所需的规则和指令。它告诉make工具如何根据源代码文件生成可执行文件,里面保存的是依赖关系和依赖方法。make是一个命令行工具&a…...

harmony开发之Text组件的使用
TextInput、TextArea是输入框组件,通常用于响应用户的输入操作,比如评论区的输入、聊天框的输入、表格的输入等,也可以结合其它组件构建功能页面,例如登录注册页面。 图片来源黑马程序员 Text组件的使用: 文本显示组…...

using meta-SQL 使用元SQL 六
%Table Syntax %Table(recname) Description Use the %Table construct to return the SQL table name for the record specified with recname. 使用%Table构造返回使用recname指定的记录的SQL表名。 This construct can be used to specify temporary tables for runn…...

如何将浮点数点左边的数每三位添加一个逗号,如 12000000.11 转化为『12,000,000.11』
// 方法二 function format1(number) {return Intl.NumberFormat().format(number); } // 方法三 function format2(number) {return number.toLocaleString("en"); }...

朴素贝叶斯 贝叶斯方法
朴素贝叶斯 贝叶斯方法 背景知识 贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。先验概率:根据以往经验和分析得到的概率。我们用 P ( Y ) P(Y) P(Y)来代表在没有训练数据前假设…...
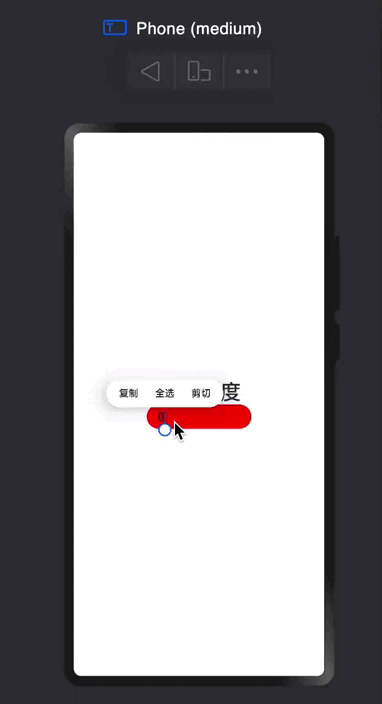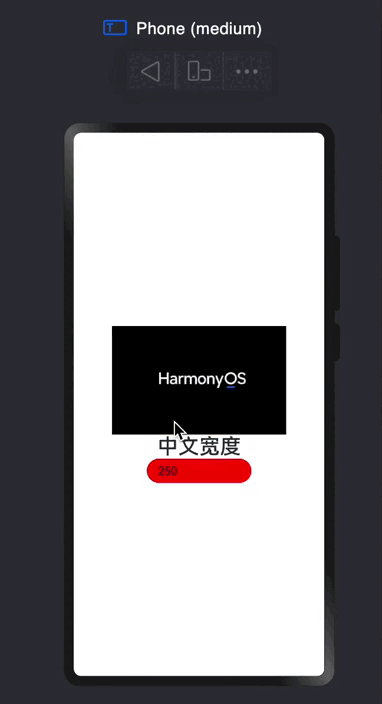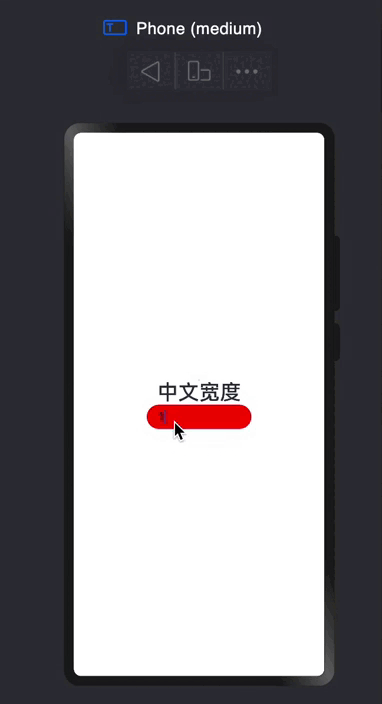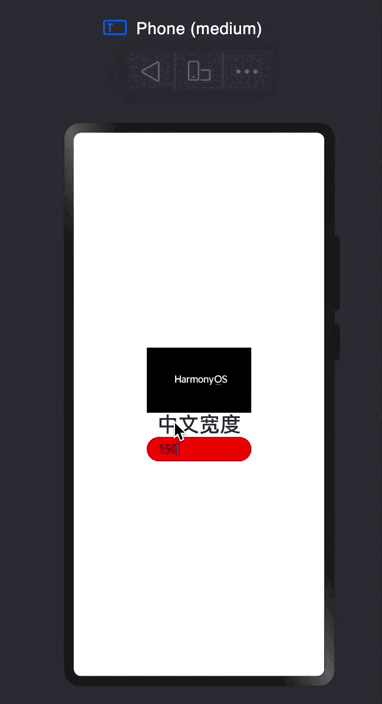
探索鸿蒙 TextInput组件
TextInput 根据组件名字,可以得知他是一个文本输出框。 声明代码👇 TextInput({placeholder?:ResourceStr,text?:ResourceStr}); placeholder: 就是提示文本,跟网页开发中的placeholder一样的 text:输入框当前的文本内容 特殊属…...
)
CNN,DNN,RNN,GAN,RL+图像处理常规算法(未完待续)
好的,让我们先介绍一些常见的神经网络模型,然后再讨论图像处理的常规算法。 神经网络模型: 1. CNN(卷积神经网络) 原理: CNN主要用于处理图像数据。它包含卷积层、池化层和全连接层。卷积层通过卷积操作…...
C# 语法笔记
1.ref、out:参数传递的两种方式 ref:引用传递 using System; namespace CalculatorApplication {class NumberManipulator{public void swap(ref int x, ref int y){int temp;temp x; /* 保存 x 的值 */x y; /* 把 y 赋值给 x */y temp; /* 把 t…...

基于MCP协议构建Naver搜索服务器,为AI智能体赋能实时信息获取
1. 项目概述:一个连接AI与实时信息的桥梁最近在折腾AI应用开发,特别是围绕OpenAI的Assistant API和Claude的Tool Use功能时,我一直在思考一个问题:如何让这些强大的AI模型摆脱其知识库的“时间枷锁”,获取到最新、最实…...

别再用游戏卡炼丹了!手把手教你给台式机装上Tesla P4/P40,搞定Ubuntu 20.04深度学习环境
低成本打造专业级AI工作站:Tesla P4/P40在Ubuntu 20.04的完整实战指南 当你在二手市场以不到2000元的价格淘到一张Tesla P40时,可能会被它12GB GDDR5显存和3840个CUDA核心的参数所吸引——这相当于RTX 2080 Ti约70%的性能,价格却只有其三分之…...

盘点那些能让性能翻倍的C++现代特性
在C开发中,“性能”是压倒一切的核心诉求之一。虽然编译器在不断变聪明,但有些底层优化仍需开发者通过选用正确的语言特性来触发。今天这篇文章,我们就来盘点几个能给代码带来质跃式性能提升的 C 现代特性,并附带直观的代码示例。…...

5个核心功能:Winhance中文版如何重塑你的Windows体验
5个核心功能:Winhance中文版如何重塑你的Windows体验 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_…...
)
分析梳理--分子动力学模拟的常规步骤八(Gromacs)
作者,Evil Genius 每一个组学内容都很多啊,都需要花费大量的时间学习,学习的最好阶段就是学生阶段,你的导师就是你的伯乐,像我这种社会底层人员,纯纯没事干,学了有没有用真的不知道。 这一篇我们继续分子动力学,上一步我们处理配体分子得到符合Gromacs的出入文件 这里…...

ant-design 1.x版本表格头部拖拽、可拖拽列实现
表格列宽拖拽调整 — 问题总结 版本 “vue”: “2.6.11”,“vue-draggable-resizable”: “^2.3.0”,"ant-design “:”1.7.0“ 问题 1:thDom 为 null 导致 getBoundingClientRect 报错 现象: TypeError: Cannot read properties of nul…...

AI教材写作神器!低查重AI工具,一键生成符合标准的专业教材!
许多教科书编写者常常会面临这样的困扰:在认真打磨正文内容的同时,配套资源的缺乏却影响到了整体的教学效果。设计有难度的课后练习题时,脑海中却没有多样的创意;想要制作生动的教学课件,却苦于缺乏技术支持࿱…...

告别手动切号!全栈实战:用AI辅助编写一个「多平台海量私信秒回」系统
最近在研究全网营销和客资管理系统,看到这样两张产品宣传图,直击痛点:一个工作台,快速处理海量私信/评论(告别多个聊天窗口来回切换)。7x24小时在线,AI秒回客户(告别响应时间长、客户…...

Taotoken用量看板如何帮助团队管理大模型API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队管理大模型API成本 作为团队的技术负责人,在引入大模型能力支持多个项目时,一…...

BookGet:构建分布式古籍数字资源采集系统的技术架构与实现
BookGet:构建分布式古籍数字资源采集系统的技术架构与实现 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget BookGet是一款基于Go语言开发的分布式古籍数字资源采集工具,专为历史研…...